前言
上一篇文章讲了一下如何搭建部署Dify平台,步骤比较简单,通过docker很快就搭建完成了。那么这一篇我们来看看如何使用Dify,它都有哪些功能。
添加模型
相对于FastGPT来说,Dify添加模型要方便的多。
点击平台右上角用户名部分,进入设置页面,第一项设置就是 模型供应商。
这里可以看到提供了市面上大部分模型,直接添加即可。
商业模型
比如百度文心,配置好API Key 和 Secret Key后,在最上方的模型列表中就可以看到文心一言的卡片了,点击最下面可以展开所有模型,直接启动想用的模型即可。

HuggingFace
单独说一下HuggingFace这个供应商,HuggingFace是一个开源社区(huggingface.co),这里面有非常多的免费模型。
获取API Key
首先注册登录,然后点击头像,选择Settings,在Access Tokens中创建一个新的token,这里注意要在下面User permissions中正确选择,否则会提示错误。如果使用Hosted Inference API 这个端点类型的话,就需要在inference中选中第一条,如下:
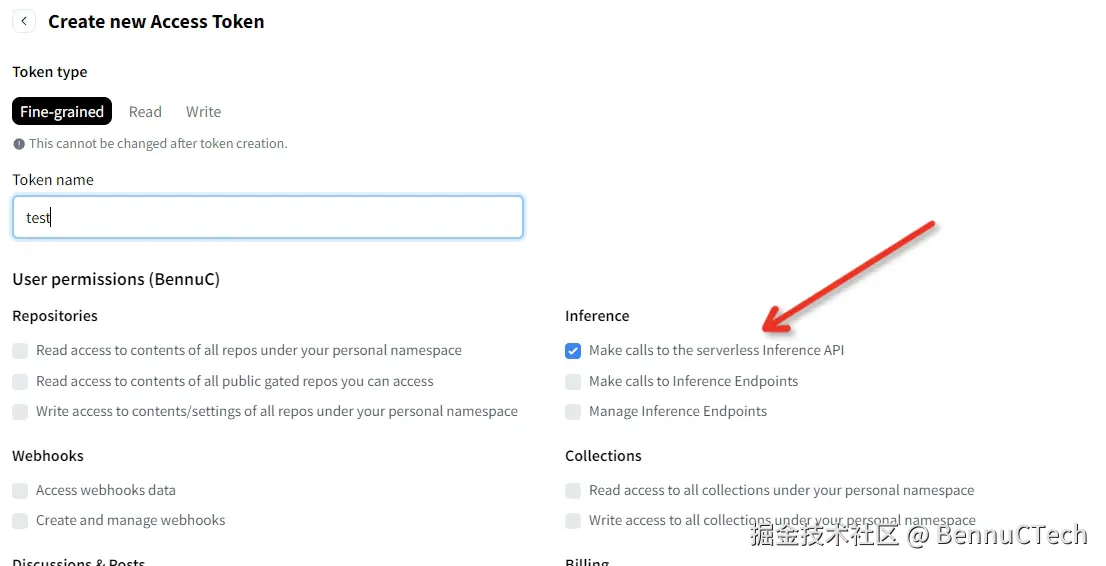
创建完Token复制保存好。
添加模型
在huggingface.co/models 中可以查看所有模型,在dify中添加模型的时候这个模型名称要注意是带着前面用户的,比如BAAI/bge-large-zh-v1.5
端点类型根据之前Token的设置来选择,推荐Hosted Inference API,因为简单一些,然后在API Token中填入刚才创建的Token即可。
如果报错404,错误是Please make sure you specified the correct repo_id and repo_type,说明模型名字不对,大概是没有带着前面的用户。
如果报错400,错误是Model xxx is not a valid task, must be one of xxx,说明模型的类型不对(比如选择Text Embedding,但是填入的是LLM模型),根据提示在huggingface中过滤一下选择正确的类型。
如果报错400,错误是Authorization header is correct, but the token seems invalid,大概率就是token的权限不对,没有开启对应的权限。
自有模型
而自己部署的模型,比如在Ollama上部署的,直接点击 添加模型,然后进行配置即可。
配置好 模型名称 和 基础URL(注意必须带 http:// 或 https:// ,否则报错),保存就可以在上方的模型列表中看到Ollama卡片了。同样点击最下面可以展开看到自己添加的模型。

如果要继续添加Ollama其他的模型,在卡片展开后点击 添加模型 就可以添加其他模型了。
TEI模型
这里单独说一下TEI上部署的模型,因为有些不同,Text Embeddings Inference是一个工具,用来部署向量模型,当然还支持其他类型的模型,比如rerank模型。
在TEI上部署完模型后在http://xxx:xxx/docs 下就可以看到接口文档,可以看到和其他平台或工具不一样,不需要模型名称,比如部署了一个rerank模型,直接用rerank接口(http://xxx:xxx/rerank )访问即可。所以在Dify上添加的时候也不一样。
在最新版本0.8.0的dify才支持Text Embeddings Inference这个供应商,老版本没有。
添加的时候注意,模型名称不能填真实的模型名称,而是填接口的路径,比如rerank模型就直接添rerank即可。而服务器地址就不用加路径了,这样才能正常访问。
OneApi
OneApi是一个模型管理和分发平台,在这个上面可以创建渠道,添加和管理其他平台的模型。使用它的优点在于可以隐藏自己商业模型的apikey,并且还能够进行费用管理。
这里说说在Dify中怎么使用OneApi上添加的模型。
在模型提供商列表中需要使用OpenAi-API-compatible这个,点击添加模型,填入信息。
这里模型名称必须跟OneApi中的模型名称一致
API key就是OneApi平台中的令牌
API endpoint URL就是OneApi的接口地址,如果是自己搭建的,OneApi平台的地址可能是http://xxx:3001 ,那么接口地址就是 http://xxx:3001/v1
然后保存就可以使用了。
注意,OneApi中多渠道可以有同名模型,这样的话使用的时候就会以负载均衡的方式来调用这些同名模型。如果想分开调用,可以通过模型重定向让模型有不同的名称。
系统模型设置
在页面右上角有 系统模型设置,在这里设置系统默认的各种模型。
注意如果是新添加的模型,可能需要刷新一下页面才会显示。
创建应用
在主页的 工作室 tab下可以创建应用。可以创建空白应用,也可以通过模板来创建,Dify提供了大量的模板。
Dify的应用有四种类型:聊天助手、文本生成应用、Agent和工作流。
这其中工作流就是自己配置流程,而文本生成应用和Agent就是固定的流程,简单配置就可以使用。
而聊天助手则分成两种:基础编排和工作流编排。
基础编排的聊天助手实际上跟Agent差不多,只不过Agent可以添加工具,实现稍微复杂一点的功能。
而工作流编排的聊天助手就可以使用工作流的各种功能,实现一个复杂流程的聊天助手。
聊天助手(基础编排)
创建一个基础编排的聊天助手,进去后就可以直接调试使用了。
在左边栏中可以配置提示语,变量和上下文。上下文中添加知识库,这个后面会说。
另外最下面可以看到还可以添加更多的功能,比如开场白、内容审查等。
这个很简单,就不细说了。
Agent
Agent跟基础编排的聊天助手差不多,就是多了一个 工具 的功能,可以添加工具来实现复杂的流程,比如Dify提供了很多现成的工具,也可以将自己实现的工作流发布成工具来使用。但是不能修改工具的内容,所以这里也不细说了。
聊天助手(工作流编排)
创建完就可以看到不同于上面两个的页面,是一个工作流编排的页面,默认三个环节:开始、LLM、直接回复,这就是一个简单的聊天助手。
我们可以在任意流程中添加新的节点,Dify提供了很多功能节点和工具,而且我们也可以自己定义工作流发布成工具来使用。
比如我们在开始和LLM之间添加一个 知识检索,然后选择一个知识库,如下:

这样就实现了一个基于知识库为上下文的聊天助手。
更多功能大家可以自己探索一下。
文本生成应用
根据提示生成文本,与基础编排的聊天助手类似,只不过不是会话。
工作流
使用各种节点和工具组成复杂的应用,里面有很多功能节点和工具,这个后面单独细说。
应用发布
应用创建完成后,点击右上角发布后,下拉可以看到有三种方式:运行、嵌入网站、访问api。
注意:工作流没有嵌入网站,多了一个批量运行,而且可以发布为工具,这样在其他应用中可以插入使用。
运行
聊天助手和Agent运行就是直接打开一个聊天页面,将这个页面的url分享出去,用户就可以直接进行聊天了。
文本生成运行则是一个文本生成页面,很简单,大家自己运行一下就知道了。
工作流运行则是一个类似文本生成页面,主要看输入是怎么配置的。
嵌入网站
Dify提供了三种方式可以将应用嵌入自己的网站中,如下
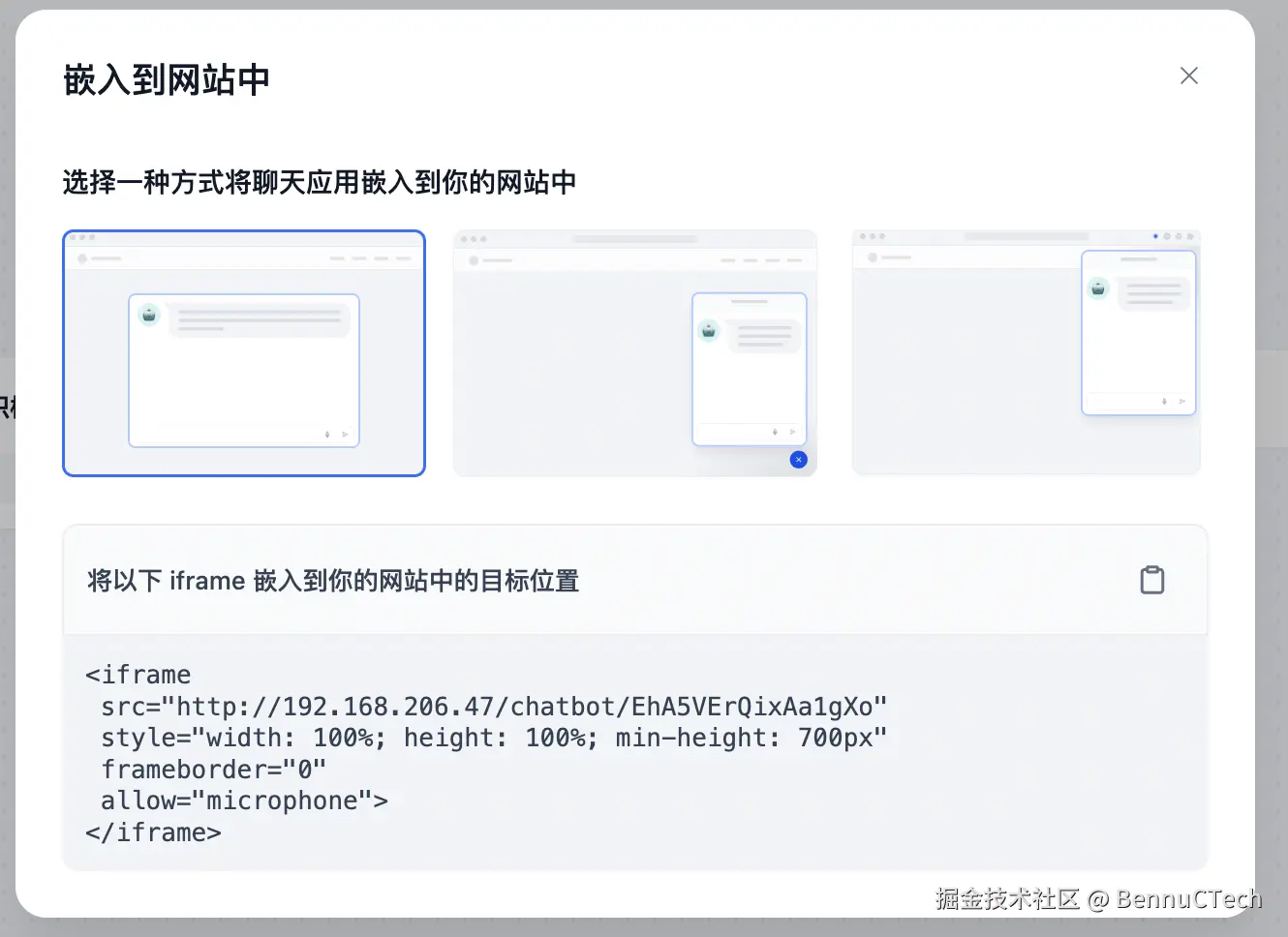
分别是iframe、js和浏览器扩展,这个大家试试就知道了。
访问api
发布后支持通过api来使用应用,其中聊天助手和Agent使用的是会话接口,文本生成应用和工作流有自己单独的一套接口。在应用左边栏第二个tab中可以查看对应的所有接口文档

在右上方可以看到API的根地址,通过这个地址来访问即可。
创建密钥
所有接口都是鉴权的,所以首先要创建密钥。在上图的右上角可以看到 API密钥,点进去创建一个密钥即可。
在应用中创建的这个密钥,只能用于访问这个应用。
发送对话消息
这个接口地址是/chat-messages,所以完整地址是http://xxx/v1/chat-messages,这个接口是Post的。
header
先在header中添加鉴权
css
Authorization: Bearer {API_KEY}这apiKey就是刚才生成的key
然后需要将content-type设置成json
bash
Content-Type: application/jsonRequest Body
请求结构大致如下
json
{
"inputs": {},
"query": "怎么退语文",
"response_mode": "streaming",
"conversation_id": "",
"user": "abc-123",
"files": []
}其中query就是用户的提问消息,response_mode来设置是否以流的形式返回。
其他参数参考文档即可。
Response
如果是流形式,注意返回的数据包括整个应用流程每个阶段的信息。下面是blocking形式的返回
json
{
"event": "message",
"task_id": "e4c5e57b-dacf-422a-914d-4678a6af49e5",
"id": "c8a69d62-7a9a-4dfe-8c4c-0d5631163084",
"message_id": "c8a69d62-7a9a-4dfe-8c4c-0d5631163084",
"conversation_id": "1baaf2fd-5084-4001-9751-1acdb2391b33",
"mode": "advanced-chat",
"answer": "家长你好,语文课非常重要,内容很丰富,不留着么",
"metadata": {},
"created_at": 1724837779
}一目了然,参考文档即可。
其他接口
其他接口这里就不一一细说了,大家参考API文档即可。
知识库
在主页的 知识库 tab页面中可以创建和管理知识库。
手动创建
点击创建知识库,支持三种数据源:文本、Notion、Web站点。还可以直接创建一个空知识库。
我们通过上传文本创建知识库,然后需要选择分段设置、索引方式和检索设置。其中索引方式选择高质量就会使用我们之前配置好的向量模型来进行索引。
注意这里还有一个是否使用QA分段,这个会影响分段的格式,如果使用整个知识库的分段都是问答形式,如果不使用都是一段文档的形式。
这里根据自己的需求进行配置即可,然后保存处理,就开始进行训练了。
后续可以继续添加文件来补充这个知识库。
点击文件里,可以手动添加分段。注意这里也可以更改是否使用QA分段,但是改完设置后之前添加的分段都会消失掉。
API
知识库也可以使用接口来管理,在 知识库 页面的 API tab下可以看到知识库相关的所有接口文档
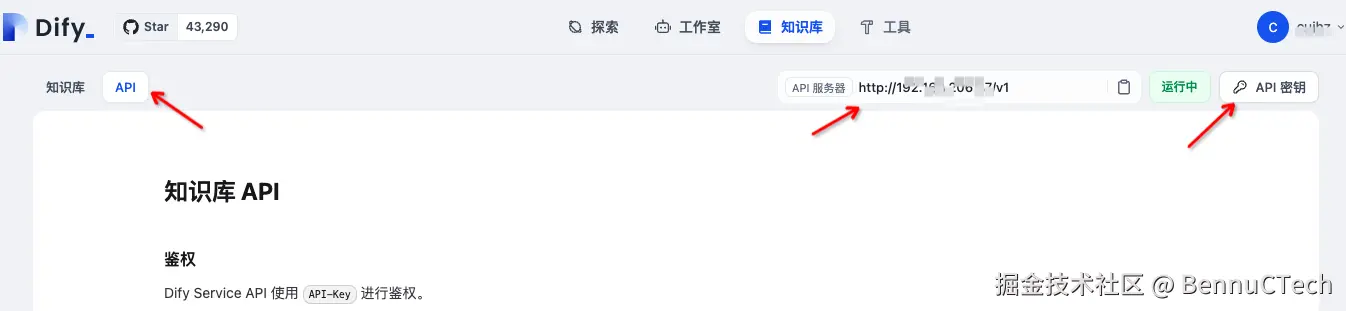
这里跟应用的类似,根地址是一样的,同样需要创建密钥,这里就不细说了。这个密钥只用来操作知识库。
接口使用也是一样的,需要添加鉴权和content-type,与上面一致。
下面以几个接口为例
创建知识库
接口地址是/datasets,注意是Post请求,用于创建一个空知识库,请求也很简单
json
{"name": "apitest"}就是知识库的名称,返回的数据中最重要的就是id,就是这个知识库的id,后续需要使用。
注意:在页面中是看不到这个id的,包括后面文档和片段id都在页面上看不到,如果想知道已有知识库id或文档id或片段id的话,可以在浏览器的开发者工具中查看网络请求的具体内容。这一点不是很方便。
获取知识库列表
接口地址同样是/datasets,但是是GET请求。
可以分页,有page和limit参数;
在官方API文档中就只有上面两个分页参数,但是在源码中可以看到还可以使用搜索词,字段是keyword;
还可以通过标签过滤,字段是tag_ids,注意这个后面不是一个列表,而是一个单独的tagId,如果要过滤多个tagId,需要添加多次,比如:
bash
http://xxxx/v1/datasets?tag_ids=1c8b011f-6e8d-47f7-b568-2dcebb7e83d0&tag_ids=bd5a0046-70a5-49f0-89a1-587a3a5838cb请求回来的数据如下:
json
{
"data": [
{
"id": "6bc4063c-ef7a-4a4e-9af7-2da94d0198c9",
"name": "空2",
"description": "",
"provider": "vendor",
"permission": "only_me",
"data_source_type": "upload_file",
"indexing_technique": "high_quality",
"app_count": 1,
"document_count": 1,
"word_count": 0,
"created_by": "1d722a62-0f6f-42eb-b579-3c4d388d5332",
"created_at": 1725436788,
"updated_by": "1d722a62-0f6f-42eb-b579-3c4d388d5332",
"updated_at": 1725863339,
"embedding_model": "mxbai-embed-large",
"embedding_model_provider": "ollama",
"embedding_available": true,
"retrieval_model_dict": {
"search_method": "semantic_search",
"reranking_enable": false,
"reranking_mode": null,
"reranking_model": {
"reranking_provider_name": "",
"reranking_model_name": ""
},
"weights": null,
"top_k": 2,
"score_threshold_enabled": false,
"score_threshold": 0.0
},
"tags": [
{
"id": "1c8b011f-6e8d-47f7-b568-2dcebb7e83d0",
"name": "test",
"type": "knowledge"
},
{
"id": "bd5a0046-70a5-49f0-89a1-587a3a5838cb",
"name": "test1",
"type": "knowledge"
}
]
}
],
"has_more": false,
"limit": 20,
"total": 1,
"page": 1
}基本通过字段名就清楚了,就不一一说了。
创建文档
可以通过文本创建文档,也可以通过文件创建文档,地址不一样,参考API文档即可。
这里用文本来创建一个空文档,地址是
/datasets/{dataset_id}/document/create_by_text
其中dataset_id就是知识库id,请求如下
json
{"name": "apitext","text": "","indexing_technique": "high_quality","process_rule": {"mode": "automatic"}}这里text如果是空的就会直接创建一个空文档。
注意这里官方文档里没有qa模式的字段,但是从源码上可以看到除了API文档中的字段还有其他字段,其中"doc_form"就是配置这个的,分"text_model"和"qa_model"两种,"qa_model"就是QA模式。
代码中可以看到还可以进行检索设置,完整的请求如下:
json
{
"name": "default.txt",
"text": "",
"indexing_technique": "high_quality",
"doc_form": "qa_model",
"doc_language": "Chinese",
"retrieval_model": {
"search_method": "semantic_search",
"reranking_enable": False,
"reranking_model": {"reranking_provider_name": "", "reranking_model_name": ""},
"top_k": 5,
"score_threshold_enabled": True,
"score_threshold": 0.5
},
"process_rule": {
"mode": "automatic"
}
}其中retrieval_model就是检索设置,其中包含rerank,score阀值等等。API文档中没有的字段都是可选的。
请求结果中的document下的id就是文档id,后续要用。
更新文档
同样是两种方式可以更新,这里不细说了。
但是要重点提醒一下,在API文档中file或者text不是必传的,但是只要请求这个接口就会重新触发文档的分段处理,所以如果文档中如果有手动添加的片段那么就会被全部删除。同时要注意在文档的分段设置页面,不论是否修改了设置,只有保存也会重新进行分段处理,收到添加的片段也会被全部删除。所以无论调用接口还是页面修改,都要非常谨慎
添加分段
添加分段的地址是
bash
/datasets/{dataset_id}/documents/{document_id}/segments其中dataset_id是知识库id,document_id是文档id。请求如下:
css
{"segments": [{"content": "语文课程怎么退","answer": "语文课程很重要,现在有优惠,建议保留","keywords": []}]}可以批量添加分段,这里content就是文本内容或问题
answer就是答案,但是注意在QA模式下才有用,在普通模式下它的值直接忽略了。
注意:虽然官方API中说keywords是非必填,但是必须有这个字段(可以是null),否则请求这接口就会报内部错误。
请求结果中会有分段id,后续更新分段要用。
更新分段
更新分段的地址是
bash
/datasets/{dataset_id}/documents/{document_id}/segments/{segment_id}这是个post,请求如下:
json
{"segment": {"content": "数学课程怎么退","answer": "数学课程很重要,现在有优惠,建议保留","keywords":null, "enabled": true}}注意这个接口是全量更新,所以如果只更新enabled,也需要其他字段保持与之前一致。
特别注意,当将enabled设为false的时候,keywords可以不用传;但是当设为true的时候必须传,否则接口不会报错,但是这个片段也不会启用,而且在页面中启用的时候会提示片段未完成,这个时候加上keywords再请求一次就好了。
其他接口
其他接口这里就不一一细说了,大家参考API文档即可。
节点和工具
在 工作流应用 和 工作流编排的聊天助手 中需要使用节点和工具来编排整个工作流程。其中节点是标准组件;而工具则是对外扩展的,Dify内置了很多工具可以直接使用,另外工作流应用还可以发表成工具来使用。
下面挑几个常用的节点说一下,其他的大家参考官方文档即可,都不太难上手。
知识检索
可以配置一个知识库,可以在知识库中检索,并根据设置(Top k 和 Score阀值)过滤检索结果输出。
注意:知识检索 的输出不能在 直接回复 中作为输入使用,但是可以用 模板转换 或 代码执行 等节点进行转换后输入 直接回复。
LLM
最核心的节点,通过大语言模型来进行回复。
除了配置模型,还可以配置上下文,比如将知识检索的结果当作上下文。但是注意,如果配置了上下文,需要在提示中填写上下文变量才行
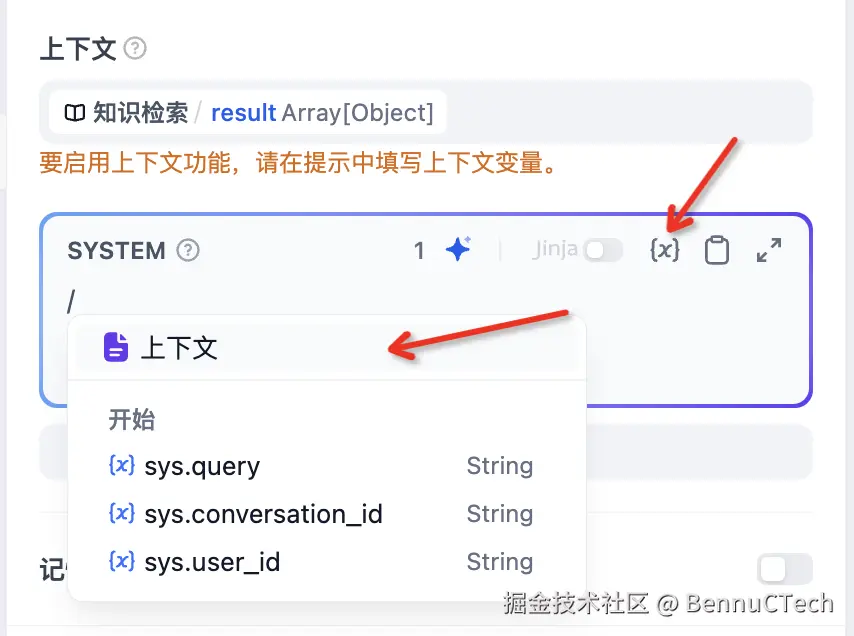
在工作流中这个节点是没有记忆功能的,在聊天助手中有记忆功能,可以将历史消息添加进prompt中,如下:
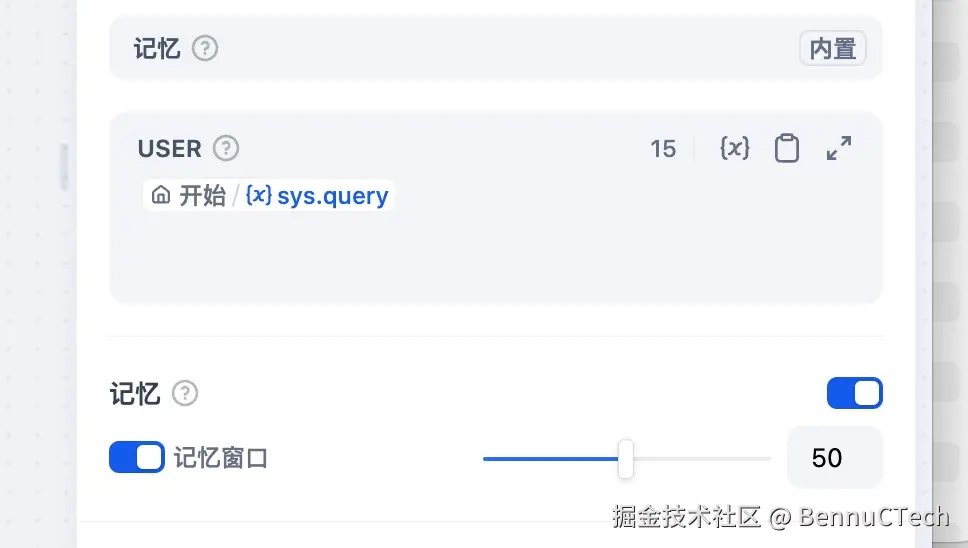
如图如果开启记忆,则会查询历史消息添加进prompt中。如果记忆窗口这个没打开,则后面的数量限制不生效,所以是无限制,但是dify内部有一个最大限制500,同时还有最大的token限制,所以并不是无限的。如果打开记忆窗口,则会根据后面配置的数量限制历史消息,同时也受最大token的限制。
代码执行
这个节点支持执行python或js代码,可以用来执行一些复杂的逻辑。
注意:最好是使用python,因为dify服务端是python实现的,这段代码也是由服务端执行的,所以用python执行速度会快很多。
最后
本文着重介绍会话相关的功能使用,至于文本生成、工作流大家可以参考官方文档来使用,基本思路都是差不多的。