一、5.5中断小节补充(很熟的话可以跳过不看)
上面是5.5小节内容,我之所以没写他的笔记是因为内容不多,是纯记忆的文科知识点,而且它在操作系统和计算机组成原理里反复出现,已经不需要单独来讲了,需要了解详情的请到我下面的《操作系统第一章》以及《计算机组成原理第七章》来加深 "中断异常" 这部分的知识点
;
操作系统第1章的《中断、系统调用》:
https://blog.csdn.net/m0_73991249/article/details/144207320
https://blog.csdn.net/m0_73991249/article/details/144207320
;
计算机组成原理第7章的《I/O方式》:


二、指令流水线概念
1)回顾CPU执行指令流程(很熟的可以跳过不看)
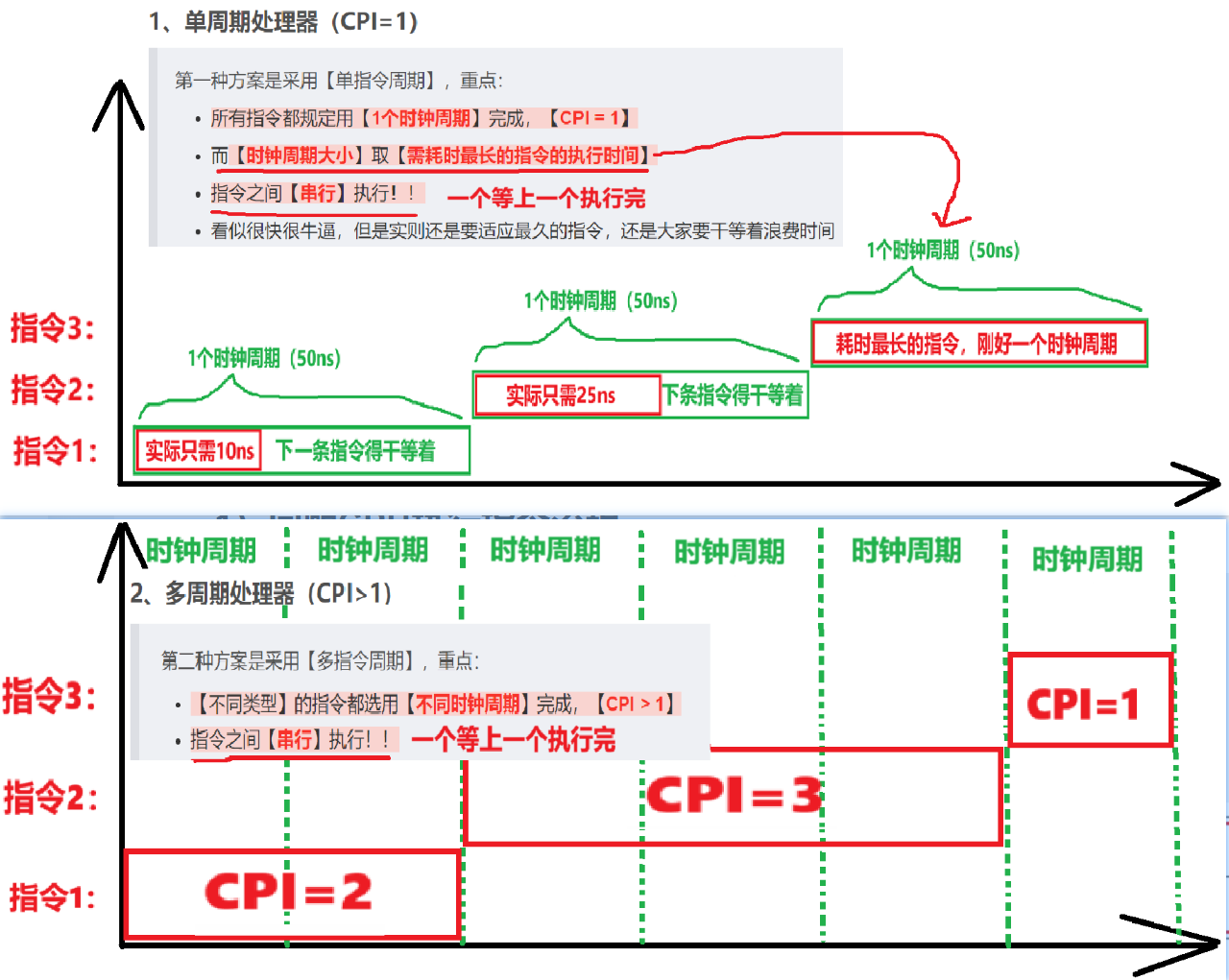
【CPU的3种执行方案】:

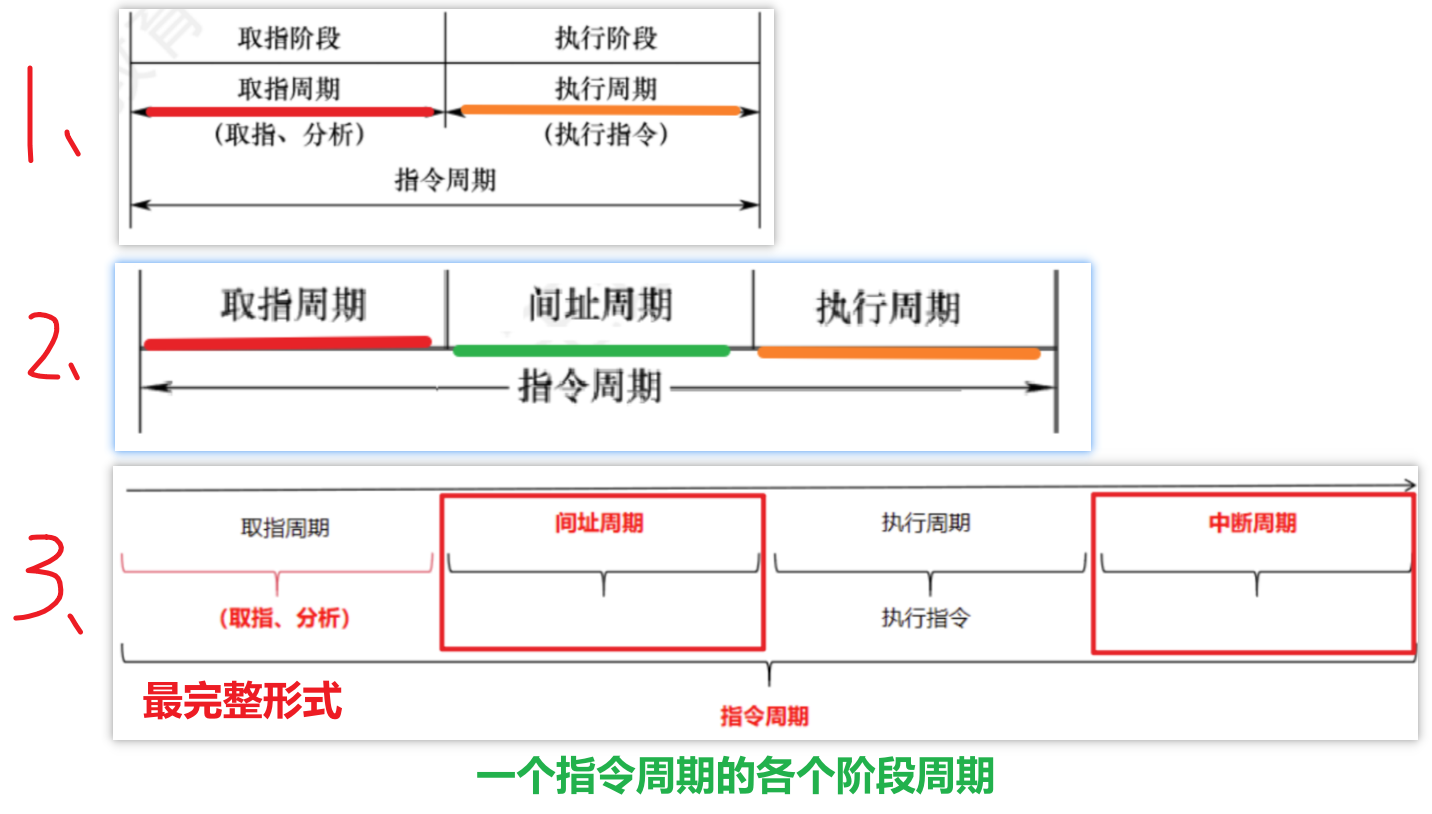
2)【指令阶段】和【指令周期】
这里我觉得需要跟之前【指令周期】做一下区分,这二者是不同的研究方向:
- 【指令周期】的各个阶段,特指的是【周期:时间性质】
- 【指令阶段】特指的是指令过程里各个阶段的【操作:要干的事情】
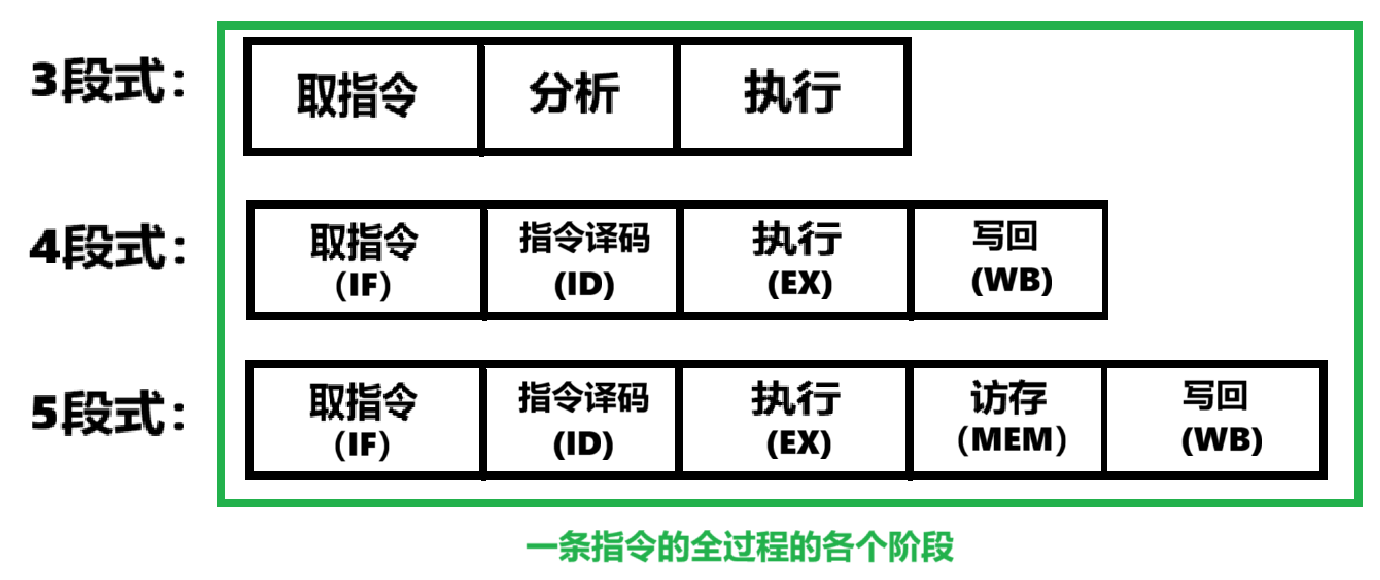
- 一般情况下可分为这3种,一般考试必考的是把指令过程分为【5段式】!!
打个比方:
- 学校把一天分为了【早读、上午操课、下午操课、晚自习】这样的周期规划;
- 但具体的执行阶段要干啥还可以细分:
- 【体育生:早练、上午文化课、下午文化课、下午锻炼、晚自习、睡前拉伸】
- 【文化生:早读、上午文化课、下午文化课、下午考试、晚自习、睡前背诵】
实在不理解也不要纠结,因为这就是两个研究方向,人家发明者规定的我们能知道个啥啊
3)正式开始【指令流水线】概念
重点:
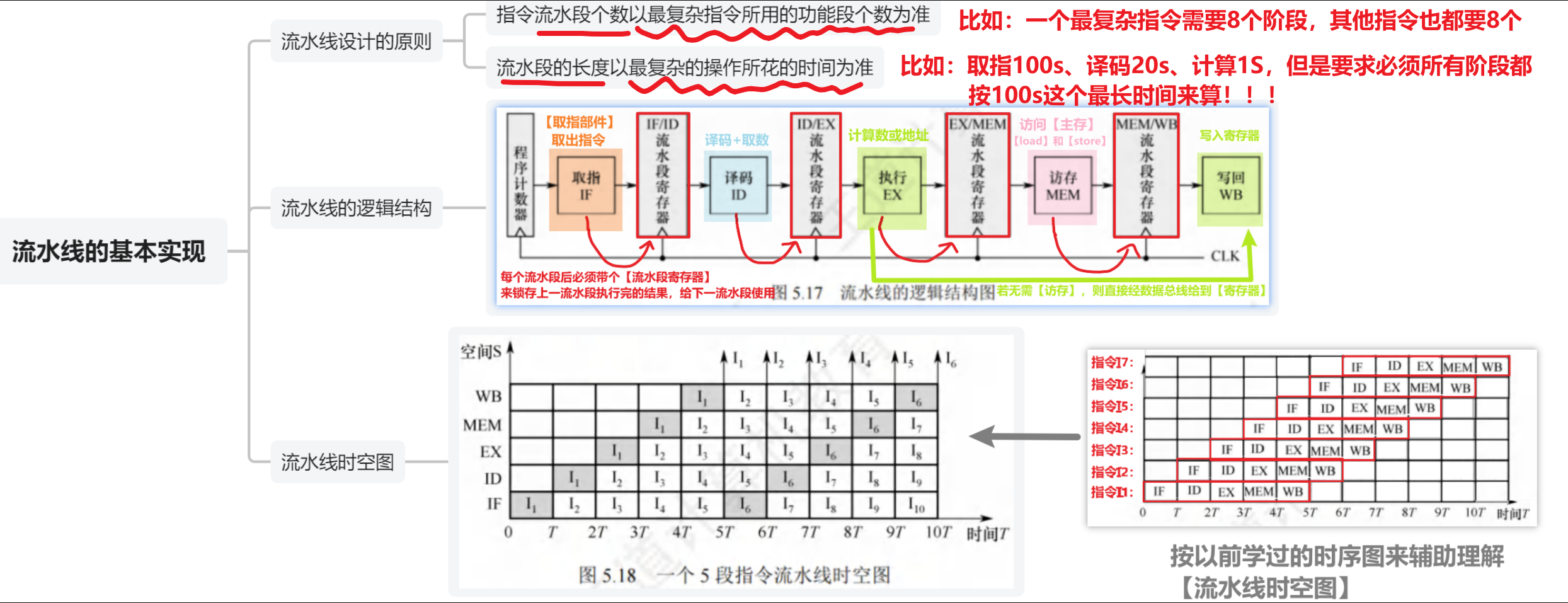
1、提高CPU的【并行性】有2种方法:
- 【时间上并行技术 】:就是我们现在学得【流水线技术】
- 把一个指令总过程分成多个子过程,各个子过程在不同功能部件上并行执行
- (比如上图第5个时钟周期,5条指令都在同时完成不同的子过程)
- 【空间上并行技术 】:用【超标量处理机】
- 一个处理机里,有多个处理相同功能的部件同时工作
- 后面会讲,只需知道这么个事
2、【5段式指令】的
- 【第一条指令】是【5个时钟周期】,CPI=5
- 【往后每一条指令】通通都只执行【1个时钟周期】!!CPI=1
- (不知道怎么计算的,看这个图)
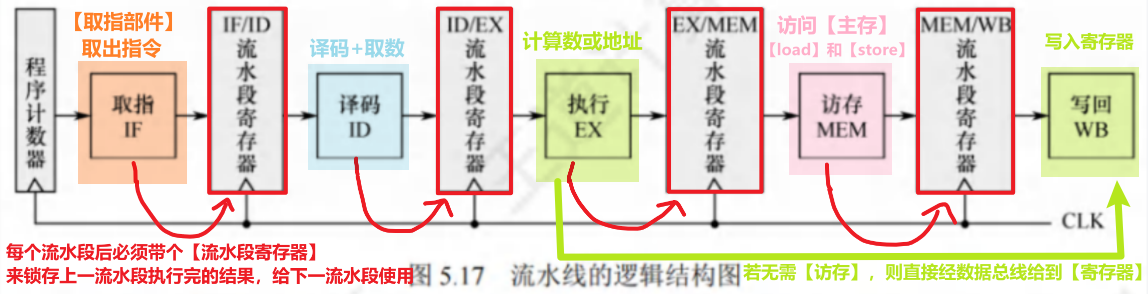
3、流水线通用模式是【分为5个阶段】: (上面思维导图有的我就不写了,仅补充)
- 【取指IF】:由【硬件:取指部件IR】自动完成
- 【译码/读寄存器ID】:包含了【译码分析】+【取数 】2件事
- 【取数】概念形象理解
- (注意:之前【指令周期】学得是【取指周期 :取指 + 译码分析】,区别一下【译码分析】的时机的区别)
- 【执行/计算地址EX】:包含【执行运算】或【地址计算】
- 【执行运算】就是比如:Rs + Rt两寄存器里的数拿出来相加
- 【地址计算】比如条件转移计算地址
- 另外,一定一定涉及【ALU部件】,只有靠它才能计算
- 【访存MEM】:就是**对【主存】**执行【load】和【store】指令
- 只有【load】和【store】指令可以访问主存!!!
- 【load】也是【lw指令】,就是访问主存、取数
- 【store】也是【sw指令】,访问主存、存数(这些后面都会细学)
- 还有一个小细节,若【Add Rd, Rs, Rt】这样的指令,运算结果只用存回Rd这个寄存器而非主存时,把【MEM流水段】空着啥事也不干,运算结果送到寄存器
- 【写回WB】:写回的地方是【寄存器】!!!!!
- 类似:【Add Rd, Rs, Rt】这样的指令,运算结果只用存回Rd这个寄存器而非主存




三、指令流水线的实现
需要注意一点:
前面我们说【5段式】是最常用的标准模式,但并非一个指令只能分5个阶段,具体分10段、100段都是可以的
注意【流水线设计】和【普通指令形式】区别:
- 流水线涉及原则要求每个【流水段】时长一样,而且取【最复杂耗时最长的阶段】;而【普通指令形式】无所谓,可以各个阶段时长不一样
- 那么假设一个五段式指令:①取指200ps、②译码100ps、③执行150ps、④访存200ps、⑤写回100ps
- 【1条指令执行】:【普通】比【流水线】快!!!
- 【普通形式】指令执行时间:200ps + 100ps + 150ps + 200ps + 100ps = 750ps
- 【流水线】指令执行时间:200ps * 5 = 1000ps
- 【N条指令执行】:【流水线】比【普通】快!!!
- 【普通形式】指令执行时间:N * 750ps
- 【流水线】指令执行时间:(5-1) + N × 200ps = (N + 4) × 200ps
【流水线结构】
;
【流水线基本要求】

四、流水线冒险(重点)
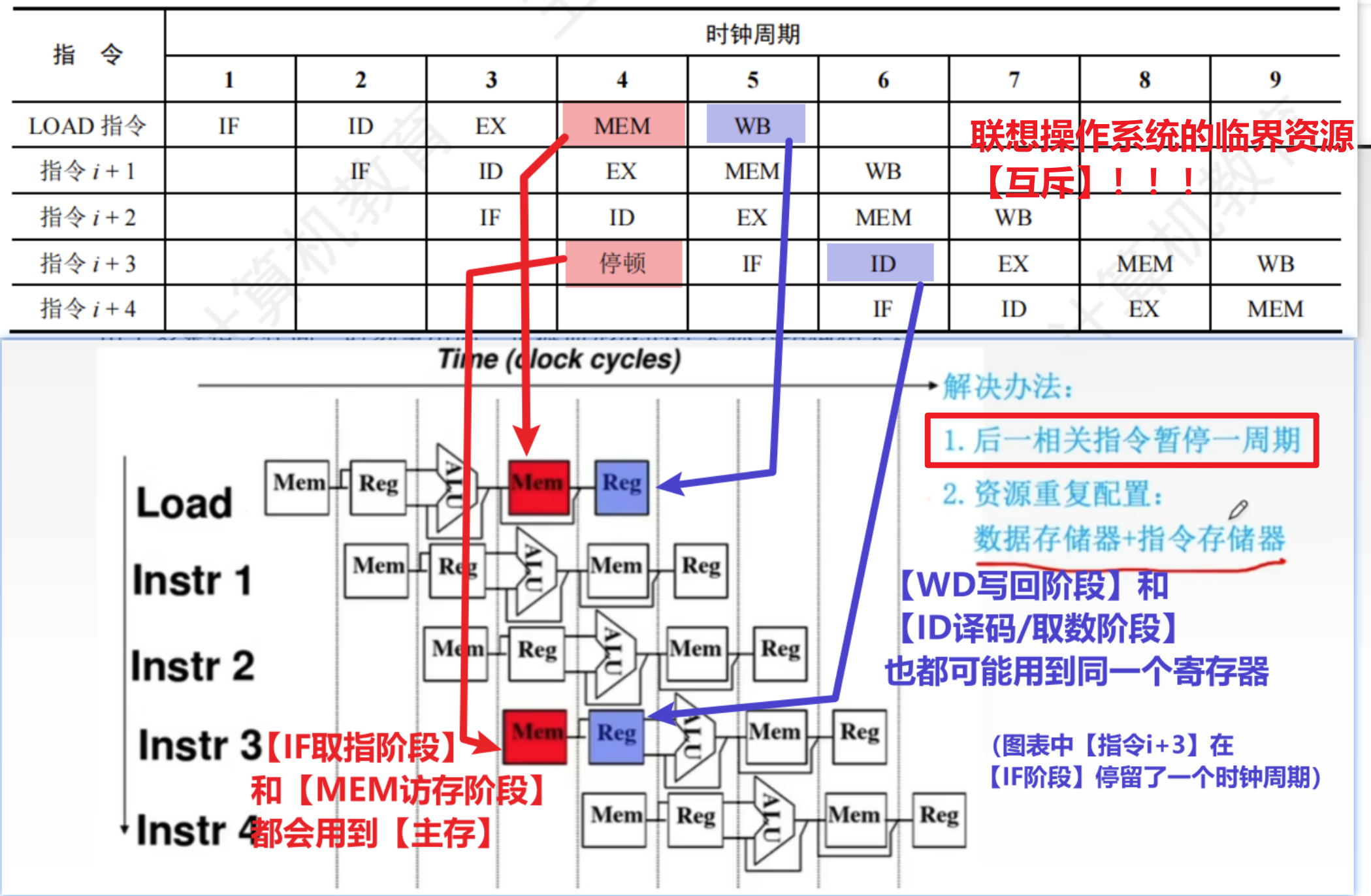
1、结构冒险(资源冒险)
跟抢占【硬件资源】有关的冲突!!
解决方法:
- 1、【暂停周期,等待互斥访问】
- 上一指令再用部件时,下一要用该部件的指令等待!!!
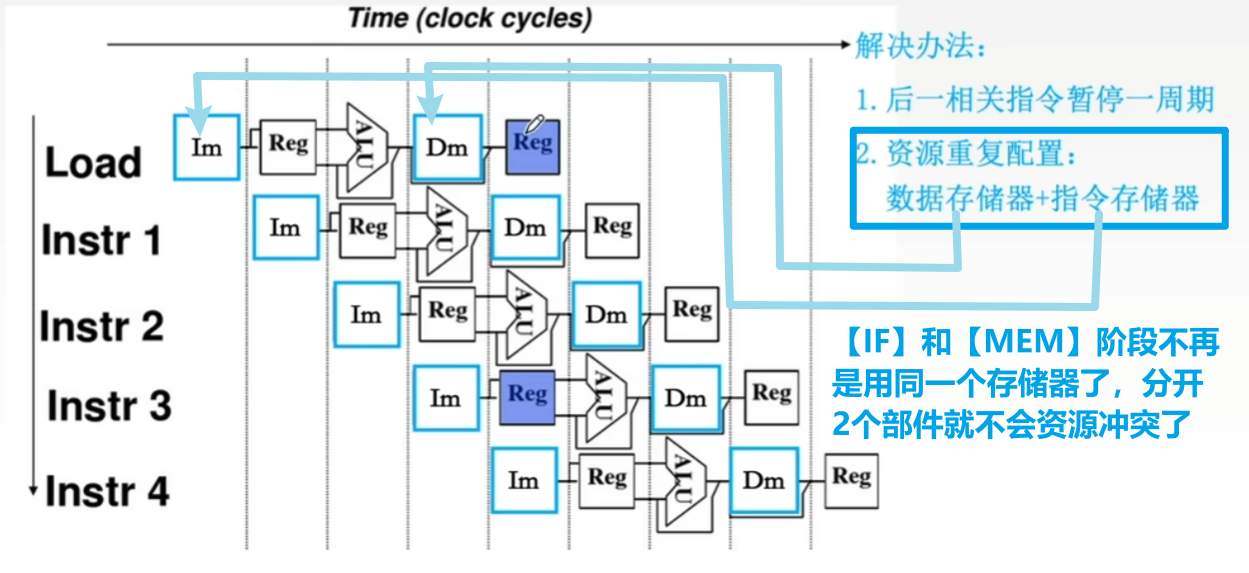
- 2、【分独立硬件资源】
- 一个阶段只用一个【独立的资源】,因为各个指令通常都是各个阶段错开执行的,不会同一阶段同时执行,所以只需要每个阶段单独用一个硬件资源就不会冲突了

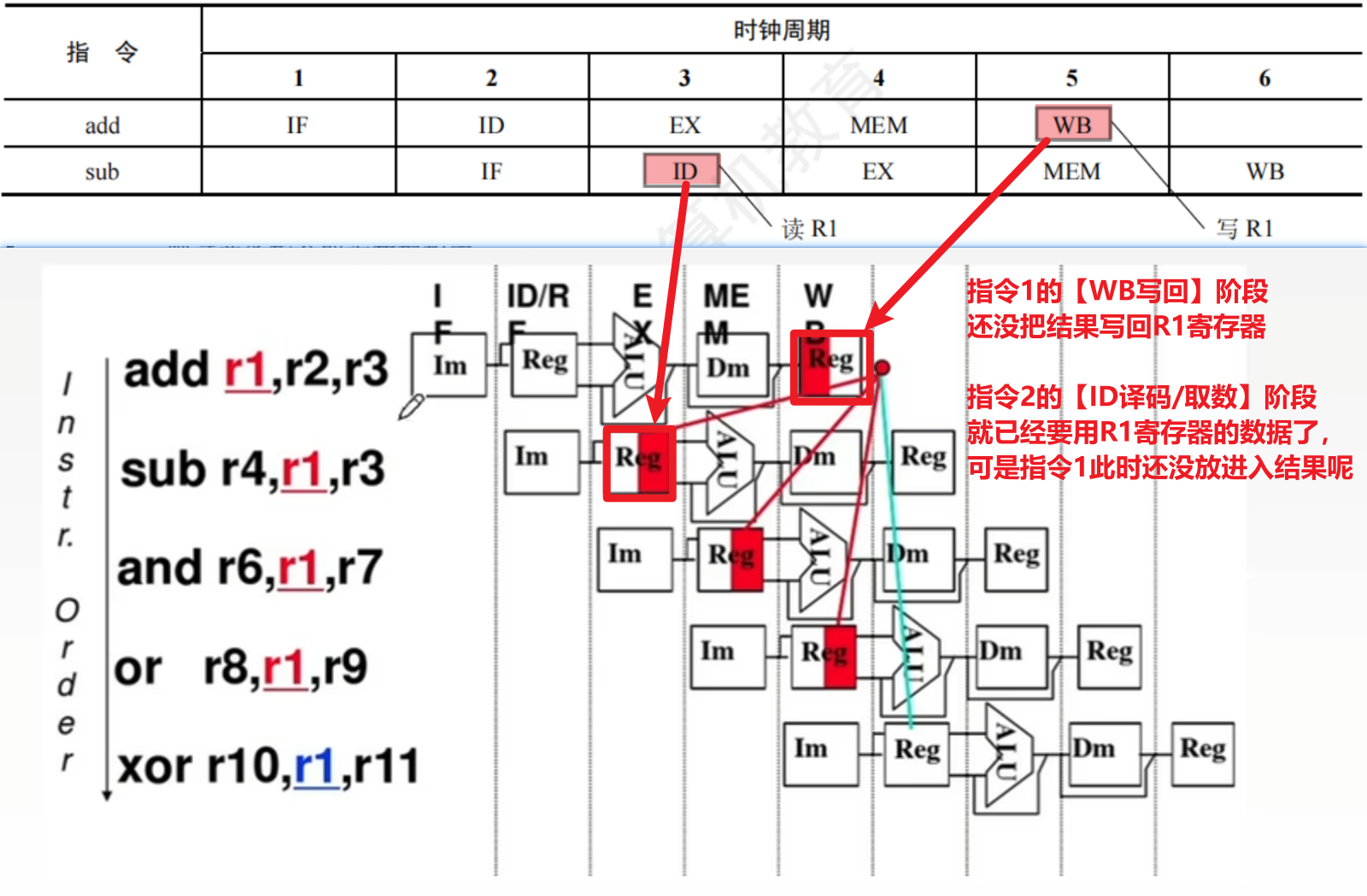
2、数据冒险(数据相关)
跟【数据】有关的冲突!!
解决方法:
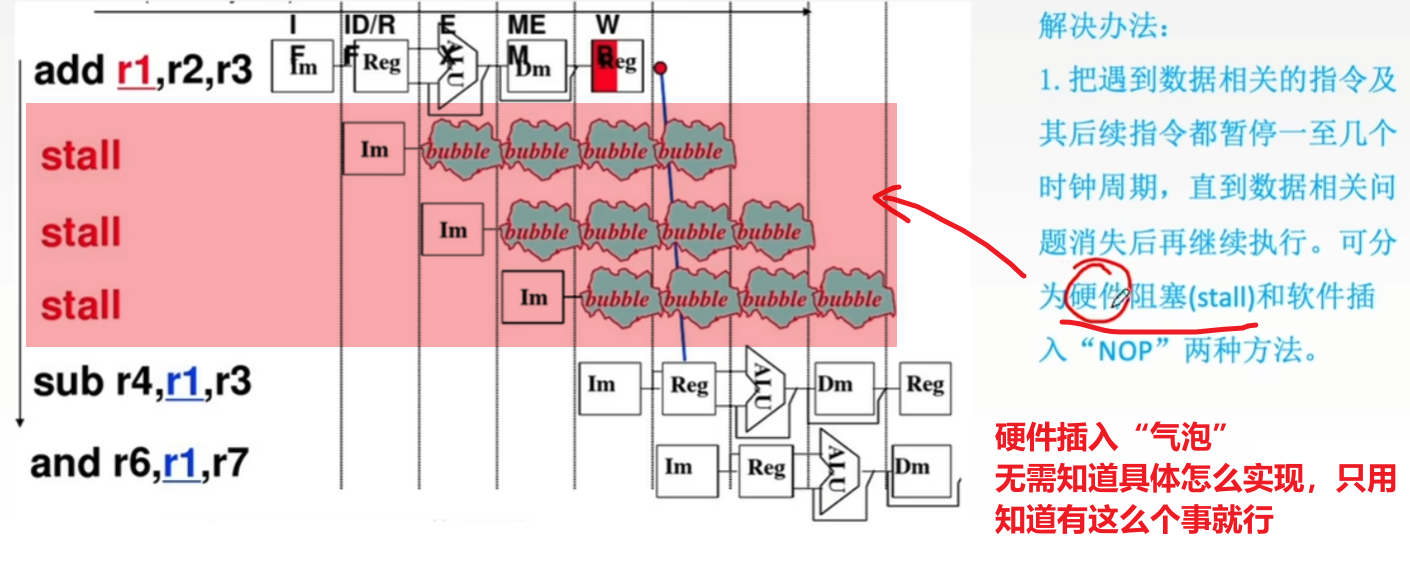
- 1、【延迟等待相关指令】
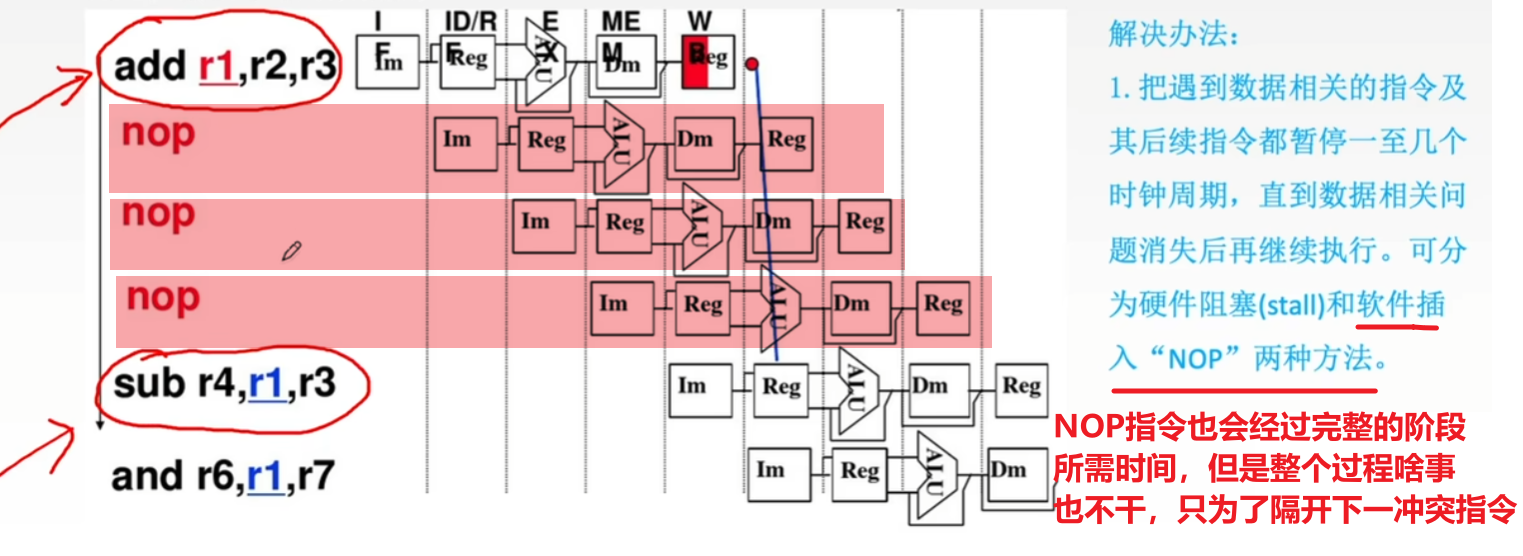
- 1)硬件阻塞stall:
- 插入【气泡】,直到上一指令的结果写入到要用的寄存器,下一指令才执行读取数(不用管是啥,记住就行)
- 2)软件插入NOP指令:
- 在下一相关指令前插入多条NOP指令,NOP指令就是啥也不干空耗时间,直到上一指令写入结果数据
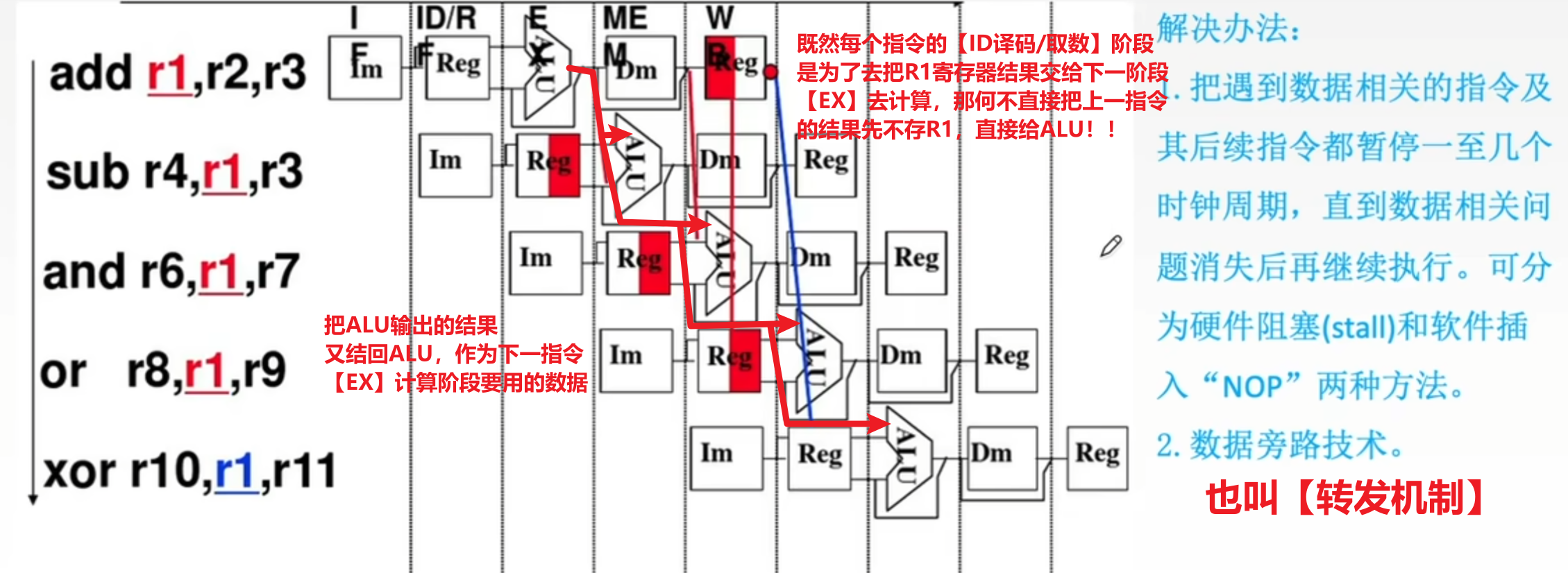
- 2、【转发机制:数据旁路技术】
- 反正这个结果数是用来计算的,那么最主要、也必须要给到的部件就是ALU运算器
- 那不如不去寄存器存数、取数了,直接ALU输出结果后,接入ALU的输入,作为下一指令计算要用的输入数据
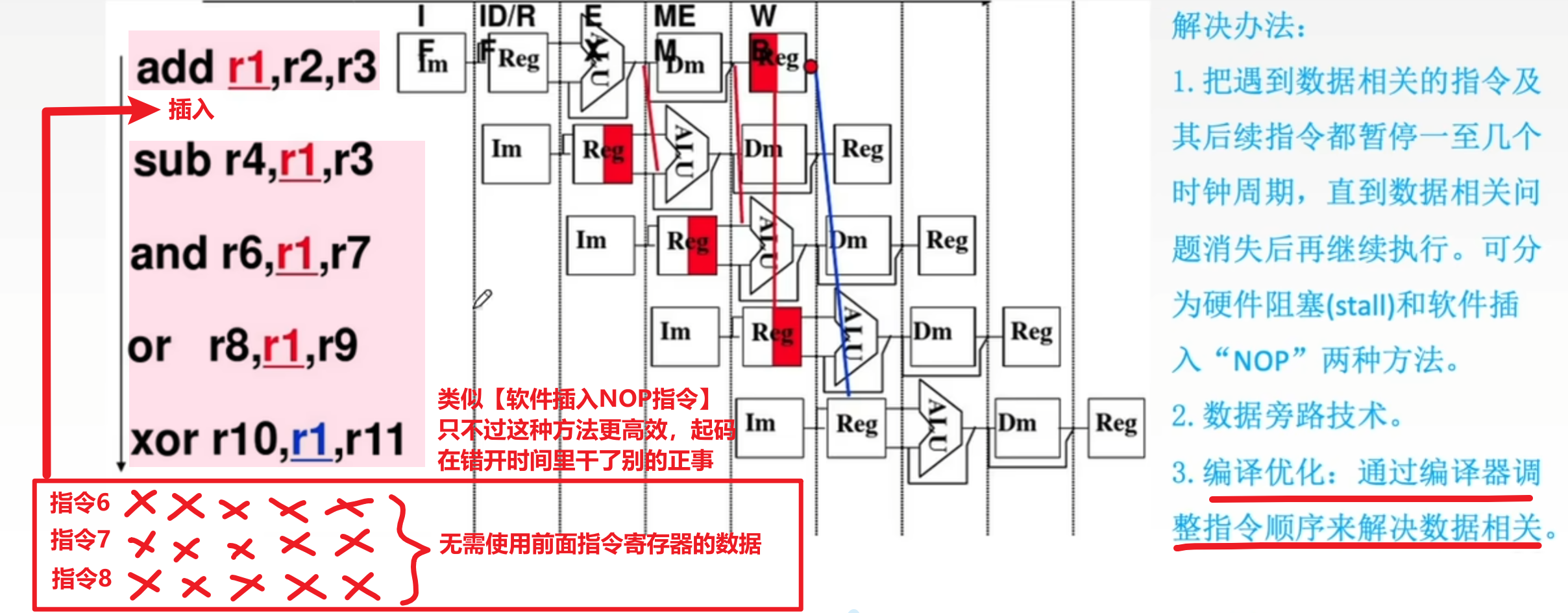
- 3、【编译优化】
- 其实就是对【软件插入NOP指令】的优化,前者是插入啥事也不干的空指令来拖时间;【编译优化】是把后面不相关的指令前放前面执行,代替NOP指令,在错开时间的同时还能干正事
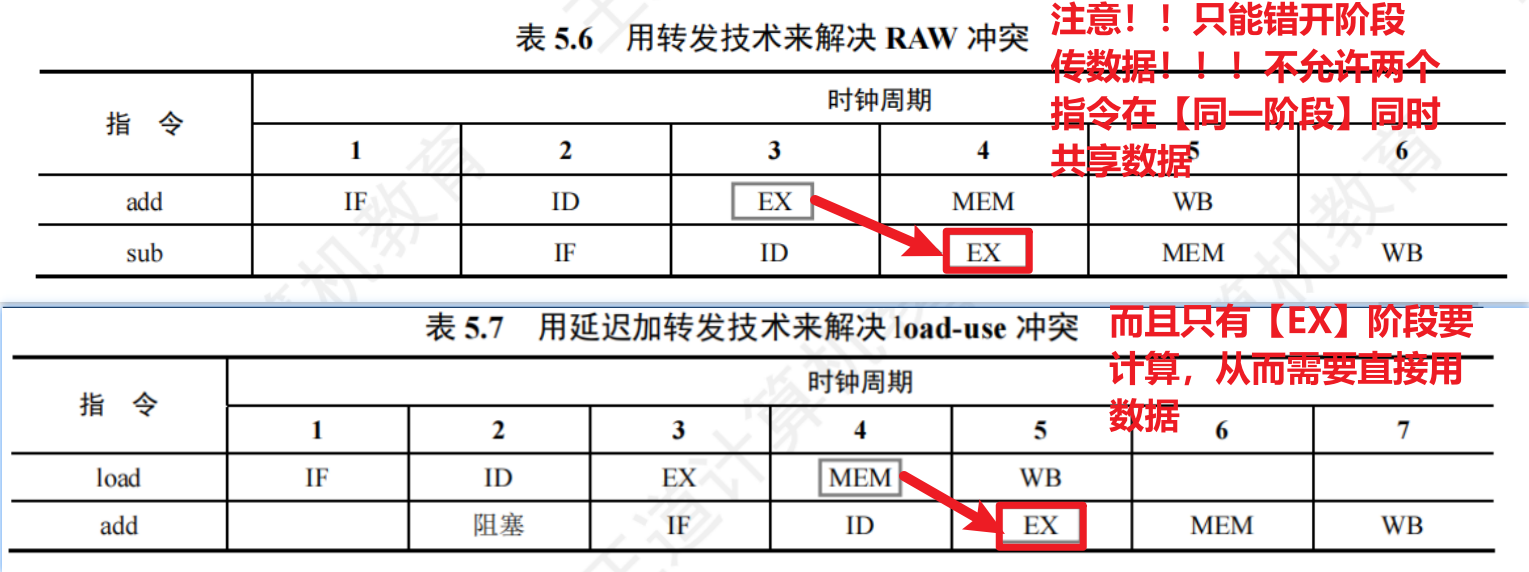
- 4、【load-use】数据冒险
- 【load指令】和【后继相关指令】的【数据冲突】有点不一样:
- 因为普通的计算指令的结果数据可以用【ALU】输出,【EX执行/计算阶段】可以得到结果数据
- 而【load指令】的结果数据需要去【主存】取出,也就是必须等到【MEM访存阶段】!!!
- 所以:不可以使用【数据转移】技术!!!!因为【主存】不能直连【ALU】!!!!
- 下一相关指令涉及计算、要用结果数据的阶段只会是【EX执行/计算】阶段;而且两个指令要使用一个数据一定要错开阶段,就像你不能在点餐的同时马上吃到东西(你就记住要像下图那样 "斜线关联" 数据)
- 所以解决方法:【下一相关指令等待!!!!】
- **【编译优化】或【软件NOP指令】**两种方法来耗时等待
- 留意一下这几个知识点:【写后读RAW】、【读后写WAR】、【写后写WAW】
- 【写后读RAW】冲突就是我们刚刚学得【数据冒险】,在按序执行指令的流水线里只可能发生这种冲突,而不是两外两种
- 记住就行,不用研究为啥,选择题直接选



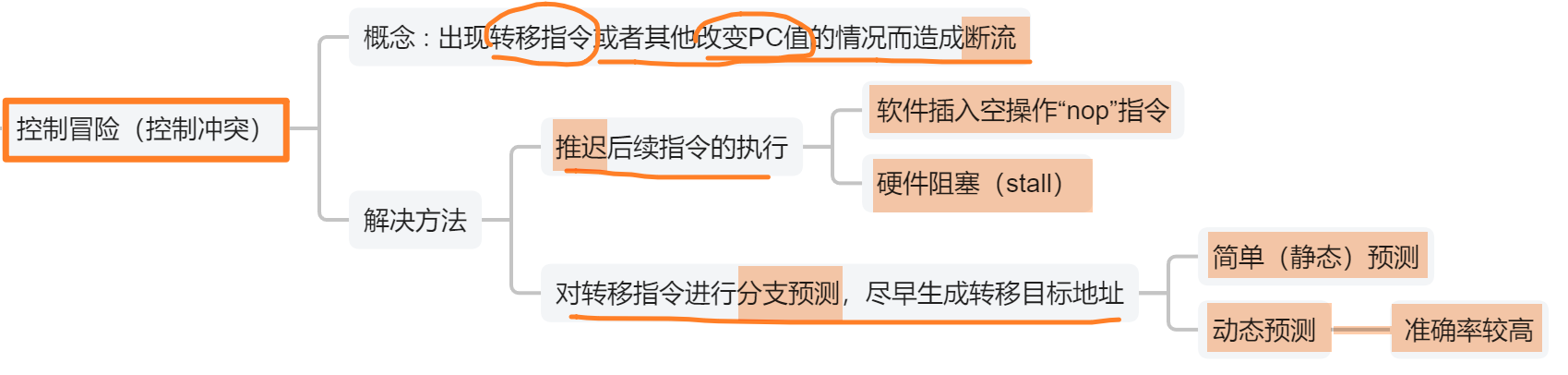
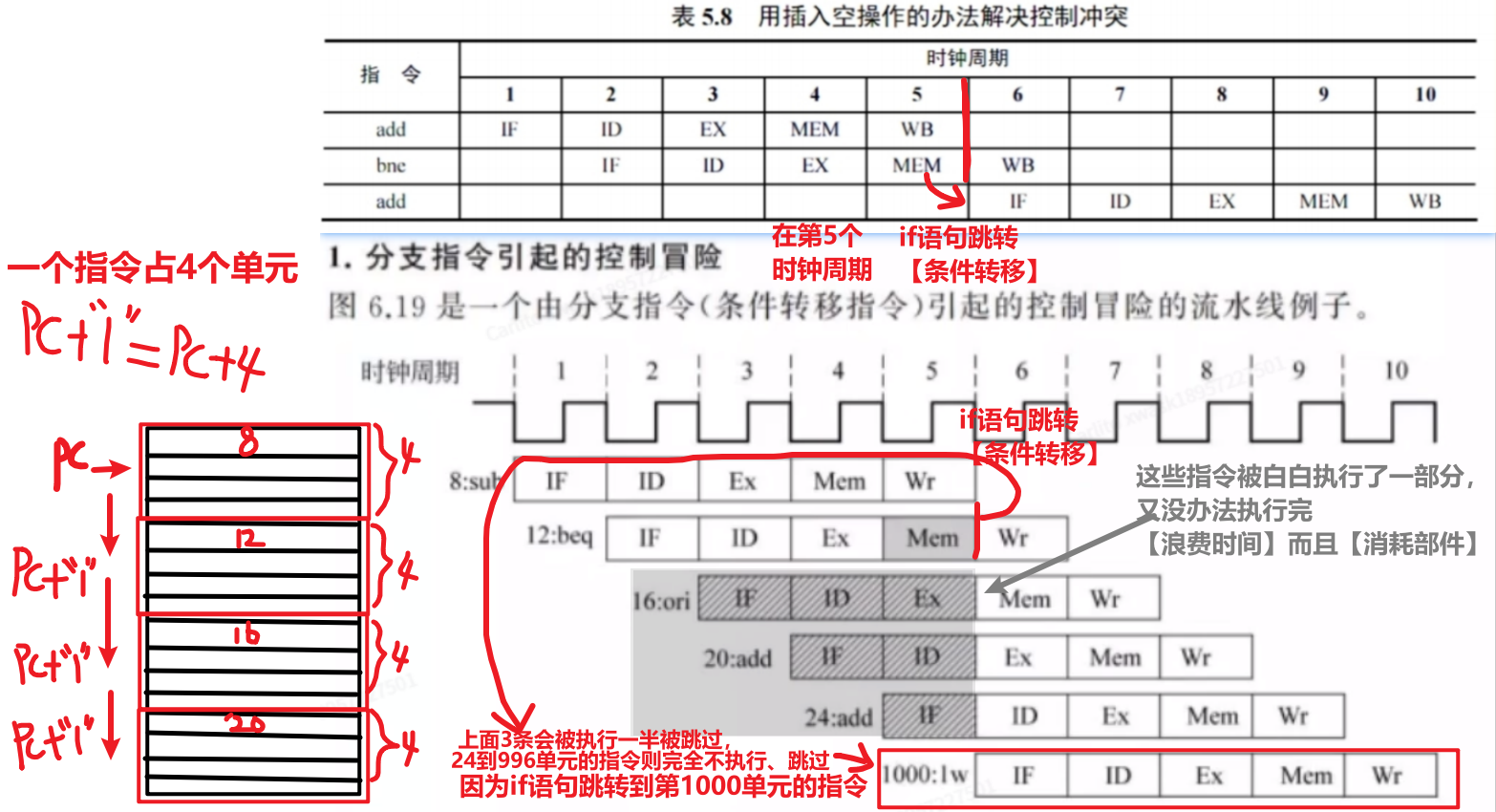
3、控制冒险(控制冲突)
跟【PC地址】有关的冲突!!会导致指令跳转!!
解决方法:
- 原理是尽量空等流水段、也别干无用功!!
- 不解决控制冲突,就会浪费时间执行一些指令的一部分;而解决的方法也是浪费时间空等
- 但是区别是前者是使用了部件完成了小部分功能,后者是啥也不干空等,没用任何部件,对部件的消耗小
- 1、【下一相关指令等待!!!!】
- 2、【预测!!!】
- 【静态预测】 :要么永远满足条转条件,而每下一条指令都空等;要么永远不满足条件,正常按顺序执行每一条指令不跳转,也不空等,相当于没解决问题
- 【动态预测】:动态判断下一阶段会不会跳转指令,动态调整下一指令要不要空等
(简单看一图片里【动态预测】会用到的:分支历史记录表BHT、分支预测缓冲表BPB、分支目标缓冲表BTB、一位预测位、两位预测位,有个印象就行,以防考选择题试考到冷门知识点,能记住就记个眼缘,记不住就算了不重要)

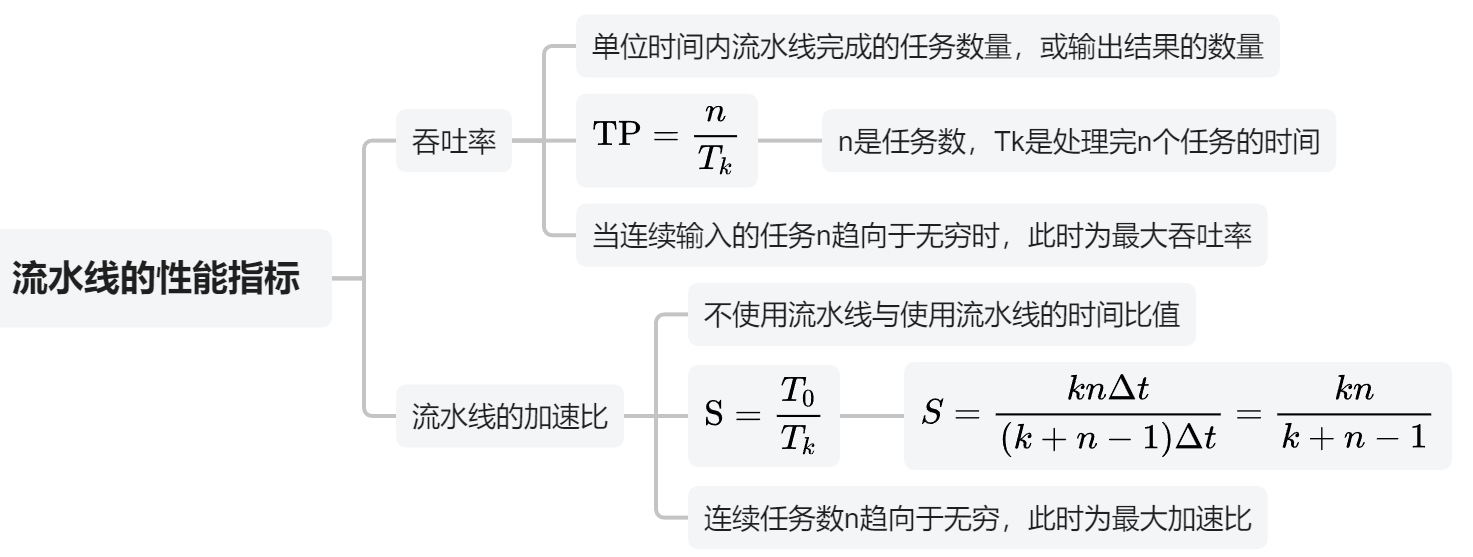
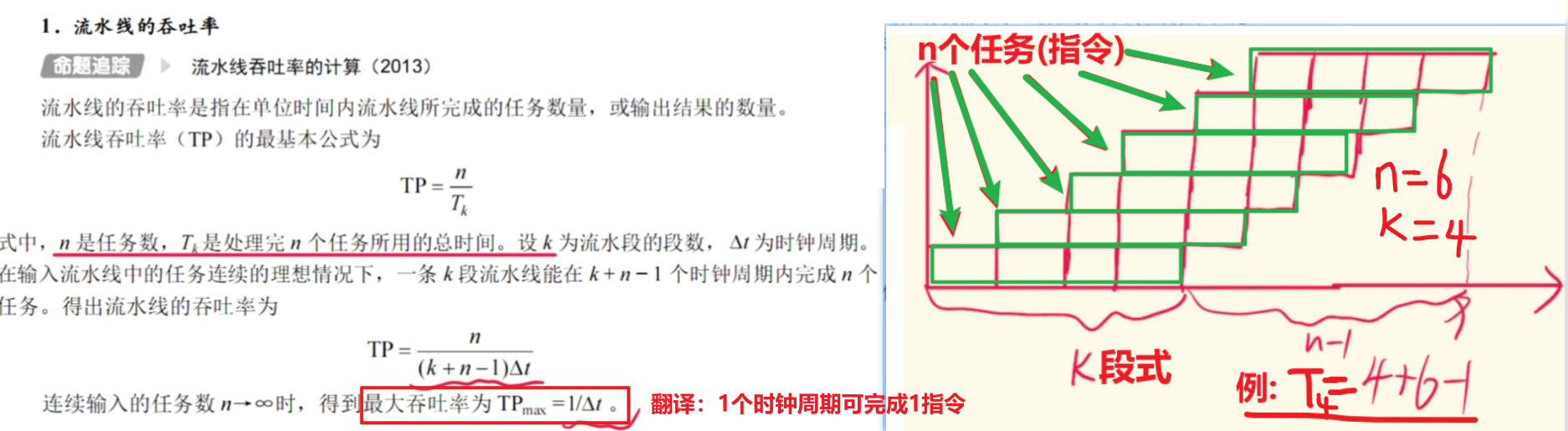
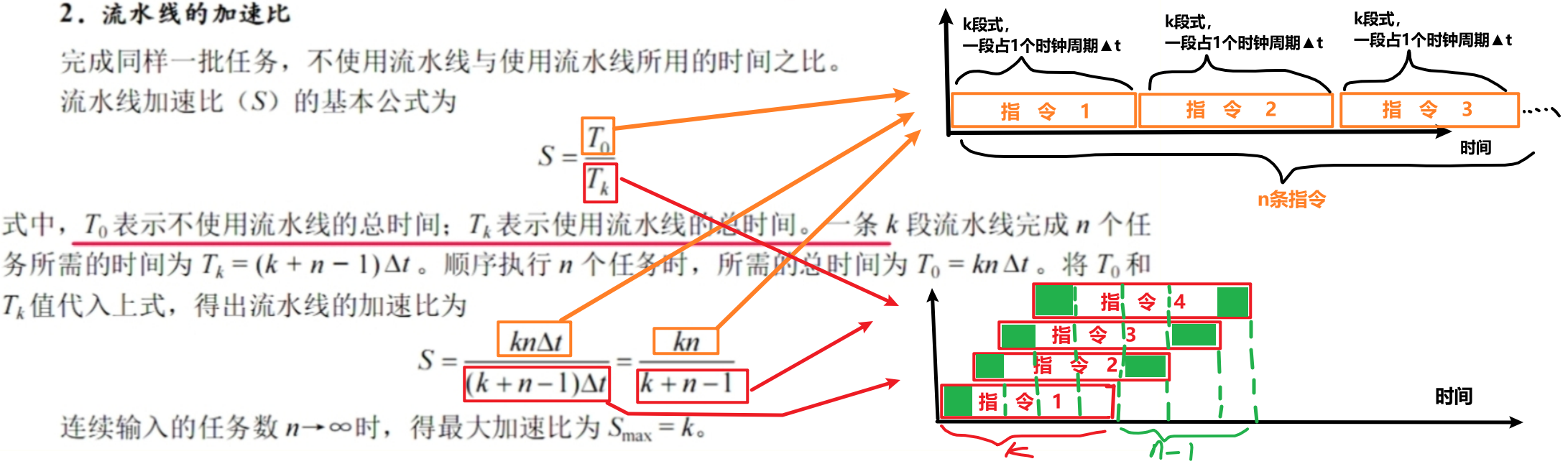
五、流水线性能指标
看图吧,我标的很清楚了
【吞吐率】=【n个指令执行的速度】=【n个指令 / 他们执行完的总时间】
;
【加速比】=【不用流水线时间 / 用了流水线时间】
六、高级流水线技术
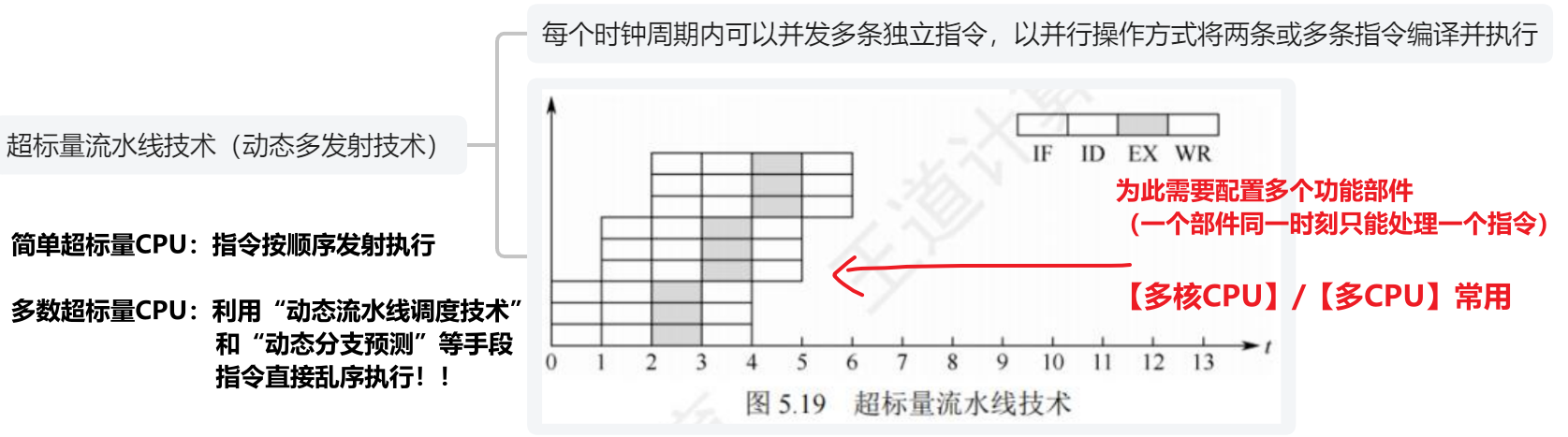
【超标量流水线技术】
- 记一下还有个名字:【动态多发射技术】
- 是【空分复用技术】
- 就是原本单核CPU一个时刻只能执行一个指令,就算流水线,也起码得等一个【IF】阶段
- 现在【多核CPU】或【多CPU】直接同时一次执行n条指令
- 不支持【乱序发射】,意思要按顺序执行指令(但是改进称"多数超标量CPU"就可以乱序了)
- 【CPI < 1】:一个时钟周期可以执行多个指令!!!!
【超长指令字技术】
- 记一下还有个名字:【静态多发射技术】
- 在有多个处理部件的基础下,【可并行的n条指令】------>【组成一个超长指令字】执行
- 【CPI < 1】:一个时钟周期可以执行多个指令!!!!
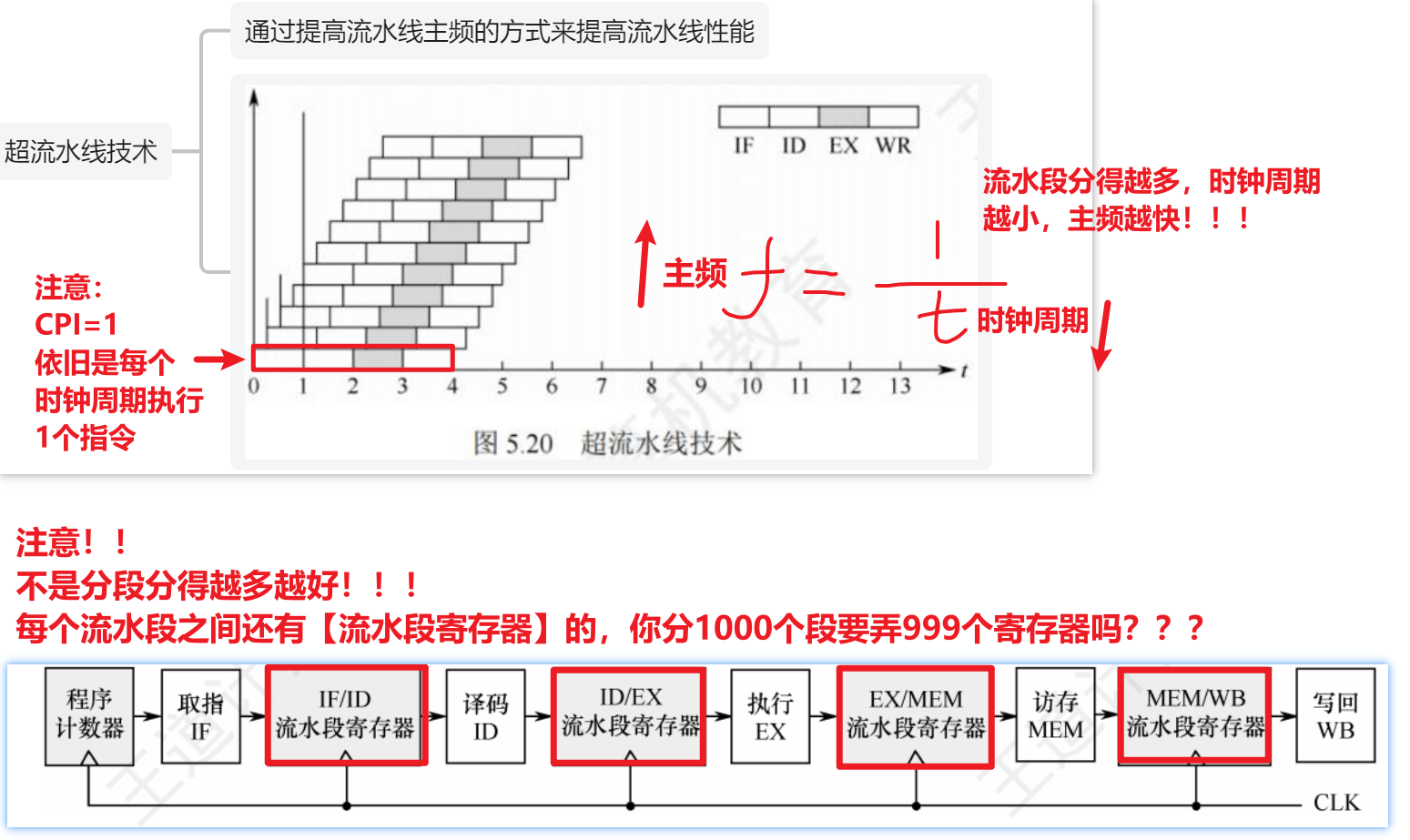
【超流水线技术】
- 是【时分复用技术】
- 就是把一个指令分成更多【流水段】,从而【时钟周期】更小,主频/吞吐量越高
- 不是分得越多越好,太多会增加硬件开销
- 也不能调整指令顺序,指令顺序靠编译器决定
- 另外记住,CPI=1!!!一个时钟周期依旧执行1个指令