本文介绍了如何将realsense-viewer录制的rosbag格式的视频导出成图片序列,方便合并成mp4视频或插入到论文中。
本文首发于❄慕雪的寒舍
说明
Intel提供的realsense-viewer软件录制的视频都是rosbag格式的,为了编写论文,需要从录制的视频中截取一两帧作为论文插图,所以需要使用工具把rosbag中的视频导出为图片。
最简单的方式肯定是直接rosplay播放bag里面的视频流然后使用image_view读取视频流然后截图,但是这个方式不太好,因为手动截图非常容易出现分辨率差异(框选的区域不一样),而且rosplay播放视频的时候不能暂停,也不好精确的截到自己想要的那张图片。
更好的方式是使用ros自带的工具把rosbag里面的视频流直接导出成图片序列,避免自己手动截图。在最终导出的图片序列里面选一两个插入到论文里面就ok了。
操作
首先,realsense-viewer录制的视频默认存放在用户的~/Documents文件夹里面,命名格式一般是今天的日期加上一串数字,比如20250331_172324.bag。首先要做的是确定我们需要的视频数据topic名称,使用如下命令查看
bash
rostopic list -b example.bag以我使用的RealSense D435为例,图像topic是下面这俩个,分别对应深度数据和RGB数据。我要的是RGB数据。
/device_0/sensor_1/Color_0/image/data
/device_0/sensor_0/Depth_0/image/data先使用另外一个终端A,开启roscore,然后在终端B里面执行如下命令,工具会在这个命令执行的目录中输出图片序列 。这个命令中使用了extract_images工具,并通过_sec_per_frame指定每0.01秒截取一张图片,通过image:=订阅的topic正是我需要的RGB图像topic。
bash
rosrun image_view extract_images \
_sec_per_frame:=0.01 \
image:=/device_0/sensor_1/Color_0/image/data再开启一个终端C,执行rosbag play命令来播放bag文件里面的视频,其中--topics选项用于列出我们想要广播的topic是谁。
bash
rosbag play exmaple.bag \
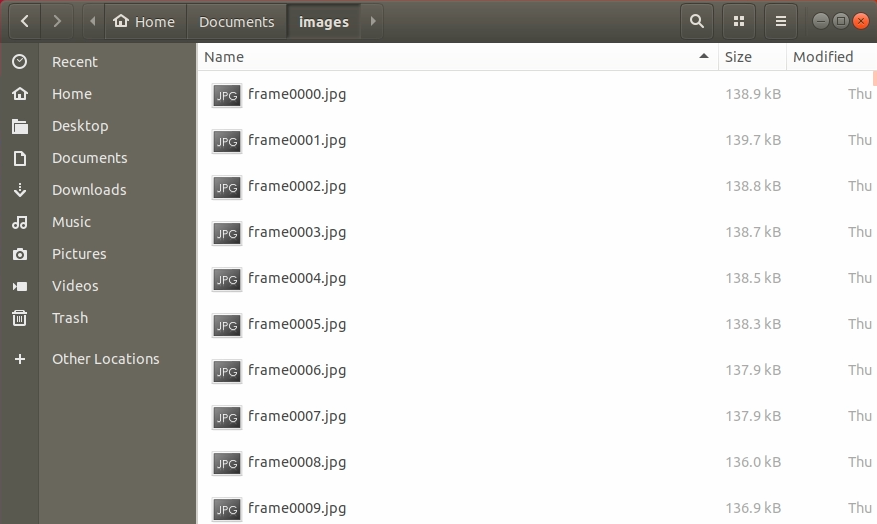
--topics /device_0/sensor_1/Color_0/image/data执行之后,extract_images工具就会自动从这个订阅的topic中截取视频流,输出到执行这个命令的PWD里面了,如下所示。图片文件的默认命名格式是frame%04.jpg,工具会自动命名序号。
king@ubuntu:~/Documents$ ls images/
frame0000.jpg frame0164.jpg frame0328.jpg frame0492.jpg frame0656.jpg
frame0001.jpg frame0165.jpg frame0329.jpg frame0493.jpg frame0657.jpg
...图片输出结果如下图所示:
注:如果你想把这些图片重新组成一个mp4格式的视频,可以用ffmpeg工具实现。
The end
至此,问题解决。