人人都能理解的"语言密码"
在社交媒体刷屏的评论区里,人工智能如何瞬间识别出愤怒的吐槽与真诚的赞美?购物平台为何能自动将"质量太差"归类为差评,把"物超所值"标记为好评?这背后正是自然语言处理(NLP)技术在发挥作用。本文中,我们将以情感分析为切入点,用举例和比喻的方式方法,带您亲历一个NLP项目的完整生命周期。你无需专业背景,只需跟着操作步骤,即可亲手打造出能理解人类情感的智能程序。
情感分析的原理
情感分析,顾名思义,就是让计算机判断一段文本是正面的 (积极的情绪,比如"很好""超值")还是负面的(消极的情绪,比如"太差了""后悔")。要做到这一点,计算机需要完成以下几个步骤:
-
数据收集:收集包含情感标签的文本数据,比如电商评论、社交媒体评论等。
-
文本预处理:去掉无关字符,进行分词,去除停用词等,使文本变得更"干净"。
-
特征提取 :将文本转换成计算机可理解的数值格式,比如使用
TF-IDF统计每个词的重要性。 -
模型训练:选择合适的机器学习模型(如SVM支持向量机),让模型学习哪些词与"正面"或"负面"相关。
-
模型评估:用测试数据检查模型的准确性,并进行优化调整。
-
情感预测:给新文本打上情感标签,判断其是正面还是负面。
接下来,我们就按照这个流程,一步步构建一个中文情感分析系统。
准备工作:安装必要的库
在开始编写代码前,我们需要安装一些必要的 Python 库。这些库可以帮助我们进行分词、特征提取和机器学习建模。在 JupyterLab 中运行以下代码安装所需库:
pip install jieba scikit-learn wordcloud matplotlib其中,jieba 负责中文分词,scikit-learn 用于机器学习建模,wordcloud 用于生成词云,matplotlib 用于数据可视化。

数据准备
为了演示,我们创建一个简单的电商评论数据集,每条评论都带有情感标签(1表示正面,0表示负面):
-
data是一个字典,包含用户评论text和情感标签sentiment。 -
pd.DataFrame(data)将数据转换为pandas的DataFrame,方便后续操作。=== 导入库 ===
import re
import jieba
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer=== 自定义中文停用词表 ===
stopwords = set("""
的 了 是 就 和 在 有 我 这 个 也 不 都 要 还 又 很 让 之 与 等 而
啊 呀 呢 吧 哦 哇 嘛 嗯 唉 啦 哟 么 哪 么 什么 怎么 为什么
""".split())=== 数据集(模拟电商评论) ===
data = {
"text": [
"手机颜值超高,运行速度特别快,拍照效果惊艳!",
"物流慢得离谱,等了一个月才到货",
"性价比一般,电池续航没有宣传的那么好",
"客服小姐姐态度超好,问题解决得非常快",
"商品有严重质量问题,完全不能用",
"这个价格能买到这样的品质真的很划算",
"包装破损严重,明显是二手商品",
"操作界面非常人性化,老人也能轻松使用",
"广告宣传和实物差距太大,感觉被欺骗",
"系统流畅不卡顿,游戏体验特别棒"
],
"sentiment": [1,0,0,1,0,1,0,1,0,1] # 1=正面 0=负面
}
df = pd.DataFrame(data)
文本预处理
计算机无法直接理解汉字,所以我们需要进行文本预处理,包括:
-
正则清洗:移除URL、标点等干扰符号
-
分词处理:将连续文本转化为词语序列
-
停用词过滤:去除"的"、"了"等无意义词汇
-
长度筛选:保留具有实际含义的词汇
我们可以使用 jieba 进行分词,并定义一个停用词表:
# === 中文预处理函数 ===
def chinese_text_processing(text):
# 清洗特殊字符
text = re.sub(r'[^\u4e00-\u9fa5]', '', text)
# 精确模式分词
words = jieba.lcut(text)
# 过滤停用词和单字
words = [word for word in words if len(word)>1 and word not in stopwords]
return ' '.join(words)
# 应用预处理
df['processed'] = df['text'].apply(chinese_text_processing)-
re.sub(r'[^\u4e00-\u9fa5]', '', text)只保留中文字符。 -
jieba.lcut(text)进行中文分词,将句子转换成词列表。 -
stopwords是停用词集合,去掉无意义的高频词。 -
df['processed'] = df['text'].apply(chinese_text_processing)将预处理函数应用到text列。
经过处理,"手机颜值超高,运行速度特别快,拍照效果惊艳!" 可能会变成 "手机 颜值 超高 运行 速度 特别快 拍照 效果 惊艳"。
可视化数据
在训练模型前,我们可以先用 词云 来看看用户评论中最常见的词汇。
# === 生成词云 ===
plt.figure(figsize=(10,6))
wordcloud = WordCloud(
font_path='simhei.ttf', # 需要中文字体文件
width=800,
height=600,
background_color='white'
).generate(' '.join(df['processed']))
plt.imshow(wordcloud)
plt.title("用户评论关键词云")
plt.axis("off")
plt.show()构建机器学习模型( 特征工程**)**
我们使用 TF-IDF 提取文本特征,并用 支持向量机(SVM) 进行分类:
-
TfidfVectorizer:用 TF-IDF 方法提取文本特征,ngram_range=(1,2) 表示同时考虑单个词和两个词的组合。
-
SVC(kernel='linear'):使用支持向量机(SVM)进行分类,linear 表示使用线性核。
-
train_test_split(df'processed', df'sentiment', test_size=0.3):将数据分成 70% 训练集,30% 测试集。
=== 构建机器学习流水线 ===
pipeline = Pipeline([
('tfidf', TfidfVectorizer(
ngram_range=(1,2), # 包含1-2个词的组合
max_features=500)), # 保留最重要的500个特征
('clf', SVC(kernel='linear', probability=True)) # 使用支持向量机
])=== 数据集划分 ===
X_train, X_test, y_train, y_test = train_test_split(
df['processed'],
df['sentiment'],
test_size=0.3,
stratify=df['sentiment'], # 保持类别分布
random_state=42
)训练模型
pipeline.fit(X_train, y_train)
模型评估
训练完成后,我们使用测试集评估模型的效果。classification_report(y_test, y_pred) 计算模型的 准确率、召回率 和 F1-score,检查模型表现。
# === 模型评估 ===
print("\n=== 模型评估报告 ===\n")
y_pred = pipeline.predict(X_test)
print(classification_report(y_test, y_pred, target_names=['负面', '正面']))如果 准确率 和 F1-score 够高,说明模型效果不错。

情感预测
我们可以用训练好的模型来预测新评论的情感。predict_proba 返回分类概率,取最大值作为置信度。
# === 预测函数 ===
def predict_sentiment(text):
processed_text = chinese_text_processing(text)
prediction = pipeline.predict([processed_text])[0]
proba = pipeline.predict_proba([processed_text])[0]
result = {
'text': text,
'sentiment': '正面' if prediction == 1 else '负面',
'confidence': f"{max(proba)*100:.1f}%"
}
return result
# === 测试用例 ===
test_cases = [
"这次购物体验真是糟糕透顶!",
"物超所值,绝对五星好评!",
"中规中矩,没什么特别的感觉",
"这手机烫得可以煎鸡蛋了",
"操作流畅得让人感动"
]
print("\n=== 预测测试 ===")
for case in test_cases:
res = predict_sentiment(case)
print(f"「{res['text']}」 → {res['sentiment']}(置信度:{res['confidence']})")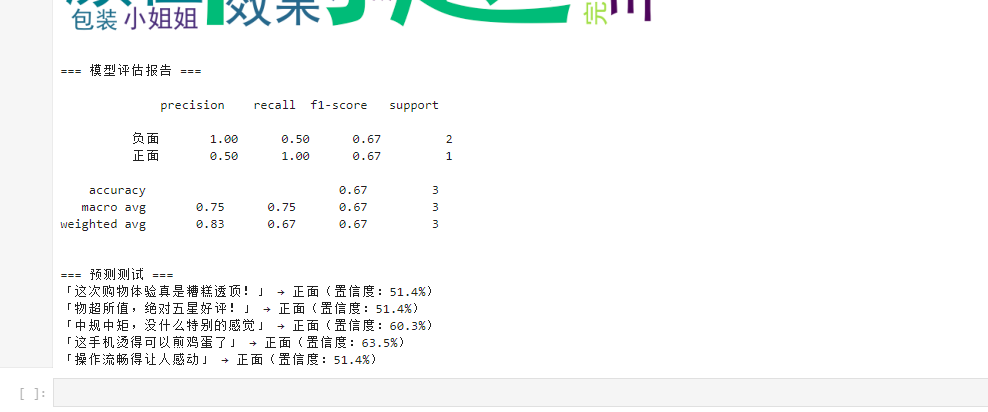
总结
通过这篇教程,我们实现了一个完整的中文情感分析系统 ,包括 文本预处理、特征提取、模型训练和预测 。从预测结果来看,返回的结果并不理想,在未来我们可以尝试更大的数据集,或使用 深度学习(如BERT) 提升准确率。