(一)克隆前的准备
1. 用 xftp 发送文件

2. 时间同步:
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3. zookpeeper 安装 部署
呼应开头发送的压缩包,解压:
cd ~
tar -zxvf zookeeper-3.4.6.tar.gz 
4. 配置环境变量:
export ZOOKEEPER_HOME=/home/hadoop/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH 


5. zoo.cfg 配置文件:
养成习惯,要先按 i 进入插入模式再粘贴哦
cd ~/zookeeper-3.4.6/conf
vim zoo.cfg
initLimit=10
syncLimit=5
#此处为数据保存目录,需自行创建
dataDir=/home/hadoop/zkdata
#此处为日志保存目录,需自行创建
dataLogDir=/home/hadoop/zklog
clientPort=2181
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
mkdir /home/hadoop/zkdata
mkdir /home/hadoop/zklog 
(二)克隆Linux虚拟机
记得先关机哈
然后请看六字明了

注意几个地方:
完整克隆,名称和安装位置:


结果要看到3个:master,salve1,salve2,最上面是我的别管。

然后,启动启动启动,
(三)克隆虚拟机后配置
1. 修改 salve1 salve2 的ip,根据自己情况修改

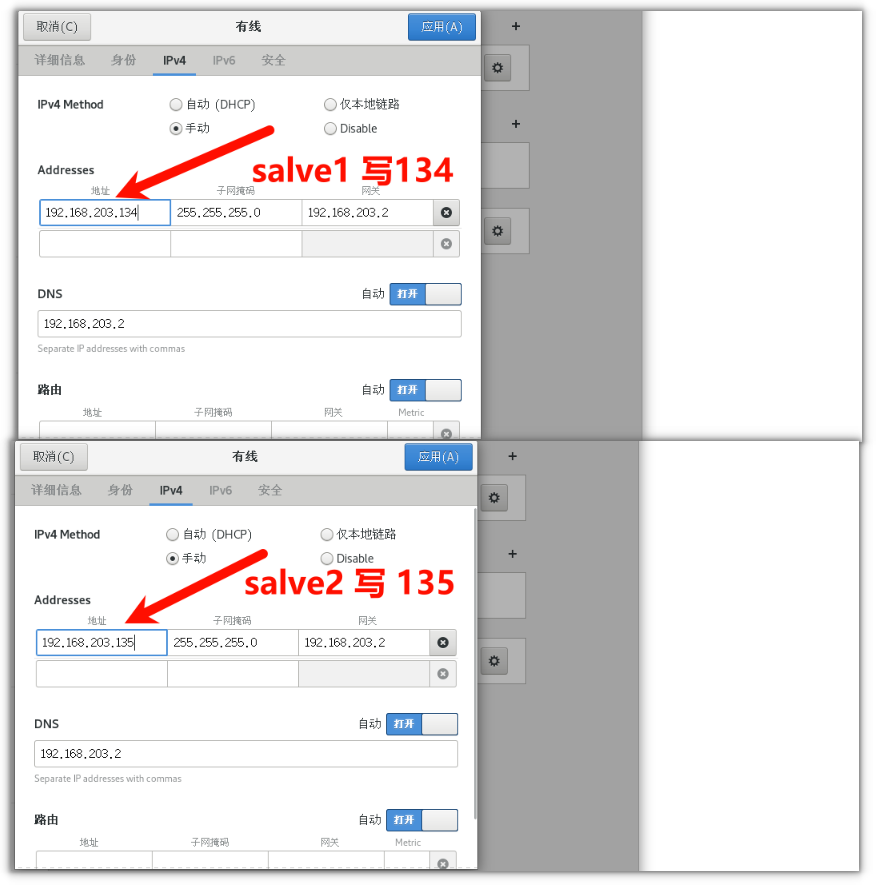
2. 修改主机名
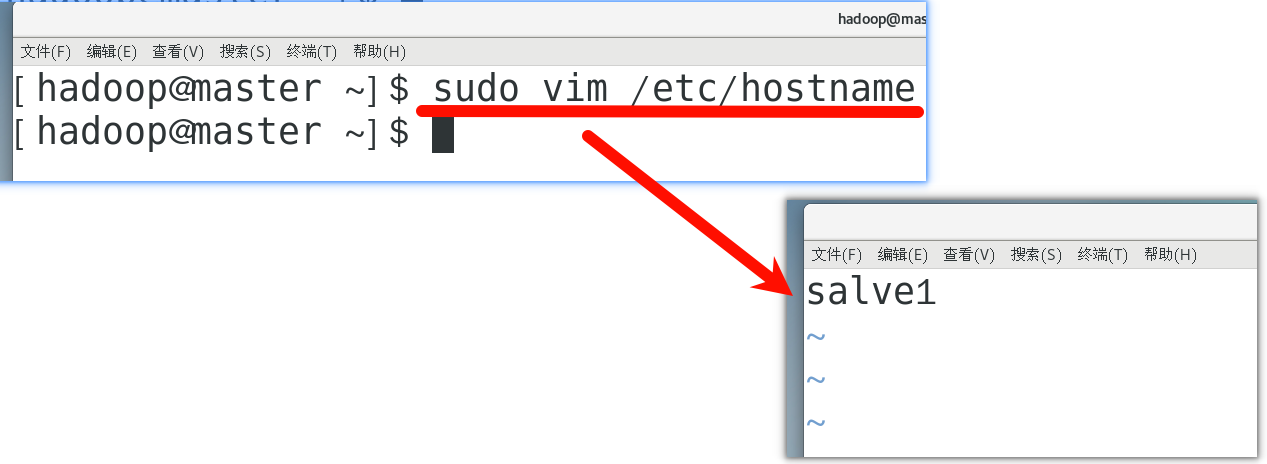

重复上述步骤,也把slave2的主机名修改为slave2
3. 为三台机器配置hosts文件
在末尾添加两行
192.168.203.XXX slave1
192.168.203.XXX slave2 
ip地址要对应上一步你自己为每一台主机设置的ip地址
重复上述步骤,把三个机子都配好。
(四)为 master 主机配置NTP服务器,用于时钟同步
1. 配置NTP服务器
是master主机哦
sudo vim /etc/ntp.conf 
:set nu 显示行号
2. 启动 NTF 服务
systemctl start ntpd 3. 自动开启 NTP 服务
chkconfig ntpd on 4. 在其他节点配置定时同步时间
在slave1、slave2都使用**crontab -e**命令打开vim编辑器编辑定时命令脚本,
在其中添加此行命令:
crontab -e
0-59/10 * * * * sudo /usr/sbin/ntpdate master 作用:slave1、slave2将定期每10分钟自动与master主机同步时间
5. 创建Zookeeper各节点服务编号
在master上:
cd /home/hadoop/zkdata
touch myid
echo 1 > myid 在salve1上:
cd /home/hadoop/zkdata
touch myid
echo 2 > myid 在salve2上:
cd /home/hadoop/zkdata
touch myid
echo 3 > myid (五)启动Zookeeper集群
在每一台机器上,分别执行以下命令启动Zookeeper服务:
zkServer.sh startjps 可以查看进程

zkServer.sh status 

会出现 follower 和 leader