书接上回,上一篇文章主要介绍了分层自动化测试自动化框架及其设计搭建浅谈(二)--分层自动化测试-CSDN博客
本篇问文章主要在设计自动化测试框架过程中的最佳实践,可以理解为一些常用的设计方法论。
目录
一、总体建议
设计自动化框架总的原则就是功能尽量模块化,可扦插 ;测试数据和测试用例应该跟业务逻辑隔离,独立维护 ;框架还要有一定的容错能力,保证运行稳定。无论是哪一种类型的自动化框架(接口、UI、客户端、性能等),基本都要满足以上的设计原则。
二、框架设计的最佳实践
1.PageObject模型
PageObject模型又叫PO模型,主要应用于UI自动化中的一个常用实践,主要特点如下
(1)将每个页面(或者待测试对象)封装成一个类,类中包括这个页面上的所有元素以及操作方法,这些操作方法可以单步的,也可是功能集合
(2)将测试代码和页面(元素和操作方法)隔离,减少代码耦合。
2.数据驱动
自动化过程中出现的数据主要分为++请求数据,期望数据,测试结果++数据三种。
- 请求数据包括调用开发接口的入参和前置准备数据
- 期望数据就是对接口返回结果的预期值
- 测试结果数据包括接口返回的实际结果即将跟期望数据进行对比的数据,和断言结果的聚合报告。
2.1数据准备
上面提到了自动化过程产生的数据,这些数据有多种构造方式,可以独立使用,也可以根据不同的场景混合使用。
(1)根据业务规则手工造数据
假设接口自动化测试过程中,调用接口需要要一个动态随机参数(比如ID),这就说明该参数每次调用接口产生的都不一样,
如果是传入参数且是必传的(1)根据开发生成该参数的规则自主实现一个构造数据的脚本(2)开发提供构造数据的脚本。
如果是接口返回数据(1)模糊断言数值范围,数值等
(2)使用第三方库生成
为了模拟用户的操作,使用第三方库生成,例如Python的第三方库Faker,可以生成更接近正常用户使用的数据,并且每次生成的数据都是动态的,不过仅适用于入参数据,对于前置数据不适用。
(3)通过数据库查询得出
这是比较常用的一种构造数据的方式,比较适用于调用接口前的前置数据准备,或者接口入参数据来自不同的系统的情况,通过编写SQL得到数据,需要注意SQL编写规范,否则会有查询效率问题
(4)数据构造平台
测试团队有专门的测试数据构造平台,调用时不需要关系数据是如何构造的,直接使用就可以
(5)从生产环境复制
从生产环境复制主要的使用场景是性能测试,需要利用流量录制回放工具并且将生产数据脱敏处理
2.2测试数据可能出现的问题
(1)测试数据过期
出现场景:在测试之前已准备的数据,例如优惠券,
解决办法:测试用定期维护
(2)多次运行导致结果不同
出现场景:第一次运行正常运行通过测试,第二次测试没有用过测试。通常是写库的时候更改了数据,导致第二次读取到的数据 不一致
解决办法:在写数据库的操作后,进行数据清理
(3)环境切换导致测试数据不同
出现场景:切换不同环境时,运行结果不一致
解决办法:框架支持多环境切换,每套环境使用独立的数据源
(4)测试数据在运行中被更改
出现场景:在测试运行中存在写操作,导致查询到的数据不一致,导致运行结果不一致
解决办法:修改测试数据的生成条件,把查询语句写的健壮
(5)并发运行导致测试数据不可用
出现场景:并发运行测试用例,多个人共同操作同一组数据,导致用例执行失败
解决办法:框架支持并发运行,一个类下面的测试用例顺序执行的方式来避免同意测试类下的测试用同时访问同一个测试数据
2.3数据驱动流程
数据驱动流程图如下:
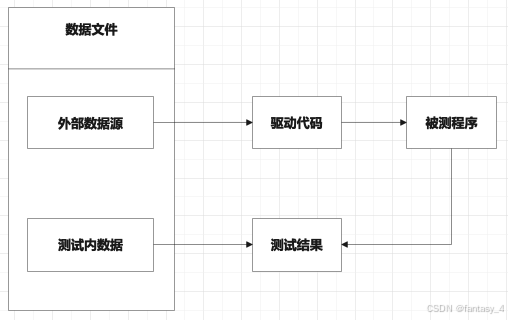
从上图可知,数据驱动流程左边是数据文件,分为外部数据源和测试内数据,在实践中这两者可以是分开设置,也可都来自外部数据源,一般是Excel文件,Yaml文件,JSON文件,数据库表等。++数据驱动比较适用于单一场景功能的详细测试++。
2.4数据驱动实践
(1)文件读写
最常见的外部数据源文件Excel文件,Yaml文件,JSON文件,
驱动代码就是读写文件的方法或者类,被测试程序调用该方法或者类,得到对应的数据源
Excel文件和YAML文件都是可以实现将外部数据源和测试内数据统一设置到同一文件的,而不是分开设置
- Excel文件文件标题栏设计
接口根据学号,姓名和年龄查找,该学生是否存在
| caseID | caseName | ProjectID | inputStr | assertStr |
|---|---|---|---|---|
| 1 | 测试XXX | 模块名字 | {"id":12345,name":"张三","age":20} | {"isExit":True} |
可以将Excel的标题列作为读取数据的关键字标识
每一行作为测试数据
每一个Sheet作为不同的测试场景,或者不同测试接口
- YAML文件设计
bash
caseID:12345
caseName:"测试XX功能"
ProjectID:"测试模块"
inputStr:{"id":12345,name":"张三","age":20}
assertStr:{"isExit":True}(2)数据库表读写
外部数据源来自于数据库表
驱动代码就是操作数据SQL的封装方法或者类,得到对应的数据源
数据库表只能提供外部数据源,而测试内数据只能在测试中硬编码设定
3.关键字驱动
关键字驱动是将多场景执行流程使用关键的方式实现,将功能场景的运行流程可配置化,++因此关键字驱动更适合测试多功能多场景测试++,例如:主流程测试,或者冒烟测试,关键驱动流程图如下
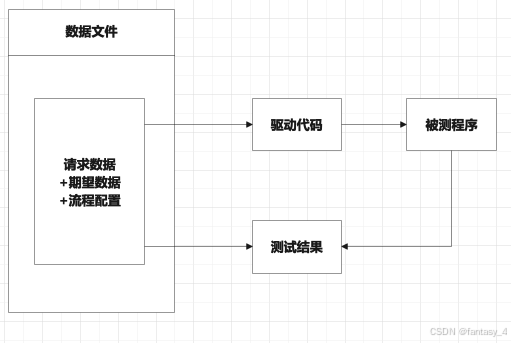
3.1关键字驱动实践
关键字驱动的数据来源主要是文件读写。
(1)Excel文件
Excel 文件设计场景如下,每行表示不同的场景,为了将不同场景串联起来,sheet表示某一场景功能的详细测试,其他的标题列可以任意发挥,例如is_need_to_run表示该场景是否要执行,讲流程配置的更灵活,还可以记录执行结果result
| caseId | case_name | sheet_name | is_need_to_run | Result |
|---|---|---|---|---|
| 1 | XX场景 | sheetName | y/n | pass/fail |
| 2 | XXX场景 | sheetName | y/n | pass/fail |
(2)YAML文件
Python的第三方库pyyaml-include可以将yaml文件嵌入另一yaml文件中,从而读取某一yaml文件,可以读取到嵌入的其他文件
bash
# 总流程yaml文件
steps:
- !inc XXX/XX场景.yaml
- !inc XXX/XXXX场景.yaml4.UI自动化和接口自动化结合
自动化测试的应用场景不仅有平常的归回测试,还可以应用到冒烟测试,这样就意味应该尽可能简化非测试部分,让自动化测试的运行时间越短越好。从上一篇文章的自动化分层测试可以得知,UI自动化的运行时间要远大于接口自动化,是小时级别的,那么是不是可以在UI自动化时,将依一些前置操作利用接口自动化完成,然后执行UI自动化,这将大大减少运行时间。
4.1融合原理
由于HTTP是无状态协议,多个HTTP请求之间,是不会保存信息状态的。要保存登录状态,必须有Cookie、Session甚至Token的支持。
所以融合UI自动化和接口自动化的关键就是保持登录装态,需要保持登录态有以下几方面
(1)各个接口请求之间应该保持登录状态
(2)各个UI操作之间应该保持登录状态
(3)当从接口请求切换到UI操作时,登录状态应该从接口请求中带过来
4.2融合实践
最常见的UI自动化和接口自动化结合的例子就是登录,测试很多功能时的前置操作都必须要登录,如果能够快速登录,那将节约很多执行时间。伪代码如下
python
# 先调用接口'login_url_api'登录
result = request.post('login_url_api',data=json.dumps(login_data))
# 拿到返回的cookie,根据实际情况解析
all_cookies = result.cookies
# 删除独有cookie
driver.get('login_url')
driver.delete_all_cookies()
# 把接口登录后的cookies传递给Selenium/Webdriver 传递登录状态
# cookie_to_selenium_format(v) 把接口登录获取的cookie转换成Selenium/Webdriver识别的格式
for k,v in all_cookies.items():
driver.add_cookie(cookie_to_selenium_format(v))
# 再次调用前端'login_url'URL,验证是否登录成功
driver.get('login_url')