1. 环境配置
需要4台虚拟机
harbor:172.25.254.200
master:172.25.254.100
k8s-node1:172.25.254.10
k8s-node2:172.25.254.20
1.1 先配置harbor
安装docker
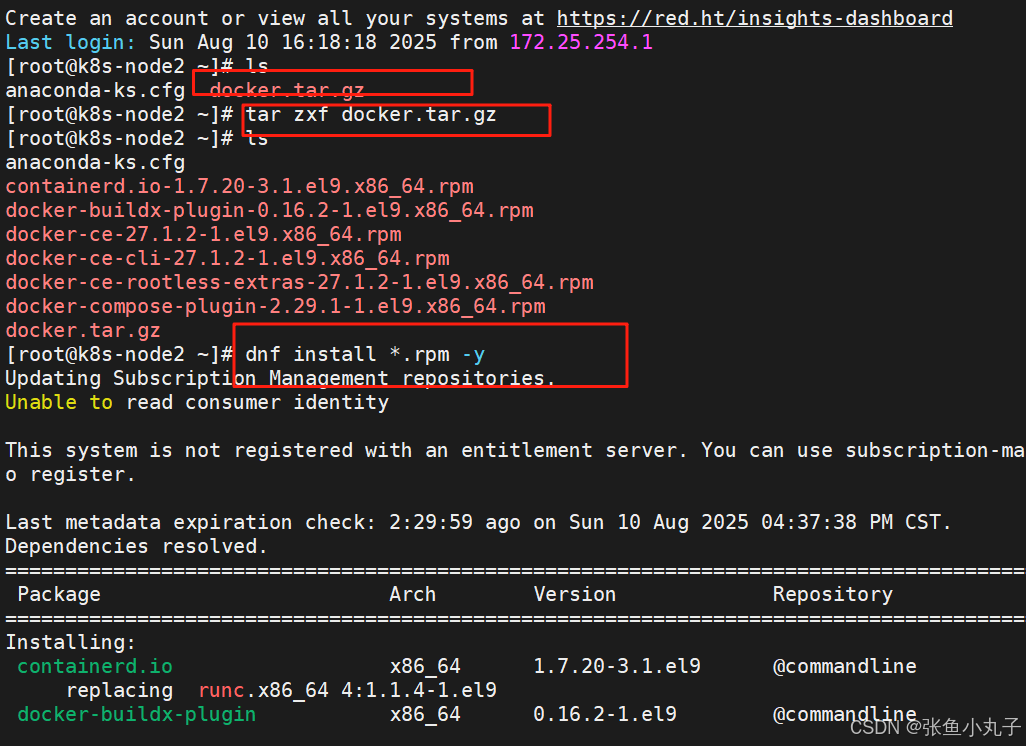
编辑配置文件
root@k8s-node2 \~# vim /lib/systemd/system/docker.service
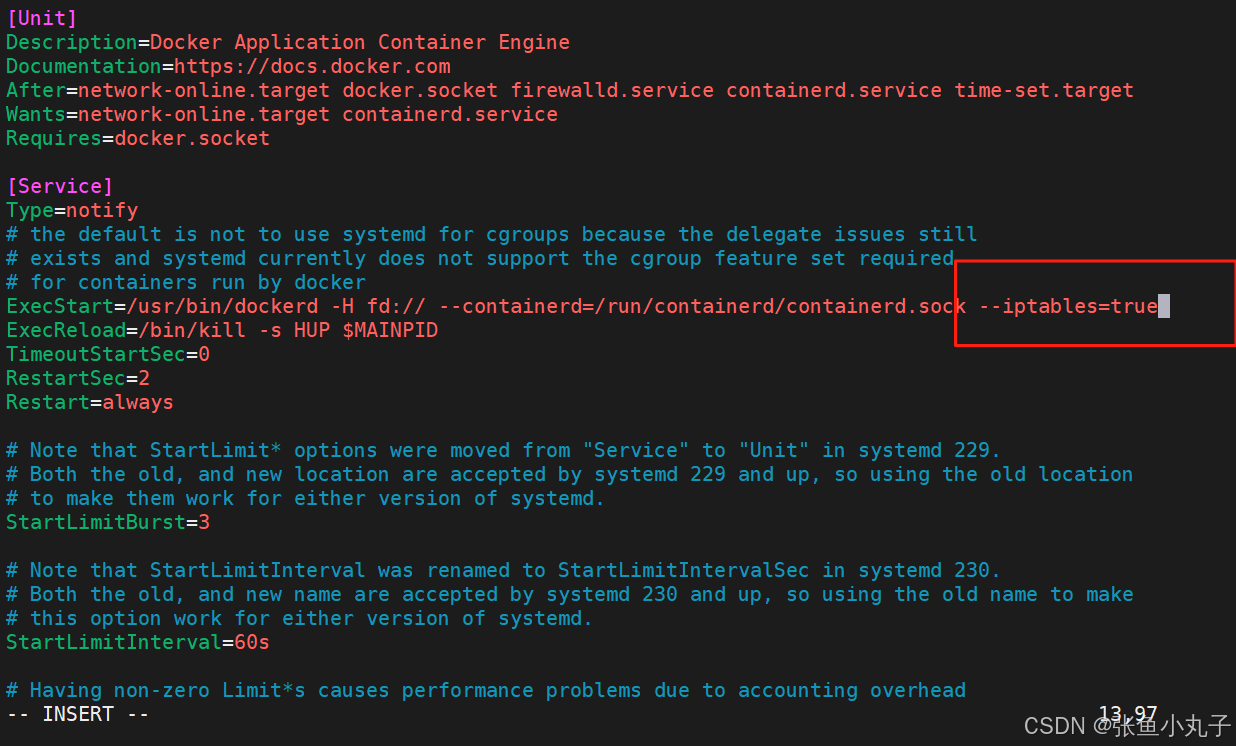
启动服务

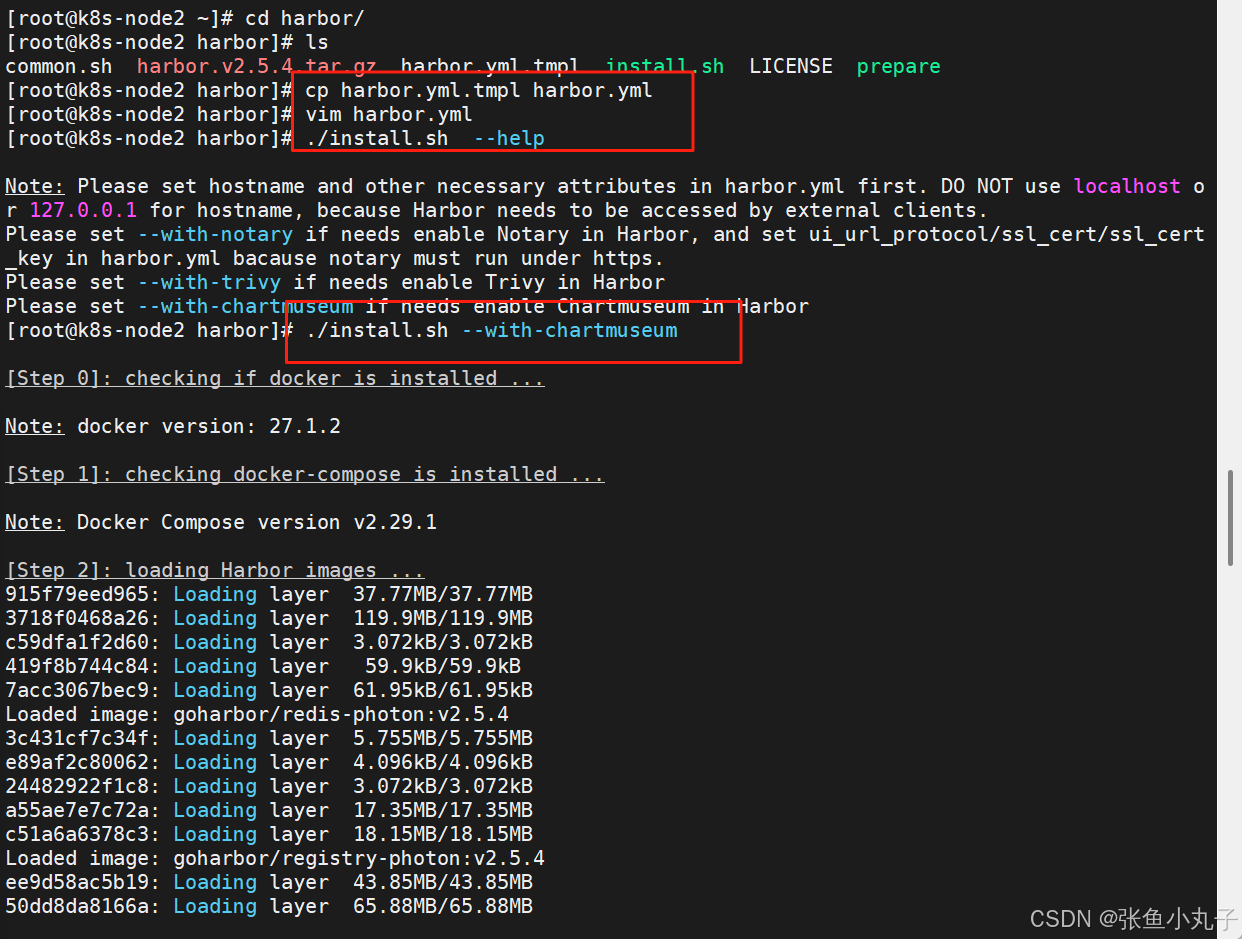
安装harbor,生成认证证书
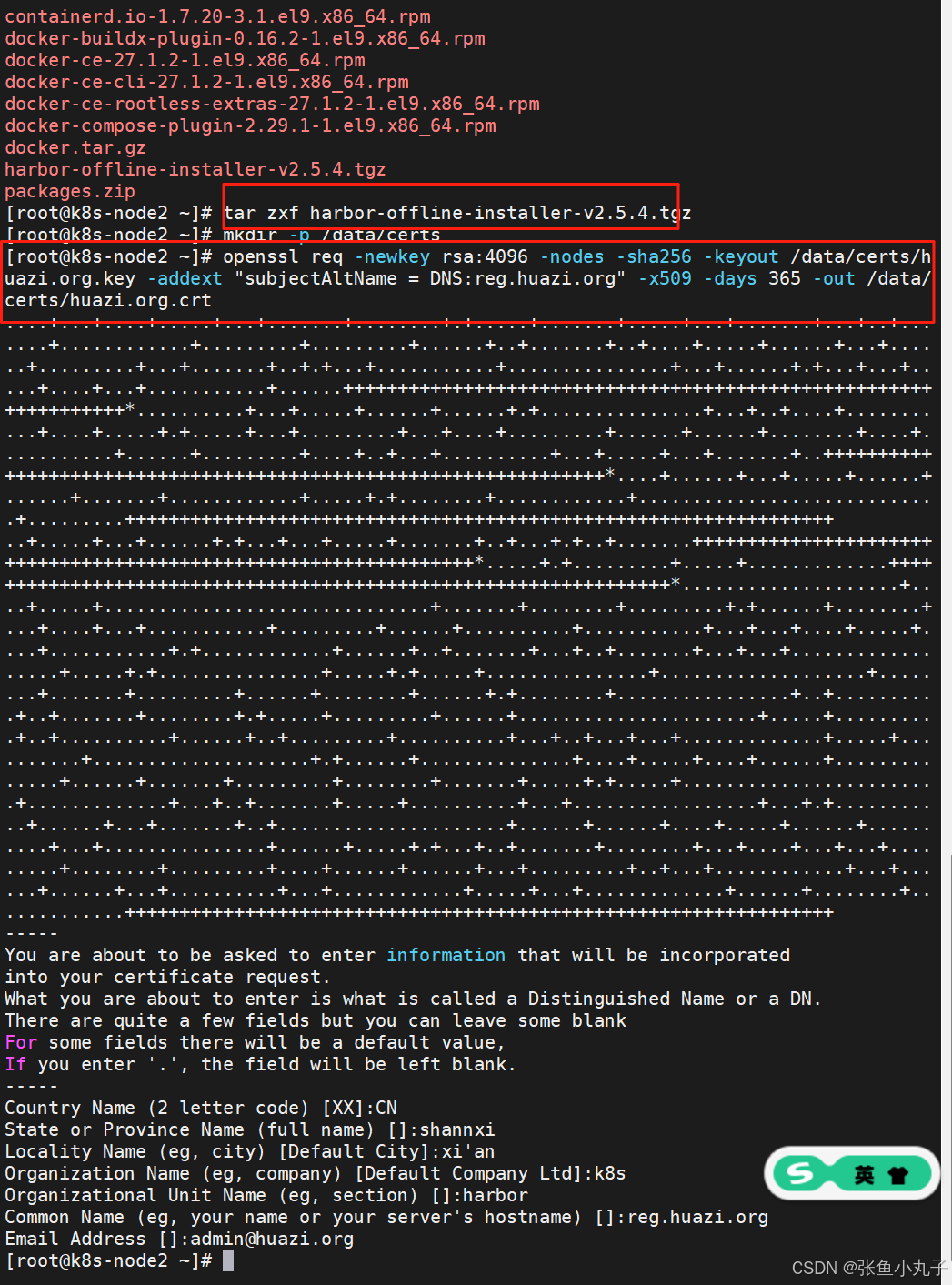
修改名字密码

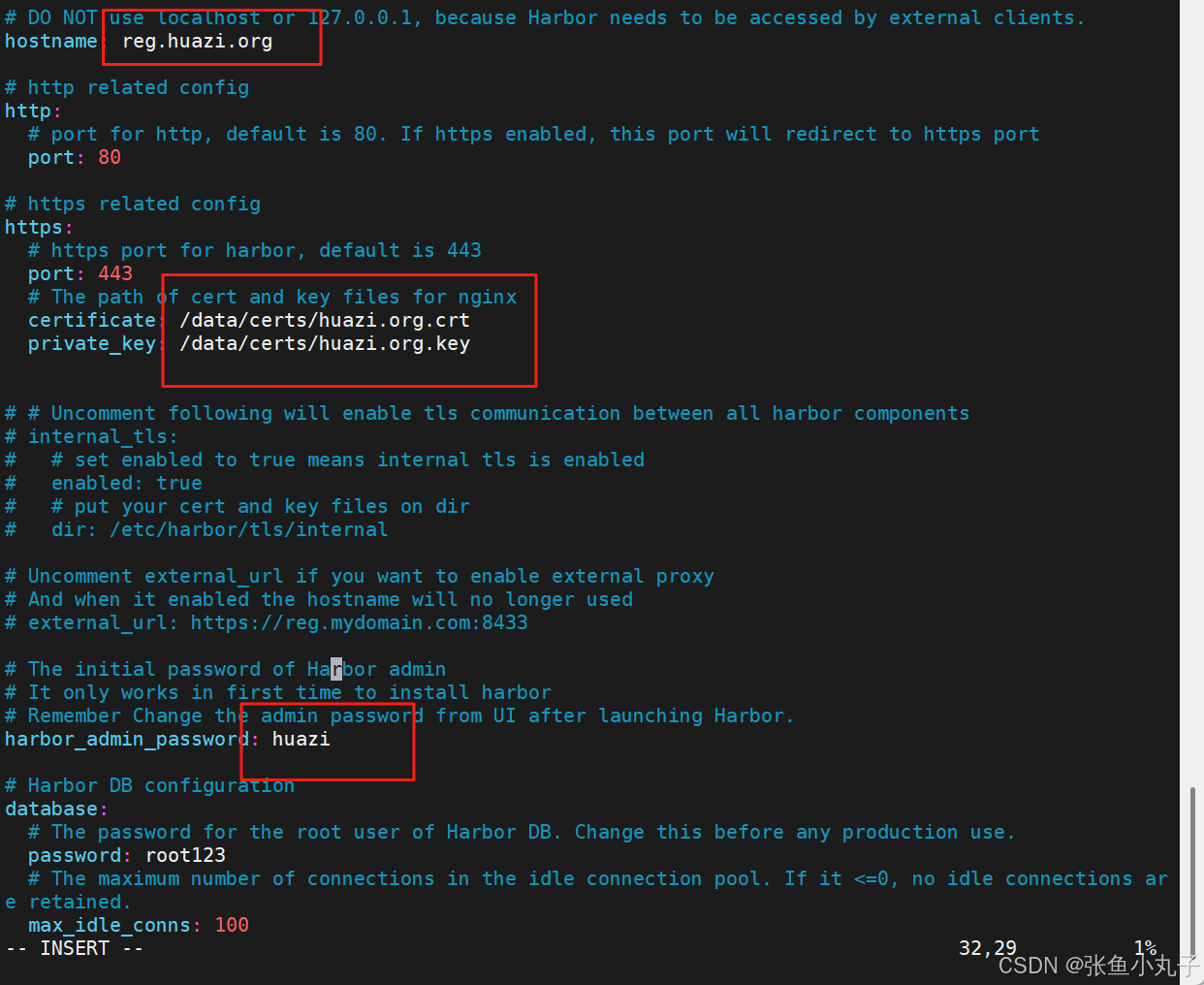
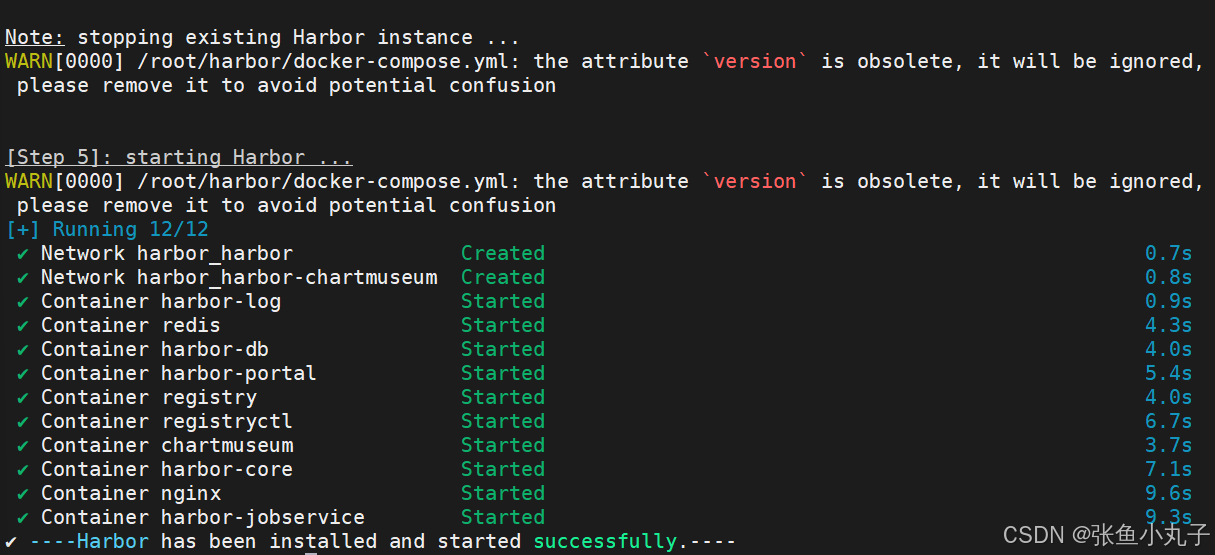
生成加载,成功即可
访问测试
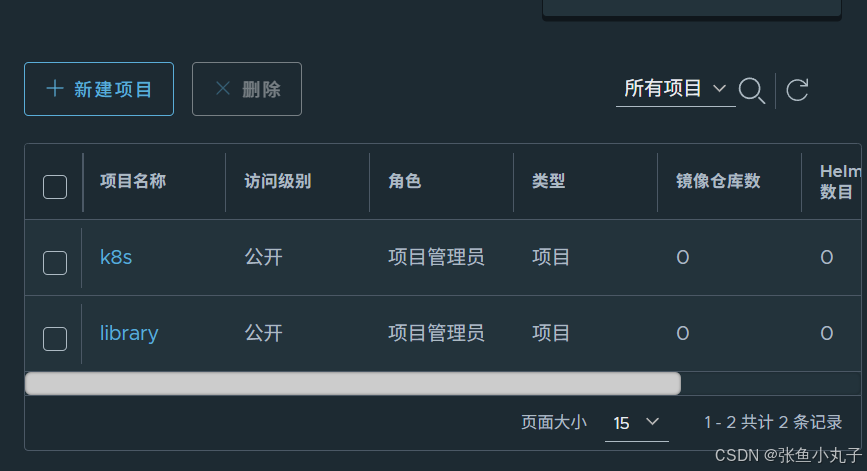
1.2 master配置
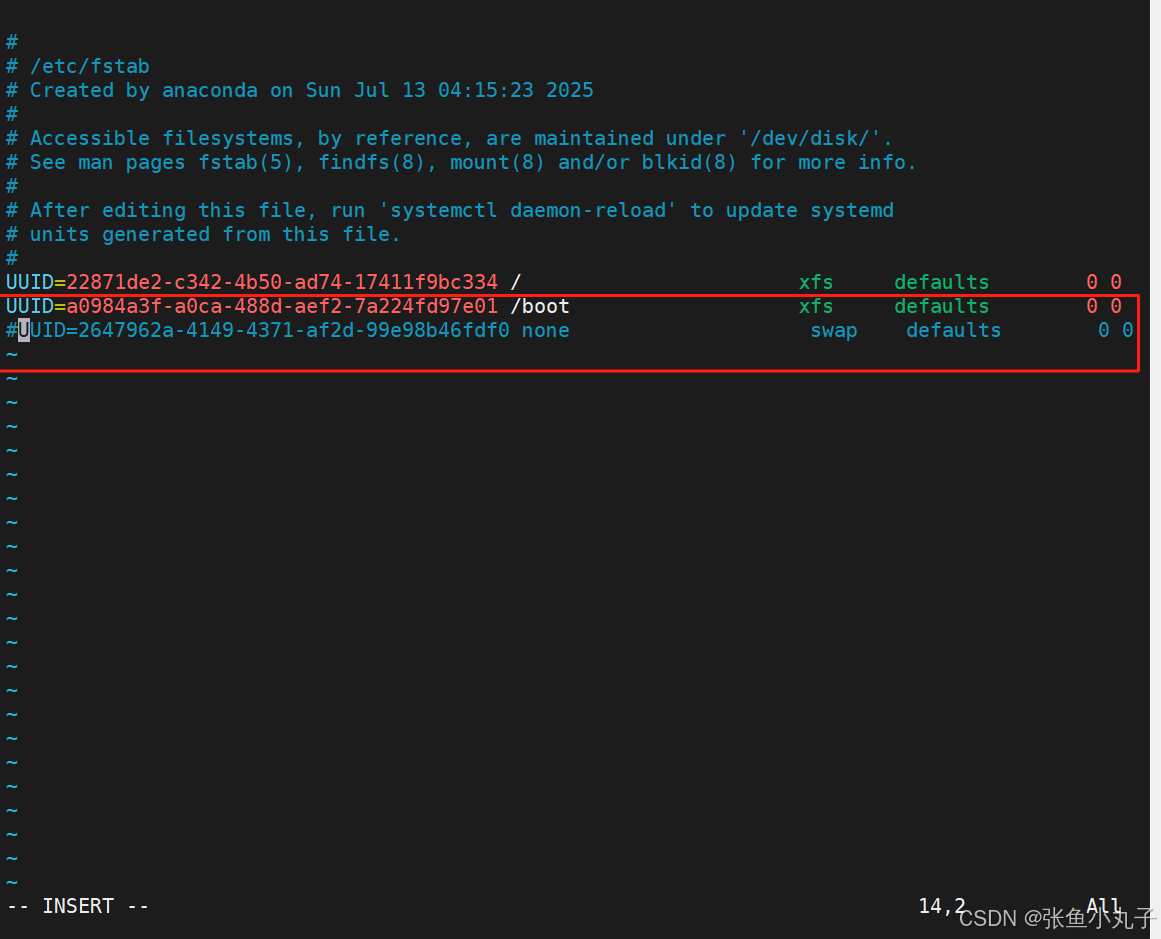
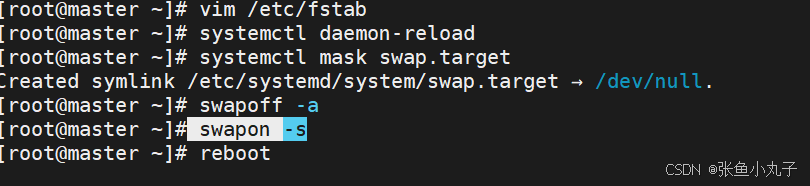
关闭swap分区,三台主机都要
root@master \~# vim /etc/fstab
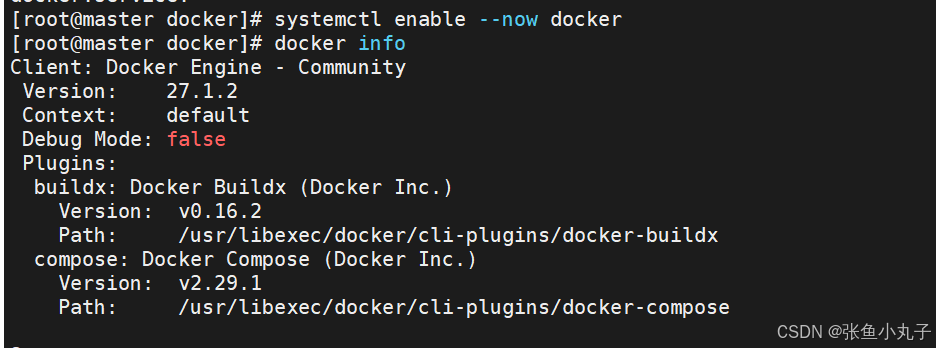
安装docker,把200复制过来就行,10和20命令一样
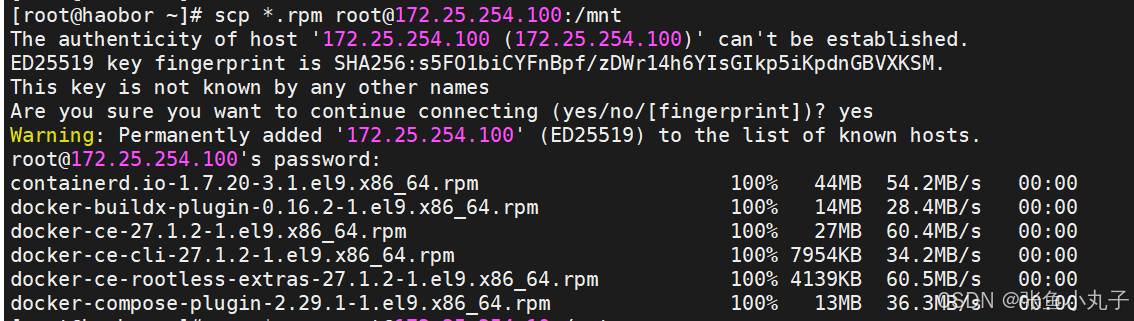
安装,三台都要
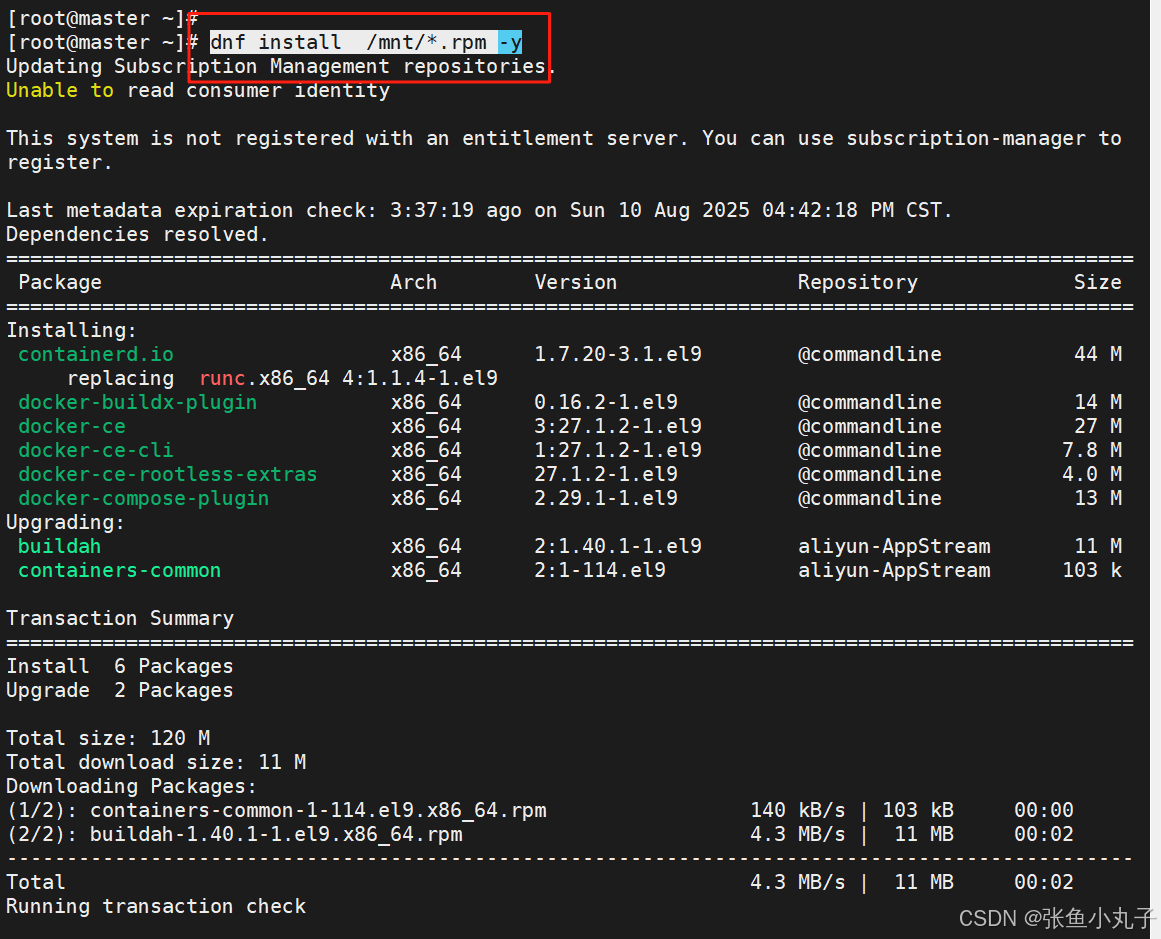
编辑配置文件
root@master \~# vim /lib/systemd/system/docker.service
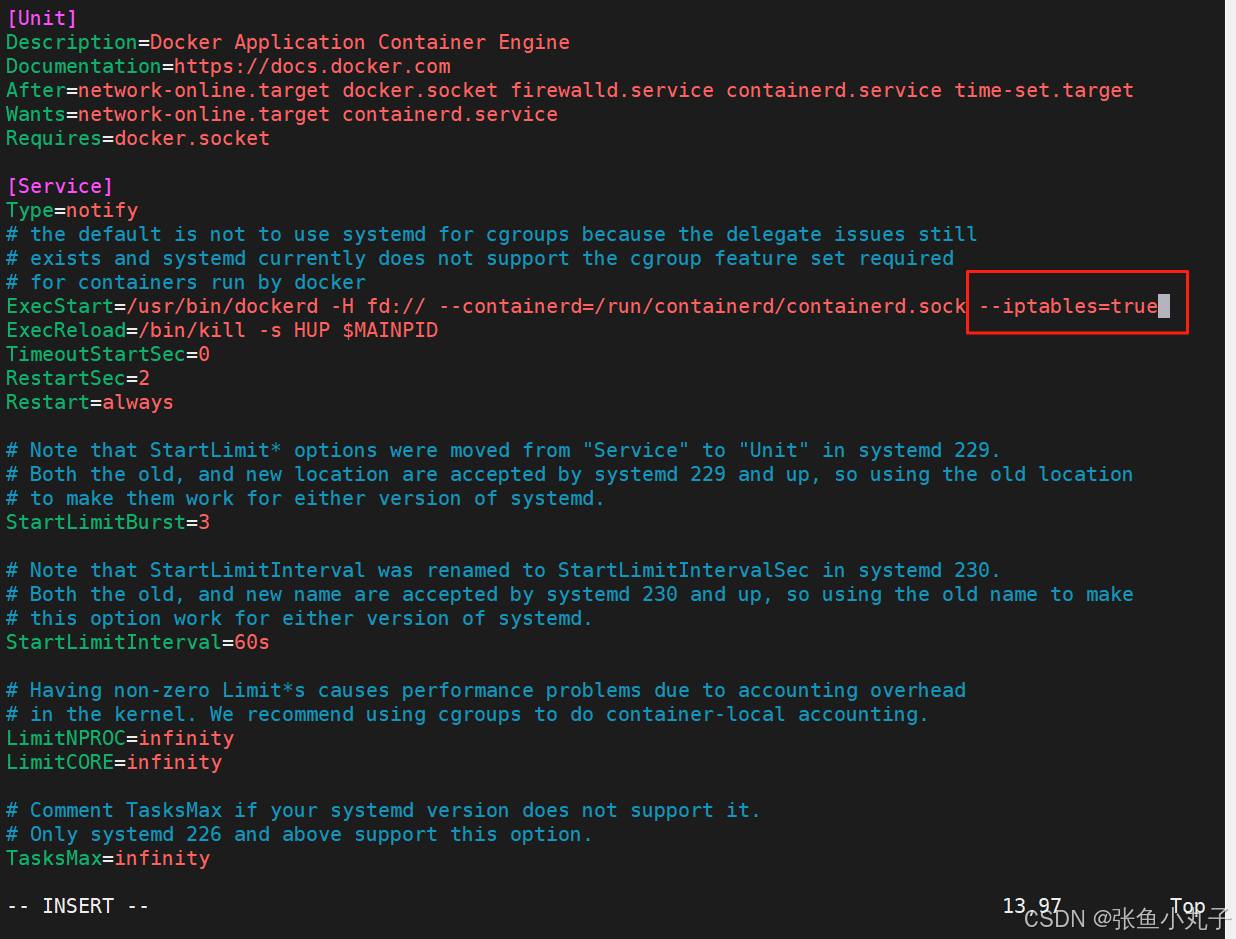
复制到10和20

复制crt过去
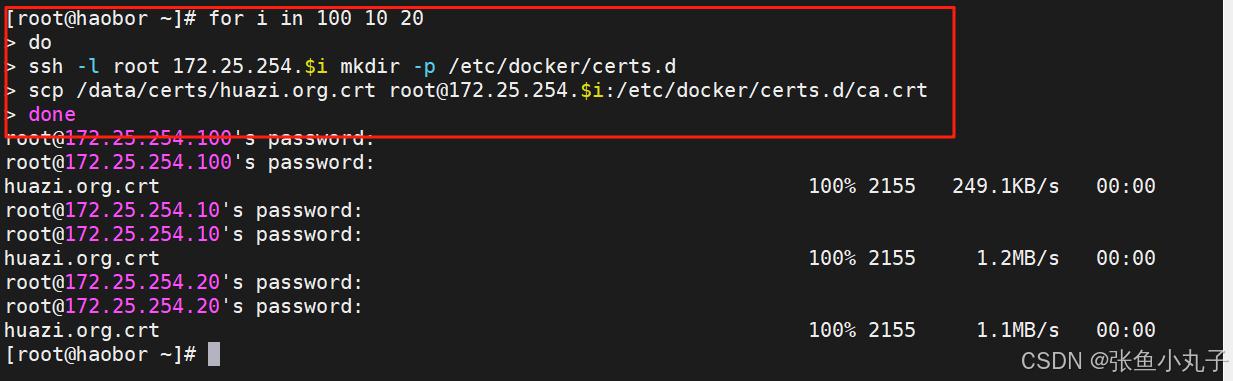
把200作为默认库
root@master docker# vim daemon.json

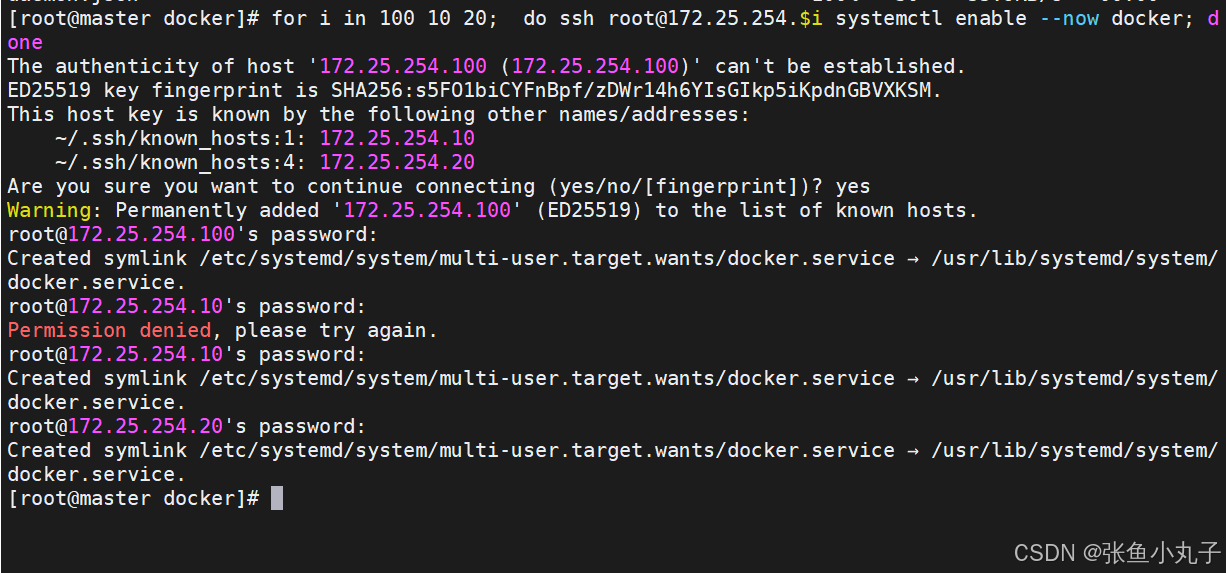
验证一下
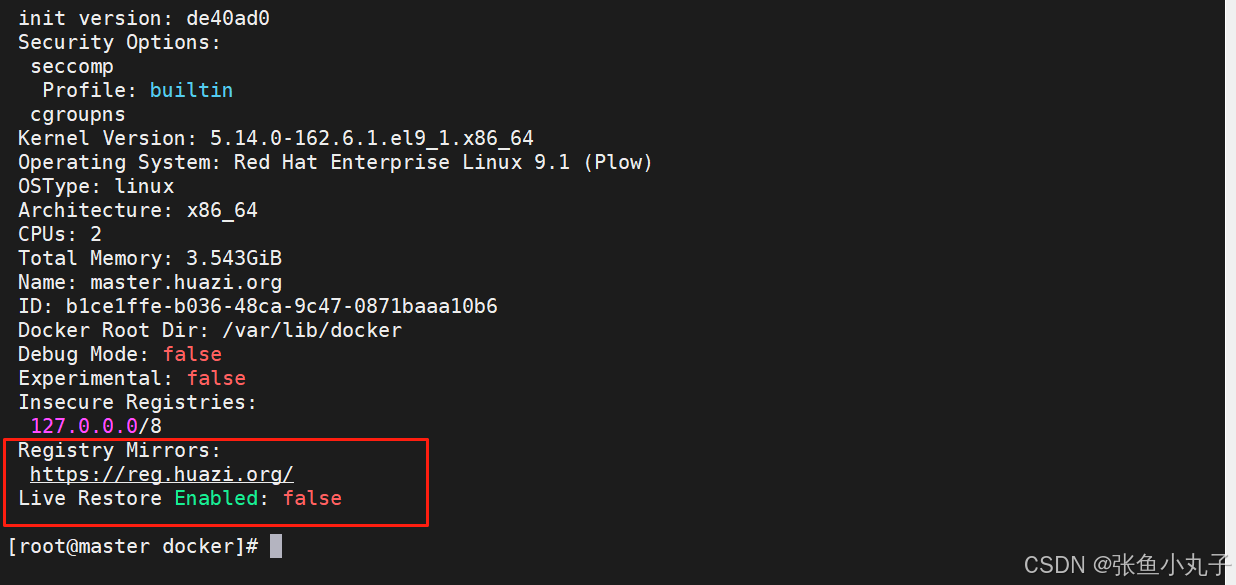
增加
root@master docker# vim /etc/hosts
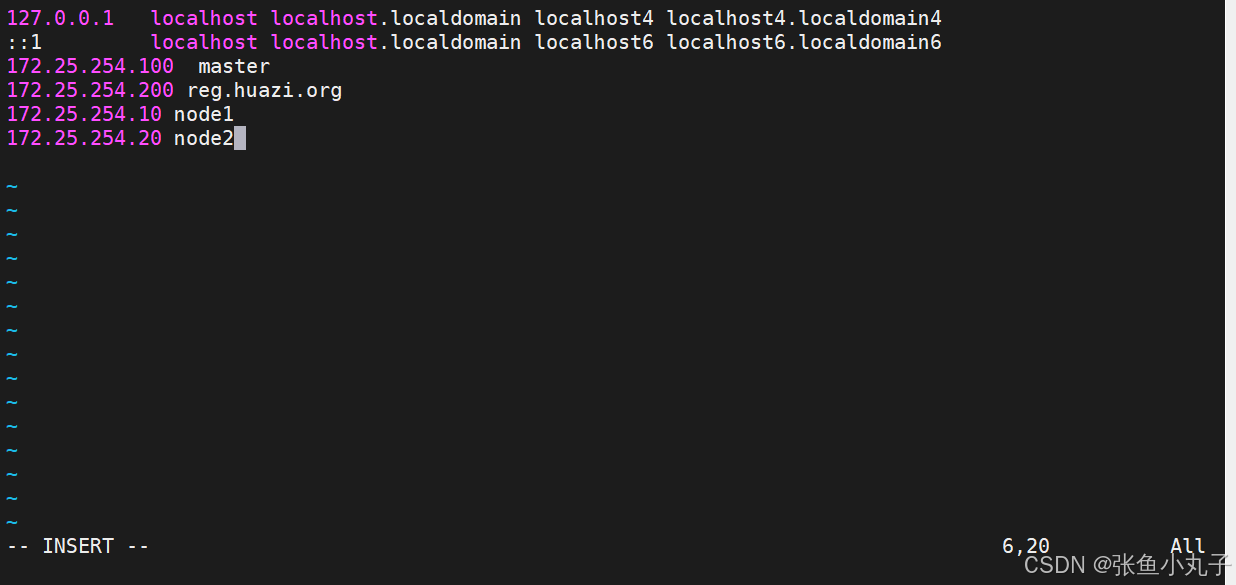
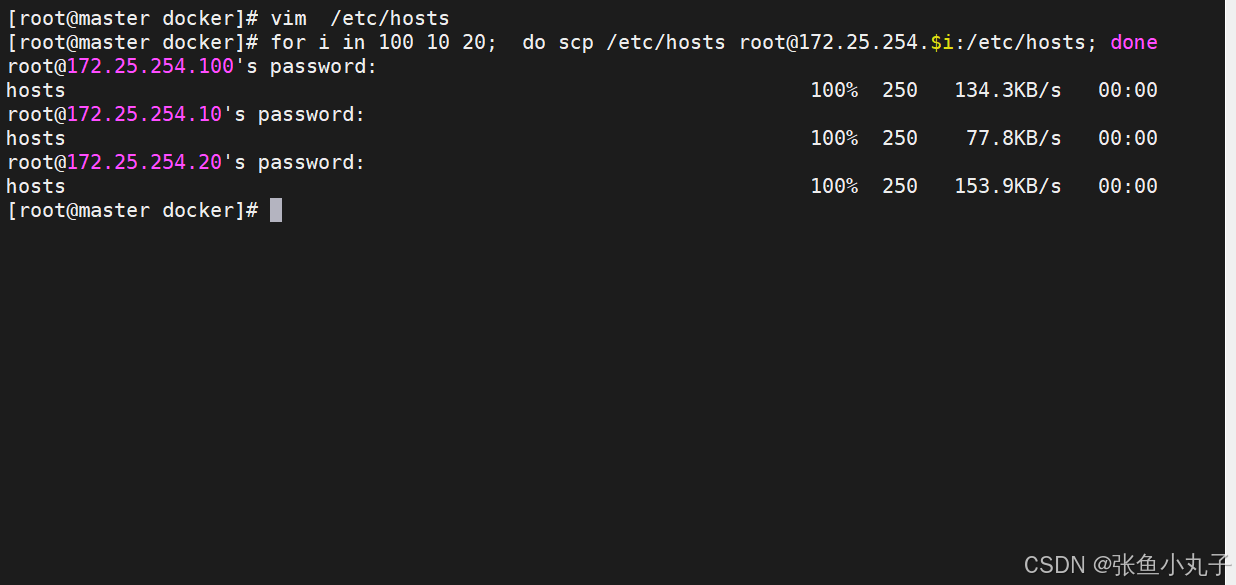
测试登录

安装k8s
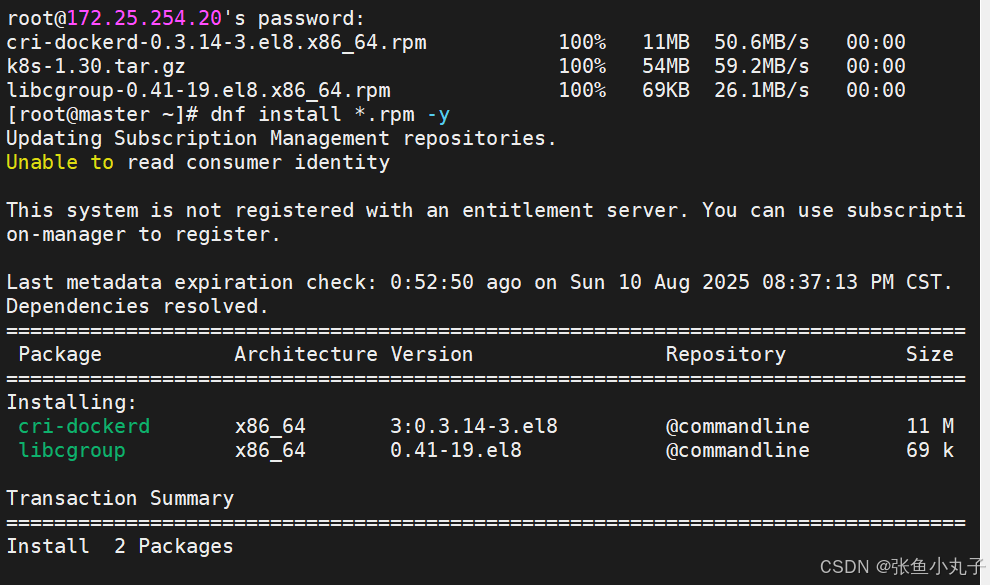
修改配置文件
root@master \~# vim /lib/systemd/system/cri-docker.service
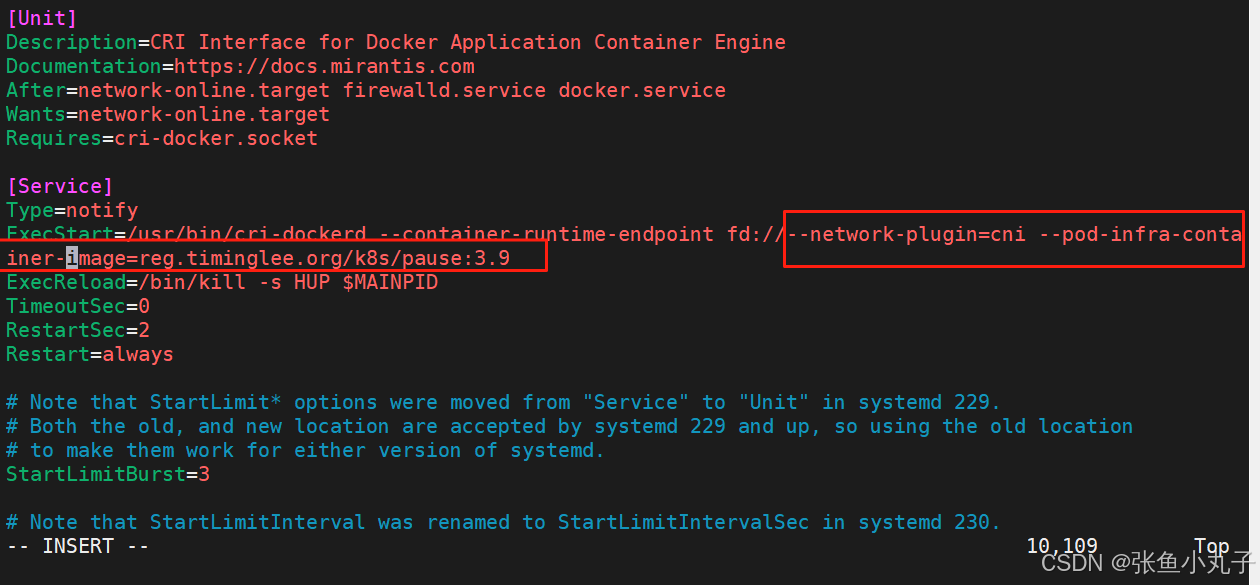
 解压k8s并安装
解压k8s并安装
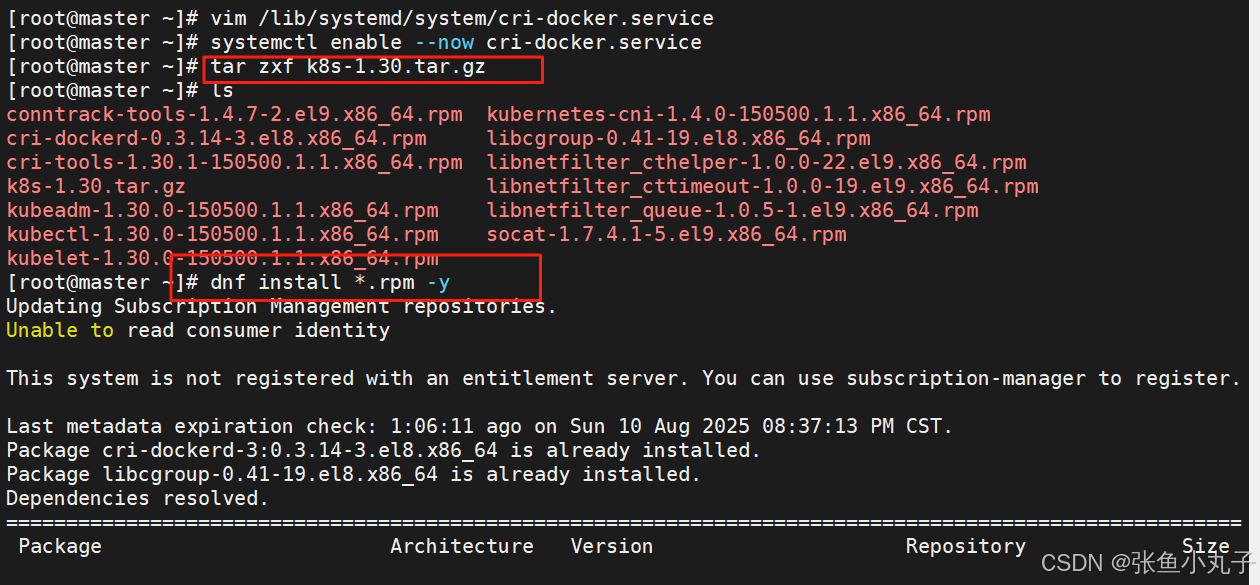
补齐功能

加载
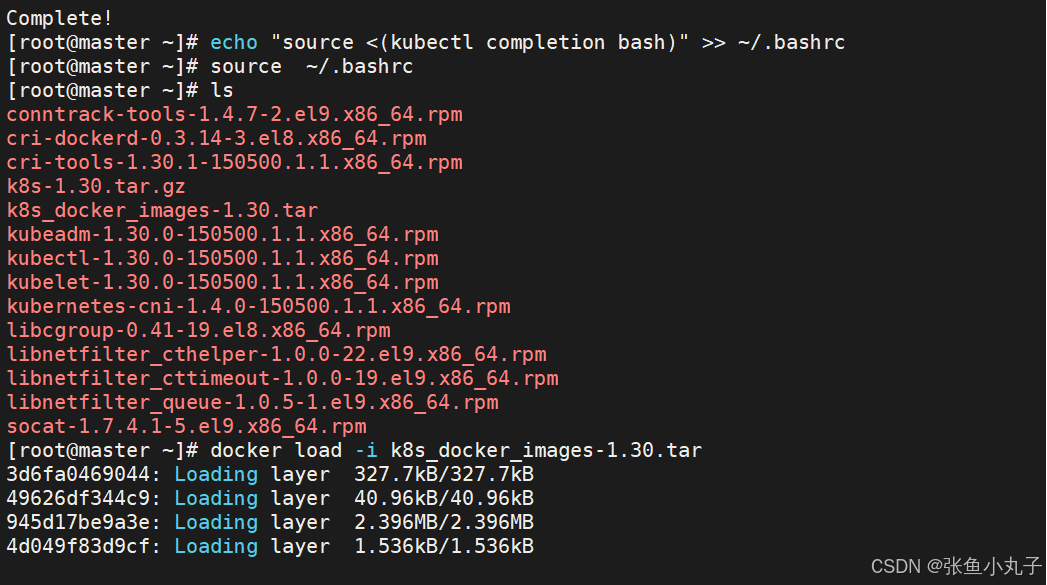
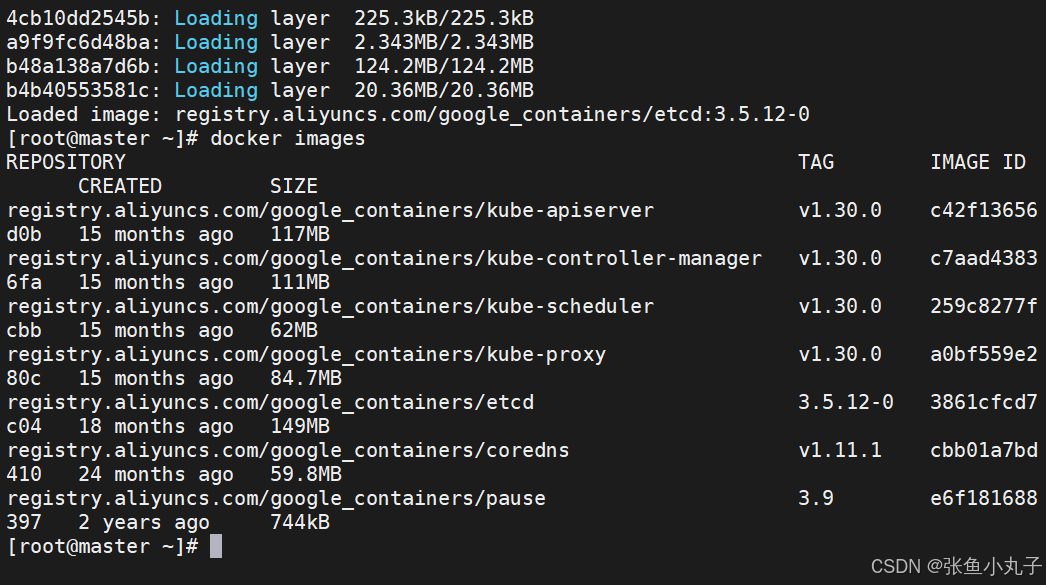
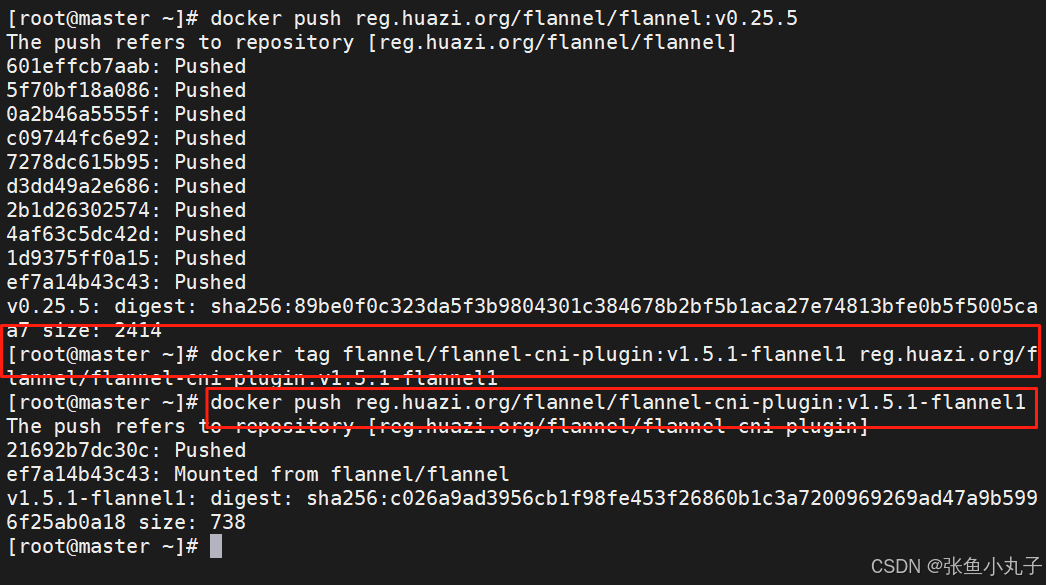
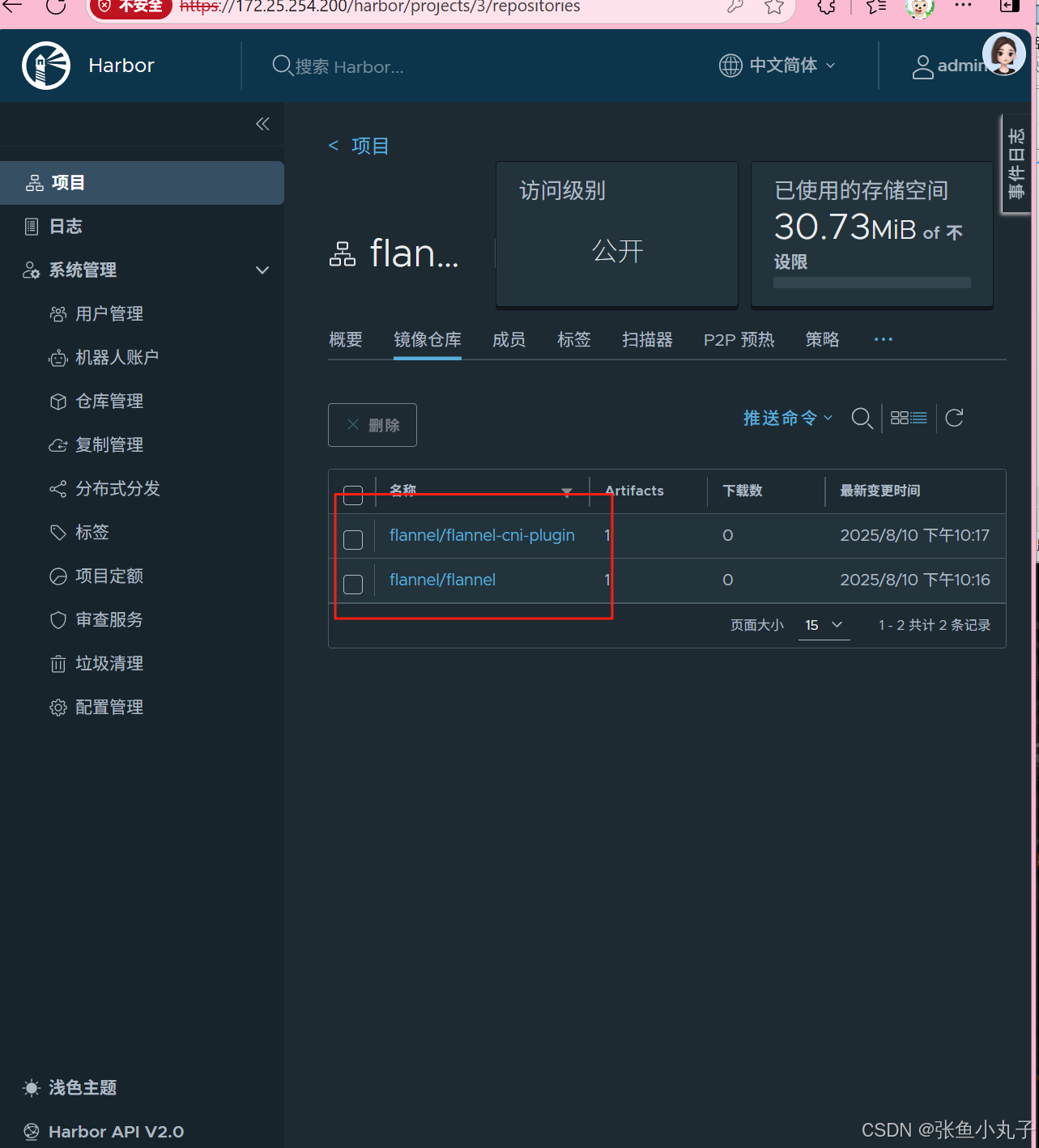
上传到harbor仓库
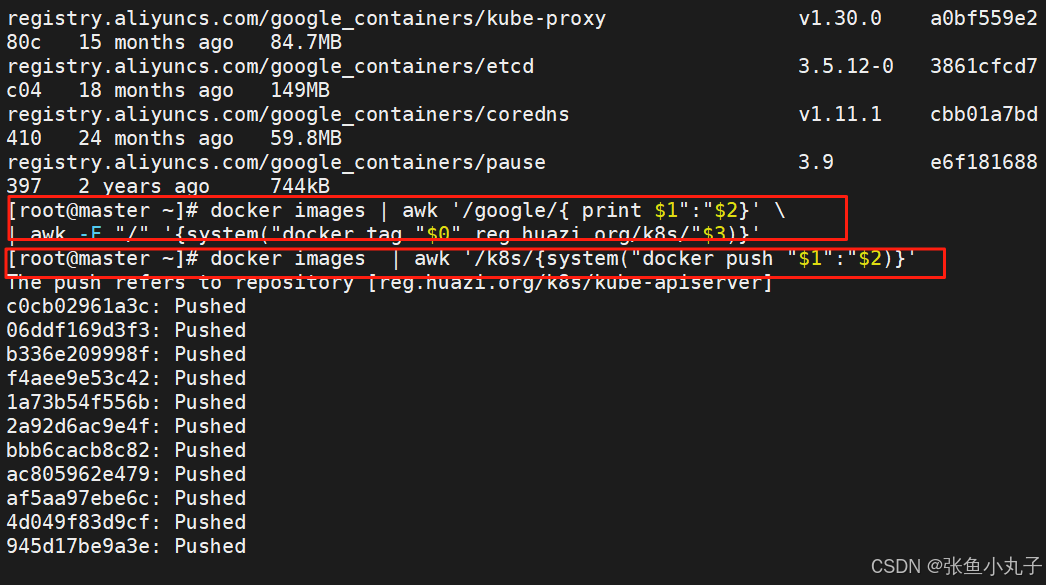
查看
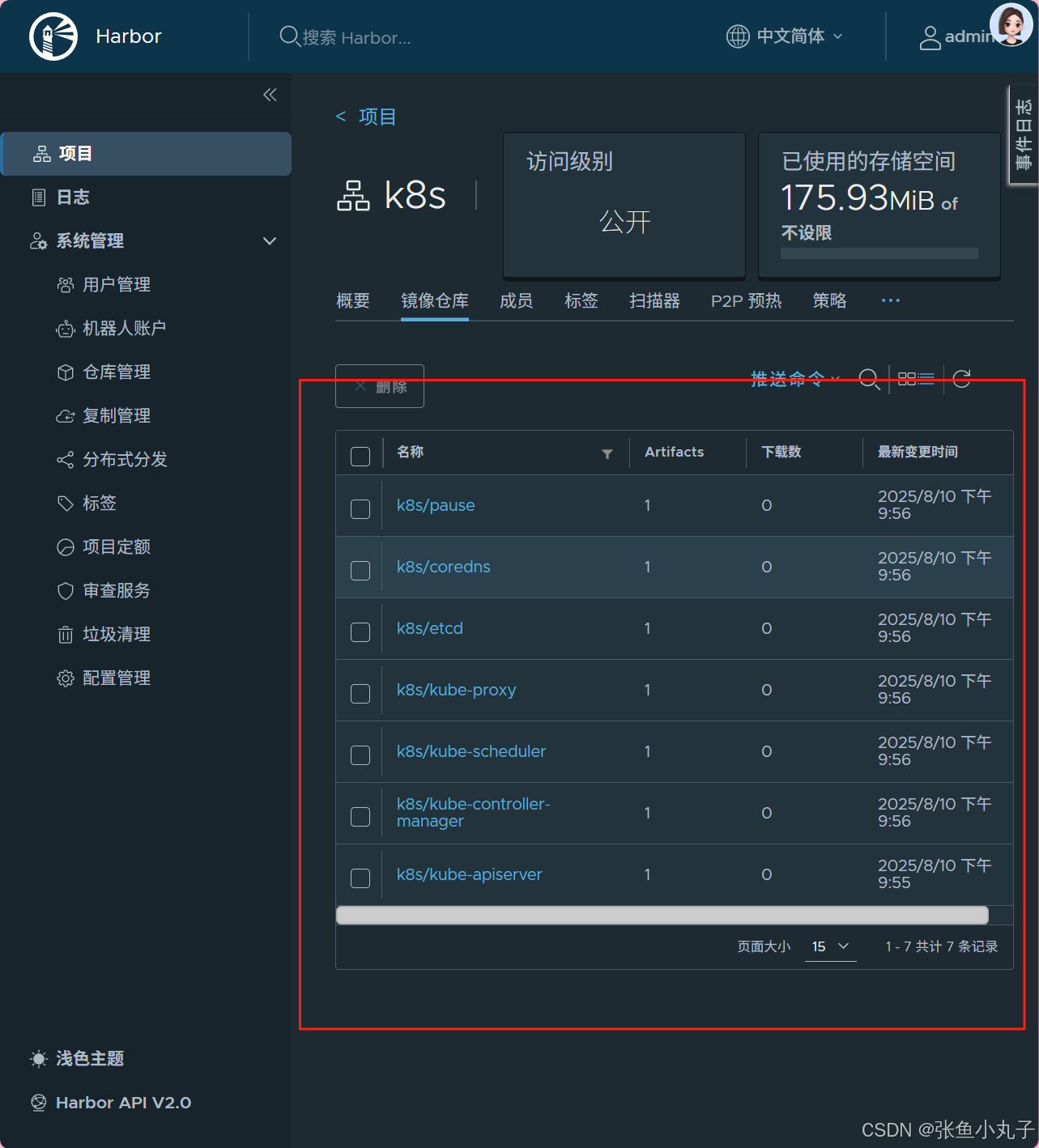
2.3 集群初始化
启动服务,所有主机都要打开

执行初始化命令
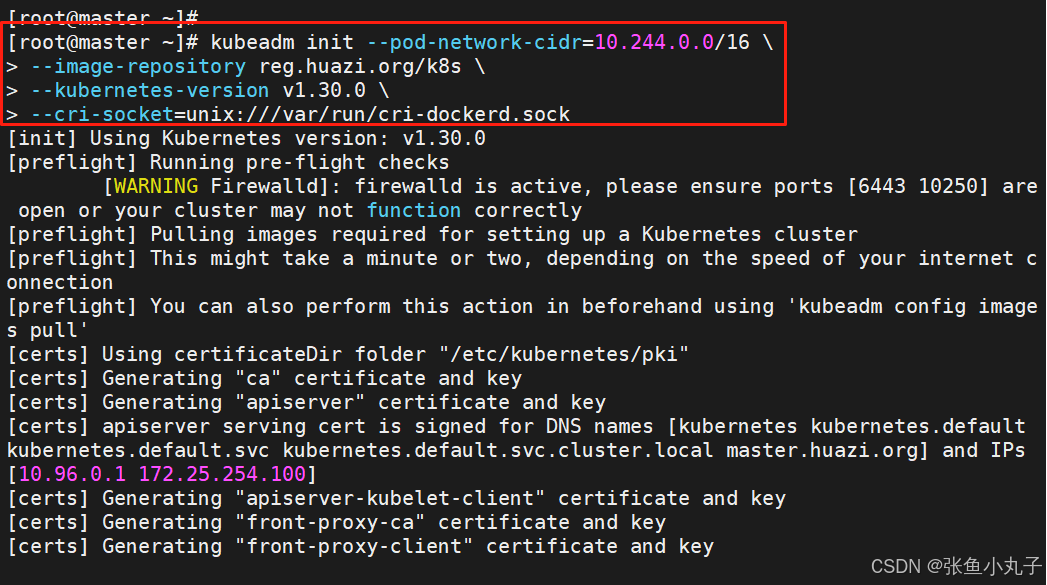
指定集群配置文件变量


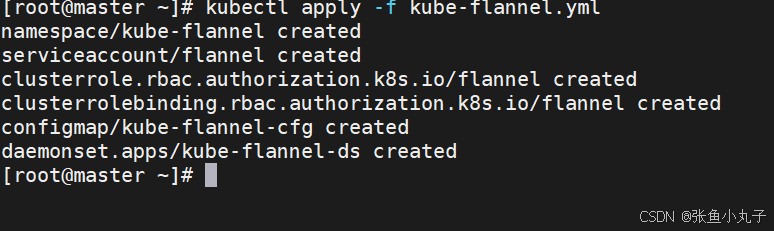
安装网络插件
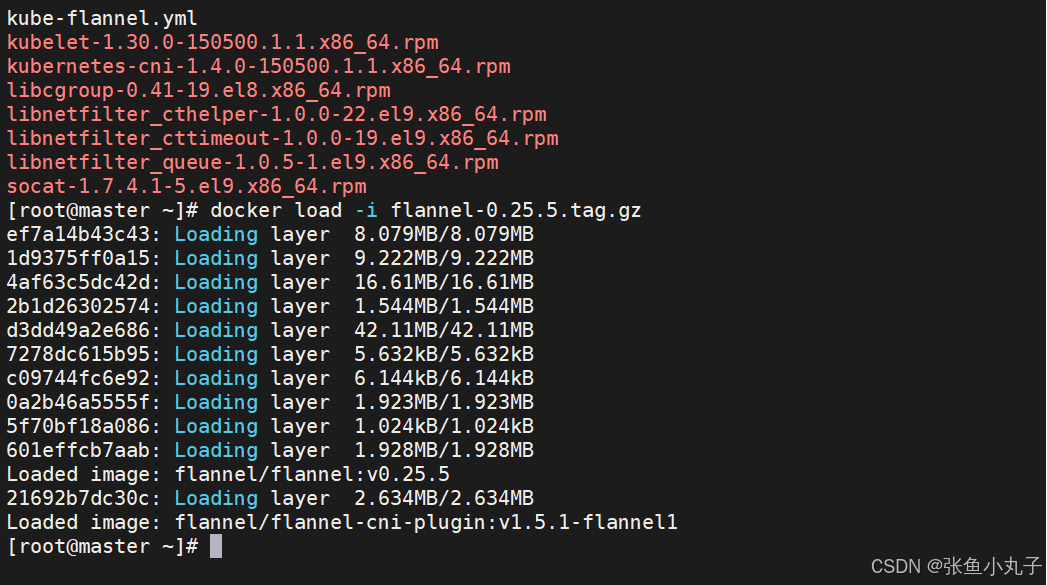

上传上去
编辑配置文件
root@master \~# vim kube-flannel.yml
都修改成这种,把前面去掉
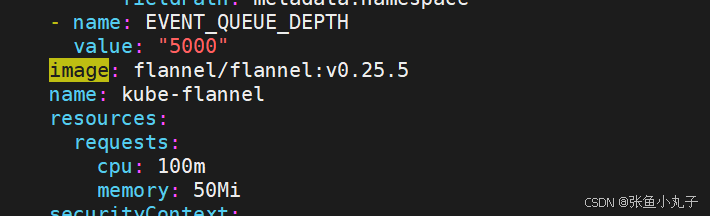

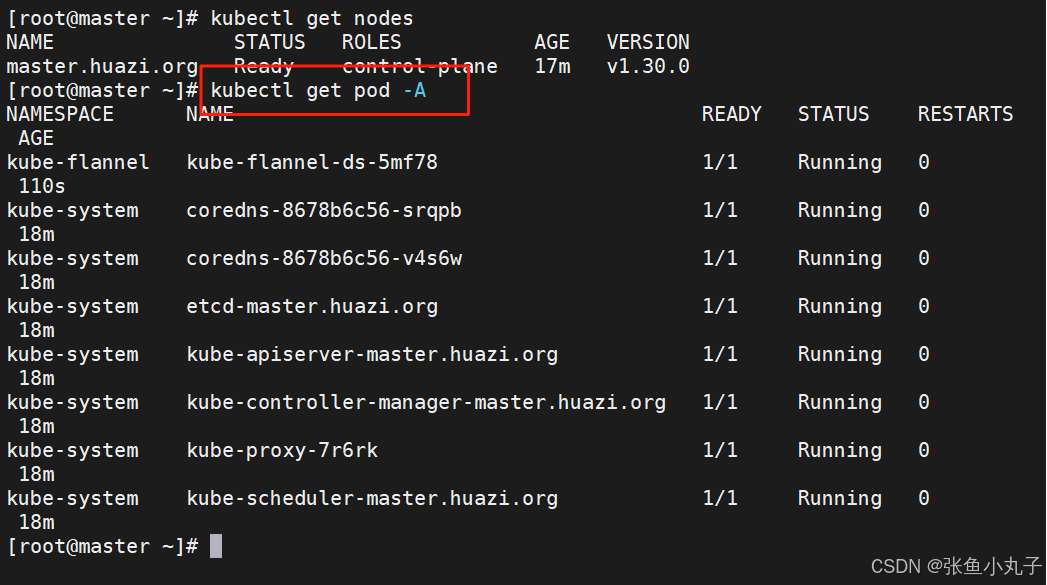
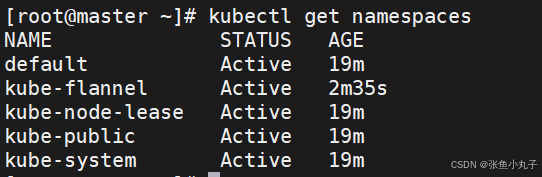

在10和20中
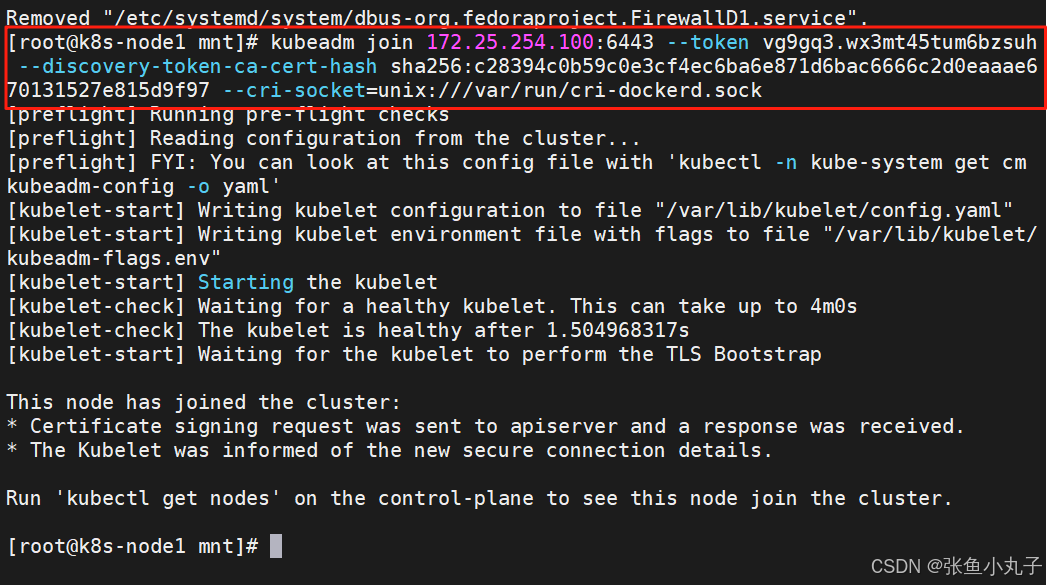
在100中查看

2. pod
-
Pod是可以创建和管理Kubernetes计算的最小可部署单元
-
一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip。
-
一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker)
-
多个容器间共享IPC、Network和UTC namespace。
2.1 创建自主式pod (生产不推荐)
优点:
灵活性高:
- 可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
学习和调试方便:
- 对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
适用于特殊场景:
- 在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
管理复杂:
- 如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
缺乏高级功能:
- 无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
可维护性差:
- 手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。

2.2 利用控制器管理pod(推荐)
高可用性和可靠性:
自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。
回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。
期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。
流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
- 一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
建立控制器并自动运行pod

添加扩容
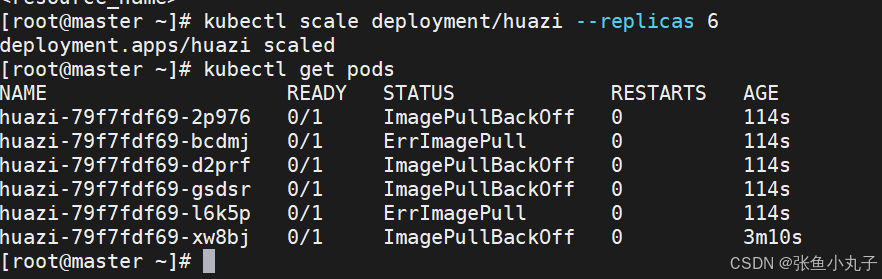
2.3 利用yaml文件部署应用
声明式配置:
-
清晰表达期望状态:以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。
-
可重复性和版本控制:配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。
-
团队协作:便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
-
丰富的配置选项:可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。
-
组合和扩展:可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
-
与 CI/CD 流程集成:可以将 YAML 配置文件与持续集成和持续部署(CI/CD)工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。
-
命令行工具支持:Kubernetes 的命令行工具
kubectl对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
资源清单参数
参数名称 类型 参数说明 version String 这里是指的是K8S API的版本,目前基本上是v1,可以用kubectl api-versions命令查询 kind String 这里指的是yaml文件定义的资源类型和角色,比如:Pod metadata Object 元数据对象,固定值就写metadata metadata.name String 元数据对象的名字,这里由我们编写,比如命名Pod的名字 metadata.namespace String 元数据对象的命名空间,由我们自身定义 Spec Object 详细定义对象,固定值就写Spec spec.containers\[\] list 这里是Spec对象的容器列表定义,是个列表 spec.containers\[\].name String 这里定义容器的名字 spec.containers\[\].image string 这里定义要用到的镜像名称 spec.containers\[\].imagePullPolicy String 定义镜像拉取策略,有三个值可选: (1) Always: 每次都尝试重新拉取镜像 (2) IfNotPresent:如果本地有镜像就使用本地镜像 (3) )Never:表示仅使用本地镜像 spec.containers\[\].command\[\] list 指定容器运行时启动的命令,若未指定则运行容器打包时指定的命令 spec.containers\[\].args\[\] list 指定容器运行参数,可以指定多个 spec.containers\[\].workingDir String 指定容器工作目录 spec.containers\[\].volumeMounts\[\] list 指定容器内部的存储卷配置 spec.containers\[\].volumeMounts\[\].name String 指定可以被容器挂载的存储卷的名称 spec.containers\[\].volumeMounts\[\].mountPath String 指定可以被容器挂载的存储卷的路径 spec.containers\[\].volumeMounts\[\].readOnly String 设置存储卷路径的读写模式,ture或false,默认为读写模式 spec.containers\[\].ports\[\] list 指定容器需要用到的端口列表 spec.containers\[\].ports\[\].name String 指定端口名称 spec.containers\[\].ports\[\].containerPort String 指定容器需要监听的端口号 spec.containers\[\] ports\[\].hostPort String 指定容器所在主机需要监听的端口号,默认跟上面containerPort相同,注意设置了hostPort同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) spec.containers\[\].ports\[\].protocol String 指定端口协议,支持TCP和UDP,默认值为 TCP spec.containers\[\].env\[\] list 指定容器运行前需设置的环境变量列表 spec.containers\[\].env\[\].name String 指定环境变量名称 spec.containers\[\].env\[\].value String 指定环境变量值 spec.containers\[\].resources Object 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) spec.containers\[\].resources.limits Object 指定设置容器运行时资源的运行上限 spec.containers\[\].resources.limits.cpu String 指定CPU的限制,单位为核心数,1=1000m spec.containers\[\].resources.limits.memory String 指定MEM内存的限制,单位为MIB、GiB spec.containers\[\].resources.requests Object 指定容器启动和调度时的限制设置 spec.containers\[\].resources.requests.cpu String CPU请求,单位为core数,容器启动时初始化可用数量 spec.containers\[\].resources.requests.memory String 内存请求,单位为MIB、GIB,容器启动的初始化可用数量 spec.restartPolicy string 定义Pod的重启策略,默认值为Always. (1)Always: Pod-旦终止运行,无论容器是如何 终止的,kubelet服务都将重启它 (2)OnFailure: 只有Pod以非零退出码终止时,kubelet才会重启该容器。如果容器正常结束(退出码为0),则kubelet将不会重启它 (3) Never: Pod终止后,kubelet将退出码报告给Master,不会重启该 spec.nodeSelector Object 定义Node的Label过滤标签,以key:value格式指定 spec.imagePullSecrets Object 定义pull镜像时使用secret名称,以name:secretkey格式指定 spec.hostNetwork Boolean 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机 上启动第二个副本
单个容器
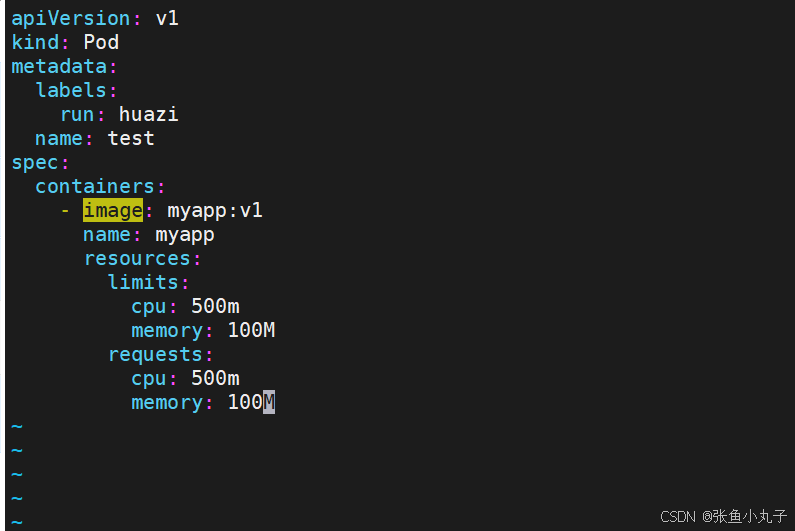
root@master \~# vim pod.yml
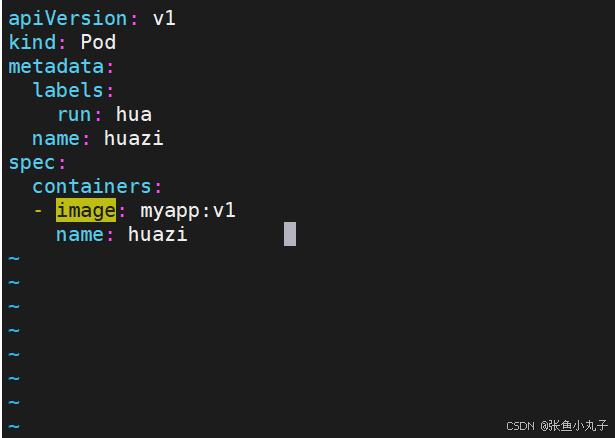
多个容器
如果多个容器运行在一个pod中,资源共享的同时在使用相同资源时也会干扰,比如端口
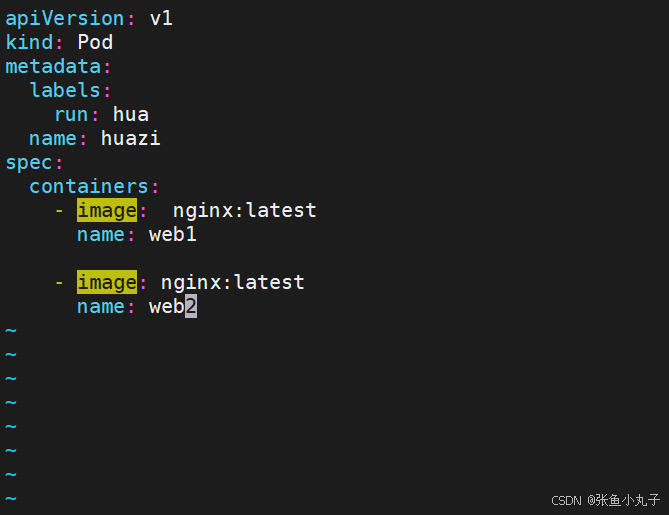
保证彼此互不打扰
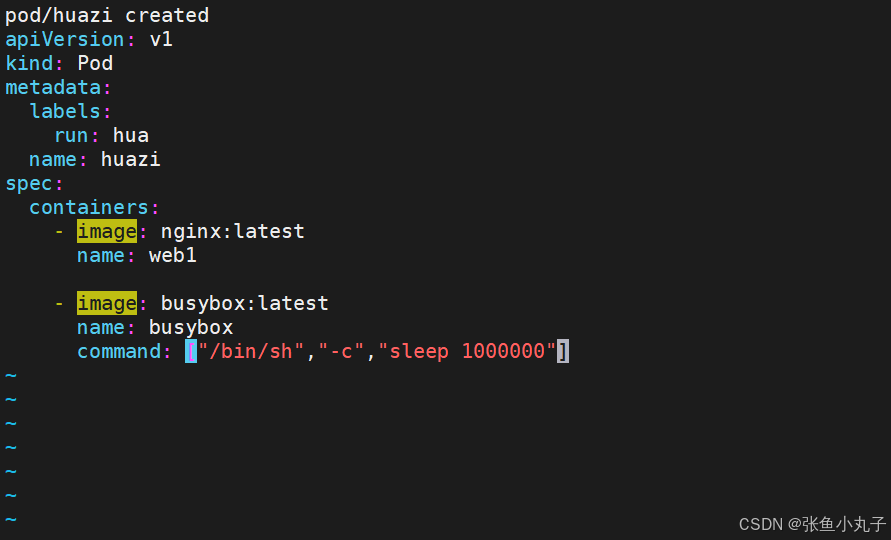
网络整合
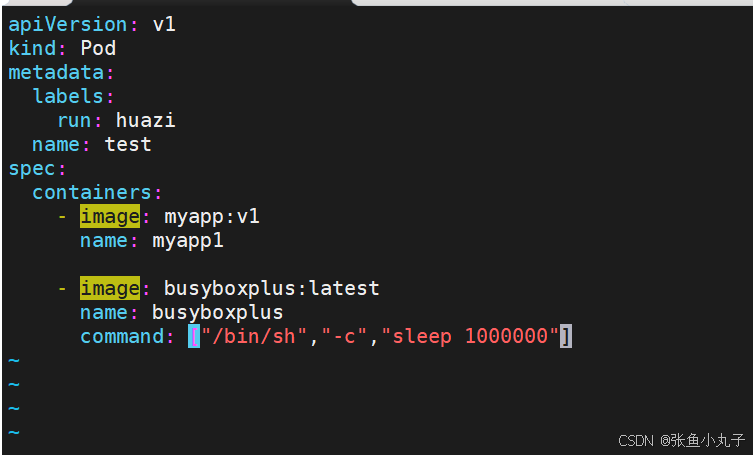
端口映射 ,修改配置文件即可
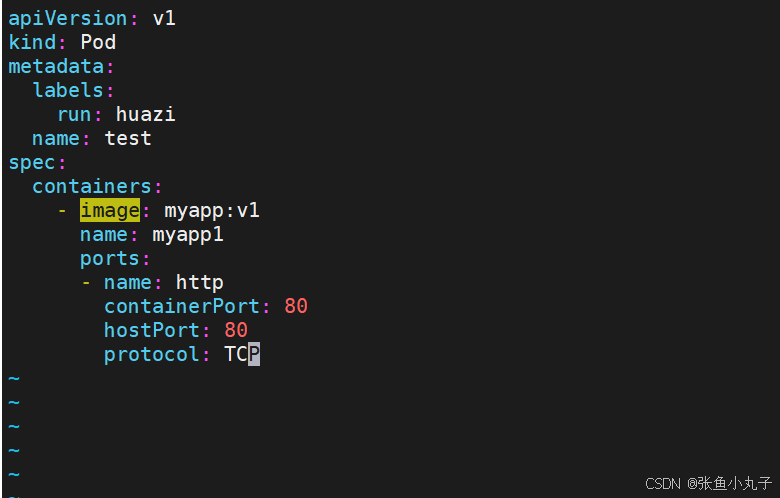
设定环境变量
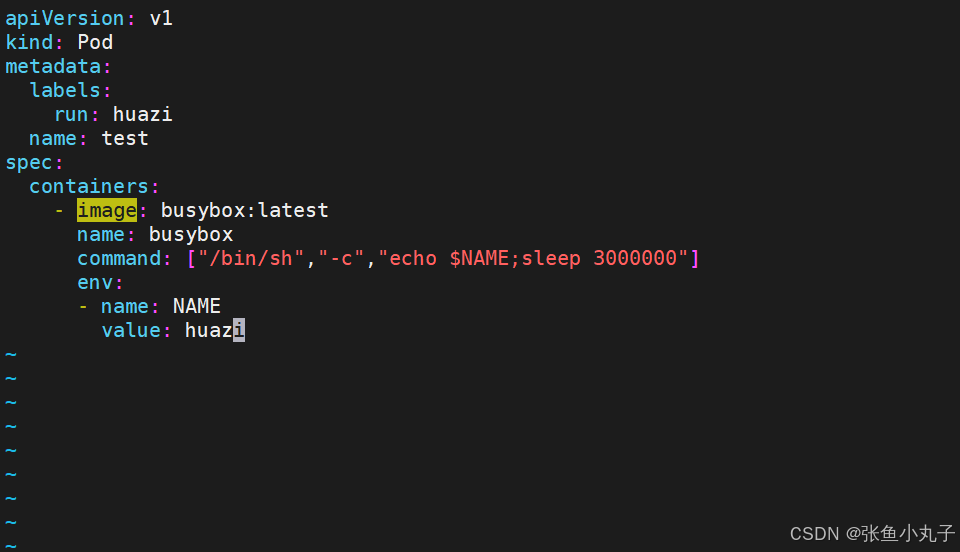
资源限制
资源限制会影响pod的Qos Class资源优先级,资源优先级分为Guaranteed > Burstable > BestEffort
| 资源设定 | 优先级类型 |
|---|---|
| 资源限定未设定 | BestEffort |
| 资源限定设定且最大和最小不一致 | Burstable |
| 资源限定设定且最大和最小一致 | Guaranteed |
root@master \~# kubectl apply -f pod.yml
root@master \~# kubectl get pods
3. 微服务类型详解
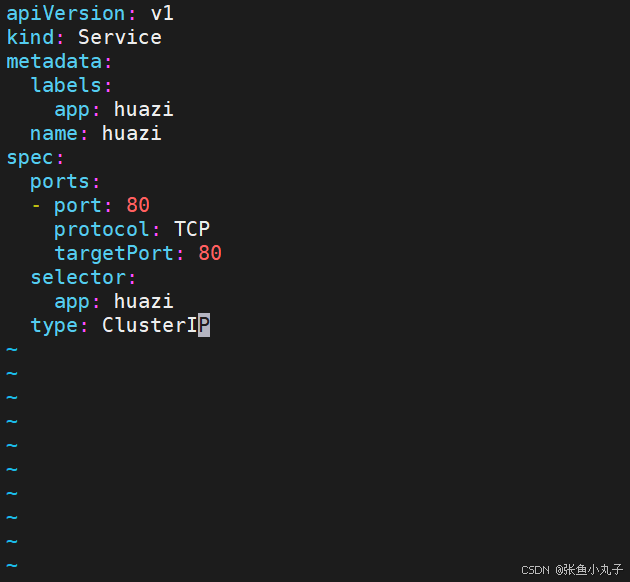
3.1 clusterip
特点:
clusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功
编辑配置文件
root@master replicaset# vim myapp.yml
service创建后集群DNS提供解析
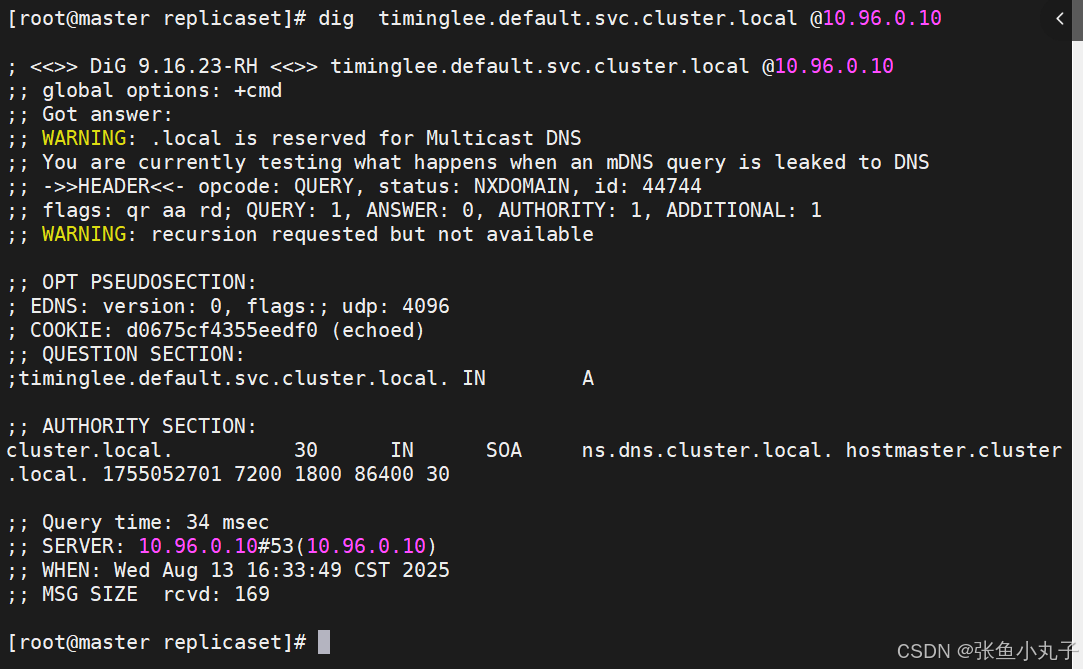
3.2 ClusterIP中的特殊模式headless
headless(无头服务)
对于无头
Services并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度有dns单独完
修改配置文件
[root@master replicaset]# vim hauzi.yaml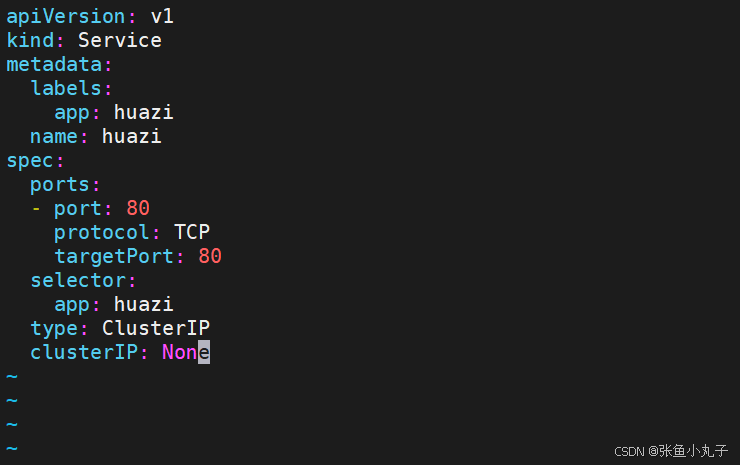
应用
[root@master replicaset]# kubectl apply -f timinglee.yaml
测试
3.3 nodeport
通过ipvs暴漏端口从而使外部主机通过master节点的对外ip:<port>来访问pod业务
其访问过程为:

编辑配置
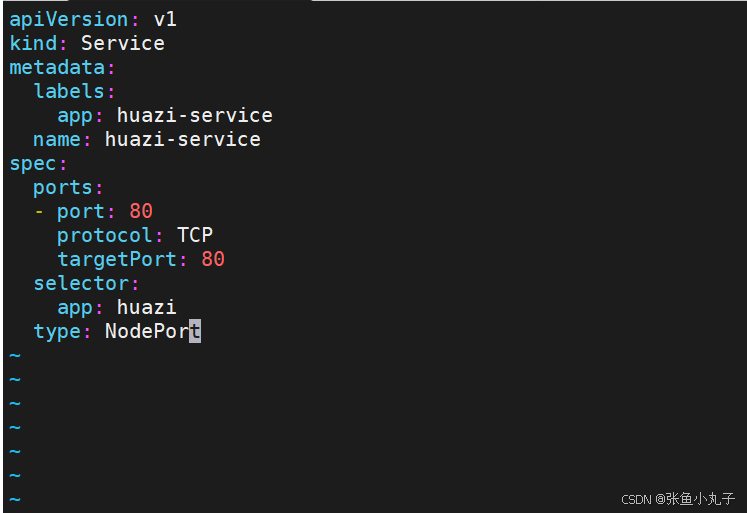
[root@master replicaset]# kubectl apply -f huazi.yaml
[root@master replicaset]# kubectl get services huazi-service3.4 loadbalancer
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配

改配置文件
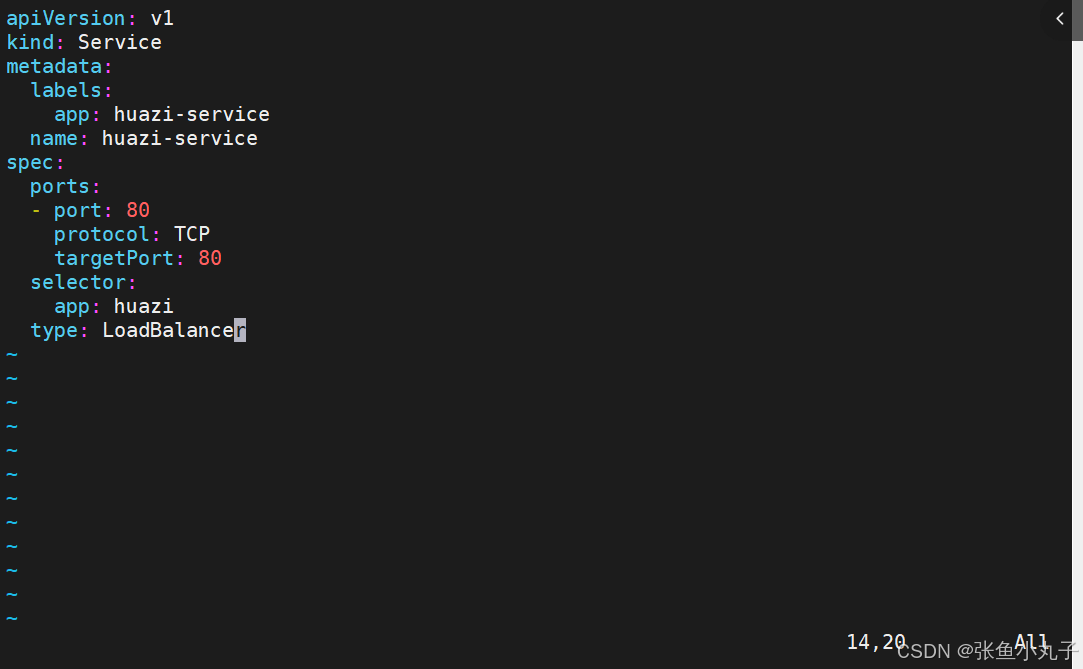
应用
[root@master replicaset]# kubectl apply -f myapp.yml默认无法分配外部访问IP
LoadBalancer模式适用云平台,裸金属环境需要安装metallb提供支持

3.5 metalLB
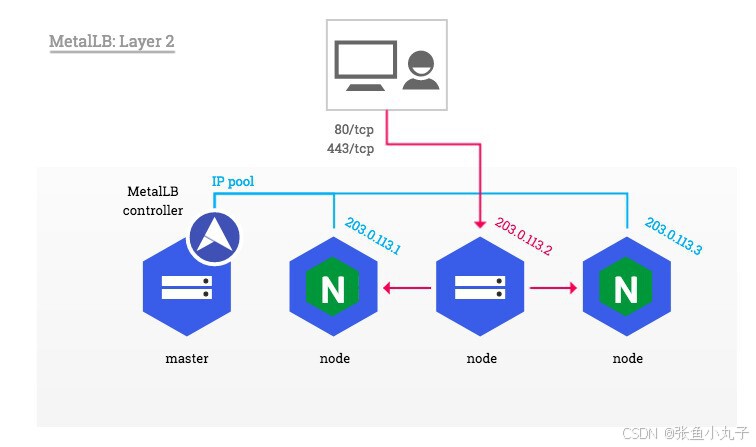
metalLB功能:为LoadBalancer分配vip
设置ipvs模式
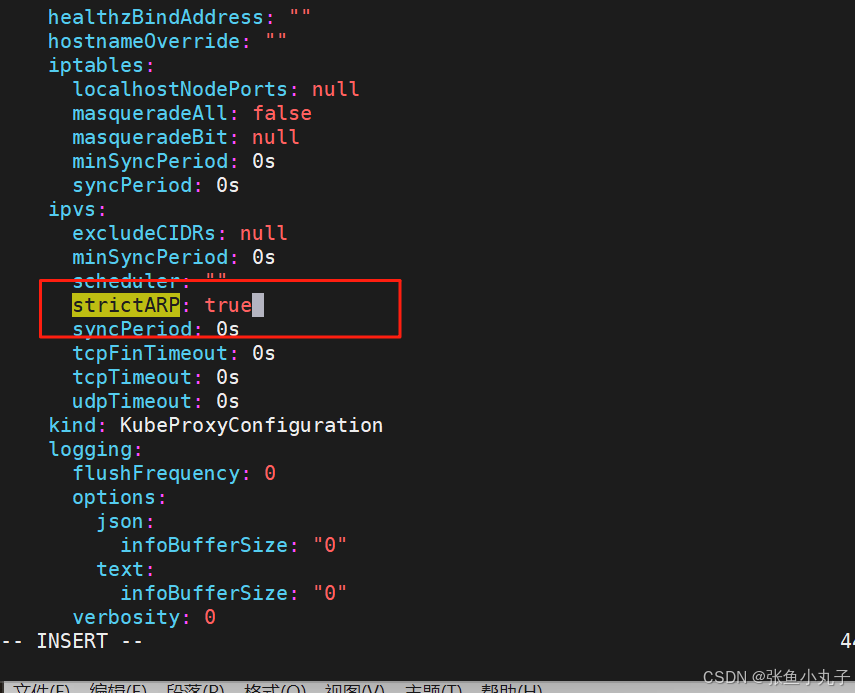

上传harbor仓库
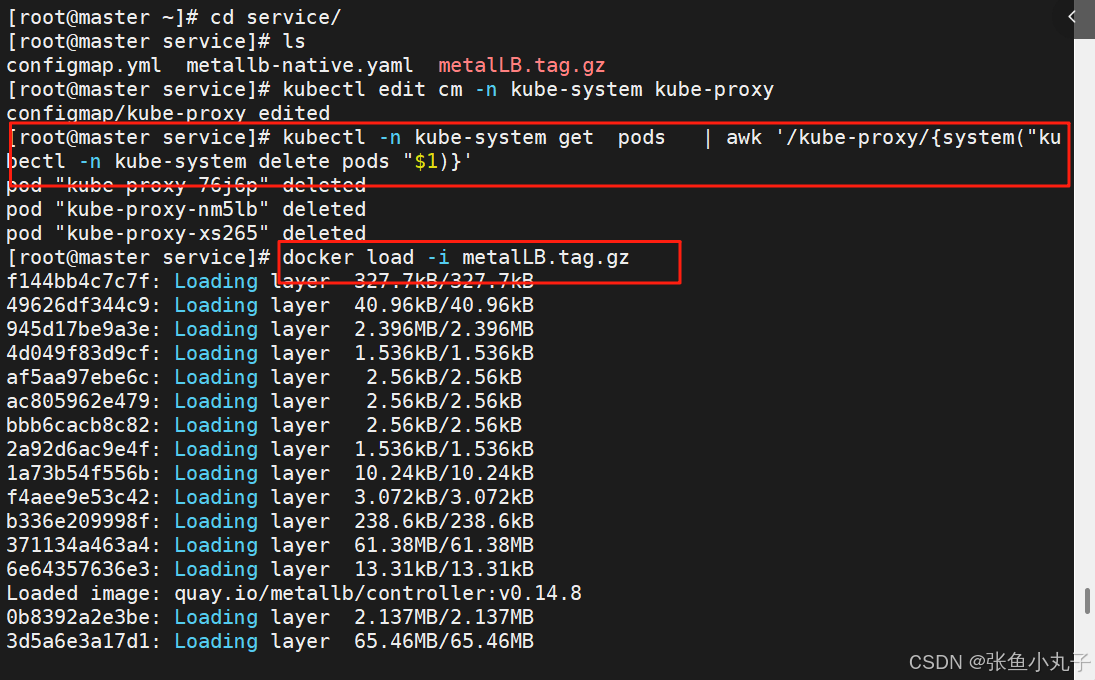
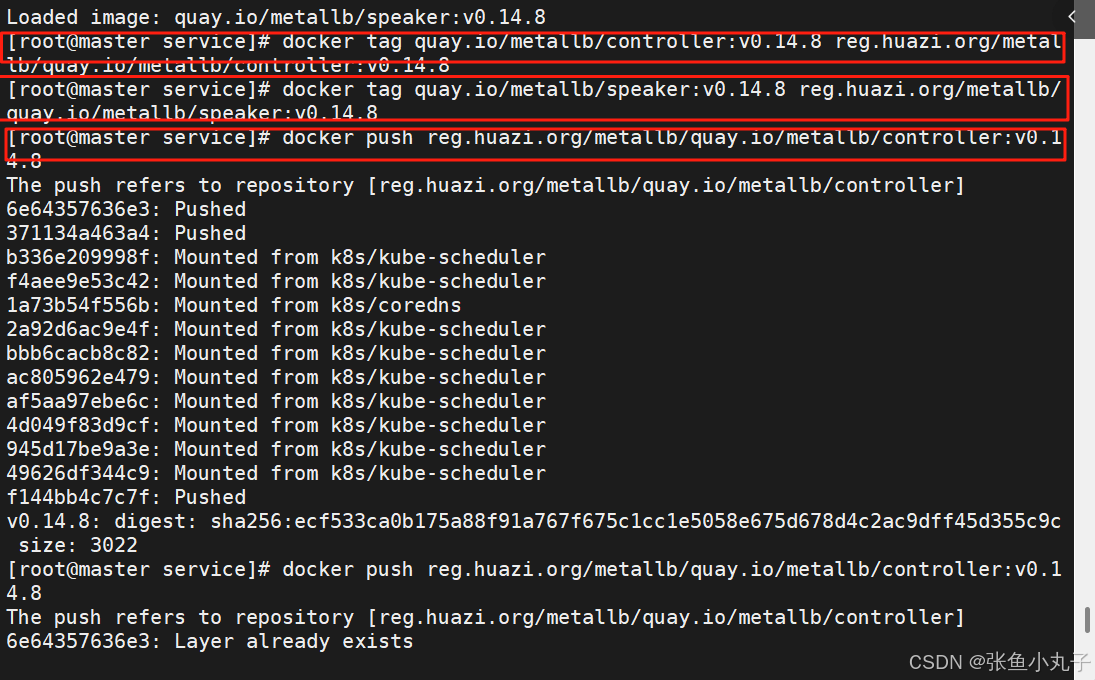
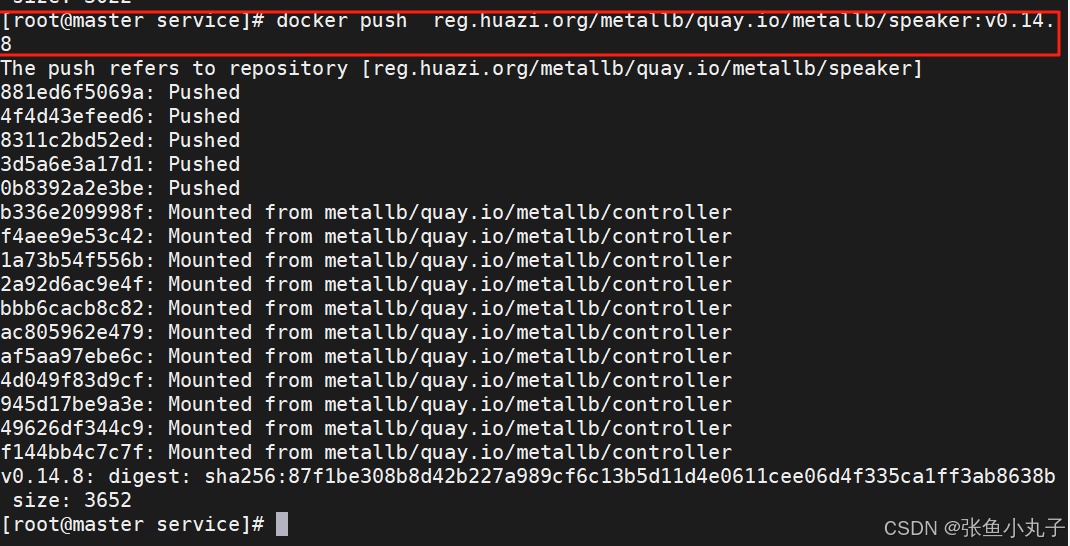
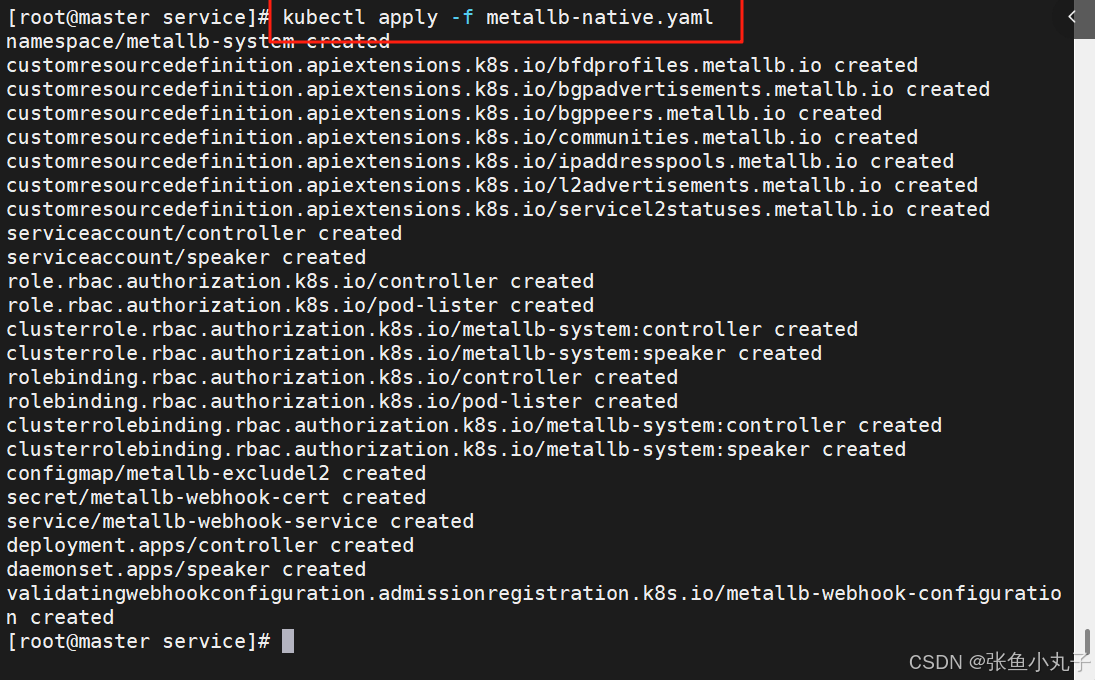
部署服务
配置分配地址段
[root@master service]# vim configmap.yml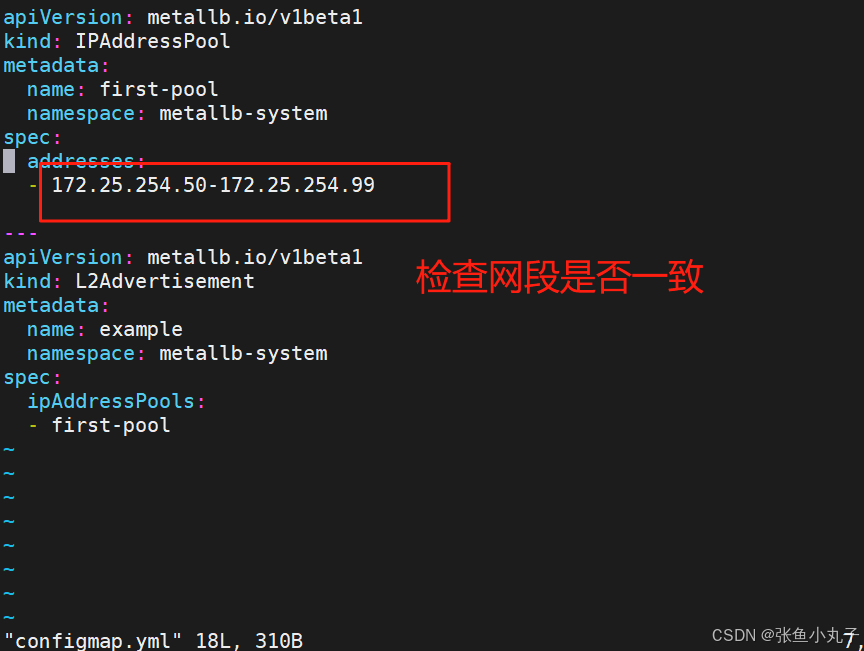
3.6 externalname
-
开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
-
一般应用于外部业务和pod沟通或外部业务迁移到pod内时
-
在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
-
集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
修改配置文件
[root@master ~]# vim huazi.yaml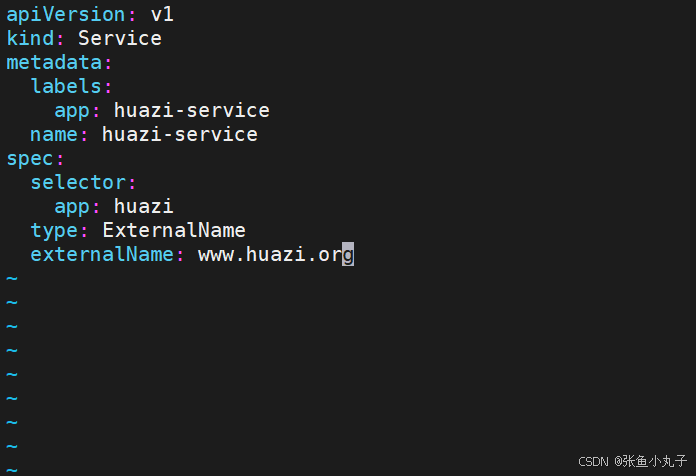
[root@master ~]# kubectl apply -f huazi.yaml
[root@master ~]# kubectl get services huazi-service4. 存储类storageclass
StorageClass说明
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到
StorageClass的属性
Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
储分配器NFS Client Provisioner
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
PV以 {namespace}-{pvcName}-${pvName}的命名格式提供(在NFS服务器上)
PV回收的时候以 archieved-{namespace}-{pvcName}-${pvName} 的命名格式(在NFS服务器上)
4.1 部署NFS Client Provisioner
上传nfs到harbor仓库中
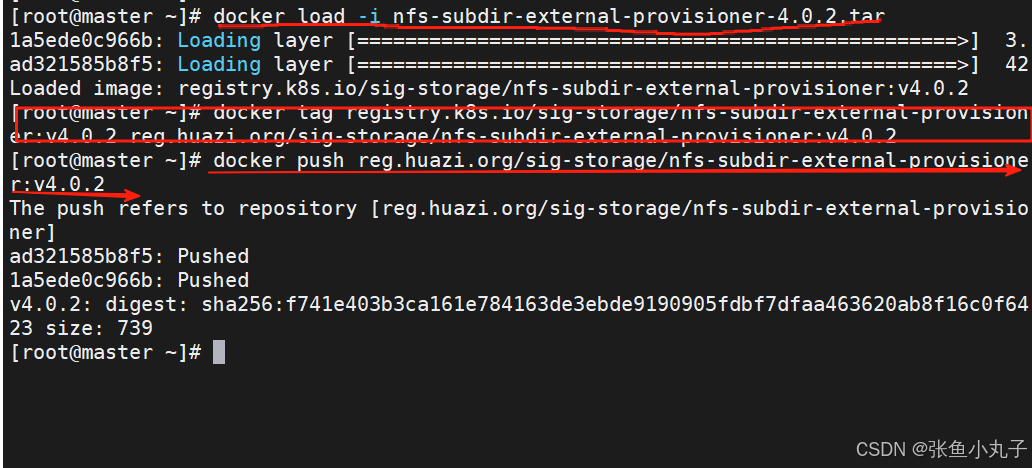
查看
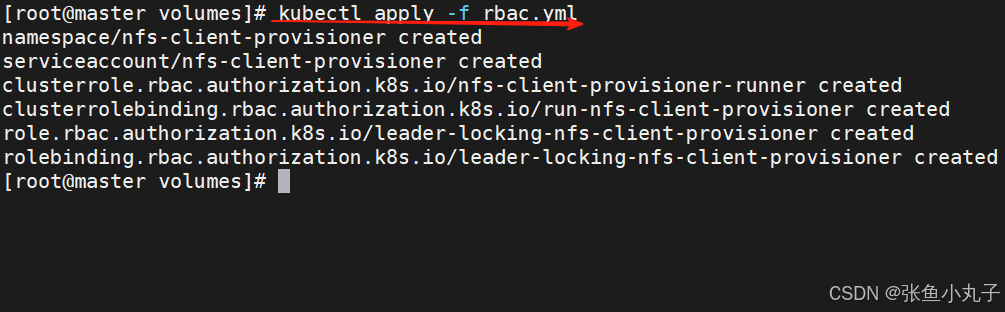
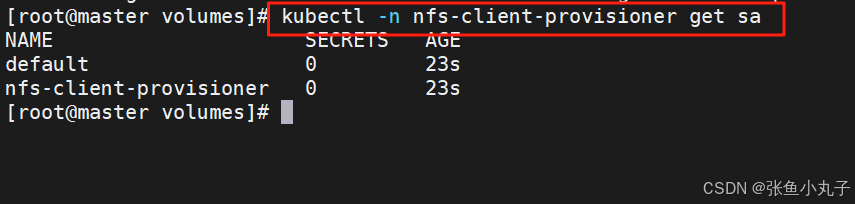
创建sa并授权
bash
[root@master volumes]# vim rbac.yml
apiVersion: v1
kind: Namespace
metadata:
name: nfs-client-provisioner
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
namespace: nfs-client-provisioner
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner
namespace: nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-client-provisioner
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io查看rbac信息
部署应用
bash
[root@master volumes]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
labels:
app: nfs-client-provisioner
namespace: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
spec:
serviceAccountName: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: sig-storage/nfs-subdir-external-provisioner:v4.0.2
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 172.25.254.250
- name: NFS_PATH
value: /nfsdata
volumes:
- name: nfs-client-root
nfs:
server: 172.25.254.250
path: /nfsdata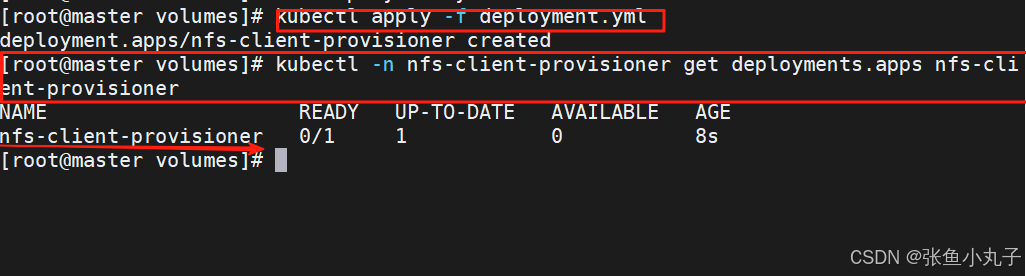
创建存储类
bash
[root@master volumes]# vim class.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-client
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
parameters:
archiveOnDelete: "false"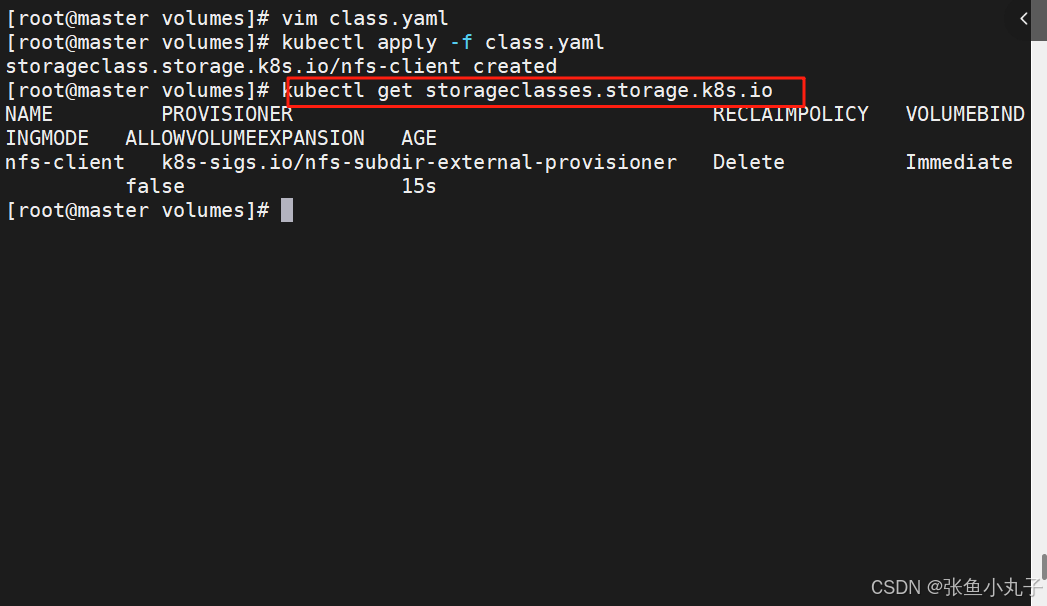
创建pvc
bash
[root@master volumes]# vim pvc.yml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: test-claim
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1G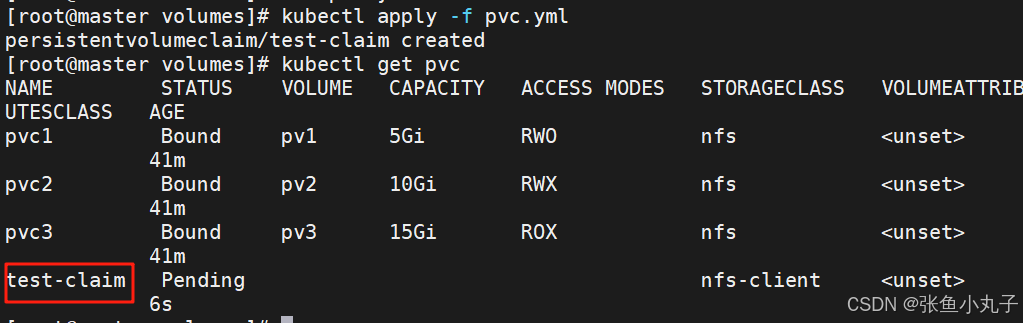
创建测试pod
bash
[root@master volumes]# vim pod.yml
kind: Pod
apiVersion: v1
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: busybox
command:
- "/bin/sh"
args:
- "-c"
- "touch /mnt/SUCCESS && exit 0 || exit 1"
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim4.2 设置默认存储类
-
在未设定默认存储类时pvc必须指定使用类的名称
-
在设定存储类后创建pvc时可以不用指定storageClassName
一次性指定多个pvc
bash
[root@master volumes]# vim pvc.yml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc1
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc2
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc3
spec:
storageClassName: nfs-client
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 15Gi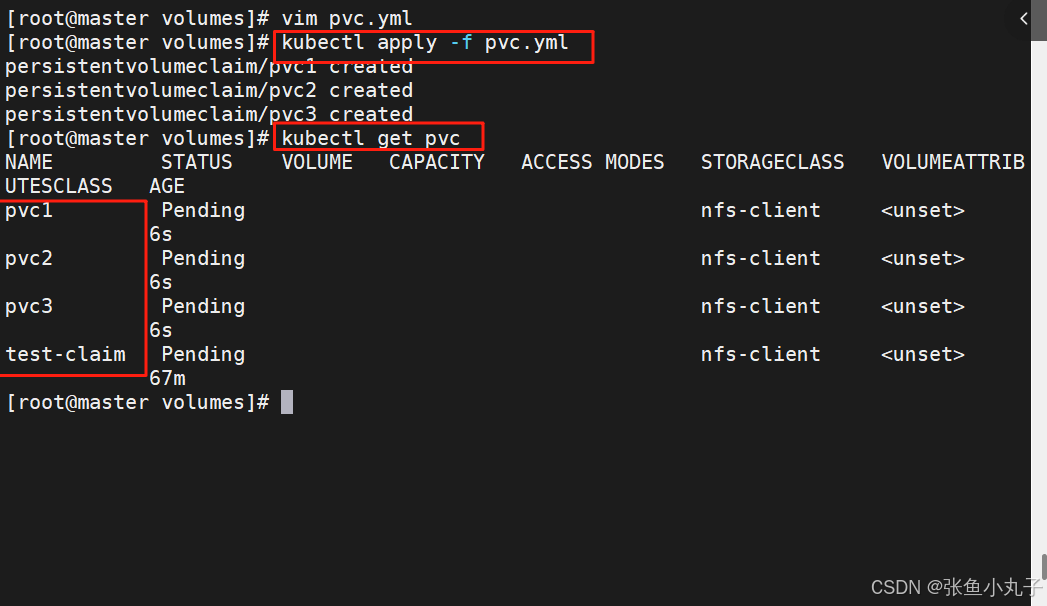
设定默认存储类
bash
[root@master volumes]# kubectl edit sc nfs-client
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"storage.k8s.io/v1","kind":"StorageClass","metadata":{"annotations":{},"name":"nfs-client"},"parameters":{"archiveOnDelete":"false"},"provisioner":"k8s-sigs.io/nfs-subdir-external-provisioner"}
storageclass.kubernetes.io/is-default-class: "true" #设定默认存储类
creationTimestamp: "2025-08-17T13:49:10Z"
name: nfs-client
resourceVersion: "218198"
uid: 9eb1e144-3051-4f16-bdec-30c472358028
parameters:
archiveOnDelete: "false"
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner
reclaimPolicy: Delete
volumeBindingMode: Immediate5. k8s网络通信
k8s通信整体架构
k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等
CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
插件使用的解决方案如下
虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。
多路复用:MacVLAN,多个容器共用一个物理网卡进行通信。
硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。
容器间通信:
同一个pod内的多个容器间的通信,通过lo即可实现pod之间的通信
同一节点的pod之间通过cni网桥转发数据包。
不同节点的pod之间的通信需要网络插件支持
pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换
pod和外网通信:iptables的MASQUERADE
Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
flannel网络插件
插件组成:
插件 功能 VXLAN 即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VXLAN可以完全在内核态实现封装和解封装工作,从而通过"隧道"机制,构建出覆盖网络(Overlay Network) VTEP VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因 Cni0 网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡) Flannel.1 TUN设备(虚拟网卡),用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端 Flanneld flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息
5.1 flannel跨主机通信原理
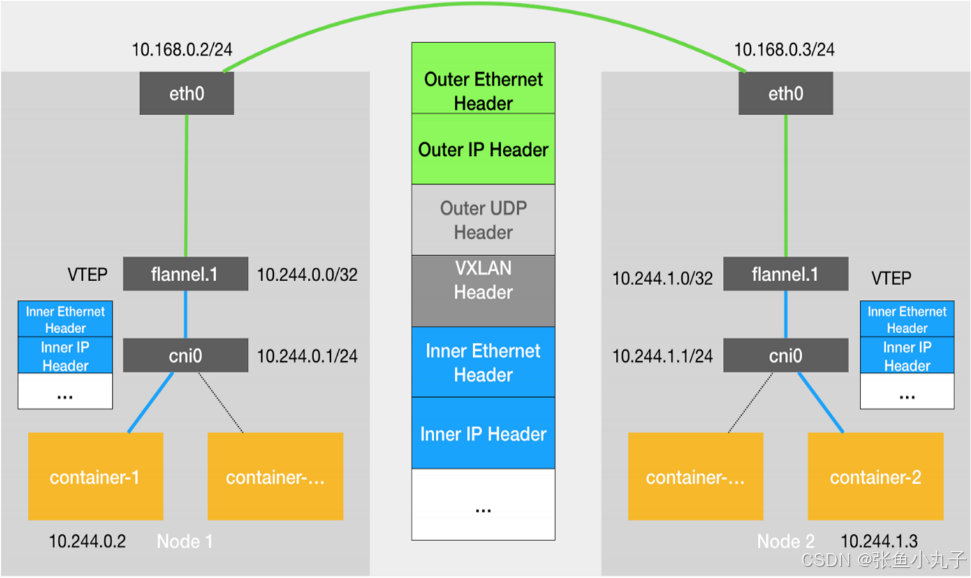
当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理。
VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识。
flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的。
linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取。
此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器。
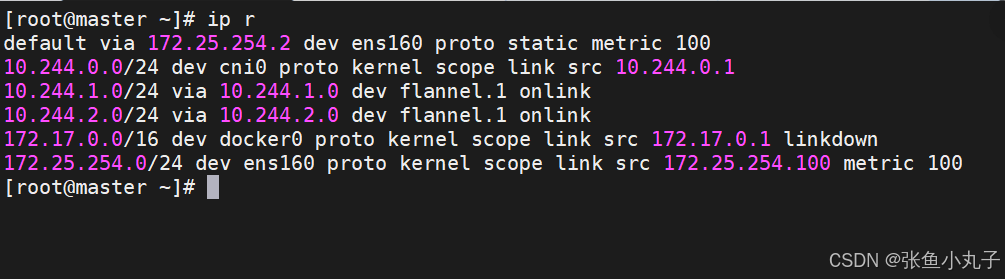
默认网络通信路由
桥接转发数据库
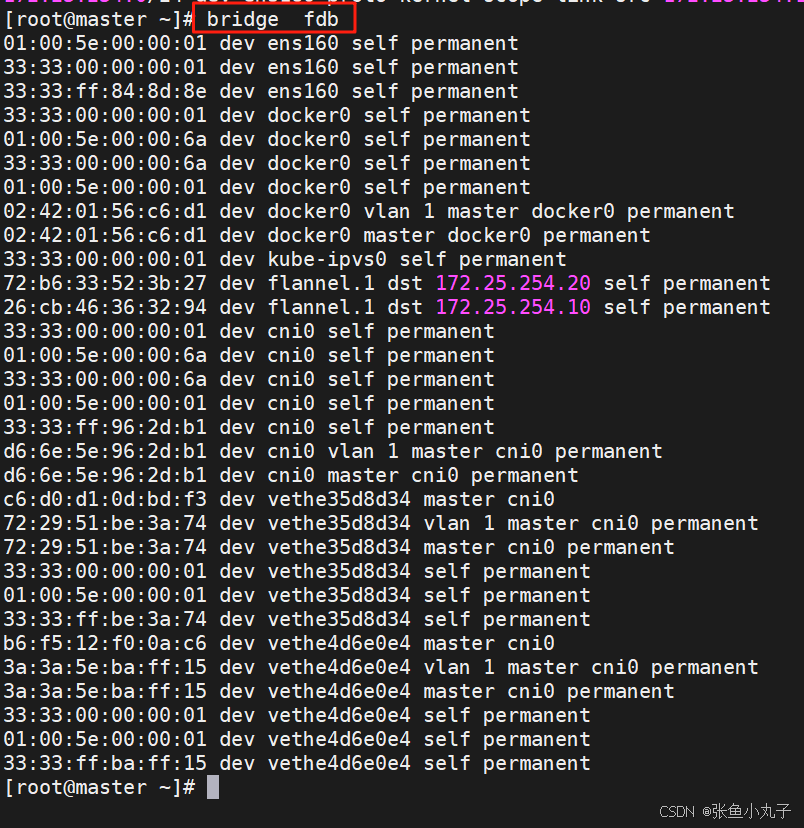
arp列表
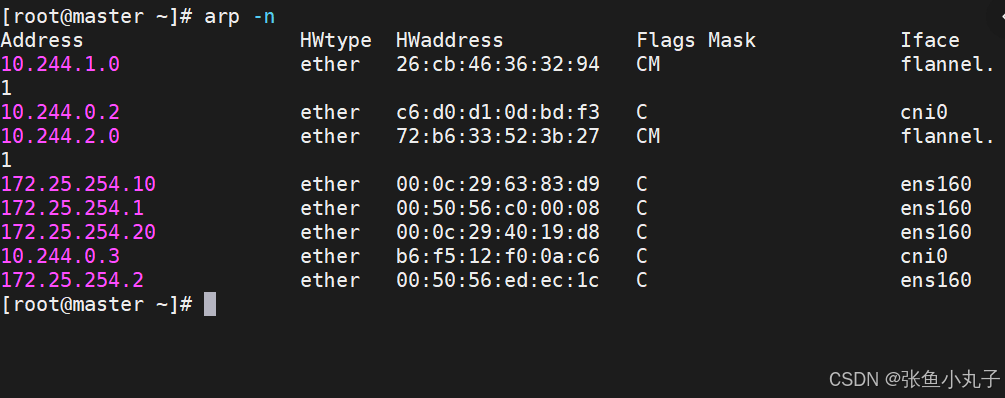
flannel支持的后端模式
网络模式 功能 vxlan 报文封装,默认模式 Directrouting 直接路由,跨网段使用vxlan,同网段使用host-gw模式 host-gw 主机网关,性能好,但只能在二层网络中,不支持跨网络 如果有成千上万的Pod,容易产生广播风暴,不推荐 UDP 性能差,不推荐
5.2 calico网络插件
calico简介:
纯三层的转发,中间没有任何的NAT和overlay,转发效率最好。
Calico 仅依赖三层路由可达。Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。
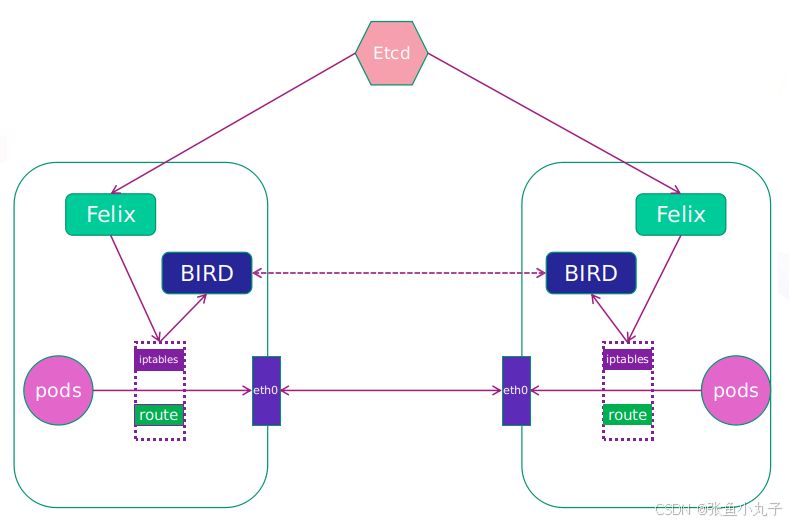
-
Felix:监听ECTD中心的存储获取事件,用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
-
BIRD:一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,路由的时候到这里
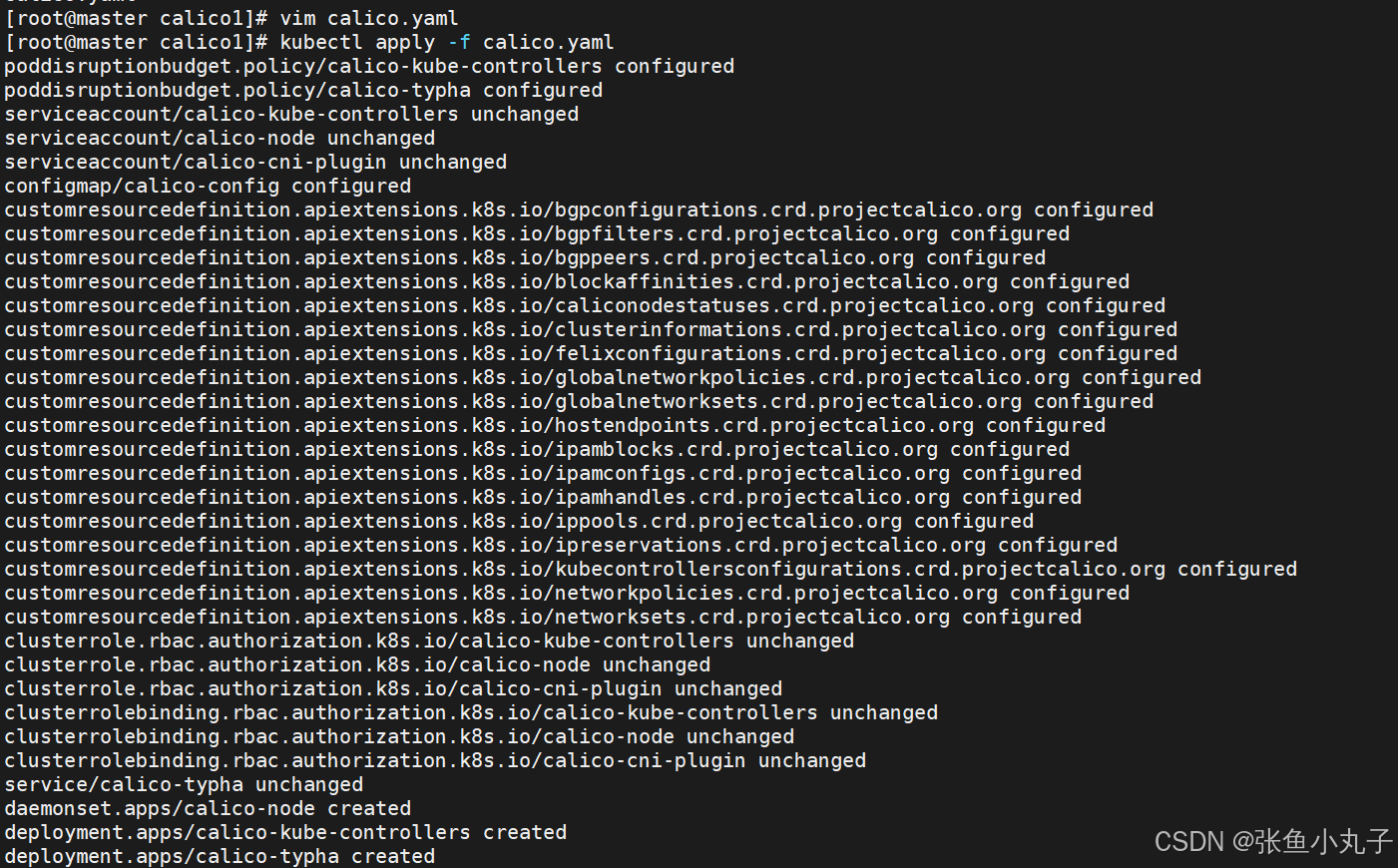
上传镜像至harbor仓库中
bash
[root@master ~]# docker load -i calico-3.28.1.tar
6b2e64a0b556: Loading layer 3.69MB/3.69MB
38ba74eb8103: Loading layer 205.4MB/205.4MB
5f70bf18a086: Loading layer 1.024kB/1.024kB
Loaded image: calico/cni:v3.28.1
3831744e3436: Loading layer 366.9MB/366.9MB
Loaded image: calico/node:v3.28.1
4f27db678727: Loading layer 75.59MB/75.59MB
Loaded image: calico/kube-controllers:v3.28.1
993f578a98d3: Loading layer 67.61MB/67.61MB
Loaded image: calico/typha:v3.28.1
[root@master ~]# docker tag calico/cni:v3.28.1 reg.huazi.org/calico/cni:v3.28.1
[root@master ~]# docker tag calico/node:v3.28.1 reg.huazi.org/calico/node:v3.28.1
[root@master ~]# docker tag calico/typha:v3.28.1 reg.huazi.org/calico/typha:v3.28.1
[root@master ~]# docker push reg.huazi.org/calico/cni:v3.28.1
The push refers to repository [reg.huazi.org/calico/cni]
5f70bf18a086: Mounted from library/busyboxplus
38ba74eb8103: Pushed
6b2e64a0b556: Pushed
v3.28.1: digest: sha256:4bf108485f738856b2a56dbcfb3848c8fb9161b97c967a7cd479a60855e13370 size: 946
[root@master ~]# docker push reg.huazi.org/calico/node:v3.28.1
The push refers to repository [reg.huazi.org/calico/node]
3831744e3436: Pushed
v3.28.1: digest: sha256:f72bd42a299e280eed13231cc499b2d9d228ca2f51f6fd599d2f4176049d7880 size: 530
[root@master ~]# docker push reg.huazi.org/calico/typha:v3.28.1
The push refers to repository [reg.huazi.org/calico/typha]
993f578a98d3: Pushed
6b2e64a0b556: Mounted from calico/cni
v3.28.1: digest: sha256:093ee2e785b54c2edb64dc68c6b2186ffa5c47aba32948a35ae88acb4f30108f size: 740查看
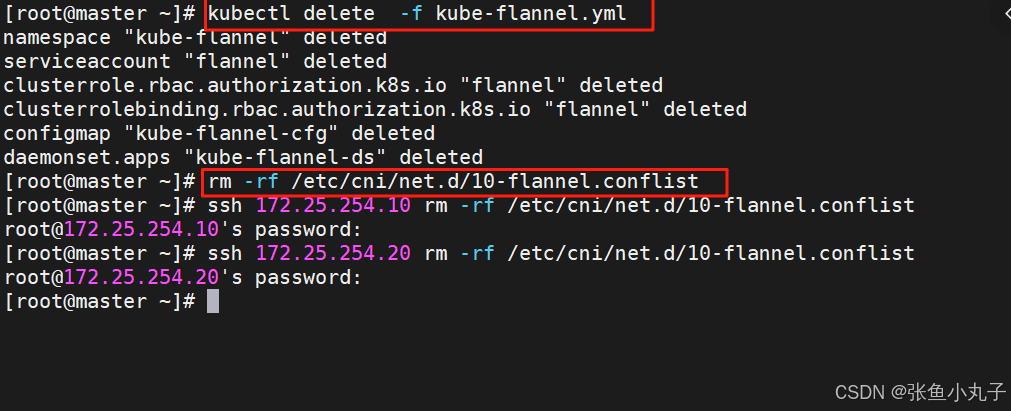
删除flannel插件,删除所有节点上flannel配置文件,避免冲突(node1和2都需)
更改yaml配置
4835 image: calico/cni:v3.28.1
4835 image: calico/cni:v3.28.1
4906 image: calico/node:v3.28.1
4932 image: calico/node:v3.28.1
5160 image: calico/kube-controllers:v3.28.1
5249 - image: calico/typha:v3.28.1
4970 - name: CALICO_IPV4POOL_IPIP
4971 value: "Never"
4999 - name: CALICO_IPV4POOL_CIDR
5000 value: "10.244.0.0/16"
5001 - name: CALICO_AUTODETECTION_METHOD
5002 value: "interface=eth0"
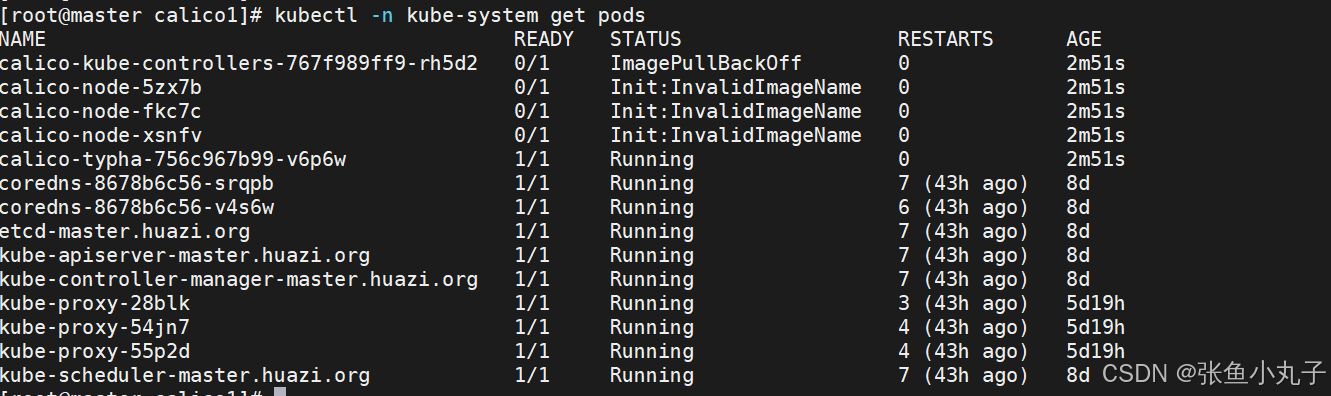
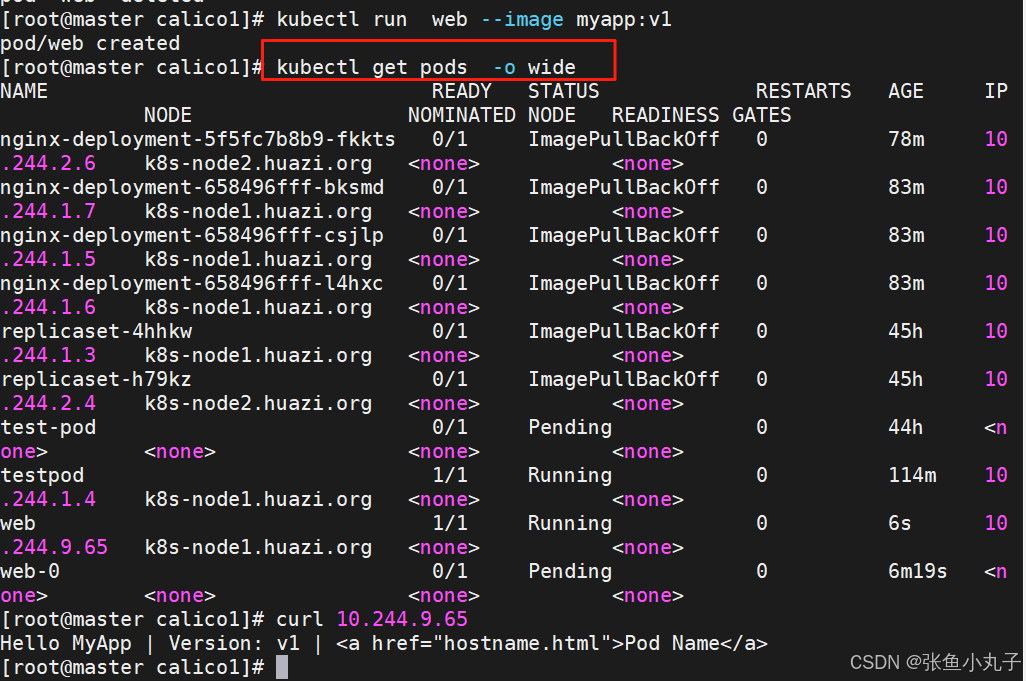
创建节点并查看
6. k8s调度(Scheduling)
调度在Kubernetes中的作用
调度是指将未调度的Pod自动分配到集群中的节点的过程
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
调度原理:
创建Pod
- 用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息。
调度器监视Pod
- Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点。
选择节点
- 调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等。
绑定Pod到节点
- 调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息。
节点启动Pod
- 节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行。
调度器种类
默认调度器(Default Scheduler):
- 是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上。
自定义调度器(Custom Scheduler):
- 是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能。
扩展调度器(Extended Scheduler):
- 是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能。
kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
6.1 常用调度方法-nodename
-
nodeName 是节点选择约束的最简单方法,但一般不推荐
-
如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
-
使用 nodeName 来选择节点的一些限制
-
如果指定的节点不存在。
-
如果指定的节点没有资源来容纳 pod,则pod 调度失败。
-
云环境中的节点名称并非总是可预测或稳定的
-
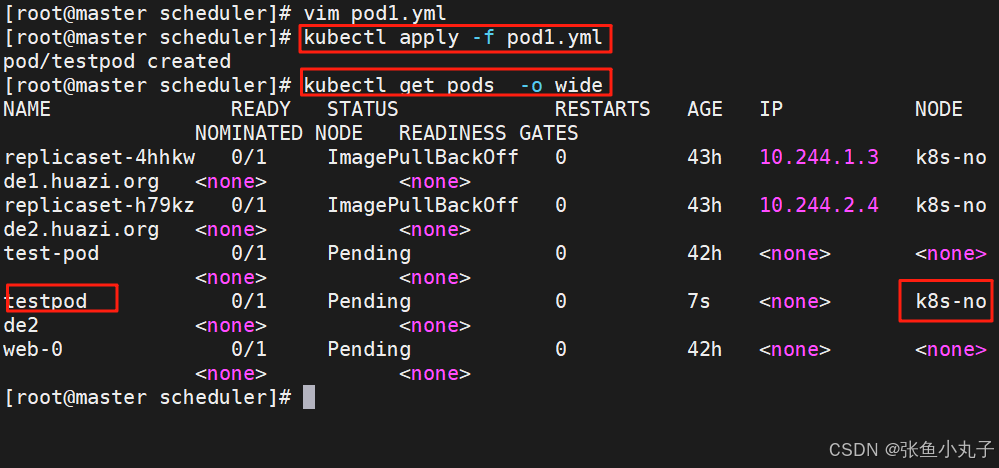
建立pod文件
root@master scheduler# kubectl run testpod --image myapp:v1 --dry-run=client -o yaml > pod1.yml
设置调度
bash
[root@master scheduler]# vim pod1.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeName: k8s-node2
containers:
- image: myapp:v1
name: testpod建立pod
6.2 Nodeselector(通过标签控制节点)
-
nodeSelector 是节点选择约束的最简单推荐形式
-
给选择的节点添加标签:
kubectl label nodes k8s-node1 lab=lee -
可以给多个节点设定相同标签
查看节点标签
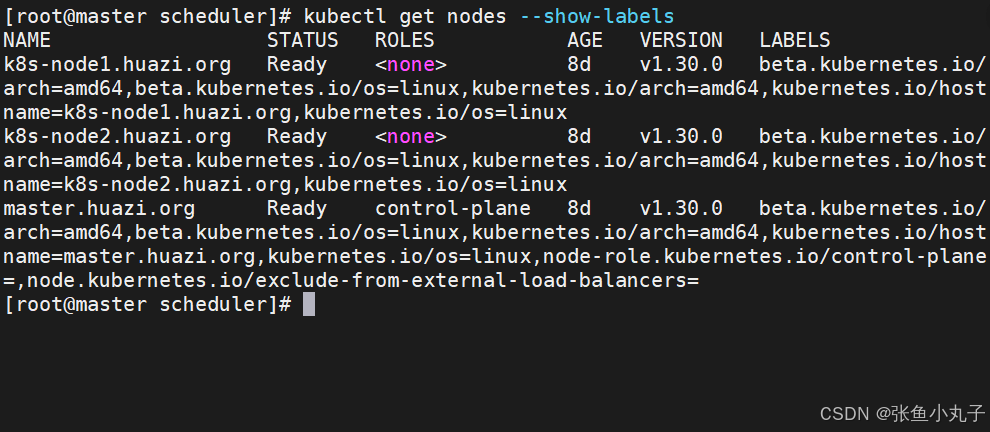
设置节点标签


设置调度
bash
[root@master scheduler]# vim pod2.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
nodeSelector:
lab: huazi
containers:
- image: myapp:v1
name: testpod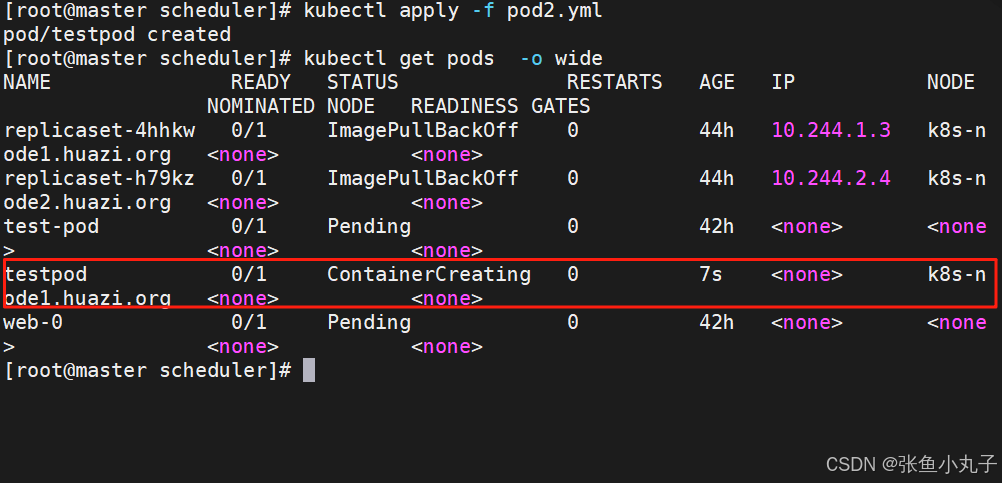
6.3 affinity(亲和性)
官方文档 :
亲和与反亲和
nodeSelector 提供了一种非常简单的方法来将 pod 约束到具有特定标签的节点上。亲和/反亲和功能极大地扩展了你可以表达约束的类型。
使用节点上的 pod 的标签来约束,而不是使用节点本身的标签,来允许哪些 pod 可以或者不可以被放置在一起。
nodeAffinity节点亲和
那个节点服务指定条件就在那个节点运行
requiredDuringSchedulingIgnoredDuringExecution 必须满足,但不会影响已经调度
preferredDuringSchedulingIgnoredDuringExecution 倾向满足,在无法满足情况下也会调度pod
- IgnoreDuringExecution 表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
nodeaffinity还支持多种规则匹配条件的配置如
匹配规则 功能 ln label 的值在列表内 Notln label 的值不在列表内 Gt label 的值大于设置的值,不支持Pod亲和性 Lt label 的值小于设置的值,不支持pod亲和性 Exists 设置的label 存在 DoesNotExist 设置的 label 不存在
编辑配置文件
bash
[root@master scheduler]# vim pod3.yml
apiVersion: v1
kind: Pod
metadata:
name: node-affinity
spec:
containers:
- name: nginx
image: nginx
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disk
operator: In | NotIn
values:
- ssdPodaffinity(pod的亲和)
那个节点有符合条件的POD就在那个节点运行
podAffinity 主要解决POD可以和哪些POD部署在同一个节点中的问题
podAntiAffinity主要解决POD不能和哪些POD部署在同一个节点中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,
Pod 间亲和与反亲和需要大量的处理,这可能会显著减慢大规模集群中的调度。
bash
[root@master scheduler]# vim exampl4.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"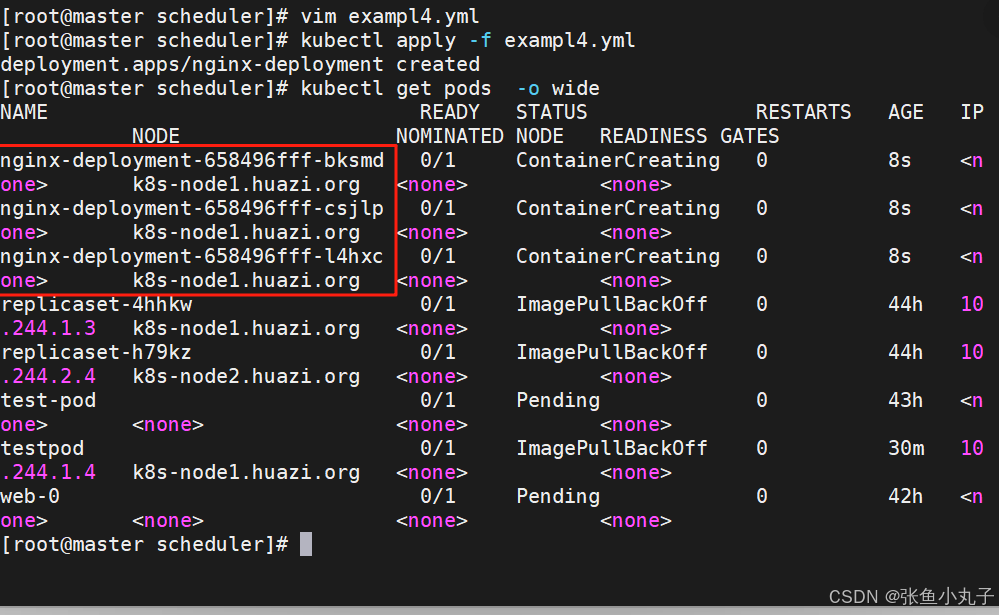
反亲和,先编辑配置文件
bash
[root@master scheduler]# vim exampl5.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
affinity:
podAntiAffinity: #反亲和
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: "kubernetes.io/hostname"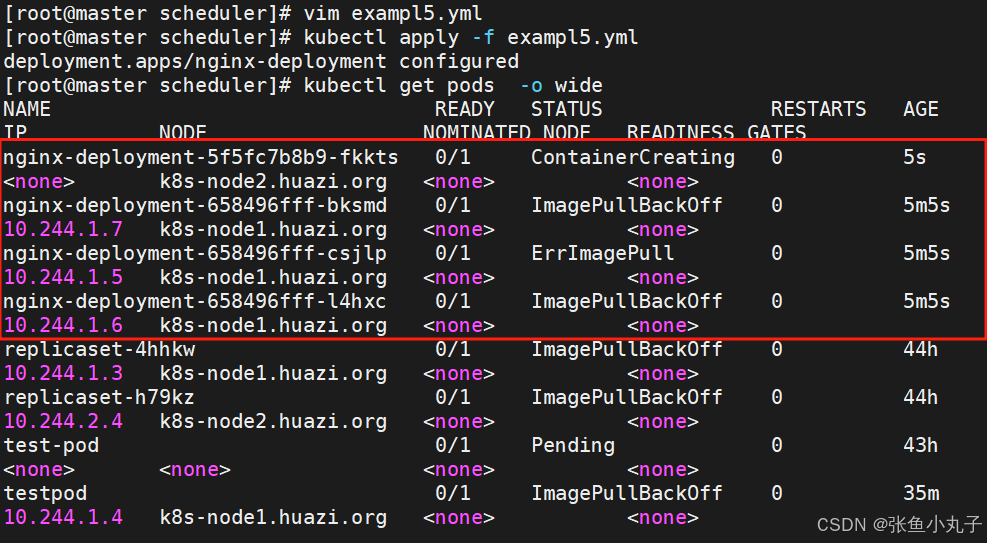
6.4 Taints(污点模式,禁止调度)
-
aints(污点)是Node的一个属性,设置了Taints后,默认Kubernetes是不会将Pod调度到这个Node上
-
Kubernetes如果为Pod设置Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去
-
可以使用命令 kubectl taint 给节点增加一个 taint:
$ kubectl taint nodes <nodename> key=string:effect #命令执行方法
$ kubectl taint nodes node1 key=value:NoSchedule #创建
$ kubectl describe nodes server1 | grep Taints #查询
$ kubectl taint nodes node1 key- #删除其中effect 可取值:
| effect值 | 解释 |
|---|---|
| NoSchedule | POD 不会被调度到标记为 taints 节点 |
| PreferNoSchedule | NoSchedule 的软策略版本,尽量不调度到此节点 |
| NoExecute | 如该节点内正在运行的 POD 没有对应 Tolerate 设置,会直接被逐出 |
建立控制器并运行
bash
[root@master scheduler]# vim example6.yml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 2
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
设定污点为NoSchedule
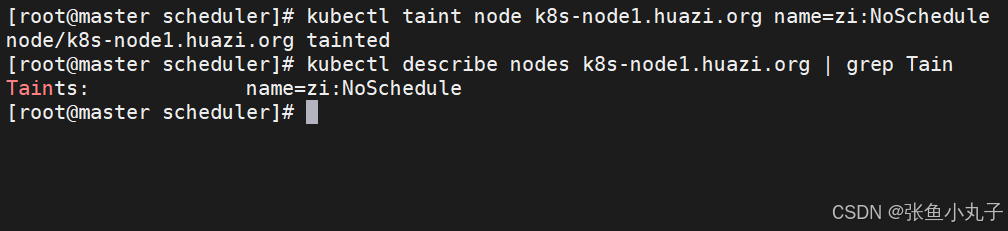
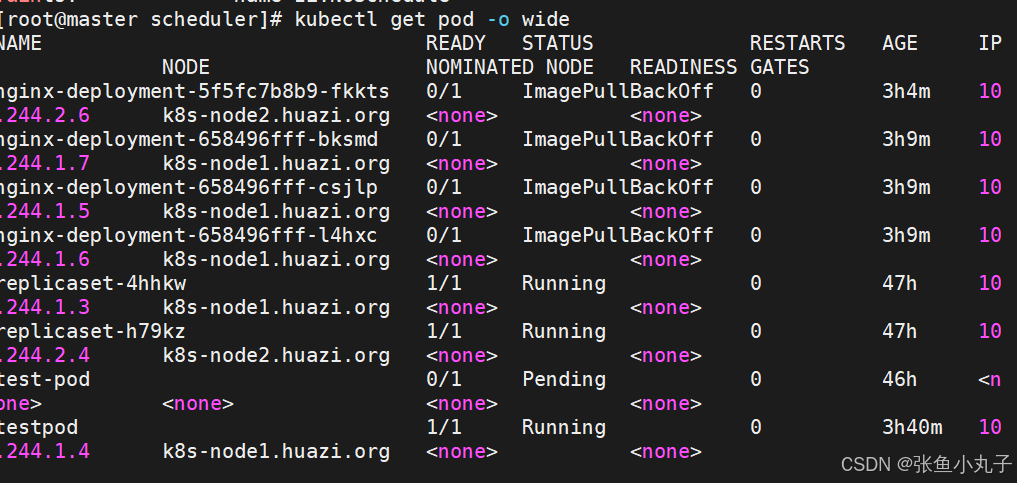
控制器增加pod
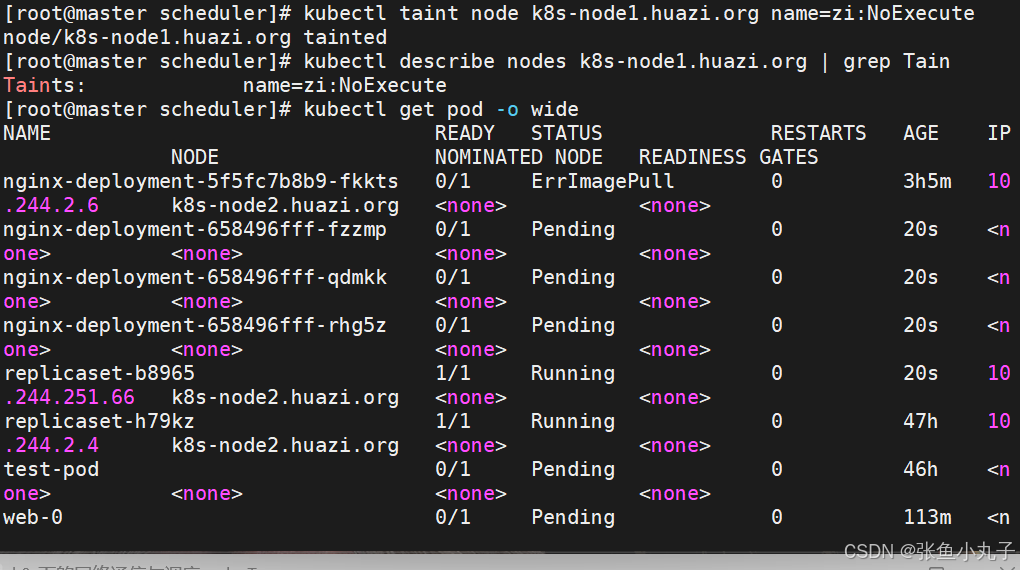
设定污点为NoExecute
删除污点

tolerations(污点容忍)
-
tolerations中定义的key、value、effect,要与node上设置的taint保持一直:
-
如果 operator 是 Equal ,则key与value之间的关系必须相等。
-
如果 operator 是 Exists ,value可以省略
-
如果不指定operator属性,则默认值为Equal。
-
-
还有两个特殊值:
-
当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点。
-
当不指定effect ,则匹配所有的effect
-