
系列文章
- Flink 实战之 Real-Time DateHistogram
- Flink 实战之从 Kafka 到 ES
- Flink 实战之维表关联
- Flink 实战之流式数据去重
流式数据是一种源源不断产生的数据,没有预定的开始与结束,至少理论上来说,它的数据输入永远不会结束。因此流式数据处理与传统的批处理技术不同,必须具备持续不断地对到达的数据进行处理的能力。
因为流式数据源源不断地产生,对流式数据做去重就十分困难,因为一条数据重复与否需要与之前的数据痕迹作比对,数据是无穷尽产生的,倘留存之前的数据,势必占据大量的存储空间,判重的过程也会随着数据量的增加而变得复杂耗时。
本文探索了一种流式大数据的实时去重方法,不一定适用于所有场景,不过或许可以给面对相似问题的你一点点启发。
Bloom 过滤器
海量数据的去重,很容易联想到 Bloom 过滤器。Bloom过滤器是由一个长度为 m 比特的数组与 k 个哈希函数组成的数据结构。
当要插入一个元素时,将数据分别输入到 k 个哈希函数,产生 k 个哈希值,以哈希值作为位数组中的索引,将相应的比特位置为 1。
如下图所示,是由 3 个哈希函数 + 18 个比特位组成的 Bloom 过滤器:

当元素 "hello" 插入时,3 个哈希函数分别计算得到 3 个哈希值,将哈希值对应的比特位置为 1。

当元素 "world" 插入时,3 个哈希函数分别计算再次得到 3 个哈希值,将哈希值对应的比特位置为 1。
Bloom 过滤器的巧妙之处就在于用一张位图来留存数据的痕迹,无需存储数据本身,用有限的空间和极低的时间复杂度即可完成过滤。
当要查询一个元素时,同样将其输入 k 个哈希函数,然后检查对应的 k 个比特,如果有任意一个比特为 0,表明该元素一定不在集合中;如果所有比特均为 1,表明该元素有(较大的)可能性在集合中。为什么无法百分之百确定元素在集合中呢?以元素 "test" 为例:

我们假设 "test" 经过哈希函数计算后得到的哈希值恰好是之前的数据 "hello" + "world" 的哈希值的子集,此时 Bloom 就会产生误判,误以为 "test" 已经在集合中。
不过这个误判率可以通过增加哈希函数的个数和位图的大小来控制在极低的范围内,给定预计输入的元素总数 n 和预期的假阳性率 p ,经过严格的数学推导可以得到哈希函数的个数 k 和位图的大小 m 的理论值:
\k = \\frac{m}{n}ln2 \\
\m = - \\frac{nlnp}{(ln2)\^2} \\
Bloom 过滤器去重流数据
使用 Bloom 对流式数据去重时,由于 Bloom 的位图空间有限而流数据是源源不断产生的,有限的位图空间无法应对无限的数据,而如果定时重置过滤器,重置将导致已保存状态位的丢失,从而引入重复记录,无法做到 "无缝" 衔接。示意图如下:

在 t 1 时刻重置过滤器时,将导致 t 1 时刻之前的 01,03 数据标记丢失,重置后再次出现的数据 03 将穿透过滤器,同理在 t 2 时刻、t 3 时刻、t4 时刻重置过滤器后,数据 06、08、09 也将穿透过滤器,造成去重结果不准确。
Bloom 过滤器队列去重流数据
既然一个 Bloom 无法应对流数据的去重,如果用多个 Bloom 过滤器能否实现预期效果呢?
我们采用 Bloom 过滤器队列对数据流进行去重,队列中的 Bloom 过滤器是按时间依次补位到队列中的,重点在 "依次",每个过滤器的 TTL (Time To Live) 相同,但存活的起止时间不同。

如图所示:
过滤器-1 的存活起止时间是*t* 0, *t*3;
过滤器-2 在 t 1 时刻补充到队列中,存活起止时间是 *t* 1, *t*4;
过滤器-3 在 t 2 时刻补位到队列中,存活起止时间是 *t* 2, *t*5;
过滤器-4 在 t 3 时刻补位到队列中,存活起止时间是 *t* 3, *t* 6,t 3 时刻,过滤器-1 的生命周期结束,从过滤器队首移除,新的队首是 过滤器-2;
过滤器-5 在 t 4 时刻补位到队列中,存活起止时间是 *t* 4, *t* 7,t 4 时刻,过滤器-2 的声明周期结束,从过滤器队首移除,新的队首是 过滤器-3;
过滤器-6 在 t 5 时刻补位到队列中,存活起止时间是 *t* 5, *t* 8,t 5 时刻,过滤器-3 的声明周期结束,从过滤器队首移除,新的队首是 过滤器-4;
过滤器队列中每隔固定时间间隔从队首移除一个旧的过滤器,同时补位到队尾一个新的过滤器,队列的规模一直保持固定的规模 (本例中为 3);
这个过滤器队列如何判别重复呢?
当接收到一个数据元素时,用过滤器队列中的 每个过滤器 来判断该数据是否出现过,只有当队列中的每个过滤器都判定为 "未出现过" 时,才认为是非重复数据,允许通过;只要队列中有任何一个过滤器判断为 "已出现过",则拦截该数据。
无论拦截或是放行该条数据,都在在当前队列中的 First 2 个过滤器中留存该数据记录的 "痕迹" (图中用相同位置的绿色 bit 标识数据的痕迹)。
还是以上图为例,介绍一下过滤器队列的工作过程:
*t* 0, *t* 1 时间段,队列中只有 1 个过滤器:过滤器-1 ,数据 01,01,03 依次到达后,经 过滤器-1 去重后的结果是 01,03,在 过滤器-1 中记录 *t* 0, *t*1 时间段流经所有数据记录的状态位;
*t* 1, *t* 2 时间段,队列中有 2 个过滤器:过滤器-1 、过滤器-2 ,当数据 03,03,04 依次到达后,03 被 过滤器-1 拦截,04 可以通过过滤器队列,因此去重后的结果是 04,同时在 过滤器-1 和 过滤器-2 中记录 *t* 1, *t*2 时间段流经所有数据记录的状态位;
*t* 2, *t* 3 时间段,队列中有 3 个过滤器:过滤器-1 、过滤器-2 、过滤器-3 。当数据 04,06,06 依次到达后,04 被 过滤器-1 、过滤器-2 拦截,06 可以通过过滤器队列,因此去重后的结果是 06,同时在 过滤器-1 和 过滤器-2 中记录 *t* 2, *t* 3 时间段流经所有数据记录的状态位,过滤器-2 就是过滤器-1 在 *t* 1, *t* 3 时间段的备份;因为 *t* 2, *t* 3 时刻 过滤器-1 的状态已经复制到了 过滤器-2 中,过滤器-3 在*t* 2, *t*3 时间段就不必留存数据记录了 (图中用灰色表示);
t 3 时刻,过滤器-4 补位到队尾,过滤器-1 从队首移除 (t 3 时刻之后,如果还有 t3 时刻之前出现过的数据再次出现,将会穿透过滤器队列,我们可以通过设置过滤器的存活时间和队列的大小来尽量避免这一情况的发生);
*t* 3, *t* 4 时间段,队列中有 3 个过滤器:过滤器-2 、过滤器-3 、过滤器-4 ,当数据 06,08,07 依次到达后,06 被 过滤器-2 拦截,08 和 07 可以通过过滤器队列,因此去重后的结果是 08,07,同时在 过滤器-2 和 过滤器-3 中记录 *t* 3, *t* 4 时间段流经所有数据记录的状态位 (过滤器-3 作为 过滤器-2 在 *t* 3, *t* 4 时间段的备份),因为 *t* 3, *t* 4 时刻 过滤器-2 的状态已经复制到了 过滤器-3 中,过滤器-4 在*t* 3, *t*4 时间段就不必留存数据记录了 (图中用灰色表示);
t 4 时刻,过滤器-5 补位到队尾,过滤器-2 从队首移除 (t 4 时刻之后,如果还有 t2 时刻之前出现过的数据再次出现,将会穿透过滤器队列,我们可以通过设置过滤器的存活时间和队列的大小来避免这一情况的发生);
*t* 4, *t* 5 时间段,队列中有 3 个过滤器:过滤器-3 、过滤器-4 、过滤器-5 ,当数据 08,08,09依次到达后,08 被 过滤器-3 拦截,09 可以通过过滤器队列,因此去重后的结果是 09,同时在 过滤器-3 和 过滤器-4 中记录 *t* 3, *t* 4 时刻流经所有数据记录的状态位 (过滤器-4 作为 过滤器-3 在 *t* 4, *t* 5 时间段的备份),因为 *t* 4, *t* 5 时间段 过滤器-3 的状态已经复制到了 过滤器-4 中,过滤器-5 在 *t* 4, *t*5 时刻就不必留存数据记录了 (图中用灰色表示);
t 5 时刻,过滤器-6 补位到队尾,过滤器-3 从队首移除 (t 5时刻之后,如果还有 t3 时刻之前出现过的数据再次出现,将会穿透过滤器队列,我们可以通过设置过滤器的存活时间和队列的大小来避免这一情况的发生);
*t* 5, *t* 6 时间段,队列中有 3 个过滤器:过滤器-4 、过滤器-5 、过滤器-6 ,当数据 09,09,10 依次到达后,09 被 过滤器-4 拦截,10 可以通过过滤器队列,因此去重后的结果是 10,同时在 过滤器-4 和 过滤器-5 中记录 *t* 5, *t* 6 时刻流经所有数据记录的状态位 (过滤器-5 作为 过滤器-4 在 *t* 5, *t* 6 时刻的备份),因为 *t* 5, *t* 6 时刻过滤器-4 的状态已经复制到了 过滤器-5 中,过滤器-6 在*t* 5, *t*6 时刻就不必留存数据记录了 (图中用灰色表示);
实现
如何把上述设计在 Flink 中实现呢,Bloom 过滤器队列是随着时间动态变化的,因此需要用到 Flink 的 定时器 。KeyedProcessFunction 算子的 TimerService 就提供了定时器注册功能,可以注册 EventTimeTimer 或 ProcessingTimeTimer。
BloomFilterProcessFunction.java:
java
package org.example.flink.operator;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.example.flink.data.Trace;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class BloomFilterProcessFunction extends KeyedProcessFunction<String, Trace, Trace> {
private static final long serialVersionUID = 1L;
// bloom预计插入的数据量
private static final long EXPECTED_INSERTIONS = 5000000L;
// bloom的假阳性率
private static final double FPP = 0.001;
// bloom过滤器TTL
private static final long TTL = 60 * 1000;
// bloom过滤器队列size
private static final int FILTER_QUEUE_SIZE = 10;
// bloom过滤器队列
private List<BloomFilter<String>> bloomFilterList;
// 是否已经注册定时器
private boolean registeredTimerTask = false;
@Override
public void open(Configuration parameters) throws Exception {
bloomFilterList = new ArrayList<>(FILTER_QUEUE_SIZE);
BloomFilter<String> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")),
EXPECTED_INSERTIONS, FPP);
bloomFilterList.add(bloomFilter);
}
@Override
public void processElement(Trace trace, KeyedProcessFunction<String, Trace, Trace>.Context context,
Collector<Trace> out) throws Exception {
BloomFilter<String> firstBloomFilter = bloomFilterList.get(0);
String key = trace.getGid();
// 只要有一个bloom未hit该元素,就意味着该元素从未出现过,在队列中的所有过滤器留下该元素的标记
if (!firstBloomFilter.mightContain(key)) {
for (BloomFilter<String> bloomFilter : bloomFilterList) {
bloomFilter.put(key);
}
// 该元素从未出现过,为非重复数据
out.collect(trace);
}
if (!registeredTimerTask) {
long current = context.timerService().currentProcessingTime();
// 注册处理时间定时器
context.timerService().registerProcessingTimeTimer(current + TTL);
registeredTimerTask = true;
}
}
@Override
public void onTimer(long timestamp, OnTimerContext context, Collector<Trace> out) throws Exception {
// append新的bloomFilter到bloom过滤器队列
bloomFilterList
.add(BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), EXPECTED_INSERTIONS, FPP));
// 清理第一个bloomFilter
if (bloomFilterList.size() > FILTER_QUEUE_SIZE) {
bloomFilterList.remove(0);
}
// 创建一个新的timer task
context.timerService().registerProcessingTimeTimer(timestamp + TTL);
}
@Override
public void close() throws Exception {
bloomFilterList = null;
}
}以下是主程序入口,实验场景还是设定为从 Kafka 消费数据,去重后写入到 MySQL:
StreamDeduplication.java:
java
package org.example.flink;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackend;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.example.flink.data.Trace;
import org.example.flink.operator.BloomFilterProcessFunction;
import com.google.gson.Gson;
public class StreamDeduplication {
public static void main(String[] args) throws Exception {
// 1. prepare
Configuration configuration = new Configuration();
configuration.setString("rest.port", "9091");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(configuration);
env.enableCheckpointing(2 * 60 * 1000);
env.setStateBackend(new EmbeddedRocksDBStateBackend()); // 使用rocksDB作为状态后端
// 2. Kafka Source
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("127.0.0.1:9092")
.setTopics("trace")
.setGroupId("group-01")
.setStartingOffsets(OffsetsInitializer.latest())
.setProperty("commit.offsets.on.checkpoint", "true")
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> sourceStream = env.fromSource(source, WatermarkStrategy.noWatermarks(),
"Kafka Source");
sourceStream.setParallelism(1); // 设置source算子的并行度为1
// 3. 转换为Trace对象
SingleOutputStreamOperator<Trace> mapStream = sourceStream.map(new MapFunction<String, Trace>() {
private static final long serialVersionUID = 1L;
@Override
public Trace map(String value) throws Exception {
Gson gson = new Gson();
Trace trace = gson.fromJson(value, Trace.class);
return trace;
}
});
mapStream.name("Map to Trace");
mapStream.setParallelism(1); // 设置map算子的并行度为1
// 4. Bloom过滤器去重, 在去重之前要keyBy处理,保障同一gid的数据全都交由同一个线程处理
SingleOutputStreamOperator<Trace> deduplicatedStream = mapStream.keyBy(
new KeySelector<Trace, String>() {
private static final long serialVersionUID = 1L;
@Override
public String getKey(Trace trace) throws Exception {
return trace.getGid();
}
})
.process(new BloomFilterProcessFunction());
deduplicatedStream.name("Bloom filter process for distinct gid");
deduplicatedStream.setParallelism(2); // 设置去重算子的并行度为2
// 5. 将去重结果写入DataBase
DataStreamSink<Trace> sinkStream = deduplicatedStream.addSink(
JdbcSink.sink("insert into flink.deduplication(gid, timestamp) values (?, ?);",
(statement, trace) -> {
statement.setString(1, trace.getGid());
statement.setLong(2, trace.getTimestamp());
},
JdbcExecutionOptions.builder()
.withBatchSize(1000)
.withBatchIntervalMs(200)
.withMaxRetries(5)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder()
.withUrl("jdbc:mysql://127.0.0.1:3306/flink")
.withUsername("username")
.withPassword("password")
.build())
);
sinkStream.name("Sink DB");
sinkStream.setParallelism(1);
// 执行
env.execute("Stream Real-Time Deduplication");
}
}测试
以下是向 Kafka 生产重复数据的测试程序,程序中模拟了数据乱序到达的情况。
java
public static void main(String[] args) throws InterruptedException {
Properties props = new Properties();
String topic = "trace";
props.put("bootstrap.servers", "127.0.0.1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
InputStream inputStream = KafkaDataProducer.class.getClassLoader().getResourceAsStream(TEST_DATA);
Scanner scanner = new Scanner(inputStream, StandardCharsets.UTF_8.name());
String content = scanner.useDelimiter("\\A").next();
scanner.close();
JSONObject jsonContent = JSONObject.parseObject(content);
int nonDuplicateNum = 100000;
int repeatNum = 100;
Random r = new Random();
for (int i = 0; i < nonDuplicateNum; i++) {
String id = jsonContent.getString(GID);
String newId = increase(id, String.valueOf(i));
jsonContent.put(GID, newId);
// 制造重复数据
for (int j = 0; j < repeatNum; j++) {
// 对时间进行随机扰动,模拟数据乱序到达
long current = System.currentTimeMillis() - r.nextInt(60) * 1000;
jsonContent.put(TIMESTAMP, current);
producer.send(new ProducerRecord<String, String>(topic, jsonContent.toString()));
}
// wait some time
Thread.sleep(5);
}
Thread.sleep(2000);
System.out.println("\n");
System.out.println("finished");
producer.close();
}共生产了 10, 000, 000 条 ID,其中非重复的 ID 共计 100, 000 个。我们看一下 Flink 是否能做到实时去重,将 100, 000 个非重复 ID 的结果正确写入到数据库。实验过程耗时较长,简单看一下动态效果图:
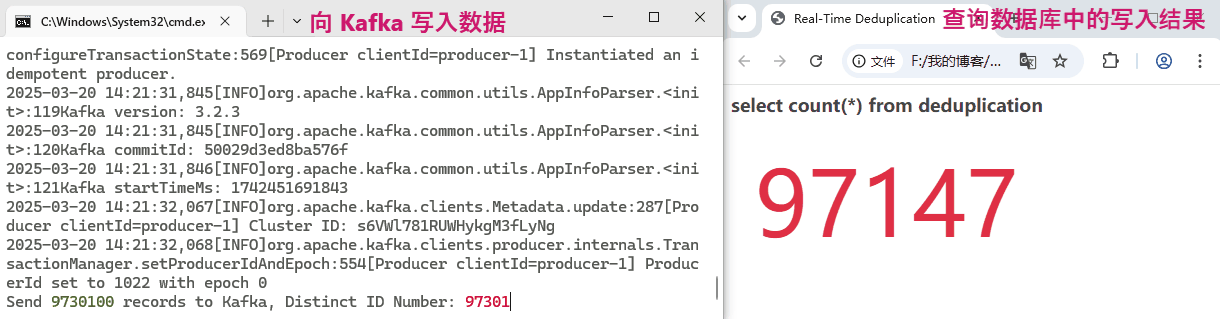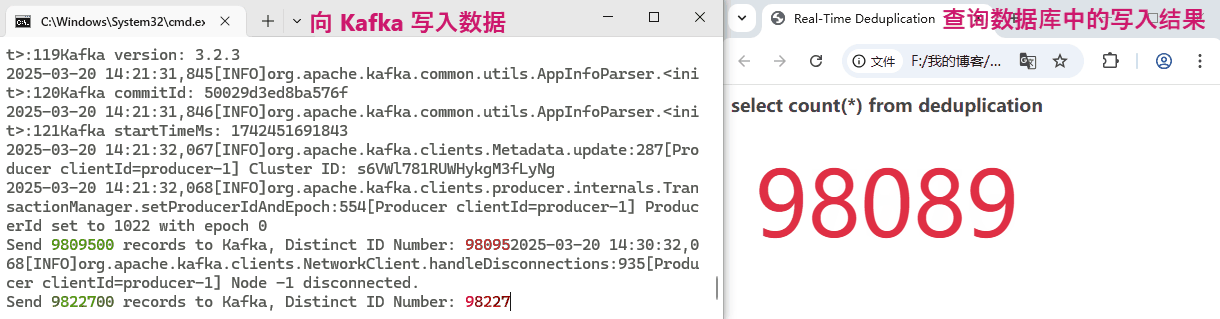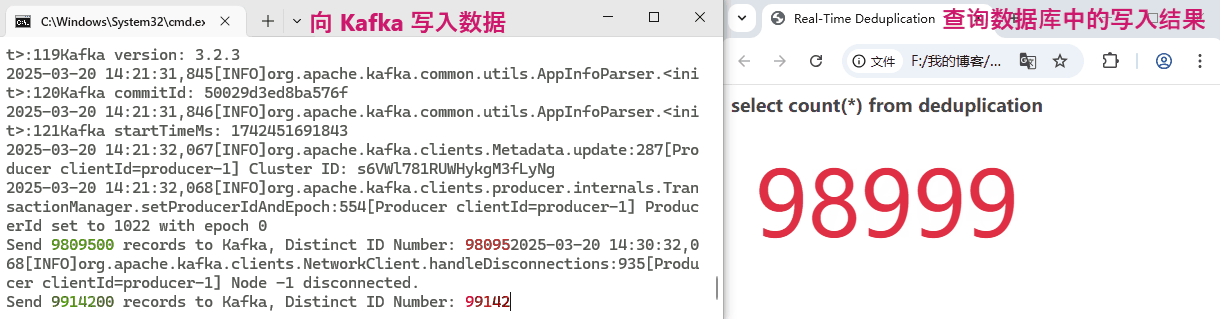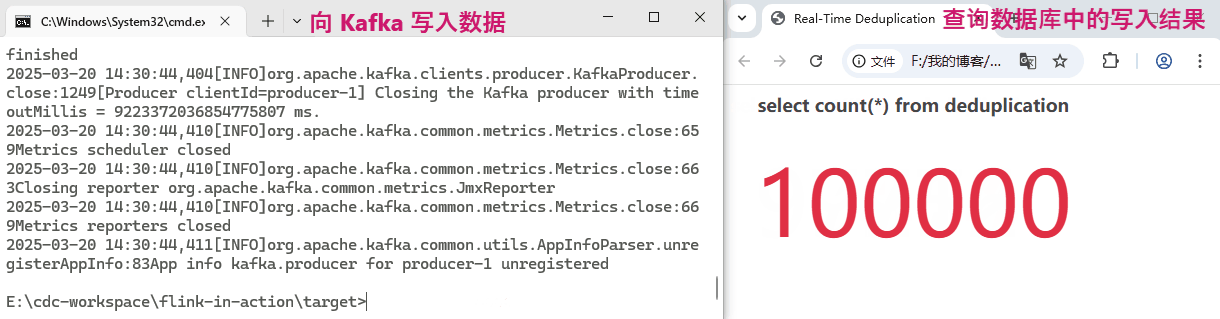
可以看到,Flink 的处理速度非常快,去重结果的数值和 Kafka 中实际的 distinct id 值跟的非常紧,几乎是毫秒延迟!