这是面试中经常问的一个场景题,主要考察研发的过往经验积累,需要系统性地回答,不能笼统简单敷衍。以下是整理的相关内容
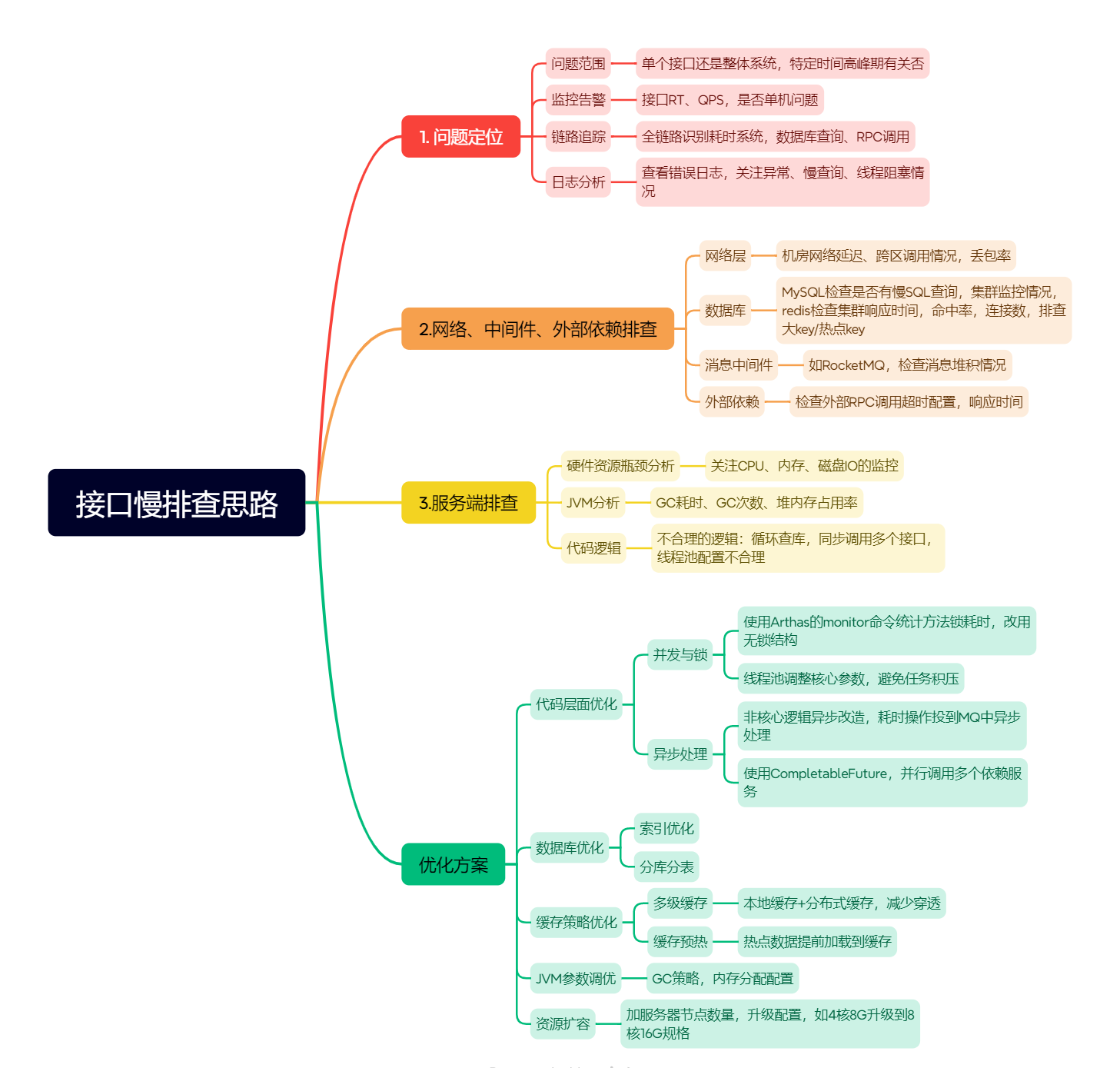
1.排查思路总览
2.方法论
面试问到这个问题,面试官其实想听到一些方法论的东西,并不想了解零零散散的排查过程。需要重点关注的点包括:
- 结合业务场景(大促、双11促销、业务高峰期等)给出具体排查过程
- 在阐述理论的同时,需结合工具的使用(Arthas、SkyWalking、Prometheus、Grafana等)
- 补充后续优化方案,如熔断、压测、方案如何实施等
3.具体排查步骤
3.1 问题定位
(1)定位问题的范围
- 确认是单个接口还是整体系统响应慢
- 是持续性问题还是突发性问题
- 是否与特定时间段(如流量高峰期)相关
- 是否与特定业务场景或请求参数相关
(2)监控告警
查看APM系统(如SkyWalking、Prometheus)的接口响应时间、错误率、QPS等指标,确认是否全局性异常或单实例问题。
(3)链路追踪
使用分布式链路系统(如SkyWalking)追踪请求全链路,识别耗时环节(如数据库查询、RPC调用)。
示例:发现某互动玩法接口因Redis集群节点故障导致缓存读取延迟。
(4)日志分析
检查错误日志(ELK Stack),重点关注慢查询日志、线程阻塞、异常堆栈。如:通过grep "Timeout" application.log过滤超时请求。
3.2 网络、中间件、外部依赖排查
(1)网络层排查
- 延迟检测:ping/traceroute确认机房内网延迟,排查跨可用区调用,有监控可看监控
- 丢包率:tcpdump抓包分析重传率,优化Nginx的keepalive_timeout。查看网络监控看板获取丢包率
(2)中间件排查
- Redis:redis-cli --latency检测集群响应时间,排查大Key/热Key,检查Redis集群的缓存命中率,连接数监控
- RocketMQ:检查堆积消息(mqadmin consumerProgress),优化消费者并发度。
- MySQL:SHOW PROCESSLIST定位慢查询,用explain分析SQL执行计划,查看数据库的性能监控,CPU使用率
- 外部依赖:检查调用外部RPC接口的响应时间
3.3 服务端性能排查
这一步排查应用服务器本身的资源性能问题,以及代码逻辑问题
1. 服务器资源瓶颈分析
- CPU:使用top -H定位高负载线程,结合jstack分析线程栈(如死循环、锁竞争)。
- 内存:通过jstat -gcutil观察GC频率,jmap排查内存泄漏(如未释放的Redis连接池)。
- 磁盘IO:iostat检查磁盘负载,优化日志写入策略(如异步刷盘)。
2. JVM调优
- GC策略:高并发场景优先选用G1,调整MaxGCPauseMillis控制停顿时间。
- 堆外内存:检查Netty等框架的DirectBuffer泄漏(Native Memory Tracking)
3.代码逻辑排查
- 检查是否存在不合理代码逻辑:循环查询数据库、同步调用多个外部接口等
4.优化方案
通过上述过程定位到响应慢的原因,接着就是如何进行优化了,从以下角度进行优化:
-
代码层面优化(锁竞争优化、异步处理、批量处理)
-
数据库优化(索引优化、SQL改写、分库分表)
-
缓存策略优化(多级缓存、大促前预加载热点数据)
-
资源扩容(增加服务器节点、提升配置)
-
JVM参数调优(内存分配、GC策略调整)
-
中间件参数调优(连接池大小、超时时间)
总结回答模板示例
在京东高并发场景下,我会先通过监控和链路追踪确定问题边界。比如某次大促发现任务领取接口变慢,追踪发现是Redis集群跨机房访问延迟导致。
临时方案是切换本地缓存,长期优化数据分片策略。
同时结合Arthas定位到线程池配置不合理,调整后QPS提升40%。
这类问题需要建立常态化巡检机制,比如每周分析慢SQL日志,提前优化潜在瓶颈。