什么是Hive?
- Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化 数据文件映射为一张数据库表,基于表提供了一种类似SQL的查询模型,称为Hive查询语言(HQL),用于访问和 分析存储在Hadoop文件中的大型数据集。
- Hive核心是将HQL转换为MapReduce程序,然后将程序提交到Hadoop群集执行。
- Hive由Facebook实现并开源。
为什么使用****Hive?
- 使用Hadoop MapReduce直接处理数据所面临的问题,人员学习成本太高 需要掌握java语言,MapReduce实现复杂查询逻辑开发难度太大
- 使用Hive处理数据的好处:
1)操作接口采用 类 SQL 语法 ,提供快速开发的能力( 简单、容易上手 )
2)避免直接写MapReduce,减少开发人员的学习成本
3)支持自定义函数,功能扩展很方便
4)背靠Hadoop, 擅长存储分析海量数据集
- 使用Hive处理数据的好处:
Hive和Hadoop****关系
- 从功能来说,数据仓库软件,至少需要具备下述两种能力:存储数据的能力、分析数据的能力
- Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
Hive 利用 HDFS 存储数据,利用 MapReduce 查询分析数据 。
- Apache Hive作为一款大数据时代的数据仓库软件,当然也具备上述两种能力。只不过Hive并不是自己实现了上述两种能力,而是借助Hadoop。
- 这样突然发现Hive没啥用,不过是套壳Hadoop罢了。其实不然,Hive的最大的魅力在于 用户专注于编写HQL, Hive帮您转换成为MapReduce程序完成对数据的分析 。、
Apache Hive架构、组件

- 用户接口
包括 CLI、JDBC/ODBC、WebGUI。其中,CLI(command line interface)为shell命令行;Hive中的Thrift服务器允许 外部客户端通过网络与Hive进行交互,类似于JDBC或ODBC协议。WebGUI是通过浏览器访问Hive。 - 元数据存储
通常是存储在关系数据库如 mysql/derby中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。 - Driver 驱动程序,包括语法解析器、计划编译器、优化器、执行器
完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在 随后有执行引擎调用执行。 - 执行引擎
Hive本身并不直接处理数据文件。而是通过执行引擎处理。当下Hive支持MapReduce、Tez、Spark3种执行引擎。
Apache Hive安装部署
Apache Hive元数据
元数据(Metadata),又称中介数据、中继数据,为 描述数据的数据 (data about data),主要是描述数据属 性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
1. Hive Metadata
- Hive Metadata即Hive的元数据。
- 包含用Hive创建的database、table、表的位置、类型、属性,字段顺序类型等元信息。
- 元数据存储在关系型数据库中。如hive内置的Derby、或者第三方如MySQL等。
2**. Hive Metastore**
- Metastore即元数据服务。Metastore服务的作用是管理metadata元数据,对外暴露服务地址,让各种客户端通 过连接metastore服务,由metastore再去连接MySQL数据库来存取元数据。
- 有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码 ,只需要连接metastore 服务即可。某种程度上也保证了hive元数据的安全。
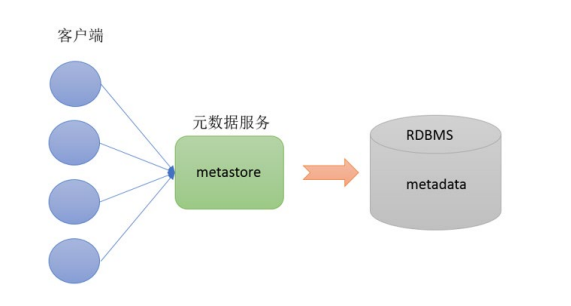
3**. metastore****配置方式**
- metastore服务配置有3种模式:内嵌模式、本地模式、远程模式。
- 区分3种配置方式的关键是弄清楚两个问题:1)Metastore服务是否需要单独配置、单独启动?2)Metadata是存储在内置的derby中,还是第三方RDBMS,比如MySQL。
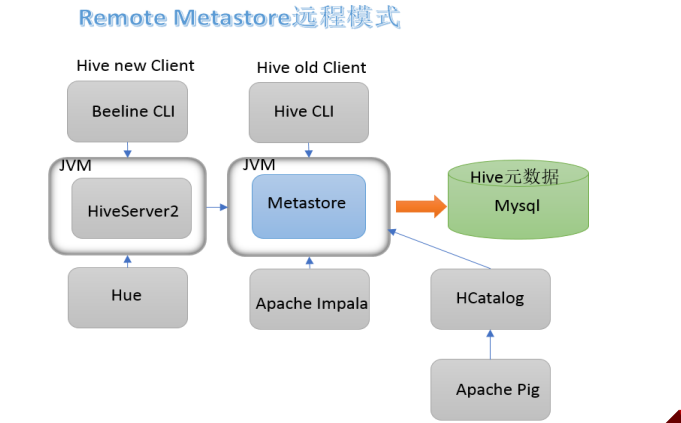
4. metastore****远程模式
在生产环境中,建议用远程模式来配置Hive Metastore。在这种情况下,其他依赖hive的软件都可以通过 Metastore访问hive。由于还可以完全屏蔽数据库层,因此这也带来了更好的可管理性/安全性。
Apache Hive部署实战
安装前准备
- 由于Apache Hive是一款基于Hadoop的数据仓库软件,通常部署运行在Linux系统之上。因此不管使用何种方式 配置Hive Metastore,必须要先保证服务器的基础环境正常,Hadoop集群健康可用。
- 服务器基础环境
集群时间同步、防火墙关闭、主机Host映射、免密登录、JDK安装 - Hadoop 集群健康可用
启动Hive之前必须先启动Hadoop集群。特别要注意,需 等待HDFS安全模式关闭之后再启动运行Hive 。
Hive不是分布式安装运行的软件,其分布式的特性主要借由Hadoop完成。包括分布式存储、分布式计算。
- 服务器基础环境
Hadoop与Hive****整合
- 因为Hive需要把数据存储在HDFS上,并且通过MapReduce作为执行引擎处理数据;
- 因此需要在Hadoop中添加相关配置属性,以满足Hive在Hadoop上运行。
- 修改Hadoop中core-site.xml,并且Hadoop集群同步配置文件,重启生效。
<!-- 整合 hive -->
< property >
< name >hadoop.proxyuser.root.hosts</ name >
< value >*</ value >
</ property >
< property >
< name >hadoop.proxyuser.root.groups</ name >
< value >*</ value >
</ property >
具体安装配置见文件如下:Hive3安装
Mysql安装
卸载Centos7自带的mariadb
[root@node3 ~]# rpm -qa|grep mariadb mariadb-libs-5.5.64-1.el7.x86_64 [root@node3 ~]# rpm -e mariadb-libs-5.5.64-1.el7.x86_64 --nodeps [root@node3 ~]# rpm -qa|grep mariadb [root@node3 ~]#安装mysql
mkdir /export/software/mysql #上传mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar 到上述文件夹下 解压 tar xvf mysql-5.7.29-1.el7.x86_64.rpm-bundle.tar #执行安装 yum -y install libaio [root@node3 mysql]# rpm -ivh mysql-community-common-5.7.29-1.el7.x86_64.rpm mysql-community-libs-5.7.29-1.el7.x86_64.rpm mysql-community-client-5.7.29-1.el7.x86_64.rpm mysql-community-server-5.7.29-1.el7.x86_64.rpm warning: mysql-community-common-5.7.29-1.el7.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY Preparing... ################################# [100%] Updating / installing... 1:mysql-community-common-5.7.29-1.e################################# [ 25%] 2:mysql-community-libs-5.7.29-1.el7################################# [ 50%] 3:mysql-community-client-5.7.29-1.e################################# [ 75%] 4:mysql-community-server-5.7.29-1.e################ ( 49%)mysql初始化设置
#初始化 mysqld --initialize #更改所属组 chown mysql:mysql /var/lib/mysql -R #启动mysql systemctl start mysqld.service #查看生成的临时root密码 cat /var/log/mysqld.log [Note] A temporary password is generated for root@localhost: o+TU+KDOm004修改root密码 授权远程访问 设置开机自启动
[root@node2 ~]# mysql -u root -p Enter password: #这里输入在日志中生成的临时密码 Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.29 Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> #更新root密码 设置为hadoop mysql> alter user user() identified by "root"; Query OK, 0 rows affected (0.00 sec) #授权 mysql> use mysql; mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION; mysql> FLUSH PRIVILEGES; #mysql的启动和关闭 状态查看 (这几个命令必须记住) systemctl stop mysqld systemctl status mysqld systemctl start mysqld #建议设置为开机自启动服务 [root@node2 ~]# systemctl enable mysqld Created symlink from /etc/systemd/system/multi-user.target.wants/mysqld.service to /usr/lib/systemd/system/mysqld.service. #查看是否已经设置自启动成功 [root@node2 ~]# systemctl list-unit-files | grep mysqld mysqld.service enabledCentos7 干净卸载mysql 5.7
#关闭mysql服务 systemctl stop mysqld.service #查找安装mysql的rpm包 [root@node3 ~]# rpm -qa | grep -i mysql mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #卸载 [root@node3 ~]# yum remove mysql-community-libs-5.7.29-1.el7.x86_64 mysql-community-common-5.7.29-1.el7.x86_64 mysql-community-client-5.7.29-1.el7.x86_64 mysql-community-server-5.7.29-1.el7.x86_64 #查看是否卸载干净 rpm -qa | grep -i mysql #查找mysql相关目录 删除 [root@node1 ~]# find / -name mysql /var/lib/mysql /var/lib/mysql/mysql /usr/share/mysql [root@node1 ~]# rm -rf /var/lib/mysql [root@node1 ~]# rm -rf /var/lib/mysql/mysql [root@node1 ~]# rm -rf /usr/share/mysql #删除默认配置 日志 rm -rf /etc/my.cnf rm -rf /var/log/mysqld.log
Hive的安装
上传安装包 解压
tar zxvf apache-hive-3.1.2-bin.tar.gz解决Hive与Hadoop之间guava版本差异
cd /export/server/apache-hive-3.1.2-bin/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/修改配置文件
cd /export/server/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.3.0 export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/libhive-site.xml
vim hive-site.xml
<configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>root</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> </property> <!-- 远程模式部署metastore metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration> 上传mysql jdbc驱动到hive安装包lib下
mysql-connector-java-5.1.32.jar初始化元数据
cd /export/server/apache-hive-3.1.2-bin/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表在hdfs创建hive存储目录(如存在则不用操作)
hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse==启动hive==
1、启动metastore服务
#前台启动 关闭ctrl+c /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore #前台启动开启debug日志 /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console #后台启动 进程挂起 关闭使用jps+ kill -9 nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &2、启动hiveserver2服务
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & #注意 启动hiveserver2需要一定的时间 不要启动之后立即beeline连接 可能连接不上3、beeline客户端连接
/export/server/apache-hive-3.1.2-bin/bin/beeline
beeline> ! connect jdbc:hive2://node1:10000
beeline> root
beeline> 直接回车
Apache Hive客户端使用
使用任何一种工具连接即可
HQL语法
1. 建库、删库语句
- 在Hive中,默认的数据库叫做default,存储数据位置位于HDFS的/user/hive/warehouse下。
- 用户自己创建的数据库存储位置是/user/hive/warehouse/database_name.db下。
-- 建库语句
CREATE ( DATABASE | SCHEMA ) IF NOT EXISTS database_nameCOMMENT database_comment
LOCATION hdfs_path
WITH DBPROPERTIES ( property_name =property_value, ...);
COMMENT:数据库的注释说明语句
LOCATION:指定数据库在HDFS存储位置,默认/user/hive/warehouse/dbname.db
WITH DBPROPERTIES:用于指定一些数据库的属性配置。
-- 删库
DROP ( DATABASE | SCHEMA ) IF EXISTS database_name RESTRICT | CASCADE ; 默认行为是RESTRICT,这意味着仅在数据库为空时才删除它。 要删除带有表的数据库(不为空的数据库),我们可以使用CASCADE 。
2. 建表语句
CREATE TABLE IF NOT EXISTS db_name. table_name
(col_name data_type COMMENT col_comment, ... )COMMENT table_comment
**ROW FORMAT DELIMITED ...** ;
蓝色字体 是建表语法的关键字,用于指定某些功能。
中括号的语法表示可选。
建表语句中的语法顺序要和语法树中顺序保持一致 。
最低限度必须包括的语法为: CREATE TABLE table_name (col_name data_type);
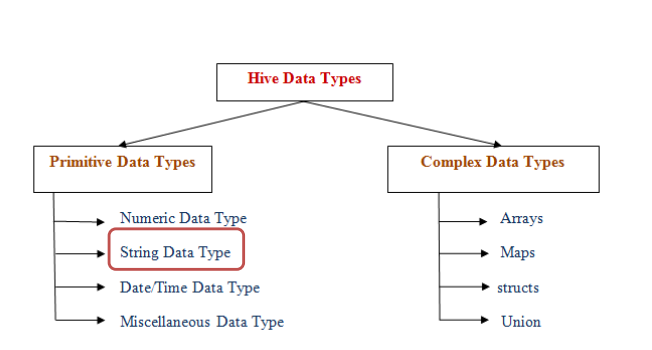
1)数据类型
- Hive数据类型指的是表中列的字段类型;
- 整体分为两类:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
- 最常用的数据类型是字符串String和数字类型Int。
2)指定分隔符
- ROW FORMAT DELIMITED语法用于指定字段之间等相关的分隔符,这样Hive才能正确的读取解析数据。
- 或者说只有分隔符指定正确,解析数据成功,我们才能在表中看到数据。
- LazySimpleSerDe是Hive默认的,包含4种子语法,分别用于 指定字段之间 、集合元素之间、map映射 kv之间、 换行的分隔符号 。
- 在建表的时候可以根据数据的特点灵活搭配使用。
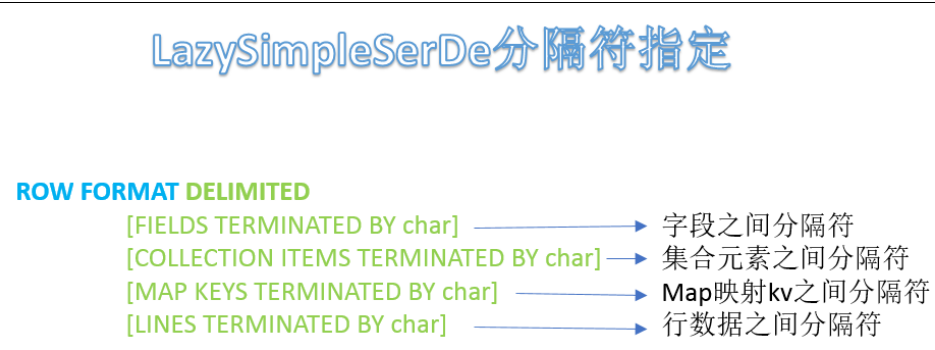
- Hive建表时如果没有row format语法指定分隔符,则采用默认分隔符;
- 默认的分割符是**'\001'**,是一种特殊的字符,使用的是ASCII编码的值,键盘是打不出来的。
- 在vim编辑器中,连续按下Ctrl+v/Ctrl+a即可输入'\001' ,显示^A
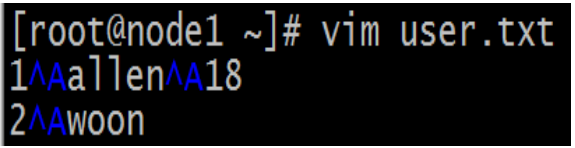
- 在一些文本编辑器中将以SOH的形式显示:

3)txt文件跟表数据的映射
- 建表成功之后,在Hive的默认存储路径下就生成了表对应的文件夹;
- 把表数据文件上传到对应的表文件夹下,使用sql查询语句就可以查出来了。
3. show语法
--1 、显示所有数据库 SCHEMAS 和 DATABASES 的用法 功能一样
show databases;
show schemas;
--2 、显示当前数据库所有表
show tables;
SHOW TABLES IN database_name ; -- 指定某个数据库
--3 、查询显示一张表的元数据信息
desc formatted t_team_ace_player ;
4. DML语法
1)load加载数据
所谓加载是指: 将数据文件移动到与Hive表对应的位置,移动时是纯 复制 、 移动 操作 。
纯复制、移动 指在数据load加载到表中时,Hive不会对表中的数据内容进行任何转换,任何操作。
LOAD DATA LOCAL INPATH 'filepath' OVERWRITE INTO TABLE tablename;
语法规则之 filepath
filepath 表示 待移动数据的路径 。可以指向文件(在这种情况下,Hive将文件移动到表中),也可以指向目录(在 这种情况下,Hive将把该目录中的所有文件移动到表中)。
filepath文件路径支持下面三种形式,要结合LOCAL关键字一起考虑:
- 相对路径,例如:project/data1
- 绝对路径,例如:/user/hive/project/data1
- 具有schema的完整URI ,例如:hdfs://namenode:9000/user/hive/project/data1
语法规则之 LOCAL
指定 LOCAL , 将在本地文件系统中查找文件路径并复制。- 若指定相对路径,将相对于用户的当前工作目录进行解释;
- 用户也可以为本地文件指定完整的URI-例如: file:///user/hive/project/data1 。
没有指定 LOCAL 关键字。- 如果filepath指向的是一个完整的URI,会直接使用这个URI;
- 如果没有指定schema,Hive会使用在hadoop配置文件中参数fs.default.name指定的(不出意外,都是HDFS,且是移动)
注意: 如果对HiveServer2服务运行此命令, 本地文件系统 指的是 Hiveserver2服务所在机器的本地Linux文件系统 ,不是Hive客户端所在的本地文件系统。
2)insert插入数据
使用标准的insert语句插入数据超级慢,推荐使用load加载数据。也可以使用insert语法把数据插入到指定的表中,最常用的配合是把查询返回的结果插入到另一张表中。
insert+select:
- 需要保证查询结果 列的数目 和需要插入数据表格的列数目 一致 。
- 如果查询出来的 数据类型 和插入表格对应的列数据类型不一致,将会进行转换,但是不能保证转换一定成功,转换 失败的数据将会为NULL。
INSERT INTO TABLE tablename select_statement1 FROM from_statement;
--step1: 创建一张源表 student
drop table if exists student ;
create table student ( num int , name string , sex string , age int , dept string )
row format delimited
fields terminated by ',' ;
-- 加载数据
load data local inpath '/root/hivedata/students.txt' into table student ;
--step2 :创建一张目标表 只有两个字段
create table student_from_insert ( sno int , sname string );
-- 使用 insert+select 插入数据到新表中
insert into table student_from_insert select num , name from student ;
select *
from student_insert1 ;
3)常规语法
ALL 、DISTINCT
-- 返回所有匹配的行
select state from t_usa_covid19 ;
-- 相当于
select all state from t_usa_covid19 ;
-- 返回所有匹配的行 去除重复的结果
select distinct state from t_usa_covid19 ;
-- 多个字段 distinct 整体去重
select distinct county , state from t_usa_covid19 ;
WHERE
在WHERE表达式中,可以使用Hive支持的任何函数和运算符,但聚合函数除外。
聚合操作
-- 统计美国总共有多少个县 county
select count ( county ) from t_usa_covid19 ;
-- 统计美国加州有多少个县
select count ( county ) from t_usa_covid19 where state = "California" ;
-- 统计德州总死亡病例数
select sum ( deaths ) from t_usa_covid19 where state = "Texas" ;
-- 统计出美国最高确诊病例数是哪个县
select max ( cases ) from t_usa_covid19 ;
GROUP BY
-- 根据 state 州进行分组 统计每个州有多少个县 county
select count ( county ) from t_usa_covid19 where count_date = "2021-01-28" group by state ;
-- 想看一下统计的结果是属于哪一个州的
select state , count ( county ) from t_usa_covid19 where count_date = "2021-01-28" group by state ;
-- 再想看一下每个县的死亡病例数,我们猜想很简单呀
把 deaths 字段加上返回
真实情况如何呢?
select state , count ( county ) , deaths from t_usa_covid19 where count_date = "2021-01-28" group by state ;
-- 很尴尬 sql 报错了 org.apache.hadoop.hive.ql.parse.SemanticException:Line 1:27 Expression not in GROUP BY key 'deaths'
-- 为什么会报错?? group by 的语法限制
-- 结论:出现在 GROUP BY 中 select_expr 的字段:要么是 GROUP BY 分组的字段;要么是被聚合函数应用的字段。
--deaths 不是分组字段 报错
--state 是分组字段 可以直接出现在 select_expr 中
-- 被聚合函数应用
select state , count ( county ) , sum ( deaths ) from t_usa_covid19 where count_date = "2021-01-28" group by state ;
HAVING
在SQL中增加HAVING子句原因是,WHERE关键字无法与聚合函数一起使用。
HAVING子句可以让我们筛选分组后的各组数据,并且可以在Having中使用聚合函数,因为此时where,group by 已经执行结束,结果集已经确定 。
--6 、 having
-- 统计 2021-01-28 死亡病例数大于 10000 的州
select state , sum ( deaths ) from t_usa_covid19 where count_date = "2021-01-28" and sum ( deaths ) > 10000 group by state ;
--where 语句中不能使用聚合函数 语法报错
-- 先 where 分组前过滤,再进行 group by 分组, 分组后每个分组结果集确定 再使用 having 过滤
select state , sum ( deaths ) from t_usa_covid19 where count_date = "2021-01-28" group by state having sum ( deaths ) > 10000 ;
-- 这样写更好 即在 group by 的时候聚合函数已经作用得出结果 having 直接引用结果过滤 不需要再单独计算一次了
select state , sum ( deaths ) as cnts from t_usa_covid19 where count_date = "2021-01-28" group by state having cnts> 10000 ;
HAVING 与 WHERE 区别
- having是在分组后对数据进行过滤
- where是在分组前对数据进行过滤
- having后面可以使用聚合函数
- where后面不可以使用聚合函数
ORDER BY
-- 根据确诊病例数升序排序 查询返回结果
select * from t_usa_covid19 order by cases ;
-- 不写排序规则 默认就是 asc 升序
select * from t_usa_covid19 order by cases asc;
-- 根据死亡病例数倒序排序 查询返回加州每个县的结果
select * from t_usa_covid19 where state = "California" order by cases desc;
LIMIT
-- 没有限制返回 2021.1.28 加州的所有记录
select * from t_usa_covid19 where count_date = "2021-01-28" and state = "California" ;
-- 返回结果集的前 5 条
select * from t_usa_covid19 where count_date = "2021-01-28" and state = "California" limit 5 ;
-- 返回结果集从第 1 行开始 共 3 行
select * from t_usa_covid19 where count_date = "2021-01-28" and state = "California" limit 2 , 3 ;
-- 注意 第一个参数偏移量是从 0 开始的
执行顺序
在查询过程中执行顺序: from > where > group (含聚合) > having >order > select ;
- 聚合语句(sum,min,max,avg,count)要比having子句优先执行
- where子句在查询过程中执行优先级别优先于聚合语句(sum,min,max,avg,count)
结合下面SQL:
-- 执行顺序
select state , sum ( deaths ) as cnts from t_usa_covid19
where count_date = "2021-01-28"
group by state
having cnts> 10000
limit 2 ;
4)JOIN关联查询
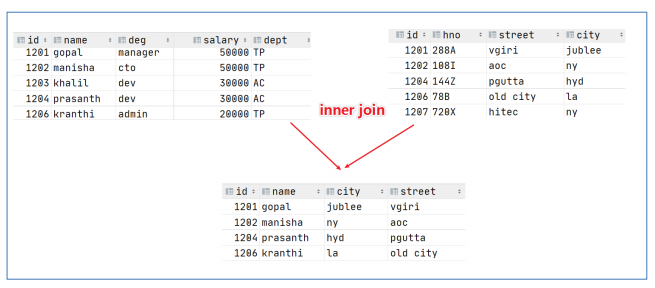
inner join内连接
内连接 是最常见的一种连接,它也被称为普通连接,其中inner可以省略: inner join == join ;
只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。
--1 、 inner join
select e. id , e. name , e_a. city , e_a. street
from employee e inner join employee_address e_a
on e. id =e_a. id ;
-- 等价于 inner join=join
select e. id , e. name , e_a. city , e_a. street
from employee e join employee_address e_a
on e. id =e_a. id ;
-- 等价于 隐式连接表示法
select e. id , e. name , e_a. city , e_a. street
from employee e , employee_address e_a
where e. id =e_a. id ;
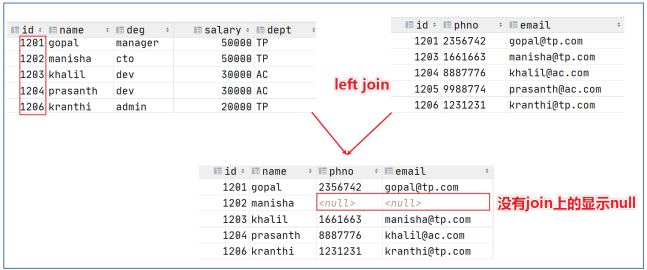
left join 左连接
- left join中文叫做是左外连接(Left Outer Join)或者左连接,其中outer可以省略,left outer join是早期的写法。
- eft join的核心就在于left左。左指的是join关键字左边的表,简称左表。
- 通俗解释:join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上 的显示null返回。
--2 、 left join
select e. id , e. name , e_conn. phno , e_conn. email
from employee e left join employee_connection e_conn
on e. id =e_conn. id ;
-- 等价于 left outer join
select e. id , e. name , e_conn. phno , e_conn. email
from employee e left outer join employee_connection e_conn
on e. id =e_conn. id ;
5)Hive 函数概述及分类标准
概述
Hive内建了不少函数,用于满足用户不同使用需求,提高SQL编写效率:
- 使用 show functions 查看当下可用的所有函数;
- 通过 describe function extended funcname 来查看函数的使用方式。
分类标准
Hive的函数分为两大类: 内置函数 (Built-in Functions)、 用户定义函数 UDF (User-Defined Functions): - 内置函数可分为:数值类型函数、日期类型函数、字符串类型函数、集合函数、条件函数等;
- 用户定义函数根据输入输出的行数可分为3类:UDF、UDAF、UDTF。
用户定义函数 UDF 分类标准
根据函数输入输出的行数:
UDF (User-Defined-Function)普通函数,一进一出
UDAF (User-Defined Aggregation Function)聚合函数,多进一出
UDTF (User-Defined Table-Generating Functions)表生成函数,一进多出
UDF 分类标准扩大化
UDF分类标准本来针对的是用户自己编写开发实现的函数。 UDF分类标准可以扩大到Hive的所有函数中:包括内置
函数和用户自定义函数 。
因为不管是什么类型的函数,一定满足于输入输出的要求,那么从输入几行和输出几行上来划分没有任何问题。
千万不要被UD(User-Defined)这两个字母所迷惑,照成视野的狭隘。
比如Hive官方文档中,针对聚合函数的标准就是内置的UDAF类型
内置函数
内置函数( build-in ) 指的是Hive开发实现好,直接可以使用的函数,也叫做内建函数。
官方文档地址: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
内置函数根据应用归类整体可以分为8大种类型,我们将对其中重要的,使用频率高的函数使用进行详细讲解。
-------------------------------------------常用内置函数----------------------------------------------
------------String Functions 字符串函数 ------------
select length ( "itcast" ) ;
select reverse ( "itcast" ) ;
select concat ( "angela" , "baby" ) ;
-- 带分隔符字符串连接函数: concat_ws(separator, string \| array(string)+)
select concat_ws ( '.' , 'www' , array ( 'itcast' , 'cn' )) ;
-- 字符串截取函数: substr(str, pos, len) 或者 substring(str, pos, len)
select substr ( "angelababy" , - 2 ) ; --pos 是从 1 开始的索引,如果为负数则倒着数
select substr ( "angelababy" , 2 , 2 ) ;
-- 分割字符串函数 : split(str, regex)
select split ( 'apache hive' , ' ' ) ;
----------- Date Functions 日期函数 -----------------
-- 获取当前日期 : current_date
select current_date () ;
-- 获取当前 UNIX 时间戳函数 : unix_timestamp
select unix_timestamp () ;
-- 日期转 UNIX 时间戳函数 : unix_timestamp
select unix_timestamp ( "2011-12-07 13:01:03" ) ;
-- 指定格式日期转 UNIX 时间戳函数 : unix_timestamp
select unix_timestamp ( '20111207 13:01:03' , 'yyyyMMdd HH:mm:ss' ) ;
--UNIX 时间戳转日期函数 : from_unixtime
select from_unixtime ( 1618238391 ) ;
select from_unixtime ( 0 , 'yyyy-MM-dd HH:mm:ss' ) ;
-- 日期比较函数 : datediff 日期格式要求 'yyyy-MM-dd HH:mm:ss' or 'yyyy-MM-dd'
select datediff ( '2012-12-08' , '2012-05-09' ) ;
-- 日期增加函数 : date_add
select date_add ( '2012-02-28' , 10 ) ;
-- 日期减少函数 : date_sub
select date_sub ( '2012-01-1' , 10 ) ;
----Mathematical Functions 数学函数 -------------
-- 取整函数 : round 返回 double 类型的整数值部分 (遵循四舍五入)
select round ( 3.1415926 ) ;
-- 指定精度取整函数 : round(double a, int d) 返回指定精度 d 的 double 类型
select round ( 3.1415926 , 4 ) ;
-- 取随机数函数 : rand 每次执行都不一样 返回一个 0 到 1 范围内的随机数
select rand () ;
-- 指定种子取随机数函数 : rand(int seed) 得到一个稳定的随机数序列
select rand ( 3 ) ;
-----Conditional Functions 条件函数 ------------------
-- 使用之前课程创建好的 student 表数据
select * from student limit 3 ;
--if 条件判断 : if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select if ( 1 = 2 , 100 , 200 ) ;
select if ( sex = ' 男 ' , 'M' , 'W' ) from student limit 3 ;
-- 空值转换函数 : nvl(T value, T default_value)
select nvl ( "allen" , "itcast" ) ;
select nvl ( null, "itcast" ) ;
-- 条件转换函数 : CASE a WHEN b THEN c WHEN d THEN e* ELSE f END
select case 100 when 50 then 'tom' when 100 then 'mary' else 'tim' end;
select case sex when ' 男 ' then 'male' else 'female' end from student limit 3 ;