树状数组是算法中一种十分重要的数据结构!通过这篇文章你能够快速的get到树状数组的精髓,即使是第一次接触树状数组也能让你完全弄懂
目录
[怎么让计算机计算 lowbit?](#怎么让计算机计算 lowbit?)
先来举个例子:我们想知道 a1...7的前缀和,怎么做?
一种做法是:a1 +a2 + a3 + a4 .... a7,需要求 7个数的和。
但是如果已知三个数 A,B,C,,A = a1...4 的总和,B = 5...6 的总和和C = a7..7(其实就是a7 自己)。你会怎么算?你一定会回答:A + B + C,只需要求 3个数的和。
这就是树状数组能快速求解信息的原因:我们总能将一段前缀 1..n 拆成 不多于 段区间 ,使得这
段区间的信息是 已知的。
于是,我们只需合并这 段区间的信息,就可以得到答案。相比于原来直接合并 个信息,效率有了很大的提高。不难发现信息必须满足结合律,否则就不能像上面这样合并了。
那么如何划分a1.. n呢? 咱们直接先说结论吧 (图片出自灵神) 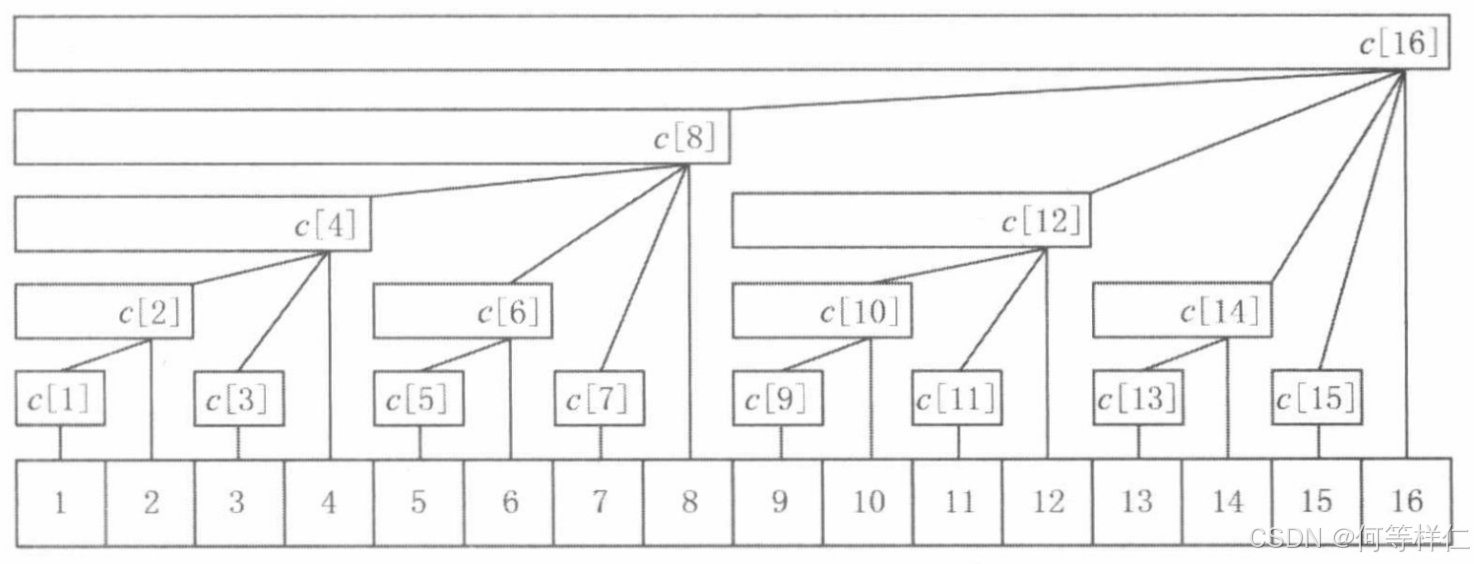
管辖区间
那么问题来了, 管辖的区间到底往左延伸多少?也就是说,区间长度是多少?
树状数组中,规定 管辖的区间长度为
,其中:
- 设二进制最低位为第 0 位,则 k 恰好为 x 二进制表示中,最低位的 1 所在的二进制位数;
- 2^k(cx 的管辖区间长度)恰好为 x 二进制表示中,最低位的 1 以及后面所有 0 组成的数。举个例子,
管辖的是哪个区间?
因为 ,其二进制最低位的 1 以及后面的 0 组成的二进制是 1000,即 8,所以
管辖 8 个 a 数组中的元素。
因此,代表
的区间信息。
我们记 x 二进制最低位 1 以及后面的 0 组成的数为 ,那么 cx 管辖的区间就是
。 为什么要加1呢这个理解的十分简单你看
这里注意:指的不是最低位 1 所在的位数
,而是这个 1 和后面所有 0 组成的
。
怎么让计算机计算 lowbit?
(如果是人那么一看就知道了,那么如何让计算机理解呢?)
根据位运算知识,可以得到 lowbit(x) = x & -x。这是一种简单的实现方法
如果对位运算不是十分敏感的可能不知道为什么是这样算的,我们可以假设x是 7那么相应的lowbit(7) 为1 对于负数的二进制就是求法:
- 先求绝对值的二进制。对于-7来说7的二进制是111
- 再求第一步的补码那么就是000
- 在将第二步得到的值 加一得到 001,那么001就是-7的二进制,当然前面缺位补0
那么言归正传 7 & -7 就是111 & 001 那么lowbit就是001 十进制就是1表示当前lowbit(7)值为1,并且区间只有一个值
python
def lowbit(self, x):
return x & -x补充:对于计算机是这样理解的,那么对于我们还有一种更容易的理解方式,参考灵神题解

区间初始化:
python
def __init__(self, nums: List[int]):
n = len(nums)
tree = [0] * (n + 1)
for i, x in enumerate(nums, 1):
tree[i] += x
nxt = i + (i & -i) #下一个关键区间的右端点,这也就说明当前区间在下一个区间内,那么就要操
#这里的 i & -i 就是lowbit
if nxt <= n:
tree[nxt] += tree[i]
self.nums = nums
self.tree = tree 更新区间
假设下标 x 发生了更新,那么所有包含 x 的关键区间都会被更新。
例如下标 5 更新了,那么关键区间 5,5,5,6,1,8,1,16 都需要更新,这三个关键区间的右端点依次为 5,6,8,16。
如果在 5-6,6-8,8-16 之间连边(其它位置也同理),我们可以得到一个什么样的结构?
如下图,这些关键区间可以形成如下树形结构(区间元素和保存在区间右端点处)。
注意到:
猜想:如果 x 是一个被更新的关键区间的右端点,那么下一个被更新的关键区间的右端点为 x+lowbit(x)。
我们需要证明两点:
- 右端点为 x 的关键区间,被右端点为 x+lowbit(x) 的关键区间包含。
- 右端点在 x+1,x+lowbit(x)−1 内的关键区间,与右端点为 x 的关键区间没有任何交集。
1) 的证明

2 )的证明

以上两点成立,就可以保证**x+lowbit(x)**是「下一个」被更新的关键区间的右端点了。
由于任意相邻被更新的关键区间之间,没有其余关键区间包含 x,所以我们可以找到所有包含 x 的关键区间,具体做法如下。
python
def update(self, index: int, val: int) -> None:#将nums[index]更新为val
delta = val - self.nums[index] #val是目标值,相当于把当前值增加了delta
self.nums[index] = val #把当前值更新了
i = index + 1 #为什么index要加1呢,因为index是下标0 --n-1 为了和1--n的c的下标对应肯定加1
while i < len(self.tree):
self.tree[i] += delta
i += i & -i #手搓lowbit 计算前缀和:
在树状数组中计算1-n的前缀和有更快的方法那就是访问树状数组的结构
python
def prefixsum(self, i: int) -> int: #计算前缀和是为了计算区间,每一个区间都可以用前缀和表示
s = 0
while i:
s += self.tree[i]
i = i - (i & -i) #相当于i - lowbit(),其实就是前缀和跳到上一个关键区间的右端点了
#相较于传统计算前缀和更快,这里的prefixsum是计算1-i的前缀和计算任意区间和:
因为本质上所有子区间都可以写成两个区间和的差
python
def sumRange(self, left: int, right: int) -> int:
return self.prefixsum(right + 1) - self.prefixsum(left)关于相关题目,博主会尽快整理发表。
下面是全部实现代码和解释:
python
class NumArray:
__slots__ = 'nums', 'tree'
#__slots__是一个特殊的内置类属性,它可以用于定义类的属性名称的集合。一旦在类中定义了__slots__属
#性,Python将限制该类的实例只能拥有__slots__中定义的属性。这有助于减少每个实例的内存消耗,
#提高属性访问速度,同时也可以防止意外添加新属性。
#最右端为i的长为lowbit(i)的关键区间是 [i - lowbit(i) + 1 , i]
def __init__(self, nums: List[int]):
n = len(nums)
tree = [0] * (n + 1)
for i, x in enumerate(nums, 1):
tree[i] += x
nxt = i + (i & -i) #下一个关键区间的右端点,这也就说明当前区间在下一个区间内,那么就要操
#这里的 i & -i 就是lowbit
if nxt <= n:
tree[nxt] += tree[i]
self.nums = nums
self.tree = tree
def update(self, index: int, val: int) -> None:#将nums[index]更新为val
delta = val - self.nums[index] #val是目标值,相当于把当前值增加了delta
self.nums[index] = val #把当前值更新了
i = index + 1 #为什么index要加1呢,因为index是下标0 --n-1 为了和1--n的c的下标对应肯定加1
while i < len(self.tree):
self.tree[i] += delta
i += i & -i #手搓lowbit
# #需要证明两点:
# 1.右端点为x的关键区间,被右端点为x + lowbit(x)的关键区间包含
# 2.右端点为[x + 1, x + lowbit(x) - 1]内的关键区间,与右端点为x的关键区间没有任何交集
def prefixsum(self, i: int) -> int: #计算前缀和是为了计算区间,每一个区间都可以用前缀和表示
s = 0
while i:
s += self.tree[i]
i = i - (i & -i) #相当于i - lowbit(),其实就是前缀和跳到上一个关键区间的右端点了
#相较于传统计算前缀和更快,这里的prefixsum是计算1-i的前缀和
return s
def sumRange(self, left: int, right: int) -> int:
return self.prefixsum(right + 1) - self.prefixsum(left)希望这篇文章能帮到你,感谢点赞收藏!
