参考:How to get the best results from Stable Diffusion 3
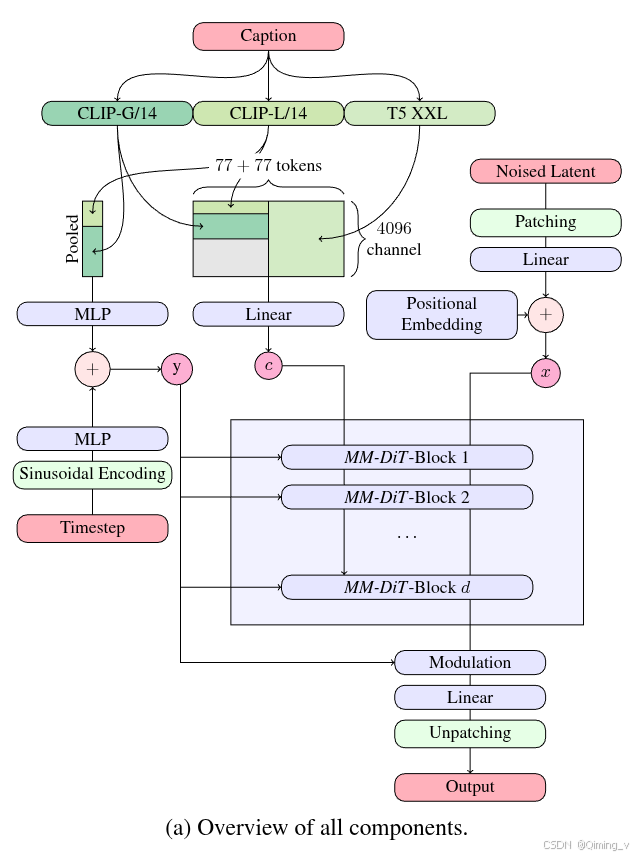
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
prompting
SD3 不再受限于CLIP的最长77个token的长度限制,可以输入更长的prompt。
(两个CLIP模型的最大序列长度为77,T5可以不限制长度)
使用更长更清晰的prompt,可以生成更符合要求的图片。
但是,更长且复杂的prompt,可能会导致model注意不到某些内容。
不使用negative prompt
SD3 训练的时候没有使用negative prompt。所以negative prompt 也不会达到期望的效果。
在实际中,negative prompt更像是在条件中添加了噪声,改变了生成的结果。
Prompting techniques
可以使用表达清楚的英文句子,也可以使用逗号分隔的关键词。
但是一定要清晰明确的描述。
Width and height
与SDXL类似,SD3在100万像素时有最好的输出效果。Width and height 必须是64的倍数。
- 1:1 - 1024 x 1024 (Square images)
- 16:9 - 1344 x 768 (Cinematic and widescreen)
- 21:9 - 1536 x 640 (Cinematic)
- 3:2 - 1216 x 832 (Landscape aspect ratio)
- 2:3 - 832 x 1216 (Portrait aspect ratio)
- 5:4 - 1088 x 896 (Landscape aspect ratio)
- 4:5 - 896 x 1088 (Portrait aspect ratio)
- 9:16 - 768 x 1344 (Long vertical images)
- 9:21 - 640 x 1536 (Very tall images)
在SD1.5和SDXL中,如果分辨率大于训练使用的分辨率,就会出现扭曲、多个头、重复等等现象。
在SD3不会出现这样的情况。在SD3中,会出现中间合理,但是边缘有重复伪影的情况。
如果输出分辨率太小,那么就会被crop。
settings
一些经验设置:
- 28 steps
- 3.5 -- 4.5 CFG
- dpmpp_2m sampler with the sgm_uniform scheduler
- 3.0 shift
steps
在SDXL中,steps一般在20左右,Lightning 版在4左右。
在SD3中,推荐使用28,能得到清晰并且没有伪影的图片,生成时间也不会太长。
SD3通常在8到10步就能生成一张看着还行的图片,尽管有伪影和局部不一致。这也和prompt和seed有关。随着步数的增加,能得到更好的图片,最佳的步数是26至36步。
CFG
SD3需要使用比SD1.5和SDXL都低的CFG,推荐使用3.5到4.5.
特别指出,CFG的值越低,不同的text encoder(T5、T5 fp16、T5fp8或者不用),输出的结果越相似。
如果使用很低的CFG,可以不用T5,对结果的影响也很小。
Sampler and scheduler
在comfyui中,SD3推荐使用dpmpp_2m 和sgm_uniform。
在Automatic1111中,dpm++ 2M 或者 Euler。
一些Sampler和scheduler在SD3中可能不起作用,比如 ancestral 和 sde 采样,以及在SDSXL中很流行的karras。
Shift
shift是SD3中的一个新参数,代表了timestep scheduling 偏移。在更高的分辨率上使用更大的shift可以更好的管理噪声。
使用shift可以更好的管理噪声,生成更好看的图像。
shift等于3.0 是人类偏好评估的最佳值,当然你也可以修改shift。
6.0 的偏移值在人工评估中得分较高,值得一试。如果使用较低的值(如 2.0 或 1.5),则可以获得更原始且"处理程度较低"的图像,这对于某些提示非常有效。
假设在不同的分辨率情况下,模型处理的噪声对信号的"破坏"是相等的,也就是含噪图像恢复到原始图像的误差标准差是相等的,这样才能保证训练和采样的稳定性。
对于高分辨率图像,更多的像素值提供了更多的观测点,使得误差的标准差减小。
对于低分辨率图像,更少的采样点导致标准差增大。
为了保证训练的稳定一致,需要在高分辨率的情况下,增大标准差,以补偿像素增多带来的噪声平均效应,从而维持与低分辨率相同的不确定性。
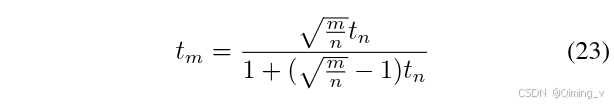
对应的代码
python
sigmas = shift * sigmas / (1 + (shift - 1) * sigmas)SD3的主要结构