鉴于Informer架构及其处理逻辑蕴含了丰富的实战技术,本文将分为上下两章进行深入探讨。
上篇将专注于解析Informer中的Reflector组件,而下篇则会详尽分析Indexer模块。通过这种结构化的呈现方式,提供一个全面且系统的学习路径。
问题发现
在前一章节中,我们探讨了使用RestClient访问Kubernetes(K8S)集群资源的方法,并详细解析了其源码实现流程。值得注意的是,尽管RestClient构成了client-go与K8S交互的基础,但在实际应用中,更常见的是采用以下几种高级客户端来简化操作:
- ClientSet :**基于RestClient构建,提供了对所有内置K8S资源类型的封装接口。**通过ClientSet,开发者能够以更为便捷的方式直接调用这些资源而无需记忆具体的API路径、资源名称或版本信息。然而,这种便利性是以牺牲灵活性为代价的------ClientSet不支持自定义资源定义(CRD)对象的操作。
- DynamicClient :作为一款动态客户端工具,它允许用户针对任何Kubernetes资源执行查询操作,其中包括自定义资源定义(CRDs)。这一特性使得DynamicClient成为处理非标准或新引入资源的理想选择。
- DiscoveryClient :主要用于发现并获取由Kubernetes API服务器提供的资源列表信息 。此外,在
kubectl命令行工具中,DiscoveryClient还会将这些信息缓存至本地目录~/.kube/cache/discovery/下,从而加快后续请求的速度。
以上所述的各种客户端组件各自具备独特优势,根据具体需求灵活选用可显著提升开发效率及系统管理能力。
在这一过程中,clientSet的informer无疑扮演了极其重要的角色。那么,为什么需要引入informer?它又是如何被开发出来的呢?记住这一点至关重要:任何技术的诞生都是为了解决特定问题。为了回答这两个问题,反证法来看下面这一个问题:
如果所有组件及外部程序都直接通过 clientSet或 RestClient来访问Kubernetes集群资源,将会遇到哪些挑战?
- 并发性问题:当基础设施的存储资源被视为业务逻辑的一部分时,所有请求无限制地涌向API服务器会导致其负载显著增加(尽管API服务器具备一定的限流机制)。然而,一旦触发了限流阈值,将可能导致服务不可用,从而对业务造成负面影响。
- 缓存缺失问题 :从
restClient的实现来看,它缺乏有效的缓存策略,这意味着每次数据查询都需要经过API服务器,这不仅增加了网络延迟,也加重了API服务器的工作负担。 - 数据时效性问题 :对于API服务器上发生的任何更新,
restClient是无法即时感知到的,因此必须定期轮询API服务器以获取最新信息。随着系统规模的增长,这种做法会进一步加剧API服务器的并发压力。虽然可以使用clientSet提供的watch功能来监听变化,但这又引出了新的挑战。 - 版本一致性问题 :采用
clientSet进行监听操作时,若因网络不稳定等因素导致监听中断,则需手动执行全量同步(Resync)以确保本地缓存与远程状态的一致性。 - 错误处理机制不足 :无论是
restClient还是clientSet,它们都将错误恢复的责任交给了应用层,这意味着开发者需要自行设计和实现相应的容错逻辑。 - 在业务处理过程中,Kubernetes(k8s)依赖于事件驱动机制来管理资源状态的变化。因此,应用程序需要自行解析不同类型的事件(如添加、更新或删除),并据此维护相应的状态机,这无疑增加了代码实现的复杂度。
- **安全方面:**访问Kubernetes集群主要依靠证书和Token进行身份验证与授权,但这一过程容易遇到配置不当或证书/Token过期的问题。
综上所述,informer作为clientSet的一部分,正是为了解决上述提到的各种问题而被引入的,它提供了一种更加高效且可靠的机制来管理Kubernetes对象的状态。
针对上述挑战,Informer提供了一种有效的解决方案:
- List/Watch机制:通过高效地监听Kubernetes集群内部发生的各类事件,Informer能够及时捕获资源状态变化。
- 事件处理简化 :Informer引入了
EventHandler接口,允许开发者将自定义的回调函数封装起来以响应特定事件,从而让开发者可以更加专注于业务逻辑的实现而非底层事件处理细节。 - 本地缓存支持:对于所有接收到的信息,Informer会在完成事件处理后将其存储至本地缓存中,并且提供了灵活多样的查询接口供应用层调用。
- 共享连接优化:利用共享的Informer实例,多个组件可以共同使用同一个Watch连接来监听相同的资源类型,比如当有十个不同的服务都需要监听Pod事件时,使用SharedInformer只需要建立一个Watch连接即可满足需求,相比之下直接使用ClientSet则需为每个服务单独创建一个独立的Watch连接。
- 定期同步 :Informer还支持周期性地重新同步数据,确保本地缓存与实际集群状态保持一致。
综上所述,这些特性共同构成了Kubernetes生态系统中极为重要的Informer功能,极大地提升了开发效率及系统的稳定性。
接下来,我们将利用goanalysis结合测试代码对informer中的controller和Reflector进行深入分析。goanalysis能够在执行结束前提供所有已执行函数的堆栈信息及其参数快照,这有助于克服使用dlv调试时频繁需要重启程序的问题。
本示例基于client-go版本v0.30.1。
请注意,这里假设您已经熟悉Go语言环境以及Kubernetes相关组件的工作原理。
通过这种方式,我们旨在更高效地理解及调试informer机制内部复杂的交互过程。
初步体验
import (
"log"
"time"
"github.com/toheart/functrace"
v1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/client-go/informers"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/tools/clientcmd"
"k8s.io/klog/v2"
)
func main() {
defer func() {
functrace.CloseTraceInstance() # 透视代码函数结束, 不用在意
}()
config, err := clientcmd.BuildConfigFromFlags("", "/root/.kube/config")
if err != nil {
panic(err)
}
config.Timeout = time.Second * 5
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}
stopCh := make(chan struct{})
defer close(stopCh)
log.Printf("create new inforemer \n")
sharedInformers := informers.NewSharedInformerFactory(clientset, time.Minute)
informer := sharedInformers.Core().V1().Pods().Informer()
informer.AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) {
mObj := obj.(v1.Object)
log.Printf("New Pod Added to Store: %s", mObj.GetName())
},
UpdateFunc: func(oldObj, newObj interface{}) {
oObj := oldObj.(v1.Object)
nObj := newObj.(v1.Object)
log.Printf("%s Pod Update to %s", oObj.GetName(), nObj.GetName())
},
DeleteFunc: func(obj interface{}) {
mObj := obj.(v1.Object)
log.Printf("Pod Deleted from Store:%s", mObj.GetName())
},
})
sharedInformers.Start(stopCh)
if !cache.WaitForCacheSync(stopCh, informer.HasSynced) {
klog.Fatal("failed to synced")
}
select {}
}从上述描述中可以看出,Informer功能的实现流程相对直接,主要包含以下几个关键步骤:
- 获取认证凭据;
- 构建
clientset实例; - 利用
clientset来初始化SharedInformerFactory对象; - 为需要监听的具体资源创建对应的Informer;
- 定义针对不同资源事件的处理逻辑;
- 启动
sharedInformers以开始监听和处理资源变动。
这样的结构化方法确保了Kubernetes集群内资源变更能够被高效地捕获与响应。
透视源码
初始化ClientSet
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err)
}在前文所述中,我们提到clientSet会创建一系列内置资源对象,并将其存储于结构体之中。通过可视化界面,可以进一步观察到其中的细节。
抽出一个函数看:
cs.admissionregistrationV1, err = admissionregistrationv1.NewForConfigAndClient(&configShallowCopy, httpClient)
if err != nil {
return nil, err
}其中,httpClient 是 RestClient 对象内部封装的 HTTP 客户端实例。
初始化ShardInformer

最终在执行过程中调用的是NewSharedInformerFactoryWithOptions函数。该函数的实现相对简洁:
func NewSharedInformerFactoryWithOptions(client kubernetes.Interface, defaultResync time.Duration, options ...SharedInformerOption) SharedInformerFactory {
factory := &sharedInformerFactory{
client: client, // clientset客户端
namespace: v1.NamespaceAll, // 使用""
defaultResync: defaultResync, // 默认重新同步时间
informers: make(map[reflect.Type]cache.SharedIndexInformer), // Informer
startedInformers: make(map[reflect.Type]bool), // informer是否已经启动
customResync: make(map[reflect.Type]time.Duration), // informer自定义同步时间
}
// Apply all options
for _, opt := range options {
factory = opt(factory)
}
return factory
}根据上述内容,可以得出以下结论:
- 对于每个资源对象,
shardInformer仅维护一个对应的Informer实例; - 关于同步时间的设定,若在
customResync中已定义,则优先采用该值;反之,在未指定的情况下,则使用默认的defaultResync配置。
创建podInformer
informer := sharedInformers.Core().V1().Pods().Informer()调用链如下:

核心代码如下:
func (f *podInformer) Informer() cache.SharedIndexInformer {
return f.factory.InformerFor(&corev1.Pod{}, f.defaultInformer)
}
func (f *sharedInformerFactory) InformerFor(obj runtime.Object, newFunc internalinterfaces.NewInformerFunc) cache.SharedIndexInformer {
f.lock.Lock()
defer f.lock.Unlock()
// 如果 &corev1.Pod{} 存在, 则直接返回informer
informerType := reflect.TypeOf(obj)
informer, exists := f.informers[informerType]
if exists {
return informer
}
resyncPeriod, exists := f.customResync[informerType]
// 如果 resync 不存在, 则使用默认的Resync
if !exists {
resyncPeriod = f.defaultResync
}
// 创建新的informer, 将保存到map中。
informer = newFunc(f.client, resyncPeriod)
informer.SetTransform(f.transform) // 这里从goanalysis中可以看出其当前为Nil.
f.informers[informerType] = informer
return informer
}
func (s *sharedIndexInformer) SetTransform(handler TransformFunc) error {
s.startedLock.Lock()
defer s.startedLock.Unlock()
if s.started {
return fmt.Errorf("informer has already started")
s.transform = handler
return nil
}在上述过程中,用于创建Informer的函数是newFunc,该函数被赋值为f.defaultInformer。具体来说,Informer的创建流程如下:
-
定义或获取
newFunc。 -
将
f.defaultInformer赋值给newFunc。 -
通过调用
newFunc来初始化并创建Informer实例。func (f *podInformer) defaultInformer(client kubernetes.Interface, resyncPeriod time.Duration) cache.SharedIndexInformer {
return NewFilteredPodInformer(client, f.namespace, resyncPeriod, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc}, f.tweakListOptions)
}func NewFilteredPodInformer(client kubernetes.Interface, namespace string, resyncPeriod time.Duration, indexers cache.Indexers, tweakListOptions internalinterfaces.TweakListOptionsFunc) cache.SharedIndexInformer {
return cache.NewSharedIndexInformer(
&cache.ListWatch{
ListFunc: func(options metav1.ListOptions) (runtime.Object, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().Pods(namespace).List(context.TODO(), options)
},
WatchFunc: func(options metav1.ListOptions) (watch.Interface, error) {
if tweakListOptions != nil {
tweakListOptions(&options)
}
return client.CoreV1().Pods(namespace).Watch(context.TODO(), options)
},
},
&corev1.Pod{},
resyncPeriod,
indexers,
)
}func NewSharedIndexInformerWithOptions(lw ListerWatcher, exampleObject runtime.Object, options SharedIndexInformerOptions) SharedIndexInformer {
realClock := &clock.RealClock{}return &sharedIndexInformer{
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, options.Indexers),
processor: &sharedProcessor{clock: realClock},
// NewFilteredPodInformer cache.ListWatch
listerWatcher: lw,
// v1.Pod 结构体
objectType: exampleObject,
objectDescription: options.ObjectDescription, //""
resyncCheckPeriod: options.ResyncPeriod, // 60000000000
defaultEventHandlerResyncPeriod: options.ResyncPeriod, // 60000000000
clock: realClock,
// "*v1.Pod"
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", exampleObject)),
}
}
最终通过调用NewSharedIndexInformerWithOptions函数来创建共享索引通知器。该过程的核心要素包括:
- List/Watch机制:此机制底层基于特定函数的初始化,旨在同步对象状态并监听这些对象的变化,从而确保数据源的实时性和准确性。
- Indexer对象初始化:这一步骤建立了本地缓存系统,允许用户在查询时直接访问本地存储的信息而非向API服务器发起请求,从而提高响应速度和效率。
- SharedProcessor对象初始化:此组件负责将从Watch接口接收到的对象变更事件转发给相应的Informer进行进一步处理,保证了信息流的有效传递与处理。
以上三个组成部分共同构成了SharedIndexInformer的核心架构,为其高效运作提供了坚实的基础。
添加EventHandler
func (s *sharedIndexInformer) AddEventHandlerWithResyncPeriod(handler ResourceEventHandler, resyncPeriod time.Duration) (ResourceEventHandlerRegistration, error) {
s.startedLock.Lock()
defer s.startedLock.Unlock()
// 如果informer已经stop
if s.stopped {
return nil, fmt.Errorf("handler %v was not added to shared informer because it has stopped already", handler)
}
.......
// 创建一个 processorListener 实例,用于处理事件通知。
// 该实例将使用给定的 handler、resyncPeriod、
// determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod) 计算的 resyncPeriod、
// s.clock.Now() 获取当前时间、initialBufferSize 初始缓冲区大小,
// 以及 s.HasSynced 方法来确定是否已同步。
listener := newProcessListener(handler, resyncPeriod, determineResyncPeriod(resyncPeriod, s.resyncCheckPeriod), s.clock.Now(), initialBufferSize, s.HasSynced)
// 如果 informer 尚未启动,则将 listener 添加到 processor 中,并返回处理程序句柄。
if !s.started {
return s.processor.addListener(listener), nil
}
// 为了安全地加入,我们需要
// 1. 停止发送添加/更新/删除通知
// 2. 对存储进行列表操作
// 3. 向新的处理程序发送合成的"添加"事件
// 4. 解锁
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
handle := s.processor.addListener(listener)
for _, item := range s.indexer.List() {
// 请注意,我们在持有锁的情况下排队这些通知
// 并在返回句柄之前。这意味着没有机会让任何人调用句柄的 HasSynced 方法
// 在一个会错误返回 true 的状态下(即,当
// 共享通知者已同步但尚未观察到一个带有 isInitialList 为 true 的 Add
// 事件,或者当处理通知的线程以某种方式比这个
// 添加它们的线程更快,计数器暂时为零)。
listener.add(addNotification{newObj: item, isInInitialList: true})
}
return handle, nil
}由此可见,shardInformer具备了动态管理监听器(listener)的能力,支持以线程安全的方式添加新的处理器。
启动shardInformer
func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) {
f.lock.Lock()
defer f.lock.Unlock()
if f.shuttingDown {
return
}
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
f.wg.Add(1)
informer := informer
go func() {
defer f.wg.Done()
informer.Run(stopCh)
}()
f.startedInformers[informerType] = true
}
}
}步骤如下:
- 鉴于
sharedInformer在系统中扮演了核心管理者的角色,因此在对其进行操作时需实施加锁机制。此举旨在确保在Go语言的不同goroutine(协程)间访问sharedInformer时的一致性和数据完整性。 - 容错处理:若检测到
sharedInformer已经处于停止状态,则直接终止当前流程并返回,以避免执行无效操作。 - 对于尚未启动的Informer实例,通过创建新的goroutine来异步启动它们。
综上所述,Start方法通过上述措施进一步增强了对sharedInformer内部Informer集合动态管理和控制的能力。
核心逻辑-Run
从这里开始透视informer.Run具体做了什么,主逻辑如下:(内部标注当前所有的参数具体值)
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
// 容错机制
if s.HasStarted() {
klog.Warningf("The sharedIndexInformer has started, run more than once is not allowed")
return
}
// 为了释放锁(美观?)
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
// 创建核心的Delta Queue, 作为Informer内部的事件交流渠道
fifo := NewDeltaFIFOWithOptions(DeltaFIFOOptions{
KnownObjects: s.indexer, // 创建podInformer时创建的indexer
EmitDeltaTypeReplaced: true,
Transformer: s.transform, // nil
})
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher, // 创建podInformer时 list watch 函数
ObjectType: s.objectType, // v1.Pod{}
ObjectDescription: s.objectDescription, // ""
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync, // 函数
Process: s.HandleDeltas, // 事件发生后核心处理函数
WatchErrorHandler: s.watchErrorHandler, // 错误处理函数
}
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
...
// 没啥用
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
// 启动listen处理器
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
s.controller.Run(stopCh)
}这里我们先分析主协程的Run函数:
func (c *controller) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
go func() {
<-stopCh
c.config.Queue.Close()
}()
// 创建一个 Reflector 实例,用于从 ListerWatcher 拉取对象/通知,并将其推送到 DeltaFIFO 中。
r := NewReflectorWithOptions(
c.config.ListerWatcher, // 创建podInformer时 list watch 函数
c.config.ObjectType, // 同controller内部
c.config.Queue, // Delta Queue
ReflectorOptions{
ResyncPeriod: c.config.FullResyncPeriod,
TypeDescription: c.config.ObjectDescription,
Clock: c.clock,
},
)
r.ShouldResync = c.config.ShouldResync
r.WatchListPageSize = c.config.WatchListPageSize
if c.config.WatchErrorHandler != nil {
r.watchErrorHandler = c.config.WatchErrorHandler
}
c.reflectorMutex.Lock()
c.reflector = r
c.reflectorMutex.Unlock()
var wg wait.Group
wg.StartWithChannel(stopCh, r.Run)
wait.Until(c.processLoop, time.Second, stopCh)
wg.Wait()
}
func NewReflectorWithOptions(lw ListerWatcher, expectedType interface{}, store Store, options ReflectorOptions) *Reflector {
reflectorClock := options.Clock
if reflectorClock == nil {
reflectorClock = clock.RealClock{}
}
r := &Reflector{
name: options.Name, // ""
resyncPeriod: options.ResyncPeriod, // 60000000000
typeDescription: options.TypeDescription, // ""
listerWatcher: lw, //controller listerWater --> pod list/watch
store: store, // Delta Queue
backoffManager: wait.NewExponentialBackoffManager(800*time.Millisecond, 30*time.Second, 2*time.Minute, 2.0, 1.0, reflectorClock),
clock: reflectorClock,
watchErrorHandler: WatchErrorHandler(DefaultWatchErrorHandler),
expectedType: reflect.TypeOf(expectedType), // v1.Pod {}
}
....
}在该实现中,创建了Reflect对象。实际上,Reflect对象的内部字段主要继承自其上层的Controller对象。
架构图
基于上述分析,我们现在可以更加清晰地理解架构图:
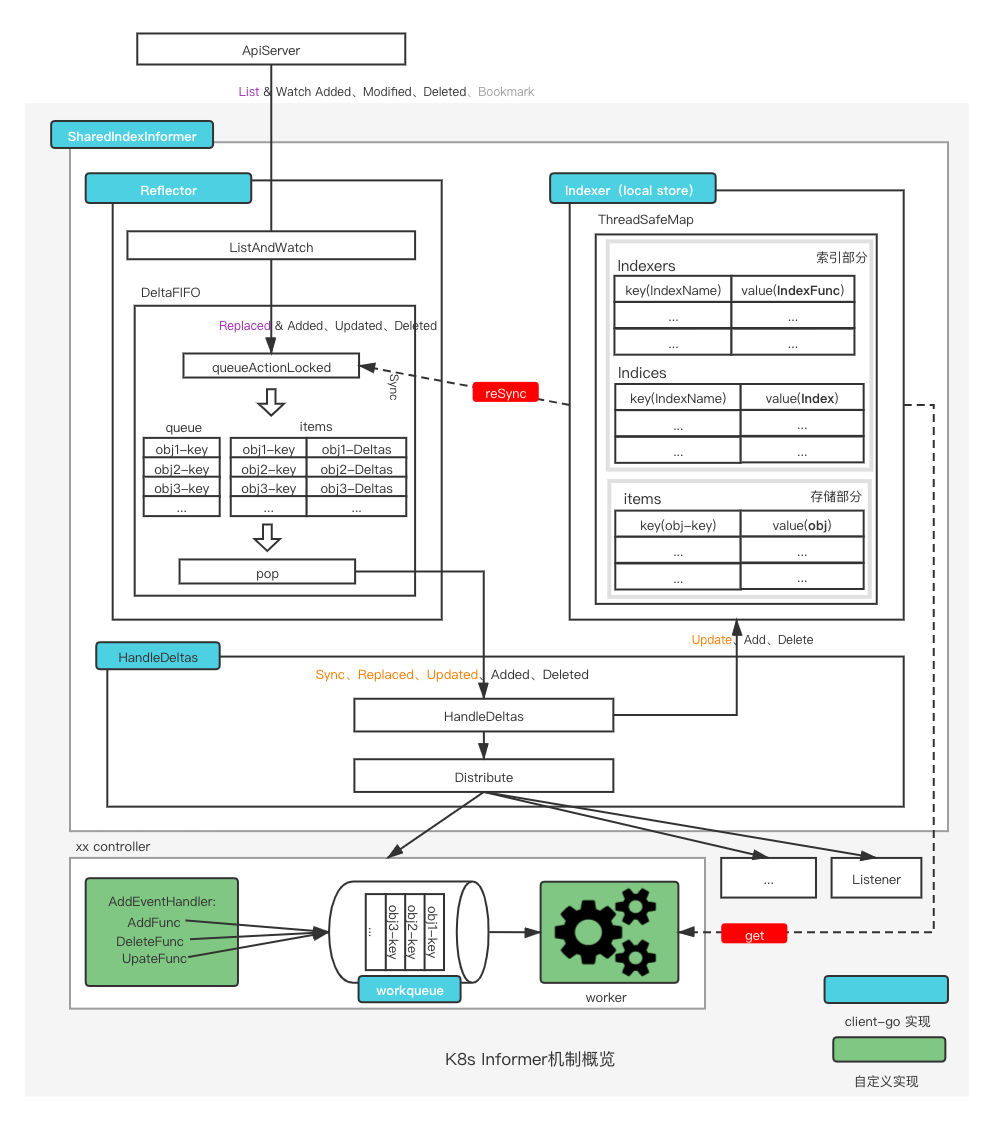
在上述过程中,启动了三个协程,具体如下:
k8s.io/client-go/tools/cache/dummyMutationDetector.Run:此函数当前未执行任何实质性操作。k8s.io/client-go/tools/cache.(*sharedProcessor).run:k8s.io/client-go/tools/cache.(*processorListener).run:该方法通过用户自定义的处理器来处理事件,与底层逻辑紧密相关。k8s.io/client-go/tools/cache.(*processorListener).pop:此方法负责将事件分发到工作队列(workqueue)中。
k8s.io/client-go/tools/cache.(*Reflector).Run:此协程负责执行列表和监视操作,从API服务器获取数据。图示中的"pop"动作由下面描述的processLoop函数执行。
而主协程最终进入一个循环,处理由Reflector.Run生成的数据,具体的处理函数为k8s.io/client-go/tools/cache.(*controller).processLoop。这构成了整个数据流处理的核心机制。

在Reflect到DeltaFifo,再到processLoop,最终至HandleDeltas的流程中蕴含了丰富的技术细节与设计考量。为便于深入理解这一过程,我们将分章节详细探讨各个环节的关键点。
从apiserver拿数据
反射器的调用链设计得相当简洁。
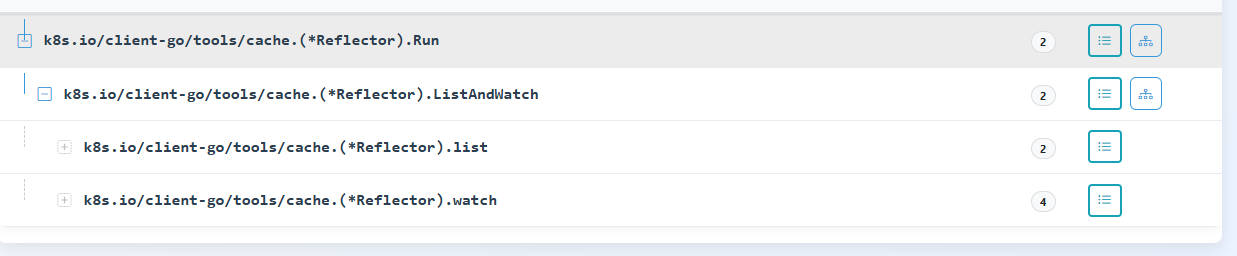
list

在调用链中未发现实际的列表操作。通过源代码分析,我们注意到请求函数被封装在一个闭包协程内(对于这种设计的选择,我尚不完全理解其背后的意图)。
// list 函数简单地列出所有项,并记录在调用时从服务器获得的资源版本。
// 该资源版本可用于进一步的进度通知(即观察)。
func (r *Reflector) list(stopCh <-chan struct{}) error {
var resourceVersion string
options := metav1.ListOptions{ResourceVersion: r.relistResourceVersion()}
...
var list runtime.Object
go func() {
defer func() {
if r := recover(); r != nil {
panicCh <- r
}
}()
pager := pager.New(pager.SimplePageFunc(func(opts metav1.ListOptions) (runtime.Object, error) {
return r.listerWatcher.List(opts)
}))
....
list, paginatedResult, err = pager.ListWithAlloc(context.Background(), options)
if isExpiredError(err) || isTooLargeResourceVersionError(err) {
r.setIsLastSyncResourceVersionUnavailable(true)
list, paginatedResult, err = pager.ListWithAlloc(context.Background(), metav1.ListOptions{ResourceVersion: r.relistResourceVersion()})
}
close(listCh)
}()
select {
case <-stopCh:
return nil
case r := <-panicCh:
panic(r)
case <-listCh:
}
initTrace.Step("Objects listed", trace.Field{Key: "error", Value: err})
if err != nil {
klog.Warningf("%s: failed to list %v: %v", r.name, r.typeDescription, err)
return fmt.Errorf("failed to list %v: %w", r.typeDescription, err)
}
if options.ResourceVersion == "0" && paginatedResult {
r.paginatedResult = true
}
r.setIsLastSyncResourceVersionUnavailable(false) // list was successful
.....
if err := r.syncWith(items, resourceVersion); err != nil {
return fmt.Errorf("unable to sync list result: %v", err)
}
...
r.setLastSyncResourceVersion(resourceVersion)
return nil
}最终从其他协程中,可以看出其调用关系如下:
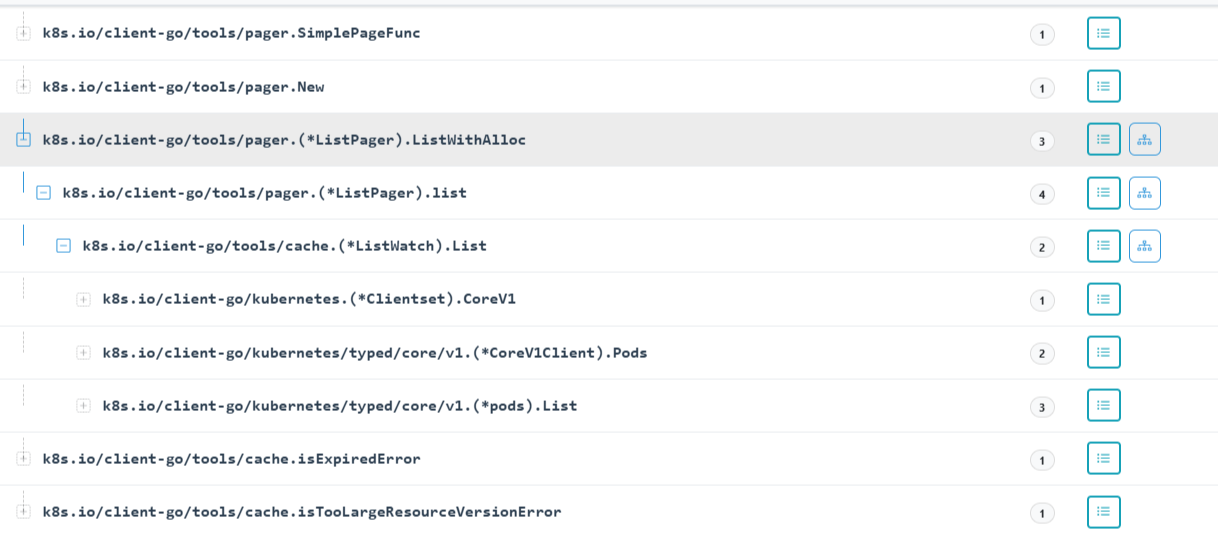
而通过参数图可以看到page对象调用ListWithAlloc时的内部字段如下,采用了分页获取:
{
"PageSize": 500,
"PageFn": "0x171bdc0",
"FullListIfExpired": true,
"PageBufferSize": 10
}在其获取成功后,最终调用syncWith 我们可以发现传入了14个结构体,为当前所有namespace中的pod总数;
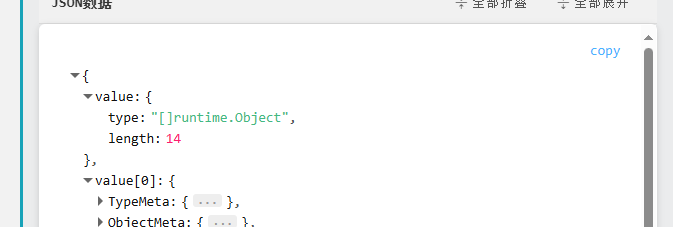
syncwatch
通过分析调用链可以观察到,在Replace函数中,KeyOf与QueueActionLocked之间存在一个循环依赖关系。
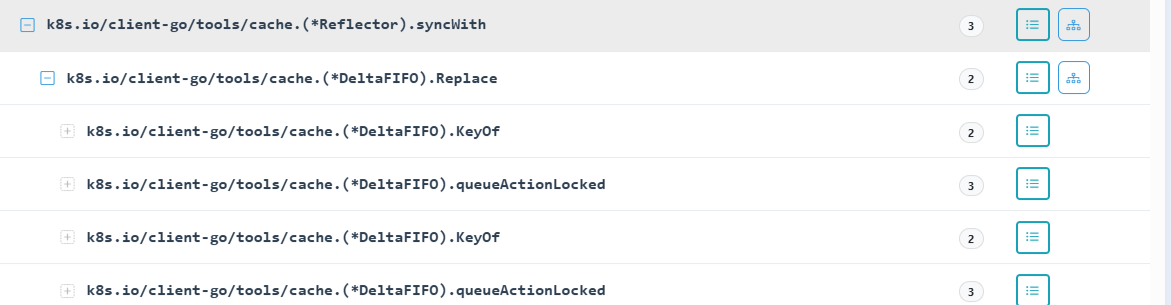
为了更好的展示我们使用生成调用图的功能:
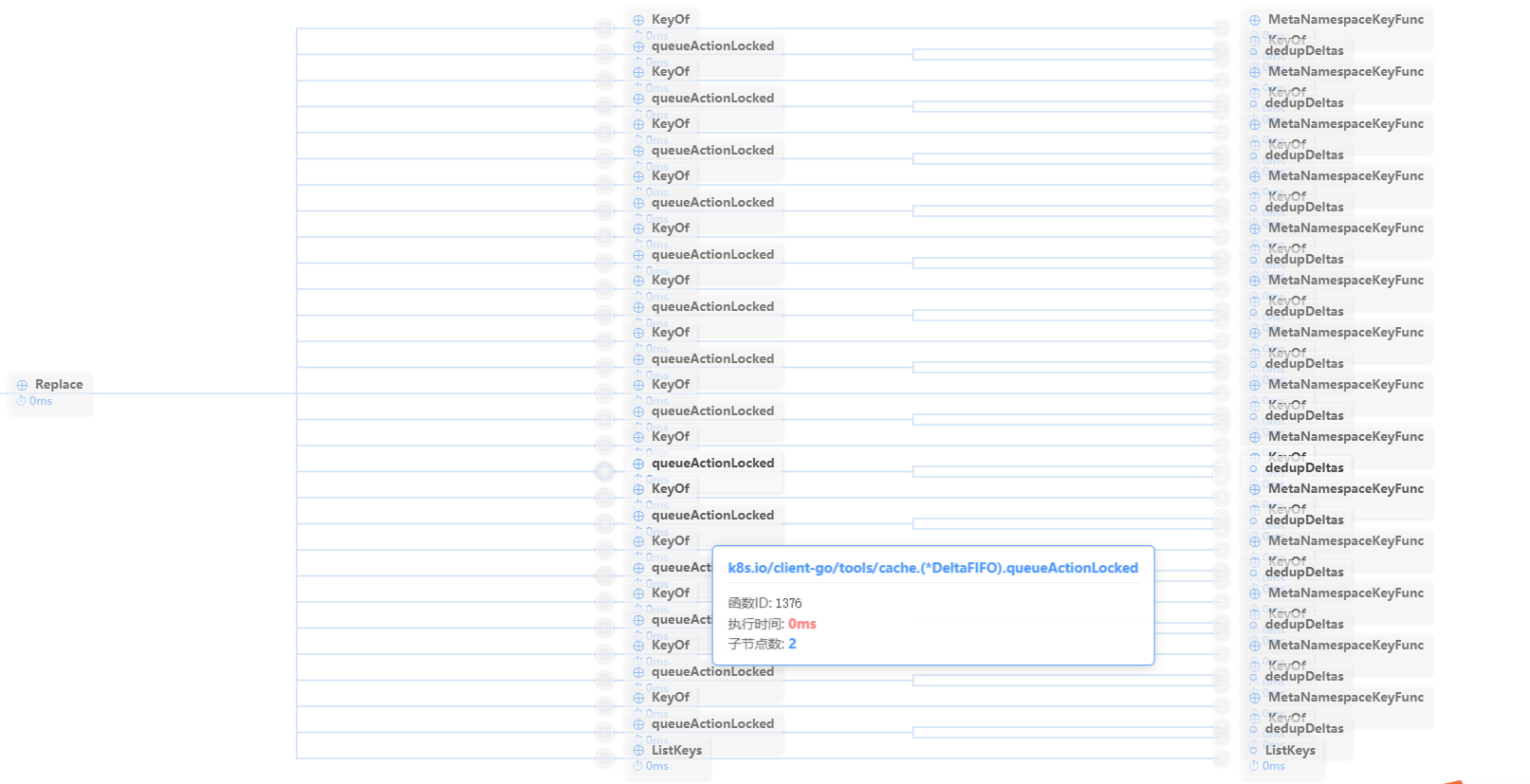
这里可以清晰的看到有14组,对应了list产生的14个对象,通过上面分析,我们继续查看Replace函数:
func (f *DeltaFIFO) Replace(list []interface{}, _ string) error {
// !!!!! 关键步骤, 加锁!!!!!
f.lock.Lock()
defer f.lock.Unlock()
keys := make(sets.String, len(list))
// keep backwards compat for old clients
action := Sync
if f.emitDeltaTypeReplaced {
action = Replaced // 执行
}
// 进入循环
for _, item := range list {
key, err := f.KeyOf(item)
if err != nil {
return KeyError{item, err}
}
keys.Insert(key)
if err := f.queueActionLocked(action, item); err != nil {
return fmt.Errorf("couldn't enqueue object: %v", err)
}
}
// Do deletion detection against objects in the queue
queuedDeletions := 0
for k, oldItem := range f.items {
.....
}
if f.knownObjects != nil {
// 为空
knownKeys := f.knownObjects.ListKeys()
for _, k := range knownKeys {
....
}
}
if !f.populated {
// 执行
f.populated = true
// 等于 13
f.initialPopulationCount = keys.Len() + queuedDeletions
}
return nil
}!!!!!!最关键的函数来了!!!!!
queueActionLocked
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
.....
oldDeltas := f.items[id]
newDeltas := append(oldDeltas, Delta{actionType, obj})
// dedupDeltas 判断是否最后两个事件是否都为delete,如果是则保留一份。
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
if _, exists := f.items[id]; !exists {
// 初始化设置, 将当前产生事件的pod对象,加入到queue中。
f.queue = append(f.queue, id)
}
// 将事件加1
f.items[id] = newDeltas
// 广播,告诉等待的地方 , 我这有数据了快来拿,
f.cond.Broadcast()
} else {
.....
}
return nil
}在这一过程中,数据在Deltas中生成,并被广播出去。
watch
调用链如下:
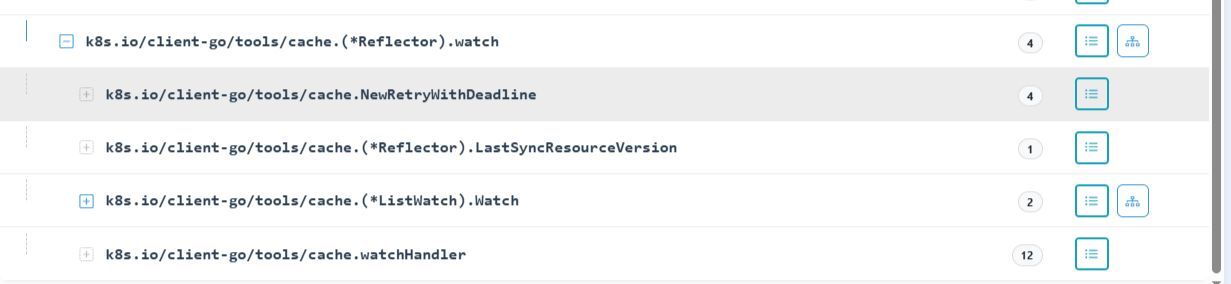
最终调用的是 PodInformer 中的 Watch 方法。
func (r *Request) Watch(ctx context.Context) (watch.Interface, error) {
...
client := r.c.Client
...
url := r.URL().String()
for {
...
req, err := r.newHTTPRequest(ctx)
if err != nil {
return nil, err
}
resp, err := client.Do(req)
retry.After(ctx, r, resp, err)
if err == nil && resp.StatusCode == http.StatusOK {
return r.newStreamWatcher(resp)
}
done, transformErr := func() (bool, error) {
defer readAndCloseResponseBody(resp)
if retry.IsNextRetry(ctx, r, req, resp, err, isErrRetryableFunc) {
return false, nil
}
if resp == nil {
// the server must have sent us an error in 'err'
return true, nil
}
if result := r.transformResponse(resp, req); result.err != nil {
return true, result.err
}
return true, fmt.Errorf("for request %s, got status: %v", url, resp.StatusCode)
}()
}
}这里关键点有两个:
- resp的响应,使用的是HTTP/2.0 作为返回:

-
进入newStreamWatcher, 在这个函数中,创建一个协程获取watch数据,并返回当前对象:
func (r *Request) newStreamWatcher(resp *http.Response) (watch.Interface, error) {
......
objectDecoder, streamingSerializer, framer, err := r.c.content.Negotiator.StreamDecoder(mediaType, params)
if err != nil {
return nil, err
}
.....
frameReader := framer.NewFrameReader(resp.Body)
watchEventDecoder := streaming.NewDecoder(frameReader, streamingSerializer)return watch.NewStreamWatcher(
restclientwatch.NewDecoder(watchEventDecoder, objectDecoder),
errors.NewClientErrorReporter(http.StatusInternalServerError, r.verb, "ClientWatchDecoding"),
), nil
} -
返回的对象会传入到
k8s.io/client-go/tools/cache.watchHandler,接受watch的事件做进一步处置:func watchHandler(....) error {
.....
loop:
for {
select {
case <-stopCh:
return errorStopRequested
case err := <-errc:
return err
case event, ok := <-w.ResultChan(): #<- 这里就是watch接受位置
// dosomething
......
resourceVersion := meta.GetResourceVersion()
switch event.Type {
case watch.Added:
err := store.Add(event.Object)case watch.Modified: err := store.Update(event.Object) case watch.Deleted: err := store.Delete(event.Object) case watch.Bookmark: // `Bookmark` 表示监视已在此处同步,只需更新资源版本 if meta.GetAnnotations()["k8s.io/initial-events-end"] == "true" { if exitOnInitialEventsEndBookmark != nil { *exitOnInitialEventsEndBookmark = true } } default: utilruntime.HandleError(fmt.Errorf("%s: unable to understand watch event %#v", name, event)) } setLastSyncResourceVersion(resourceVersion) if rvu, ok := store.(ResourceVersionUpdater); ok { rvu.UpdateResourceVersion(resourceVersion) } eventCount++ if exitOnInitialEventsEndBookmark != nil && *exitOnInitialEventsEndBookmark { watchDuration := clock.Since(start) klog.V(4).Infof("exiting %v Watch because received the bookmark that marks the end of initial events stream, total %v items received in %v", name, eventCount, watchDuration) return nil }}
}
....
return nil
}
以上我们搞明白了数据的来源,接下来看DeltaFifo如何拿数据;
从DeltaFifo拿数据
拿数据的地方,则是上面主协程中的 wait.Until(c.processLoop, time.Second, stopCh):
func (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
....
}
}
}其中Pop则等于DetalFIfo中的Pop函数,PopProcessFunc对应handleDeltas,可以看下架构图,代码解析如下:
// Pop 阻塞直到队列中有一些项目,然后返回一个。如果有多个项目准备好,它们将按照添加/更新的顺序返回。
// 在返回之前,该项目会从队列(和存储)中移除,因此如果您没有成功处理它,
// 您需要使用 AddIfNotPresent() 将其添加回来。
// process 函数在锁定下调用,因此可以安全地更新需要与队列同步的数据结构(例如 knownKeys)。
// PopProcessFunc 可能返回一个 ErrRequeue 的实例,
// 其中嵌套的错误指示当前项目应该被重新排队(相当于在锁下调用 AddIfNotPresent)。
// process 应避免昂贵的 I/O 操作,以便其他队列操作,即 Add() 和 Get(),不会被阻塞太久。
//
// Pop 返回一个 'Deltas',它包含在队列中等待时对象发生的所有事情(deltas)的完整列表。
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
// 这个地方也加锁了
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
// 当队列为空时,调用 Pop() 会被阻塞,直到有新项目被入队。
// 当调用 Close() 时,f.closed 被设置并且条件被广播。
// 这会导致这个循环继续并从 Pop() 返回。
if f.closed {
return nil, ErrFIFOClosed
}
// 等待上面的广播后, 才被唤起
f.cond.Wait()
}
isInInitialList := !f.hasSynced_locked()
id := f.queue[0]
f.queue = f.queue[1:]
depth := len(f.queue)
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
item, ok := f.items[id]
if !ok {
// This should never happen
klog.Errorf("Inconceivable! %q was in f.queue but not f.items; ignoring.", id)
continue
}
delete(f.items, id)
err := process(item, isInInitialList) <- 处理
....
}
return item, err
}
}在上述流程中,当Board调用该函数时,将从队列(queue)中提取一个条目(item)。需要注意的是,此条目包含了特定资源在一段时间内产生的所有事件。随后,这些事件将被传递给Process (handleDeltas) 进行处理。
f.queue的设计目的是确保在指定时间窗口内,所有生成的事件能够按照资源的接收顺序被有序保存。由于items是以映射(map)的形式存储,而映射本身并不保证元素间的顺序性,因此采用了队列结构来维持事件的序列完整性。
在对该段代码进行分析时,我们注意到一个关键点:从apiserver获取的数据被存储到队列中时会使用锁机制 ,并且该锁仅在函数终止时才会被释放。
然而,在当前讨论的函数中同样存在加锁操作,并且这个锁也在同一函数内部被释放。值得注意的是,f.cond.Wait() 方法调用时会首先解锁,然后将当前协程置于阻塞状态(详情可参考先前关于条件变量Cond的工作原理分析)。
基于上述观察,我推测在初始化阶段可能存在lock与f.cond.Locker()引用相同锁对象的情况,这一点可以从初始配置代码中得到验证。
func NewDeltaFIFOWithOptions(opts DeltaFIFOOptions) *DeltaFIFO {
if opts.KeyFunction == nil {
opts.KeyFunction = MetaNamespaceKeyFunc
}
f := &DeltaFIFO{
items: map[string]Deltas{},
queue: []string{},
keyFunc: opts.KeyFunction,
knownObjects: opts.KnownObjects,
emitDeltaTypeReplaced: opts.EmitDeltaTypeReplaced,
transformer: opts.Transformer,
}
f.cond.L = &f.lock <--------------------------------
return f
}非常搞。
处理数据-HandleDeltas
整体的调用链如下:
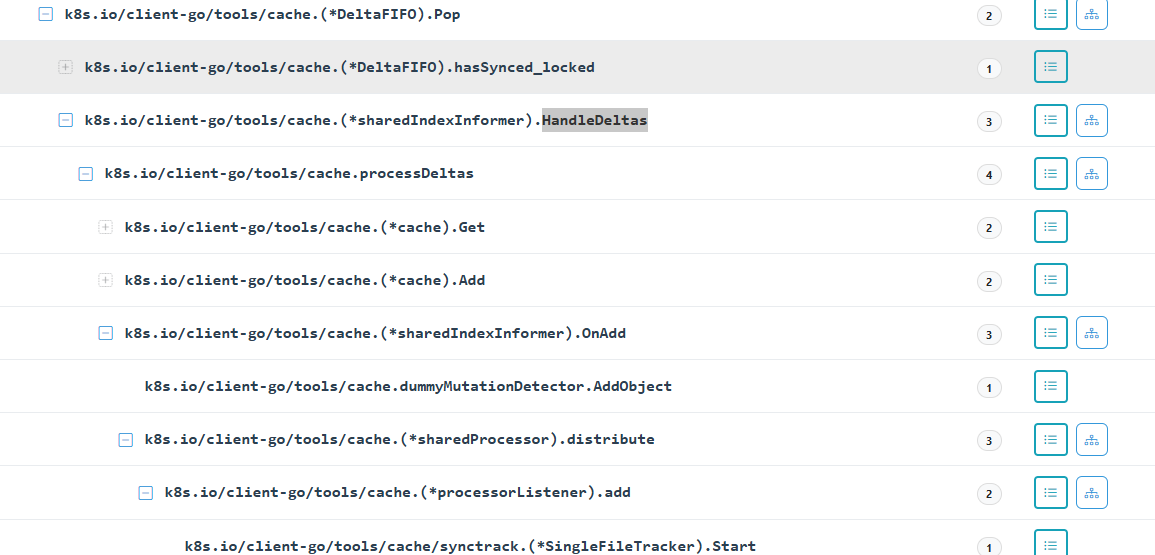
最终核心函数:
func processDeltas(
// Object which receives event notifications from the given deltas
handler ResourceEventHandler,
clientState Store,
deltas Deltas,
isInInitialList bool,
) error {
// from oldest to newest
for _, d := range deltas {
obj := d.Object
switch d.Type {
case Sync, Replaced, Added, Updated:
old, exists, err := clientState.Get(obj)
if err != nil {
return err
}
if exists {
if err := clientState.Update(obj); err != nil {
return err
}
handler.OnUpdate(old, obj)
continue
}
if err := clientState.Add(obj); err != nil {
return err
}
handler.OnAdd(obj, isInInitialList)
case Deleted:
if err := clientState.Delete(obj); err != nil {
return err
}
handler.OnDelete(obj)
}
}
return nil
}根据参数,展示其为Replaced,代码中clientState.Add(obj)主要是加indexer,下篇中说明;
而OnAdd,核心逻辑如下:
// Conforms to ResourceEventHandler
func (s *sharedIndexInformer) OnAdd(obj interface{}, isInInitialList bool) {
s.cacheMutationDetector.AddObject(obj) // 没做啥
s.processor.distribute(addNotification{newObj: obj, isInInitialList: isInInitialList}, false)
}
func (p *sharedProcessor) distribute(obj interface{}, sync bool) { <- 当前为false
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
for listener, isSyncing := range p.listeners {
switch {
case !sync:
// 非同步消息会发送给每个监听器
listener.add(obj)
case isSyncing:
// 同步消息会发送给每个正在同步的监听器
listener.add(obj)
default:
// skipping a sync obj for a non-syncing listener
}
}
}
func (p *processorListener) add(notification interface{}) {
if a, ok := notification.(addNotification); ok && a.isInInitialList {
p.syncTracker.Start()
}
p.addCh <- notification
}走了这么多路,p.addCh我早就忘记是啥玩意儿了。其实它躲在了上述新开的三个协程的:k8s.io/client-go/tools/cache.(*processorListener).pop中:
func (p *processorListener) pop() {
defer utilruntime.HandleCrash()
defer close(p.nextCh) // Tell .run() to stop
var nextCh chan<- interface{}
var notification interface{}
for {
select {
case nextCh <- notification:
// Notification dispatched
var ok bool
notification, ok = p.pendingNotifications.ReadOne()
if !ok { // Nothing to pop
nextCh = nil // Disable this select case
}
case notificationToAdd, ok := <-p.addCh:
if !ok {
return
}
if notification == nil { // No notification to pop (and pendingNotifications is empty)
// Optimize the case - skip adding to pendingNotifications
notification = notificationToAdd
nextCh = p.nextCh
} else { // There is already a notification waiting to be dispatched
p.pendingNotifications.WriteOne(notificationToAdd)
}
}
}
}这段代码的逻辑设计颇具匠心,具体分析如下:
- 首先,我们观察到数据被添加到了
p.addCh通道中。 - 接着,在执行流程进入第二个分支时,将
p.nextCh赋值给了nextCh变量。这一操作确保了在下一次循环迭代中,控制流能够顺利地转移到第一个分支。 - 当程序控制权转回至第一个分支时,之前通过步骤2获取的数据(即存储于
#2中的信息)会被发送至nextCh,实际上也就是p.nextCh。- 如果此时
pendingNotifications缓冲区中有待处理的数据,则继续沿用当前的第一个分支进行处理。 - 反之,如果该缓冲区为空,则程序将暂停并等待新数据的到来。
这种机制有效地实现了异步通信与任务调度之间的协调。
- 如果此时
流程图如下:

组件图如下:

走过了这么长的代码,离了个大谱,还没到处理函数;p.nextCh在哪被接受呢?就剩最后一个协程了:k8s.io/client-go/tools/cache.(*processorListener).run:
func (p *processorListener) run() {
// 此调用会阻塞,直到通道关闭。当在通知过程中发生恐慌时,
// 我们会捕获它,**有问题的项将被跳过!**,并在短暂延迟(一秒钟)后
// 尝试下一个通知。这通常比从不再交付要好。
stopCh := make(chan struct{})
wait.Until(func() {
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj, notification.isInInitialList)
if notification.isInInitialList {
p.syncTracker.Finished()
}
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
// the only way to get here is if the p.nextCh is empty and closed
close(stopCh)
}, 1*time.Second, stopCh)
}天了个姥爷,这里终于到达了我们的自定义处理器。
以上,我们走完了一个item的处理过程。我们回过头来看一下,启动一个informer时的goroutine如下:
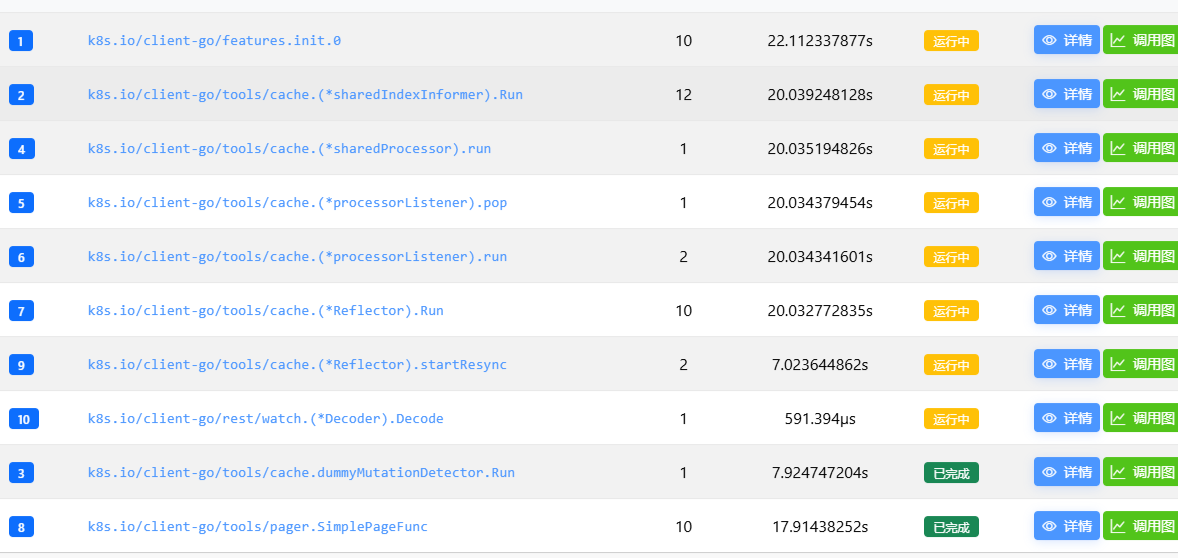
而startResync篇幅有限不在赘述,感兴趣的可以自己读一读;
总结
以上完成了对Informer数据流图中所有关键函数的详细解析,希望能为您的理解提供帮助。在接下来的文章中,我们将进一步探讨Indexer的实现原理,并深入研究其核心结构体的设计,请持续关注。
在Kubernetes(k8s)的设计中,为了追求代码的简洁性和执行效率,Informer机制广泛采用了接口抽象和多协程并发处理的方式。这种设计虽然有效提升了系统的灵活性与性能,但同时也增加了其复杂性,给初次接触该机制的学习者带来了较大的理解难度。
在此背景下,使用Delve(dlv)这样的调试工具进行代码跟踪和问题排查变得相对困难,因为需要对并发编程有深入的理解以及对Informer内部结构有所掌握才能有效利用这些工具。
你懂我意思,快来关注我的源码阅读神器:https://github.com/toheart/goanalysis。只要你能将程序跑起来,那么就你能够阅读源码!!!