一、对话效果演示
ESP32与豆包大模型的RTC连续对话
二、ESP-ADF 介绍
乐鑫 ESP-ADF(Espressif Audio Development Framework)是乐鑫科技(Espressif Systems)专为 ESP32 系列芯片开发的一款音频开发框架。它旨在简化基于 ESP32 芯片的音频应用的开发,提供丰富的音频功能和工具,帮助开发者快速构建高质量的音频产品。
1、主要特点
1.1、跨平台支持
ESP-ADF 支持多种操作系统,包括 FreeRTOS 和 Linux,适用于不同的开发环境。
1.2、丰富的音频功能
- 支持多种音频格式(如 MP3、AAC、WAV、FLAC、OPUS 等)的解码和编码。
- 提供音频流处理功能,支持网络流媒体(如 HTTP、HLS、RTSP)和本地文件播放。
- 支持音频效果处理,如均衡器、混音、回声消除等。
1.3、模块化设计
ESP-ADF 采用模块化设计,开发者可以根据需求灵活选择功能模块,降低开发复杂度。
1.4、易于集成
提供丰富的 API 和示例代码,方便开发者快速上手并集成到现有项目中。
1.5、支持多种外设
- 支持 I2S、PWM、DAC 等音频接口。
- 兼容多种麦克风、扬声器和音频编解码器。
1.6、低功耗设计
针对 ESP32 的低功耗特性优化,适合电池供电的音频设备。
2、主要组件
2.1、音频管道(Audio Pipeline)
提供音频数据流的处理框架,支持多路音频流的混合和处理。
2.2、音频编解码器(Codec)
支持多种音频格式的编解码,方便处理不同来源的音频数据。
2.3、音频流(Stream)
支持从网络、本地文件或外设获取音频数据。
2.4、音频效果(Effect)
提供音频效果处理功能,如均衡器、混音、回声消除等。
2.5、音频服务(Service)
提供高级音频服务,如语音助手集成、语音识别等。
3、应用场景
ESP-ADF 适用于多种音频应用场景,包括:
- 智能音箱和语音助手
- 网络音频播放器
- 蓝牙音频设备
- 录音设备
- 语音识别和语音控制设备
三、安装 ESP-ADF 框架
Step1、克隆仓库源码
# git clone --recursive https://github.com/espressif/esp-adf.git
git clone --recursive https://gitee.com/EspressifSystems/esp-adf.git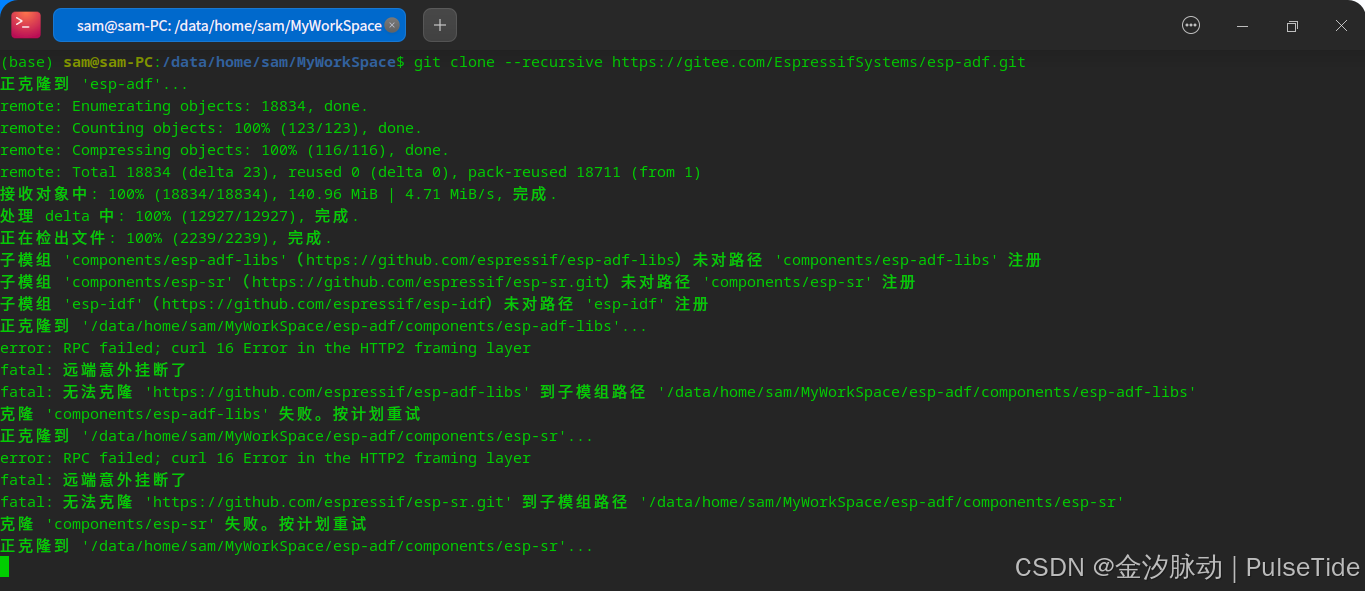
执行"recursive"更新失败,是因为 github 网络问题,此时需要使用工具仓库 esp-gitee-tools,可以参照 Linux下ESP32开发环境搭建:新手也能轻松上手_esp32 linux环境搭建-CSDN博客,
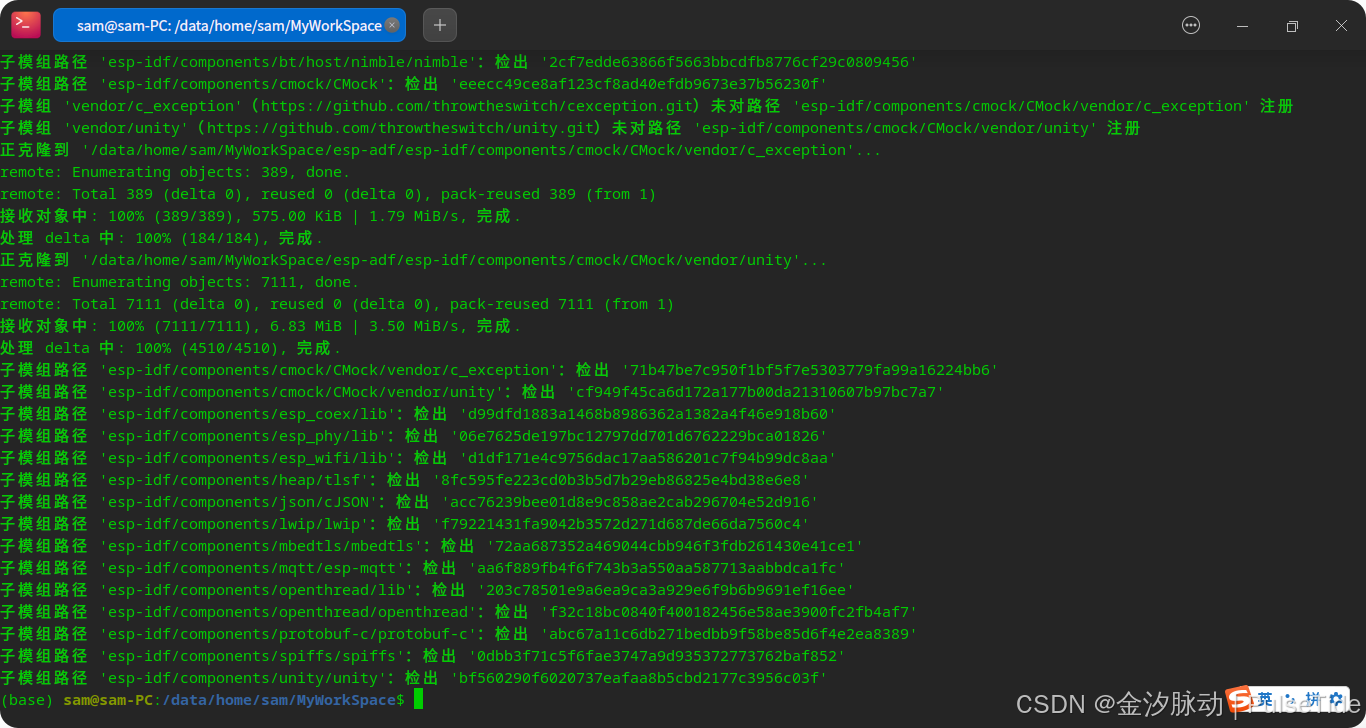
Step2、配置 ESP-IDF 与 ESP-ADF
cd esp-adf
./install.sh
. ./export.sh
如果在安装时,又遇到网络问题,可以把下载链接直接复制到其他软件进行下载,然后拷贝到 /home/sam/.espressif/dist/ 这个路径下,重新执行安装脚本,
这样子太麻烦了,实际上官方文档中有解决方案,
export IDF_GITHUB_ASSETS="dl.espressif.cn/github_assets"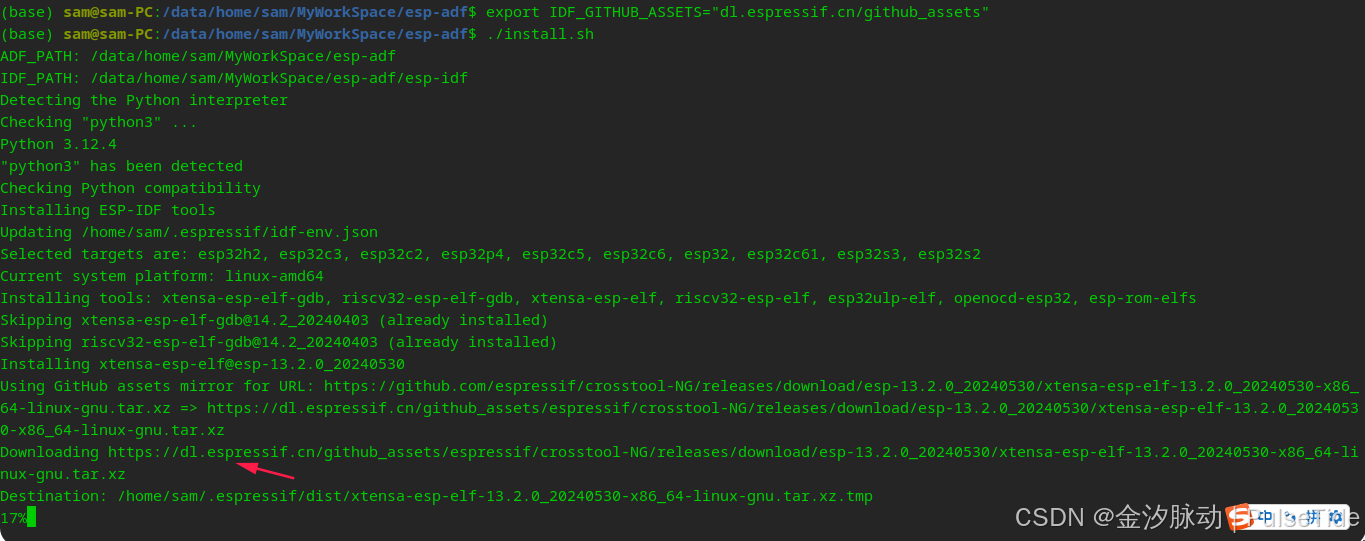
可以看到使用了镜像地址之后下载速度一下子就提升了,

接着配置环境变量,
sudo vim ~/.bashrc
# export ADF_PATH=/data/home/sam/MyWorkSpace/esp-adf
# export IDF_PATH=/data/home/sam/MyWorkSpace/esp-adf/esp-idf
source ~/.bashrc 
. ./export.sh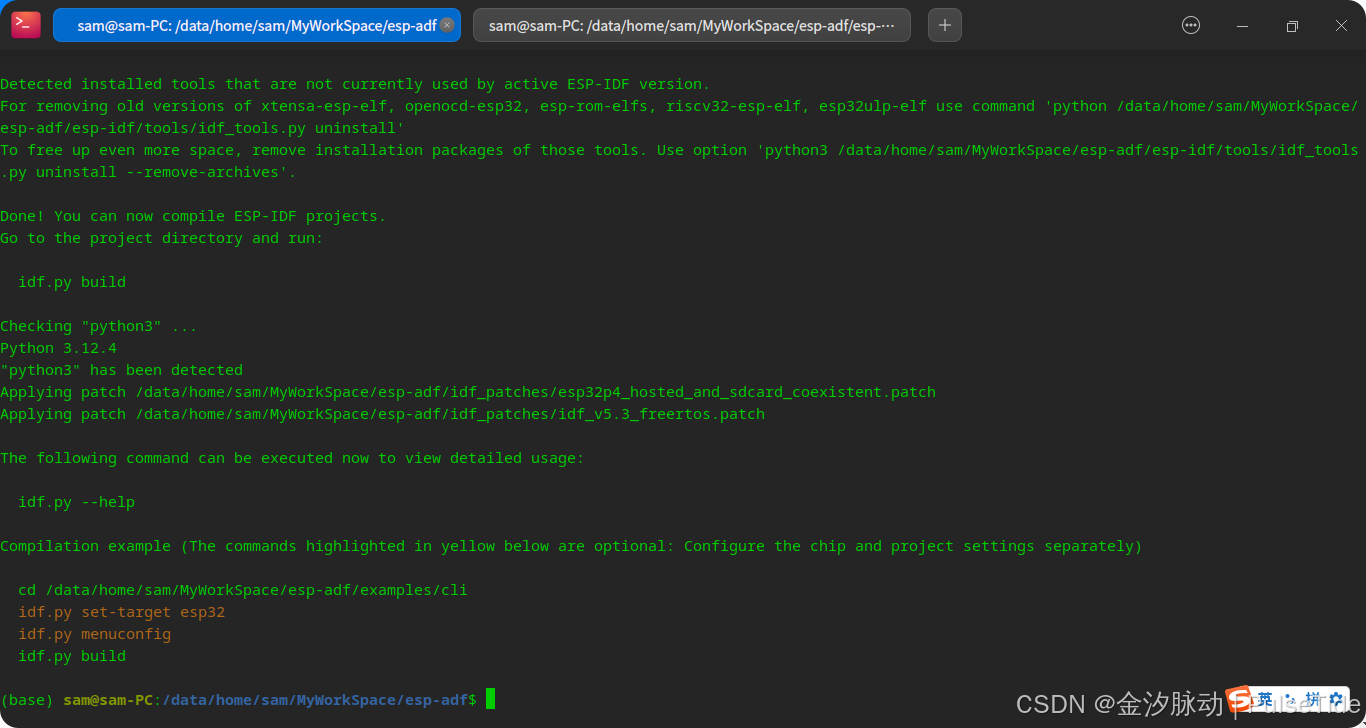
至此,环境搭建完毕。注意,这仅对当前命令窗口有效,如果新开了窗口,则需要重新执行脚本,因此我们可以为脚本导入一个别名,在 .bashrc 文件底部添加:
alias get_adf='. /data/home/sam/MyWorkSpace/esp-adf/export.sh'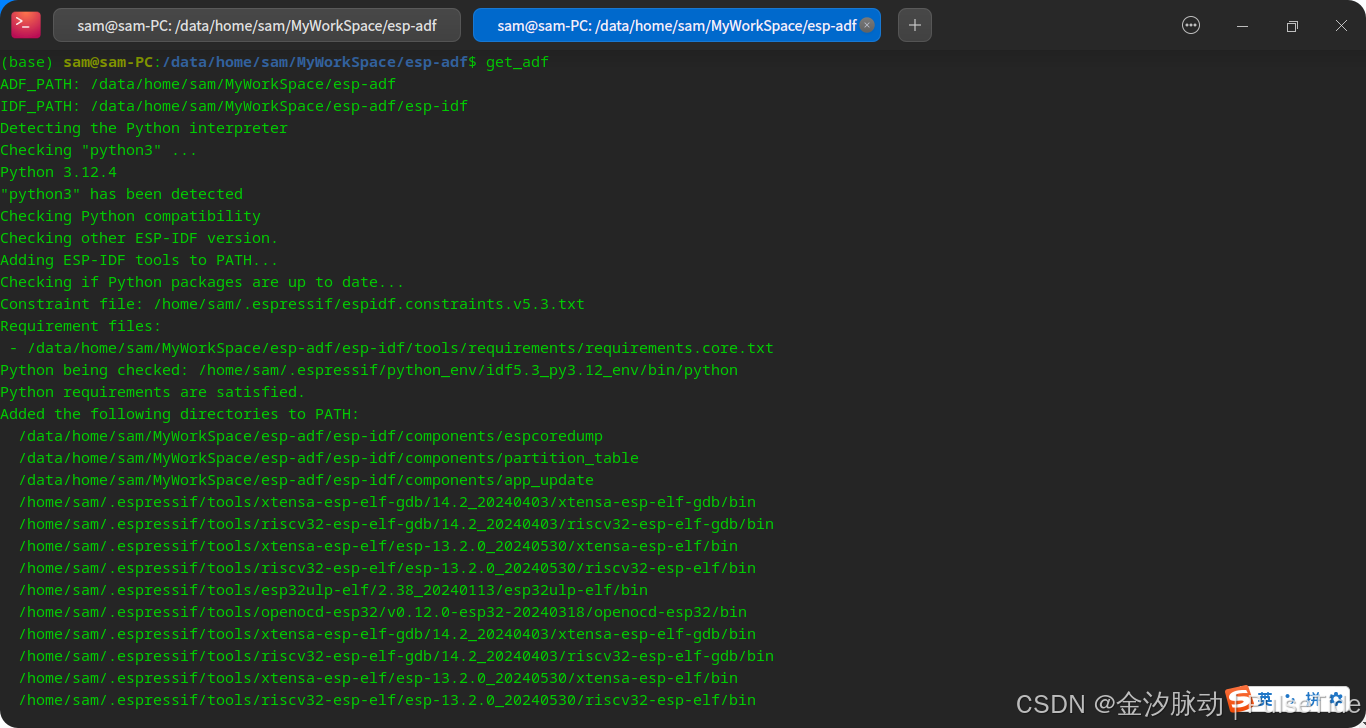
四、烧录 volc_rtc 固件
1、准备工作
使用 vs code 打开 esp-adf 项目,打开路径 examples/ai_agent/volc_rtc ,
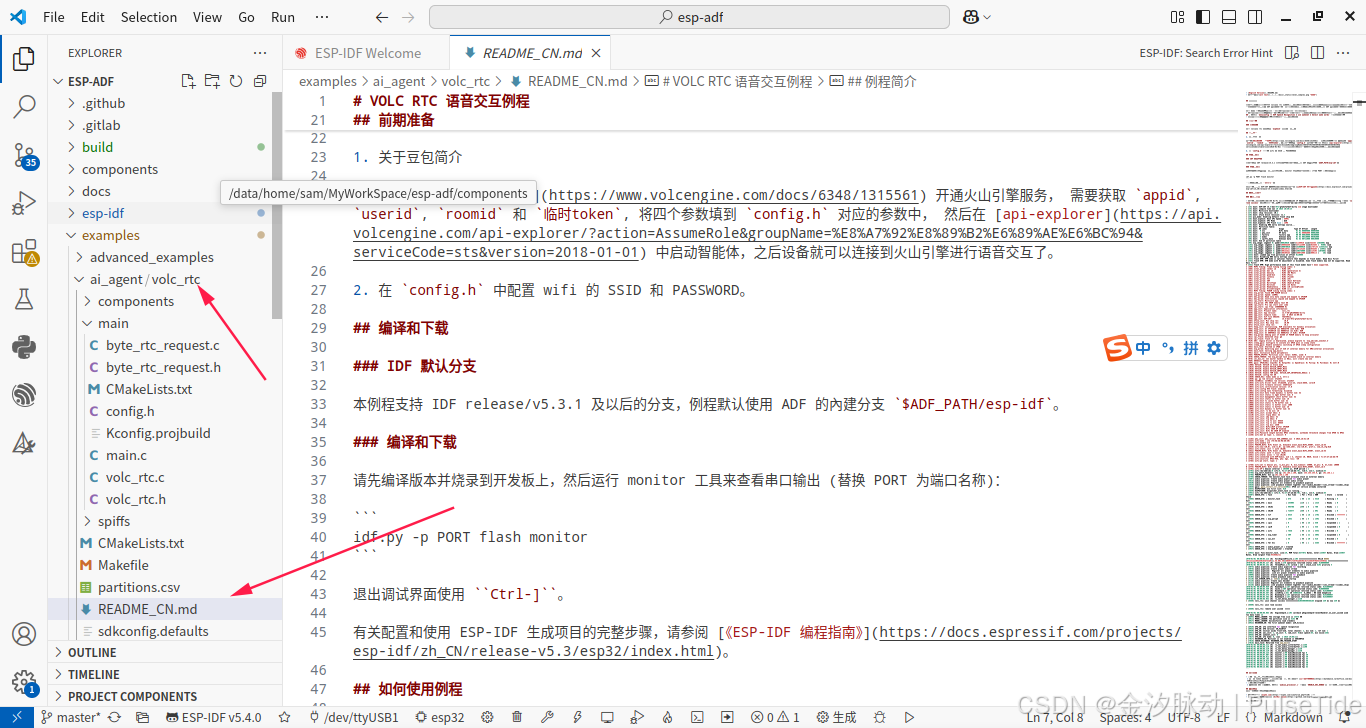
根据 README 文件的指引,需要登录火山引擎申请 token 与配置各个参数。
2、火山引擎配置
2.1、账号注册
登录网址:账号登录-火山引擎
首次注册登录需要实名认证,认证完之后直接搜索"实时音视频",
2.2、开通"实时音视频"服务
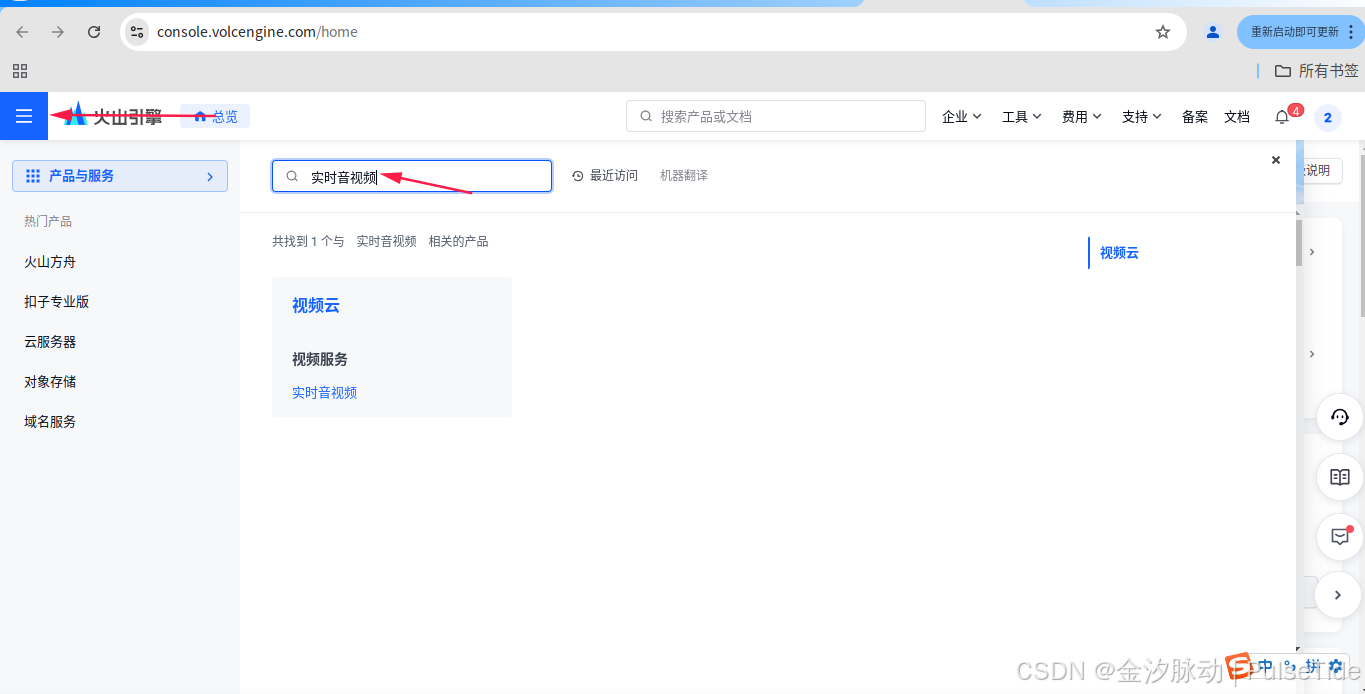
点击"视频服务"的"实时音视频"就会跳转页面,
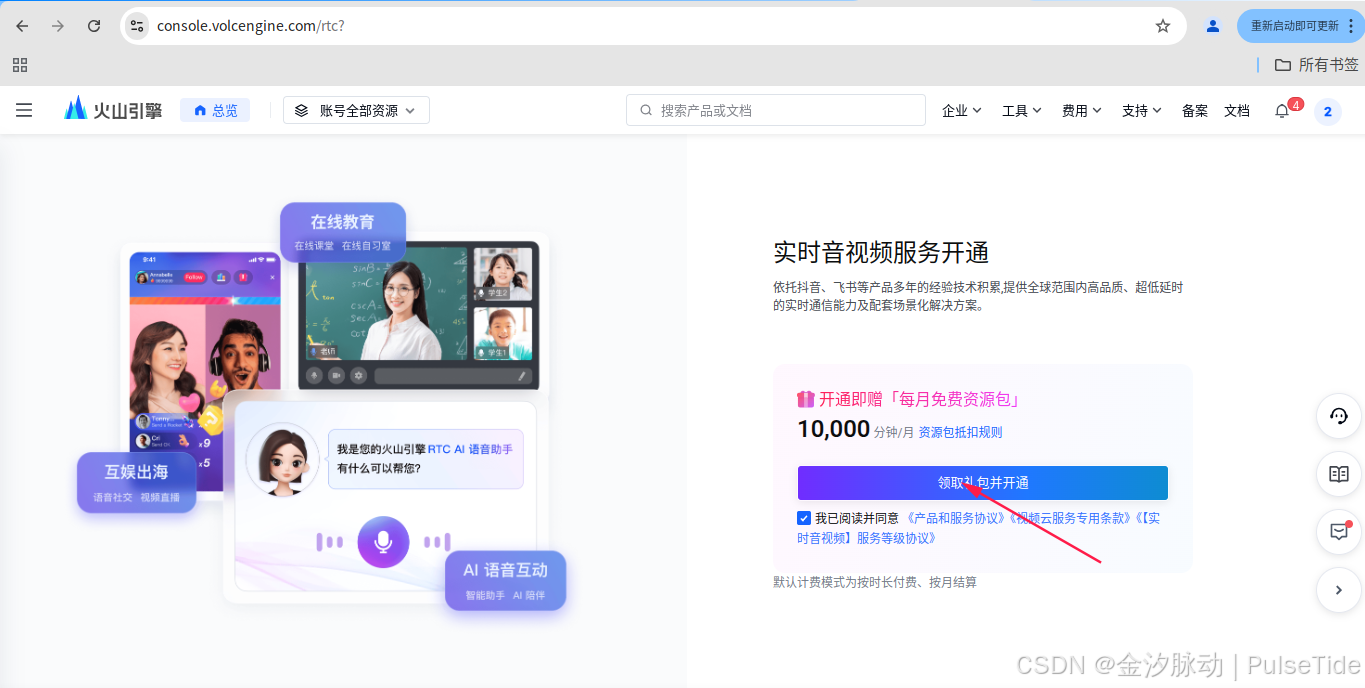
点击"领取礼包并开通",
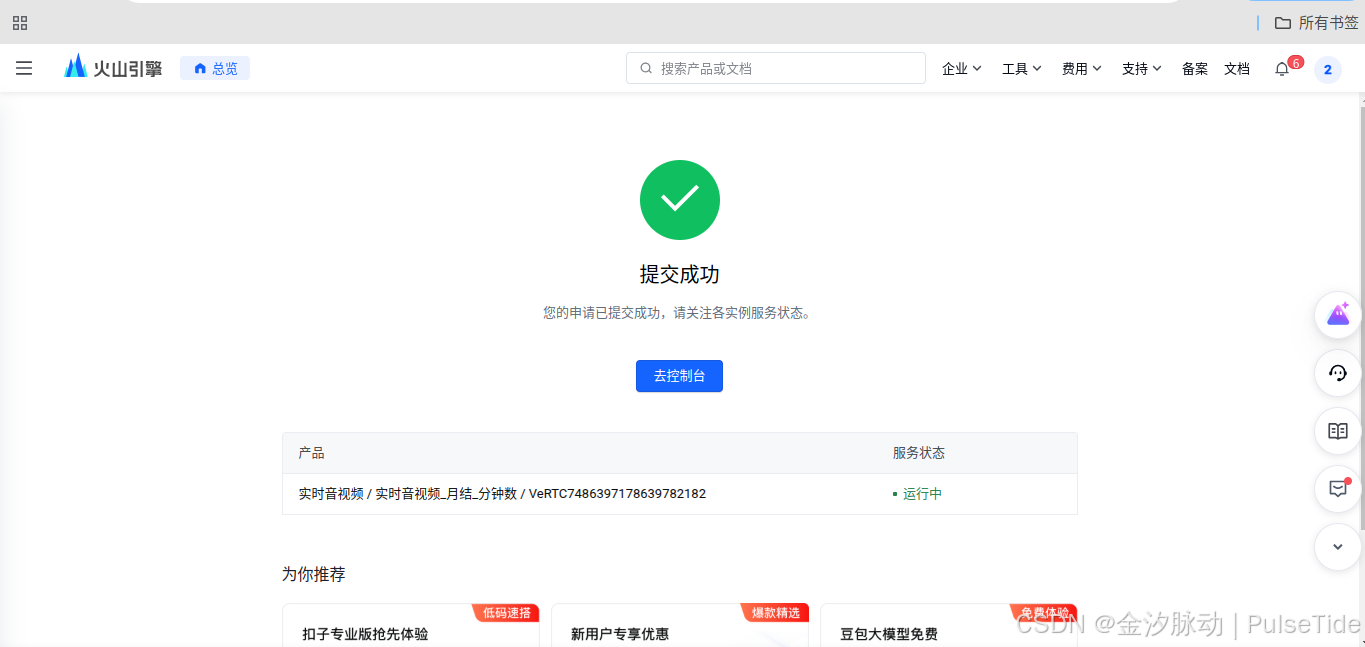
提交成功之后,点击"去控制台",
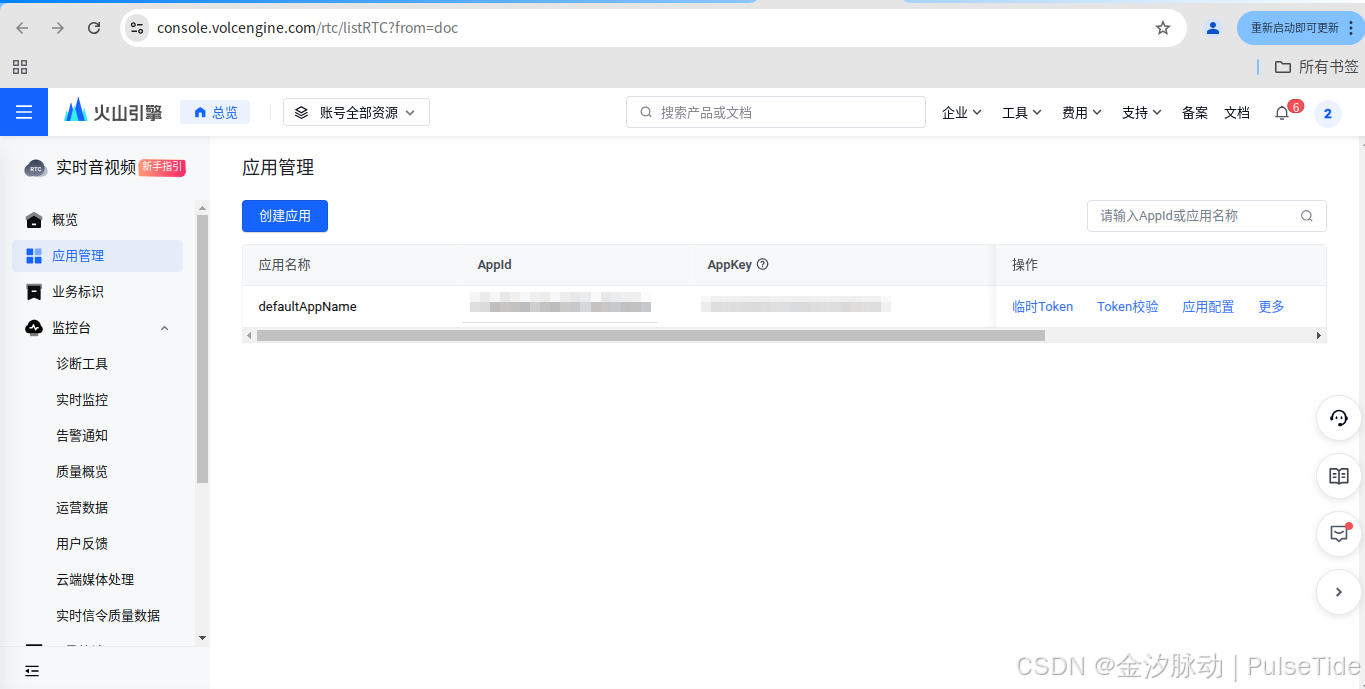
可以看到已经创建了默认应用,直接点击"临时token",
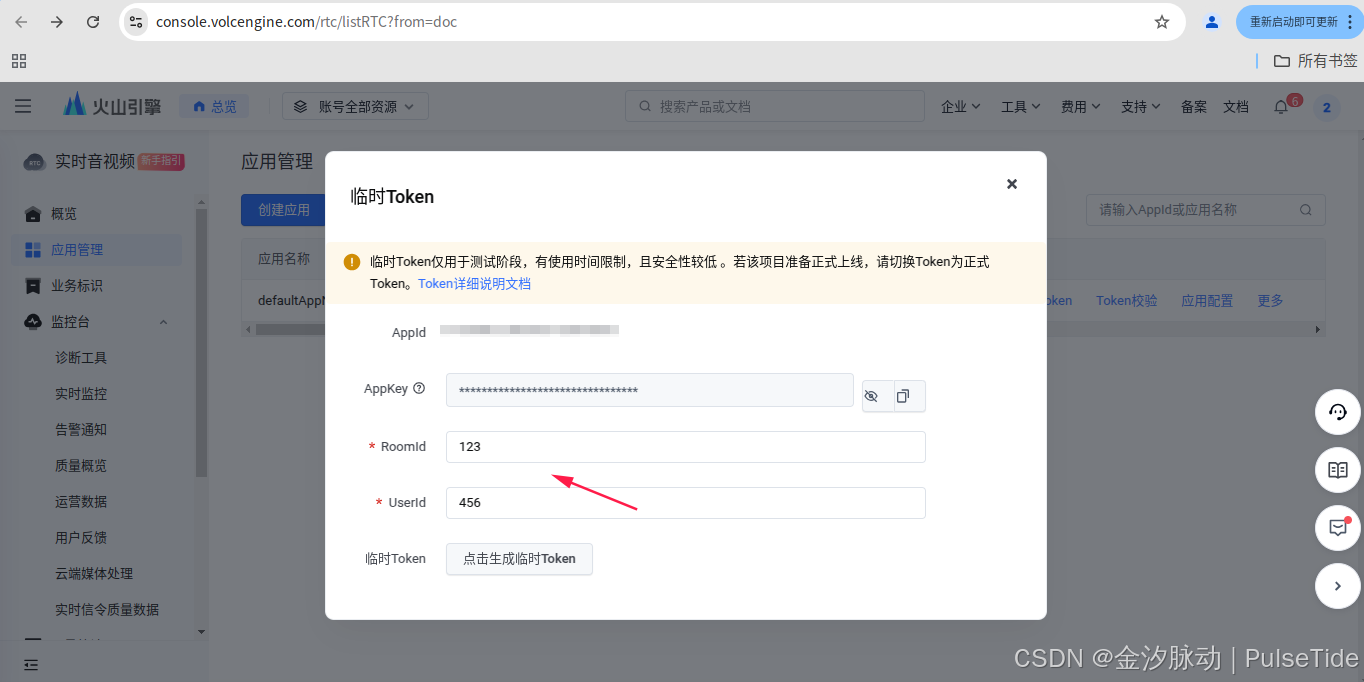
RoomId 与 UserId 随便填就可以,然后生成临时 Token,
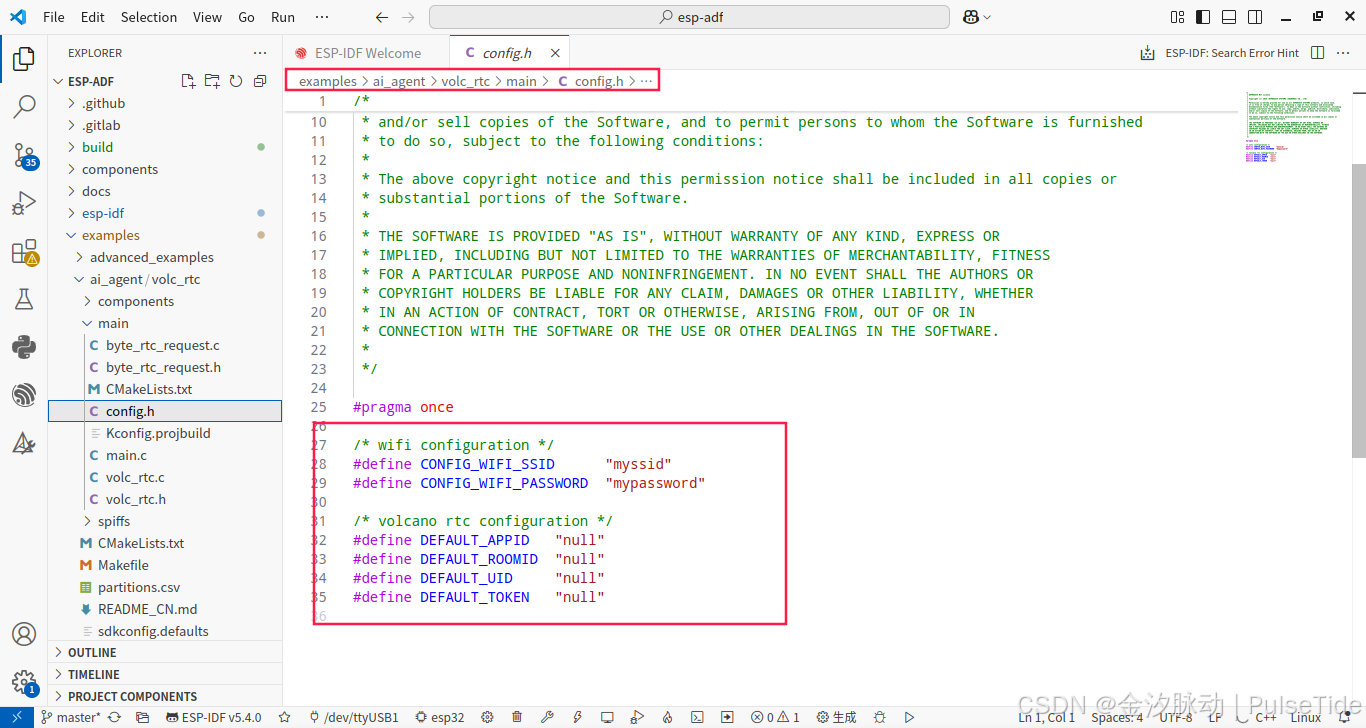
把参数全部配置到 examples/ai_agent/volc_rtc/main/config.h 文件,还要配置 WIFI 账号密码,不然没法联网。
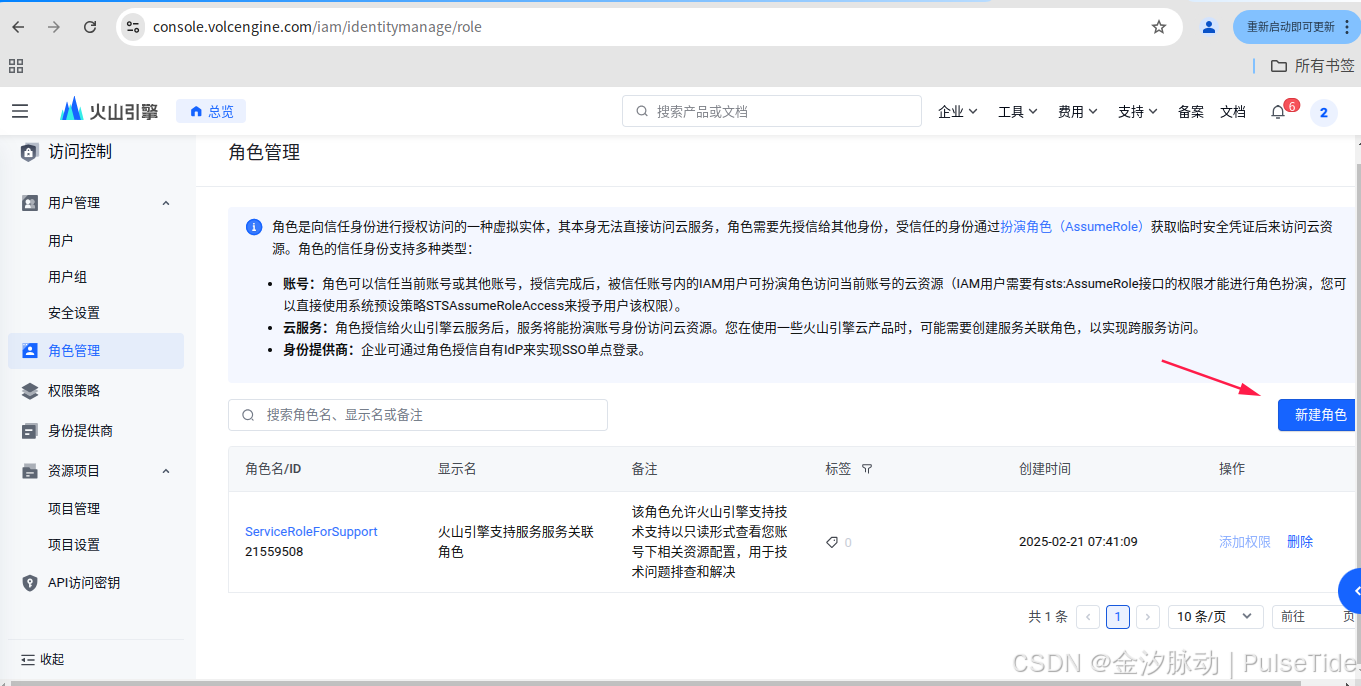
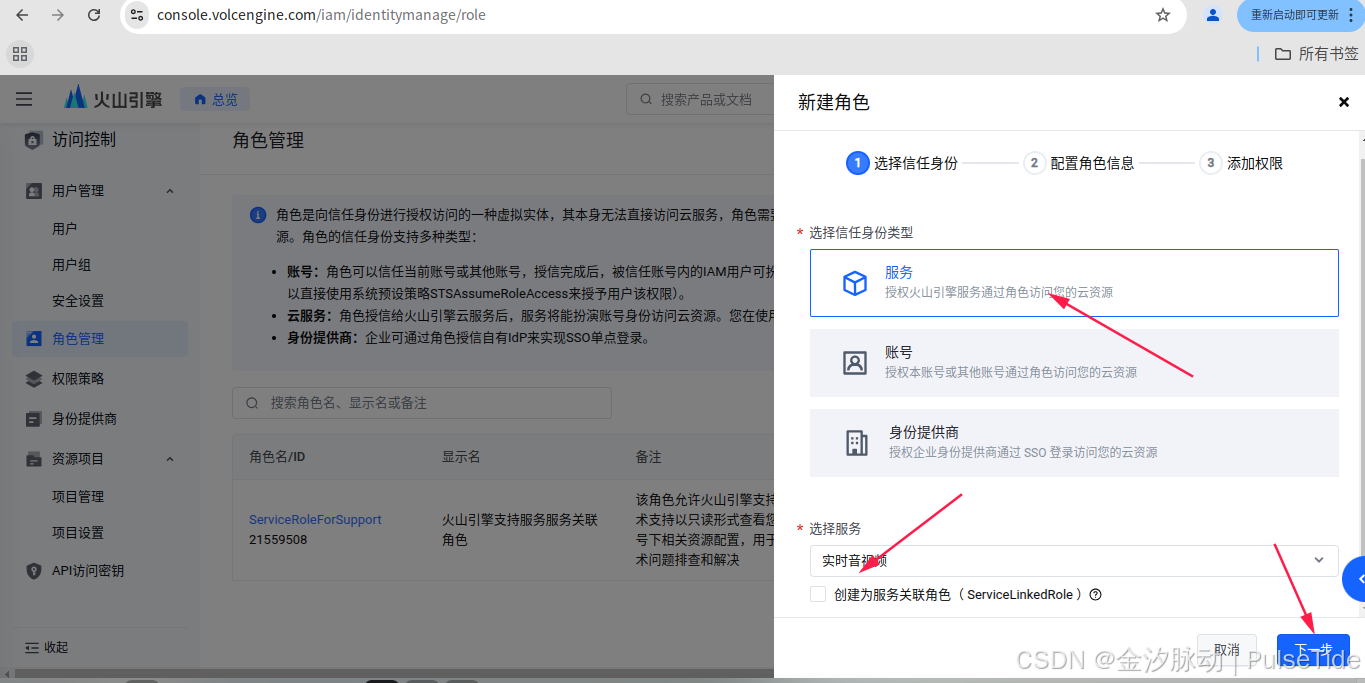
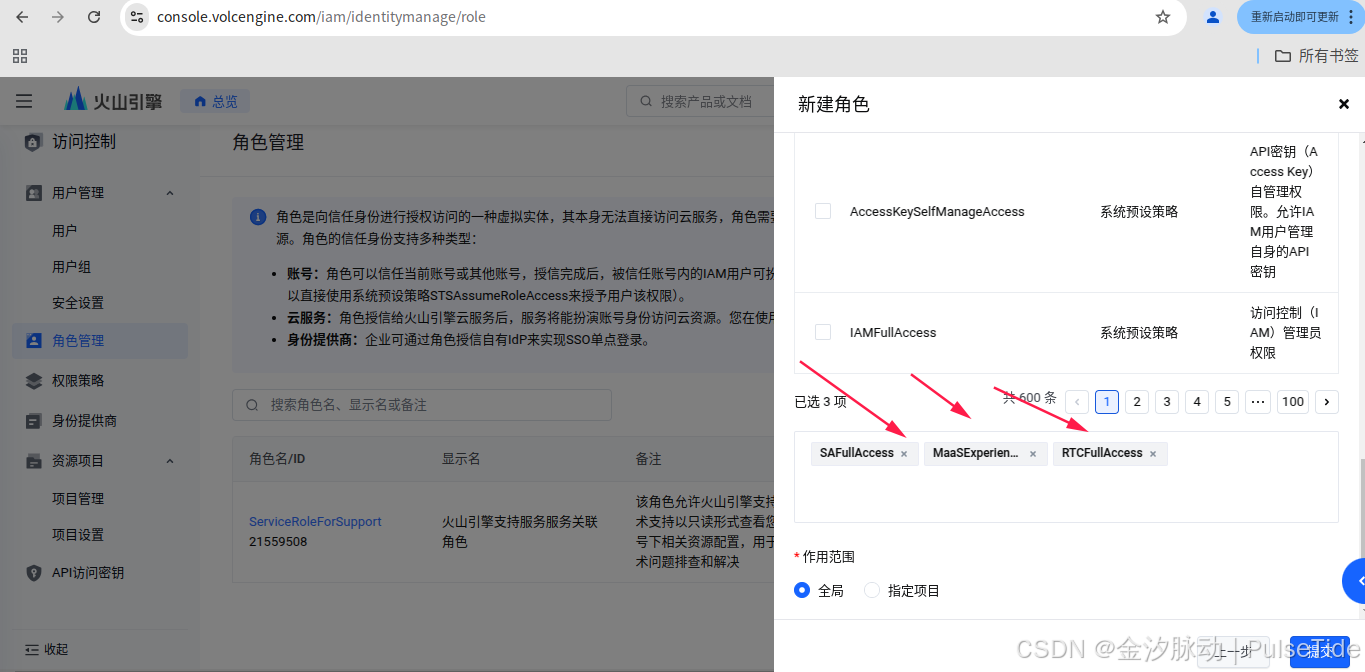
2.3、设置权限
配置"访问控制":账号登录-火山引擎

2.4、智能体 API
智能体配置:API Explorer
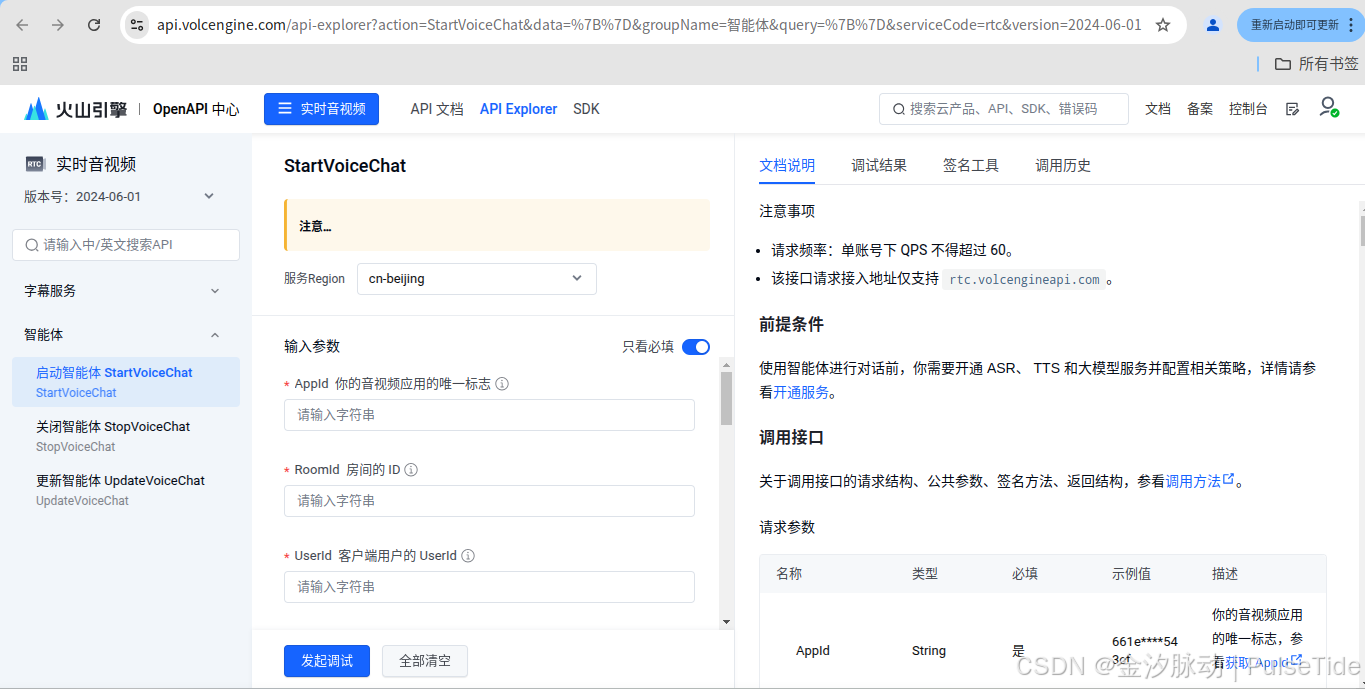
使用智能体进行对话前,你需要开通 ASR、 TTS 和大模型服务并配置相关策略,详情请参看开通服务。
2.5、开通 ASR/TTS 服务
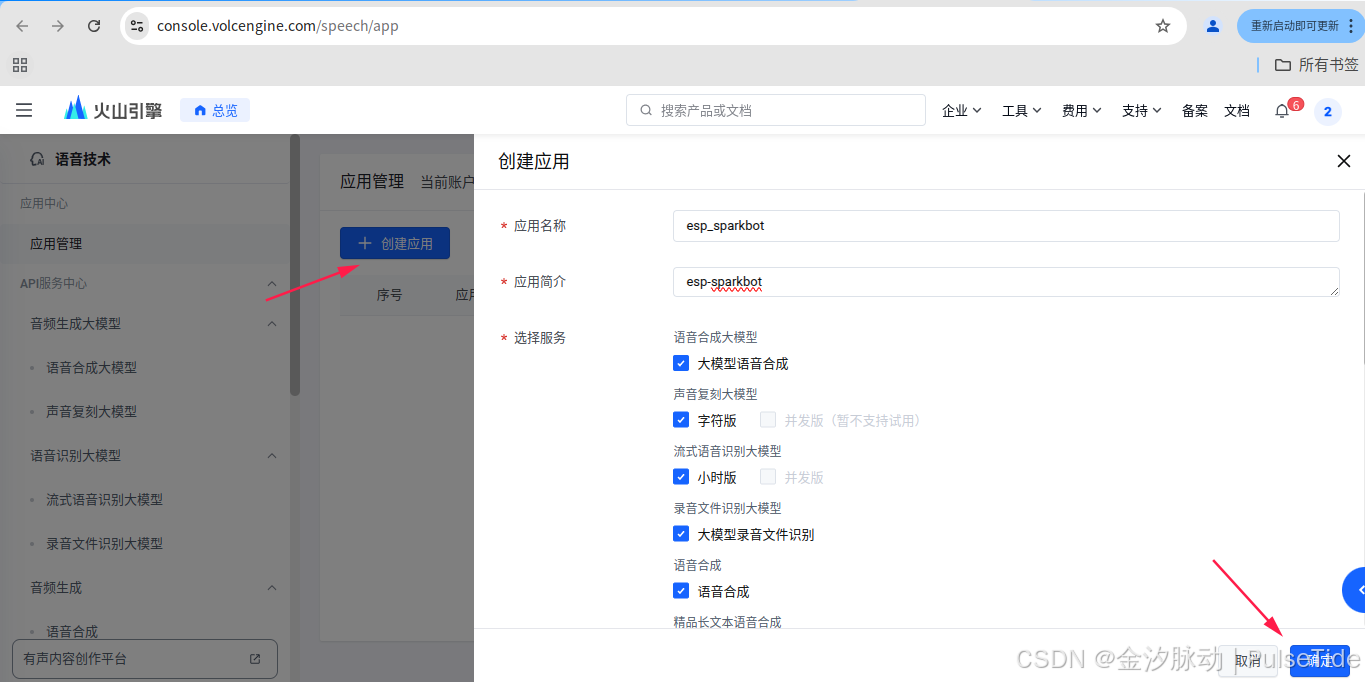
ASR/TTS:账号登录-火山引擎
进入页面后,点击"创建应用",主要选中"大模型语音合成"、"语言合成" 、"流式语音识别",
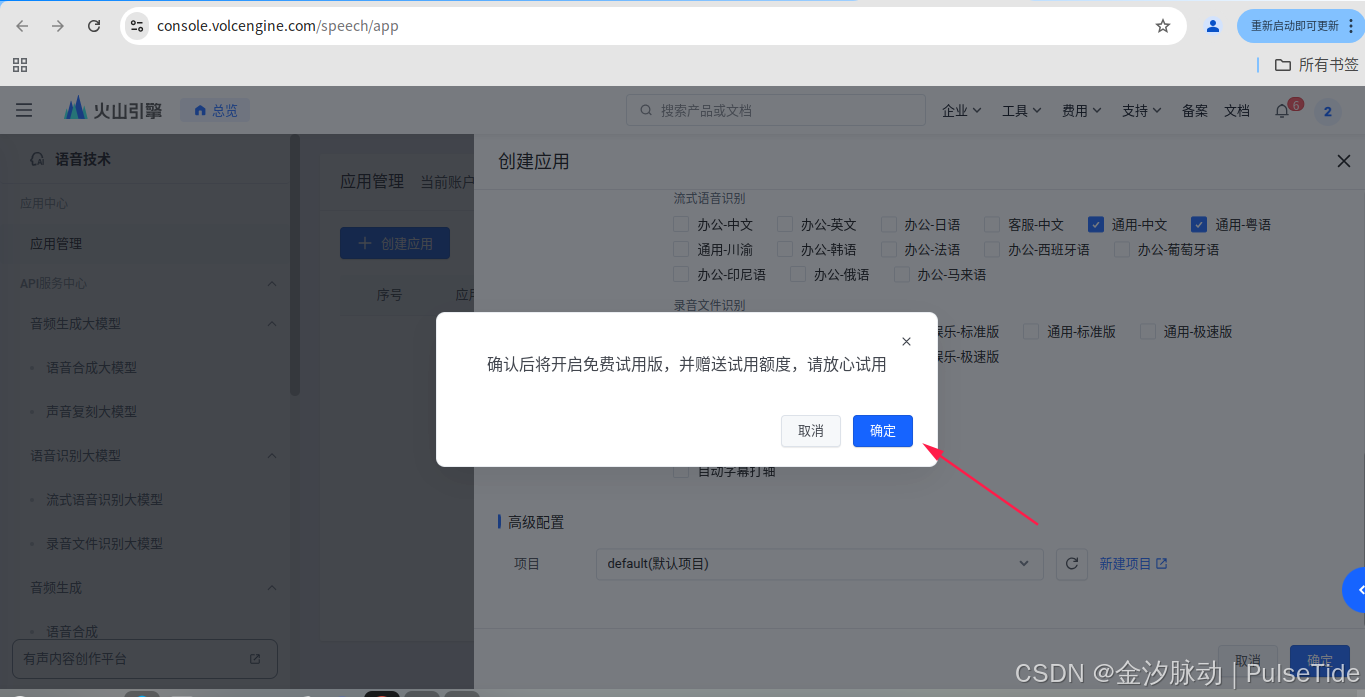
如果需要配置音色,则需要开通服务,这里先用试用版,
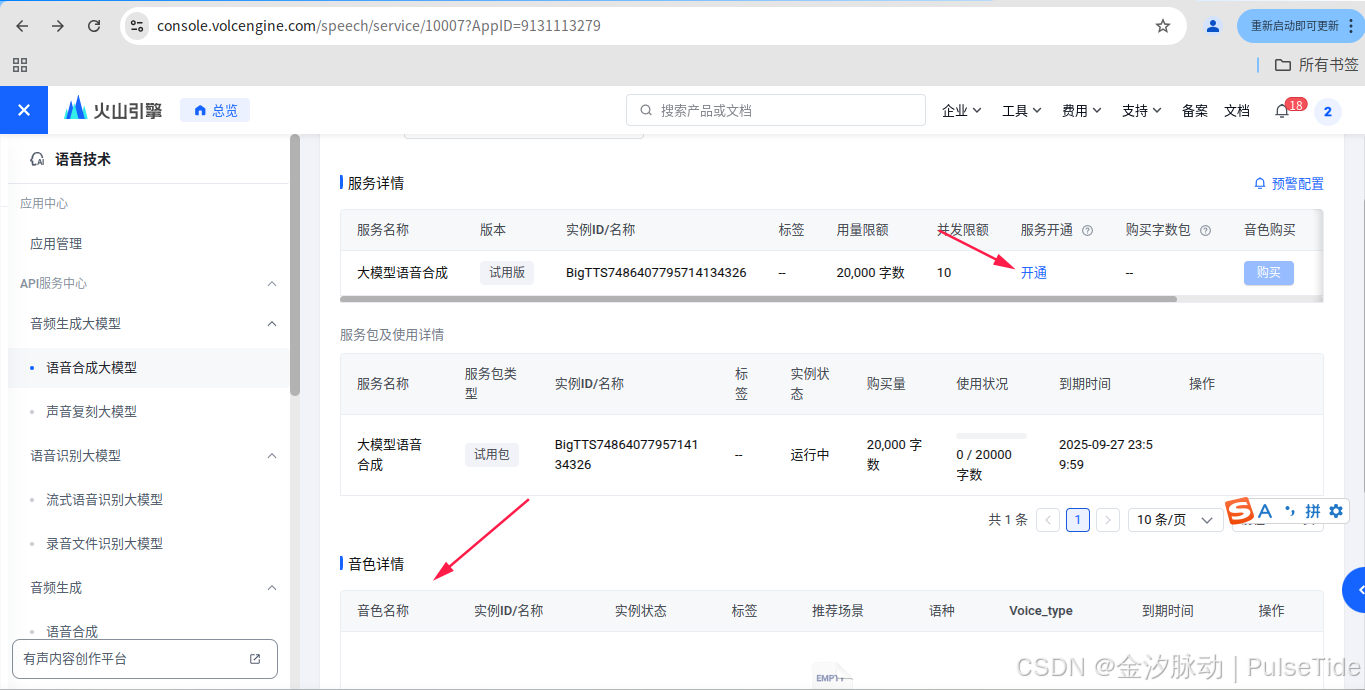
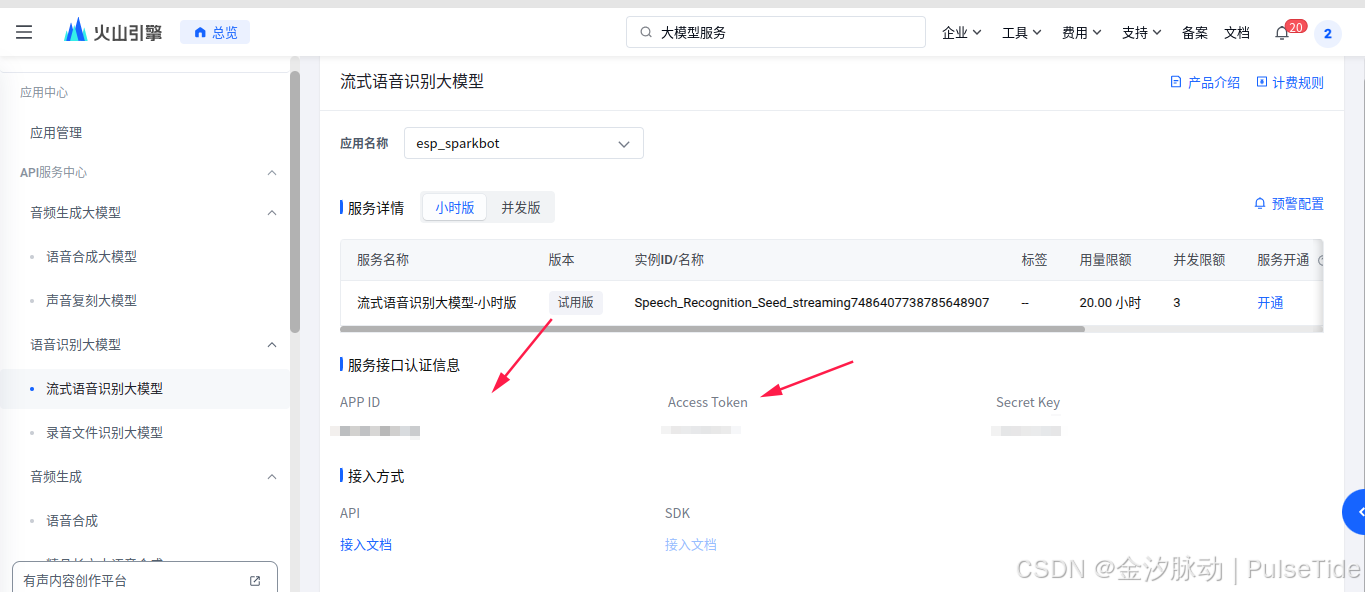
AppId 与 Token 可以在底部查到:
2.6、开通 LLM 服务
大语言模型配置:账号登录-火山引擎
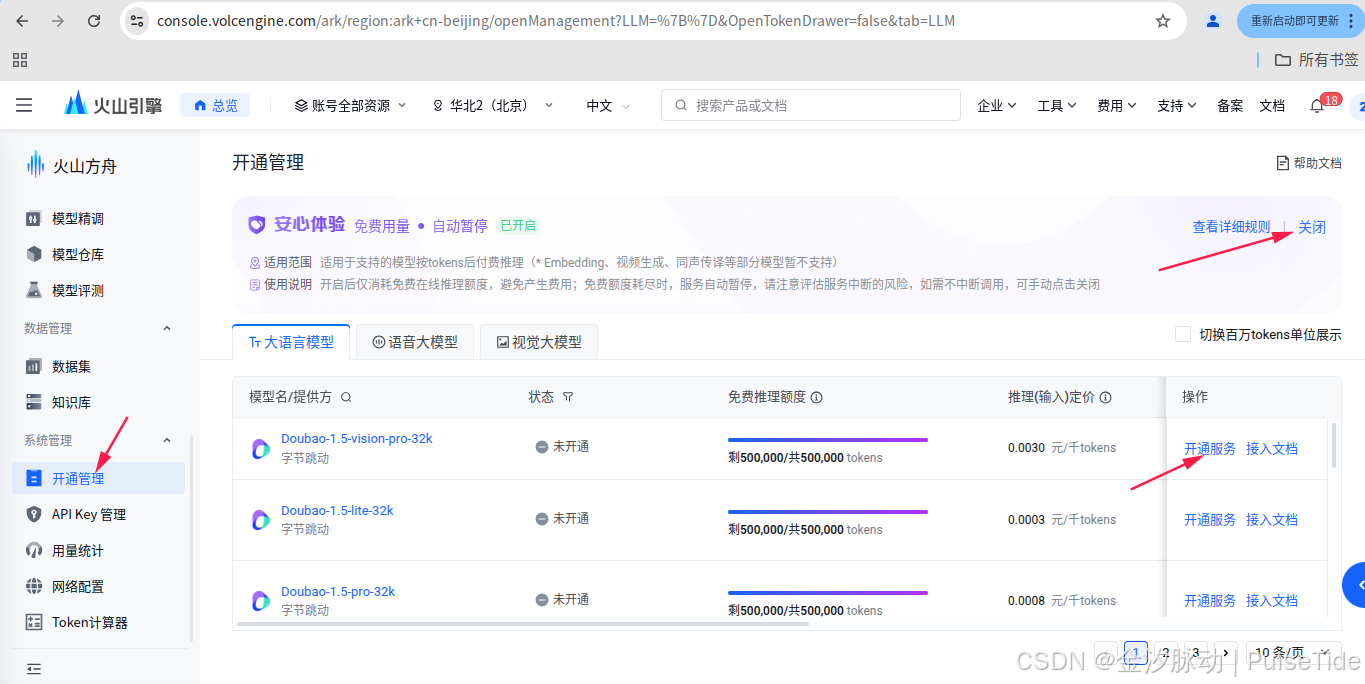
点击"系统管理",注意右上角开启"免费用量 自动暂停",然后选中其中一个模型进行开通。
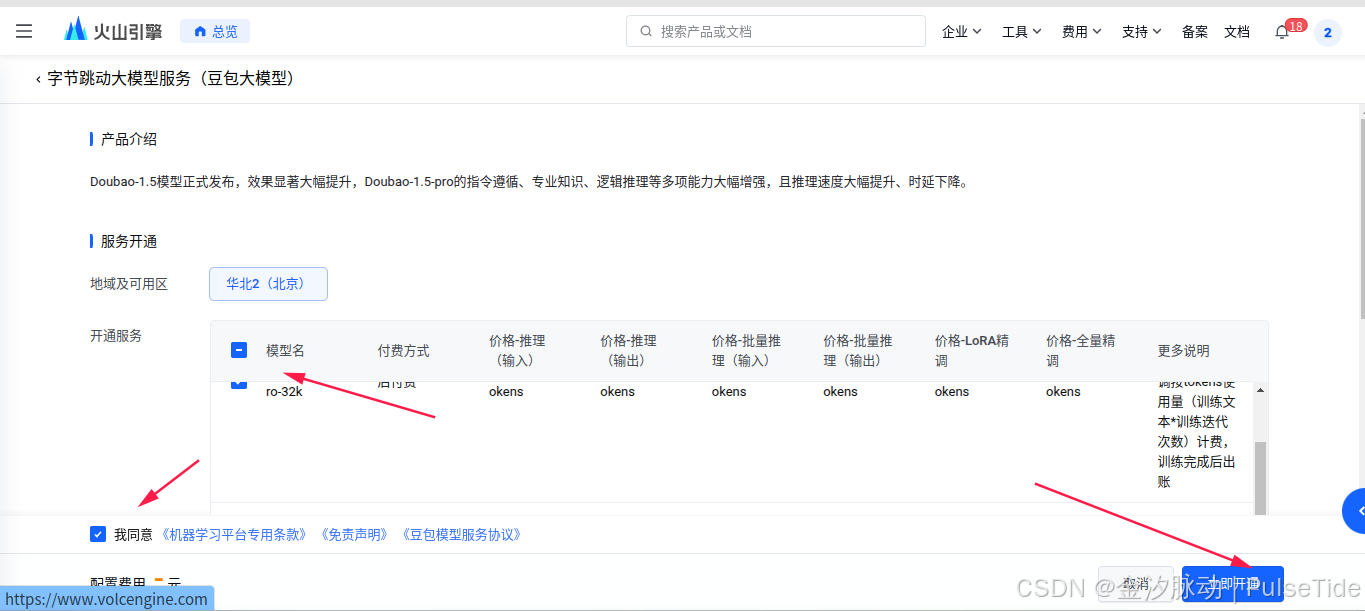
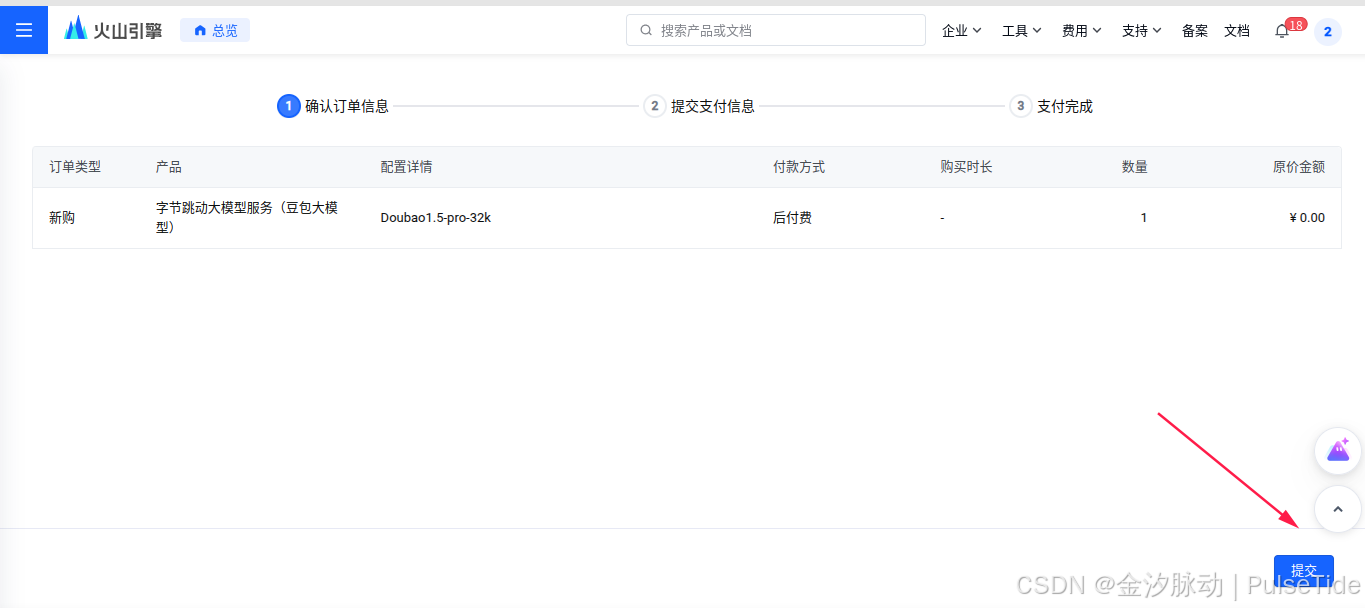
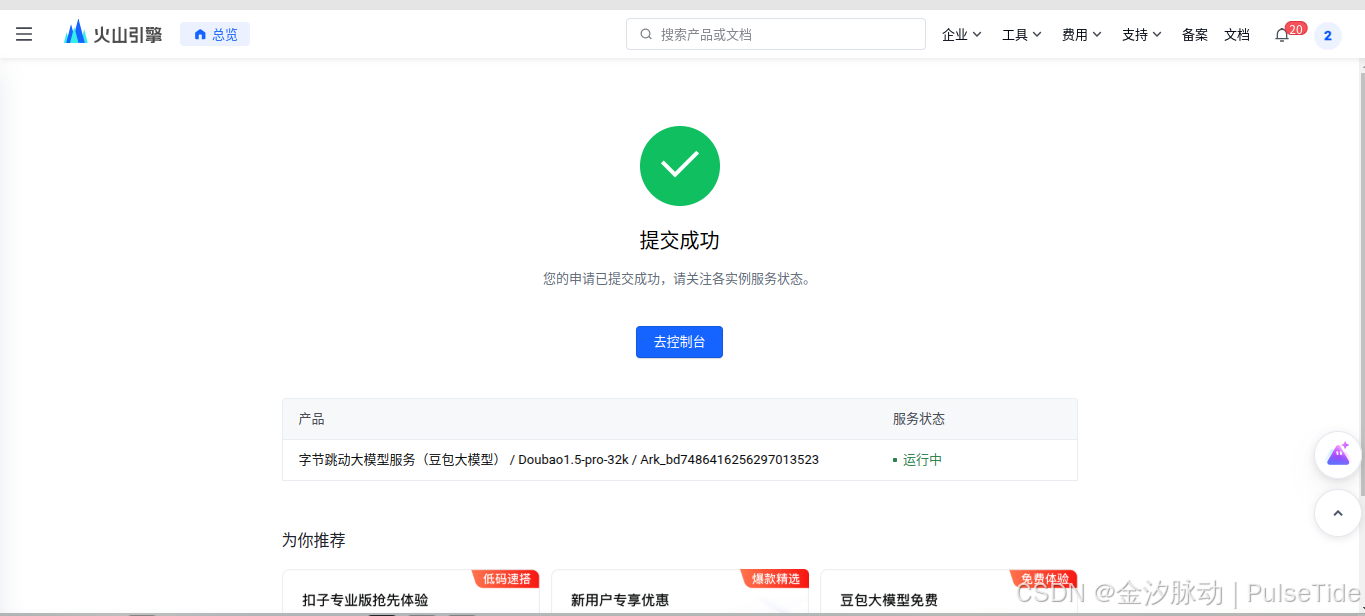

可以看到已经开通成功,接着配置"在线推理":
2.7、自定义推理接入点
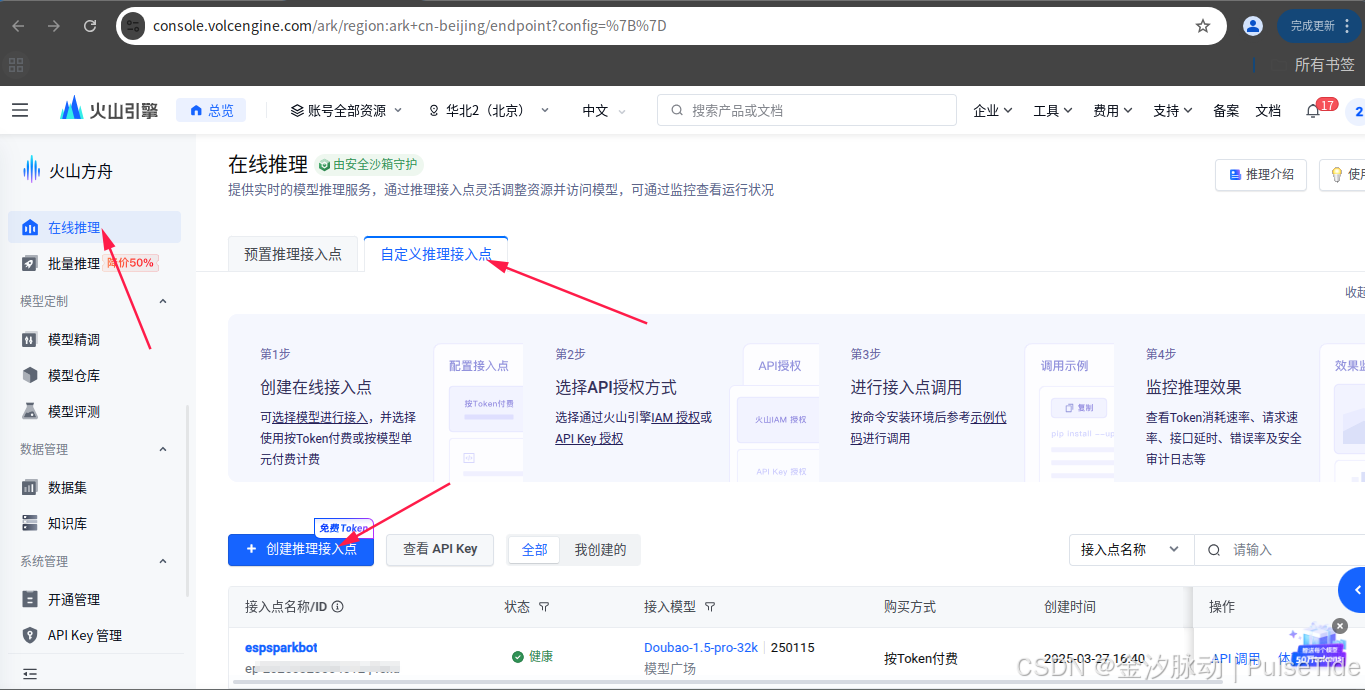
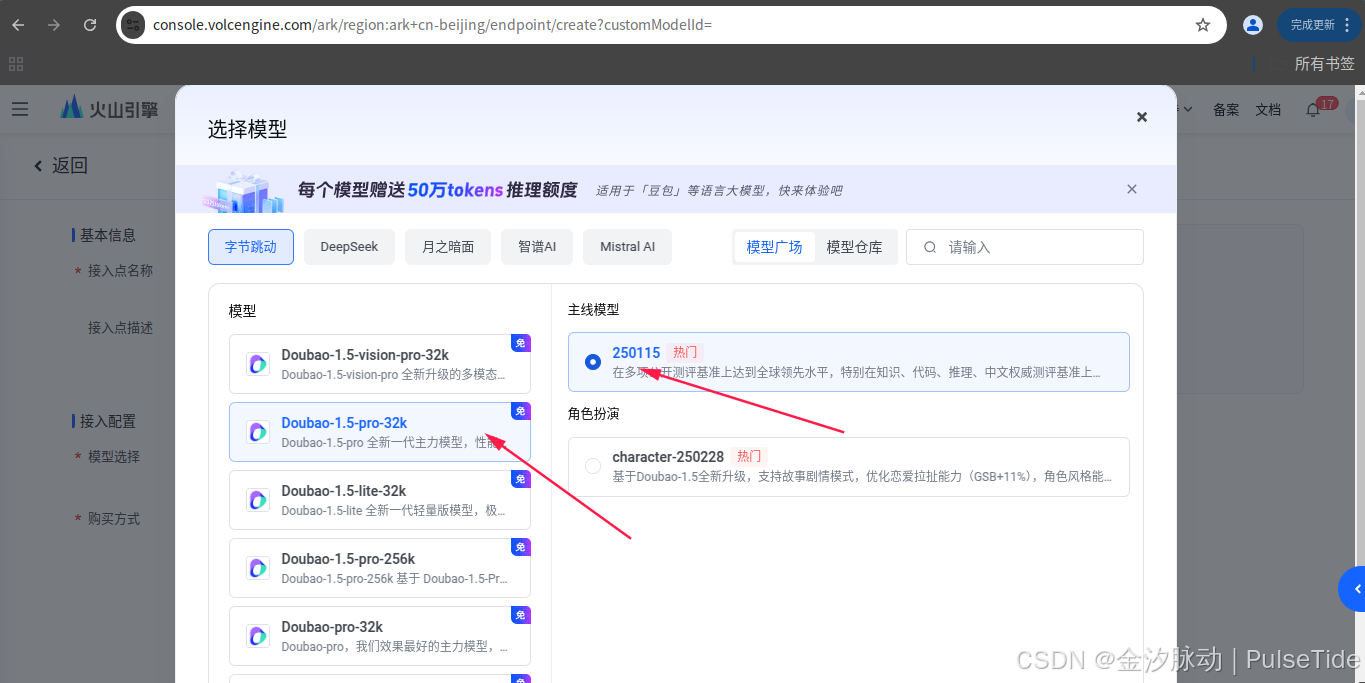
选中刚刚开通的大模型,点击"确认接入",
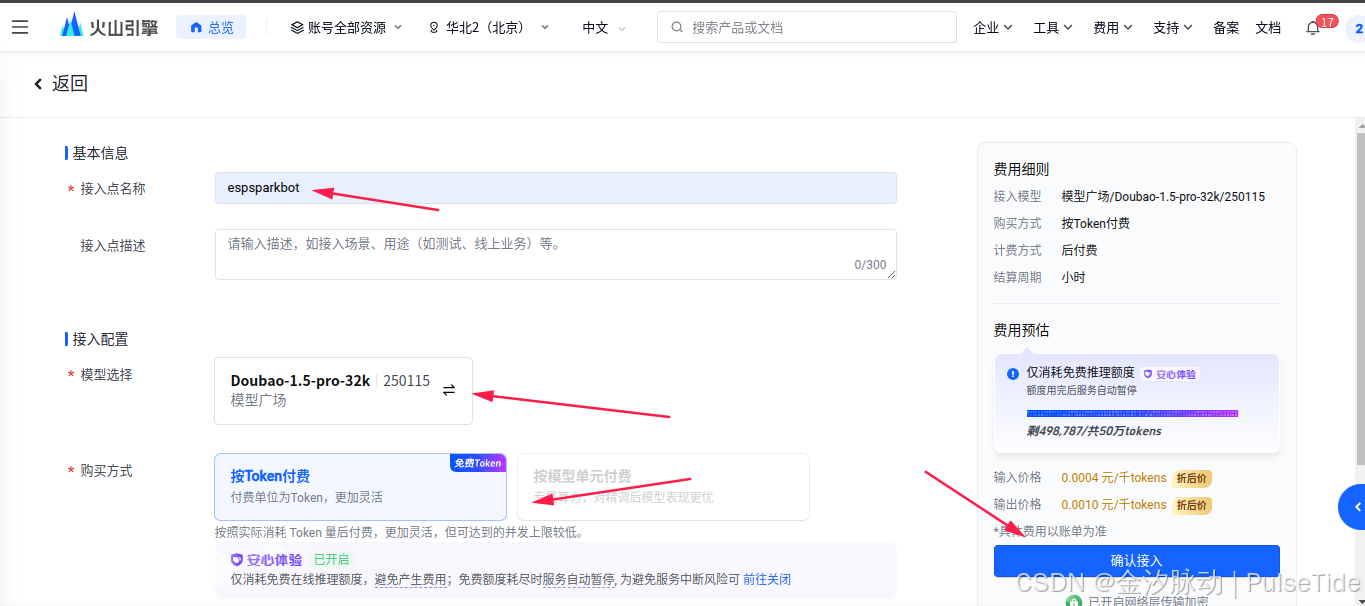
这里 ep 开头的就是需要获取的 EndPointId 参数值,
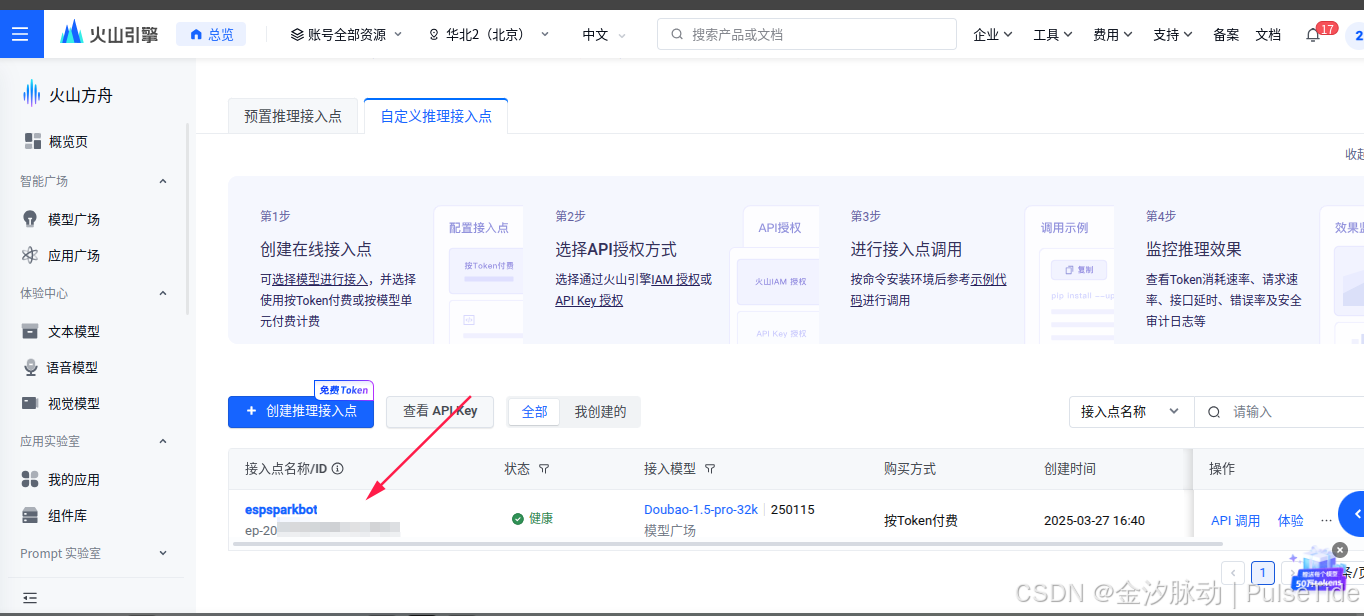
以上我们已经获取了启动智能体所需的所有参数,先用 Web 端测试参数是否可以正常使用,
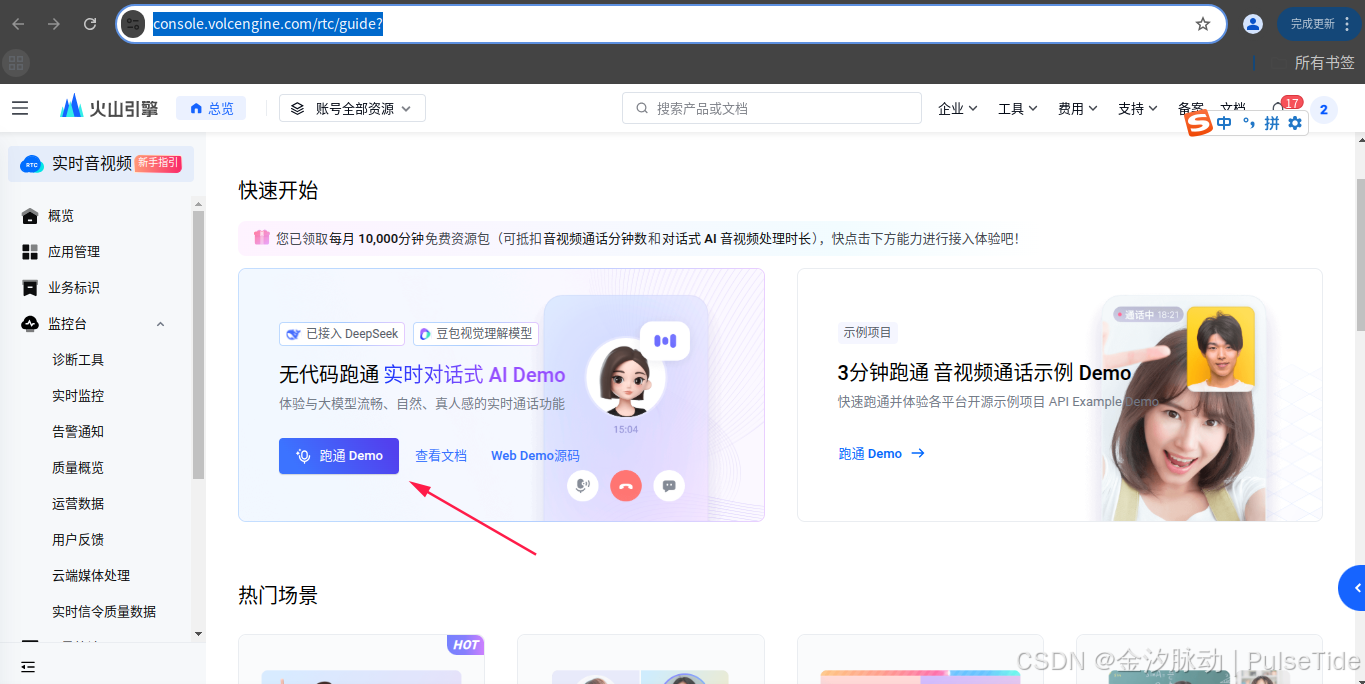
2.8、无代码测试
弹窗中,依次检查 Step1、Step2,然后"加入 RTC 房间",
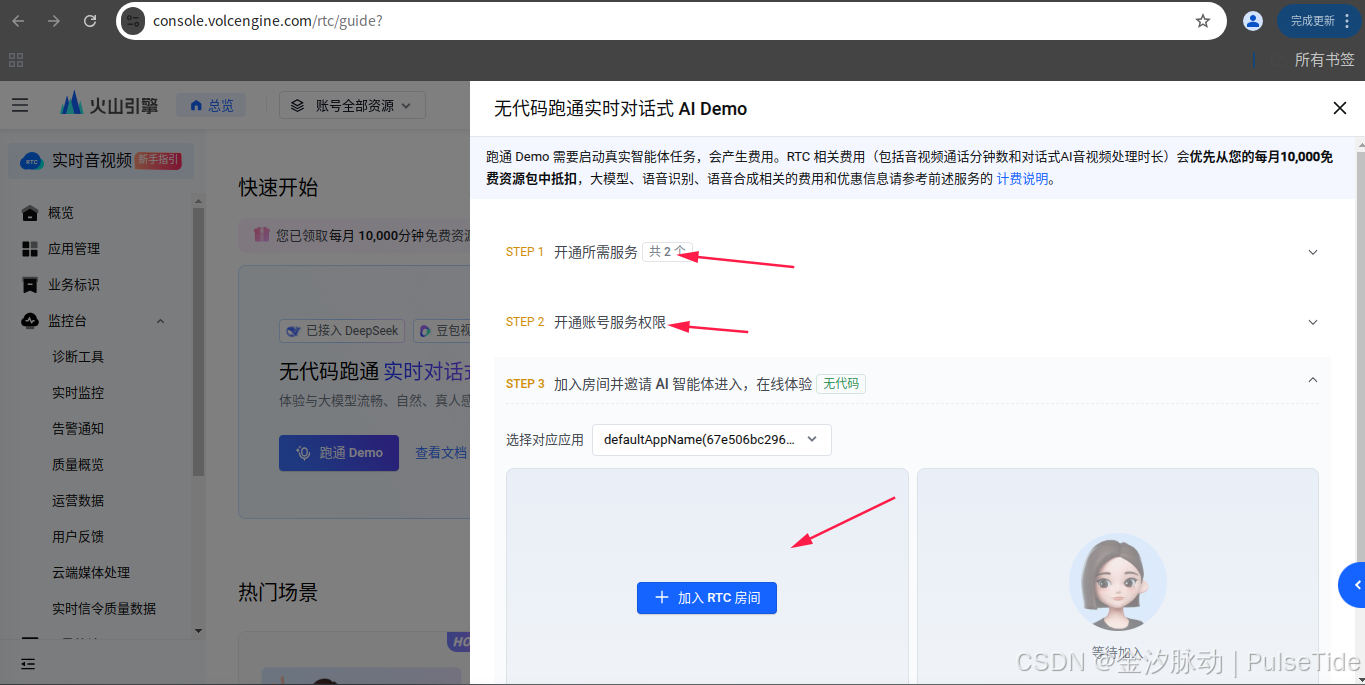
生成临时 token 并且使用临时 token 进入房间,
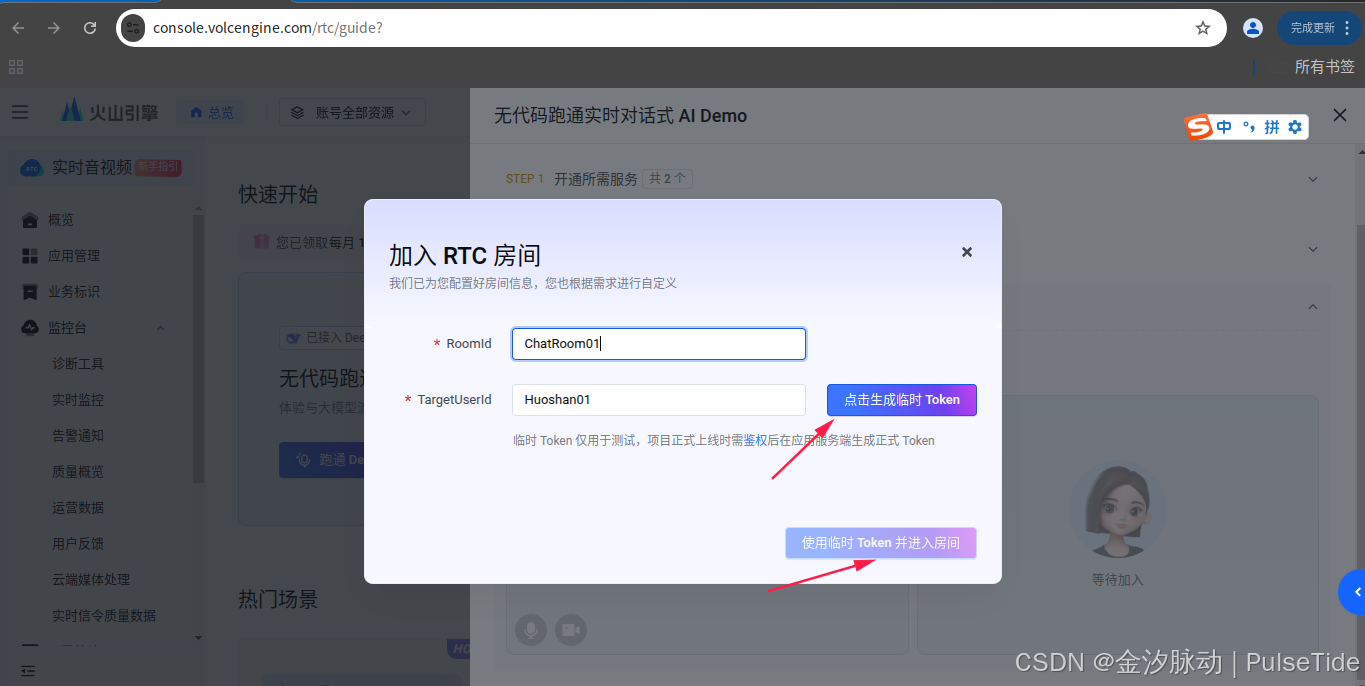
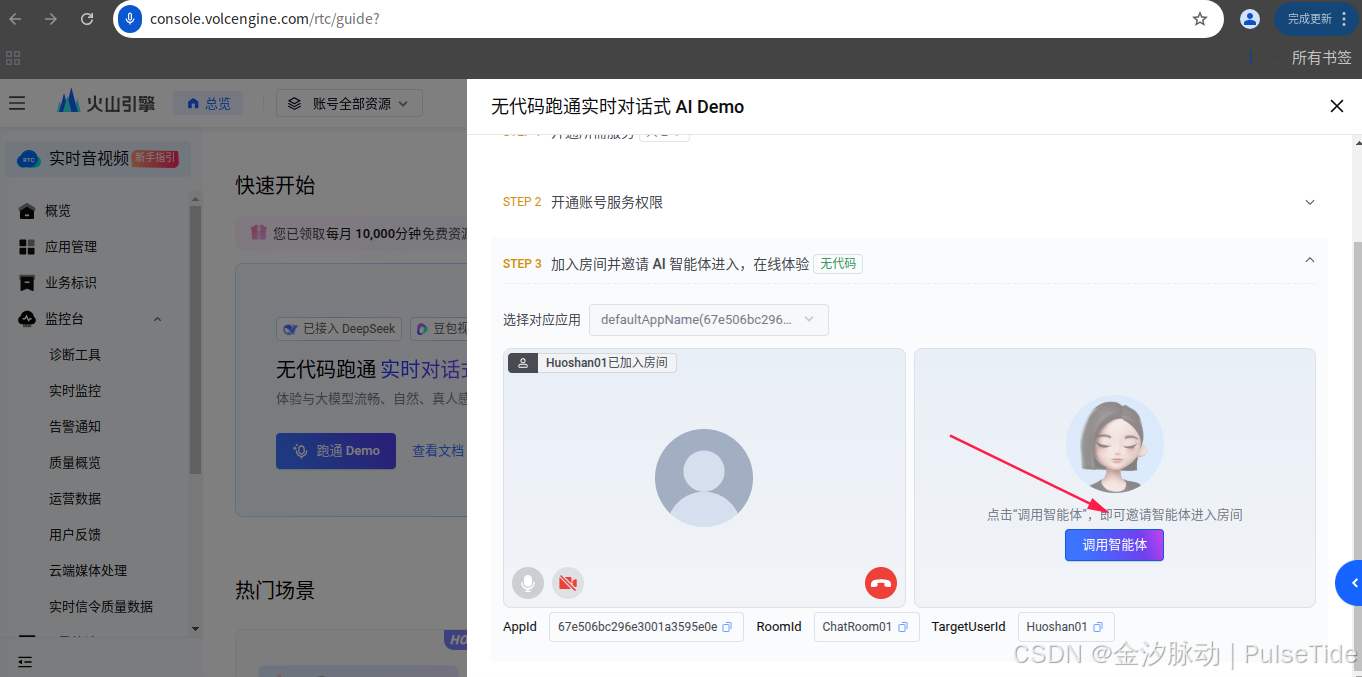
接着配置智能体,
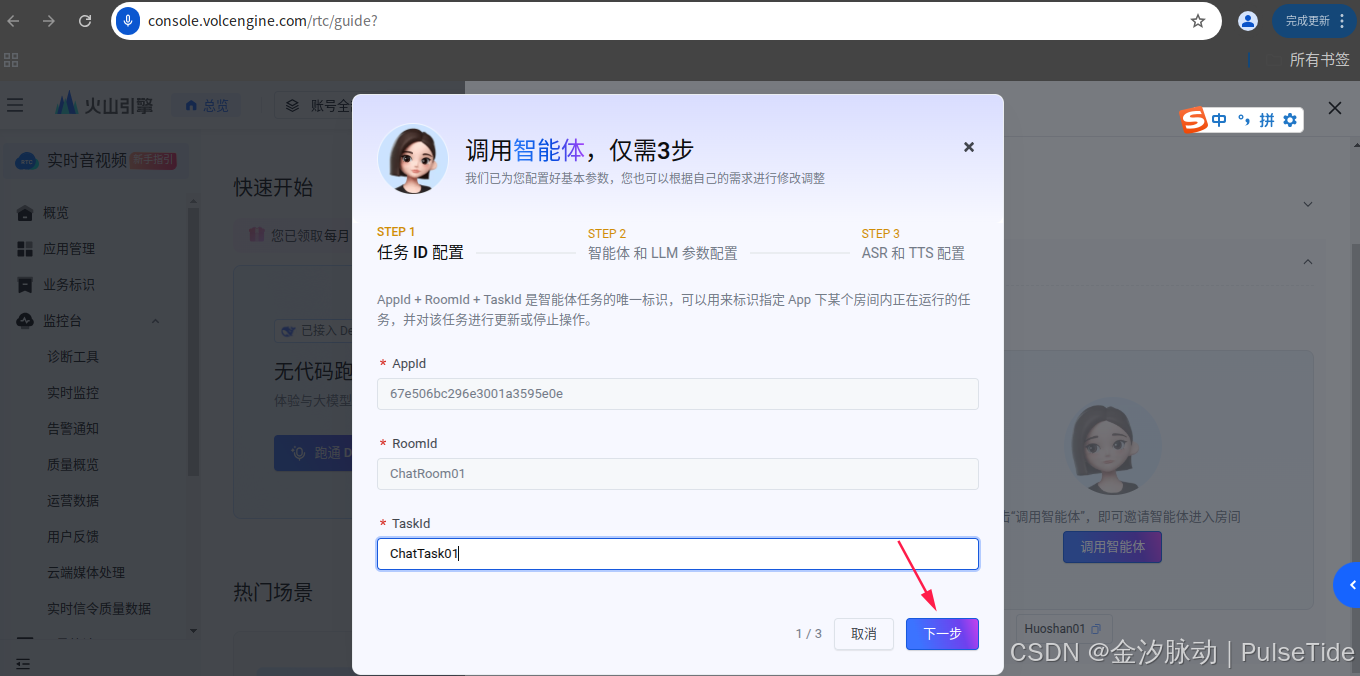
输入刚刚获取的 ep 开头的 EndPointId ,
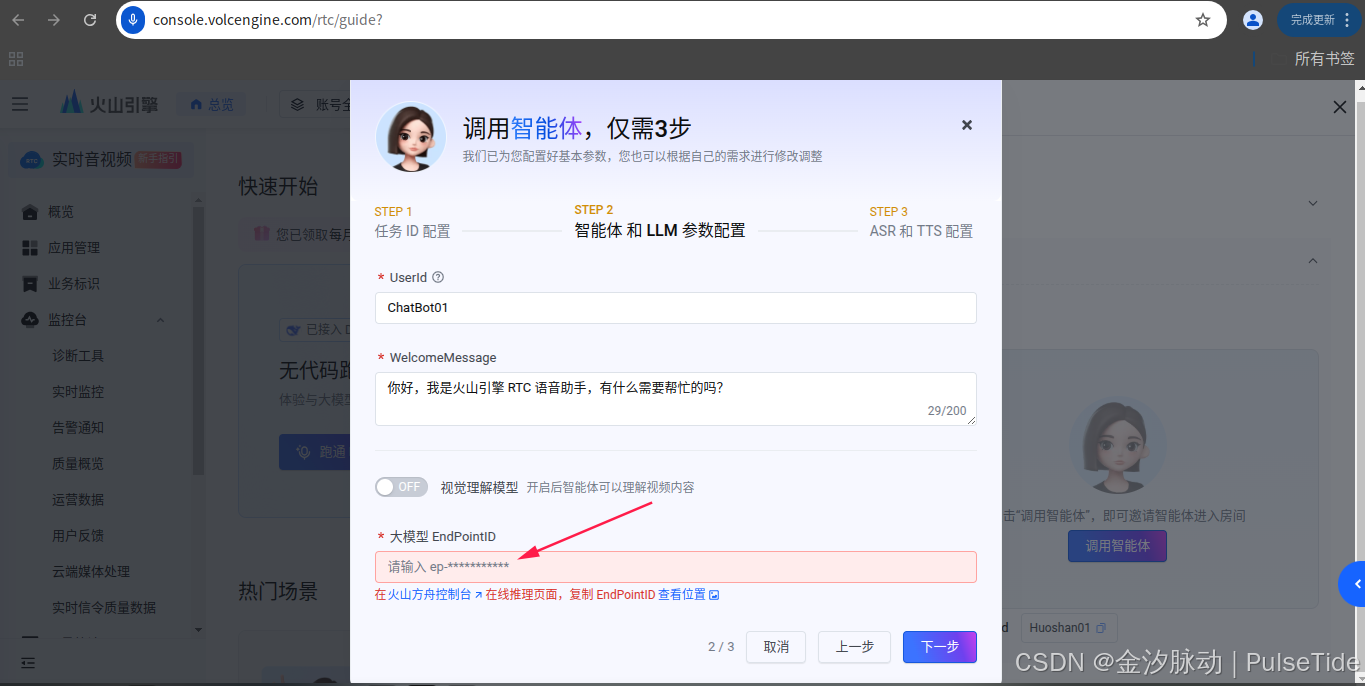
ASR 与 TTS 配置需要在语音技术页面找到 AppId 与 Cluster,点击下方蓝色提示词就可以跳转到对应的页面了,
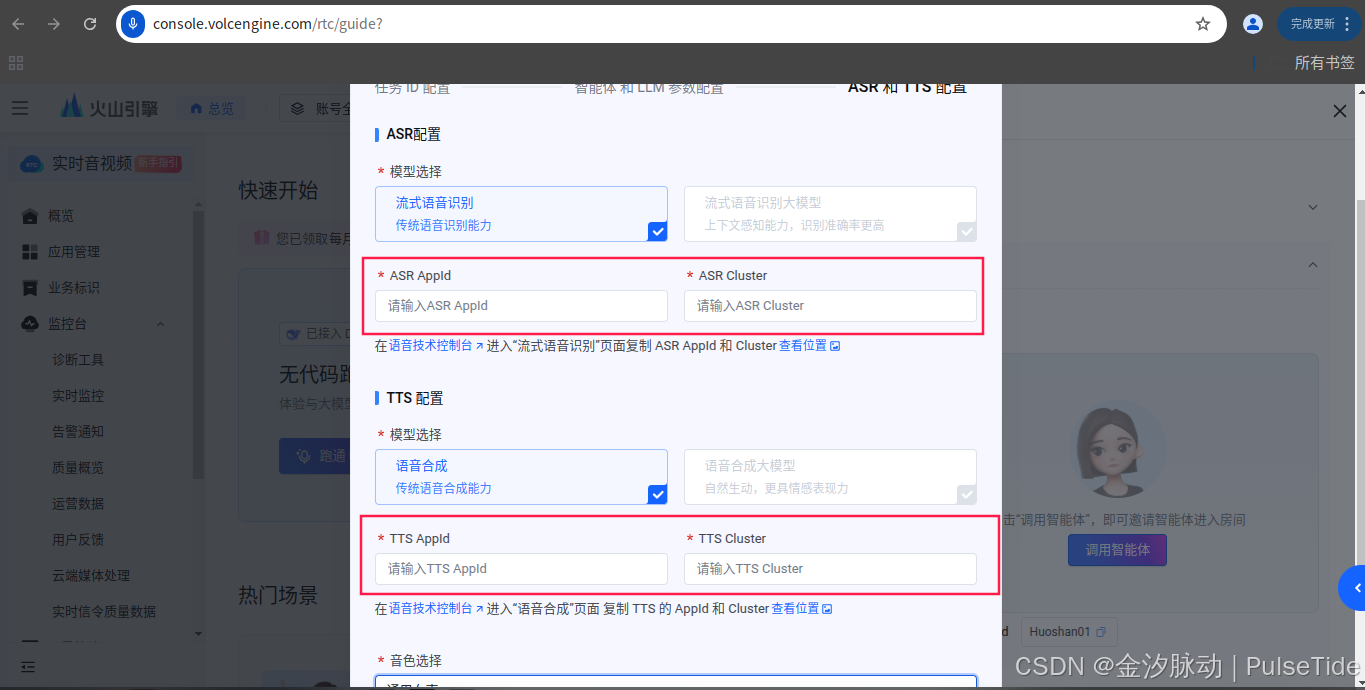
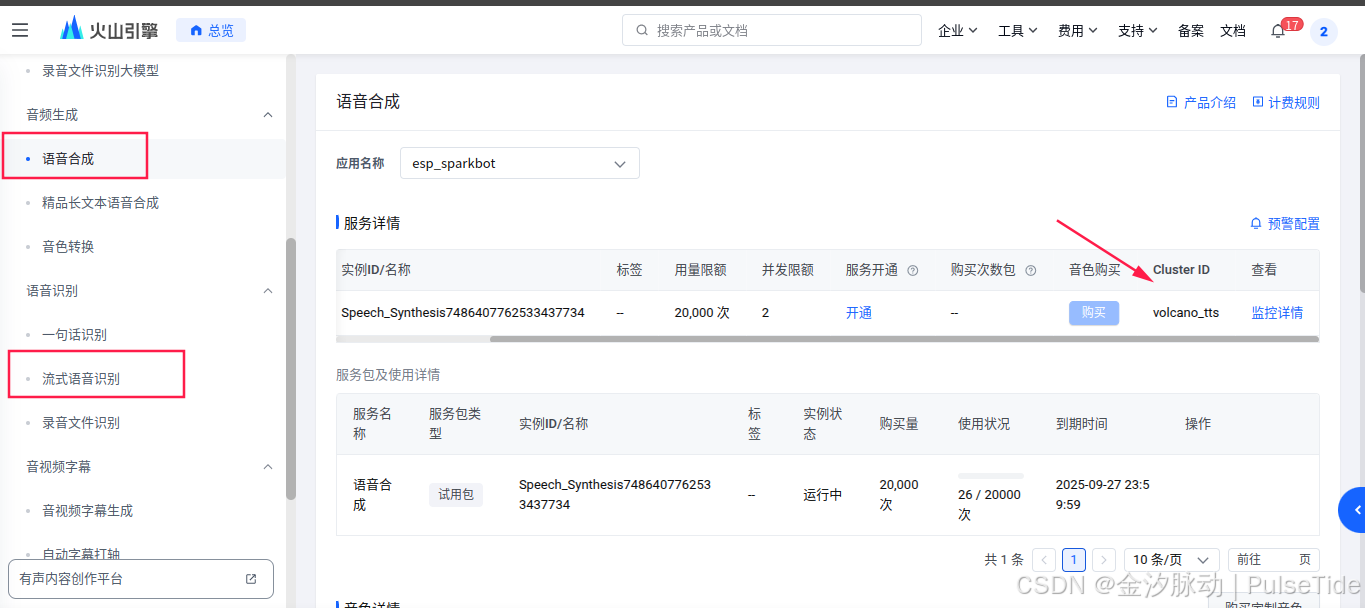
最后点击"开始调用",
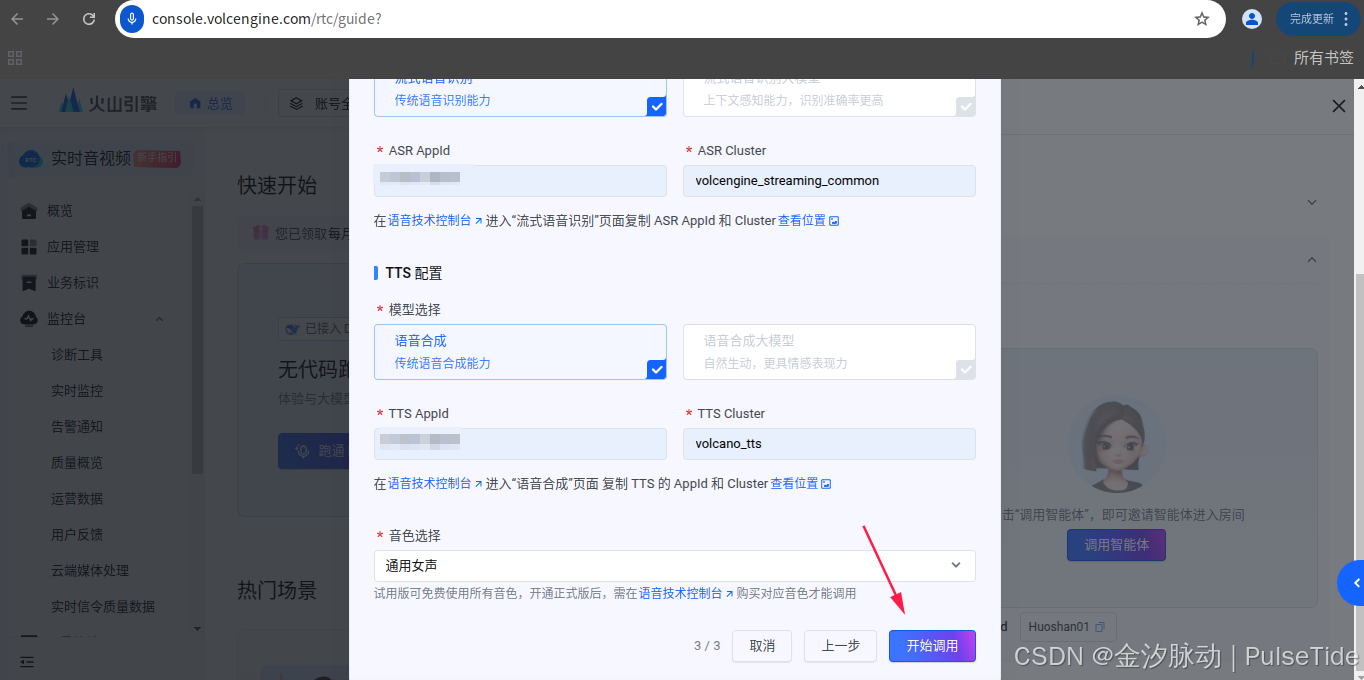
此时会听到豆包AI在说话就表示正常调用。
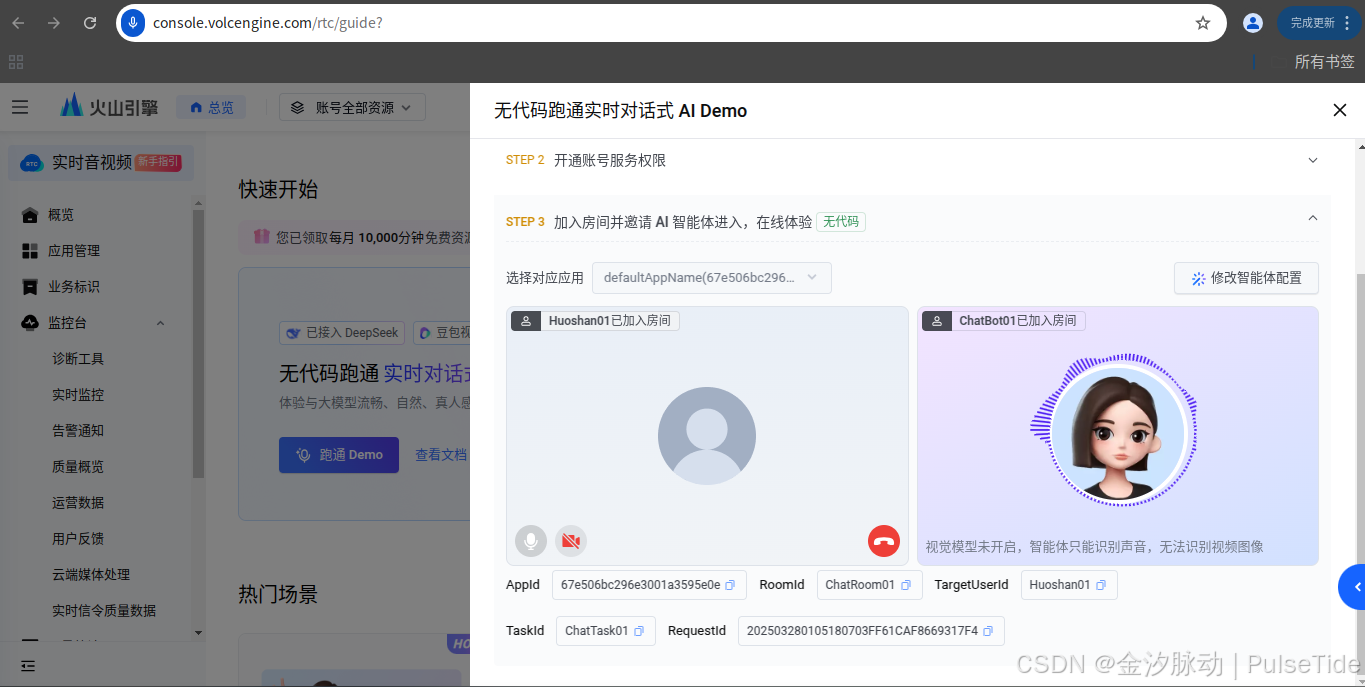
2.9、启动智能体
接下来整合参数配置、发起请求启动智能体:
"ASRConfig": {
"Provider": "volcano",
"ProviderParams": {
"Mode": "smallmodel",
"AppId": "9*******"
}
},语音识别配置,这里使用小模型,只需改 AppId。
"TTSConfig": {
"Provider": "volcano",
"ProviderParams": {
"app": {
"appid": "9*******",
"cluster":"volcano_tts"
}
}
},语音合成配置,这里只需改 AppId。
"LLMConfig": {
"Mode": "ArkV3",
"EndPointId": "ep*******",
"MaxTokens": 1024,
"Temperature": 0.1,
"TopP": 0.3,
"SystemMessages": [
"你是小马,性格幽默又善解人意。你在表达时需简明扼要,有自己的观点。"
],
"WelcomeSpeech": "你好,我是小马"
}大语音模型配置,这里只需改 EndPointId,角色预设与欢迎语根据自己需求修改。
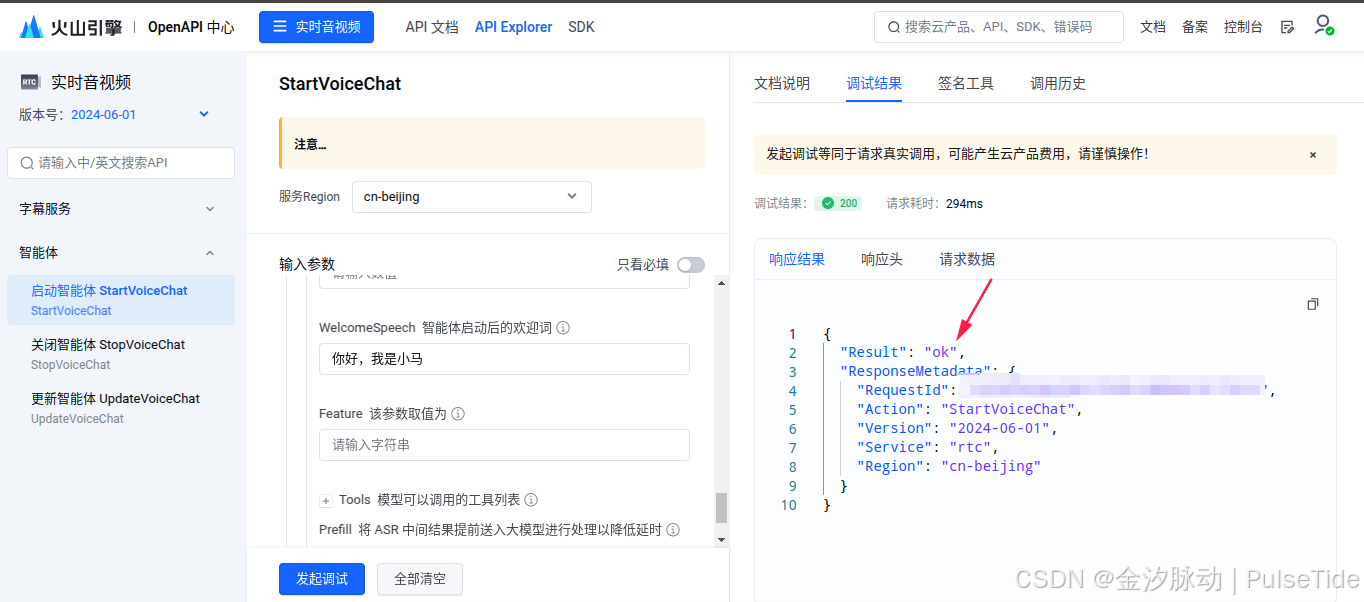
配置好参数后,点击"发起调试",可以看到已经调用成功。如果需要关闭智能体,则点第二个菜单,同样填入页面需要的参数即可。
五、编译烧录
1、自定义设备
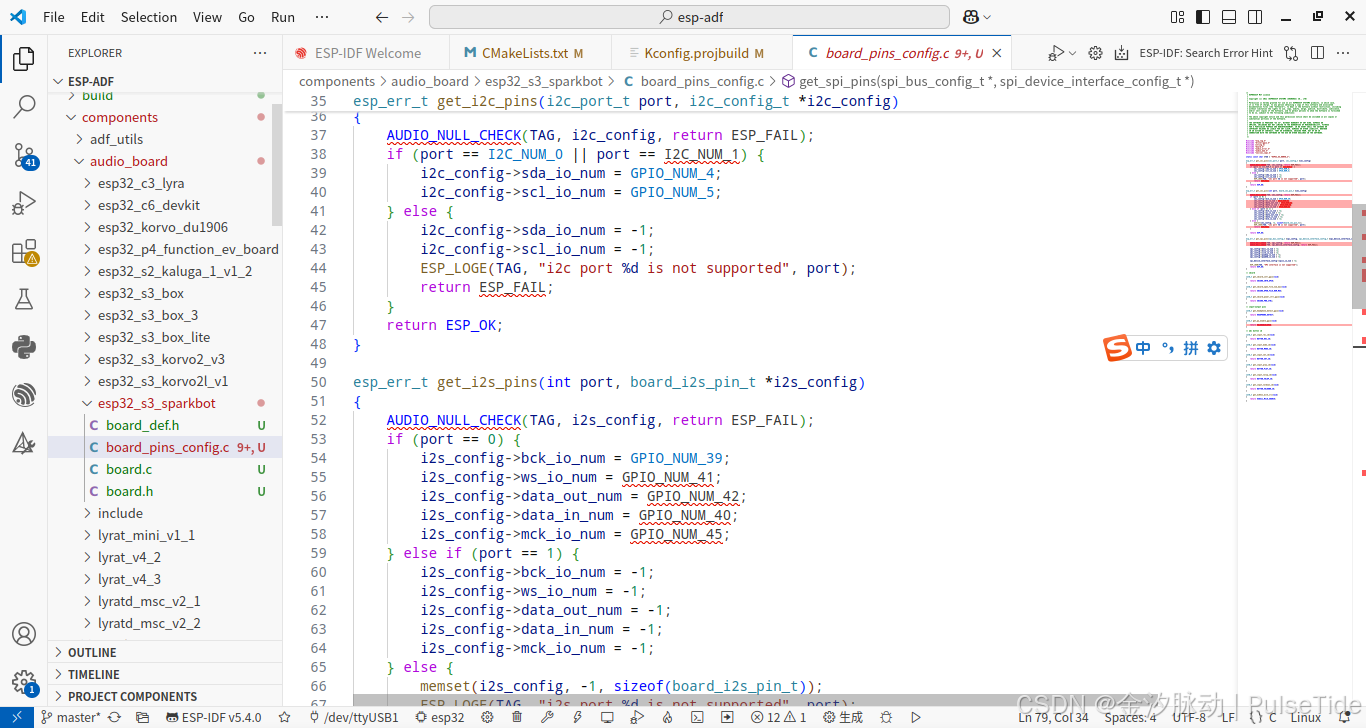
添加 components/audio_board/esp32_s3_sparkbot,因为该硬件 codex 芯片采用 ES8311 ,因此可以参考示例中同样音频芯片的 ESP32-S3-BOX-3 设备,只需要修改对应 IO 即可,
修改 components/audio_board/CMakeLists.txt,
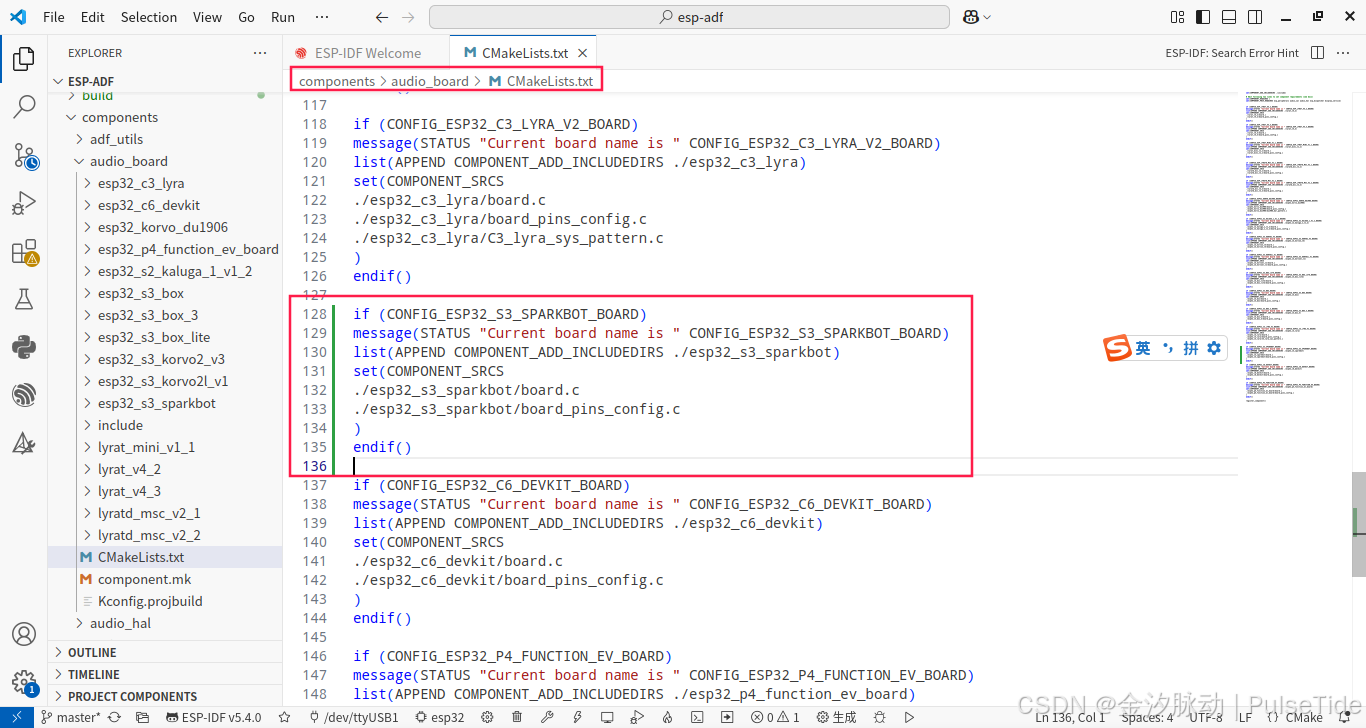
if (CONFIG_ESP32_S3_SPARKBOT_BOARD)
message(STATUS "Current board name is " CONFIG_ESP32_S3_SPARKBOT_BOARD)
list(APPEND COMPONENT_ADD_INCLUDEDIRS ./esp32_s3_sparkbot)
set(COMPONENT_SRCS
./esp32_s3_sparkbot/board.c
./esp32_s3_sparkbot/board_pins_config.c
)
endif()修改 components/audio_board/Kconfig.projbuild ,
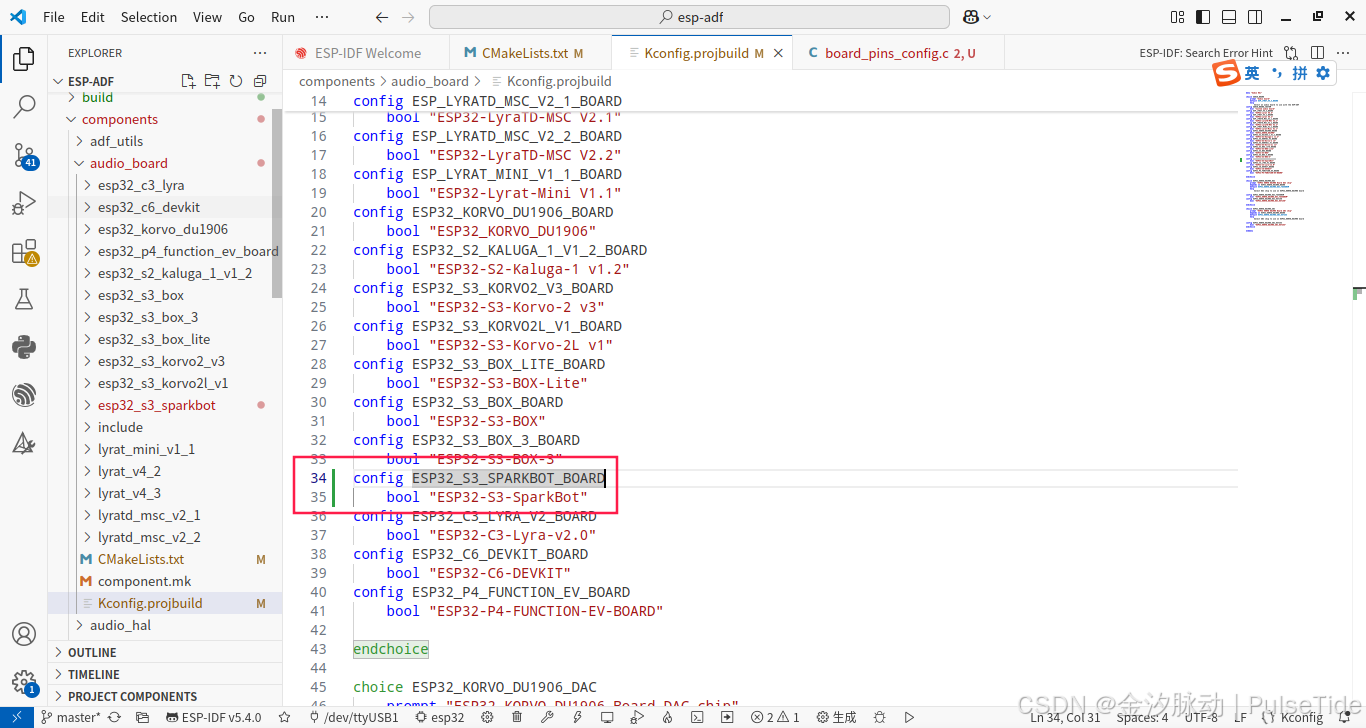
config ESP32_S3_SPARKBOT_BOARD
bool "ESP32-S3-SparkBot"2、设置目标芯片
idf.py set-target esp32s3
3、配置 menuconfig
idf.py menuconfig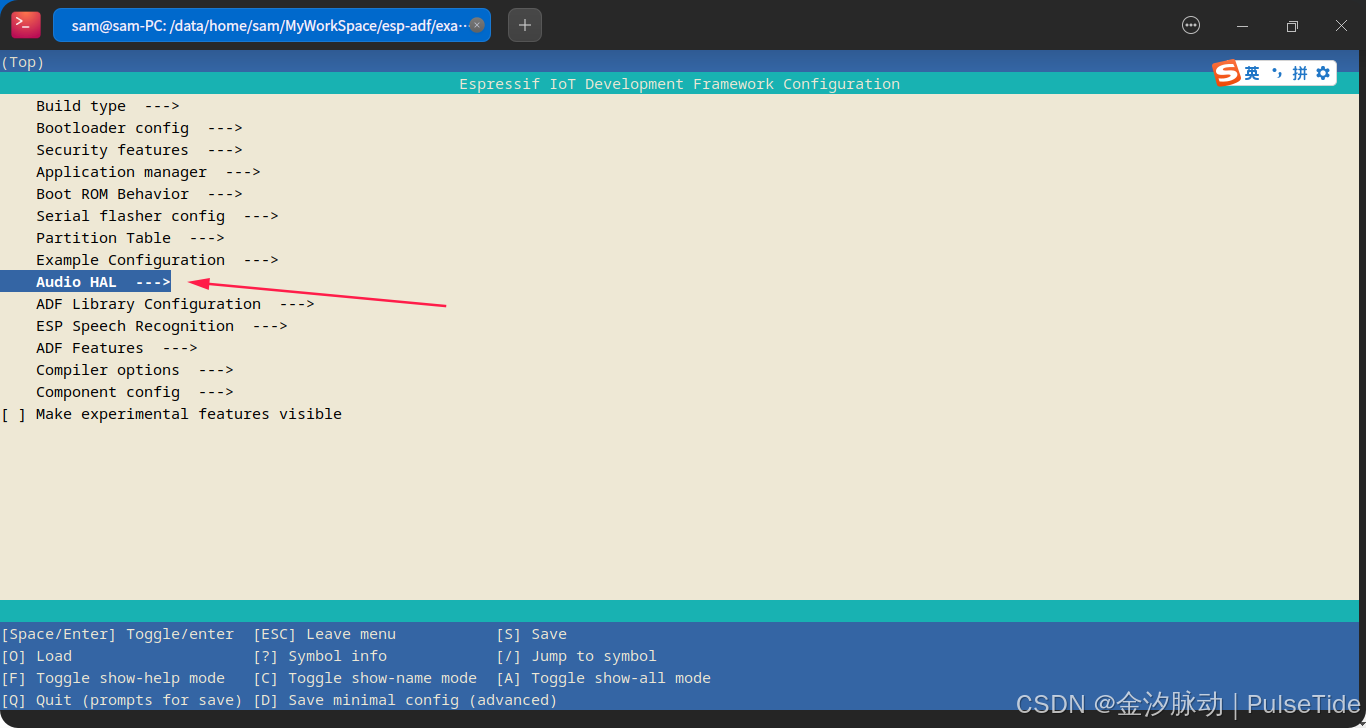
这里我们选中刚刚自定义的 ESP32-S3-SparkBot,
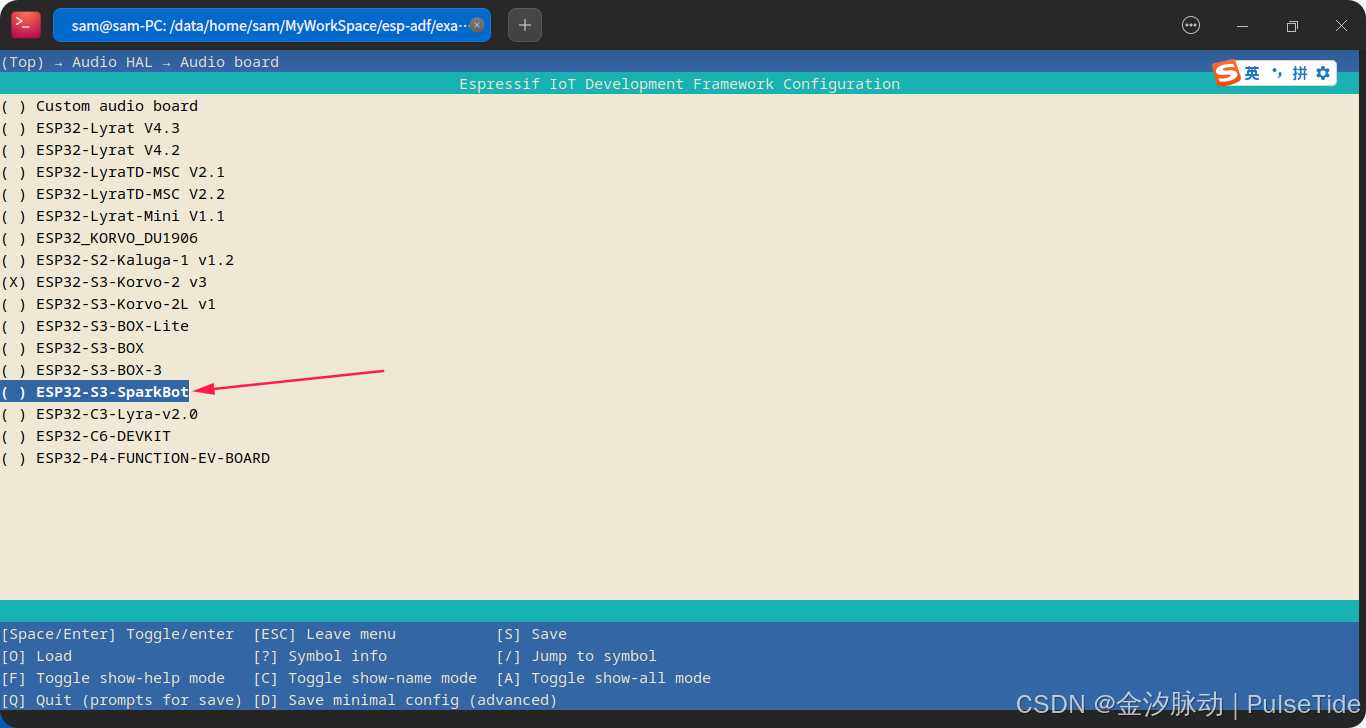
4、执行编译
idf.py build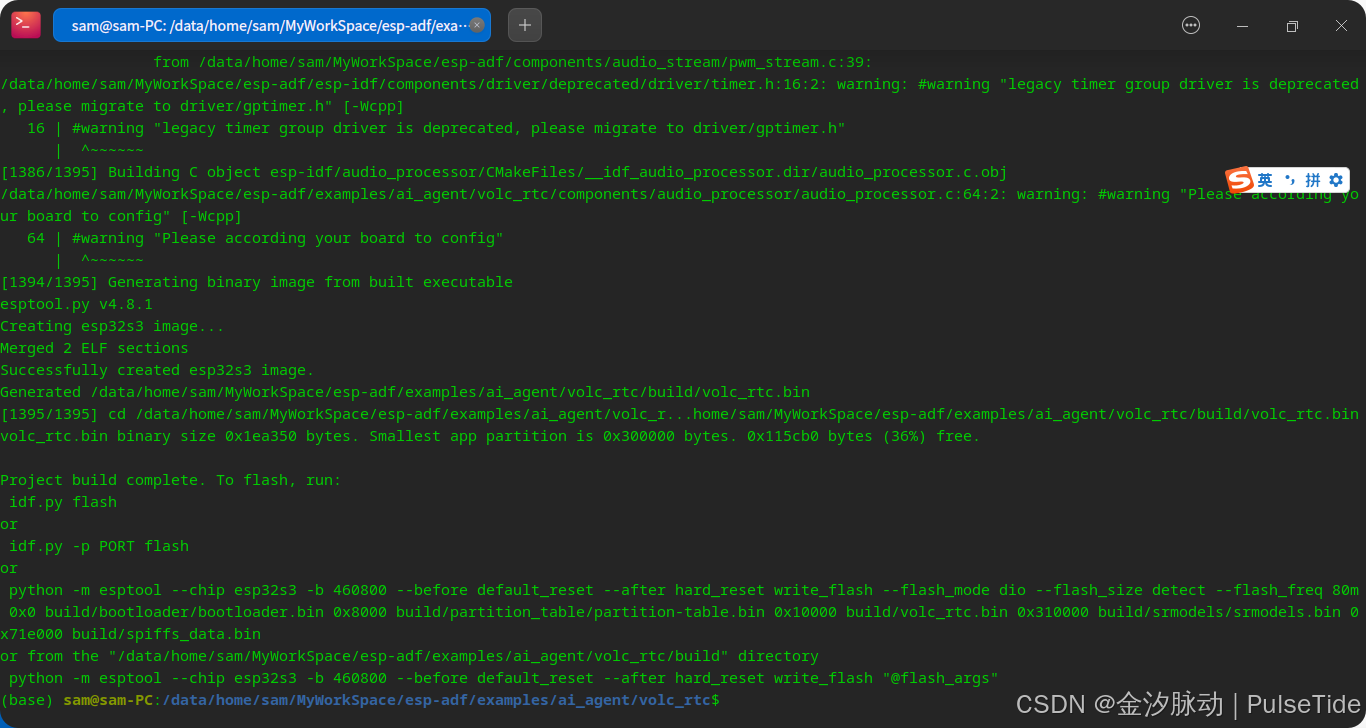
5、一键烧录
idf.py -p /dev/ttyACM0 flash monitor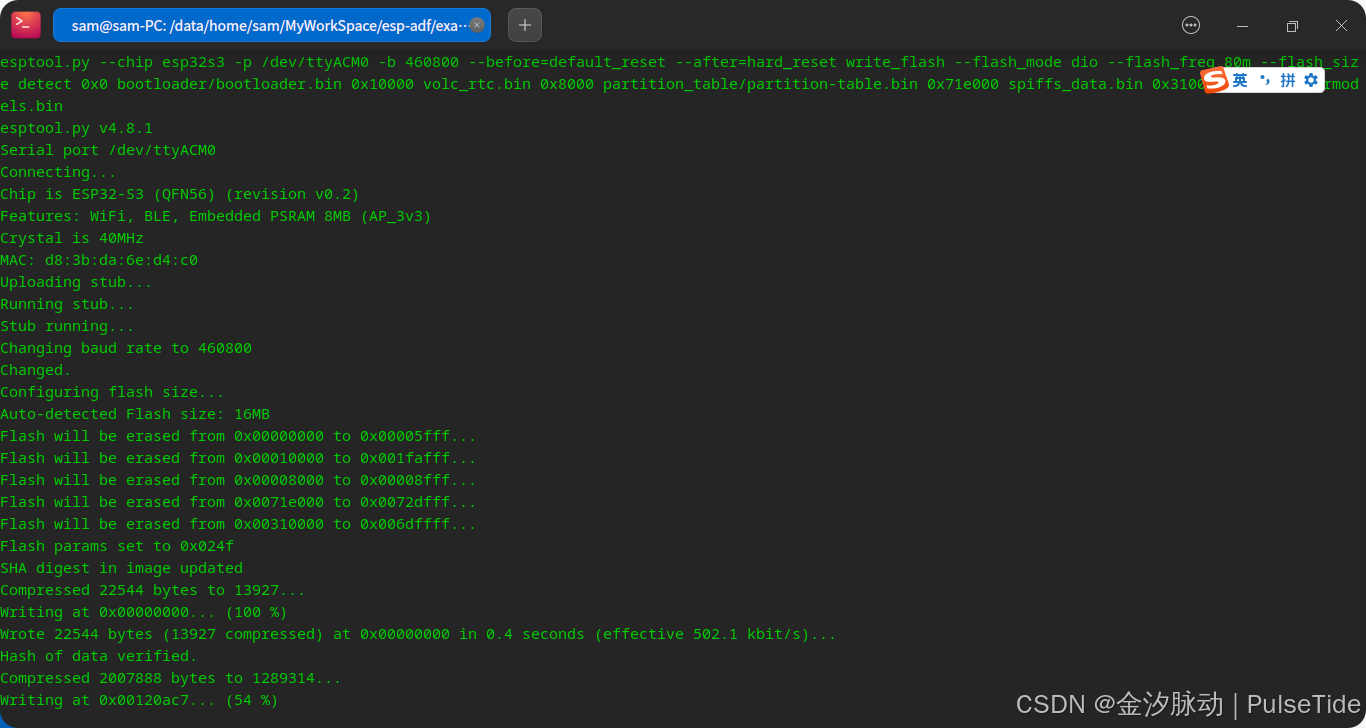
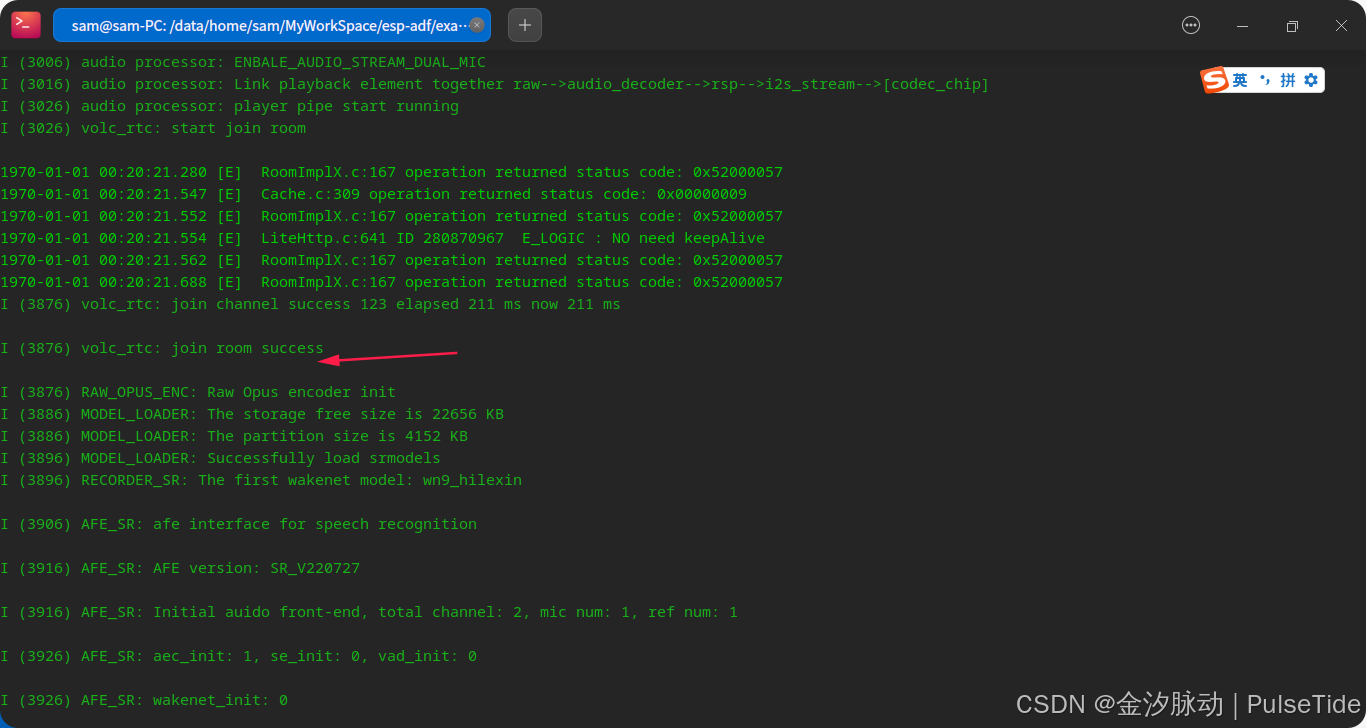
可以看到加入房间成功,可以开始与豆包AI对话。
ESP32与豆包大模型的RTC连续对话
彩蛋:EspSparkBot 对接豆包大模型




博客链接:手把手教你玩转ESP-SPARKBOT与豆包大模型:从零到一的完整指南-CSDN博客