在 Oracle 数据库中,COUNT(1) 和 COUNT(*) 都用于统计表中的行数,但它们的语义和性能表现存在一些细微区别。
1. 语义区别
-
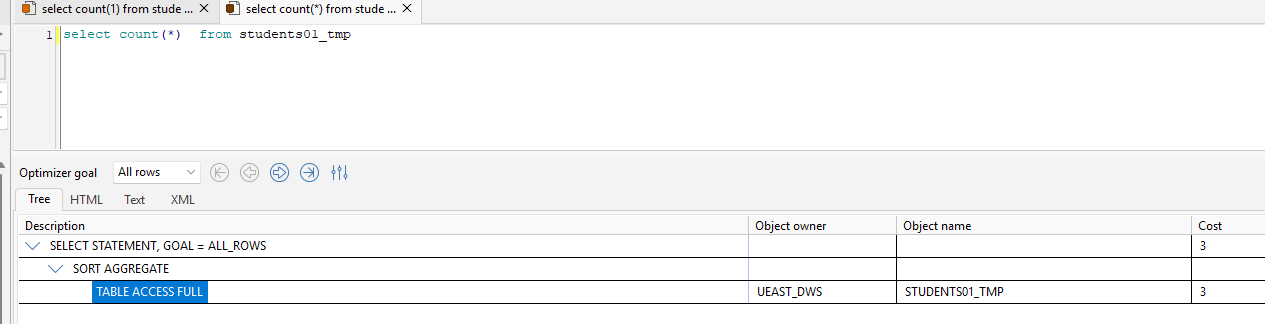
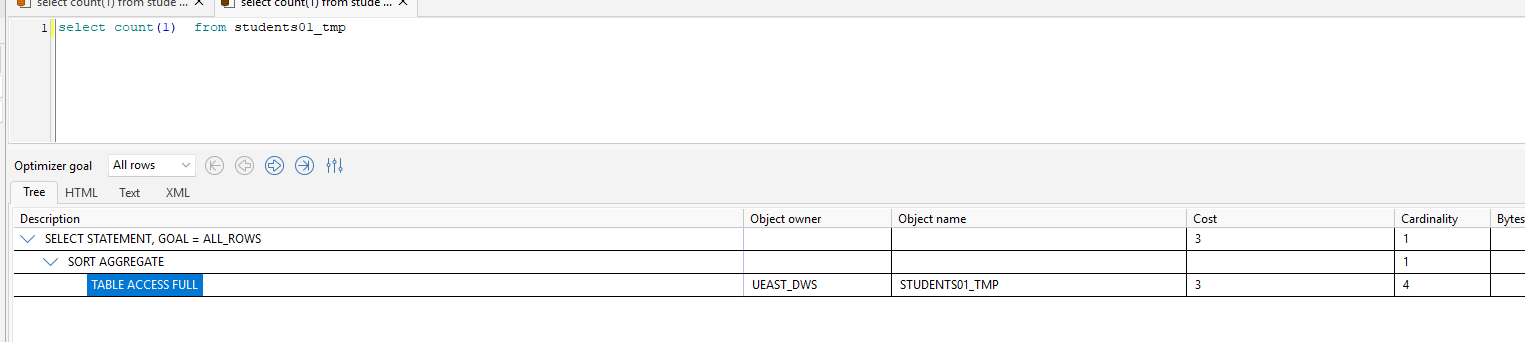
COUNT(*)统计表中所有行的数量,包括所有列值为
NULL的行。它直接针对表的行进行计数,不关心具体列的值。 -
COUNT(1)统计表中所有行的数量,同样包括所有列值为
NULL的行 。这里的1是常量表达式,对每一行进行求值。由于1永远非空,因此结果与COUNT(*)相同。
2. 性能区别
在 Oracle 中,两者的执行效率几乎完全相同,因为优化器会对它们进行等价处理:
-
对于大多数场景,
COUNT(*)和COUNT(1)会生成相同的执行计划(如全表扫描或索引快速全扫描)。 -
即使表中包含大量
NULL值,两者的性能也无差异,因为 Oracle 不会因为COUNT(*)需要检查所有列而降低效率。
3. 使用建议
-
推荐使用
COUNT(*):这是 SQL 标准中定义的行数统计方式,语义更明确(直接表示"统计所有行"),可读性更高。
-
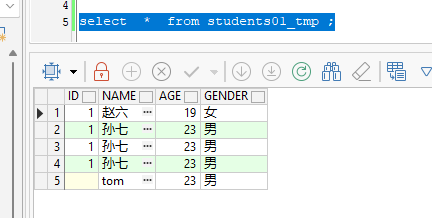
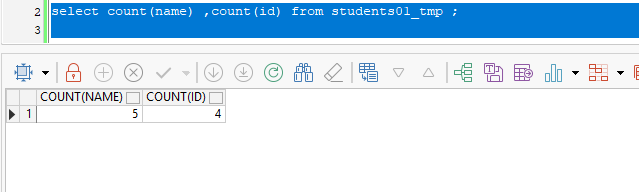
避免使用
COUNT(列名)(除非必要) :如果使用
COUNT(列名),会跳过该列为NULL的行,可能导致结果与预期不符。例如:
4 总结
| 对比项 | COUNT(*) |
COUNT(1) |
|---|---|---|
| 语义 | 统计所有行 | 统计所有行 |
| 性能 | 与 COUNT(1) 相同 |
与 COUNT(*) 相同 |
| 可读性 | 更高(符合 SQL 标准) | 稍低(依赖常量表达式) |
| 适用场景 | 通用行数统计 | 通用行数统计 |
在 Oracle 中,COUNT(*) 和 COUNT(1) 功能等价且性能一致 。推荐优先使用 COUNT(*) 以提高代码可读性,避免对 COUNT(1) 的过度依赖。