
【新智元导读】Llama 4 本该是 AI 圈的焦点,却成了大型翻车现场。开源首日,全网实测代码能力崩盘。更让人震惊的是,模型训练测试集被曝作弊,内部员工直接请辞。
Meta 前脚刚发 Llama 4,后脚就有大佬请辞了!
一亩三分地的爆料贴称,经过反复训练后,Llama 4 未能取得 SOTA,甚至与顶尖大模型实力悬殊。
为了蒙混过关,高层甚至建议:
在后训练阶段中,将多个 benchmark 测试集混入训练数据。
在后训练阶段中,将多个 benchmark 测试集混入训练数据。
最终目的,让模型短期提升指标,拿出来可以看起来不错的结果。

这位内部员工 @dliudliu 表示,「自己根本无法接受这种做法,甚至辞职信中明确要求------不要在 Llama 4 技术报告中挂名」。
另一方面,小扎给全员下了「死令」------4 月底是 Llama 4 交付最后期限。
在一系列高压之下,已有高管提出了辞职。

其实,Llama 4 昨天开源之后,并没有在业内得到好评。全网测试中,代码能力极差,实力不如 GPT-4o。
网友 Flavio Adamo 使用相同的提示词,分别让 Llama 4 Maveric 和 GPT-4o 制作一个旋转多边形的动画。

可以看出,Llama 4 Maveric 生成的多边形并不规则而且没有开口。小球也不符合物理规律,直接穿过多边形掉下去了。
相比之下 GPT-4o 制作的动画虽然也不完美,但至少要好得多。
甚至,有人直接曝出,Llama 4 在 LMarena 上存在过拟合现象,有极大的「作弊」嫌疑。

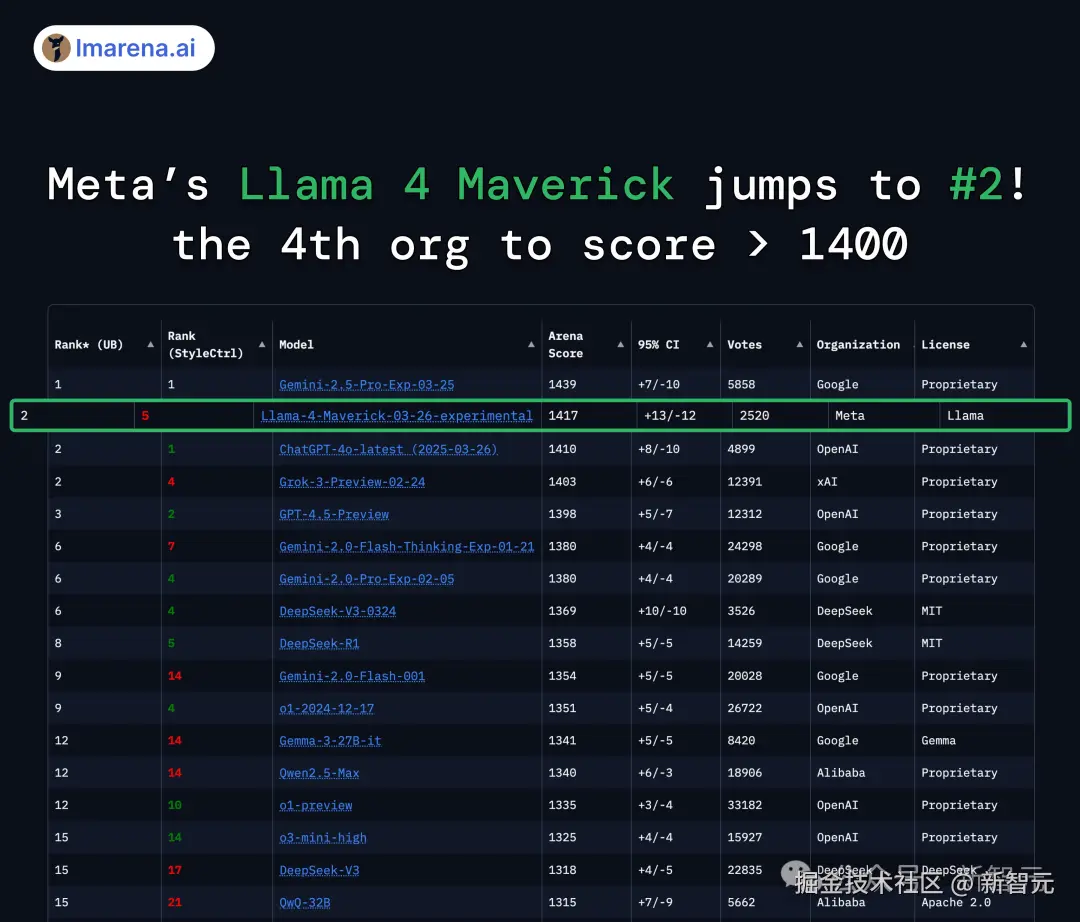
而如今,内部员工爆料,进一步证实了网友的猜想。
沃顿商学院教授 Ethan Mollick 一语中的,「如果你经常使用 AI 模型,不难分辨出哪些是针对基准测试进行优化的,哪些是真正的重大进步」。

不过,另一位内部员工称,并没有遇到这类情况,不如让子弹飞一会儿。


内部员工爆料,Llama 4 训练作弊?
几位 AI 研究人员在社交媒体上都「吐槽」同一个问题,Meta 在其公告中提到 LM Arena 上的 Maverick 是一个「实验性的聊天版本」。

如果看得仔细一点,在 Llama 官网的性能对比测试图的最下面一行,写着「Llama 4 Maverick optimized for conversationality.」
翻译过来就是「针对对话优化的 Llama 4 Maverick」------似乎有些「鸡贼」。

这种「区别对待」的会让开发人员很难准确预测该模型在特定上下文中的表现。
AI 的研究人员观察到可公开下载的 Maverick 与 LM Arena 上托管的模型在行为上存在显著差异。

而就在今天上午,已经有人爆料 Llama 4 的训练过程存在严重问题!
即 Llama 4 内部训练多次仍然没有达到开源 SOTA 基准。
Meta 的领导层决定在后训练过程中混合各种基准测试集------让 Llama 4「背题」以期望在测试中取得「好成绩」。

这个爆料的原始来源是「一亩三分地」,根据对话,爆料者很可能来自于 Meta 公司内部。

对话中提到的 Meta AI 研究部副总裁 Joelle Pineau 也申请了 5 月底辞职。(不过,也有网友称并非是与 Llama4 相关)

但是根据 Meta 的组织架构体系,Pineau 是 FAIR 的副总裁,而 FAIR 实际上是 Meta 内部与 GenAI 完全独立的组织,GenAI 才是负责 Llama 项目的组织。

GenAI 的副总裁是 Ahmad Al-Dahle,他并没有辞职。

Llama 4 才刚刚发布一天,就出现如此重磅的消息,让未来显得扑朔迷离。
代码翻车,网友大失所望
在昨天网友的实测中,评论还是有好有坏。
但是过去一天进行更多的测试后,更多的网友表达了对 Llama 4 的不满。
在 Dr_Karminski 的一篇热帖中,他说 Llama-4-Maverick------总参数 402B 的模型------在编码能力方面大致只能与 Qwen-QwQ-32B 相当。
Llama-4-Scout------总参数 109B 的模型------大概与 Grok-2 或 Ernie 4.5 类似。


在评论中,网友响应了这个判断。
有人说 Llama 4 的表现比 Gemma 3 27B 还要差。

有人认为 Llama 4 的表现甚至和 Llama 3.2 一样没有任何进步,也无法完成写诗。

其他用户在测试后也表达了同样的观点,Llama 4 有点不符合预期。

网友 Deedy 也表达了对 Llama 4 的失望,称其为「一个糟糕的编程模型」。
他表示,Scout (109B) 和 Maverick (402B) 在针对编程任务的 Kscores 基准测试中表现不如 4o、Gemini Flash、Grok 3、DeepSeek V3 和 Sonnet 3.5/7。

他还给出了贴出了 Llama 4 两个模型的一张测试排名,结果显示这两个新发布的模型远远没有达到顶尖的性能。

网友 anton 说,Llama 4「真的有点令人失望」。
他表示自己不会用它来辅助编码,而 Llama 4 的定位有点尴尬。
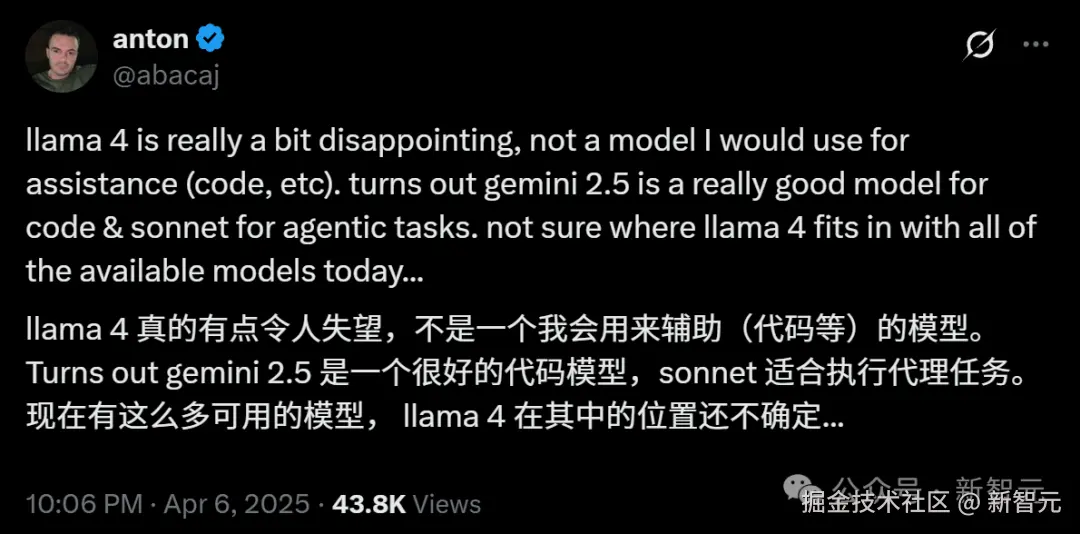
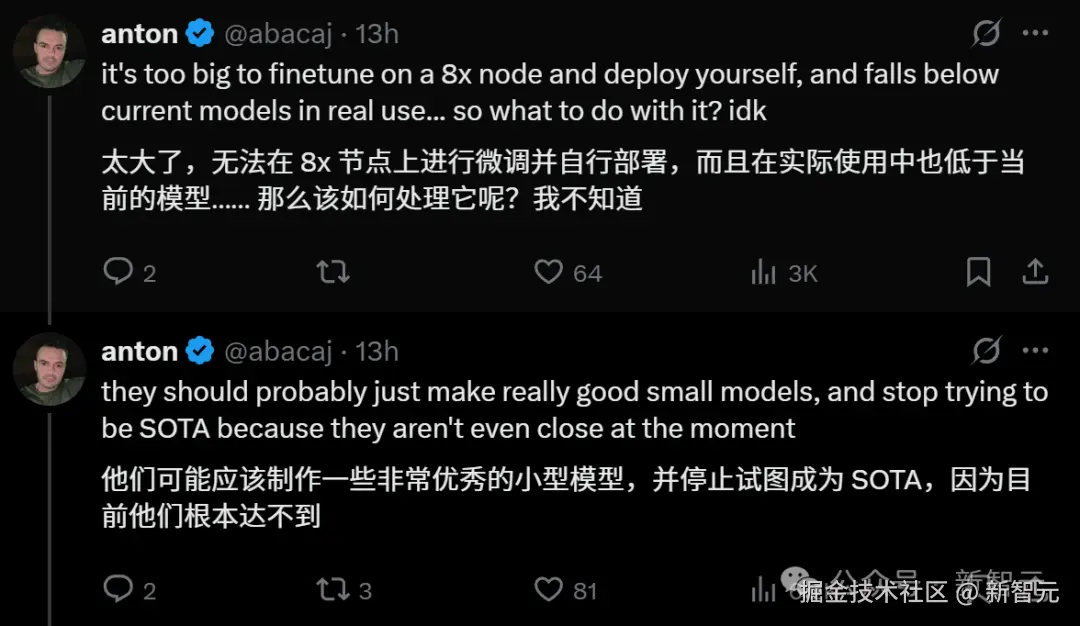
anton 认为 Llama 4 的两个模型太大了,不太好本地部署。他建议 Meta 应该推出性能优秀的小模型,而不是去追求成为 SOTA。
「因为目前他们根本做不到。」他写道。
参考资料: