简介
上文中,我们讲到了选择排序,冒泡排序,插入排序,希尔排序。
都是相对比较简单的实现方式,因为它们都是以人的思维,维护一个index,将index与周围元素逐步对比。直到整个数组有序。
但越是效率高的算法,反而要越接近计算的的思维。否则非常难以突破O(N^2)的桎梏。
而接下来的几种效率高算法,则是一步一步接近计算机的思维,实现排序高效。
二叉树前序遍历:快速排序
快速排序的核心思路是:先将一个元素排好序,然后递归排序剩下的元素
这里可能难以理解,这说的是什么逼话?我们再拆解一下。
-
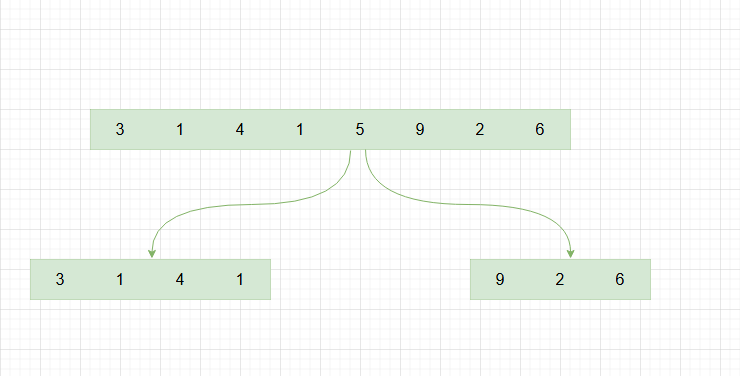
在数组中随机选一个作为排序元素
[3,1,4,1,5,9,2,6]
^
pivot -
进行排序,将大于pivot的元素放右边,小于的放左边
[1,1,2,3,4,5,9,6]
^
pivot -
递归重复以上步骤,寻找新的切分元素,然后交换。
[[1,1,2],3, [4,5,9,6]]
^ ^ ^
pivot2 pivot pivot3 -
直到全部排序完成
[1,1,2,3,4,5,6,9]
根据上面的思维描述,我们可以写出一个代码框架,并将它们抽象成一颗二叉树
public void Sort(int[] arr,int left,int right)
{
if (left > right)
return;
//进行切分,并将P排好序
int p = Partition(arr, left, right);
//对左右子数
//是不是类似二叉树的前序遍历?
Sort(arr, left, p - 1);
Sort(arr, p + 1, right);
}
/// <summary>
/// 分区操作
/// </summary>
/// <param name="arr"></param>
/// <param name="left"></param>
/// <param name="right"></param>
/// <returns></returns>
private static int Partition(int[] arr, int left, int right)
{
// 选择最右边的元素作为基准元素
int pivot = arr[right];
int i = left - 1;
for (int j = left; j < right; j++)
{
if (arr[j] <= pivot)
{
i++;
(arr[i], arr[j]) = (arr[j], arr[i]);
}
}
(arr[i + 1], arr[right]) = (arr[right], arr[i + 1]);
return i + 1;
}
复杂度分析
- 时间复杂度
在理想情况下,这是一颗平衡二叉树,但在极端情况下退化成单链表。因此时间复杂度平均为O(n log n),最坏为O(n ^2) - 空间复杂度
平均情况下为O(log n),最坏情况下为O(n),主要取决于递归调用栈的深度 - 排序稳定性
排序不稳定,因此排序稳定的前提是交换左右元素,而Partition会带来切分,所以这是可以推理出来的。 - 原地排序
快速排序不需要额外的辅助空间,所以是原地排序算法。在遍历二叉树时,递归深度为树的高度,所以空间复杂度为O(log n)
二叉树的后序遍历:归并排序
上面说到,快速排序的核心思路是先将一个元素排好序,然后递归排序剩下的元素。
而归并排序的思路是,把数组切成两半,然后单独排序,最后再合并。
public void Sort(int[] arr)
{
if (arr.Length <= 1)
return;
int mid = arr.Length / 2;
//归并排序需要空间来合并有序数组,复杂度O(N)
int[] left = new int[mid];
int[] right = new int[arr.Length - mid];
Array.Copy(arr, 0, left, 0, mid);
Array.Copy(arr, mid, right, 0, arr.Length - mid);
Sort(left);
Sort(right);
//合并有序数组,是不是有点类似二叉树的后序位置?
Merge(arr, left, right);
}
private static void Merge(int[] arr, int[] left, int[] right)
{
int i = 0, j = 0, k = 0;
while (i < left.Length && j < right.Length)
{
if (left[i] < right[j])
{
arr[k] = left[i];
i++;
}
else
{
arr[k] = right[j];
j++;
}
k++;
}
while (i < left.Length)
{
arr[k] = left[i];
i++;
k++;
}
while (j < right.Length)
{
arr[k] = right[j];
j++;
k++;
}
}复杂度分析
- 时间复杂度
归并排序的时间复杂度始终为O(n log n),其中 n 是数组的长度。这是因为每次分解数组的时间复杂度为O(log n),而每次合并数组的时间复杂度为O(n)。 - 空间复杂度
O(n),主要用于存储合并过程中临时创建的数组。 - 排序稳定性
稳定排序,因为在合并过程中,当两个元素相等时,会优先选择左边子数组的元素,从而保证相同元素的相对顺序不变。 - 原地排序
不是原地排序,因为需要额外的辅助数组。
二叉堆的妙用:堆排序
堆排序是二叉堆衍生出来的排序算法,核心分为两步。第一在原数组上建堆(大顶堆 or 小顶堆),在进行原地排序。
最简单的堆排序算法,就是直接利用二叉堆的优先级队列,然后用一个数组存储结果不就好了吗?
public static void Run()
{
//创建一个小顶堆
var q = new PriorityQueueSimple(10);
q.Push(3);
q.Push(2);
q.Push(1);
q.Push(5);
q.Push(4);
var arr = new int[q.Count];
for (int i = 0; i < arr.Length; i++)
{
arr[i] = q.Pop();
Console.WriteLine(arr[i]);
}
}这里带来的问题是,我们额外用了一个数组来存储元素。而我们希望是原地排序,不带来额外的空间复杂度。
因此,我们优化后的代码就变成了:
public class HeapSort
{
public static void Run()
{
var t =new HeapSort();
//第一步,原地建堆
var arr = new int[] { 3, 1, 4, 1, 5, 9, 2, 6 };
for (int i = 0; i < arr.Length; i++)
{
t.MinHeapSwim(arr, i);
}
//第二部,排序
var length = arr.Length;
while (length > 0)
{
//删除堆顶,并放到堆最后面
(arr[0], arr[length - 1]) = (arr[length - 1], arr[0]);
length--;
//下浮
t.MinHeapSink(arr, 0, length);
}
for (int i = arr.Length-1; i>=0; i--)
{
Console.WriteLine(arr[i]);
}
}
/// <summary>
/// 小顶堆的上浮
/// </summary>
/// <param name="heap"></param>
/// <param name="node"></param>
void MinHeapSwim(int[] heap,int node)
{
while(heap[node] < heap[Parent(node)])
{
//swap
(heap[Parent(node)], heap[node]) = (heap[node], heap[Parent(node)]);
node = Parent(node);
}
}
void MinHeapSink(int[] heap, int node,int count)
{
while (Left(node) < count || Right(node) < count)
{
int minNode = node;
if (Left(node) < count&& heap[node] > heap[Left(node)])
{
minNode = Left(node);
}
if (Right(node) < count && heap[minNode] > heap[Right(node)])
{
minNode = Right(node);
}
if (minNode == node)
{
break;
}
//swap
(heap[node], heap[minNode]) = (heap[minNode], heap[node]);
}
}
// 父节点的索引
int Parent(int node)
{
return (node - 1) / 2;
}
// 左子节点的索引
int Left(int node)
{
return node * 2 + 1;
}
// 右子节点的索引
int Right(int node)
{
return node * 2 + 2;
}
}其实没什么变化,相对之前实现的优先级队列来说。只是把数组作为参数传递,实现原地排序而已。
复杂度分析
- 时间复杂度
O(n log n) ,因为要对swim/sink要对每个元素调用 - 空间复杂度
O(1) - 排序稳定性
不稳定,因为skin过程中,要将堆顶元素,与堆尾元素交换。 违背了相邻元素交换的原则,所以不稳定。 - 原地排序
是,我们的优化过程就是为了结果原地排序的问题。