Spark
运行架构
Spark 框架的核心是一个计算引擎,整体来说,它采用了标准 master-slave 的结构。
如下图所示,它展示了一个 Spark 执行时的基本结构。图形中的 Driver 表示 master,负责管理整个集群中的作业任务调度。图形中的 Executor 则是 slave,负责实际执行任务。
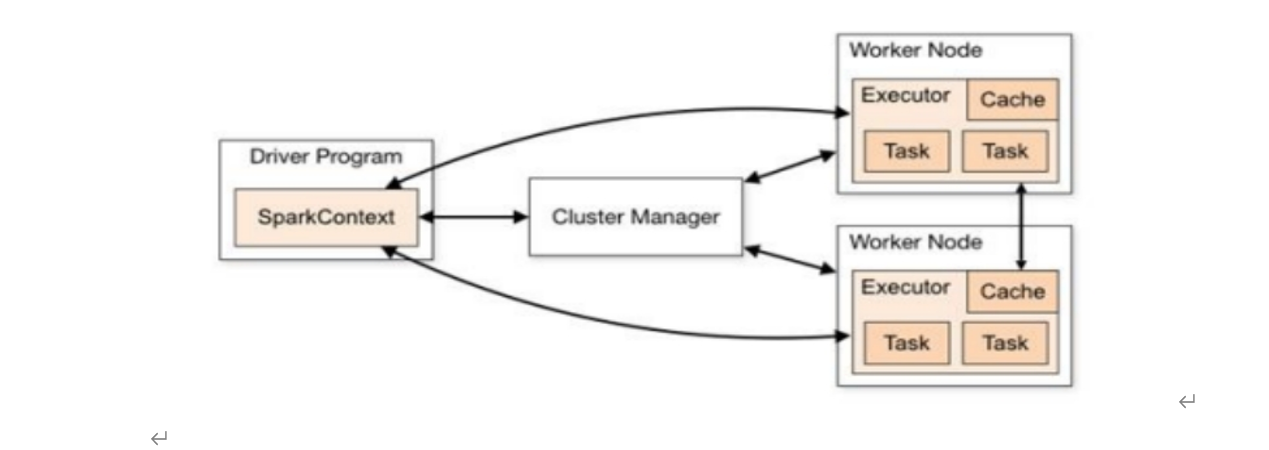
核心组件
Spark 框架有两个核心组件:
Driver
Spark 驱动器节点,用于执行 Spark 任务中的 main 方法,负责实际代码的执行工作。
Executor
Spark Executor 是集群中工作节点(Worker)中的一个 JVM 进程,负责在 Spark 作业中运行具体任务(Task),任务彼此之间相互独立。Spark 应用启动时,Executor 节点被同时启动,并且始终伴随着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃,Spark 应用也可以继续执行,会将出错节点上的任务调度到其他 Executor 节点上继续运行。
核心概念
Executor 与 Core
Spark Executor 是集群中运行在工作节点(Worker)中的一个 JVM 进程,是整个集群中的专门用于计算的节点。在提交应用中,可以提供参数指定计算节点的个数,以及对应的资源。这里的资源一般指的是工作节点 Executor 的内存大小和使用的虚拟 CPU 核(Core)数量。
应用程序相关启动参数如下:
提交流程:Spark应用在Yarn环境有Client和Cluster两种部署模式。Client模式下,Driver在本地机器运行,适用于测试;Cluster模式下,Driver在Yarn集群资源中执行,常用于生产环境。两种模式都需与ResourceManager通讯申请资源,启动ApplicationMaster和Executor,Executor注册完成后Driver执行main函数,遇到Action算子时划分stage并分发task执行。
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于处理不同的应用场景。三大数据结构分别是:
RDD : 弹性分布式数据集
累加器:分布式共享只写变量
广播变量:分布式共享只读变量
RDD
什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
核心属性
分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算。
RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系。
分区器(可选)
当数据为 K-V 类型数据时,可以通过设定分区器自定义数据的分区。
首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算。
RDD 序列化
执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
-
Spark 通过申请资源创建调度节点和计算节点
-
Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
-
调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
执行与序列化:在Yarn环境中,RDD将逻辑封装并生成Task供Executor计算。执行前会进行闭包检查,且Spark支持Kryo序列化框架提升性能,即便使用Kryo,相关对象仍需继承Serializable接口。
依赖与持久化:RDD通过血缘关系记录元数据和转换行为,用于恢复丢失分区。
依赖关系分窄依赖和宽依赖,据此划分阶段和任务。RDD可通过Cache或Persist缓存结果,也能利用CheckPoint将中间结果写入磁盘,两者在依赖、存储位置和可靠性上存在差异 。
分区与文件操作:Spark支持Hash、Range分区和自定义分区,仅Key-Value类型RDD有分区器。数据读取和保存可按文件格式(text、csv、sequence、object文件等)和文件系统(本地、HDFS、HBASE、数据库)区分,不同文件类型操作方式各异。
RDD 持久化
- RDD Cache 缓存
RDD 通过 Cache 或者 Persist 方法将前面的计算结果缓存,默认情况下会把数据以缓存在 JVM 的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的 action 算子时,该 RDD 将会被缓存在计算节点的内存中,并供后面重用。
RDD 分区器
Spark 目前支持 Hash 分区和 Range 分区,和用户自定义分区。
RDD 文件读取与保存
Spark 的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:text 文件、csv 文件、sequence 文件以及 Object 文件;
文件系统分为:本地文件系统、HDFS、HBASE 以及数据库。