文章目录
- 从0到1:XPath语法完全指南(实战详解版)
-
- 引言
- [1. 准备工作](#1. 准备工作)
-
- [1.1 推荐工具](#1.1 推荐工具)
- [1.2 示例HTML文档](#1.2 示例HTML文档)
- [2. XPath基础知识](#2. XPath基础知识)
-
- [2.1 什么是XPath?](#2.1 什么是XPath?)
- [2.2 基本路径表达式](#2.2 基本路径表达式)
- [3. 基本选择器](#3. 基本选择器)
-
- [3.1 选择特定元素](#3.1 选择特定元素)
- [3.2 选择特定路径上的元素](#3.2 选择特定路径上的元素)
- [3.3 通配符选择](#3.3 通配符选择)
- [4. 属性选择器](#4. 属性选择器)
-
- [4.1 选择具有特定属性的元素](#4.1 选择具有特定属性的元素)
- [4.2 选择特定属性值的元素](#4.2 选择特定属性值的元素)
- [4.3 选择具有特定属性的元素(无论值是什么)](#4.3 选择具有特定属性的元素(无论值是什么))
- [5. 条件表达式](#5. 条件表达式)
-
- [5.1 使用条件选择元素](#5.1 使用条件选择元素)
- [5.2 使用or条件](#5.2 使用or条件)
- [5.3 使用not函数](#5.3 使用not函数)
- [6. 位置选择器](#6. 位置选择器)
-
- [6.1 选择第一个元素](#6.1 选择第一个元素)
- [6.2 选择最后一个元素](#6.2 选择最后一个元素)
- [6.3 选择特定位置范围的元素](#6.3 选择特定位置范围的元素)
- [7. 文本内容选择](#7. 文本内容选择)
-
- [7.1 选择包含特定文本的元素](#7.1 选择包含特定文本的元素)
- [7.2 选择完全匹配文本的元素](#7.2 选择完全匹配文本的元素)
- [8. XPath轴](#8. XPath轴)
-
- [8.1 子节点轴](#8.1 子节点轴)
- [8.2 父节点轴](#8.2 父节点轴)
- [8.3 兄弟节点轴](#8.3 兄弟节点轴)
- [8.4 祖先节点轴](#8.4 祖先节点轴)
- [8.5 后代节点轴](#8.5 后代节点轴)
- [9. XPath函数](#9. XPath函数)
-
- [9.1 字符串函数](#9.1 字符串函数)
-
- [9.1.1 contains()函数](#9.1.1 contains()函数)
- [9.1.2 starts-with()函数](#9.1.2 starts-with()函数)
- [9.2 数值函数](#9.2 数值函数)
-
- [9.2.1 使用数值比较](#9.2.1 使用数值比较)
- [9.3 组合函数](#9.3 组合函数)
- [10. 实际应用场景](#10. 实际应用场景)
-
- [10.1 提取所有商品名称](#10.1 提取所有商品名称)
- [10.2 提取所有有货商品的价格](#10.2 提取所有有货商品的价格)
- [10.3 找出所有缺货商品](#10.3 找出所有缺货商品)
- [10.4 获取导航菜单项](#10.4 获取导航菜单项)
- [11. XPath调试技巧](#11. XPath调试技巧)
-
- [11.1 分步构建复杂表达式](#11.1 分步构建复杂表达式)
- [11.2 使用Chrome开发者工具的Elements面板](#11.2 使用Chrome开发者工具的Elements面板)
- [11.3 使用XPath Helper插件](#11.3 使用XPath Helper插件)
- [12. XPath常见问题与解决方案](#12. XPath常见问题与解决方案)
-
- [12.1 处理动态生成的内容](#12.1 处理动态生成的内容)
- [12.2 处理iframe中的内容](#12.2 处理iframe中的内容)
- [12.3 XPath性能优化](#12.3 XPath性能优化)
- [13. 高级XPath技巧](#13. 高级XPath技巧)
-
- [13.1 使用索引动态选择元素](#13.1 使用索引动态选择元素)
- [13.2 使用多重条件](#13.2 使用多重条件)
- [13.3 使用normalize-space()处理空白](#13.3 使用normalize-space()处理空白)
- [13.4 组合使用轴和函数](#13.4 组合使用轴和函数)
- 结语
从0到1:XPath语法完全指南(实战详解版)
引言
大家好!在学习XPath的过程中,最有效的方式莫过于通过实际例子进行操作和验证。本篇博客将使用一个完整的HTML示例,从基础到进阶,系统地讲解XPath语法,让你能够真正掌握这个强大的工具。我们将详细解释每一个操作,确保即使你是零基础,也能轻松理解并应用XPath。
1. 准备工作
1.1 推荐工具
首先,我们需要一些工具来验证XPath表达式:
-
Chrome 开发者工具 :按 F12 或右键"检查"打开,在 Console 面板中使用
$x('xpath表达式')测试- 为什么选择它:Chrome开发者工具内置支持XPath测试,无需安装额外插件
- 如何使用:在Console面板输入
$x('//div')会返回所有div元素的数组
-
Firefox 开发者工具 :同样支持
$x('xpath表达式'),操作方式与Chrome类似 -
在线XPath测试工具:
- 优势:可以将HTML代码和XPath表达式一起测试,适合离线学习
-
XPath Helper:Chrome扩展,可实时测试XPath表达式
- 特点:提供实时高亮显示选中元素的功能,直观感受XPath效果
本文将使用在线测试工具来进行演示,在线XPath测试工具网上有很多,大家可以自行搜索选择使用。
1.2 示例HTML文档
我们将使用下面这个模拟电子商城的HTML文档作为学习示例。这个文档包含了多种HTML结构和常见的网页元素,非常适合学习XPath:
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>小小电子商城</title>
<style>
.product { border: 1px solid #ddd; margin: 10px; padding: 10px; }
.highlight { background-color: #ffffd0; }
</style>
</head>
<body>
<header id="main-header">
<h1>小小电子商城</h1>
<nav class="main-nav">
<ul>
<li><a href="/" class="active">首页</a></li>
<li><a href="/products">全部商品</a></li>
<li><a href="/about">关于我们</a></li>
<li><a href="/contact">联系方式</a></li>
</ul>
</nav>
</header>
<div class="container">
<aside class="sidebar">
<h3>商品分类</h3>
<ul class="categories">
<li data-category="phone">手机</li>
<li data-category="laptop" class="highlight">笔记本电脑</li>
<li data-category="tablet">平板电脑</li>
<li data-category="accessory">配件</li>
</ul>
</aside>
<main>
<section class="featured">
<h2>热门商品</h2>
<div class="product-list">
<div class="product" id="product-1" data-price="4999">
<h3>超薄笔记本 Pro</h3>
<p class="description">8核处理器,16GB内存,512GB固态硬盘</p>
<div class="price">¥4,999</div>
<div class="stock" data-count="15">有货</div>
<button class="add-to-cart">加入购物车</button>
</div>
<div class="product" id="product-2" data-price="3299">
<h3>智能手机 Max</h3>
<p class="description">6.7英寸屏幕,256GB存储,<span class="highlight">三摄像头</span></p>
<div class="price">¥3,299</div>
<div class="stock" data-count="8">有货</div>
<button class="add-to-cart">加入购物车</button>
</div>
<div class="product" id="product-3" data-price="2599">
<h3>平板电脑 Air</h3>
<p class="description">10.9英寸屏幕,64GB存储</p>
<div class="price">¥2,599</div>
<div class="stock" data-count="0">缺货</div>
<button class="add-to-cart" disabled>加入购物车</button>
</div>
</div>
</section>
<section class="newsletter">
<h2>订阅我们的通讯</h2>
<form id="subscribe-form">
<input type="text" name="name" placeholder="您的姓名">
<input type="email" name="email" placeholder="您的邮箱" required>
<select name="interest">
<option value="">选择您感兴趣的产品</option>
<option value="phone">手机</option>
<option value="laptop">笔记本电脑</option>
<option value="tablet">平板电脑</option>
</select>
<button type="submit">订阅</button>
</form>
</section>
</main>
</div>
<footer>
<div class="links">
<div class="column">
<h4>购物指南</h4>
<ul>
<li><a href="/guide/account">账户注册</a></li>
<li><a href="/guide/payment">支付方式</a></li>
</ul>
</div>
<div class="column">
<h4>服务支持</h4>
<ul>
<li><a href="/support/faq">常见问题</a></li>
<li><a href="/support/return">退换货政策</a></li>
</ul>
</div>
</div>
<p class="copyright">© 2025 小小电子商城 版权所有</p>
</footer>
</body>
</html>请将上述HTML代码保存为shop.html文件,然后在浏览器中打开,我们将基于这个页面来学习XPath。
2. XPath基础知识
2.1 什么是XPath?
XPath (XML Path Language) 是一种用于在XML和HTML文档中导航并选择元素的查询语言。它通过路径表达式来选择节点,就像文件系统的路径一样。
为什么需要XPath?
- 在网页自动化测试中,需要精确定位元素
- 在网络爬虫中,需要提取特定信息
- 在处理XML配置文件时,需要查询和修改特定节点
XPath的核心概念:
- 节点(Node):HTML/XML文档中的每个部分(元素、属性、文本等)
- 路径表达式:用于导航和选择节点的表达式
- 轴(Axis):定义节点间关系的方式(父子、兄弟等)
2.2 基本路径表达式
在我们的示例页面上测试基本路径表达式:
- 选择根元素
xpath
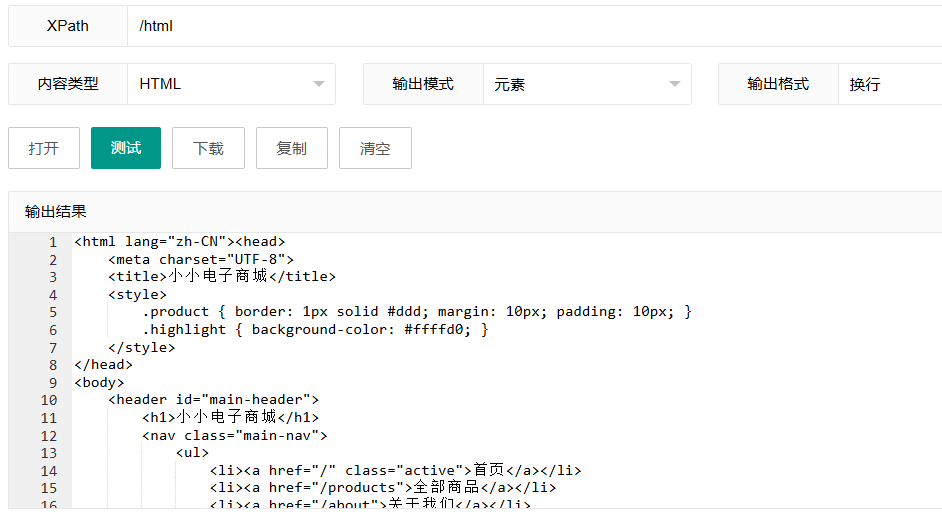
/html这个表达式以斜杠"/"开头,表示从文档根部开始,直接选择html元素。"/"在XPath中表示绝对路径的起点。
- 选择子元素
xpath
/html/body这个表达式从根开始,先选择html元素,然后选择其直接子元素body。每个"/"表示下降一级,只会选择直接子元素,不会跨级选择。

- 选择任意位置的元素
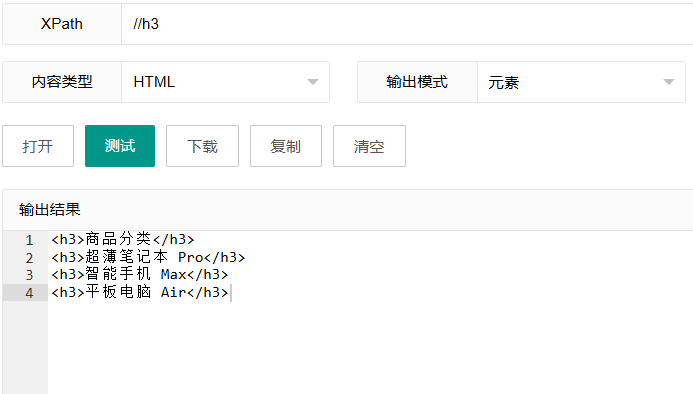
xpath
//h3这个表达式使用双斜杠"//",表示"无论在文档中的什么位置",选择所有的h3元素。"//"是一个非常强大的选择器,但使用时要注意它会搜索整个文档,可能影响性能。
两种斜杠的区别解析:
- 单斜杠"/":表示选择直接子元素(只走一步)
- 双斜杠"//":表示选择任意深度的后代元素(可以走多步)
3. 基本选择器
3.1 选择特定元素
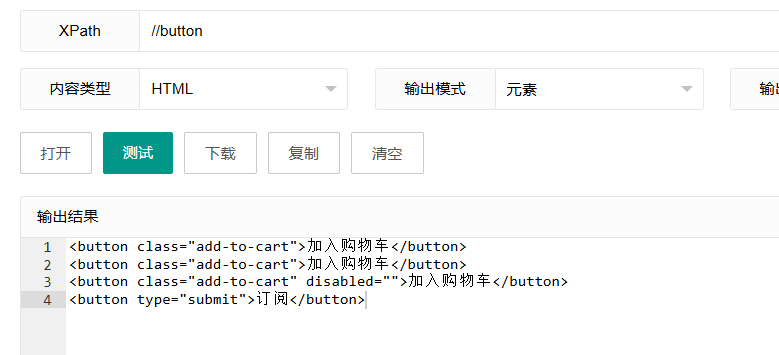
xpath
//button这将选择页面中所有的button元素,无论它们在文档的什么位置。
工作原理: 双斜杠"//"开始表示从文档的任意位置查找,后面跟着元素名"button"表示我们要查找的是button标签元素。
使用场景: 当你需要获取页面上所有的按钮,比如进行批量事件绑定或检查按钮状态时。
3.2 选择特定路径上的元素
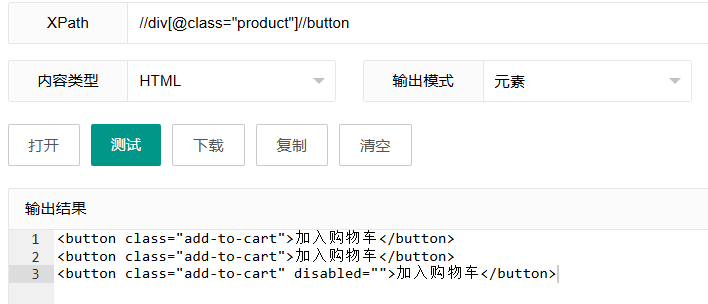
xpath
//div[@class="product"]//button这个表达式分两步工作:
- 首先找到所有class属性为"product"的div元素
- 然后在这些div元素内部查找所有button元素
表达式解析:
//div[@class="product"]:选择特定class的div元素[@class="product"]:方括号内是筛选条件,这里是属性选择器//button:在前面结果的上下文中查找任何button元素
使用场景: 当你只想选择特定区域内的元素,而不是页面上所有相同类型的元素时。比如只想获取产品卡片中的"加入购物车"按钮,而不是页面上的所有按钮。
3.3 通配符选择
xpath
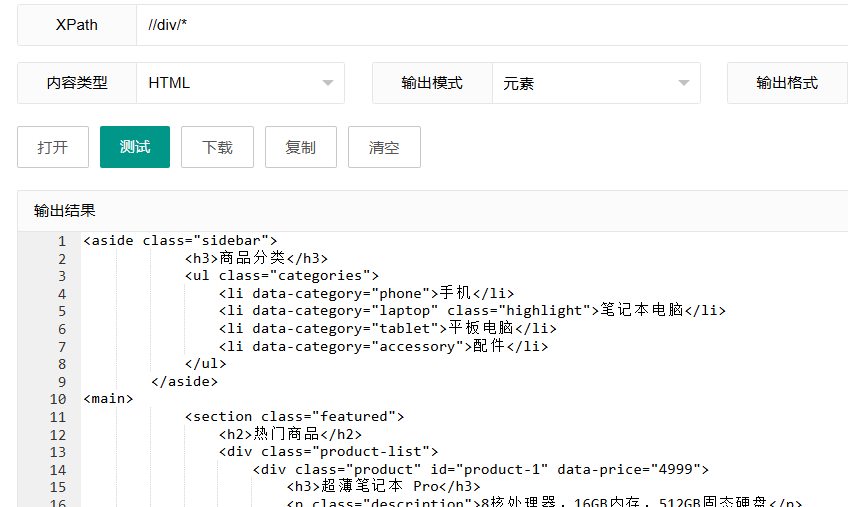
//div/*星号"*"是通配符,表示"任何元素"。这个表达式选择所有div元素的所有直接子元素,无论它们是什么标签。
为什么使用通配符: 当你关心元素的位置或层级关系,而不关心具体的标签名时,通配符非常有用。
工作原理:
//div:找到所有div元素/*:选择这些div元素的所有直接子元素(只下降一级)
使用场景: 当你需要获取特定容器内的所有直接子元素,而不关心它们的具体标签类型时。
4. 属性选择器
4.1 选择具有特定属性的元素
xpath
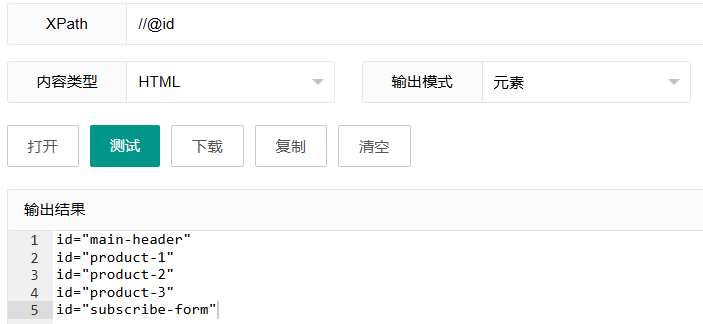
//@id这个表达式使用"@"符号来选择属性节点。它会选择文档中所有具有id属性的节点的属性值。
"@"符号的作用: 在XPath中,@符号专门用于指代属性,无论是选择属性本身还是根据属性筛选元素。
使用场景: 当你需要提取页面上所有具有特定属性的元素的属性值时,比如收集所有ID值或检查属性分布情况。
4.2 选择特定属性值的元素
xpath
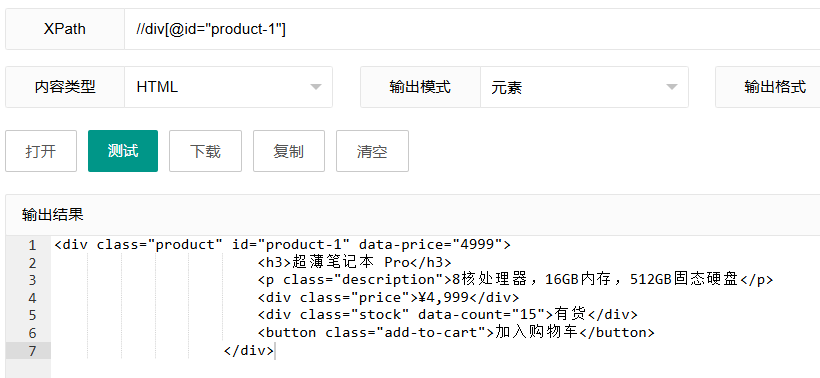
//div[@id="product-1"]这个表达式选择id属性值恰好等于"product-1"的div元素。
表达式解析:
//div:选择所有div元素[@id="product-1"]:方括号内的条件筛选出id等于"product-1"的元素
使用场景: 当你需要精确定位具有唯一标识符的元素时。ID选择器通常是定位特定元素最快、最可靠的方法,因为ID在整个文档中应该是唯一的。
4.3 选择具有特定属性的元素(无论值是什么)
xpath
//button[@disabled]这个表达式选择所有具有disabled属性的按钮元素,不管这个属性的值是什么(甚至可以是空值)。
工作原理: 当方括号中只有@属性名而没有等于某个值的条件时,XPath会选择所有具有该属性的元素,不考虑属性值。
使用场景: 当你需要找出所有被禁用的按钮,或查找所有具有特定HTML5自定义数据属性的元素时非常有用。

5. 条件表达式
5.1 使用条件选择元素
xpath
//div[@class="product" and @data-price > 3000]这个表达式使用"and"逻辑运算符结合两个条件,选择同时满足:
- class属性为"product"
- data-price属性值大于3000
的div元素。
工作原理:
@class="product":第一个条件,检查class属性and:逻辑与操作符,要求两边条件都满足@data-price > 3000:第二个条件,进行数值比较
使用场景: 当你需要基于多个条件过滤元素时,例如在电商网站上查找价格在特定范围内且属于特定类别的产品。

5.2 使用or条件
xpath
//div[@id="product-1" or @id="product-3"]这个表达式使用"or"逻辑运算符,选择id为"product-1"或id为"product-3"的div元素。
表达式解析:
@id="product-1":第一个条件or:逻辑或操作符,满足任一条件即可@id="product-3":第二个条件
使用场景: 当你需要同时处理多个不相关但结构相似的元素时。例如,想同时获取第一个和最后一个产品的信息进行比较。

5.3 使用not函数
xpath
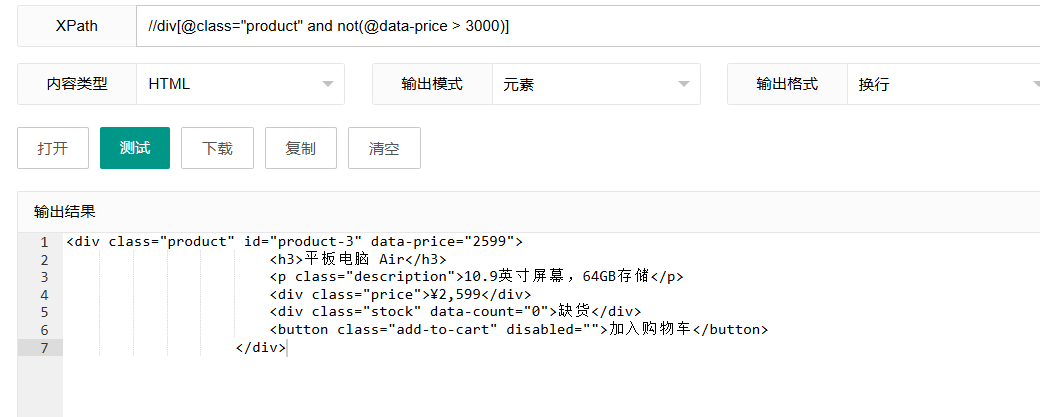
//div[@class="product" and not(@data-price > 3000)]这个表达式使用"not()"函数来否定条件,选择data-price属性不大于3000的div元素。
工作原理:
not():逻辑否定函数,对括号中的表达式结果取反@data-price > 3000:被否定的条件
使用场景: 当你需要排除某些元素时。例如,找出所有非高价产品,或者所有未标记为特殊状态的元素。
注意: not函数可以与任何条件表达式组合使用,非常灵活。
6. 位置选择器
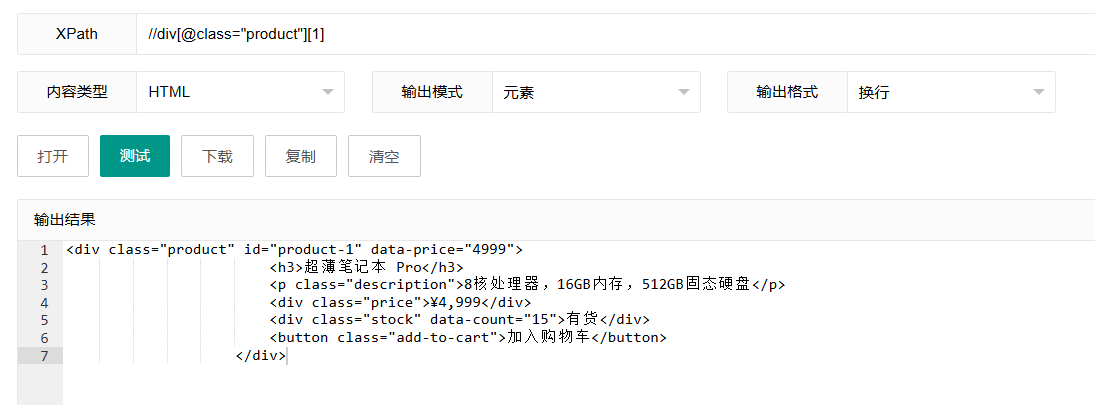
6.1 选择第一个元素
xpath
//div[@class="product"][1]这个表达式选择第一个class为"product"的div元素。
表达式解析:
//div[@class="product"]:选择所有class为"product"的div元素[1]:方括号中的数字表示位置索引,从1开始计数(不是从0开始)
特别注意: XPath中的索引是从1开始的,这与大多数编程语言从0开始索引不同。
使用场景: 当你只关心匹配元素集合中的第一个时,比如获取第一个产品信息或处理列表中的第一项。
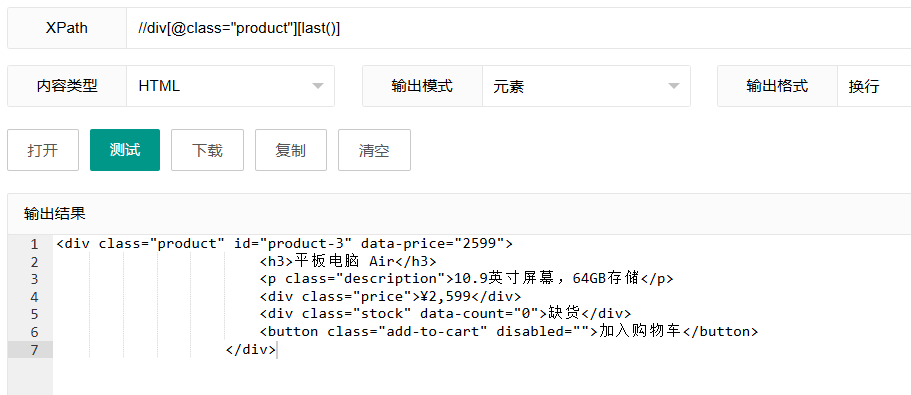
6.2 选择最后一个元素
xpath
//div[@class="product"][last()]这个表达式使用"last()"函数选择最后一个class为"product"的div元素。
工作原理:
last():是一个XPath函数,返回当前上下文节点集合的大小(即节点数量)[last()]:选择索引等于这个大小的元素,也就是最后一个元素
使用场景: 当你需要获取列表或集合中的最后一个元素时,比如获取最新添加的项目或列表底部的元素。
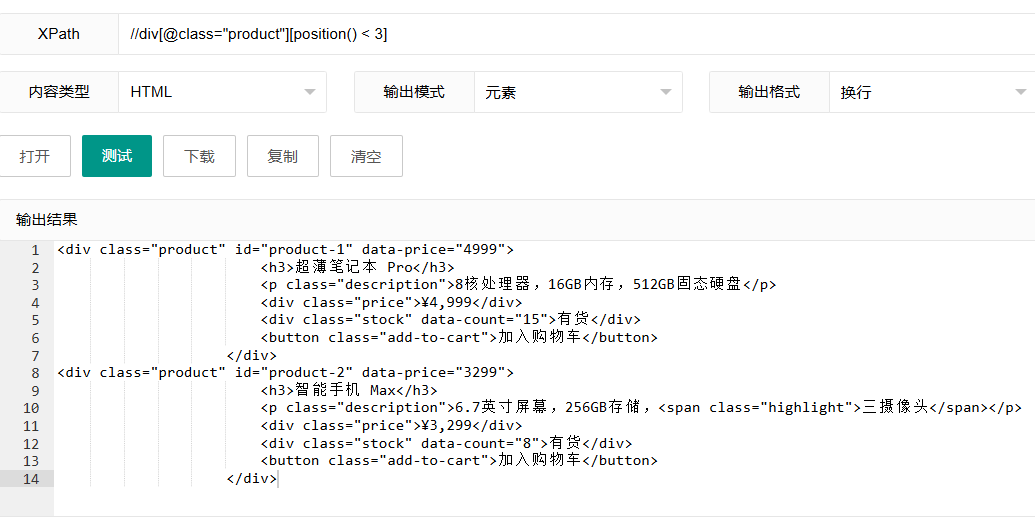
6.3 选择特定位置范围的元素
xpath
//div[@class="product"][position() < 3]这个表达式使用"position()"函数选择前两个class为"product"的div元素。
表达式解析:
position():返回当前节点在其上下文中的位置(从1开始)position() < 3:选择位置小于3的节点,即第1个和第2个元素
使用场景: 当你需要处理集合中的一个子集,如前N个元素、特定范围内的元素等。例如,只显示搜索结果的前几项,或者分页显示内容的某一页。
7. 文本内容选择
7.1 选择包含特定文本的元素
xpath
//p[contains(text(), "英寸")]这个表达式使用"contains()"函数选择文本内容中包含"英寸"的p元素。
工作原理:
text():是一个函数,返回当前节点的文本内容contains(字符串1, 字符串2):检查字符串1是否包含字符串2,返回布尔值- 整体效果:选择文本内容中包含指定子串的元素
使用场景: 当你需要根据文本内容的部分匹配来定位元素时。例如,查找包含特定关键词的段落,或者找到描述中提到某个特性的产品。

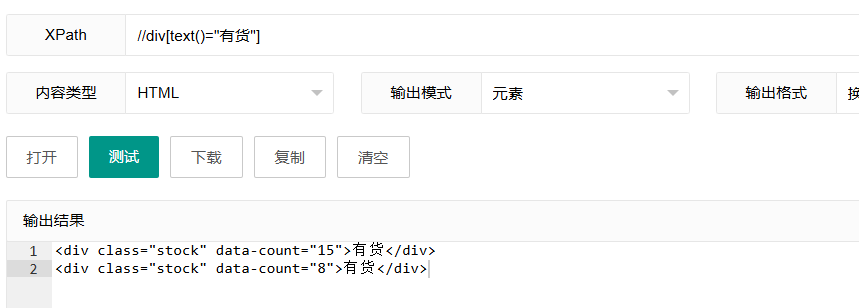
7.2 选择完全匹配文本的元素
xpath
//div[text()="有货"]这个表达式选择文本内容完全等于"有货"的div元素。
表达式解析:
text():获取元素的文本内容text()="有货":要求文本内容精确等于"有货",不多不少
"contains"与精确匹配的区别:
contains(text(), "有货"):会匹配"有货"、"现在有货"、"有货商品"等text()="有货":只会匹配恰好是"有货"的文本,更加严格
使用场景: 当你需要精确匹配元素的全部文本内容时。例如,找出显示特定状态的元素,或者根据精确的标签文本定位按钮。
8. XPath轴
XPath轴用于定义相对于当前节点的节点集。它们让我们能够基于元素之间的关系进行导航,比如父子关系、兄弟关系等。
8.1 子节点轴
xpath
//aside/child::h3这个表达式使用"child"轴选择所有aside元素的h3子元素。
工作原理:
//aside:首先选择所有aside元素/child:::指定接下来要使用child轴(表示直接子元素)h3:指定要选择的子元素类型
等价表达式: //aside/h3 与 //aside/child::h3 效果相同,因为默认轴就是child。
使用场景: 当你需要明确指定要查找直接子元素(而非后代元素)时。在复杂的XPath表达式中,显式指定轴可以提高可读性。

8.2 父节点轴
xpath
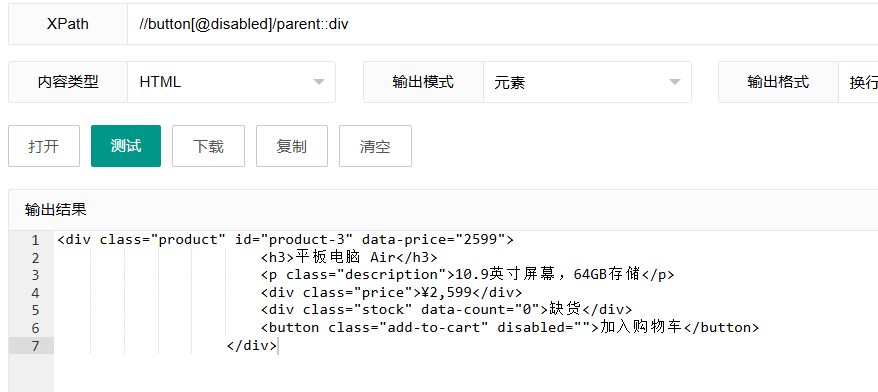
//button[@disabled]/parent::div这个表达式使用"parent"轴,选择拥有disabled按钮的父div元素。
表达式解析:
//button[@disabled]:首先选择所有具有disabled属性的button元素/parent:::指定要沿父节点轴移动div:指定父节点必须是div元素
使用场景: 当你已知子元素的特征,需要获取其父元素进行操作时。例如,找到包含特定输入框的表单,或者包含特定按钮的容器。
8.3 兄弟节点轴
xpath
//h3[text()="智能手机 Max"]/following-sibling::p这个表达式使用"following-sibling"轴,选择标题为"智能手机 Max"后面的p元素兄弟节点。
工作原理:
//h3[text()="智能手机 Max"]:先选择文本是"智能手机 Max"的h3元素/following-sibling:::指定要查找的是后续的兄弟元素p:指定兄弟节点的类型为p元素
与之对应的轴: 还有preceding-sibling::轴,用于选择之前的兄弟节点。
使用场景: 当元素之间有明确的顺序关系,你需要基于某个已知元素找到其相邻元素时。例如,找到标题下方的描述段落,或者表格中某个单元格旁边的单元格。

8.4 祖先节点轴
xpath
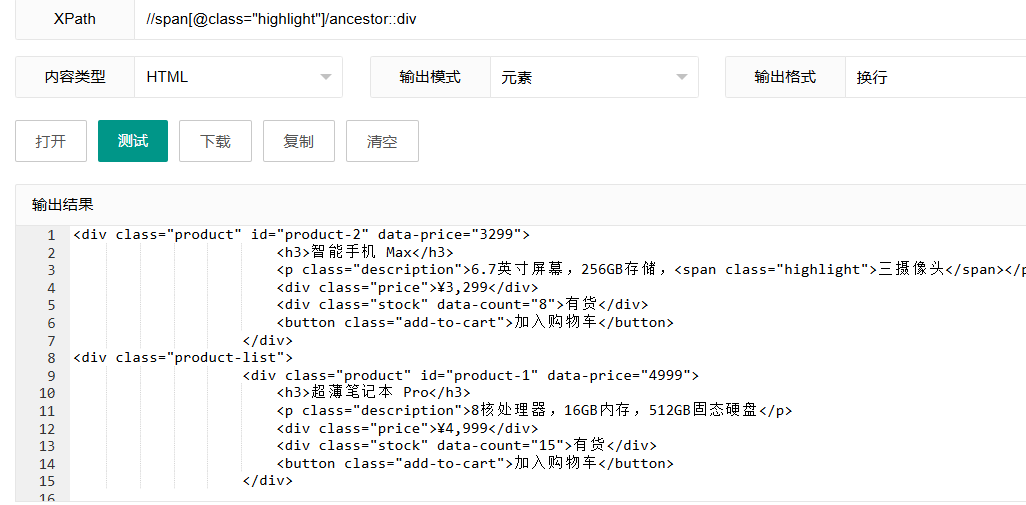
//span[@class="highlight"]/ancestor::div这个表达式使用"ancestor"轴,选择带有highlight类的span元素的所有div祖先元素。
表达式解析:
//span[@class="highlight"]:选择class为"highlight"的span元素/ancestor:::指定要查找的是所有祖先节点div:只选择类型为div的祖先节点
ancestor与parent的区别:
parent:::只选择直接父节点(上一级)ancestor:::选择所有层级的祖先节点(父节点、祖父节点等)
使用场景: 当你需要向上遍历DOM树,找到特定元素所在的容器或上下文时。例如,找到包含特定元素的最近的div容器,或者判断元素是否位于特定区域内。
8.5 后代节点轴
xpath
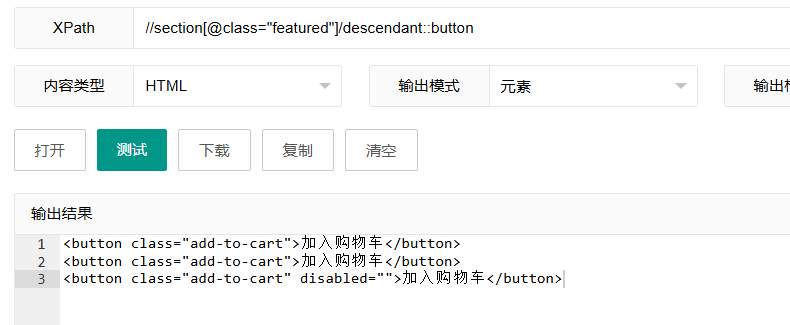
//section[@class="featured"]/descendant::button这个表达式使用"descendant"轴,选择featured部分的所有button后代元素。
工作原理:
//section[@class="featured"]:选择class为"featured"的section元素/descendant:::指定要查找的是所有后代节点button:只选择类型为button的后代节点
与child轴的区别:
child:::只选择直接子节点(下一级)descendant:::选择所有层级的后代节点(子节点、孙节点等)
简写形式: //section[@class="featured"]//button 等价于使用descendant轴,双斜杠"//"隐含了descendant-or-self轴的含义。
使用场景: 当你需要查找容器内的所有特定类型元素,不管它们的嵌套深度如何时。例如,找出特定部分中的所有按钮或链接。
9. XPath函数
9.1 字符串函数
9.1.1 contains()函数
xpath
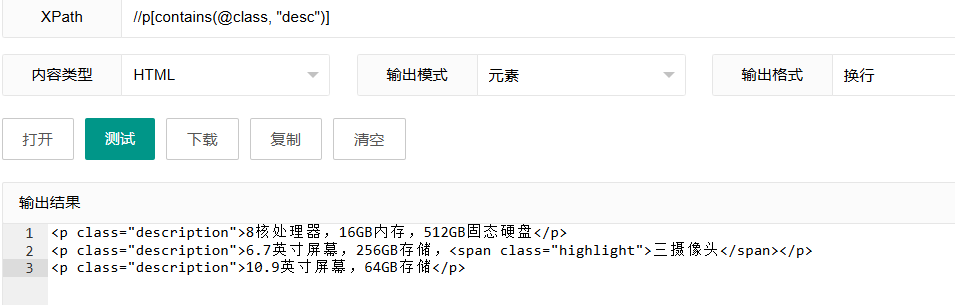
//p[contains(@class, "desc")]这个表达式使用"contains()"函数,选择class属性中包含"desc"子字符串的p元素。
函数详解:
contains(字符串1, 字符串2):检查字符串1是否包含字符串2- 这里检查
@class属性值是否包含"desc"
使用场景: 当元素的属性值可能包含多个值或部分匹配时非常有用。例如,查找包含特定CSS类的元素,或者URL中包含特定参数的链接。
特点: 部分匹配,不区分大小写(取决于XML解析器的设置)。
9.1.2 starts-with()函数
xpath
//a[starts-with(@href, "/guide")]使用场景: 当你需要匹配属性值的前缀时非常有用。例如,找出指向特定目录的所有链接,或者筛选以特定字符开头的ID。在处理有明确命名规则的元素时尤为实用。
与contains()的区别:
contains():检查是否包含子字符串,子字符串可以出现在任何位置starts-with():更严格,要求子字符串必须位于开头位置
补充函数: XPath 2.0还提供了ends-with()函数用于检查字符串结尾,但在XPath 1.0中不可用。

9.2 数值函数
9.2.1 使用数值比较
xpath
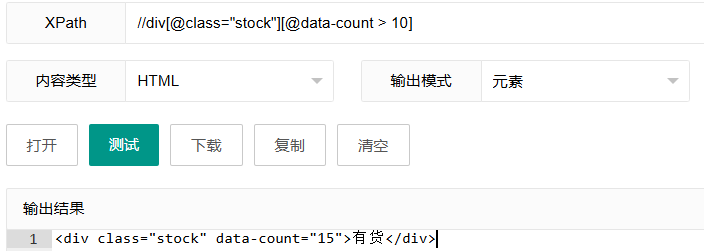
//div[@class="stock"][@data-count > 10]这个表达式选择class为"stock"且data-count属性值大于10的div元素。
表达式解析:
//div[@class="stock"]:首先选择class为"stock"的div元素[@data-count > 10]:添加数值比较条件,筛选data-count大于10的元素
XPath中的数值转换: 当在XPath表达式中使用比较运算符(>、<、>=、<=)时,会尝试将操作数转换为数值。如果无法转换,则使用特定的转换规则或报错。
使用场景: 当需要基于数值属性进行筛选时。例如,选择库存数量超过特定值的产品,或者价格在特定范围内的商品。
注意事项: 确保比较的值能正确转换为数值,否则比较可能产生意外结果。
9.3 组合函数
xpath
//div[number(@data-price) > 3000]/h3这个表达式使用number()函数将属性值转换为数值,然后进行比较,最后选择价格超过3000的商品标题。
表达式详解:
number(@data-price):将data-price属性值显式转换为数值> 3000:数值比较条件/h3:选择满足条件的div元素下的h3子元素
为什么使用number()函数:
- 确保属性值被正确地解释为数字
- 处理可能包含非数字字符的属性值
- 提高表达式的可读性和明确性
使用场景: 当需要对属性值进行复杂数值处理或转换时。例如,处理带有货币符号的价格值,或者需要确保正确的数值比较。

10. 实际应用场景
让我们通过几个实际应用场景来巩固所学知识,这些场景直接对应到网页数据提取和自动化测试的常见需求:
10.1 提取所有商品名称
xpath
//div[@class="product"]/h3/text()这个表达式用于提取所有商品的名称文本。
表达式解析:
//div[@class="product"]:定位所有产品容器元素/h3:找到每个产品容器中的h3标题元素/text():提取h3元素的文本内容
text()函数的作用: 返回元素的文本节点,不包括HTML标签。这在数据提取时非常有用,可以直接获取文本内容而不是整个HTML结构。
使用场景: 爬虫场景中,需要提取网页上所有产品名称进行分析或保存。
注意: 在某些XPath实现中,text()可能返回节点列表而非合并的文本字符串。

10.2 提取所有有货商品的价格
xpath
//div[.//div[@class="stock" and text()="有货"]]//div[@class="price"]/text()这个表达式选择所有有货商品的价格文本。
表达式详细解析:
//div[...]:查找满足括号内条件的div元素.//div[@class="stock" and text()="有货"]:点号(.)表示当前上下文,这部分查找当前div内的stock类div元素,且其文本为"有货"//div[@class="price"]:在满足条件的div内查找class为"price"的div/text():提取价格文本
点号(.)的作用: 表示当前节点上下文,这里用于限定搜索范围在当前div元素内部。
使用场景: 电商网站数据分析,需要获取所有可购买商品的价格进行市场分析或价格比较。

10.3 找出所有缺货商品
xpath
//div[.//div[@class="stock" and text()="缺货"]]这个表达式查找包含"缺货"状态标签的所有商品div。
表达式解析:
//div:查找所有div元素[.//div[@class="stock" and text()="缺货"]]:筛选条件,要求div内部存在class为"stock"且文本内容为"缺货"的div子元素
嵌套条件的工作原理: 方括号中可以包含完整的XPath表达式作为条件,这里的条件是"包含特定子元素"。
使用场景: 库存管理系统,需要快速识别缺货商品进行补货或调整显示。
10.4 获取导航菜单项
xpath
//nav[@class="main-nav"]//li/a/text()这个表达式获取主导航栏中所有菜单项的文本内容。
表达式解析:
//nav[@class="main-nav"]:定位类名为"main-nav"的导航元素//li:在导航元素内寻找所有列表项/a:选择列表项的直接子元素a(链接)/text():提取链接文本
使用场景: 网站地图生成、导航结构分析,或测试导航菜单是否包含预期的所有项目。
提示: 这种结构化数据提取是XPath最常见的应用之一,特别适合具有清晰HTML结构的网站。
11. XPath调试技巧
11.1 分步构建复杂表达式
当你需要构建复杂的XPath表达式时,建议从简单部分开始,逐步添加条件。这种增量开发的方法可以帮助你更容易地发现和修复问题。
具体步骤演示:
- 先找到大致区域:
xpath
//div[@class="product-list"]首先确定你要操作的大区域,确保这部分能正确选中。
- 再定位具体元素:
xpath
//div[@class="product-list"]/div在确定的区域内,进一步缩小范围到具体元素类型。
- 最后添加条件:
xpath
//div[@class="product-list"]/div[@data-price > 3000]在确保前两步正确的基础上,添加具体的筛选条件。
调试建议:
- 每添加一个条件,就测试一次表达式
- 如果某步结果不符合预期,立即进行调整
- 使用元素计数(
$x('xpath表达式').length)快速验证结果数量
11.2 使用Chrome开发者工具的Elements面板
Chrome开发者工具提供了快速生成和测试XPath的功能,可以大大提高开发效率:
-
快速生成XPath:
- 在Elements面板中右键点击元素
- 选择"Copy" -> "Copy XPath"
- 浏览器会生成一个可以唯一识别该元素的XPath表达式
-
浏览器自动生成的XPath特点:
- 通常使用绝对路径和索引
- 可能很长且可读性不高
- 可能过于具体,不适合动态页面
-
优化自动生成的XPath:
- 移除不必要的索引和层级
- 使用ID、class等属性替换复杂路径
- 测试简化后的XPath是否仍然唯一匹配目标元素
11.3 使用XPath Helper插件
Chrome扩展商店提供的XPath Helper插件可以实时测试和高亮显示XPath表达式匹配的元素:
-
安装插件后的使用方法:
- 点击工具栏的XPath Helper图标激活
- 在输入框中输入XPath表达式
- 页面上会高亮显示匹配的元素
- 下方会显示匹配元素的数量和详情
-
实时测试的优势:
- 直观看到匹配结果,不需要在控制台切换
- 支持高亮显示,便于验证是否选中了正确的元素
- 提供结果计数和节点信息
12. XPath常见问题与解决方案
12.1 处理动态生成的内容
问题描述:现代网站大量使用JavaScript动态加载内容,导致XPath可能无法立即找到元素。
解决方案:
- 使用等待机制:
javascript
// 使用JavaScript等待元素出现
function waitForElement(xpath, timeout = 5000) {
const startTime = new Date().getTime();
return new Promise((resolve, reject) => {
const checkExist = setInterval(() => {
const element = document.evaluate(xpath, document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue;
if (element) {
clearInterval(checkExist);
resolve(element);
} else if (new Date().getTime() - startTime > timeout) {
clearInterval(checkExist);
reject(new Error(`元素未在${timeout}ms内出现: ${xpath}`));
}
}, 100);
});
}
// 使用方法
waitForElement('//div[@id="dynamic-content"]')
.then(element => console.log('找到元素:', element))
.catch(error => console.error(error));-
观察DOM变化:
- 使用MutationObserver API监听DOM变化
- 在变化回调中执行XPath查询
- 适合监听动态加载的列表或内容区域
-
检查XPath表达式正确性:
- 确认元素是否真的存在于DOM中(可能在iframe内)
- 使用浏览器开发者工具的Elements面板检查元素实际结构
- 考虑元素可能有动态生成的属性或类名
12.2 处理iframe中的内容
问题描述:iframe创建独立的文档上下文,标准XPath无法直接跨越iframe边界。
解决方案:
- 切换到iframe上下文:
javascript
// 获取iframe文档对象
let iframe = document.getElementById('my-iframe');
let iframeDocument = iframe.contentDocument || iframe.contentWindow.document;
// 在iframe文档上下文中执行XPath
let result = document.evaluate('//div[@class="product"]', iframeDocument, null, XPathResult.ANY_TYPE, null);
let node = result.iterateNext();
while (node) {
console.log(node);
node = result.iterateNext();
}-
在自动化测试框架中:
- Selenium:
driver.switchTo().frame("frameName") - Cypress:
cy.frameLoaded('#iframe-id').iframe().find('元素')
- Selenium:
-
使用JavaScript跨iframe通信:
- 如果有多层iframe嵌套,可能需要递归查找
- 注意同源策略限制,不同域的iframe可能无法直接访问
12.3 XPath性能优化
问题描述:XPath表达式效率低下可能导致页面响应缓慢,尤其是在大型文档上。
优化策略:
-
避免使用
//开头的XPath:- 不推荐:
//div[@class="product"] - 推荐:
/html/body//div[@class="product"]或使用ID缩小范围
- 不推荐:
-
尽量使用具体元素名称而非
*:- 不推荐:
//*[@id="product-1"] - 推荐:
//div[@id="product-1"]
- 不推荐:
-
使用ID和class等唯一标识符缩小搜索范围:
- 不推荐:
//div//button[text()="加入购物车"] - 推荐:
//div[@id="product-1"]//button
- 不推荐:
-
使用索引而非文本匹配(当适用时):
- 不推荐:
//div[contains(text(), "很长的文本内容")] - 推荐:
//div[@class="product"][1](如果索引稳定)
- 不推荐:
-
合理使用轴选择器:
- 对前向轴(parent, ancestor等)的使用要谨慎,它们通常性能较低
性能比较示例:
xpath
//div//p//span <!-- 最慢,搜索整个文档 -->
/html/body//div[@class="main"]//span <!-- 较快,限定了范围 -->
//div[@id="container"]//span <!-- 更快,使用ID直接定位 -->
id("container")//span <!-- 最快,使用id()函数 -->13. 高级XPath技巧
13.1 使用索引动态选择元素
xpath
//div[@class="product"][position() mod 2 = 1]这个表达式使用取模运算mod来选择位置是奇数的产品元素。
表达式详解:
position():返回当前节点在当前上下文的位置mod:取模运算符,返回除法的余数position() mod 2 = 1:位置除以2余数为1,即选择奇数位置的节点
使用场景:
- 实现隔行选择(如表格的隔行着色)
- 批处理数据时分组选择元素
- 实现分页逻辑(如选择第n页的元素)
注意事项:XPath支持基本的算术运算(+, -, *, div, mod)和比较运算,可以组合使用创建复杂条件。
13.2 使用多重条件
xpath
//div[contains(@class, "product") and (.//div[@class="price"]/text() = "¥2,599" or .//div[@class="stock" and @data-count="0"])]这个复杂表达式演示了如何使用多重嵌套条件进行精确选择。
表达式解析:
- 主要条件:
contains(@class, "product"),选择类名包含"product"的div - 子条件组:用括号
()分组,包含两个条件- 条件1:
.//div[@class="price"]/text() = "¥2,599",价格为¥2,599 - 条件2:
.//div[@class="stock" and @data-count="0"],有库存为0的标记 - 两个条件用
or连接,满足任一即可
- 条件1:
逻辑运算符优先级:
- 在XPath中,
and的优先级高于or - 使用括号
()可以改变运算顺序,提高表达式的可读性
使用场景:当需要基于多个复杂条件组合进行元素筛选时,如复合搜索条件或多因素过滤。
13.3 使用normalize-space()处理空白
xpath
//button[normalize-space(text()) = "加入购物车"]这个表达式使用normalize-space()函数来处理文本中的空白字符,使匹配更加鲁棒。
函数详解:
normalize-space():删除字符串前后的空白,并将内部连续的空白字符替换为单个空格normalize-space(" Hello World ")会返回"Hello World"
应用场景:
- 处理HTML源码中格式化导致的额外空白
- 匹配可能包含不可见空白字符的文本内容
- 确保文本匹配不受空白格式影响
为什么重要 :网页中的实际文本常常包含额外的空白字符,尤其是经过格式化的HTML代码,使用normalize-space()可以增强XPath表达式的健壮性。
13.4 组合使用轴和函数
xpath
//h3[contains(text(), "笔记本")]/ancestor::div[1]/descendant::button[not(@disabled)]这个高级表达式结合使用轴和函数,实现了"找到标题包含'笔记本'的产品区域内的可用按钮"。
表达式详解:
//h3[contains(text(), "笔记本")]:找到文本包含"笔记本"的标题/ancestor::div[1]:向上选择最近的div祖先(产品容器)/descendant::button:在该容器中查找所有按钮后代[not(@disabled)]:筛选没有disabled属性的按钮
高级技巧解析:
- 使用
ancestor::div[1]而非简单的/parent::,确保选中整个产品卡片 - 使用索引
[1]限制只选择最近的祖先,避免选中更高层级的容器 - 结合使用
descendant轴和not()函数进行复杂筛选
使用场景:复杂的网页交互自动化,需要精确定位特定上下文中的可操作元素。
结语
通过这个实际的HTML示例,我们全面学习了XPath的语法和用法,从基础选择器到高级函数和轴,从理论到实际操作验证。我希望这个系统性的教程能帮助你真正理解XPath的工作原理和强大之处。
XPath不仅是网络爬虫和自动化测试的重要工具,它还广泛应用于XML数据处理、配置文件操作和各种结构化数据的提取场景。掌握XPath的各种技巧将大大提高你处理结构化文档的能力。
记住,XPath的学习和任何编程技能一样,需要通过实践来巩固。我建议你:
- 在自己的项目中尝试使用XPath
- 探索更复杂的网页结构并编写XPath提取数据
- 比较不同XPath表达式的性能和可维护性
- 结合自动化测试框架(如Selenium)实践XPath
如有任何问题或需要进一步探讨某个XPath概念,欢迎在评论区留言交流!祝你在数据提取和网页自动化的道路上取得成功!