Ansible-Playbook详解
- [1 Playbook介绍](#1 Playbook介绍)
-
- [1.1 Playbook概念](#1.1 Playbook概念)
- [1.2 Playbook组成](#1.2 Playbook组成)
- [2 Playbook组件](#2 Playbook组件)
-
- [2.1 hosts组件](#2.1 hosts组件)
- [2.2 tasks列表和task组件](#2.2 tasks列表和task组件)
- [2.3 remote_user组件](#2.3 remote_user组件)
- [2.4 ignore_errors组件](#2.4 ignore_errors组件)
- [2.5 handlers和notify组件](#2.5 handlers和notify组件)
- [2.6 tags组件](#2.6 tags组件)
- [3 Variables变量](#3 Variables变量)
-
- [3.1 使用 setup 模块中变量](#3.1 使用 setup 模块中变量)
- [3.2 register注册变量](#3.2 register注册变量)
- [3.3 在playbook命令行中定义变量](#3.3 在playbook命令行中定义变量)
- [3.4 在playbook文件中定义变量](#3.4 在playbook文件中定义变量)
- [3.5 playbook公共的变量文件](#3.5 playbook公共的变量文件)
- [3.6 在主机清单中定义主机和主机组的变量](#3.6 在主机清单中定义主机和主机组的变量)
- [3.7 针对当前项目的主机和主机组的变量](#3.7 针对当前项目的主机和主机组的变量)
- [4 Templates模板](#4 Templates模板)
- [5 流程控制](#5 流程控制)
-
- [5.1 循环迭代 loop](#5.1 循环迭代 loop)
- [5.2 条件判断 when](#5.2 条件判断 when)
- [5.3 分组 block](#5.3 分组 block)
- [5.4 changed_when](#5.4 changed_when)
- [5.5 滚动执行](#5.5 滚动执行)
- [5.6 委派至其它主机执行](#5.6 委派至其它主机执行)
- [5.7 只执行一次 run_once](#5.7 只执行一次 run_once)
- [5.8 yaml文件的相互调用](#5.8 yaml文件的相互调用)
- [6 Roles角色](#6 Roles角色)
1 Playbook介绍
1.1 Playbook概念
在 ansible 中,较简单的任务,我们可以直接调用单个模块来完成,但是,如果遇到复杂的需求,需要调用大量模块才能完成一个需求,或多个任务间有依赖的时候,使用单条命令就特别不方便,这种情况下,我们就可以使用 playbook 来实现这种需求
在 ansible 中,我们写好 playbook,服务器作演员,由服务器根据我们编排的剧本,完成环境安装,服务部署,系统搭建,状态检测等各种各样的功能。
playbook 文件规范
- 扩展名为 yaml 或 yml
- 第一行用
"---"(英文输入法下的中划线) 表示 yaml 的开始,一般不写,如果有多个 yaml 文件合并,则可用此标识每个 yaml 文件内容,使用#作为注释 - 大小写敏感
- 缩进符要统一,用空格键缩进,不要用 tab
- 缩进空格的数量不重要,但是,相同层级的左边缩进,要保持一致,要对齐,就是说,同样的缩进,代表同样的级别
- 使用
"-"(英文输入法下的中划线)+一个空格来表示单个列表项 - 使用
":"(冒号)+空格来表示一个键值对 - 使用
"{}"(花括号)来表示一个键值表 - 一个 name 只能有一个 task
1.2 Playbook组成
- 一个 playbook(剧本)文件是一个YAML语言编写的文本文件
- 通常一个playbook只包括一个play,但可以包括多个Play
- 一个play的主要包括两部分: 主机和tasks. 即实现在指定一组主机上执行一个tasks定义好的任务列表。
- 一个tasks中可以有一个或多个task任务
- 每一个Task本质上就是调用ansible的一个module
- 在复杂场景中,一个playbook中也可以包括多个play,实现对多组不同的主机执行不同的任务
2 Playbook组件
playbook 是由一个或多个 "play" 组成的列表。playbook 的主要功能在于,将多个 play 组织在一个playbook 文件中,让多台预定义的主机按照 playbook 中编排的内容来完成一系列复杂的功能。一个 playbook 至少要包含 name 和 tasks 两部份。
2.1 hosts组件
Hosts:playbook中的每一个play的目的都是为了让特定主机以某个指定的用户身份执行任务。hosts用于指定要执行指定任务的主机列表,须事先定义在主机清单中,其值可以是通配符,主机或组,可以用 -i 选项指定自定义的主机清单文件
yaml
- hosts: 10.0.0.206 #IP写法
- hosts: 192.168.1.* #通配符
- hosts: node.linux-magedu.com #主机名写法
- hosts: group1 #分组写法
- hosts: group1:group2 #分组写法,或者关系,两个分组并集
- hosts: group1:&group2 #分组写法,与关系,两个分组交集
- hosts: group1:!group2 #分组写法,非关系,两个分组差集2.2 tasks列表和task组件
tasks:定义要在远程主机上执行的任务列表,play的主体部分,各任务按顺序在 hosts 中指定的主机上执行,即所有主机做完当前任务,才会开始下一个任务。
task:执行指定模块,后面跟上预定的参数,参数中可以使用变量。每个task是一个字典,一个完整的代码块功能需最少元素需包括 name 和 task,一个name只能包括一个task
- 模块的执行是幂等的,这意味着多次执行是安全的,因为其结果均一致,如果在执行过程中发生错误,则会全部回滚(包括前面己执行成功的)
- 每个 task 都应该定义name,用于playbook的执行结果输出,建议其内容能清晰地描述任务执行步骤
- 如果没有指定 name ,则 action 的结果将用于输出
yaml
- hosts: group
tasks:
- name: test
command: id2.3 remote_user组件
remote_user:指定任务在远程主机上执行时所使用的用户,可以是任意用户,前提是用户是存在的,默认 root
- 可用于 Host 和 task 中。也可以通过指定其通过sudo的方式在远程主机上执行任务,其可用于play全局或某任务;此外,甚至可以在sudo时使用 sudo_user 指定sudo时切换的用户
- 可以全局指定,也可以在特定 task 中指定,切换用户执行需要先完成登录校验或者用 -k 选项手动输入ssh 密码
yaml
- hosts: group1 #指定主机分组
gather_facts: no #不收集主机信息
remote_user: tom #全局设置远程执行用户
tasks: #task列表
- name: task1 #task名称,此task以tom身份认行
shell: id #具体执行的模块和参数
- name: task2 #task名称,此task以jerry身份连接主机执行
shell: id #具体执行的模块和参数
remote_user: jerry
- name: task3 #task名称,此task以jerry身份运行sudo到root执行
shell: id #具体执行的模块和参数
remote_user: jerry
sudo: yes #默认sudo为root
- name: task4 #task名称,此task以jerry身份运行sudo到tom执行
shell: id #具体执行的模块和参数
remote_user: jerry
sudo: yes #默认sudo为root
sudo_user: tom #sudo为tom2.4 ignore_errors组件
在同一个 playbook中,如果一个task出错,默认将不会继续执行后续的其它 task
利用 ignore_errors: yes 可以忽略此task的错误,继续向下执行playbook其它 task,此项也可以配置为全局选项
yaml
- hosts: group
ignore_errors: yes # 全局配置
tasks:
- name: task-1
command: id1
ignore_errors: yes # 忽略此task的错误2.5 handlers和notify组件
notify 和 handlers:配合使用,某任务的状态在运行后为changed时,可通过"notify"通知给相应的 handlers 任务,可以达到一种触发调用的效果,(类似于函数调用或触发器),由特定条件触发的操作,满足条件方才执行,否则不执行
- handlers本质上也是 tasks,其中的 task 与前述的 task 并没有本质上的不同,只不过 handlers 中定义的 task,不会主动执行,只有notify关注的资源(task)发生变化时, notify去通知相应的handelrs,才会调用handler中定义的 task,没有改变则不会触发handlers
- handers中的 task,是在playbook的 tasks 中所有的 task 都执行完成之后才调用,就算多个task触发了相同的handlers, 此handlers也仅会在所有task结束后运行一次,这样是为了避免多次触发同一个hander
- handlers是在所有前面的 tasks 都成功执行才会执行,如果前面任何一个task失败,会导致handler跳过执行
范例:当文件发生变化时,重启服务
yaml
- hosts: rocky
tasks:
- name: config file
copy: src=/root/nginx_v2/linux.magedu.com.conf dest=/etc/nginx/conf.d/
notify: restart service #当配置文件发生了变化时,通知重启服务,与handlers的name相匹配
handlers:
- name: restart service
service: name=nginx state=restarted在 task 中使用 notify 来调用 handlers 中的任务,如果该 task 执行成功,但在该 task 之后的其它 task 执行失败,则会导致 notify 通知的 handlers 中的任务不会被调用,如果不论后面的task成功与否,都希望handlers能执行, 可以使用 force_handlers: yes 强制执行handler
force_handlers 是以整个 playbook 的角度来理解的,在 playbook 中,如果有 task 执行失败,那整个 playbook 也执行失败,就算后面有task,也不会继续执行,那么对应的handler也就不会执行了,所以force_handlers保证的是己成功执行的 task 对应的 handlers 一定会被执行。
yaml
- hosts: localhost
force_handlers: yes #force_handlers 可以保证handlers-1被执行,因为task-1任务执行成功
tasks:
- name: task-1
shell: echo "task-1"
notify: handlers-1
- name: task-2
shell: echoooooo "task-2"
notify: handlers-2 #task-2执行失败,handlers-2不会执行
- name: task-3
shell: echo "task-3"
notify: handlers-3 #因为task-2执行失败,playbook不会继续执行task-3,所以不论成功与否,handers-3都不会执行
handlers:
- name: handlers-1
debug: msg="handlers-1"
- name: handlers-2
debug: msg="handlers-2"
- name: handlers-3
debug: msg="handlers-3"2.6 tags组件
tags:还可以通过"tags"给 task 打标签,可在ansible-playbook命令上使用 -t 指定进行调用,定义哪些代码内容可以被忽略。ansible虽然具有幂等性,会自动跳过没有变化的部分,即便如此,有些代码为测试其确实没有发生变化的时间依然会非常地长。此时,如果确信其没有变化,就可以通过tags执行特定的 task
- 可以一个task对应多个tag,也可以多个task对应同一个tag
- 还有另外3个特殊关键字用于标签,tagged,untagged 和 all,tagged 表示所有被 tag 标记的任务,untagged 表示所有没有被标记的任务,all 表示所有任务。
yaml
- hosts: all
tasks:
- name: configure file
copy:
src: files/httpd.conf
dest: /etc/httpd/conf/
tags:
- conf3 Variables变量
Playbook中同样也支持变量,通过 variables 定义 playbook 运行时需要的使用的变量,有多种定义方式,内置变量或自定义变量
- 变量名:仅能由字母、数字和下划线组成,区分大小写,且只能以字母开头
- 变量定义:
variable=value或variable: value - 变量调用方式:通过
{``{ variable_name }}调用变量,且变量名前后建议加空格,有时用"{``{ variable_name }}"才生效
变量优先级(从高到低)):-e 选项定义变量 --> playbook中vars_files --> playbook中vars变量定义 --> host_vars/主机名文件 --> 主机清单中主机变量--> group_vars/主机组名文件 --> group_vars/all文件 --> 主机清单组变量
3.1 使用 setup 模块中变量
setup:默认会自动调用的模块,获取远程主机的一些信息都是放在 facts 变量中的,在playbook中,可以直接使用 gather_facts 选项来获得目标主机的信息,默认是yes
facts中所有可用变量请参考官方文档:ansible_facts
yaml
- hosts: rocky
gather_facts: yes
tasks:
- name: show-facts
debug: msg={{ ansible_facts }}
- name: show-facts-hostname
debug: msg={{ ansible_hostname }}
- name: show-facts-ipv4-A
debug: msg={{ ansible_facts["eth0"]["ipv4"]["address"] }}--{{ ansible_facts.eth0.ipv4.address }}
- name: show-facts-ipv4-B
debug: msg={{ ansible_eth0["ipv4"]["address"] }}--{{ ansible_eth0.ipv4.address }}
- name: show-facts-ipv4-C
debug: msg={{ ansible_default_ipv4["address"] }}--{{ ansible_default_ipv4.address }}每次执行playbook,默认会收集每个主机的所有facts变量,每次执行都需要消耗一定的资源和时间,在不需要facts变量时可以禁用该项 gather_facts: no 来加快 playbook 的执行效率。
如果又需要使用 facts 中的内容,还希望执行的速度快,这时候可以设置 facts 的缓存,可以在 ansible 的配置文件中设置在本地做缓存,也可以将 facts 变量信息存在 redis 服务器中,以便在频繁执行时减少资源消耗
bash
[defaults]
gathering=smart|implicit|explicit #facts策略,默认smart,新版默认implicit
fact_caching_timeout=86400 #本地缓存时长,默认86400S
fact_caching=memeory|jsonfile|redis #缓存类型,默认memory
fact_caching_connection=/path|REDIS #缓存路径或redis信息gathering 参数说明
- smart:远程主机信息如果有本地缓存,则使用缓存,如果没有,就去抓取,再存到缓存中,下次就直接使用缓存信息
- implicit:不使用缓存,每次都抓取新的,可以使用 gather_facts: no 来限制不去抓取新的
- explicit:不收集主机信息,除非在playbook中用 gather_facts: yes 显式指定
fact_caching 参数说明
- memeory:只在当前有效,下次还是要重新抓取
- jsonfile:本地缓存,
fact_caching_connection需要指定本地缓存路径 - redis:使用 redis 缓存,
fact_caching_connection的格式为REDIS_IP:REDIS_PORT:REDIS_DB_NUMBER[:REDIS_PASSWORD]
3.2 register注册变量
在playbook中可以使用register将捕获命令的输出保存在临时变量中,方便后续调用此变量,比如可以使用debug模块进行显示输出
yaml
- hosts: dbsrvs
tasks:
- name: get variable
shell: hostname
register: name
- name: "print variable"
debug:
msg: "{{ name }}" #输出register注册的name变量的全部信息,注意变量要加" "引起来
#msg: "{{ name.cmd }}" #显示命令
#msg: "{{ name.rc }}" #显示命令成功与否,相当于$?
#msg: "{{ name.stdout }}" #显示命令的输出结果为字符串形式,所有结果都放在一行里显示,适合于结果是单行输出
#msg: "{{ name.stdout_lines }}" #显示命令的输出结果为列表形式,逐行标准输出,适用于多行显示
#msg: "{{ name['stdout_lines'] }}" #显示命令的执行结果为列表形式,和效果上面相同
#msg: "{{ name.stdout_lines[0] }}" #显示命令的输出结果的列表中的第一个元素范例:修改主机名形式为 web_<随机字符>
yaml
- hosts: webservers
tasks:
- name: generate random
shell: openssl rand -base64 12 | tr -dc '[:alnum:]'
register: num
- name: show random
debug:
msg: "{{ num }}"
- name: change hostname
hostname:
name: web-{{ num.stdout }}3.3 在playbook命令行中定义变量
bash
#直接在命令行中指定
[root@ubuntu ~]# ansible-playbook -e uname=tom -e age=18 -e gender=M var1.yaml
#多个变量一次定义
[root@ubuntu ~]# ansible-playbook -e "uname=tom age=18 gender=M" var1.yaml
#从文件中读取
[root@ubuntu ~]# cat var.txt
uname: jerry
age: 20
gender: F
#文件前面要加 @
[root@ubuntu ~]# ansible-playbook -e "@/root/var.txt" var1.yaml
[root@ubuntu ~]# ansible-playbook -e "@./var.txt" var1.yaml3.4 在playbook文件中定义变量
此方式定义的是私有变量,即只能在当前playbook中使用,不能被其它Playbook共用
yaml
- hosts: webservers
remote_user: root
vars:
username: user1
groupname: group1
tasks:
- name: create group {{ groupname }}
group: name={{ groupname }} state=present
- name: create user {{ username }}
user: name={{ username }} group={{ groupname }} state=present范例:变量的相互调用
yaml
- hosts: webservers
vars:
suffix: "txt"
file: "{{ ansible_nodename }}.{{suffix}}"
tasks:
- name: test var
file: path="/data/{{file}}" state=touch3.5 playbook公共的变量文件
可以在一个独立的 yaml 文件中定义公共变量,在其它的playbook文件中可以引用变量文件中的变量
此方式比playbook中定义的变量优化级高
yaml
[root@ansible ~]#cat vars.yml
var1: httpd
var2: nginx
[root@ansible ~]#cat var.yml
- hosts: web
vars_files:
- vars.yml # 可以使用相对路径和绝对路径的写法
tasks:
- name: create httpd log
file: name=/app/{{ var1 }}.log state=touch
- name: create nginx log
file: name=/app/{{ var2 }}.log state=touch3.6 在主机清单中定义主机和主机组的变量
主机变量:在 inventory 主机清单文件中为指定的主机定义变量以便于在playbook中使用
bash
[webservers]
www1.wang.org http_port=80 maxRequestsPerChild=808
www2.wang.org http_port=8080 maxRequestsPerChild=909主机组变量:在inventory 主机清单文件中赋予给指定组内所有主机上的在playbook中可用的变量,如果和主机变量是同名,优先级低于主机变量
bash
[webservers]
10.0.0.8
10.0.0.18
[webservers:vars] # webservers组所拥有
ntp_server=ntp.wang.org
nfs_server=nfs.wang.org
[all:vars] # 所有主机所拥有
ntp_server=ntp.wang.org
nfs_server=nfs.wang.org3.7 针对当前项目的主机和主机组的变量
上面的方式是针对所有项目都有效,而官方更建议的方式是使用ansible特定项目的主机变量和组变量
生产建议在每个项目对应的目录中创建额外的两个变量目录,分别是host_vars和group_vars
- host_vars下面的文件名和主机清单主机名一致,针对单个主机进行变量定义
- 格式:host_vars/hostname
- group_vars下面的文件名和主机清单中组名一致,针对单个组进行变量定义
- 格式:group_vars/groupname
- group_vars/all 文件内定义的变量对所有组都有效
yaml
[root@ubuntu ~]#cat hostname.yaml
- hosts: all
tasks:
- name: change hostname
hostname: name=web-{{ id }}.{{ domain }}
[root@ubuntu ~]#cat /etc/ansible/hosts
[webserver]
10.0.0.8
10.0.0.18
[appserver]
10.0.0.28
10.0.0.38
[root@ubuntu ~]#cat host_vars/10.0.0.8
id: 8
[root@ubuntu ~]#cat host_vars/10.0.0.18
id: 18
[root@ubuntu ~]#cat host_vars/10.0.0.28
id: 28
[root@ubuntu ~]#cat host_vars/10.0.0.38
id: 38
[root@ubuntu ~]#cat group_vars/webserver
domain: wang.org
#不属于webserver组的使用
[root@ubuntu ~]#cat group_vars/all
domain: wu.org
[root@ubuntu ~]#ansible-playbook hostname.yaml
#最终结果是
[root@10.0.0.8 ~]#hostname
web-8.wang.org
[root@10.0.0.18 ~]#hostname
web-18.wang.org
[root@10.0.0.28 ~]#hostname
web-28.wu.org
[root@10.0.0.38 ~]#hostname
web-38.wu.org4 Templates模板
templates:模板模块,配合变量使用的模板文件,可以实现批量执行时,在不同主机上用同一个模板生成不同配置文件的功能,可替换模板文件中的变量并实现一些简单逻辑的文件,用于根据每个主机的不同环境而为生成不同的文件。模板文件中支持嵌套jinja2语言的指令,来实现变量、条件判断、循环等功能。
template文件建议存放在和 playbook 文件同级目录的 templates 目录下,且以 .j2 结尾,这样在 playbook 中使用模板文件时,就不需要指定模板文件的路径了。
范例:利用template生成不同的nginx配置文件
yaml
[root@ansible ~]#mkdir templates
[root@ansible ~]#vim templates/nginx.conf.j2
......
worker_processes {{ ansible_processor_vcpus*2 }}; #根据不同主机的CPU核数生成不同的配置
......
[root@ansible ~]#vim temnginx.yml
---
- hosts: webservers
remote_user: root
tasks:
- name: install nginx
yum: name=nginx
- name: template config to remote hosts
template: src=nginx.conf.j2 dest=/etc/nginx/nginx.conf
- name: start service
service: name=nginx state=started enabled=yestemplate中也可以使用流程控制 for 循环和 if 条件判断,实现动态生成文件功能
for 循环格式
python
{% for i in EXPR %}
...
{% endfor %}if 条件判断格式
python
#单分支
{% if EXPR %}
...
{% endif %}
#双分支
{% if EXPR %}
...
{% else %}
...
{% endif %}
#多分支
{% if EXPR %}
...
{% elif EXPR %}
...
{% else %}
...
{% endif %}playbook 文件 templnginx5.yml
yaml
- hosts: webservers
remote_user: root
vars:
nginx_vhosts:
- listen: 8080
root: "/var/www/nginx/web1/"
- listen: 8080
server_name: "web2.wang.org"
root: "/var/www/nginx/web2/"
- listen: 8080
server_name: "web3.wang.org"
root: "/var/www/nginx/web3/"
tasks:
- name: template config
template:
src: nginx.conf5.j2
dest: /data/nginx5.conf模版文件 templates/nginx.conf5.j2
python
{% for vhost in nginx_vhosts %}
server {
listen {{ vhost.listen }};
{% if vhost.server_name is defined %}
server_name {{ vhost.server_name }};
{% endif %}
root {{ vhost.root }};
}
{% endfor %}生成结果
bash
server {
listen 8080;
root /var/www/nginx/web1/;
}
server {
listen 8080;
server_name web2.wang.org;
root /var/www/nginx/web2/;
}
server {
listen 8080;
server_name web3.wang.org;
root /var/www/nginx/web3/;
}5 流程控制
5.1 循环迭代 loop
ansible 的 task 中,如果要重复执行相同的模块,则可以使用循环的方式来实现
对于迭代项的引用,要使用固定内置变量 item 来引用,这是固定写法。
范例:安装多个安装包
yaml
- hosts: webservers
tasks:
- name: Install Httpd and Php-fpm Package
yum:
name: "{{ item }}"
state: latest
loop:
- httpd
- php-fpm在迭代中,还可以嵌套子变量,关联多个变量在一起使用
范例:批量修改用户密码
yaml
- hosts: ssh-host
tasks:
- name: change user passwd
user:
name: "{{ item.name }}"
password: "{{ item.chpass | password_hash('sha512') }}"
update_password: always
loop:
- { name: 'root', chpass: '123456' }
- { name: 'app', chpass: '654321' }5.2 条件判断 when
可以实现条件测试。例如可以根据变量、facts或此前任务的执行结果来做为某task执行与否的前提,通过在task后添加when子句即可使用 jinja2 的语法格式条件测试
范例: 判断服务状态决定是否重新启动
yaml
- hosts: webservers
tasks:
- name: Check nginx Service
command: systemctl is-active nginx
ignore_errors: yes
register: check_nginx
- name: debug var
debug:
var: check_nginx
- name: Httpd Restart
service:
name: nginx
state: restarted
when: check_nginx.rc == 0 #如果nginx服务没启动,就重新启动
#failed_when: check_nginx.rc != 0 #条件不成立才执行,和when相反范例: 多条件判断写法
yaml
- hosts: all
tasks:
- name: "shut down CentOS 6 and Debian 7 systems"
shell:
cmd: /sbin/shutdown -h now
when: (ansible_facts['distribution'] == "CentOS" and ansible_facts['distribution_major_version'] == "6") or (ansible_facts['distribution'] == "Debian" and ansible_facts['distribution_major_version'] == "7")
- name: "shut down CentOS 7 systems"
shell: /sbin/shutdown -h now
when: # when的列表形式表示 and 关系
- ansible_facts['distribution'] == "CentOS"
- ansible_facts['distribution_major_version'] == "7"其他判断条件
- 操作系统版本判断的第二种写法:
ansible_distribution_file_variety == "Debian" - 操作系统主版本号判断的第二种写法:
ansible_distribution_major_version == "7" - 判断变量是否被定义:
name is undefined,name指定要判断的变量名 - 对主机名进行条件判断:
ansible_fqdn is match ("web*")
5.3 分组 block
当想在满足同样条件下,执行多个任务时,就需要分组。而不再针对每个任务都用相同的when来做条件判断
使用 block 可以对 task 任务进行分组,将多个 task 任务放到一个 block 下,可以在写一个 when 判断的情况下调用多个 task 任务
yaml
- hosts: localhost
tasks:
- block:
- debug: msg="first"
- debug: msg="second"
when:
- ansible_facts['distribution'] == "CentOS"
- ansible_facts['distribution_major_version'] == "8"
#相当于下面写法
- hosts: localhost
tasks:
- debug: msg="first"
when:
- ansible_facts['distribution'] == "CentOS"
- ansible_facts['distribution_major_version'] == "8"
- debug: msg="second"
when:
- ansible_facts['distribution'] == "CentOS"
- ansible_facts['distribution_major_version'] == "8"5.4 changed_when
第一个作用:关闭 changed 状态
只有在 task 的执行结果返回状态为 changed 的时候,我们才认为该 task 是真实执行了,在远程主机上产生了数据变化,但是在 ansible 中,不是所有模块都具有幂等性,对于某些不会产生数据变化的 task,ansible 也会给出 changed 输出。所以当确定某个task不会对被控制端产生数据变化时,而不想显示的是黄色的changed状态,可以通过 changed_when: false 来避免这一情况
yaml
- hosts: localhost
tasks:
- name: task-1
shell: id
changed_when: false第二个作用:自定义条件判断
Ansible 在执行任务之后,会依据任务的执行状况判断该任务是否使系统状态发生了改变,并且在输出结果里标记为 changed 或者 ok。不过,有时候 Ansible 默认的判断规则不符合我们的需求,这时就可以使用 changed_when 来自定义判断逻辑。
yaml
- hosts: webservers
tasks:
- name: check config
shell: /usr/sbin/nginx -t
register: check_nginx_config
changed_when: "'successful' in check_nginx_config.stdout" #自定义条件判断任务是否发生了变更5.5 滚动执行
默认情况下,Ansible将尝试并行管理playbook中所有的机器,如果一个 playbook 中有多个 task,在有多台远程主机的情况下,需要在所有远程主机上执行完当前的 task 之后才执行下一个 task,如果主机过多,或者需要执行的task 比较消耗时间,则会导致所有主机都处于一个执行中状态。如下图,先在 A,B,C 三台主机上执行 Task-1,再在三台主机上执行 Task-2
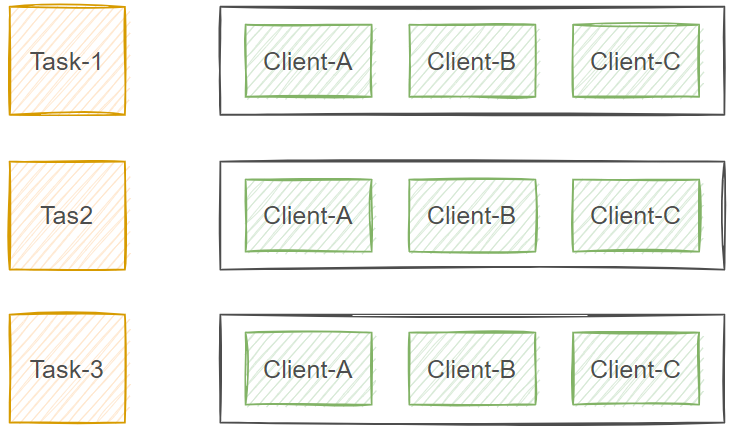
这样的话,在有些场景中是不利于的。比如升级场景,我们希望是先A主机执行完所有task,再到B主机依次执行,就不会导致所有主机都处于一个执行中状态,都无法对外提供服务。所以对于滚动更新用例,可以使用 serial 关键字定义Ansible一次应管理多少主机,还可以将 serial 关键字指定为百分比,表示每次并行执行的主机数占总数的比例
yaml
- hosts: all
serial: 2 #每次只同时处理2个主机
#serial: "20%" #每次只同时处理20%的主机
gather_facts: false
tasks:
- name: task one
command: hostname
- name: task two
command: hostname5.6 委派至其它主机执行
利用委托技术,可以在非当前被控主机的其它主机上执行指定操作,即可以在非指定的主机上执行 task,委派时必须要有key验证
范例:将任务委派给指定的主机执行
yaml
#在10.0.0.8上执行hostname -I,而非当前主机localhost
- hosts: localhost
tasks:
- name: show ip address
command: hostname -I
delegate_to: 10.0.0.8 #指定当前任务被委派给的目标主机
delegate_facts: true #收集被委派的目标主机的facts信息范例: 将任务被委派给控制端ansible主机执行
yaml
#在本地执行ifconfig,而非10.0.0.8,下面展示三种实现方式
- hosts: 10.0.0.8
tasks:
- name: show ip address
local_action: #旧语法,委派给控制端ansible主机执行
module: command
args: ifconfig
- name: show hostname
shell: hostname
connection: local #委派给控制端ansible主机执行
- name: kernel version
shell: uname -r
delegate_to: localhost #委派给控制端ansible主机执行5.7 只执行一次 run_once
利用 run_once 指令可以只执行一次,而非在所有被控主机都执行,通常会在第一个匹配的主机上执行该任务
yaml
- hosts: webservers
tasks:
- name: Run hostname command once
command: hostname
run_once: true5.8 yaml文件的相互调用
利用 include 或 include_tasks 可以在某个 task 中调用其它的只有 task 内容的 yaml 文件,include 在 2.16 版本之后被弃用,建议使用 include_tasks 来实现包含。include_tasks 一次只能引用一个 yaml 文件
注意:一个task只有一个include_tasks生效,也可以配合when和变量一起使用
yaml
#a.yml
- hosts: webservers
tasks:
- name: run a job
command: wall run a job
- name: excute b.yml
include_tasks: b.yml #调用b.yml执行task
#b.yml
- name: run b job
command: wall run b jobimport_playbook 合并多个 playbook 文件,将多个包含完整内容的 yaml 文件交由一个 yaml 统一调用
yaml
[root@ansible ansible]#cat main.yml
- import_playbook: tasks1.yml
- import_playbook: tasks2.yml
[root@ansible ansible]#cat tasks1.yml
- hosts: webservers
tasks:
- name: run task1 job
command: wall run task1 job
[root@ansible ansible]#cat tasks2.yml
- hosts: dbsrvs
tasks:
- name: run task2 job
command: wall run task2 job6 Roles角色
角色是ansible自1.2版本引入的新特性,用于层次性、结构化地组织playbook。roles能够根据层次型结构自动装载变量文件、tasks以及handlers等。要使用roles只需要在playbook中使用 include 指令即可。简单来讲,roles就是通过分别将变量、文件、任务、模板及处理器放置于单独的目录中,分门别类的管理起来,使其看起来更像一个项目,并可以便捷地 include 它们的一种机制,主要用来解决多文件之间的相互包含,引用,组合等问题
在Playbook中调用角色
一、直接调用
yaml
- hosts: webservers
remote_user: root
roles:
- mysql
- memcached
- nginx二、传参
键role用于指定角色名称,后续的k/v用于传递变量给角色
yaml
- hosts: all
remote_user: root
roles:
- role: mysql
username: mysql三、结合条件测试调用
yaml
- hosts: all
remote_user: root
roles:
- role: nginx
username: nginx
when: ansible_distribution_major_version == '7'四、结合tags调用
yaml
- hosts: appsrvs
remote_user: root
tags: app
roles:
- role: nginx
tags:
- nginx
- web五、依赖其它角色,在meta目录下编写与该role相关的依赖角色
yaml
dependencies:
- role: nginx
- role: php-fpm
- role: mysql