Kube Scheduler 介绍
Kube Scheduler 是 Kubernetes 集群中的核心组件之一,负责调度决策,即将 Pod 绑定到集群中的节点上。它确保 Pod 能够高效、公平地同时遵守各种调度约束和优化目标被调度到集群中的节点上。通过合理配置和优化 Kube Scheduler,可以提高集群的资源利用率和应用程序的性能。
容器调度本身是一件比较复杂的事,因为要确保以下几个目标:
- 公平性:在调度 Pod 时需要公平的进行决策,每个节点都有被分配资源的机会,调度器需要对不同节点的使用作出平衡决策。
- 资源高效利用:最大化群集所有资源的利用率,使有限的 CPU、内存等资源服务尽可能更多的 Pod。
- 效率问题:能快速的完成对大批量 Pod 的调度工作,在集群规模扩增的情况下,依然保证调度过程的性能。
- 灵活性:在实际运作中,往往希望 Pod 的调度策略是可控的,从而处理大量复杂的实际问题。因此平台要允许多个调度器并行工作,同时支持自定义调度器。
关键特性和功能
1、调度策略:
Kube Scheduler 根据预定义的调度策略来决定 Pod 应该在哪个节点上运行。这些策略包括资源需求、亲和性与反亲和性规则、数据局部性、工作负载间干扰等。
2、过滤(Filtering):
在过滤阶段,Kube Scheduler 会评估所有节点,根据 Pod 的要求(如资源需求、亲和性规则等)来筛选出合适的节点候选列表。
3、打分(Scoring):
对于过滤后的节点候选列表,Kube Scheduler 会为每个节点打分,根据一系列预定义的策略(如节点的资源剩余量、Pod 间亲和性等)来评估每个节点的适宜性。
4、绑定(Binding):
打分最高的节点将被选为 Pod 运行的位置。Kube Scheduler 然后会绑定 Pod 到该节点,这意味着它会在 Kubernetes API 中更新 Pod 的状态,指明它应该在哪个节点上运行。
5、调度扩展性:
Kube Scheduler 支持扩展性,允许开发者实现自定义的调度器插件。这些插件可以用于实现特定的调度逻辑,如特定的亲和性规则或资源分配策略。
6、多调度器支持:
Kubernetes 支持运行多个调度器实例,每个实例可以配置不同的调度策略。这允许在同一集群中运行不同的调度策略,以适应不同的工作负载需求。
7、领导者选举:
在多调度器配置中,Kube Scheduler 支持领导者选举机制,确保在任何给定时间只有一个调度器实例在进行调度决策。
9、监控和日志:
Kube Scheduler 提供监控端点和日志记录,以便集群管理员可以监控调度器的性能和调试问题。
9、配置:
Kube Scheduler 的行为可以通过一个配置文件来定制,该文件定义了调度器的策略、插件和其他参数。
10、与 Kubernetes API 服务器的交互:
Kube Scheduler 通过与 Kubernetes API 服务器通信来获取集群状态信息,如当前的 Pod 和节点列表,并在调度决策后更新这些信息。
观测云
观测云是一个统一实时监测平台,它提供全面的系统可观测性解决方案,帮助用户快速实现对云平台、云原生、应用及业务的监控需求。观测云的核心功能包括:基础设施监测,日志采集和分析,用户访问监测(RUM),应用性能监测(APM),服务可用性监测(拨测),安全巡检,智能监控等等。
DataKit 提供 Kube Scheduler 指标的采集,安装好 DataKit 之后,开通 kubernetesprometheus 采集器,挂载 Kube Scheduler 配置的 configMap,即可采集 Kube Scheduler指标到观测云。
部署 DataKit
登录观测云控制台,点击「集成」 -「DataKit」 - 「Kubernetes」,下载 datakit.yaml,拷贝第 ③ 步中的 token。
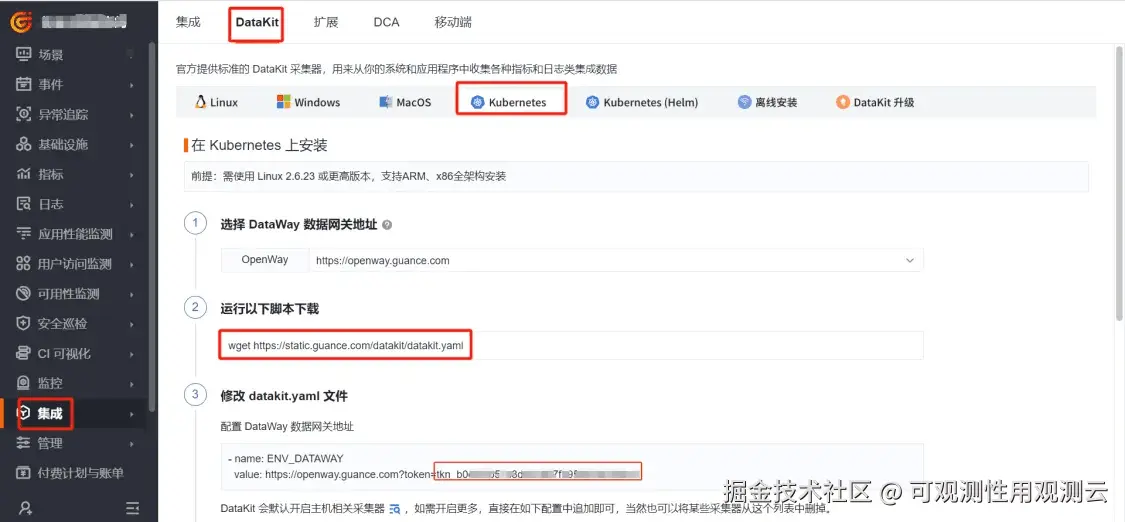
编辑 datakit.yaml ,把 token 粘贴到 ENV_DATAWAY 环境变量值中"token="后面,把 datakit.yaml 上传到可以连接到 Kubernetes 集群的主机上,执行如下命令:
arduino
kubectl apply -f datakit.yaml
kubectl get pod -n datakit采集器配置
在 datakit.yaml 中配置 ConfigMap 资源来收集 Kube Scheduler 的指标数据。
ini
apiVersion: v1
kind: ConfigMap
metadata:
name: datakit-conf
namespace: datakit
data:
kubernetesprometheus.conf: |-
# 以下配置不是一成不变,请根据实际情况进行修改
[[inputs.kubernetesprometheus.instances]]
role = "pod"
namespaces = ["kube-system"]
selector = "component=kube_scheduler,tier=control-plane"
scrape = "true"
scheme = "https"
port = "10259"
path = "/metrics"
interval = "30s"
[inputs.kubernetesprometheus.instances.custom]
measurement = "kube_scheduler"
job_as_measurement = false
[inputs.kubernetesprometheus.instances.custom.tags]
cluster_name_k8s = "k8s-test"
node_name = "__kubernetes_pod_node_name"
instance = "__kubernetes_mate_instance"
[inputs.kubernetesprometheus.instances.auth]
bearer_token_file = "/var/run/secrets/kubernetes.io/serviceaccount/token"
[inputs.kubernetesprometheus.instances.auth.tls_config]
insecure_skip_verify = true
ca_certs = []
cert = ""
cert_key = ""
bash
# 重启dk,使cm配置生效
kubectl rollout restart ds datakit -n datakit登录观测云控制台,点击「指标」 -「指标管理」,通过 scheduler 检索指标集,指标采集如下:
关键指标
| 指标 | 描述 | 类型 |
|---|---|---|
| scheduler_scheduler_cache_size | 调度器缓存中节点、Pod和AssumedPod(假定要调度的Pod)的数量 | Gauge |
| scheduler_pending_pods | Pending Pod的数量。队列种类如下:unschedulable :不可调度的Pod数量。backoff :backoffQ的Pod数量,即因为某种原因暂时不能被调度的Pod数量。active:activeQ的Pod数量,即准备就绪并等待被调度的Pod数量。 | Gauge |
| rest_client_request_duration_seconds_bucket | 从方法(Verb)和URL维度分析HTTP请求时延。 | Histogram |
| rest_client_requests_total | 从状态值(Status Code)、方法(Method)和主机(Host)维度分析HTTP请求数。 | Counter |
视图
登录观测云控制台,点击「场景」 -「新建仪表板」,模板库系统视图中,输入 "Scheduler", 选择"Kube Scheduler",点击"确定"。

监控器(告警)
- Scheduler pending pods 数量过多

- Kube API 请求时延过高

- Kube API 请求过多

总结
通过观测云监控 Kubernetes 集群中的核心组件之一 Kube Scheduler 的关键指标,可以更加清楚知道目前集群的运行情况,调整优化集群中 pod 的调度效率,及时响应和处理出现的各种问题,提高集群的稳定性。