Training Large Networks in Parallel
计算机集群上高效训练大型深度神经网络(DNN)的方法和技术。从神经网络的基本概念出发,逐步深入到并行训练的具体实现策略,包括数据并行、模型并行以及参数服务器的设计等。
研究背景与动机
- 大型神经网络的挑战:现代深度神经网络(DNN)包含数百万甚至数十亿的参数,训练这些网络需要大量的计算资源和时间。例如,VGG-16网络的参数需要约500MB的内存,而训练过程可能需要数天时间。
- 并行训练的需求:为了加速训练过程,研究人员探索了在多个计算节点上并行训练DNN的方法。这不仅可以减少训练时间,还可以扩展到更大的数据集和更复杂的模型。
神经网络基础
- 教授分类任务:文章通过一个简单的例子引入了神经网络的基本概念,即根据教授的外貌特征将其分类为"容易"、"刻薄"、"无聊"或"书呆子"。
- 网络结构:介绍了神经网络的基本结构,包括卷积层、最大池化层和全连接层。文章中提到的模型包含多个卷积层和全连接层,每层的神经元数量分别为253440、186624、64896、64896、43264、4096、4096和1000。
- 训练目标:训练的目标是最小化网络输出与真实标签之间的损失函数。文章中使用了softmax损失函数作为示例。
梯度下降与反向传播
- 梯度下降:介绍了梯度下降的基本思想,即通过调整网络参数以减少损失函数的值。文章通过一个简单的函数示例解释了如何使用梯度下降来优化参数。
- 反向传播:详细描述了反向传播算法,这是计算神经网络中每个参数梯度的关键步骤。文章通过图示和公式解释了如何通过链式法则计算梯度,并通过矩阵形式展示了反向传播的计算过程。
并行训练策略
- 数据并行:将训练数据分割成多个小批次(mini-batch),并将这些小批次分配给不同的计算节点。每个节点独立计算其分配数据的梯度,然后通过全局同步点(如参数服务器)汇总梯度并更新参数。
- 模型并行:当模型参数过多,无法在单个节点上存储时,可以将模型分割成多个部分,分别存储在不同的节点上。文章提到,通过使用小尺寸卷积(如1x1卷积)和减少全连接层的大小,可以减少节点间的通信量。
- 参数服务器:介绍了参数服务器的设计,它负责存储全局参数,并接收来自各个工作节点的梯度更新。参数服务器可以被切分成多个部分,以减少单个服务器的负载。
异步执行与优化
- 异步更新:为了避免全局同步带来的延迟,文章提出了异步更新策略。在这种策略下,工作节点在计算梯度后立即将其发送给参数服务器,而无需等待其他节点完成计算。这种策略可以提高系统的吞吐量,但可能会对训练的收敛性产生影响。
- 分片参数服务器:为了进一步优化参数服务器的性能,文章提出了将参数服务器分片的策略。每个分片负责存储和更新一部分参数,从而减少了单个服务器的负载。
实验与结果
- FireCaffe实验:文章通过在Titan超级计算机上使用FireCaffe框架进行实验,展示了并行训练的加速效果。实验结果表明,在128个GPU上训练GoogLeNet时,与单GPU训练相比,可以实现47倍的加速,同时保持相同的准确率。
- 通信开销比较:文章还比较了使用参数服务器和使用减少树(reduction tree)进行梯度汇总的通信开销。结果显示,减少树在通信效率上具有优势。
DNN Accelerator Architectures 1
1. DNN加速器的核心问题
深度神经网络(DNN)的计算效率主要受限于内存访问瓶颈。由于DNN计算需要频繁读写数据(如权重、激活值和中间结果),内存访问(尤其是DRAM访问)成为主要的性能瓶颈。例如,AlexNet需要724M次MAC操作,但需要2896M次DRAM访问。
2. 内存访问瓶颈的解决方案
为了减少内存访问,DNN加速器通常采用以下策略:
- 本地内存层次结构:通过引入多级本地内存(如寄存器文件、全局缓冲区)来重用数据,减少对DRAM的访问。
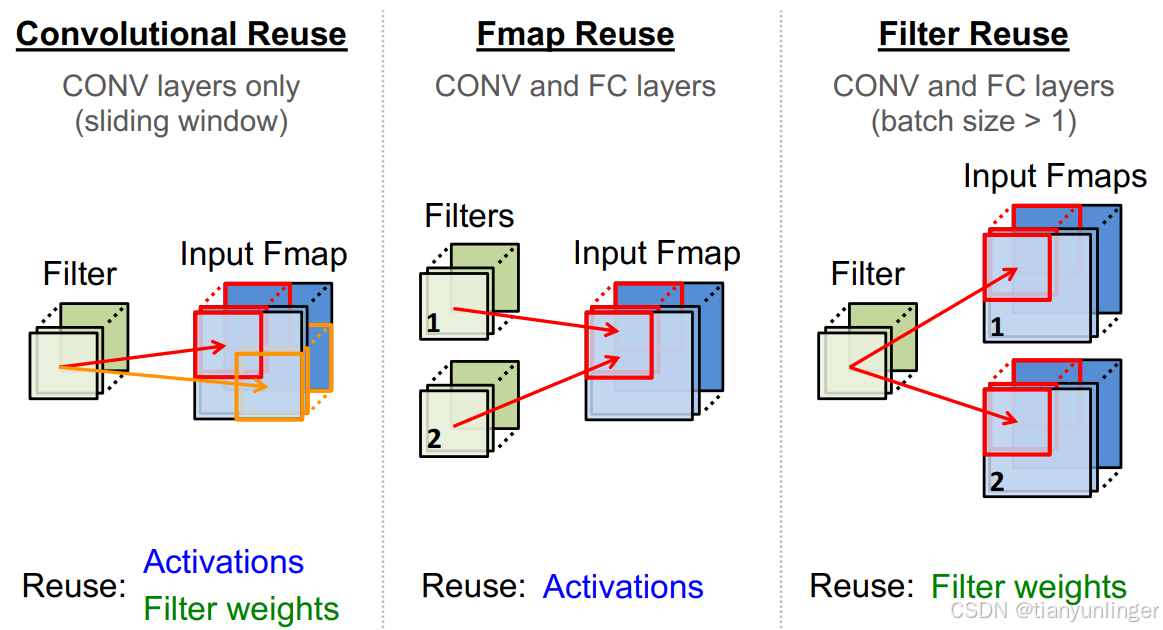
- 数据重用 :最大化数据的重用,例如:
- 卷积重用:在卷积层中利用滑动窗口技术。
- Fmap重用:在卷积层和全连接层中重用激活值。
- 滤波器重用 :在批量处理中重用滤波器权重。
3. DNN加速器的架构设计
- 空间架构:通过并行计算单元(PE)和片上网络(NoC)实现高效的数据流动。 PE单元负责执行基本的算术运算,而NoC负责PE单元之间的高效通信,两者协同工作以实现DNN加速器的整体性能提升。
- 多级内存访问:从DRAM到全局缓冲区,再到PE内的寄存器文件,每层访问成本差异显著。
4. 数据流分类
数据流的设计是DNN加速器的关键,主要分为以下三类:
- 输出 stationary(OS):最小化部分和的读写能耗,适合最大化本地累积。例如,ShiDianNao和ENVISION。
- 权重 stationary(WS):最小化权重读取能耗,适合最大化权重重用。例如,NeuFlow和NVDLA。
- 输入 stationary(IS):最小化激活读取能耗,适合最大化输入激活的重用。例如,SCNN。
5. 数据流的应用示例
- OS数据流:ShiDianNao通过保持输出特征图的部分和,减少对DRAM的访问。
- WS数据流:NVDLA通过保持权重,循环输入和输出特征图,减少权重的重复读取。
- IS数据流:SCNN利用稀疏CNN的特性,减少激活值的读取。
6. 并行计算的应用
并行计算在DNN加速器中通过以下方式实现:
- 任务并行:将计算任务分配到多个PE中并行执行。
- 数据并行:将数据分割成多个部分,分别在不同PE上处理。
7. 优化策略
- 内存优化:通过分层内存结构和数据重用,减少内存访问。
- 算法优化:选择适合硬件架构的算法,例如稀疏CNN。
- 硬件优化:利用高性能处理器和高速存储设备提升性能。
补充图表
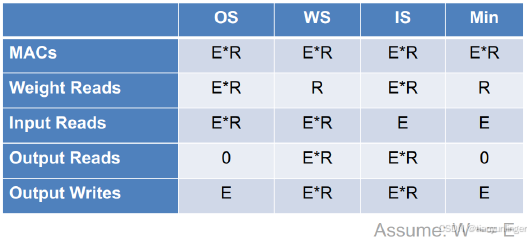
这个表格展示了不同数据流(Output Stationary (OS)、Weight Stationary (WS)、Input Stationary (IS))在执行1-D卷积操作时的性能指标对比。表格中的变量E和R分别代表输出长度和滤波器长度。以下是逐行解释:
-
MAC操作数:
- 所有数据流类型(OS、WS、IS)的MAC操作数都是E*R(E 和 R 是与1-D卷积操作相关的两个关键参数,分别表示:E (Output Length):输出特征图(output feature map)的长度。R (Filter Length):滤波器(filter)的长度。),这是固定的计算量,与数据流类型无关。
-
权重读取次数:
- OS:需要读取E*R次权重,因为每个权重在每个输出位置都需要读取一次。
- WS:只需要读取R次权重,因为权重在PE阵列中被广播并重用。
- IS:需要读取E*R次权重,因为权重在每个输入位置都需要读取一次。
-
输入读取次数:
- OS:需要读取E*R次输入,因为输入在每个输出位置都需要读取一次。
- WS:需要读取E*R次输入,因为输入在每个输出位置都需要读取一次。
- IS:只需要读取E次输入,因为输入在PE阵列中被广播并重用。
-
输出读取次数:
- OS:不需要读取输出(0次),因为输出在本地累积。
- WS:需要读取E*R次输出,因为输出在PE阵列中需要多次读取。
- IS:需要读取E*R次输出,因为输出在PE阵列中需要多次读取。
-
输出写入次数:
- OS:需要写入E次输出,因为每个输出只写入一次。
- WS:需要写入E*R次输出,因为输出在PE阵列中需要多次写入。
- IS:需要写入E*R次输出,因为输出在PE阵列中需要多次写入。
总结:
- OS在权重读取和输出读取方面表现最佳,因为它最小化了部分和的读写。
- WS在权重读取方面表现最佳,因为它最小化了权重的读取。
- IS在输入读取方面表现最佳,因为它最小化了输入的读取。
- Min列显示了每个指标的最小值,表明哪种数据流类型在特定指标上表现最好。
补充伪代码
- Output Stationary (OS) 代码
c
for (e = 0; e < E; e++)
for (r = 0; r < R; r++)
O[e] += I[e+r] * W[r];- 外层循环 :遍历输出索引
e,从0到E-1。 - 内层循环 :遍历滤波器索引
r,从0到R-1。 - 操作 :对于每个输出索引
e和滤波器索引r,将输入I[e+r]和权重W[r]的乘积累加到输出O[e]中。 - 特点 :输出
O[e]在每个周期中被多次更新,权重和输入被读取。
- Weight Stationary (WS) 代码
c
for (r = 0; r < R; r++)
for (e = 0; e < E; e++)
O[e] += I[e+r] * W[r];- 外层循环 :遍历滤波器索引
r,从0到R-1。 - 内层循环 :遍历输出索引
e,从0到E-1。 - 操作 :对于每个滤波器索引
r和输出索引e,将输入I[e+r]和权重W[r]的乘积累加到输出O[e]中。 - 特点 :权重
W[r]在每个周期中被多次重用,减少了权重的读取次数。
- Input Stationary (IS) 代码
c
for (h = 0; h < H; h++)
for (r = 0; r < R; r++)
O[h-r] += I[h] * W[r];- 外层循环 :遍历输入索引
h,从0到H-1。 - 内层循环 :遍历滤波器索引
r,从0到R-1。 - 操作 :对于每个输入索引
h和滤波器索引r,将输入I[h]和权重W[r]的乘积累加到输出O[h-r]中。 - 特点 :输入
I[h]在每个周期中被多次重用,减少了输入的读取次数。
总结
- Output Stationary (OS):输出部分和在本地累积,减少对全局缓冲区的访问。
- Weight Stationary (WS):权重被多次重用,减少权重的读取次数。
- Input Stationary (IS):输入激活被多次重用,减少输入的读取次数。
这些代码展示了不同数据流(OS、WS、IS)在1-D卷积中的实现方式,通过改变循环的顺序和数据的访问模式来优化性能和能效。
DNN Accelerator Architectures 2
1. 数据流分类与优化
-
数据流分类:
- 数据流分为三种类型:激活数据(Activation)、权重数据(Weight)和部分和(Partial Sum, psum)。
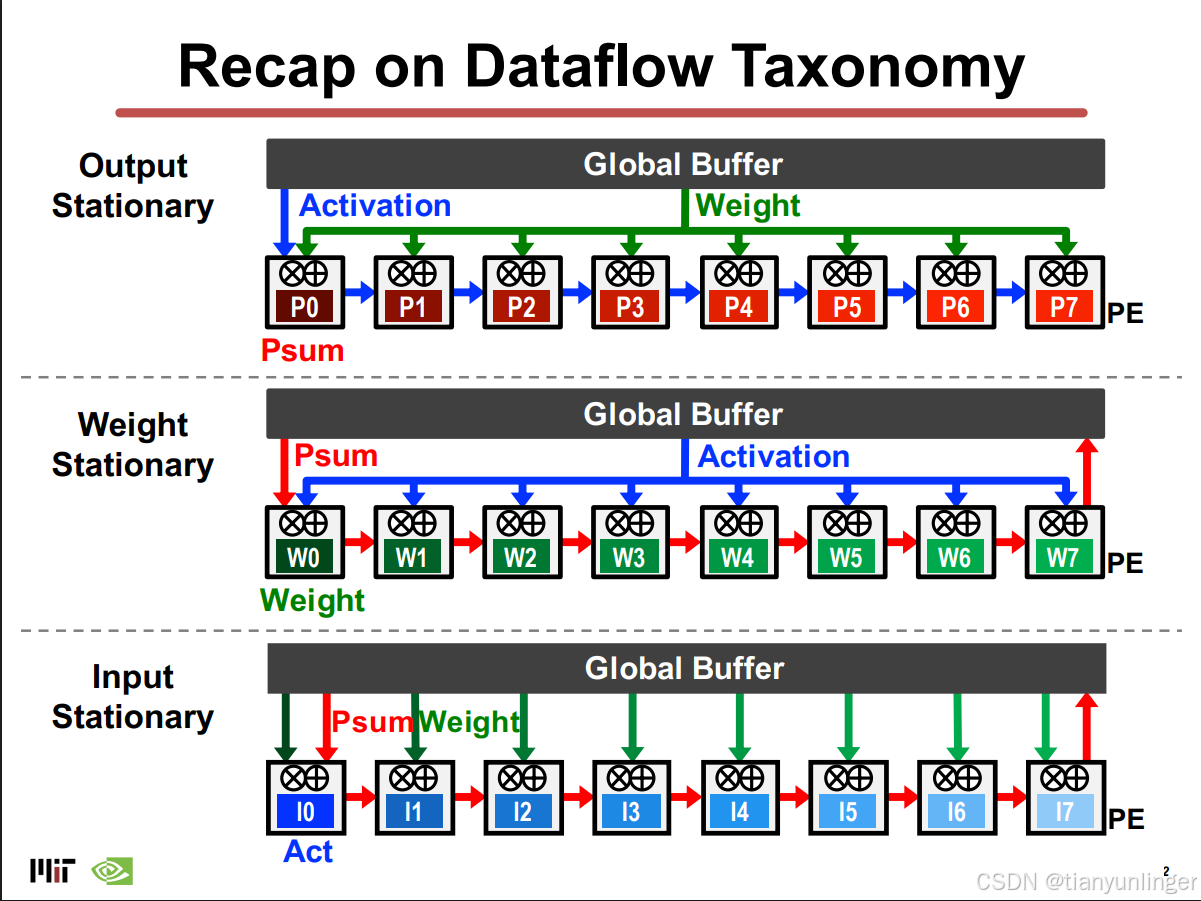
- 根据数据复用的方式,数据流可以分为输入驻留(Input Stationary)、权重驻留(Weight Stationary)和行驻留(Row Stationary)。
-
行驻留(Row Stationary, RS)数据流:
- 优化目标:最大化数据复用,优化整体能效,而非仅针对某一类型数据。
- 实现方式 :
- 在寄存器文件(RF)中保留滤波器行和特征图滑动窗口,减少数据频繁读取。
- 最大化行卷积复用和部分和积累。
2. PE阵列中的卷积计算
-
1D行卷积:
- 在PE(Processing Element)中,通过寄存器文件(Reg File)存储滤波器行和特征图滑动窗口,计算部分和。
- 示例:滤波器行为
a b c,特征图行为a b c d e,通过滑动窗口计算部分和。
-
2D卷积:
- 在PE阵列中,通过多行滤波器和特征图的组合,完成二维卷积计算。
- 示例:PE阵列中,每行PE处理不同的滤波器行和特征图行,逐步积累部分和。
3. 多通道和多特征图的处理
-
滤波器复用:
- 在PE中,滤波器行可以在多个特征图中复用。
- 示例:滤波器行
Row 1可以在特征图Fmap 1和Fmap 2中复用。
-
特征图复用:
- 在PE中,特征图行可以在多个滤波器中复用。
- 示例:特征图行
Row 1可以在滤波器Filter 1和Filter 2中复用。
-
通道累积:
- 在PE中,不同通道的部分和可以通过交替通道的方式进行累积。
- 示例:通道1和通道2的部分和可以累积为最终结果。
4. 编译器与硬件协同设计
-
编译器的作用:
- 根据DNN的形状和大小,优化映射配置(Mapping Config),将计算任务分配到PE阵列中。
- 示例:将多个特征图、滤波器和通道映射到同一个PE中,以利用不同的数据复用和局部累积。
-
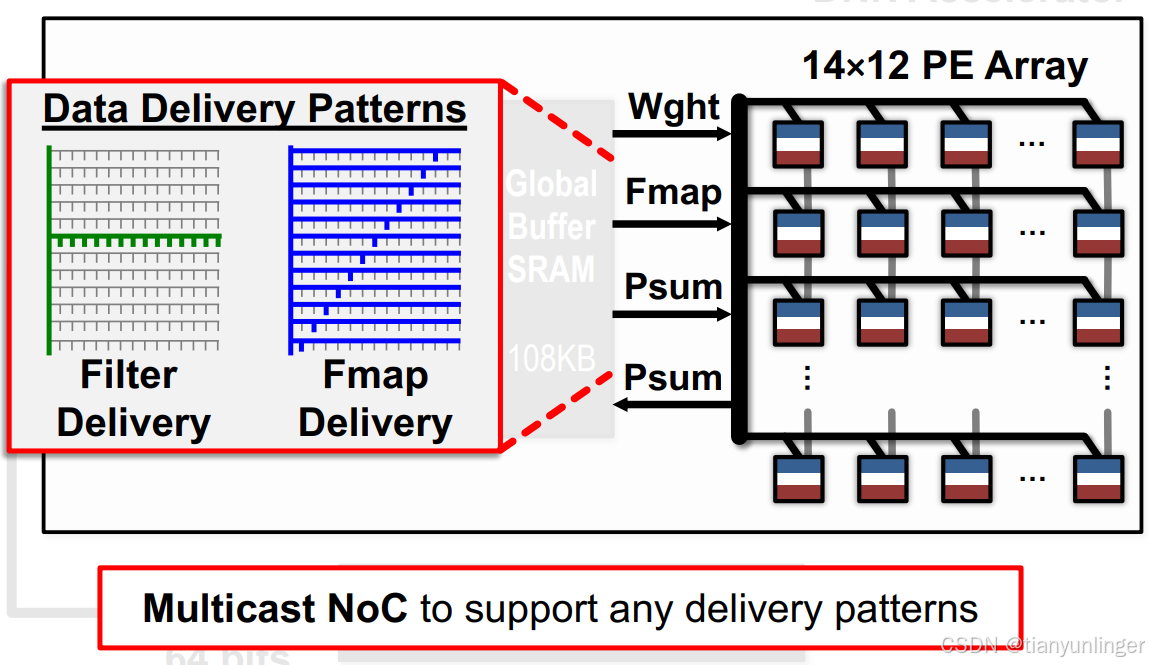
硬件资源:
- 包括ALU(算术逻辑单元)、全局缓冲区(Global Buffer)等。
- 示例:通过全局缓冲区存储输入特征图、输出特征图和权重数据。
5. 性能评估框架(Eyexam)
-
评估目标:
- 快速理解DNN加速器在不同工作负载下的性能限制。
- 示例:通过分析MAC(乘积累加操作)每周期的性能和数据每周期的性能,评估硬件的计算能力和带宽限制。
-
评估步骤:
- 最大工作负载并行性。
- 最大数据流并行性。
- 在有限PE阵列尺寸下的激活PE数量。
- 在固定PE阵列尺寸下的激活PE数量。
- 在有限存储容量下的激活PE数量。
- 由于平均带宽不足导致的激活PE利用率降低。
- 由于瞬时带宽不足导致的激活PE利用率降低。

6. 片上网络(NoC)设计
-
传统网络的局限性:
- 单播(Unicast)和广播(Broadcast)网络难以同时满足高复用和高带宽的需求。
- 示例:广播网络适合高复用场景,但带宽较低;全连接网络适合高带宽场景,但扩展性差。

-
提出的解决方案:
- 层次化网格网络(Hierarchical Mesh Network) :
- 支持从高复用到高带宽的各种数据传输模式。
- 通过分层设计,降低复杂性并提高扩展性。
- 示例:
- 高带宽模式:支持所有PE之间的全连接通信。
- 高复用模式:支持从单一源到多个目标的高效数据传输。
- 组播和交织多播模式:适应不同的数据复用和带宽需求。
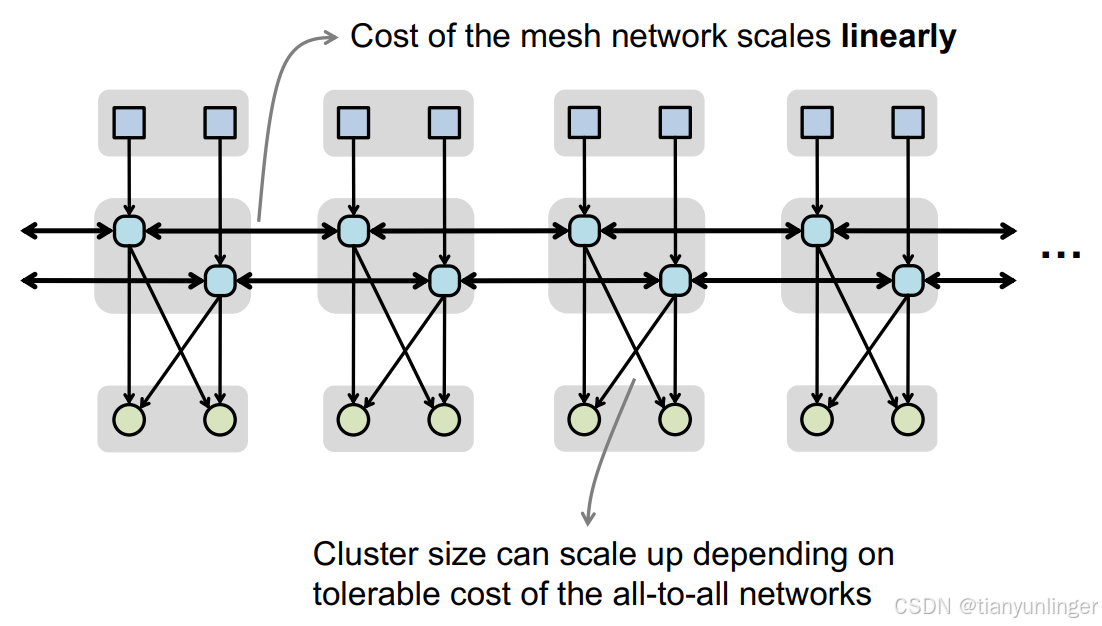
- 层次化网格网络(Hierarchical Mesh Network) :
-
Eyeriss加速器的改进:
- Eyeriss v2采用层次化网格网络,相比v1在性能和能效方面有显著提升。
- 示例:AlexNet的加速比为6.9倍,能效提升2.6倍;MobileNet的加速比为5.6倍,能效提升1.8倍。
7. 总结
- 关键点 :
- 数据复用是实现高能效的关键。
- 通过灵活的片上网络设计,可以提高PE利用率,从而实现高性能。
- 数据流与硬件的协同设计对于优化DNN加速器的性能、能效和灵活性至关重要。