问题描述
在处理一个数据收集工作任务上,收集到的数据内容格式都不能直接对应到数据库中的表格内容。
比如:
**第一种情况:**服务名作为第一列内容,然后之后每一列为一个人名,1:代表此人拥有这个服务,0:代表不拥有。

**第二种情况:**服务名称为第一列,第二列紧跟人名,并均有重复的情况。

** 以上两种情况,都需要转换为 Name所对应的Services数据(多个Services用逗号连接在一起)。
由于数据量大,如果人工处理,工作量非常巨大,机械性,重复且易出错。于是,借助Python Pandas,短短几句代码就可以实现!
问题解答
1: 通过引入 pandas 组件,读取CSV文件
import pandas as pd
df = pd.read_csv('service.csv')
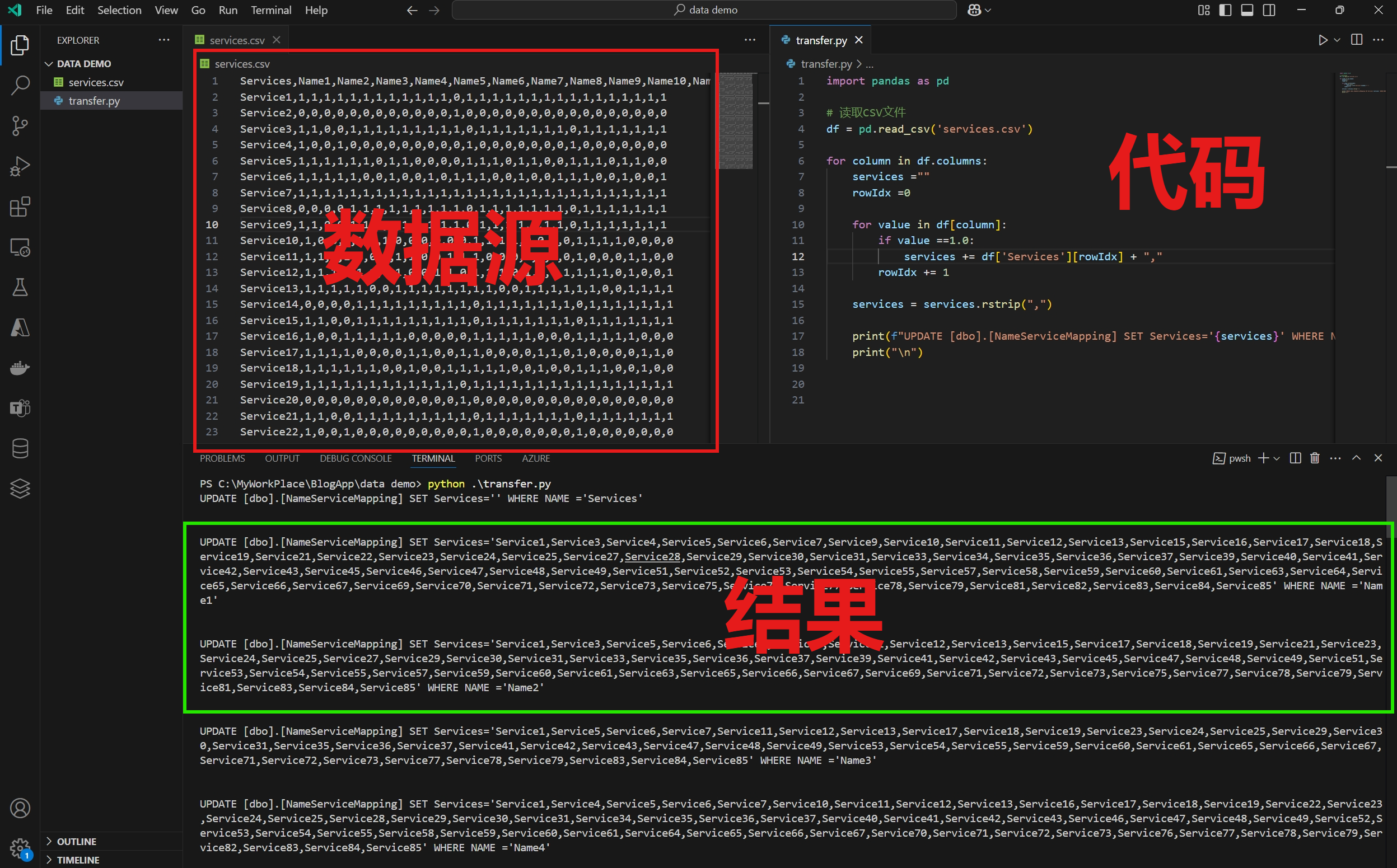
2:第一种情况:使用双层 for 循环
- 第一层循环文件中的全部列,并且增加一个"行索引" rowIdx ,用于标记并获取当前行所代表的Service名称
- 第二层循环列中的每一个单元格,判断值是否等于1,相等则取出Service名并进行追加
- 第二层循环完成后,对 services 字符串的最后一个逗号进行清除
- 根据固定格式,正常UPDATE SQL语句
for column in df.columns:
services =""
rowIdx =0
for value in df[column]:
if value ==1.0:
services += df['Services'][rowIdx] + ","
rowIdx += 1
services = services.rstrip(",")
print(f"UPDATE [dbo].[NameServiceMapping] SET Services='{services}' WHERE NAME ='{column}'")
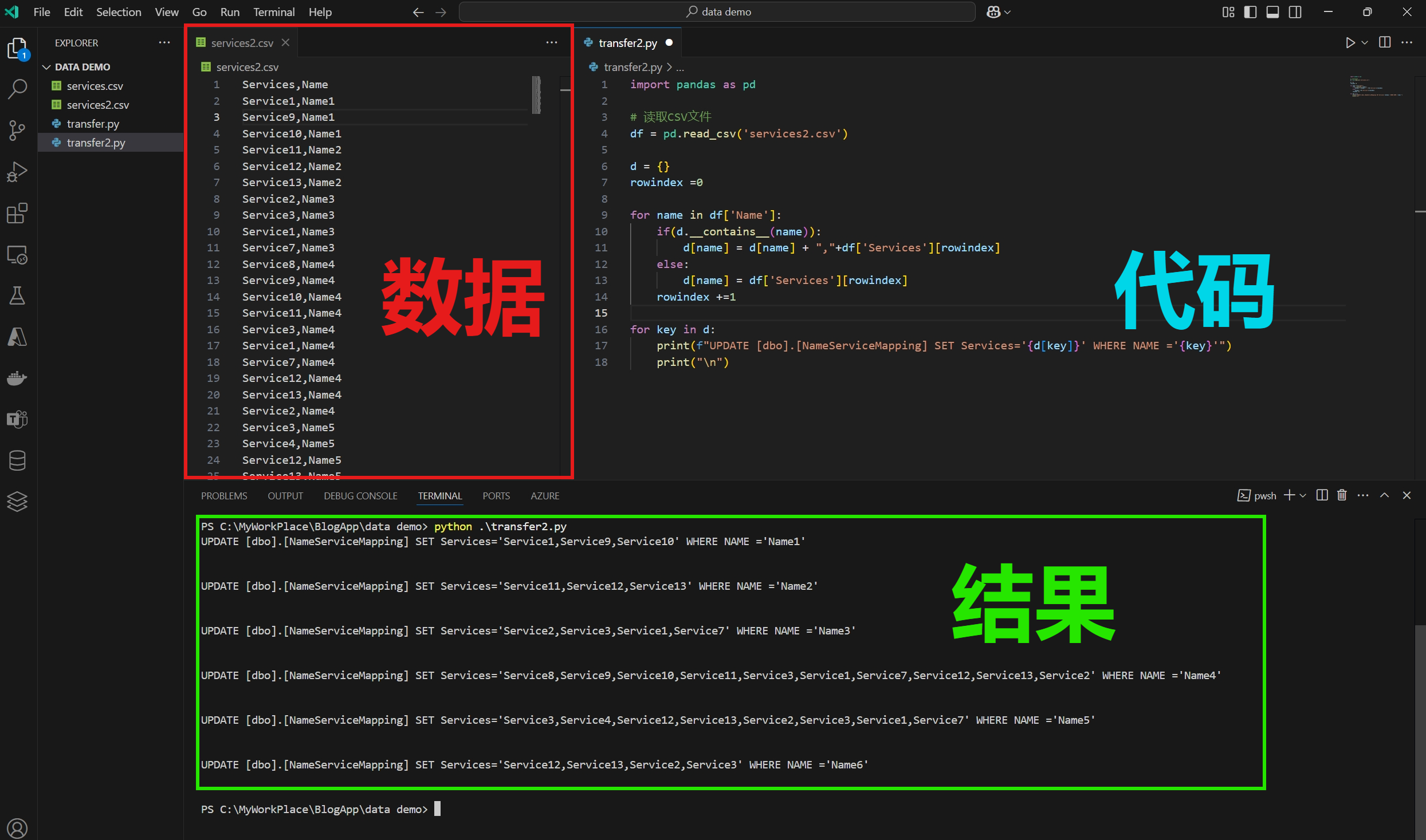
print("\n")3:第二种情况:使用一个 For 加 字典数据结构 {}
- 读取第二列 Name, 作为字典 d 的Key
- 判断字典 d 中是否已经存在这个Name的Key, 使用 contains 进行判断
- 如存在,则追加第一列中的Service。
- 反之,则为字典新加一个Key。
- 最后循环字典 d, 并生成 UPDATE SQL语句
d = {}
rowindex =0
for name in df['Name']:
if(d.__contains__(name)):
d[name] = d[name] + ","+df['Services'][rowindex]
else:
d[name] = df['Services'][rowindex]
rowindex +=1
for key in d:
print(f"UPDATE [dbo].[NameServiceMapping] SET Services='{d[key]}' WHERE NAME ='{key}'")
print("\n")3:执行结果
第一种结果:
第二种结果:
参考资料
Python 字典(Dictionary):https://www.runoob.com/python/python-dictionary.html