探秘Transformer系列之(19)----FlashAttention V2 及升级版本
目录
- [探秘Transformer系列之(19)----FlashAttention V2 及升级版本](#探秘Transformer系列之(19)----FlashAttention V2 及升级版本)
- [0x00 概述](#0x00 概述)
- [0x01 FlashAttention V2](#0x01 FlashAttention V2)
- [1.1 动机](#1.1 动机)
- [1.2 方案](#1.2 方案)
- [1.3 算法](#1.3 算法)
- [1.4 Causal Mask处理](#1.4 Causal Mask处理)
- [1.5 MQA/GQA](#1.5 MQA/GQA)
- [1.6 总结](#1.6 总结)
- [1.7 问题](#1.7 问题)
- [1.8 实现](#1.8 实现)
- [0x02 Flash-Decoding](#0x02 Flash-Decoding)
- [2.1 现状](#2.1 现状)
- [2.2 方案](#2.2 方案)
- [2.3 讨论](#2.3 讨论)
- [0x03 Flash-Mask](#0x03 Flash-Mask)
- [3.1 动机](#3.1 动机)
- [3.2 思路](#3.2 思路)
- [3.3 算法](#3.3 算法)
- [0x04 FlashAttention-3](#0x04 FlashAttention-3)
- [0xFF 参考](#0xFF 参考)
0x00 概述
FlashAttention利用了GPU内存的非对称层次结构,将内存消耗降至线性(而非二次方),并相较于优化基线实现了2到4倍的运行速度提升。然而,该技术的速度依然没有达到优化矩阵乘法(GEMM)操作的速度,前向传播的计算吞吐量仅达到理论最大浮点运算速率(FLOPs/s)的30-50%,而反向传播只能达到25-35%。这种低效率是由于GPU上不同线程块之间的负载分配不佳,导致低占用率或不必要的共享内存读/写。
因此,原作者对FlashAttention进行了升级,得到了V2版本。而其它研究人员也在V1和V2之上发挥自己的聪明才智,进行了优化和发展。
0x01 FlashAttention V2
1.1 动机
作者发现在GPU的不同线程块和warp的不合理的work分区是导致计算低效的一个主要原因。为了解决这个问题,FlashAttention 2设计了更好的worker分区方案。充分的利用并行化和高效的work分解提高计算利用率。
1.2 方案
FlashAttention 2 的优化点主要包括以下,其中第二和第三点都可以归结为在cuda gemm层面的优化。
- 减少冗余计算。减少非矩阵乘法运算(non-matmul)的FLOPs,增加Tensor Cores的运算比例。
- 序列长度维度的并行。在不同线程块之间把并行化做到单个头级别,在序列长度的维度上对前向传播和反向传播做并行化。该方法在输入序列很长(此时batch size通常很小)的情况下增加了GPU利用率。即使对于单个head,也在不同的thread block之间进行并行计算。
- 调整Warp Partitioning(分区)策略,分散负载,减少通信。在一个attention计算块内,将工作分配在一个单个线程块的不同warp上,来减少数据交换和共享内存读写。
减少冗余计算
为什么要减少非矩阵乘法运算(non-matmul)计算?这是因为矩阵乘法可以在现代硬件上被高效实现。
在深度学习中通常会使用矩阵乘法运算来进行前向传播和反向传播。为了迎合加速需求,硬件厂商定制了矩阵乘法(GEMM)的专用计算单元;而有了专用计算单元后,软件算法的设计实现又在朝这个方向靠拢,两者互相影响。然而,并不是所有的运算都可以被表示成矩阵乘法的形式,如加法、乘法、除法等就是在矩阵乘法之外的操作。虽然这些非矩阵乘法运算的FLOPs要比矩阵乘法低,但是由于其没有针对性加速,所以其计算吞吐要远低于矩阵乘法运算。因此需要想办法在GPU上避免非矩阵运算。减少了非矩阵乘法的FLOPs。
减少冗余计算和交换循环顺序是通过调整算法结构来完成的,主要是消除了原先频繁的rescale操作。
增加并行
FlashAttention V1在batch size和head维度施加了并行化,即每个head被分配了一个线程块,一共batch_size * head_num 个线程块进行并行。但是由于内存限制,在处理长序列输入时,人们通常会减小batch size和head数量,这样就降低了并行化程度。
因此,FlashAttention V2还在序列长度这一维度上进行并行化,即将V1中Q的循环也修改为使用多个线程块来并行操作,这样总的线程块有所增加,就提高了 GPU 的利用率。具体来说,V2 通过增加 num_m_block 的概念,将 Q 矩阵在序列长度方向上进一步划分为多个小块,每一块由不同的 block 来处理。而且,每个 block 可以独立地计算它所负责的输出部分,减少了不同 block 之间的依赖和通信开销。
序列并行的目的就是如何更好地划分线程块。
调整Warp Partitioning策略
FlashAttention V1使用是split-K策略,在该策略中,所有warp将中间结果写入共享内存进行同步,然后将中间结果相加,这些共享内存读取会拖慢前向传播的计算。
FlashAttention V2使用更好的Warp Partitioning(分区)策略,在每个线程块内部来分散warps之间的工作负载,进而减少通过共享内存的通信。
从本质上来说,调整warps工作负载策略是在线程块内部进行优化。
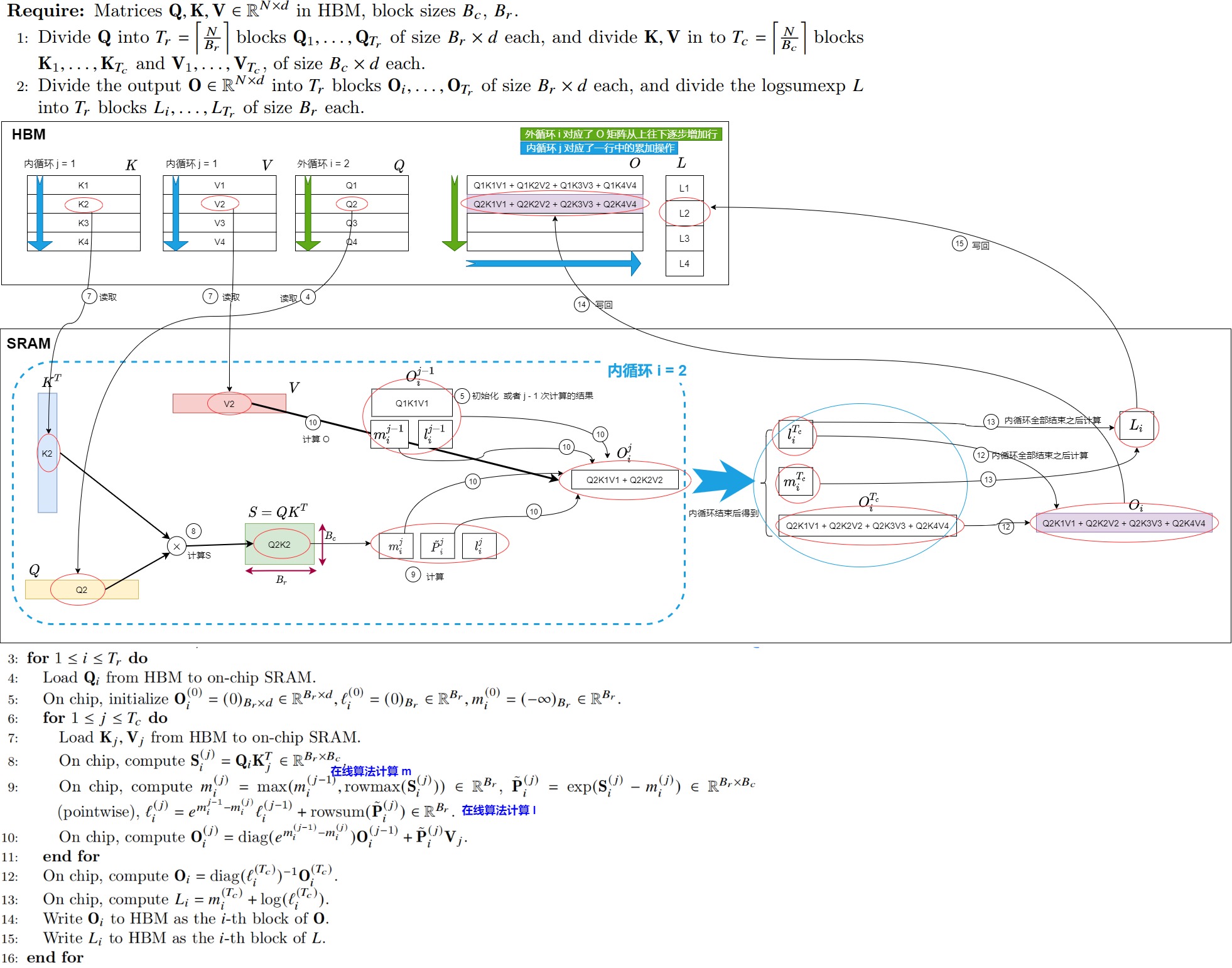
1.3 算法
FlashAttention V2 算法主要优化点是调换了外层和内层循环的顺序。把Q循环挪到了最外层,把KV移到了内循环。

具体如下。
- 和V1相比,V2的第3行和第6行调换了外层和内层循环的顺序。把Q循环挪到了最外层,把KV移到了内循环。
- 第8行会计算分块 \(S_i^{(i)}\)。
- 第9行会更新三个中间变量。
- \(m_i^{(j)}\) 表示截止到当前分块 \(S_i^{(j)}\)(包含当前分块)为止的rowmax;
- \(\tilde P_i^{(j)}\)表示使用当前每行最大值计算归一化前的 \(P_i^{(i)}\) ;
- \(l_i^{(j)}\) 表示截止到当前分块 \(S_i^{(j)}\) (包含当前分块为止)的rowsum;
- 第10行会计算O。\(O_i^{(i)}\) 表示截止到当前分块\(S_i^{(i)}\)(包含当前分块)止计算出的O值。由第9和第10行知,当我们固定Q循环KV时,我们每个分块都是用当前最新的rowmax和rowsum计算的,同理对应的 \(O_i^{(i)}\)也是用当前最新的rowmax和rowsum计算的。这样当我们遍历完所有的KV时,得到的 \(O_i^{(i)}\) 就等于最终全局的结果。
- 第12行的\(diag(l_i^{(j)})^{−1}\)会对O进行统一的归一化操作。在内循环中没有做归一化,而是统一放到外循环来做,这样可以减少非矩阵运算。
- 第13行会计算中间变量 \(L_i=m_i^{(T_c)} + log(l_i^{(T_c)})\)。并且在第15行回写到HBM中。因为从HBM上读取\(l_i\),\(m_i\) 会消耗读写,所以我们不希望再存每一Q分块对应的 \(m_i\)和 \(l_i\)。但是在反向传播中,我们依然需要 \(l_i\),\(m_i\) 来做 \(S_i^{(i)}\) 和\(P_i^{(i)}\) 的重计算(用链式求导法则来计算dQ,dK,dV,需要如此操作)。所以在V2中,我们只存储 \(L_i=m_i^{(T_c)} + log(l_i^{(T_c)})\) ,然后通过\(L_i\)来计算\(P_i^{(i)}=exp(S_{ij}-L_i)\)。这样可以节省HBM读写操作。L是log-sum-exp的缩写。
减少冗余计算
FlashAttention V2 算法通过减少中间缩放的次数减少了冗余计算。
原始Softmax
原始softmax为了数值稳定性(因为指数增长太快,数值会过大甚至溢出),会减去最大值,这样带来的代价就是要对token遍历3次。
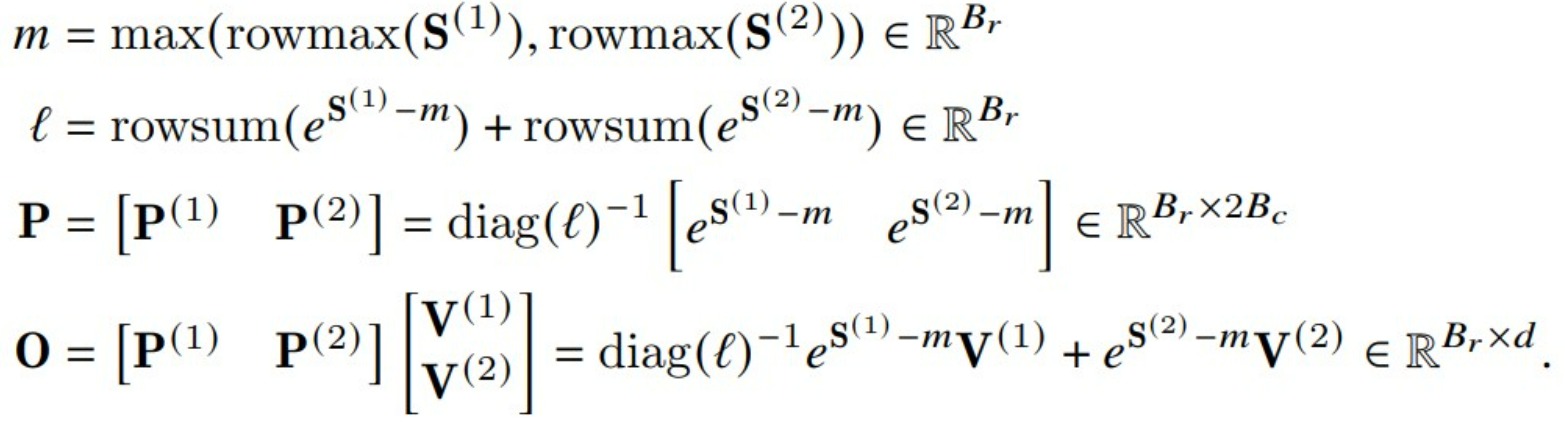
FlashAttention V1
FlashAttention V1计算O的操作如下所示。
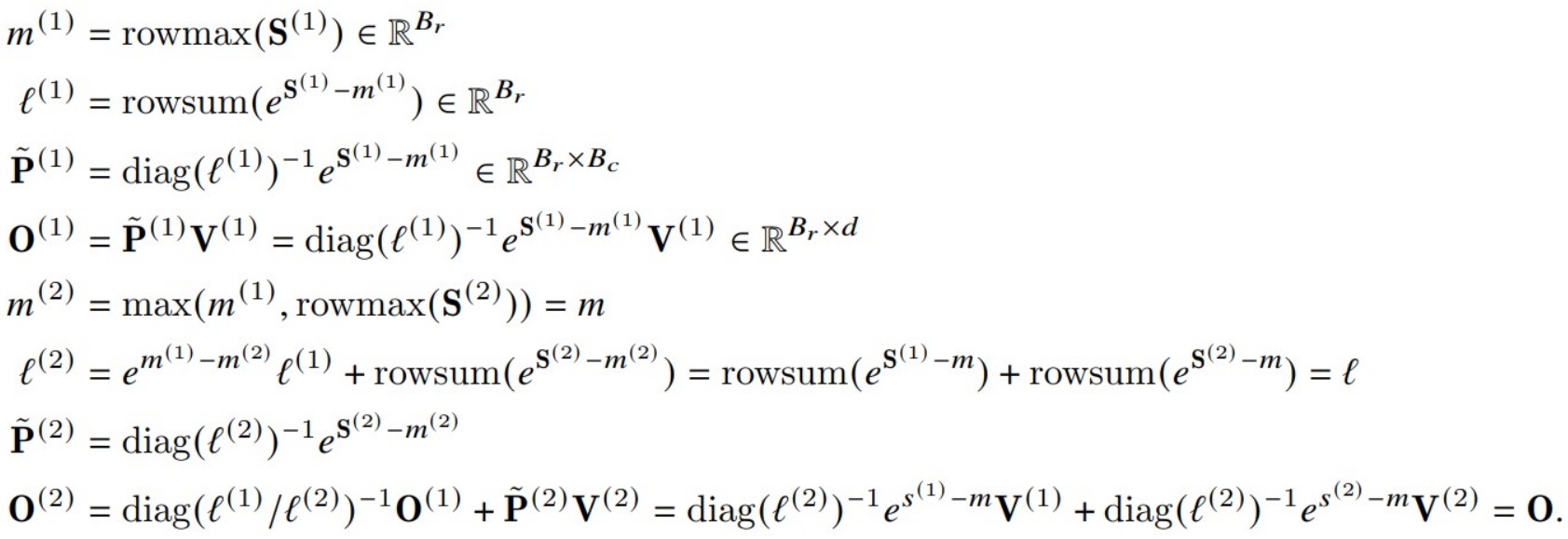
下图展示了FlashAttention如何使用online softmax进行分块计算。
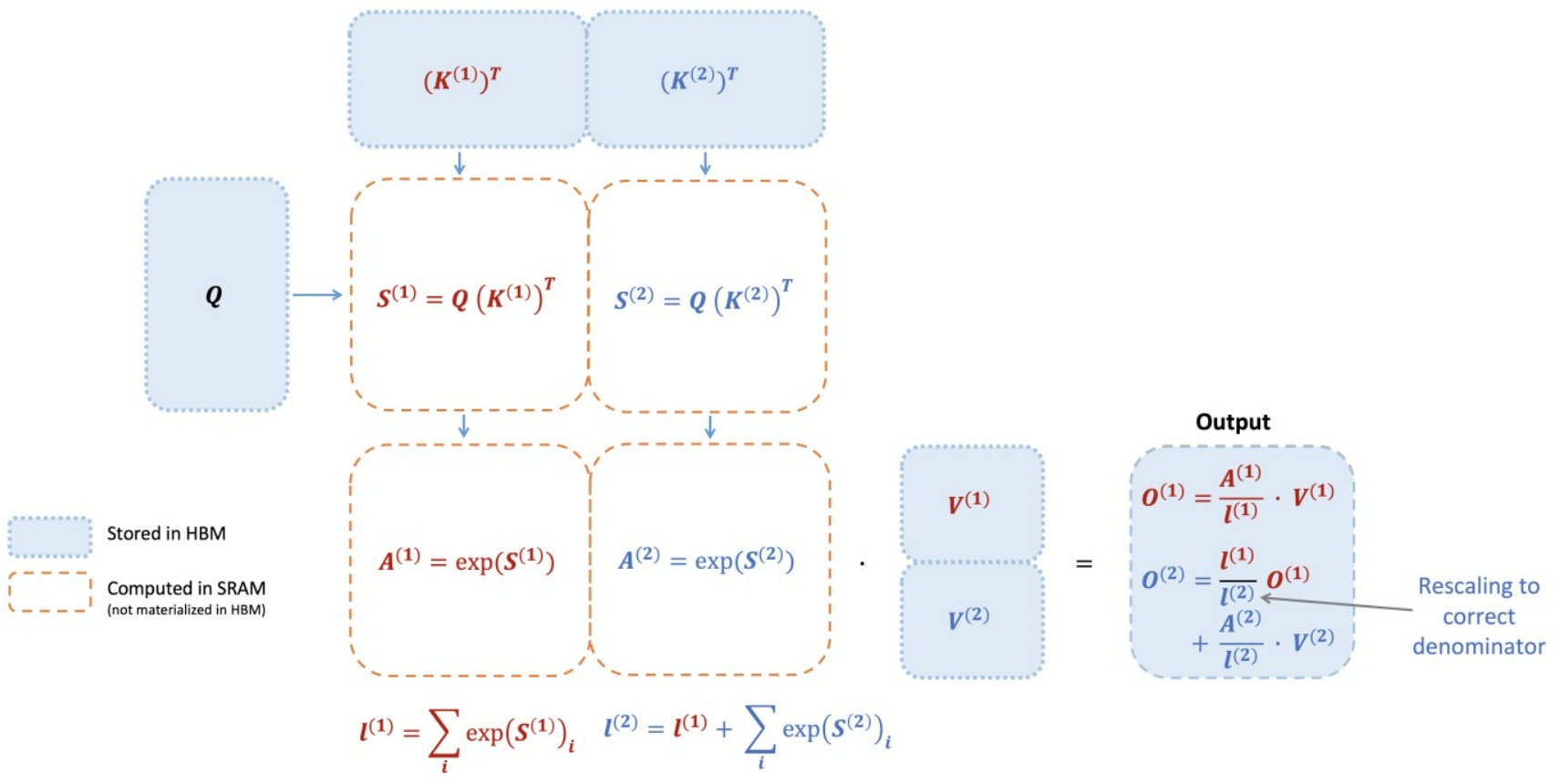
FlashAttention V2
FlashAttention V2则修改为如下。
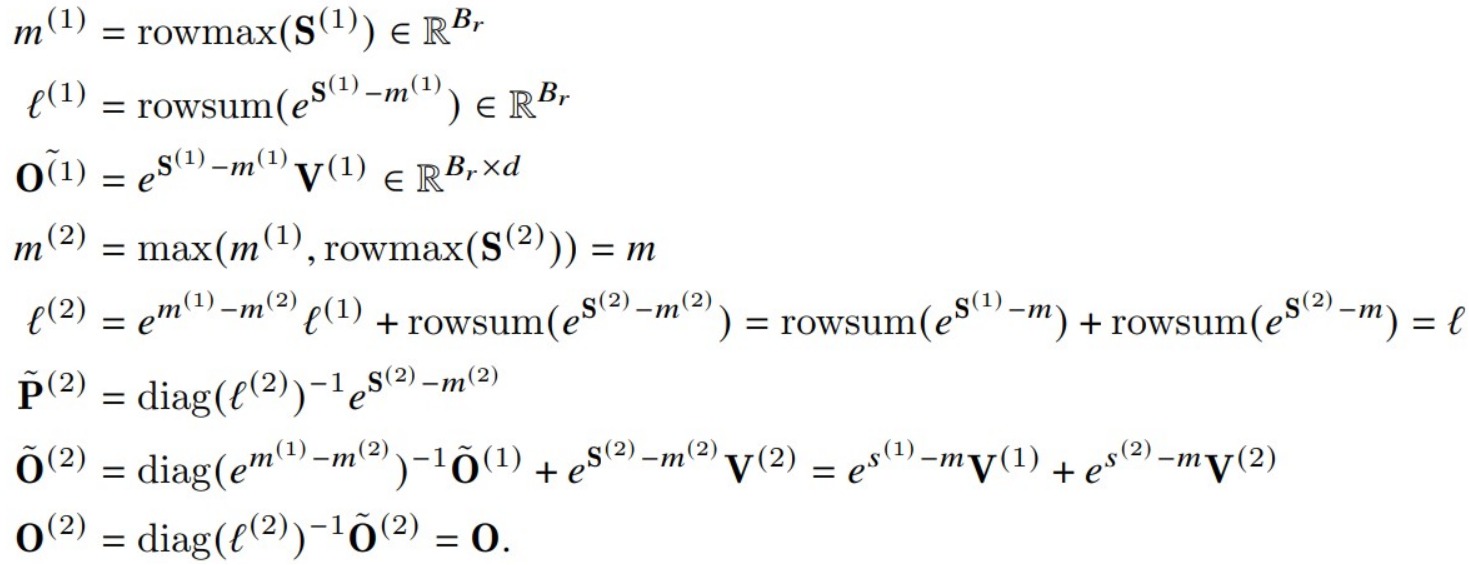
我们把V1和V2放在一起比较可以更好的看出区别。
- V1算法会在内循环中迭代地对前序值用rescale进行修正,即每个block的每次迭代都需要执行rescale操作,这涉及到除法运算。
- V2算法则把rescale操作从内循环转移到外循环中,这种rescale操作被延后到循环的最后才执行一次,每次计算可以减少一次除法运算。即:
- 在内循环中,计算\(O^{(1)}\)时删除了\(diag(l^{(1)})^{-1}\)操作,只是对\(O^{(1)}\)的分子进行修正;在计算\(O^{(2)}\)时删除了\(diag(l^{(2)})^{-1}\)操作。
- 在内循环结束后,在外循环中统一执行一次rescale修正,得到最终值。这样每次内循环计算可以减少一次除法(非矩阵乘法运算)运算。V2只要在每次迭代中确保分子部分\(O^{(1)}\)和\(O^{(2)}\)被scale为正确值、以及可以计算出最终的分母部分 \(ℓ^{(2)}\),就可以得到和V1同样的效果。

交换循环顺序
GPU特点
在详细介绍FlashAttention v2的并行策略之前,需要简单回顾一下GPU的基本工作原理。
从硬件层面上看,GPU适合并行任务的原因是因为GPU通常含有大量计算单元。虽然GPU的单个计算单元通常不如CPU强大,但大量的计算单元可以同时完成并行任务。SM(Streaming multiprocessors)就是GPU中真正的物理计算单元,在A100中一共有108个SM。为了提高计算吞吐量,需要尽可能保证在每个时刻有较多的SM同时在参与计算。
从软件层面上看,GPU依靠线程完成计算工作。GPU有大量线程,这些线程按照线程块的形式进行管理。比如每个线程块包括128个线程,这些线程块被调度到SM上进行计算。
为了更好的协作,在每个线程块又划分成多个warp。warps 是NVIDIA GPU并行计算的基本单元(线程实际调度的最小单位)。一个Warp通常包含32个线程,它们同时执行相同的指令,但对不同的数据进行操作。在GPU执行指令时,通常以Warps为单位进行调度,这可以充分利用GPU的并行处理能力。同一个warp中的所有线程可以协作完成矩阵乘法。但是如果共享变量不在一个线程块内,则意味着要往共享内存上写更多的中间结果。
FlashAttention V1
我们首先从并行化角度看看V1版本的一些特点。
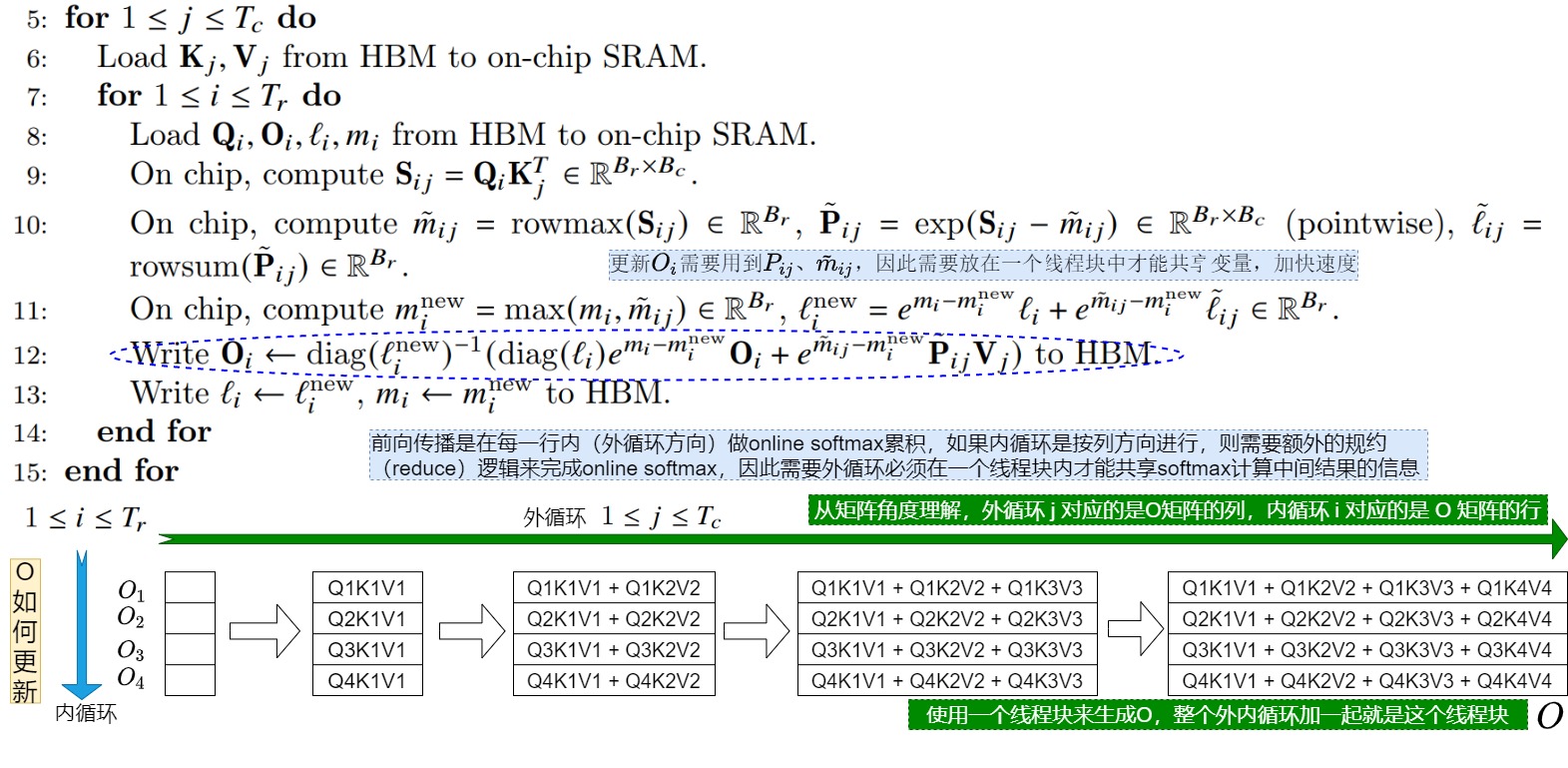
首先,前置条件是:如果我们把O看作一个矩阵,那么从矩阵角度理解,V1版本的外循环 j 对应的是O矩阵的列,内循环 i 对应的是 O 矩阵的行。
其次,目前内外循环的配置会导致需要把整个外循环操作放在一个线程块内,这是因为:
- 前向传播时,我们需要在每一行内按列(外循环方向)来做online softmax累积,更新\(O_i\)需要用到 P_{ij}\\(、\\)\\tilde m_{ij}\\(,而\\) P_{ij}\\(、\\)\\tilde m_{ij}是在内循环中计算出来。
- 内循环按行方向进行迭代,和online softmax的在每一行上按列方向操作有冲突,需要额外的规约(reduce)逻辑来完成online softmax。
理想状态下,V1应该把整个外循环操作放在一个线程块内才能共享softmax计算中间结果的信息,加快速度。如果整个外循环操作不在同一个线程块内,这些中间结果信息就要放在共享内存中,或者需要额外的通信操作。比如cross thread block reduce。
第三,目前内外循环的配置会导致内外循环有依赖。这是因为更新\(O_i\)需要用到\(V_j\),而V1的两重循环中会先在外层循环加载K, V,然后内层循环再加载Q。这就会导致内层循环每次计算的只是\(O_i\)的一部分,且每次内循环的迭代都需要对\(O_i\)进行全局内存的读写。
综上所述,V1只能在batch_size和headnum维度以线程块为粒度做并行,当序列比较长,batch size比较小时,V1的效率就大幅下降。具体也可以参见下图,在FlashAttention v1中使用一个线程块(thread block)来生成下图中的结果O,或者可以理解为,整个内外循环加起来是一个线程块。
FlashAttention V2
由V1的分析可知,不应该让内循环放在softmax规约的维度。另外,在Attention的计算中,不同query的Attention计算是完全独立的。输出结果O1仅和Q1相关,与Q2、Q3、Q4均无逻辑依赖关系,应该可以并行。
因此,FA2对于前向传播调整了循环的顺序,先load Q,再load K, V。
我们来分析下调整顺序带来的影响。
- 外循环可以增加并行度。交换了Q loop顺序到最外层之后,\(Q*K^T\)在"行"方向的seqlen上天然可以并行,外循环的每个迭代计算之间没有任何依赖。可以把这一维度的并行度从串行迭代改成并行的线程块,即把不同query块的注意力计算发送给不同的线程块来并行执行,这些线程块之间不需要通信。
- 内循环可以减少操作。
- 对比FA1,内循环不需要每次存取 O_i,ℓ_i,m_i到HBM,从而减少了IO操作,耗时也随之减少。
- online softmax是在每一行上按列进行累积,和内循环的迭代方向一致,所以不需要额外的规约逻辑。
因此,V2可以对batch_size,num_heads,seq_len三层循环以thread block为粒度并行切分,对于seq_len,可以理解为外循环被切成了\(T_r\)个并行块。这些thread block之间是不需要通信的,从而显著增加GPU的吞吐。
如下图所示,在FlashAttention v1中使用一个thread block来生成下图中的结果O;但是在FlashAttention v2中一个thread block仅负责生成图示中结果O的一个子集,也就是图下方中的每一行(O1, O2...)。在单个线程块中会迭代地对(Q1,K1,V1),(Q1,K2,V2),(Q1,K3,V3),(Q1, K4, V4)数据进行tiling化的attention运算,将结果累积至O1中,迭代中的O1值是中间结果值,而最后一轮迭代后O1即为真实结果值。这也符合attention是加权平均和的语义解释,可以理解为,O1是Q1的更深语义空间的加权平均和表示。
这样多个thread block可以并行地生成O2,O3,O4部分从而增大算法整体并行度,提高了GPU利用率。

反向传播遵循同样的原理,没有把inner loop放在softmax规约的维度,因此反向传播的循环依然和V1相同,外层循环先load K,V, 内层循环再load Q,但是在seq length("列"方向)上增加了一维并行度。具体分析如下。
在BWD的过程中主要是求 \(dV_j\) \(dK_j\), \(dQ_i\) (为了求它们还需要求中间结果 \(dS_{ij}\), \(dP_{ij}\) ),我们来总结一下这些梯度都需要沿着哪些方向AllReduce:
- \(dV_j\) :沿着i方向做AllReduce,也就是需要每行的结果加总。
- \(dK_j\) :沿着i方向做AllReduce,也就是需要每行的结果加总。
- \(dQ_i\) : 沿着j方向做AllReduce,也就是需要每列的结果加总。
- \(dS_{ij}\), \(dP_{ij}\) :只与当前i,j相关。
如果还是保持Q内循环,KV外循环,相当于固定行,遍历列,那么在这些梯度中,只有 \(dQ_i\) 从中受益了。但是KV梯度要往HBM上写中间结果,总体占用显存和显存操作都大。因为KV的数据量比Q大,所以只能做权衡,牺牲Q,让KV进入内循环(S和P的计算不受循环变动影响)。
反向传播具体算法如下。

序列并行
在写CUDA代码时,我们需要确定总共需要分配多少个block。对于FlashAttention来说,会在每个block中做注意力计算。因为计算注意力时,batch、head之间是数据独立的,因此如何划分块要看Q、K、V之间的数据依赖关系是否可以支持并行。
- 因为存在数据依赖关系,所以V1对batch_size,num_heads两个维度来划分线程块。一共有
batch_size * num_heads个block,每个block负责计算O矩阵的一部分。具体设置grid代码举例如下:dim3 grid(params.b, params.h)。 - 因为Qi需要和全量的K和V计算,所以V2对batch_size,num_heads,seq_len三个维度来划分线程块。一共有
batch_size * num_heads * num_m_block个block,每个block负责计算矩阵O的一部分。num_m_block是沿着Q矩阵行方向做的切分,每份维护了若干个token。具体设置grid代码举例如下。
c++
if (params.num_splits == 1) {
dim3 grid(params.b, params.h, params.num_splits);
kernel<<<grid, Kernel_traits::THREADS, smem_size_dq_dk_dv, stream>>>(params);
} else {
dim3 grid_dot(params.b, params.h, (params.seqlen_q + 128 - 1) / 128);
fmha_bwd_dot_do_o_kernel<Kernel_traits><<<grid_dot, Kernel_traits::THREADS, 0, stream>>>(params);
int num_splits = params.seqlen_k / blocksize_c; // seqlen_k is divisible by blocksize_c
dim3 grid(params.b, params.h, num_splits);
kernel_seqparallel<<<grid, Kernel_traits::THREADS, smem_size_dq_dk_dv, stream>>>(params);
}增加序列并行的目的是为了更好的利用SM,让SM打满。当batch_size和num_heads都比较大时,block也比较多,此时SM利用率比较高。但是如果我们的数据seq_len比较长,此时往往对应着较小的batch_size和num_heads,此时就会有闲置的SM。而为了解决这个问题,V2就引入在Q的seq_len上的划分。
FlashAttention V1
FlashAttention V1在batch和heads两个维度上进行了并行化。
- 对于单个序列来说,FlashAttention v1的并行计算主要在注意力头之间。在一次前向计算过程中,同一自注意力计算中的注意力头可以并行计算。
- 同一batch中的数据也是并行处理的。
所以FlashAttention v1的并行实际在两个维度同时进行:batch和注意力头。需要thread block的数量等于batch size × number of heads。每个block被调到到一个SM上运行,A100一共有108个streaming multiprocessors。当块数量很大,就会有更多的SM在并行计算,整体的吞吐量自然也就会比较高,可以充分利用GPU资源。
但是在处理长序列输入时,由于内存限制,通常会减小batch size和注意力头的数量,这样并行化程度就降低了。因为如果batch size和注意力头的数量设置太大,就会OOM。因此,对于长上下文的场景来说由于能组的batch比较小或者注意力头比较少。单卡上的batch size通常变得非常小,因此实际可以并行的attention head数量可能远远少于SM数量,导致系统整体吞吐量较低。
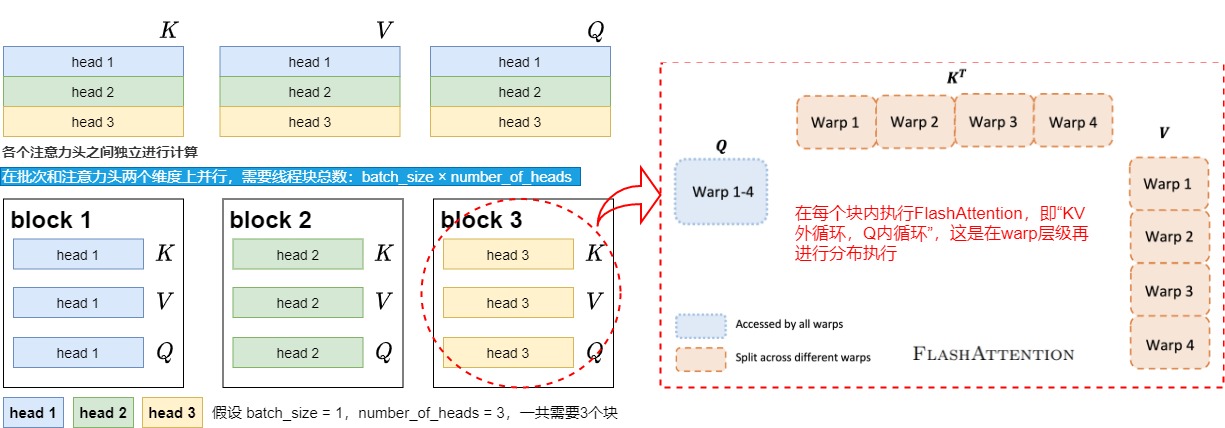
V1的线程块分布如下图所示。
假设batch_size = 1,num_heads = 3,我们用不同的颜色来表示不同的注意力头。我们知道在Multihead Attention中,各个注意力头是可以独立进行计算的,在计算完毕后将结果拼接起来即可。所以我们将1个注意力头划分给1个block,这样就能实现block间的并行计算。而每个block内就能执行V1中的"KV外循环,Q内循环"的过程了。这个过程是由block的再下级warp level层面进行组织,由thread实行计算的。最终,每个block只要在计算完毕后把结果写入自己所维护的O的对应位置即可。
FlashAttention V2
FlashAttention v1的并行策略导致输入序列较长时,会因batch size较小而导致整体可并行的线程块数远少于SM数量。因此需要思考除了在batch和attention head维度之外,还能在哪些维度进行并行。所以FlashAttention v2实际上在FlashAttention v1的并行策略基础上,增加了在序列长度这一维度上的并行操作。这其实也是内外循环置换这个总体思想的配套改进措施。
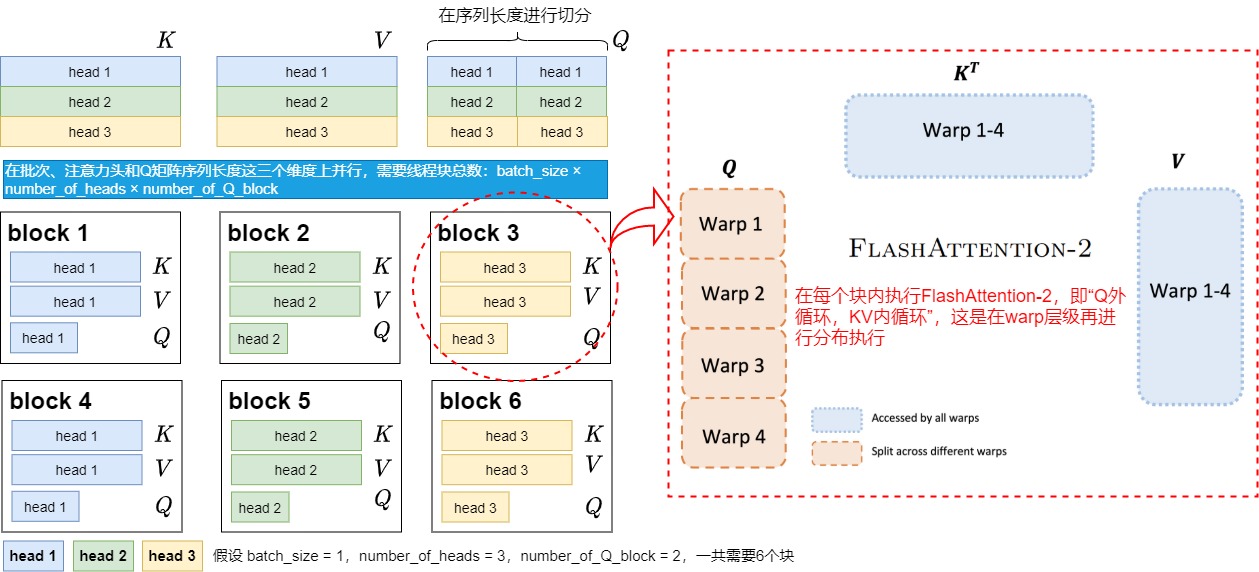
前向传播划分
现在我们继续假设batch_size = 1,num_heads = 3。与V1不同的是,我们在Q的seq_len维度上也做了切分,将其分成2份,即num_m_block = 2。所以现在我们共有1x2x3 = 6个block在跑。这些block之间的运算也是独立的,因为:
- head的计算是独立的,所以各种颜色的block互不干扰
- 采用Q做外循环,KV做内循环时,行与行之间的block是独立的,因此不同行的block互相不干扰。
每个block从Q上加载对应位置的切块,同时从KV上加载对应head的切块,计算出自己所维护的那部分O,然后写入O的对应位置。
划分区别
因为V2中FWD和BWD的内外循环不一致,所以thread block的划分也会有所不同。
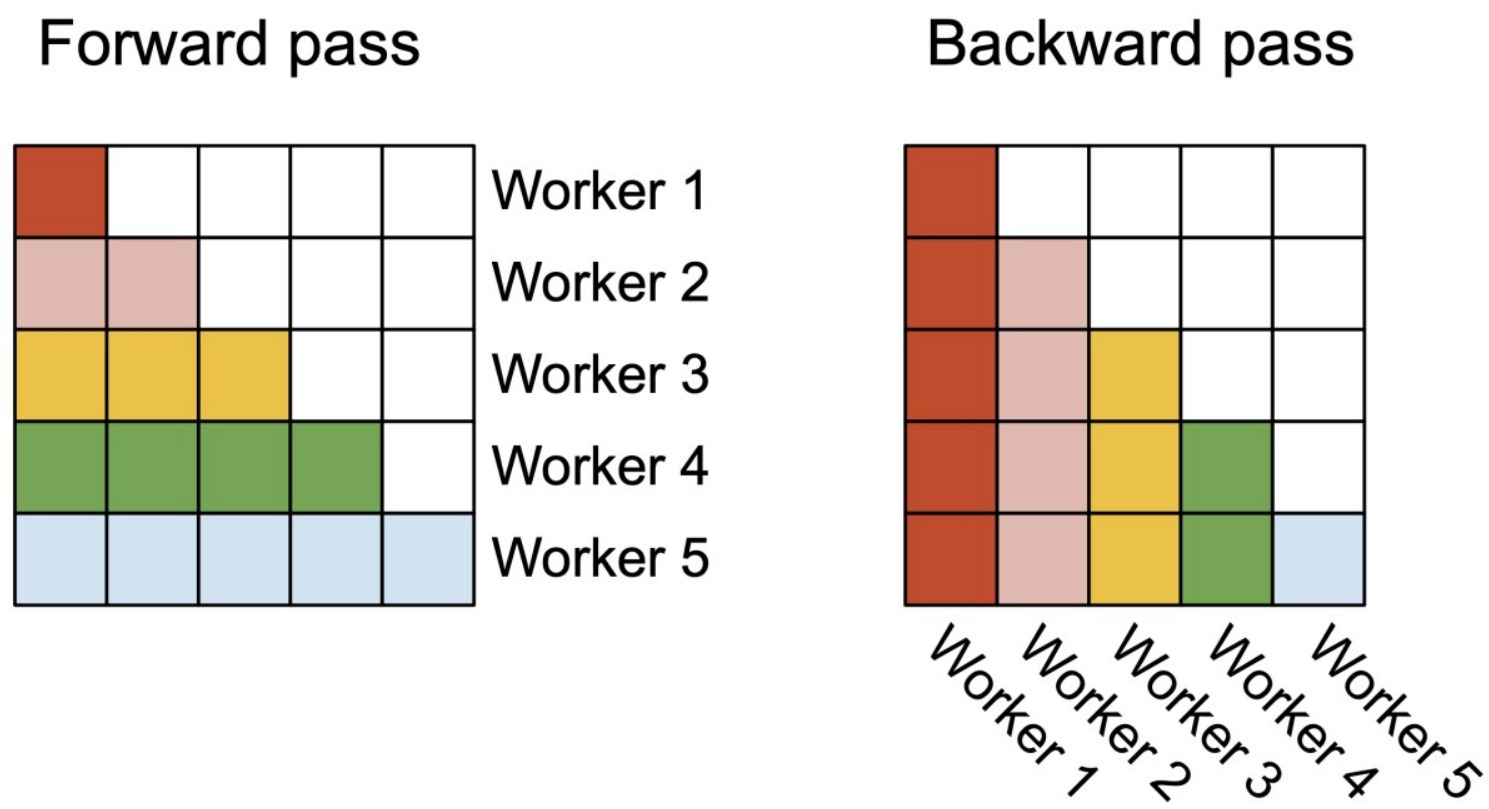
图中的整个大方框表示输出矩阵,worker表示thread block,不同的thread block用不同颜色表示,白色代表因为mask操作而免于计算。
- 前向传播:每一行对应一个worker,它表示O矩阵的每一行都是由一个thread block计算出来的(假设num_heads = 1)。
- 反向传播:每一列对应一个worker,这是因为BWD中我们是KV做外循环,Q做内循环,这种情况下dK, dV都是按行累加的,而dQ是按列累加的,少数服从多数,因此这里thread_block是按 \(K^T\) 的列划分的。
其它可能性
- 为什么V1不做序列并行?其实无论是FA1还是FA2其实都可以做,从代码中看,在V1后期的版本中,也出现了seq维度的并行。虽然V1也引进过seq parallel,但是它的grid组织形式是(batch_size, num_heads, num_m_blocks),而V2的组织形式是(num_m_blocks, batch_size, num_heads),这种顺序调换的意义是什么呢?这样的调换是为了提升L2 cache hit rate。对于同一列的block,它们读的是KV的相同部分,因此同一列block在读取数据时,有很大概率可以直接从L2 cache上读到自己要的数据(别的block之前取过的)。
- 为什么只对Q的seq_len做了切分,而不对KV的seq_len做切分?答案是,一般来说,在Q seq length上拆block并行对于GPU occupancy已经够了。除非你认为SM真得打不满,否则尽量不要在KV维度上做切分,因为如此一来,不同的block之间是没法独立计算的(比如对于O的某一行,它的各个部分来自不同的block,为了得到全局的softmax结果,这些block的结果还需要汇总做一次计算),会额外带来通信开销。其实,在V2的cutlass实现中,确实也提供了对KV的seq_len做切分的方法。
另外,FlashAttention V2在训练和推理prefill的时候计算并行度均比较高,因为query_num比较大,另外还有head_num和batch_size。但是在推理decode阶段就不适合,因为此时query_num为1,单纯batch_size * head_num的值就很小了,所以推理的时候没有使用FlashAttention V2。
调整warps间工作负载
说完了thread block的并行,再来看一个block内的warp怎么分配工作的,此处是优化thread blocks内部warp级别的工作模式,尽量减少warp间的通讯和读取shared memory的次数。
矩阵乘法本身是可分块计算的。所以我们可以充分利用多个warps的计算能力来对矩阵进行分块处理,从而加快整体计算速度。每一个thread block负责某个分块的一个attention head的计算。在每个thread block中,threads又会被组织为多个warps,每个warp中的threads可以协同完成矩阵乘法计算。Work Partitioning主要针对的是对warp的组织优化。不管是V1还是V2,在Ampere架构下,每个block内进一步被划分为4个warp,在Hopper架构下则是8个warp。
左图表示V1,右图表示V2。
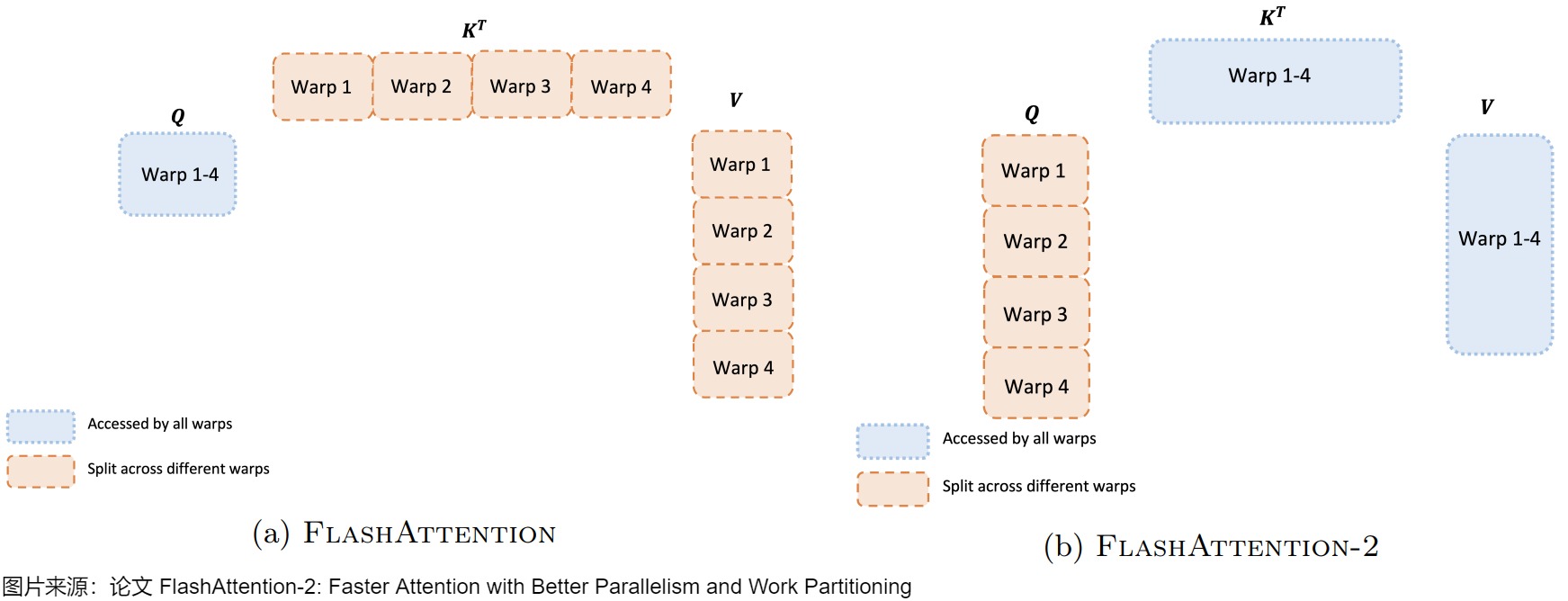
FlashAttention V1
flash attention1的forward计算中,对于每一个block,是将\(K,V\)切分到4个不同的warps上,但是将\(Q\)保持为对所有的4个warps是可见的。作者把这个计算方法称之为'split-K'。
每个warp都从shared memory上读取相同的Q块以及自己所负责计算的KV块。每个warp计算自己的 QK\^T ,然后再和被分割的V相乘。对于同一个Q需要所有KV都计算过才能出结果,而每个warp只是计算出了列方向上的结果,这些列方向上的结果必须汇总起来,才能得到最终O矩阵行方向上的对应结果。所以,每个warp需要把自己算出来的中间结果写到shared memory上,再由一个warp(例如warp1)进行统一的整合。这就是各个warp间需要通讯的原因。需要写中间结果,所以影响了计算效率。另外,内外循环的依赖也导致了V1无法进行并行操作,只能把外循环整体作为一个线程块执行,warp内部也是串行操作。
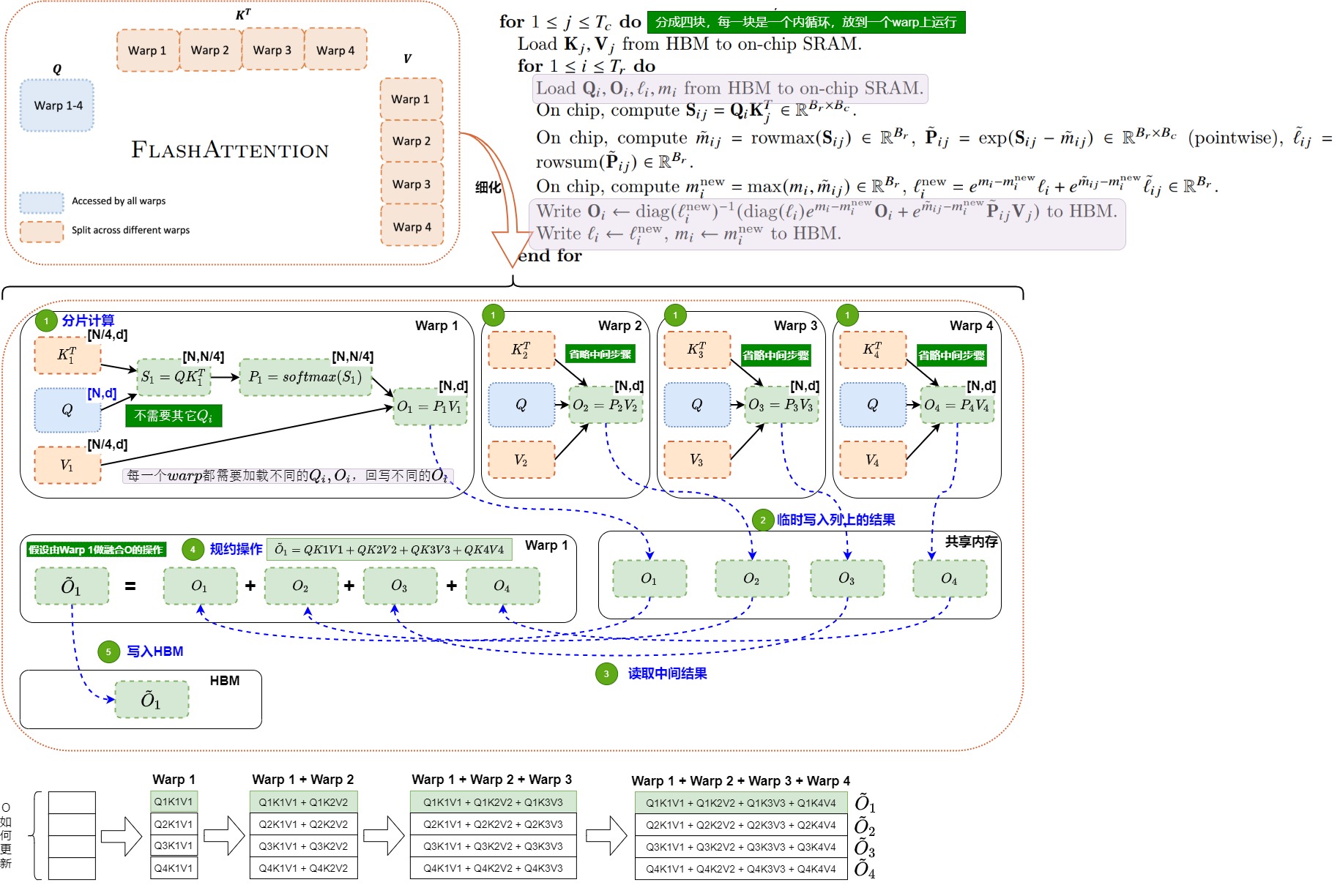
FlashAttention V2
Flash Attention 1这样分块的缺点是:因为而且fwd的目的是沿着行方向计算softmax,行方向信息最后要汇总的,所以需要把中间结果写回SRAM,然后调用耗时的Synchronize后进行相加操作。内存操作就会减慢计算。为了克服这个缺点,v2则使用的是split-Q策略,这样在每个warp计算\(QK^\top\)后,结果只需要对应的V分片即可得到O的对应分片,而无需进行warps间的通信,减少了中间共享内存读写。
关于这样修改为什么会减少shared memory的读写以提高性能,paper的原文是这么说的:

V2实现中,在Q维度上按warp进行切分,每个warp都从shared memory上读取相同的KV块以及自己所负责计算的Q块。Q维度上的切分是互相独立的(行方向上的计算是完全独立的)。对于确定的 Q token,对应的序列维K的所有结果都在一个 warp内,即:一个local softmax的所有计算元素都在一个quarter warp内。即每个warp最后只需要跟分割后的V相乘得到对应的分块输出结果,然后把自己计算出的结果写到O的对应位置即可。这样softmax的计算以及后面 \(P \times VT\) 的计算,都在一个warp内。因为并减少了额外的加法以及它对应的读写操作,所以warp间不需要再做通讯。同时不需要在内循环中进行HBM写入(改为更低频的外循环写入,因为内循环一轮直接就计算完成了,不需要跨外循环同步),减少了I/O开销。
不过这种warp并行方式在V2的BWD过程中就有缺陷了:由于bwd中dK和dV是在行方向上的AllReduce,所以这种切分方式会导致warp间需要通讯。
1.4 Causal Mask处理
V2还有一个针对Causal Masking(因果掩码)的简单优化。在对LLM进行自回归训练时,通常需要使用一个Mask作用于Attention Score矩阵,来保证每个token不会attend到它之后的token。
FlashAttention 本身基于分块计算,因此如果某个分块需要被完全mask,那么可以直接跳过该分块,而无需进行任何计算。所以计算过程就存在Early Exit的可能。也就是,存在mask全为0的block以及索引满足某些条件的block,可以不需要计算直接返回。具体来说可以根据row和column的index大小可以分为三种类型:
- column_index < row_index,此时整个块都需要进行计算\(Softmax(QK^T)\),无需causal mask。
- column_index > row_index,此时整个块都可以skip,不需要进行计算\(QK^T\),无需causal mask。
- column_index = row_index,需要应用causal mask对块内数据进行处理后再计算,即\(Softmax(Mask(QK^T))\),可避免部分运算。
具体论文部分摘录如下。

1.5 MQA/GQA
在FlashAttention中,也支持MQA和GQA。对于MQA和GQA的情形,FlashAttention采用Indexing的方式,而不是直接复制多份KV Head的内容到显存然后再进行计算。而是通过传入KV/KV Head索引到Kernel中,然后计算内存地址,直接从内存中读取KV。

1.6 总结
比较
我们首先把V1和V2进行系统性比较。

计算量
FlashAttention v2 的优势在于少了原来每一步的乘法和除法。其缩减操作的思路具体如下。
假设我们一个向量x,并将其"一切为二"进行分块得到两个子向量。
当都计算完两个子向量后,为了将子向量\(x_2\)的 softmax 更新至全局,需要对它进行分母替换:即将局部的EXP求和项升级为全局。而替换的逻辑是乘上原来的分母\(l_2\),然后再除以新的全局EXP求和项\(l_{all}^{new}\)。这一步更新完后也就得到\(x_2\)最终的 softmax。如果我们对向量x 进行一分为二,而是一分为三。此时,\(x_2\)的 softmax 在由本次更新后,在后续还会再更新一次:当\(x_3\)处理完之后。此时对于\(x_2\)的 softmax ,我们又要乘以\(l_{all}^{new}\) (上一次的全局EXP求和项),并除以此时新的全局EXP求和项。
回过头再来看,就会发现其实没有必要去除以\(l_2\),因为下一次更新由需要乘以一个\(l_2\)来抵消分母。同理,如果 \(x_2\) 之后还有分块,那么我们也无需除以此时的\(l_{all}^{new}\),因为下一次更新时又会乘以一个 \(l_{all}^{new}\) 来抵消。
所以我们其实可以在每一次分块计算完毕后不去除以此时的EXP求和项,只需要等到最后去直接除以最终的 \(l_{all}^{new}\)即可。其本质是在每一次迭代过程中,不再除以EXP求和项。因为不除以EXP求和项了,所以也就无需对EXP求和项进行更新。直到处理完最后一个分块后,直接用此时的全局EXP求和项来做分母即可。
IO
调整循环顺序后,对比FA1,内循环不需要每次读写\(o_i, l_i, m_i\)到HBM,从而减少了IO-Accesses,耗时也会随之减少。
V2总体
我们再用一个V2的整体图作为总结。
1.7 问题
FlashAttention-2 使用online softmax 技术来将单个查询块的注意力计算分割成工作块。每个工作块包括一个键块和一个相应的值块,并且这些工作块按顺序到达,以更新给定查询块的注意力输出。FlashAttention-2 为每个传入的工作块计算在线 softmax,重新调整从前一个工作块获得的中间输出,并将其与当前工作块的部分输出结合起来,以获得最新的更新输出。然而,这种精确计算注意力的方法在其顺序性上受到限制,在解码阶段特别是在需要遍历大量键/值块的情况下,会导致计算速度较慢。
1.8 实现
此处我们用V2的实现来进行学习。
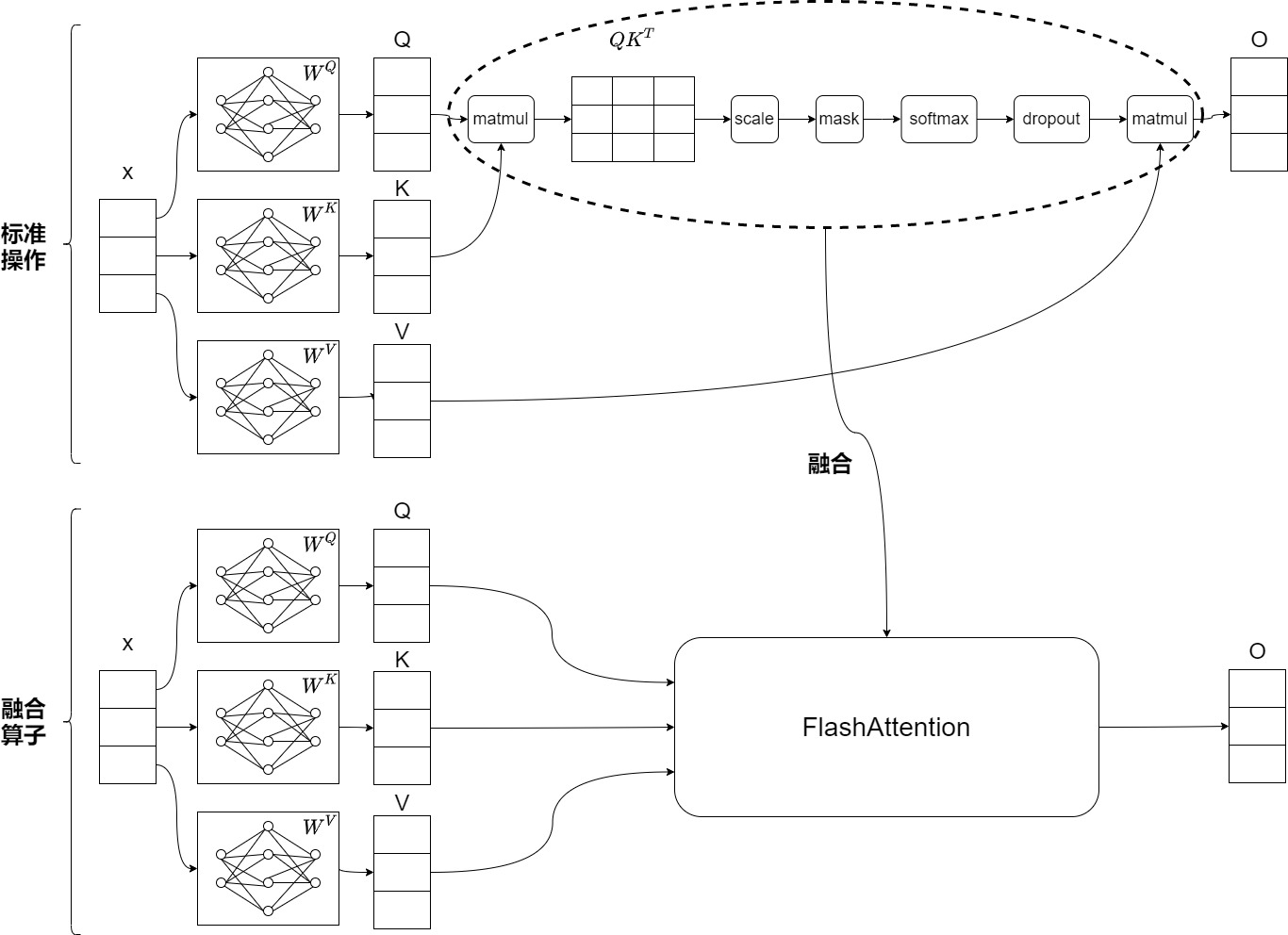
融合算子
最终,FlashAttention可以用一个kernel来执行注意力的操作:从HBM中加载输入数据,在SRAM中执行所有的计算操作(矩阵乘法,mask,softmax,dropout,矩阵乘法),再将计算结果写回到HBM中。通过kernel融合将多个操作融合为一个操作,不需要保留中的S和P矩阵,避免了反复地从HBM中读写数据。
Triton实现
菲尔-蒂勒特(Phil Tillet)在 Triton实现中首次提出并实现了交换循环顺序(行块上的外循环和列块上的内循环,而非最初 FlashAttention 论文中的相反顺序)以及序列长度维度上的并行化等想法。
注:FlashAttention V1算法在 k v 的维度上做外循环,在 q 的维度上做内循环。而在triton的代码实现中,则采用了在 q 的维度上做外循环,在 k v 的维度上做内循环。
V2中调换了循环顺序,使outer loop每个迭代计算没有依赖,可以发送给不同的thread block并行执行,也就是可以对batch* head* sequence三层循环以thread block为粒度并行切分,从而显著增加GPU的吞吐。反向遵循同样的原理:不要把inner loop放在softmax规约的维度,因此正向反向的循环顺序是不同的。
基本思路
FlashAttention V2的计算流程如下, Q按inner loop顺序分别和K, V分开进行计算得到partial sum, 最后将partial sum累加,得到和Q形状一样的输出。伪码描述为。
python
flash_attention_2():
# outter loop
parallel do q[NUM_BLOCK_M]:
# inner loop
for i in range(NUM_BLOCK_N):
qk = q @ k[i].T
score = online_softmax(qk)
out += score @ v[i]
rescale(out)对应到代码,基本思路为:_attention实现并行、发射算子。_att_fwd找到本线程应该存取的数据,_attn_fwd_inner负责实际计算注意力。
线程模型
单线程的注意力计算做如下操作: q[seqlen, headdim] @ k[seqlen, headdim].T @ v[seqlen, headdim]
多线性的注意力计算需要从q的维度切分,每个线程负责Block_M个token的单头注意力计算([Block_M, headdim])。即如果输入的形状为[bs, head, seqlen, headdim],则总线程数为bs x head x seqlen/Block_M。在bs x head维度和seqlen维度都并行。
class _attention
_attention利用 torch.autograd.Function 实现 Flash Attention 的自定义算子。
python
class _attention(torch.autograd.Function):
@staticmethod
def forward(ctx, q, k, v, causal, sm_scale):
# shape constraints
# q k v 的 shape 是 [B, H, S, D],因此数组-1是最后一个维度,就是D_HEAD,头的维度。
Lq, Lk, Lv = q.shape[-1], k.shape[-1], v.shape[-1]
assert Lq == Lk and Lk == Lv
assert Lk in {16, 32, 64, 128}
# 初始化输出
o = torch.empty_like(q)
# 设置q在S维度上的切分,即Q分块的粒度。每个块需要处理q块的形状为 [1, 1, BLOCK_M, D]
BLOCK_M = 128 # BLOCK SIZE of Q、O Matrix
# 设置关于内循环时,K、V块在S维度上的长度,即,KV的分块计算的粒度
BLOCK_N = 64 if Lk <= 64 else 32 # TILE SIZE of K、V Matrix
# num_stages 是关于 A100 中新的异步数据拷贝特性的设置,可以粗略地理解为 prefetch 的深度,缓存多少份数据在buffer里
num_stages = 4 if Lk <= 64 else 3
# 每个kernel所需要的 warp数量是4,线程数是 4 x 32
num_warps = 4
stage = 3 if causal else 1
# Tuning for H100
if torch.cuda.get_device_capability()[0] == 9:
num_warps = 8
num_stages = 7 if Lk >= 64 else 3
# 划分二维网格,共有 triton.cdiv(q.shape[2], BLOCK_M)*q.shape[0]*q.shape[1]个块
grid = (triton.cdiv(q.shape[2], BLOCK_M), q.shape[0] * q.shape[1], 1)
# 存下S矩阵每行的最大值,用于用于反向传播使用
M = torch.empty((q.shape[0], q.shape[1], q.shape[2]), device=q.device, dtype=torch.float32)
_attn_fwd[grid](
q, k, v, sm_scale, M, o, #
q.stride(0), q.stride(1), q.stride(2), q.stride(3), #
k.stride(0), k.stride(1), k.stride(2), k.stride(3), #
v.stride(0), v.stride(1), v.stride(2), v.stride(3), #
o.stride(0), o.stride(1), o.stride(2), o.stride(3), #
q.shape[0], q.shape[1], #
N_CTX=q.shape[2], #
BLOCK_M=BLOCK_M, #
BLOCK_N=BLOCK_N, #
BLOCK_DMODEL=Lk, # head size
STAGE=stage, #
num_warps=num_warps, # _attn_fwd函数被分成了4个warp
num_stages=num_stages #
)
ctx.save_for_backward(q, k, v, o, M)
ctx.grid = grid
ctx.sm_scale = sm_scale
ctx.BLOCK_DMODEL = Lk
ctx.causal = causal
return o
@staticmethod
def backward(ctx, do):
q, k, v, o, M = ctx.saved_tensors
assert do.is_contiguous()
assert q.stride() == k.stride() == v.stride() == o.stride() == do.stride()
dq = torch.empty_like(q)
dk = torch.empty_like(k)
dv = torch.empty_like(v)
BATCH, N_HEAD, N_CTX = q.shape[:3]
PRE_BLOCK = 128
NUM_WARPS, NUM_STAGES = 4, 5
BLOCK_M1, BLOCK_N1, BLOCK_M2, BLOCK_N2 = 32, 128, 128, 32
BLK_SLICE_FACTOR = 2
RCP_LN2 = 1.4426950408889634 # = 1.0 / ln(2)
arg_k = k
arg_k = arg_k * (ctx.sm_scale * RCP_LN2)
PRE_BLOCK = 128
assert N_CTX % PRE_BLOCK == 0
pre_grid = (N_CTX // PRE_BLOCK, BATCH * N_HEAD)
delta = torch.empty_like(M)
_attn_bwd_preprocess[pre_grid](
o, do, #
delta, #
BATCH, N_HEAD, N_CTX, #
BLOCK_M=PRE_BLOCK, D_HEAD=ctx.BLOCK_DMODEL #
)
grid = (N_CTX // BLOCK_N1, 1, BATCH * N_HEAD)
_attn_bwd[grid](
q, arg_k, v, ctx.sm_scale, do, dq, dk, dv, #
M, delta, #
q.stride(0), q.stride(1), q.stride(2), q.stride(3), #
N_HEAD, N_CTX, #
BLOCK_M1=BLOCK_M1, BLOCK_N1=BLOCK_N1, #
BLOCK_M2=BLOCK_M2, BLOCK_N2=BLOCK_N2, #
BLK_SLICE_FACTOR=BLK_SLICE_FACTOR, #
BLOCK_DMODEL=ctx.BLOCK_DMODEL, #
num_warps=NUM_WARPS, #
num_stages=NUM_STAGES #
)
return dq, dk, dv, None, None可以这么调用_attention()类。Z,H,N_CTX,D_head分别是batch, head, sequence length, head dimension,如此看来,batch, head, sequence length已经融合到q,k,v里面了。
python
q = torch.empty((Z, H, N_CTX, D_HEAD), dtype=dtype, device="cuda").normal_(mean=0.1, std=0.2).requires_grad_()
k = torch.empty((Z, H, N_CTX, D_HEAD), dtype=dtype, device="cuda").normal_(mean=0.4, std=0.2).requires_grad_()
v = torch.empty((Z, H, N_CTX, D_HEAD), dtype=dtype, device="cuda").normal_(mean=0.3, std=0.2).requires_grad_()_attn_fwd
_attn_fwd是Triton中的一个内核函数,用于将一个批次的输入Q、K、V矩阵与权重矩阵相乘,然后执行 softmax 操作。此内核函数通过计算每个位置的加权和,并将其存储在输出矩阵中来实现self-attention操作。在计算期间,每个线程块处理一个输入矩阵行的一部分,并将其存储在共享内存中,以便在处理其他行时可以重用该数据。这段代码的逻辑是这样的:
- 根据当前程序的索引和输入矩阵的行跨度(即每行占用的字节数),计算出输入矩阵中当前行的起始指针。
- 根据块大小(即每个程序处理的列数),创建一个偏移量数组,表示每个程序要访问的输入元素的索引。注意块大小是大于等于列数的最小2的幂,所以可以保证每行可以被一个块完全处理。
- 根据偏移量和掩码(用于过滤掉超出列数的偏移量),从输入指针中加载当前行的元素到寄存器中,并减去当前行的最大值,以提高数值稳定性。
- 对减去最大值后的元素进行指数运算,并在给定轴上求和,得到分母。然后将分子除以分母,得到softmax输出。
- 根据偏移量和掩码(用于过滤掉超出列数的偏移量),将softmax输出从寄存器中存储到输出指针中。
这样,每个程序都可以并行地处理输入矩阵的一部分,并将结果写入输出矩阵中。这种方式可以提高内存访问和计算的效率和并行度。
具体代码如下。
python
"""
# Another trick we can use is to ask the compiler to use more threads per row by
# increasing the number of warps (`num_warps`) over which each row is distributed.
# You will see in the next tutorial how to auto-tune this value in a more natural
# way so you don't have to come up with manual heuristics yourself.
"""
@triton.jit
def _attn_fwd(Q, K, V, sm_scale, M, Out, #
stride_qz, stride_qh, stride_qm, stride_qk, # stride_qz就是batch,使用它就能在batch上并行
stride_kz, stride_kh, stride_kn, stride_kk, # k和n与v相反
stride_vz, stride_vh, stride_vk, stride_vn, # k和n与k相反
stride_oz, stride_oh, stride_om, stride_on, #
Z, H, #
N_CTX: tl.constexpr, #
BLOCK_M: tl.constexpr, #
BLOCK_DMODEL: tl.constexpr, #
BLOCK_N: tl.constexpr, #
STAGE: tl.constexpr #
):
# 目的是知道本线程块应该操作什么数据
# program_id是外层循环中线程块的id,线程块包括warp组线程。start_m就是线程块的grid第一维度坐标,借此可以获取本线程块在 q 的 S 维度上的指针位置 start_m * BLOCK_M。
start_m = tl.program_id(0) # 对应论文算法的外层循环,即Q矩阵的第几个块
# 获取本线程块的grid的第二维度坐标。第二维度的数量等于 Z * H,因此使用它可以确定在第几个 batch 的第几个 head。此处用Z表示B维度
# 下面三行依据内层循环对应的线程索引知道本线程在qkv上应该在的offset
off_hz = tl.program_id(1)
off_z = off_hz // H # batch 的 offset
off_h = off_hz % H # head 的 offset
# 获取当前 head 的 shape 为 [S, D] tensor 的 offset
# 使用 stride_qz来对batch并行,使用stride_qh在head上并行,就是对batch, head在线程角度进行并行
qvk_offset = off_z.to(tl.int64) * stride_qz + off_h.to(tl.int64) * stride_qh
# 根据当前程序的索引和输入矩阵的行跨度(即每行占用的字节数),计算出输入矩阵中当前行的起始指针
# 创建一个 block 指针指向对应 [S, D] tensor 里的 [start_m * BLOCK_M:(start_m + 1) * BLOCK_M, D] BLOCK_DMODEL=D,即第 start_m 个 block 加载 Q 的一个子 tensor [BLOCK_M, BLOCK_DMODEL]
# 以行的方式访问则使用 order=(1, 0)
Q_block_ptr = tl.make_block_ptr( # 构建一个指针
base=Q + qvk_offset, # 找到在输入矩阵中的起始位置
shape=(N_CTX, BLOCK_DMODEL),
strides=(stride_qm, stride_qk),
offsets=(start_m * BLOCK_M, 0), # Q在外层,和算法一致
block_shape=(BLOCK_M, BLOCK_DMODEL),
order=(1, 0),
)
v_order: tl.constexpr = (0, 1) if V.dtype.element_ty == tl.float8e5 else (1, 0)
V_block_ptr = tl.make_block_ptr(
base=V + qvk_offset,
shape=(N_CTX, BLOCK_DMODEL),
strides=(stride_vk, stride_vn),
offsets=(0, 0),
block_shape=(BLOCK_N, BLOCK_DMODEL),
order=v_order,
)
# k 需要进行一个转置
K_block_ptr = tl.make_block_ptr(
base=K + qvk_offset,
shape=(BLOCK_DMODEL, N_CTX),
strides=(stride_kk, stride_kn),
offsets=(0, 0),
block_shape=(BLOCK_DMODEL, BLOCK_N),
order=(0, 1), # 转置
)
O_block_ptr = tl.make_block_ptr(
base=Out + qvk_offset,
shape=(N_CTX, BLOCK_DMODEL),
strides=(stride_om, stride_on),
offsets=(start_m * BLOCK_M, 0), # 外层循环,利用start_m(外层循环对应的线程索引)知道本线程在q上的offset
block_shape=(BLOCK_M, BLOCK_DMODEL),
order=(1, 0),
)
# initialize offsets
# tl.arange函数,用于创建一个从0到指定值的连续整数序列,类似于Python中的range函数。
offs_m = start_m * BLOCK_M + tl.arange(0, BLOCK_M)
offs_n = tl.arange(0, BLOCK_N)
# initialize pointer to m and l
m_i = tl.zeros([BLOCK_M], dtype=tl.float32) - float("inf") # 初始化为负无穷
l_i = tl.zeros([BLOCK_M], dtype=tl.float32) + 1.0
acc = tl.zeros([BLOCK_M, BLOCK_DMODEL], dtype=tl.float32) # 向量o
# load scales
qk_scale = sm_scale
qk_scale *= 1.44269504 # 1/log(2)
# load q: it will stay in SRAM throughout
# 对于每个 block 需要整个 q 的子 tensor [BLOCK_M, BLOCK_DMODEL] 全程参与
q = tl.load(Q_block_ptr)
# stage 1: off-band
# For causal = True, STAGE = 3 and _attn_fwd_inner gets 1 as its STAGE
# For causal = False, STAGE = 1, and _attn_fwd_inner gets 3 as its STAGE
if STAGE & 1:
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M, BLOCK_DMODEL, BLOCK_N, #
4 - STAGE, offs_m, offs_n, N_CTX, V.dtype.element_ty == tl.float8e5 #
)
# stage 2: on-band
if STAGE & 2:
# barrier makes it easier for compielr to schedule the
# two loops independently
tl.debug_barrier()
acc, l_i, m_i = _attn_fwd_inner(acc, l_i, m_i, q, K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M, BLOCK_DMODEL, BLOCK_N, #
2, offs_m, offs_n, N_CTX, V.dtype.element_ty == tl.float8e5 #
)
# 后处理
# 算法流程第13步
m_i += tl.math.log2(l_i)
# 算法流程第12步
acc = acc / l_i[:, None]
m_ptrs = M + off_hz * N_CTX + offs_m
# 将结果写回
# 算法流程第15步
tl.store(m_ptrs, m_i)
# 算法流程第14步
tl.store(O_block_ptr, acc.to(Out.type.element_ty))_attn_fwd_inner
_attn_fwd_inner()函数是具体执行注意力操作的地方。首先,第 start_m 个 block 加载 Q 的一个子 tensor BLOCK_M, BLOCK_DMODEL,依次跟 K 的 N_k 个子 tensor BLOCK_DMODEL, BLOCK_N 相乘,其中 N_k x BLOCK_N = start_m x BLOCK_M,这里面跟 K 的子 tensor 得到结果 BLOCK_M, BLOCK_N 后,再与对应 V 的子 tensor BLOCK_N, BLOCK_DMODEL 相乘得到 O 的 子 tensor BLOCK_M, BLOCK_DMODEL,由于要循环 N_k 次,所以最后 O 的结果是 N_k 个叠加的结果。可知第 start_m 个 block 得到 Q 和 K 所有子 tensor 相乘的结果拼接之后,实际形状为 BLOCK_M, start_m x BLOCK_M。
具体代码如下,按照按照V2流程来标注。
python
@triton.jit
def _attn_fwd_inner(acc, l_i, m_i, q, #
K_block_ptr, V_block_ptr, #
start_m, qk_scale, #
BLOCK_M: tl.constexpr, BLOCK_DMODEL: tl.constexpr, BLOCK_N: tl.constexpr, #
STAGE: tl.constexpr, offs_m: tl.constexpr, offs_n: tl.constexpr, #
N_CTX: tl.constexpr):
# range of values handled by this stage
if STAGE == 1:
lo, hi = 0, start_m * BLOCK_M
elif STAGE == 2:
lo, hi = start_m * BLOCK_M, (start_m + 1) * BLOCK_M
lo = tl.multiple_of(lo, BLOCK_M)
# causal = False
else:
lo, hi = 0, N_CTX
# 调整 block 指针的起始 offsets
K_block_ptr = tl.advance(K_block_ptr, (0, lo))
V_block_ptr = tl.advance(V_block_ptr, (lo, 0))
# loop over k, v and update accumulator
# 第一阶段从 0, start_m * BLOCK_M
# 算法流程第6步,执行内循环
for start_n in range(lo, hi, BLOCK_N): # 对应的内层循环
start_n = tl.multiple_of(start_n, BLOCK_N)
#实际执行QK^T @ V
# -- compute score=QK^T ----
# k [BLOCK_DMODEL, BLOCK_N]
# 算法流程第7步,load Kj, Vj到SRAM
k = tl.load(K_block_ptr)
# qk [BLOCK_M, BLOCK_N]
qk = tl.zeros([BLOCK_M, BLOCK_N], dtype=tl.float32)
# 算法流程第8步
qk += tl.dot(q, k)
# 算法流程第9步
if STAGE == 2:
# 第二阶段去除小三角形对结果的影响
mask = offs_m[:, None] >= (start_n + offs_n[None, :])
qk = qk * qk_scale + tl.where(mask, 0, -1.0e6)
m_ij = tl.maximum(m_i, tl.max(qk, 1)) # 最大的m, 最后一个维度(行向量)的最大值构成的向量
qk -= m_ij[:, None]
else:
# 统计当前的 m_ij
m_ij = tl.maximum(m_i, tl.max(qk, 1) * qk_scale) # 最大的m
qk = qk * qk_scale - m_ij[:, None]
p = tl.math.exp2(qk) # 计算exp
# 统计当前的 l_ij
l_ij = tl.sum(p, 1) # 最后一个维度的求和
# -- update m_i and l_i
# 计算当前的修正因子 alpha
alpha = tl.math.exp2(m_i - m_ij)
# 修正当前的 l_i
l_i = l_i * alpha + l_ij
# 算法流程第10步
# -- update output accumulator --
# 对 O 子 tensor 的累加结果进行修正
acc = acc * alpha[:, None]
# update acc
# 算法流程第7步,load Kj, Vj到SRAM
v = tl.load(V_block_ptr)
# score @V
acc += tl.dot(p.to(tl.float16), v)
# update m_i
m_i = m_ij
# 调整 K 和 V 的指针
V_block_ptr = tl.advance(V_block_ptr, (BLOCK_N, 0))
K_block_ptr = tl.advance(K_block_ptr, (0, BLOCK_N))
return acc, l_i, m_i0x02 Flash-Decoding
虽然 FlashAttention-2 比 FlashAttention 实现了 2 倍的加速,但是因为它们忽略了注意机制在解码阶段与解码阶段的不同行为,所以仅在解码的预填充阶段才能发挥效果。在decoding 阶段会严重浪费GPU核心。而且由于缺乏对张量并行的支持,Vanilla FlashAttention-2也无法适应多GPU场景。
而当代大型语言模型需要一个能够在多GPU场景中良好扩展的注意力机制,这样才可以对越来越长的上下文长度提供有效支持。为了提高 attention 在推理阶段的计算速度,FlashAttention作者提出了 FlashDecoding,其博客地址:
2.1 现状
在LLM的推理过程本质上包括两个不同的计算阶段。
- 第一阶段是提示计算阶段(有时称为预填充阶段)。在此阶段,来自输入提示的所有token都经过模型的前向传播以生成第一个输出token。 此阶段计算量较大,需要较高的 FLOPS/s。
- 第二阶段是解码阶段(有时称为Token 生成阶段)。该阶段以自回归方式开始,每个后续token都是根据前一个token的前向传播结果,以及序列中先前的KV-Cache来生成的。 随着上下文长度的增加,这个缓存的上下文可能会很长。如此长的上下文长度的顺序处理使得解码阶段变慢,而且受内存带宽和容量限制。
下图总结了自注意力涉及的三个操作,以及解码和预填充阶段涉及的相应维度。
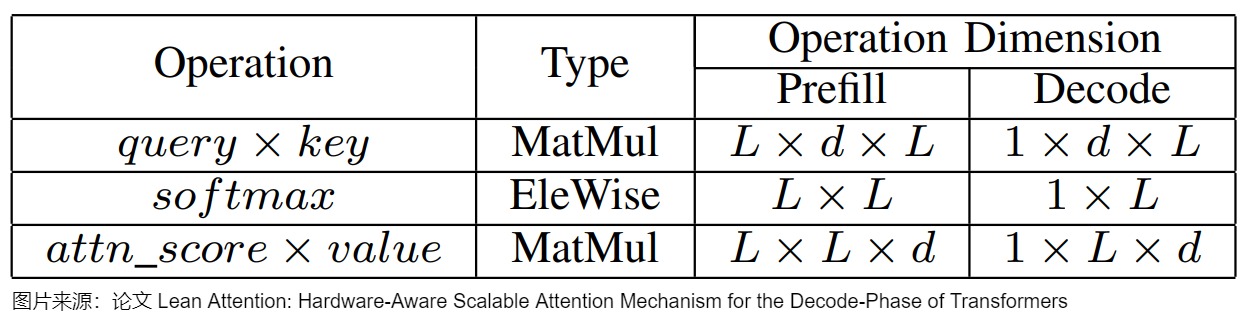
虽然研究人员已经提出了KV-Cache和 FlashAttention 等机制,来满足LLM的低延迟需求。 然而,这些技术并不能根据推理过程中不同阶段在计算上的不同性质来进行处理。
FlashAttention V2 前向传播会在Q的seqlen维度以及batch_size维度做并行。从下图可以看到,对于当前的Q的分块Queries,forward pass会在thread block中,逐个遍历所有的K, V分块,计算逐个分块的局部Attention输出。每个局部的Attention输出,会在thread block内部遍历的过程中,随着每一次迭代,根据当前次迭代的值进行scale,一直到沿着K,V的迭代完成后,就获得了最终正确的Output。

这种方式对于训练时期的前向传播是有效的,因为因为训练时,seqlen或bs会比较大,GPU资源能够被有效地利用。但是推理的Generation阶段是逐token生成,每次推理实际的queries token数为1,已经无法通过queries进行并行了。特别是如果bs还比较小,会导致GPU资源无法得到有效的利用。即,如果batch size小于 GPU 上流处理器(SM)的数量(A100 GPU 上有 108 个 SM),那么 atttention 操作只能使用一小部分 GPU!尤其是在使用较长的上下文时。
2.2 方案
于是针对这种情况,FlashAttention作者开发了FlashDecoding,对推理阶段的forward进行优化。基本的思路其实也很直观:既然在推理场景decode阶段,query_num = 1和可能过小的batch size会导致block数量不够,那么是否可以不去考虑query增加block,而考虑在key和vlaue的维度去增加block?
按照此思路,Flash-Decoding 在 FlashAttention V2对 batch size 和 query length 并行的基础上增加了一个新的并行化维度:keys/values 的序列长度。这种新的并发性减少了延迟,同时增加了硬件占用率,但需要额外的最终规约成本。
Flash Decoding主要包含以下三个步骤:
- 将K/V切分成更小的块,这样可以支持后续的并发。因为不需要在物理上分开,所以此处数据分块不涉及GPU操作。键/值块依然是完整键/值张量的视图。
- 并行启动这些K/V块。在这些K/V块上使用标准FlashAttention并行计算query与每个块的注意力。对于每个块的每行(因为一行是一个特征维度),Flash Decoding会记录一个额外的标量:注意力值的 log-sum-exp。
- 最后,利用内积中的加法可交换性,通过对所有拆分块的计算结果进行归约,结合 log-sum-exp 调整各个块的贡献,计算出最终的结果。
我们只需要对第2步和第3步执行单独的kernels。虽然最终的reduction操作会引入一些额外的计算,但在总体上,Flash-Decoding通过增加并行化的方式取得了更高的效率。
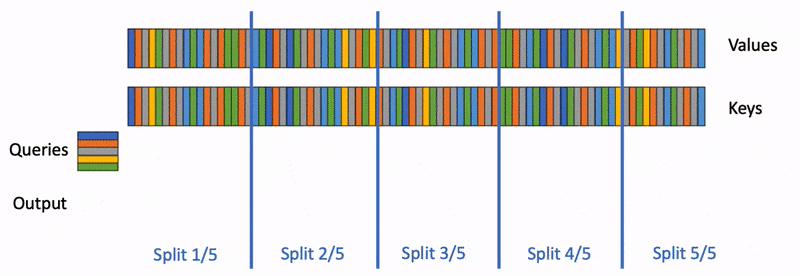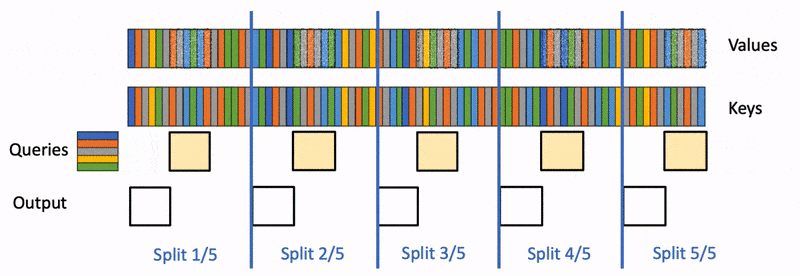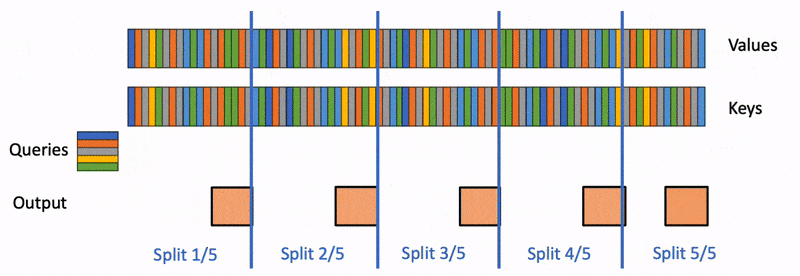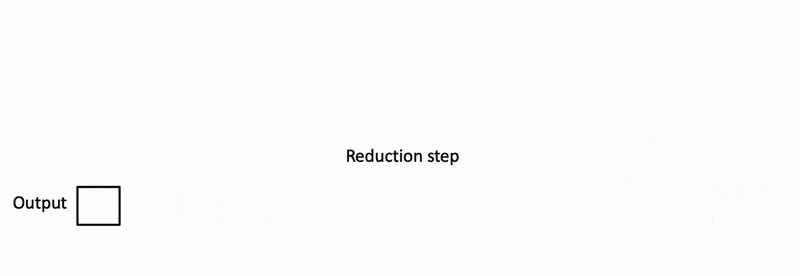
我们以一张图来对Flash-Decoding和FlashAttention V2进行对比。图中假设有2个head,一个batch,5个SM。1个block只能做相同的事情,如,只能单独计算head1或者head0,不能同时计算head0和head1。batch为1的时候,FlashAttention2就只能分配2个block,FlashDecoding 则能分配4个block。
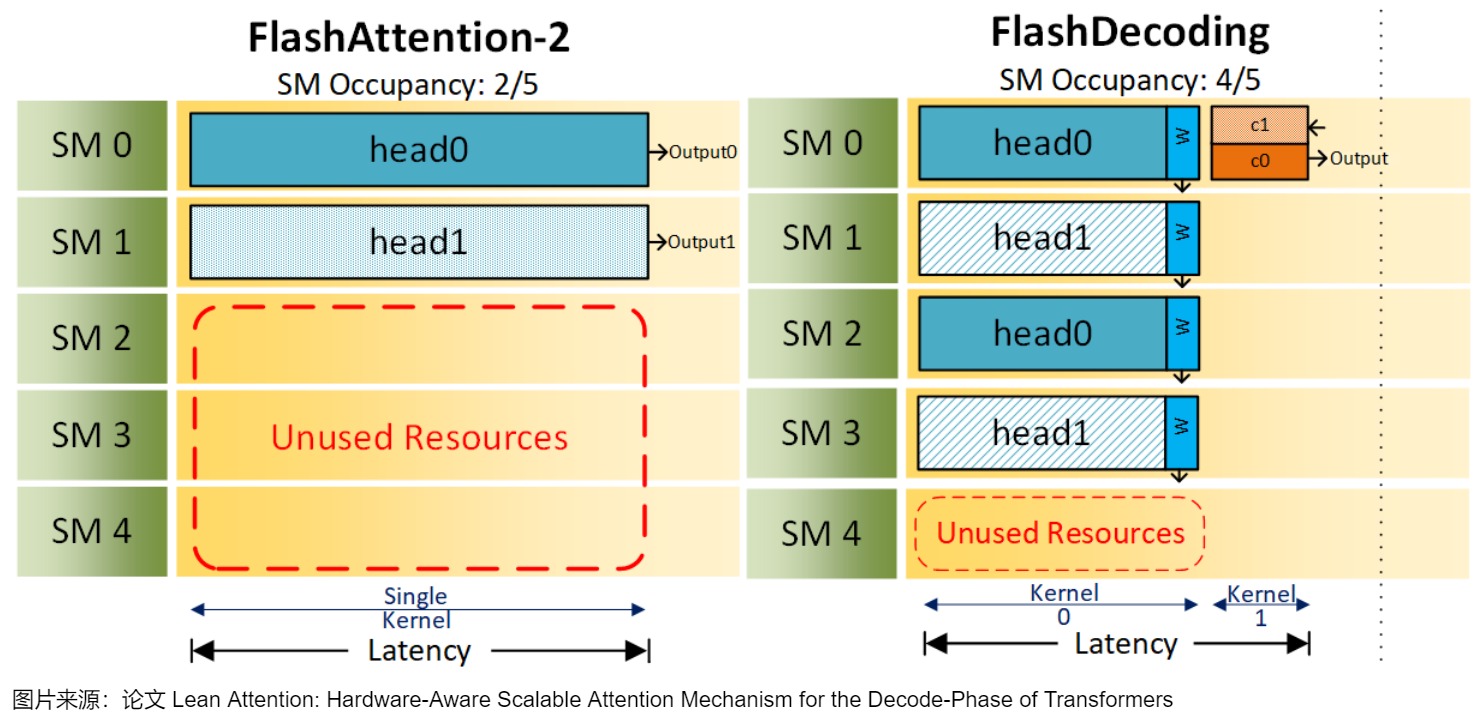
2.3 讨论
FlashAttention对batch size和query length进行了并行化加速,Flash-Decoding在此基础上增加了一个新的并行化维度:keys/values的序列长度。即使batch size很小,但只要上下文足够长,它就可以充分利用GPU。与FlashAttention类似,Flash-Decoding几乎不用额外存储大量数据到全局内存中,从而减少了内存开销。
FlashDecoding有如下2个可能不高效的地方。
- 需要启动2次的kernel,第一次kernel是每个block算query和部分key和部分value的部分attention结果,第二次kernel主要是对第一次的部分attention结果进行校正reduce。
- 第一次计算的时候,序列维度的并行度是固定的,长序列和短序列使用的block数量是一样多的,这就导致长序列计算的慢,短序列计算的快。
FlashDecoding++(作者并非Tri Dao)基于FlashDecoding进行了修改,通过近似softmax中的全局最大值来消除同步成本,以避免最终重新缩放。FlashDecoding++在FlashDecoding的内部循环中避免了计算中间局部softmax,一旦算法可以确定所有部分指数和(partial exponential sums),就会计算最终全局softmax。此外,FlashDecoding++使用双缓冲来隐藏内存访问延迟。
尽管有这些改进,FlashDecoding和FlashDecoding++ 依然是一种非最优的负载平衡策略。它需要启动额外的reduce核心,因此受到内核启动开销,以及随着问题规模增加而增加的减少或修正开销的影响。
0x03 Flash-Mask
随着人工智能技术的迅猛发展,以 Transformer 为代表的大模型在自然语言处理、计算机视觉和多模态应用中展现出了非凡的能力。在这些大模型中,注意力(Attention)机制是一个关键环节。为了在大模型训练任务中确定哪些 Query-Key token 之间需要进行有效的 Attention 计算,业界通常使用注意力掩码(Attention Mask)。然而,目前的注意力掩码通常采用二维稠密矩阵表示,这导致了一些问题。一方面,这种表示方法引入了大量冗余计算,因为许多无效 token 的 Attention 仍需计算;另一方面,另一方面因其巨大的存储占用导致难以实现长序列场景的高效训练,难以进行高效训练。
虽然业界已有 FlashAttention 等针对特定注意力掩码的计算加速方法,但其支持的注意力掩码模式有限,难以满足大模型训练任务对灵活注意力掩码的需求。为了解决上述问题,飞桨独创 FlashMask 技术,提出了列式稀疏的注意力掩码表示方法,支持灵活多样的注意力掩码模式,这样可以降低存储复杂度,并在此基础上实现了高效的算子 Kernel,其线性访存复杂度 O(N),这极大的加速了大模型训练效率,尤其是长序列场景下的训练效率。
3.1 动机
FLASHMASK可以理解为是对FA的一个扩展。FA旨在解决传统注意力机制在处理长句子时面临的计算和内存需求呈平方阶增长的问题。这种增长对于 Transformer 模型在任意一个硬件上来说都是一个重大挑战,尤其是长句子的LLM训练中。具体点讲,FA通过 IO 感知的内存优化减少了注意力延迟,并消除了对 \(O(N^2)\) 的内存依赖。然而,在上述训练场景下,FA的不足有二:
- 对某些attention mask类型的原生支持有限,并不天然地适应更复杂的mask需求,如下图上方粉色区域,FlashAttention 只能支持如纯因果掩码(Causal)、滑动窗口掩码(Sliding Window)、因果文档掩码(Causal Document Mask)和文档掩码(Document Mask)等几种固定形式的掩码。然而,实际训练任务中使用的注意力掩码形式往往丰富多变,当前技术难以满足大模型不同训练任务对注意力掩码灵活性的要求。
- 以往的方法使用稠密mask矩阵,这会导致 \(O(N^2)\) 的访存增长,从而效率不高,导致支持的最大上下文长度有限。
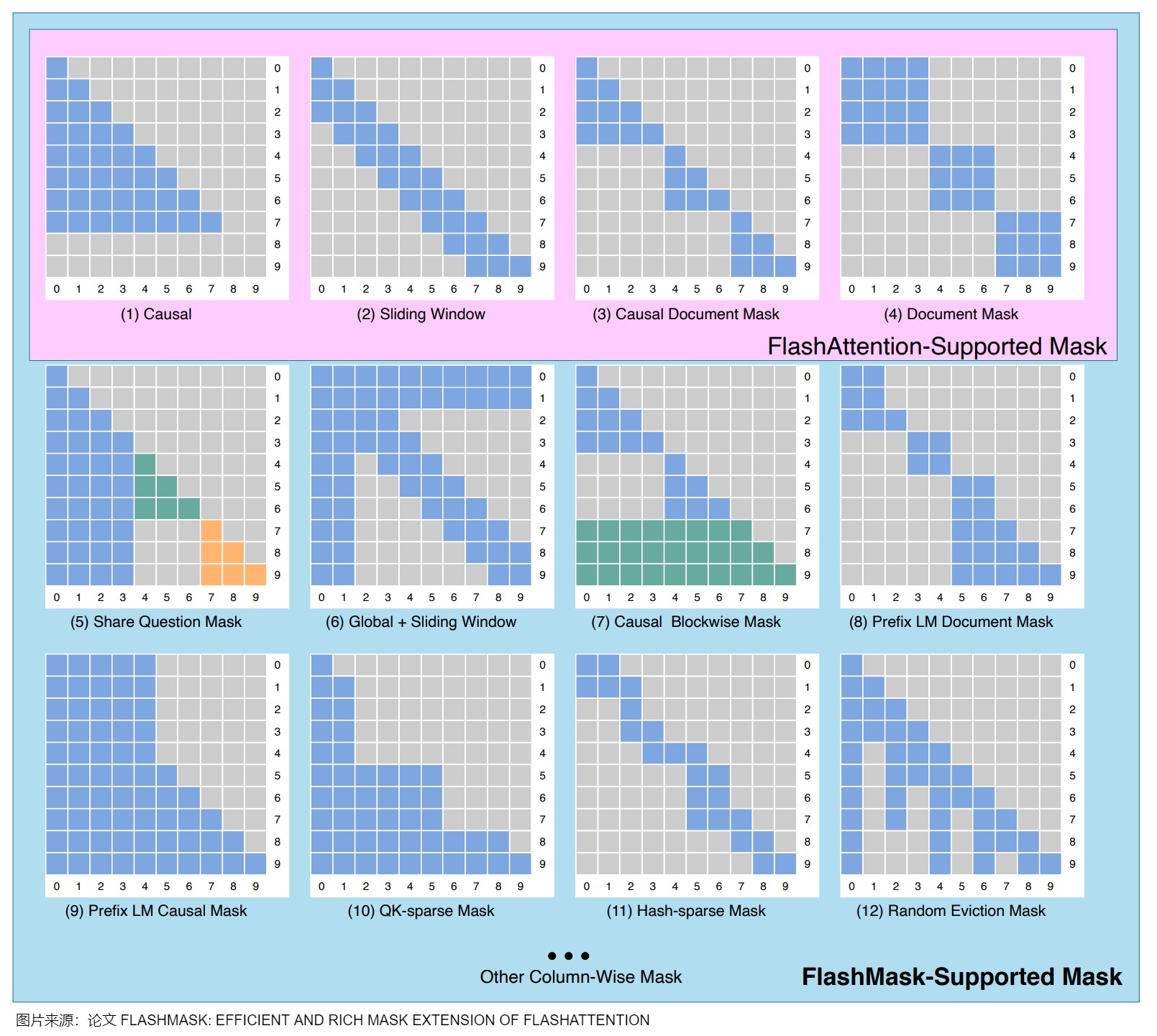
3.2 思路
FlashMask 的核心发现是,在大模型常见的注意力掩码模式中,Query-Key token 的掩码模式具有一定的连续性。具体而言,对于每一个 Key token,无效注意力计算的 Query token 是相邻排列的。也就是说,在上图的二维掩码矩阵中,当Query token 和 Key token 相互作用时,是沿列方向连续分布的。基于这一洞察,FlashMask 巧妙地将二维稠密掩码矩阵转换为一维的行索引区间,从而实现更为紧凑的表示形式,并显著降低了存储需求。我们可以公式化表示为:
\M_j = \[start_j, end_j), \\forall j \\in {1,...N} \\
其中 N 为 Key 的序列长度,\(M_j\)为二维的稠密掩码矩阵的第 j 列,为连续的行索引区间,表示这些连续 Query token 是被 mask 掉,置为无效 Attention 计算。
为了高效处理因果和双向注意力场景中的复杂掩码模式,FlashMask 提出了一种新颖的列式稀疏表示方法。以对角线为区分,它使用四个一维向量来表示掩码:
- 下三角起始行索引(Lower Triangular Start,简称 LTS)。
- 下三角结束行索引(Lower Triangular End,简称 LTE)。
- 上三角起始行索引(Upper Triangular Start,简称 UTS)。
- 上三角结束行索引(Upper Triangular End,简称 UTE)。
其中下三角被 mask 掉的行索引区间使用[𝐿𝑇𝑆, 𝐿𝑇𝐸)表示,上三角被 mask 掉的行索引区间使用 [𝑈𝑇𝑆, 𝑈𝑇𝐸)表示。
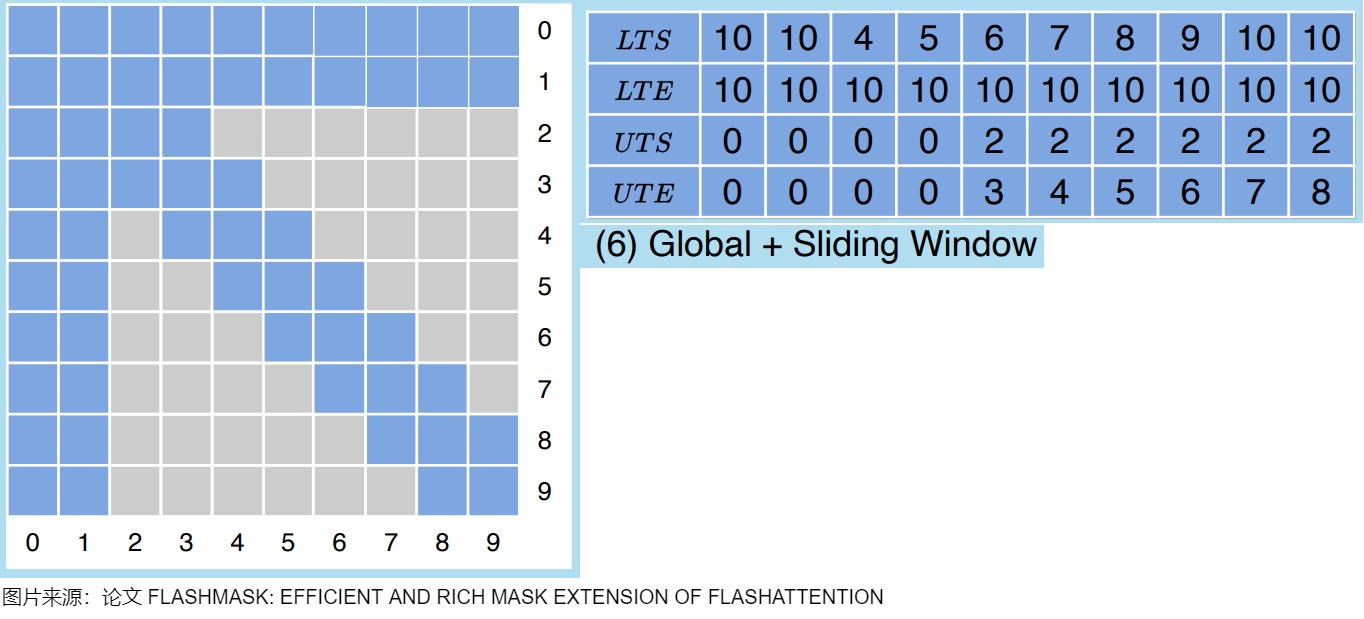
熟悉稀疏矩阵的朋友都知道,表示稀疏矩阵通常用几个一维数组或向量就可以表示,无需用二维tensor,这也是稀疏化的重要收益来源。同理,FlashMask 也是相同的思想,用4个向量表示k矩阵每一个token在左下角和右上角对应的哪些q token被mask了。FlashMask把mask分为两个区域,一个左下角,一个右上角,LT开头的描述左下角的masked情况,UT表示右上角的masked情况,拿(6)举例如下,q有10个token,k也有10个token,针对每个k维度的token,我们来计算对应q维度token的masked情况,比如对于5号token,灰色部分有下图红圈部分,所以[LTS,LTE)=[7,10),[UTS,UTE)=[2,4)。
3.3 算法
FlashMask 将列式掩码表示方法集成到 FlashAttention-2算法中,增强了其对注意力掩码的支持能力。在 FlashAttention Kernel 的分块计算基础上,FlashMask 利用上述的 LTS 等掩码向量,来判断当前分块的掩码类型:
- 完全掩码块:此类块的所有元素均被掩码,计算时可直接跳过。
- 部分掩码块:此类块仅部分元素被掩码,因此需要对该块进行逐元素的掩码处理。
- 未掩码块:此类块中的所有元素均未被掩码,可以简化计算过程,无需额外的掩码操作。
通过这种分类处理,FlashMask 显著提升了计算效率,如下图所示。
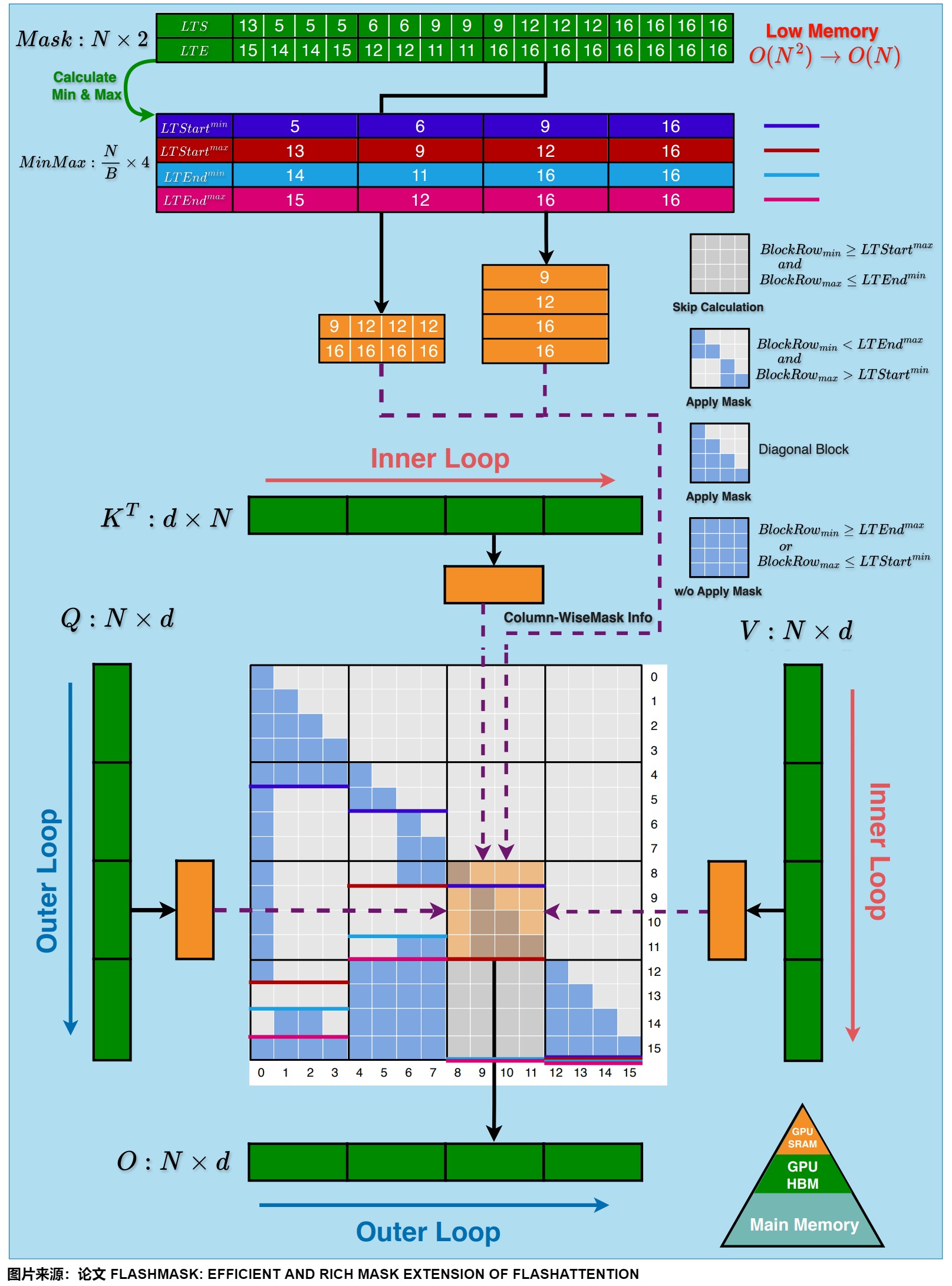
下图的算法详细描述了 FlashMask 扩展 FlashAttention-2的前向计算过程,其中浅蓝色阴影部分表示 FlashMask 新增的计算步骤。

0x04 FlashAttention-3
FlashAttention作者又推出了V3,其特点是:
- 更高效的 GPU 利用率。针对H100 GPU 推出了WGMMA(翘曲矩阵乘法累加)功能,比A100吞吐量高3倍。针对H100 GPU 的TMA(张量记忆加速器)功能,可加速全局内存和共享内存之间的数据传输,负责所有索引计算和越界预测。这样可以释放寄存器,增加图块大小和效率的宝贵资源。
- 以更低的精度获得更好的性能。FlashAttention-3 可以在保持精度的同时处理较低精度的数字 (FP8),具体而言,FlashAttention-3 利用QuIP: 2-Bit Quantization of Large Language Models With Guarantees技术,通过非相干处理减少量化误差,即将查询和键与随机正交矩阵相乘,以"分散"异常值并减少量化误差。
- 能够在 LLM 中使用更长的上下文。通过加速注意力机制,FlashAttention-3 使 AI 模型能够更有效地处理更长的文本片段。这可以使应用程序能够理解和生成更长、更复杂的内容,而不会减慢速度。
因为其主要是和硬件相关,我们不做深入介绍,有兴趣的读者可以自行深入研究。
0xFF 参考
(Beta) Implementing High-Performance Transformers with Scaled Dot Product Attention (SDPA)
大模型训练 FlashAttention v1、v2 - 最清晰的公式推导 && 算法讲解 Alan小分享
[1805.02867 Online normalizer calculation for softmax (arxiv.org)](https://arxiv.org/abs/1805.02867) Maxim Milakov and Natalia Gimelshein. Online normalizer calculation for softmax. CoRR, abs/1805.02867, 2018.
Attention优化2w字🔥原理&图解: 从Online-Softmax到FlashAttention V1/V2/V3 DefTruth
Attention优化万字🔥TensorRT 9.2 MHA/Myelin Optimize vs FlashAttention-2 profile DefTruth
FlashAttention2w字🔥原理&图解: 从Online-Softmax到FlashAttention-1/2/FlashDecoding/FlashDecoding++ DefTruth
Antinomi:FlashAttention核心逻辑以及V1 V2差异总结
Flash Attention on INTEL GPU 毛毛雨
Flash Attention V2 的 Triton 官方示例学习forward 来自L77星云
flash attention论文及源码学习 KIDGINBROOK
FlashAttention v2论文温故 进击的Killua
FlashAttention-3: Fast and Accurate Attention with Asynchrony and Low-precision
FlashAttention:加速计算,节省显存, IO感知的精确注意力 回旋托马斯x
FlashAttention图解(如何加速Attention) Austin
FlashAttention核心逻辑以及V1 V2差异总结 Antinomi
From Online Softmax to FlashAttention by Zihao Ye
From Online Softmax to FlashAttention
LLM 推理加速技术------ Flash Attention 的算子融合方法 sudit
NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能 紫气东来
ops(7):self-attention 的 CUDA 实现及优化 (上) 紫气东来
ops(8):self-attention 的 CUDA 实现及优化 (下) 紫气东来
Scaled Dot Product Attention (SDPA) 在 CPU 上的 性能优化 Mingfei
【手撕LLM-FlashAttention2】只因For循环优化的太美 小冬瓜AIGC
【手撕LLM-FlashAttention】从softmax说起,保姆级超长文!! 小冬瓜AIGC
一心二用的Online Softmax TaurusMoon
万字长文详解FlashAttention v1/v2 Civ
万字长文详解FlashAttention v1/v2 Civ
使用cutlass cute复现flash attention 66RING
回旋托马斯x:FlashAttention:加速计算,节省显存, IO感知的精确注意力
图解大模型计算加速系列:Flash Attention V2,从原理到并行计算 猛猿
图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑 猛猿
大模型训练加速之FlashAttention系列:爆款工作背后的产品观 方佳瑞
学习Flash Attention和Flash Decoding的一些思考与疑惑 稻壳特溯
序列并行DeepSpeed-FPDT 手抓饼熊 大模型新视界(javascript:void(0)😉
我的 Transformer 加速笔记(一):FlashAttention 篇 delin
手撕Flash Attention!原理解析及代码实现 晚安汤姆布利多
线性Attention的探索:Attention必须有个Softmax吗? By 苏剑林
细嚼慢咽地学习FlashAttention2-举例子1 迷途小书僮
通透理解FlashAttention与FlashAttention2:让大模型上下文长度突破32K的技术之一 v_JULY_v
降低Transformer复杂度O(N^2)的方法汇总(一) Civ
降低Transformer复杂度O(N^2)的方法汇总(二) Civ
A Case Study in CUDA Kernel Fusion: Implementing FlashAttention-2 on NVIDIA Hopper Architecture using the CUTLASS Library[5](https://zhuanlan.zhihu.com/p/668888063#ref_5)
Andrew Kerr. Gtc 2020: developing cuda kernels to push tensor cores to the absolute limit on nvidia a100. May 2020.
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. https://arxiv.org/abs/2307.08691
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness[2](https://zhuanlan.zhihu.com/p/668888063#ref_2)
FlashMask: Efficient and Rich Mask Extension of FlashAttention. https://arxiv.org/abs/2410.01359
FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention. https://pytorch.org/blog/flexattention/
From Online Softmax to FlashAttention(@http://cs.washington.edu)
From Online Softmax to FlashAttention. https://courses.cs.washington.edu/courses/cse599m/23sp/notes/flashattn.pdf
Maxim Milakov and Natalia Gimelshein. Online normalizer calculation for softmax. CoRR, abs/1805.02867, 2018.
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.[6](https://zhuanlan.zhihu.com/p/668888063#ref_6)
Self-attention Does Not Need O(n^2) Memory. https://arxiv.org/abs/2112.05682
The I/O Complexity of Attention, or How Optimal is Flash Attention?[4](https://zhuanlan.zhihu.com/p/668888063#ref_4)
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: fast and memory- efficient exact attention with io-awareness. CoRR, abs/2205.14135, 2022.
晚安汤姆布利多](https://www.zhihu.com/people/Rancho2508)
从Coding视角出发推导Ring Attention和FlashAttentionV2前向过程 杨鹏程
结合代码聊聊FlashAttentionV3前向过程的原理 杨鹏程
聊聊CUDA编程中线程划分和数据分块 之 PagedAttention(V1/V2)分析 杨鹏程
DefTruth:[Attention优化📚FFPA(Split-D): FA2无限HeadDim扩展,2x↑🎉 vs SDPA EA](https://zhuanlan.zhihu.com/p/13975660308)