目录
[3.5. 自己实现线程池。](#3.5. 自己实现线程池。)
1.阻塞队列。
1.1阻塞队列是什么。
阻塞队列是一种特殊的数据结构,遵守的依旧是我们在学习数据结构的时候普通的队列的原则------"先进先出"的原则。
阻塞队列 是一种线程安全的数据结构,并且它具有以下特征:
1.当队列满的时候,继续入队就会产生阻塞,直到有其他的线程从队列中取走元素。
2.当队列空的时候,继续出队就会产生阻塞,直到有其他的线程在队列中插入元素。
阻塞队列在我们的生活中也是有应用场景的,就是"消费者生产者模型",这是一种非常典型的开发模型。
1.2阻塞队列的作用。
1.阻塞队列就相当于一个缓冲区,平衡消费者和生产者之间的处理能力。(削峰填谷)
下面我通过图片带大家更好的理解"削峰填谷"。

我们众多周知,我们国家的下游在之前的时候 ,是经常产生暴雨和洪涝的,这是因为我们的上游的降雨量一旦多的时候,下游就一下没有办法接受的了这么多的降雨量就发生了灾难;就相对于上游我们有多少降雨量就会在下游也会产生多少降雨量。之后呢,我们就创建了各种大坝,它的作用就是控制水流量的多少,上游的降雨量一旦多了,我们的下游就不会一下也流经这么多的水量,就是通过三峡大坝这样的大坝进行调节的,当下游降雨量少的时候,就会将大坝里面的水打开;要是上游的水量多的时候,就会用大坝将大雨控制住。这样就产生了水量的平衡。
放到我们的程序中,要是程序的访问量和信息多的时候就会将消息先放到队列中去,防止过度的访问导致服务器的瘫痪。
2.阻塞队列也能使生产者和消费者之间解耦。
例子:当我们过年的时候,我们绝大多数地方到时间都是吃的饺子,那当然离不开包饺子的人。就我和我的妈妈,我的爸爸过年的时候就会包饺子,那么我们都可以自己擀饺子皮,并且自己包饺子,可是我们要是同时要擀饺子皮的时候,就会产生其他的人只能等着。后面呢我们就产生了其他的方法,一个人专门擀饺子皮,其他的两个人包饺子,这样就不会进行其他的人进行等待了。我擀饺子皮的时候,擀好了之后就放到一边就好了,他们只需要从那边去取。就现在呢我们在快递行业也是这样进行的,每个人负责好自己的一个部分,不去关心其他的部分是怎么干的。
阻塞队列使得生产者和消费者之间不进行直接的交互,通过阻塞队列进行了消息缓冲,降低了两者之间的相互依赖的关系。
1.3标准库中的阻塞队列
在JAVA的标准库中给我们提供了内置的阻塞队列,BlockingQueue。
1.BlockingQueue只是一个接口,真正实现的类是LinkedBlockingQueue。
2.put 用于如对的操作,take 用于出队的操作。
3.BlockingQueue 也有其他的方法,例如offer , poll ,peek这些方法,但是这些方法不带有阻塞的效果。
代码展示:
java
public static void main(String[] args) throws InterruptedException {
//创建队列
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();
//入队
queue.put(123);
queue.put(456);
queue.put(789);
for (int i = 0; i < 3; i++) {
int elem = queue.take();
System.out.println(elem);
}
}运行结果:

我们观察结果可以发现这个结果是符合阻塞队列的特点的,先进先出。
我们要是没有进行插入元素的时候,进行出队列的操作:
代码展示:
java
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();
int elem = queue.take();
System.out.println(elem);运行结果:
我们发现没有打印的结果。这就符合了我们没有元素进行不能进行出队列的操作。
代码展示:
java
public static void main(String[] args) throws InterruptedException {
//创建队列
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(4);
queue.put(123);
queue.put(456);
queue.put(654);
queue.put(5);
queue.put(8);
for (int i = 0; i < 4; i++) {
int elem = queue.take();
System.out.println(elem);
}
}运行结果:

我们发现没有输出结果。
那是因为我们阻塞的队列容量设置了四个,所以进行插入五个的时候,是不会成功的,我们要先出去一个就可以继续进行插入结果了,最后并打印。
代码展示:
java
public static void main(String[] args) throws InterruptedException {
//创建队列
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(4);
queue.put(123);
queue.put(456);
queue.put(654);
queue.put(5);
int elem = queue.take();
System.out.println(elem);
queue.put(8);
for (int i = 0; i < 4; i++) {
int elemm = queue.take();
System.out.println(elemm);
}
}运行结果:
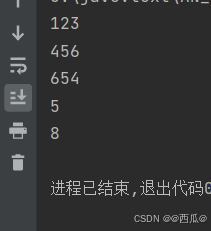
这样我们就验证了阻塞队列的基本特性。
1.4自己实现阻塞队列。
自己实现阻塞队列的话,小编已经将这个单独写成了一片博客,大家可以从下面的链接进行访问。这里呢,小编就不过多说了。
2.定时器。
2.1定时器是什么。
定时器顾名思义就是到达一定的时间之后干某个事情,放到我们的代码中的话 ,那当然也是需要的,我们之后也需要在程序中设置某些代码在一定时间之后去执行的。
定时器之后在我们的开发中也是用的比较多的一个组件。
例如:
1.网络通信中,如果对方500ms内没有返回数据,则断开连接尝试重连。
2.比如我们在某些时候需要用手机给电脑连接网路的时候,我们要是带着手机走开之后我们的手机热点刚开始还是一直打开着呢,但是我们一定会有一个截止时间,当到达一定的时间了,我们的热点就会自动关闭。
2.2标准库中的定时器。
标准库中提供了一个 Timer 类,核心方法是 schedule。
schedule 包含两个参数,第一个参数是即将要执行的任务代码,第二个参数是多久时间之后执行(单位:毫秒)。
代码演示:
java
Timer time = new Timer();
time.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello java");
}
},3000);
time.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello word");
}
},2000);
time.schedule(new TimerTask() {
@Override
public void run() {
System.out.println("hello xigua");
}
},1000);运行结果:
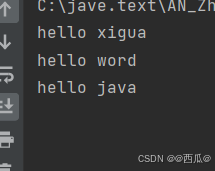
我们观察运行结果的时候会发现,这个运行结果不是一下就出来的,是等待了相应的时间才执行的。
2.3自己实现定时器。
自己实现定时器的操作我已经单独写成了一片博客,大家可以从下面的链接进行访问去读取。
3.线程池。
3.1线程池是什么。
线程池顾名思义就是一个可以容纳多个线程的容器,预先创建一定数量的线程,当有任务提交时,从线程池中取出空闲线程来执行任务,任务执行完毕后,线程不会销毁,而是返回到线程池中等待下一个任务。
为什么使用线程池呢?
1.减少线程创建和销毁的开销。
创建线程和销毁线程是比较昂贵的操作,会消耗大量的系统资源和时间,使用线程池可以复用已有的线程,避免频繁创建和销毁线程带来的性能损耗。
2.提高响应速度。
由于线程提前已经创建好了,当任务到来的时候,无需进行等待线程创建,可以立即执行任务,从而提高系统的相应速度。
3.便于线程管理。
线程池提供了统一的管理接口,可以方便的对线程进行监控,调度和管理。
3.2线程池的参数介绍
我们观察 ThreadPoolExecutor 的参数。

观察到一共有七个参数,七个参数的含义分别是:
1.corePoolSize 是核心线程数。创建线程的时候就申请的,用完之后,一直存在,除非清除线程池,这样就不存在了。 2.maximumPoolSize 是总线程数。等于核心线程数加上临时线程数的总和。里面的临时线程就是没有工作的时候就会将其销毁,不在存在到线程池里面。 3.keepAliveTime 临时线程的存活时间。 4.unit 时间单位。 5.workQueue 阻塞队列。用于存放数据。 6.threadFactory 创建线程的工厂。参与具体的线程创建的工作,通过不同的线程工厂创建出的线程相当于对属性进行不同的初始化。 7.handler 是拒绝策略。
拒绝策略就类似于别人给你交代一个事情让你去做,我们不同的选择结果。
1.终止就是直接拒绝。
2. 调用者自己处理执行任务。
3.丢弃队列中最老的任务。
4.丢弃队列中最新的任务。
3.3线程池的工作流程
1.线程池的初始化。创建线程池的时候,会先创建一定数量的线程,并将他们存储到线程池里面。
**2.提交任务。**当有新的任务提交到线程池时,线程池会从空闲线程中选择一个线程来执行该任务。
**3.任务执行。**被选中的线程开始执行任务,任务执行完毕后,线程不会销毁,而是返回到线程池中等待下一个任务。
**4.线程池关闭。**当不再需要线程池的时候,就调用线程池的关闭方法,将线程池中的所有线程销毁。
3.4.标准库中的线程池。
JAVA提供的都在 Executors 下面。
创建线程的方式有以下几种:
1.newFixedThreadPool 是创建一个固定线程数
2.newCachedThreadPool 是创建核心线程数为0,最大线程数为"int 最大值"。
3.newSingleThreadExecutor 是创建固定只有一个线程的线程池。
4.newScheduledThreadPool 是定时器,会在一定的时间之后再去指定这个具体的任务。
代码展示:
java
public static void main(String[] args) {
//固定线程池,核心线程数和总线程数都是一样的(后面的变量)
ExecutorService service = Executors.newFixedThreadPool(4);
//核心线程数为0,最大线程数为"int最大值"
ExecutorService service1 = Executors.newCachedThreadPool();
//创建固定只有一个线程的线程池
ExecutorService service2 = Executors.newSingleThreadExecutor();
//定时器,会在一定的时间之后在进行执行
ExecutorService service3 = Executors.newScheduledThreadPool(10);
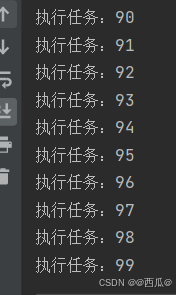
for( int i = 0;i < 100;i++){
int id = i;
service.submit(new Runnable() {
@Override
public void run() {
System.out.println("执行任务:" + id);
}
});
}
}运行结果:
3.5. 自己实现线程池。
下面呢我们实现第一种,实现固定线程数的线程池 newFixedThreadPool。
3.5.1实现类。
代码展示:
java
class MyNewFixed{
//创建阻塞队列
private BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>();
public MyNewFixed(int n){
//创建线程,线程完成的任务就是从从队列中取出元素并执行
for(int i = 0; i < n;i++){
Thread t = new Thread(()->{
try{
while (true){
Runnable task = queue.take(); //取出元素
task.run(); //执行
}
}catch(InterruptedException e){
e.printStackTrace();
}
});
t.start();
}
}
//向队列中添加元素
public void subMit(Runnable elem) throws InterruptedException{
queue.put(elem);
}
}上述代码中我们实现的话首先是需要一个阻塞队列,用于存放消息,我们在这个类的构造方法中去初始化,创建线程,并且让线程完成的任务就是从队列中取出元素并进行执行。
在下面的添加元素方法 submit 操作里面就需要执行真正添加的操作,里面的变量就是去确定创建几个线程。
3.5.2测试类
代码展示:
java
public class Demo12_BlockingQueue {
public static void main(String[] args) throws InterruptedException {
MyNewFixed myNewFixed = new MyNewFixed(3);
for (int i = 0; i < 100; i++) {
int id = i;
myNewFixed.subMit(()->{
System.out.println("执行任务:" + id);
});
}
}
}在测试类里面就实例化了一下我们自己构造的方法,之后就进行真正的添加操作,多个线程执行的情况下。
运行结果:
这里呢,我要是将线程创建的数目改为1,那么我们就会得到递增顺序的结果。
运行结果: