官方连接:Doris Streamloader - Apache Doris
简单概述:Doris Streamloader 是一款用于++将数据导入 Doris 数据库++的专用客户端工具。
step1:安装go环境
[root@localhost ~]# rpm --import https://mirror.go-repo.io/centos/RPM-GPG-KEY-GO-REPO
[root@localhost ~]# curl -s https://mirror.go-repo.io/centos/go-repo.repo | tee /etc/yum.repos.d/go-repo.repo
yum install gostep2:新建一个目录,用于存放Doris Streamloader工具
mkdir /opt/DorisStreamloader
cd /opt/DorisStreamloader
git clone https://github.com/apache/doris-streamloader.git
cd doris-streamloader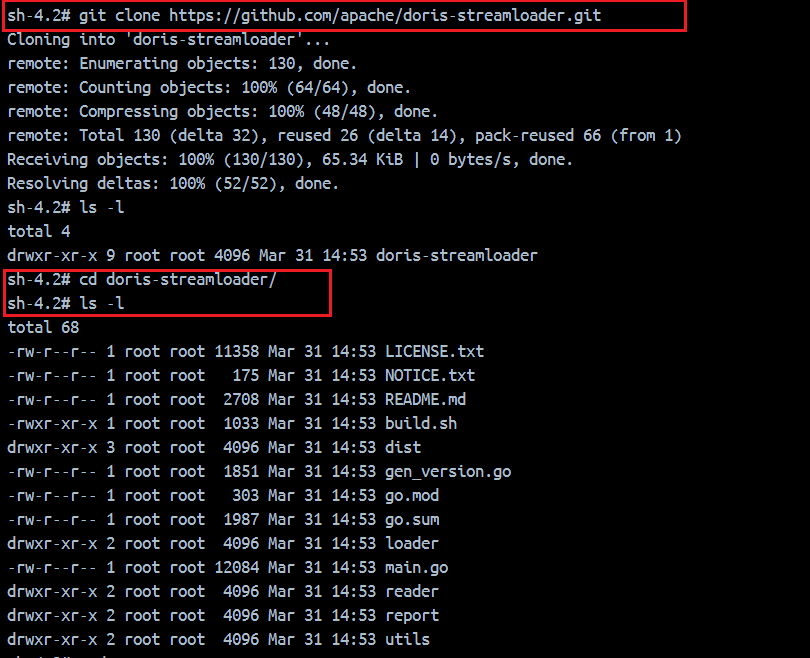
step3:编译项目
./build.sh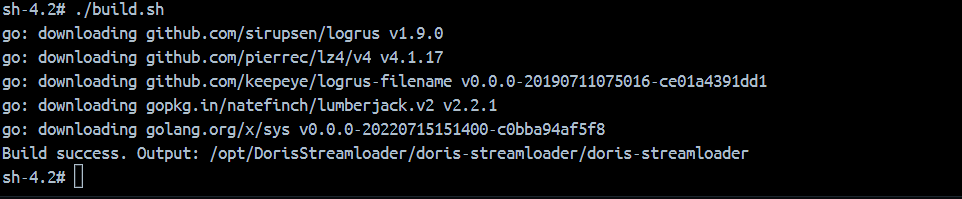
编译构建成功。
step4:加入到环境变量中
vim /etc/profile
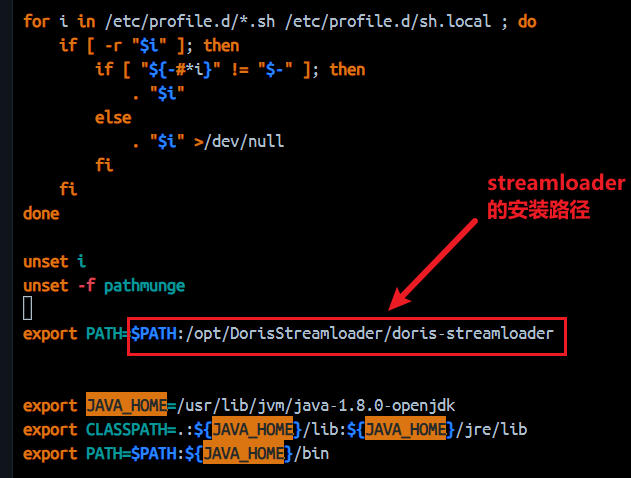
source /etc/profile
step5:构建测试数据,试验工具是否安装成功
创建streamloader_example.csv文件
1,Emily,25
2,Benjamin,35
3,Olivia,28
4,Alexander,60
5,Ava,17
6,William,69
7,Sophia,32
8,James,64
9,Emma,37
10,Liam,64创建表:
CREATE TABLE TEST.test_streamloader(
user_id BIGINT NOT NULL COMMENT "用户 ID",
name VARCHAR(20) COMMENT "用户姓名",
age INT COMMENT "用户年龄"
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES(
"replication_num" = "2"
);使用steamloader
doris-streamloader --source_file="/root/streamloader_example.csv" --url="http://udh01:8030" --header="column_separator:," --db="TEST" --table="test_streamloader"--source_file:为刚刚创建的CSV绝对路径
--url=:为FE_OR_BE_SERVER_URL:PORT,FE_OR_BE_SERVER_URL是FE或任意BE的IP,PORT是doris webUI访问的端口,我用的是8030
--db="TEST",代表需要导入到TEST库中
--table="test_streamloader",代表导入对应表是test_streamloader
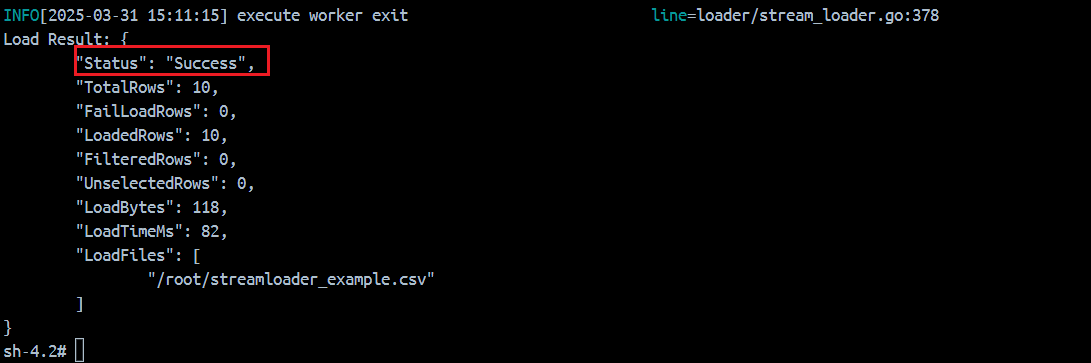
执行以上命令返回如下图代表成功: