目标是根据pdf文档生成问答,并进行评估。
首先,安装依赖
pip install PyPDF2 pandas tqdm openai -q
具体过程如下:
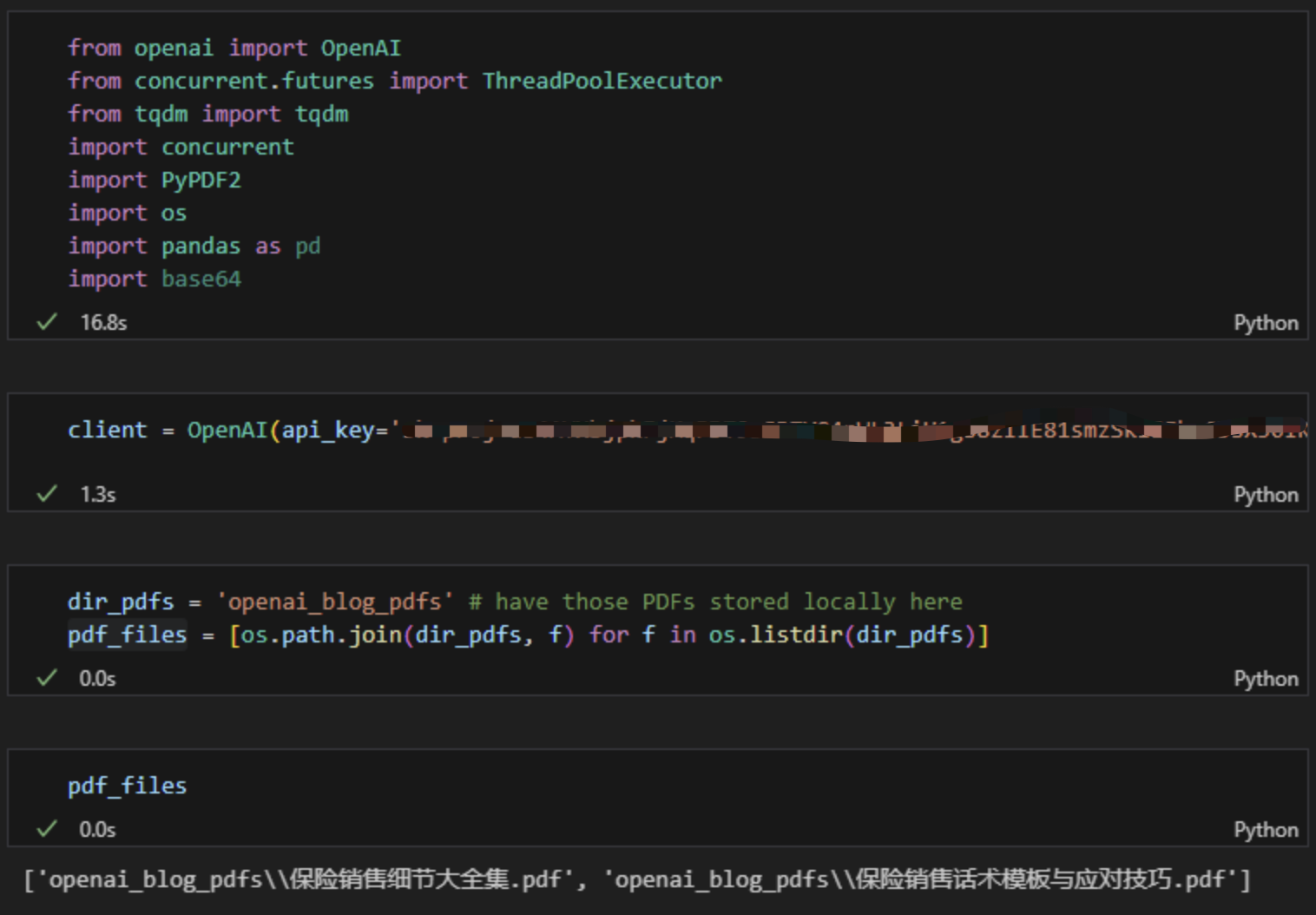
1、将pdf放在opeai_blog_pdfs目录下,引用依赖
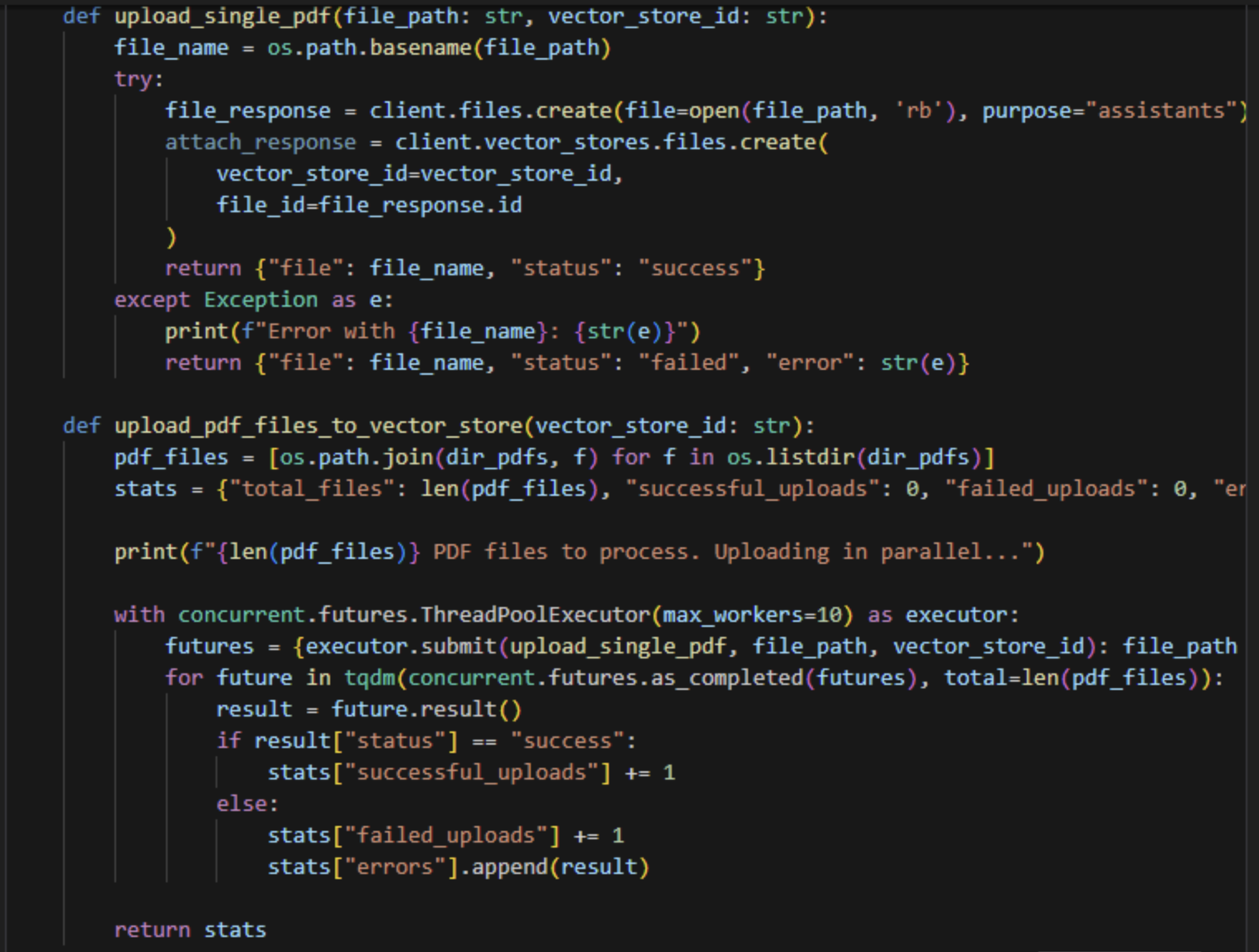
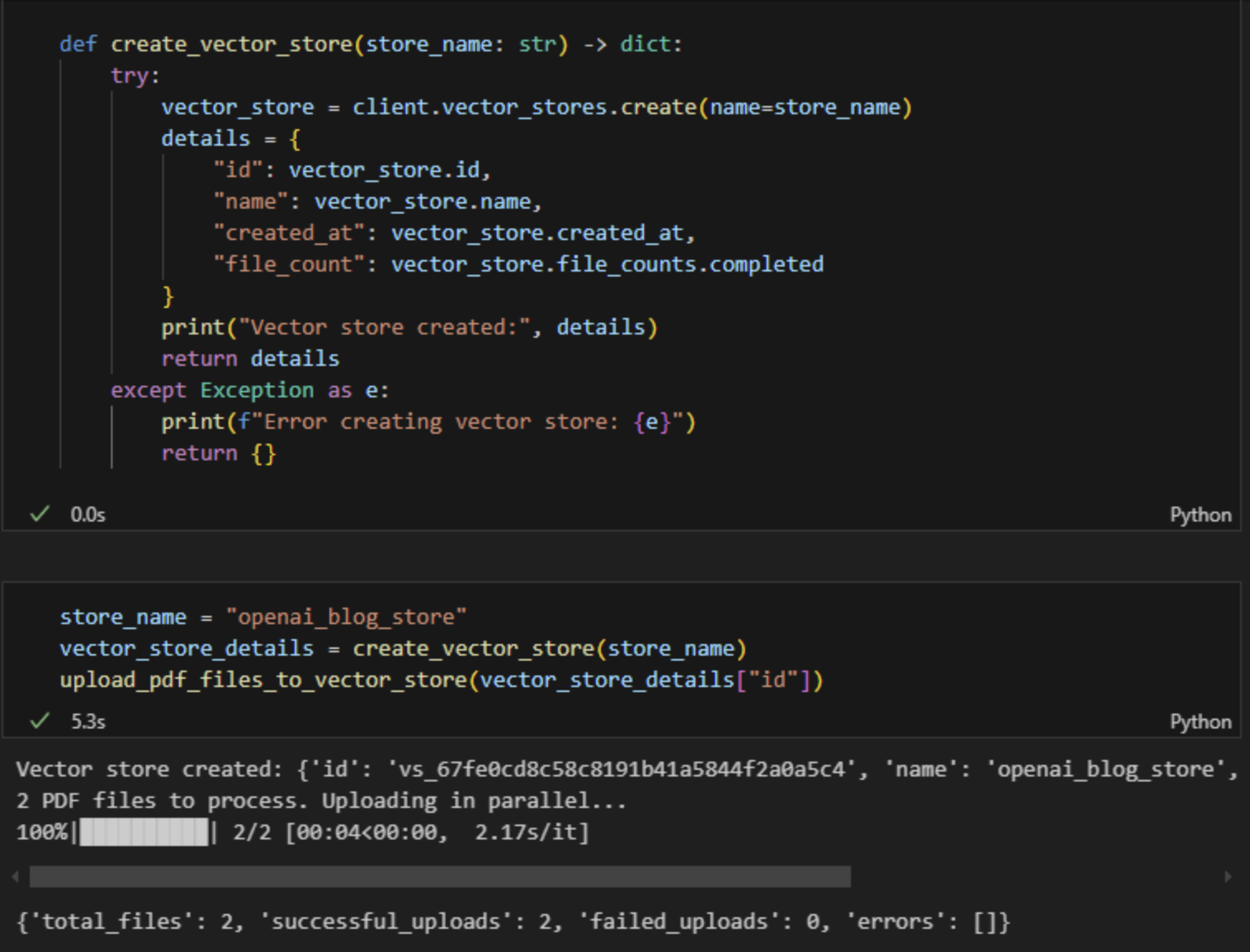
2、上传pdf文件,创建向量库
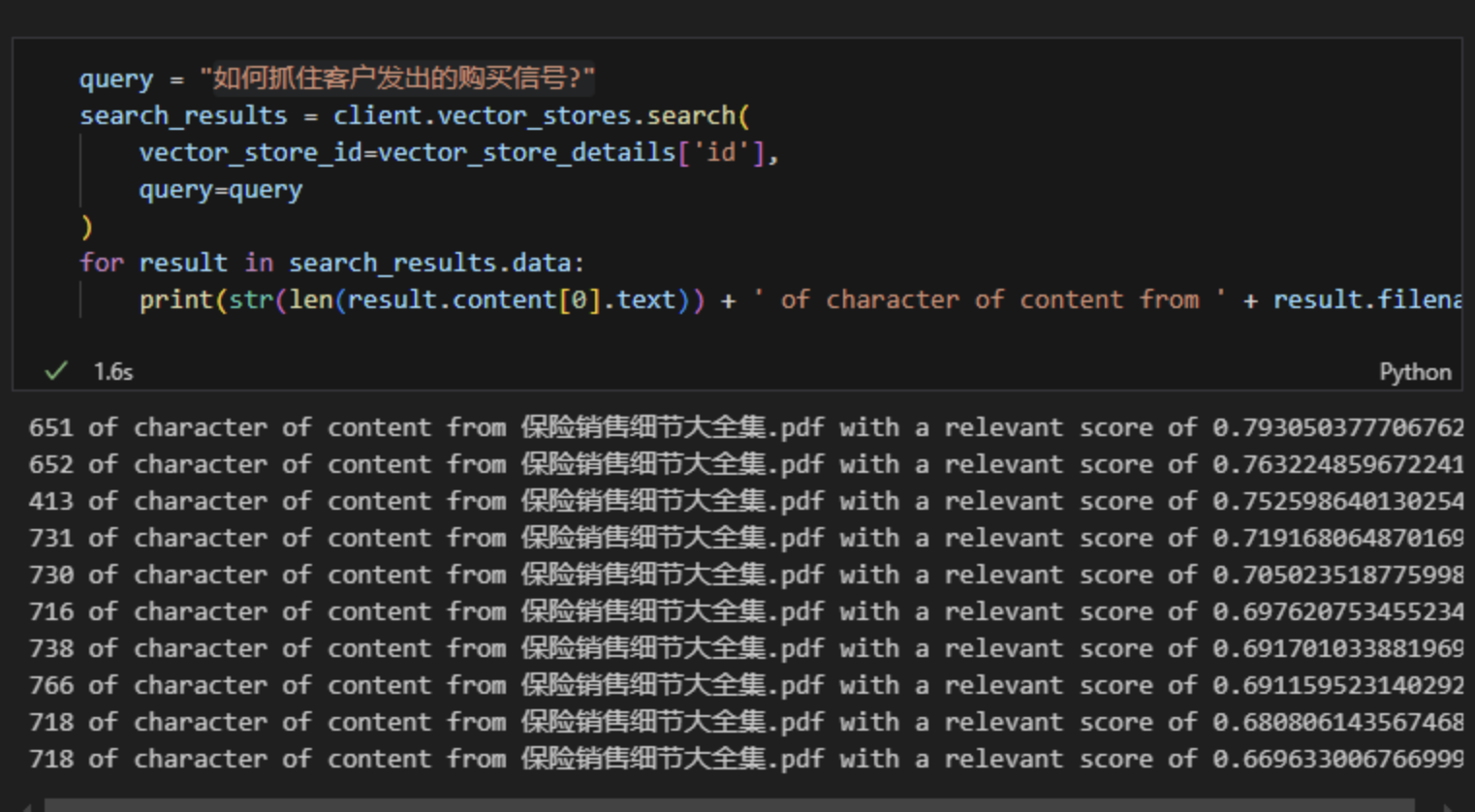
3、单个提问的向量检索
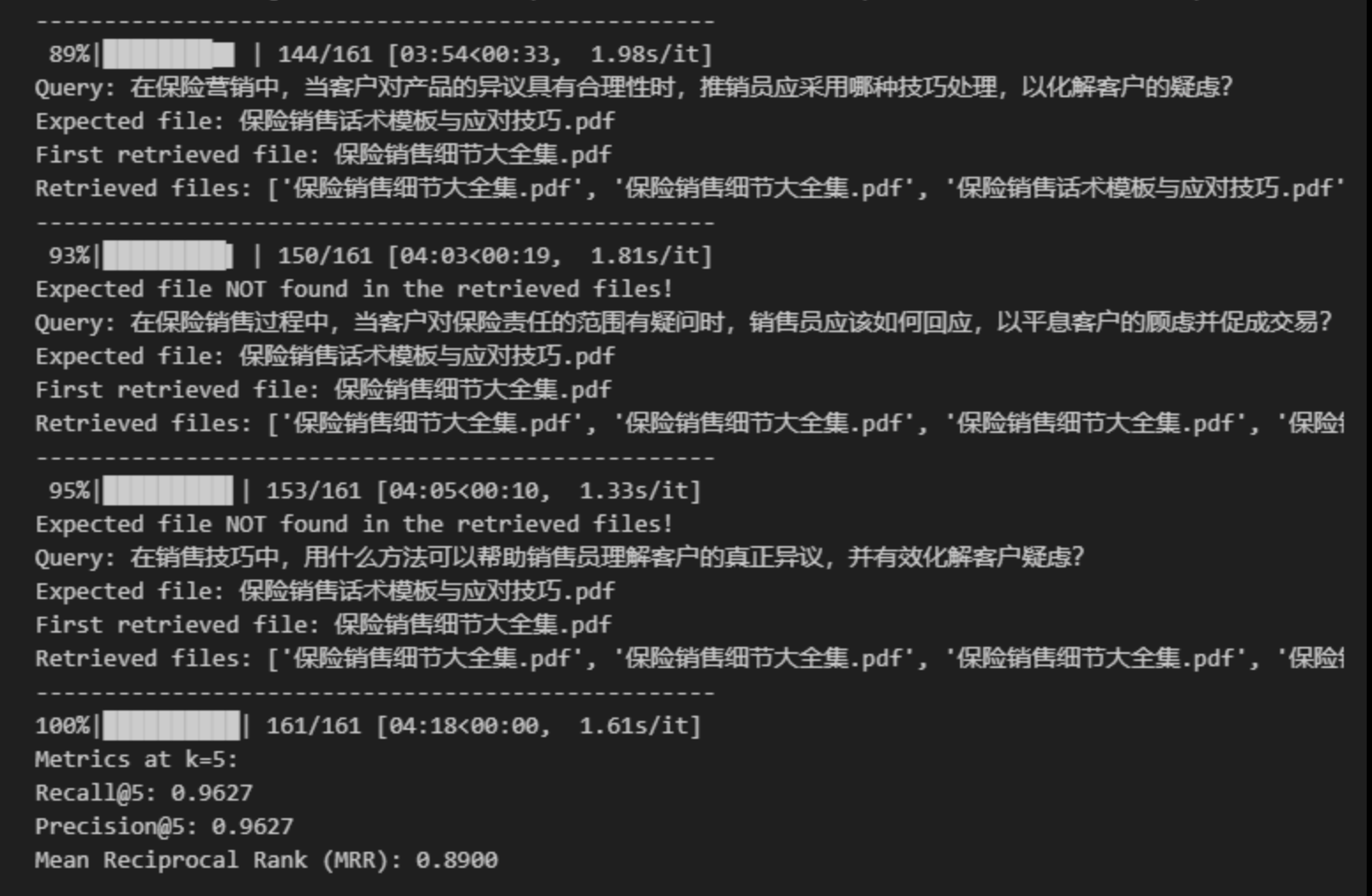
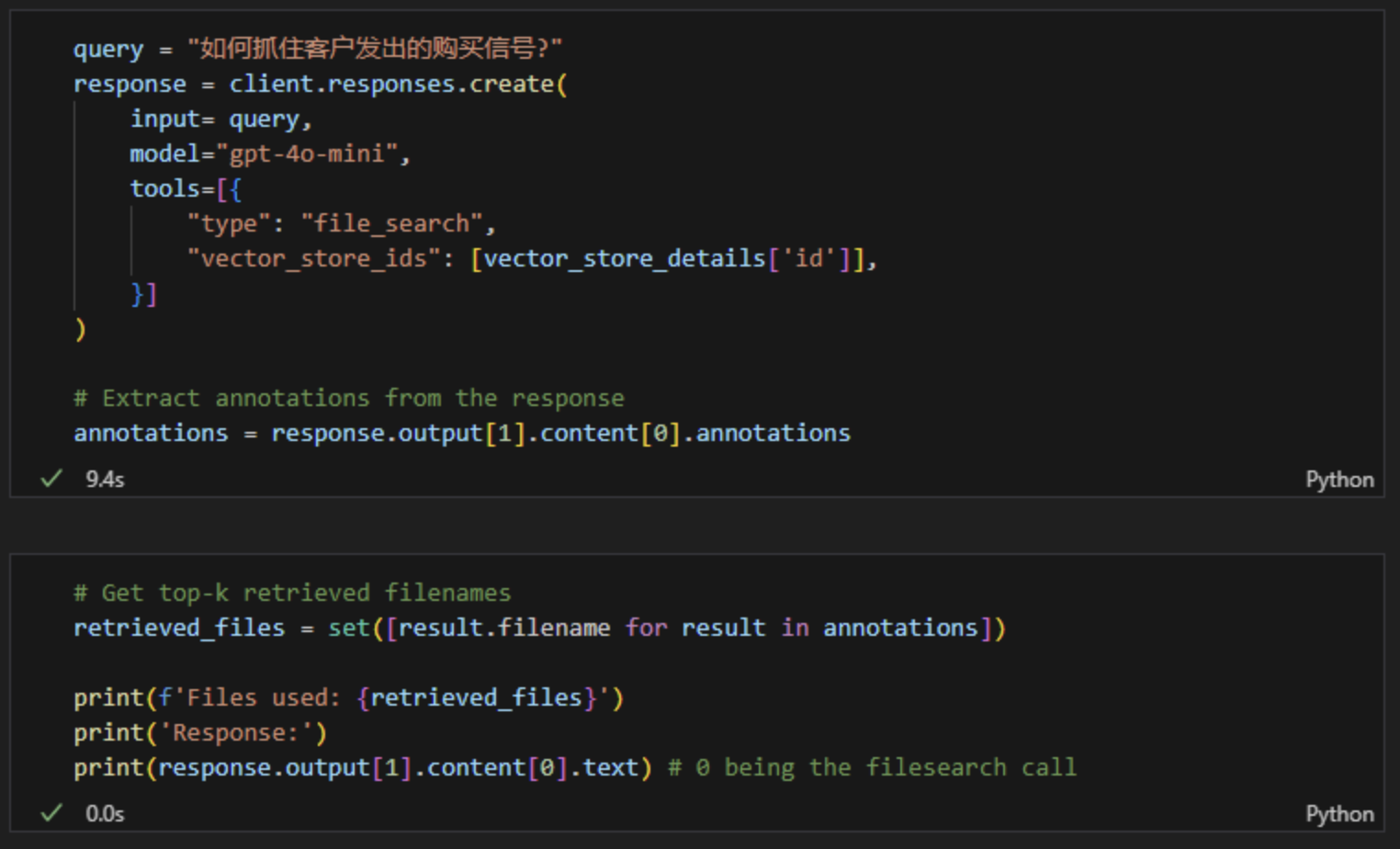
4、单个提问的检索结果

5、生成问题列表,这里需要注意chunk的大小及重合。
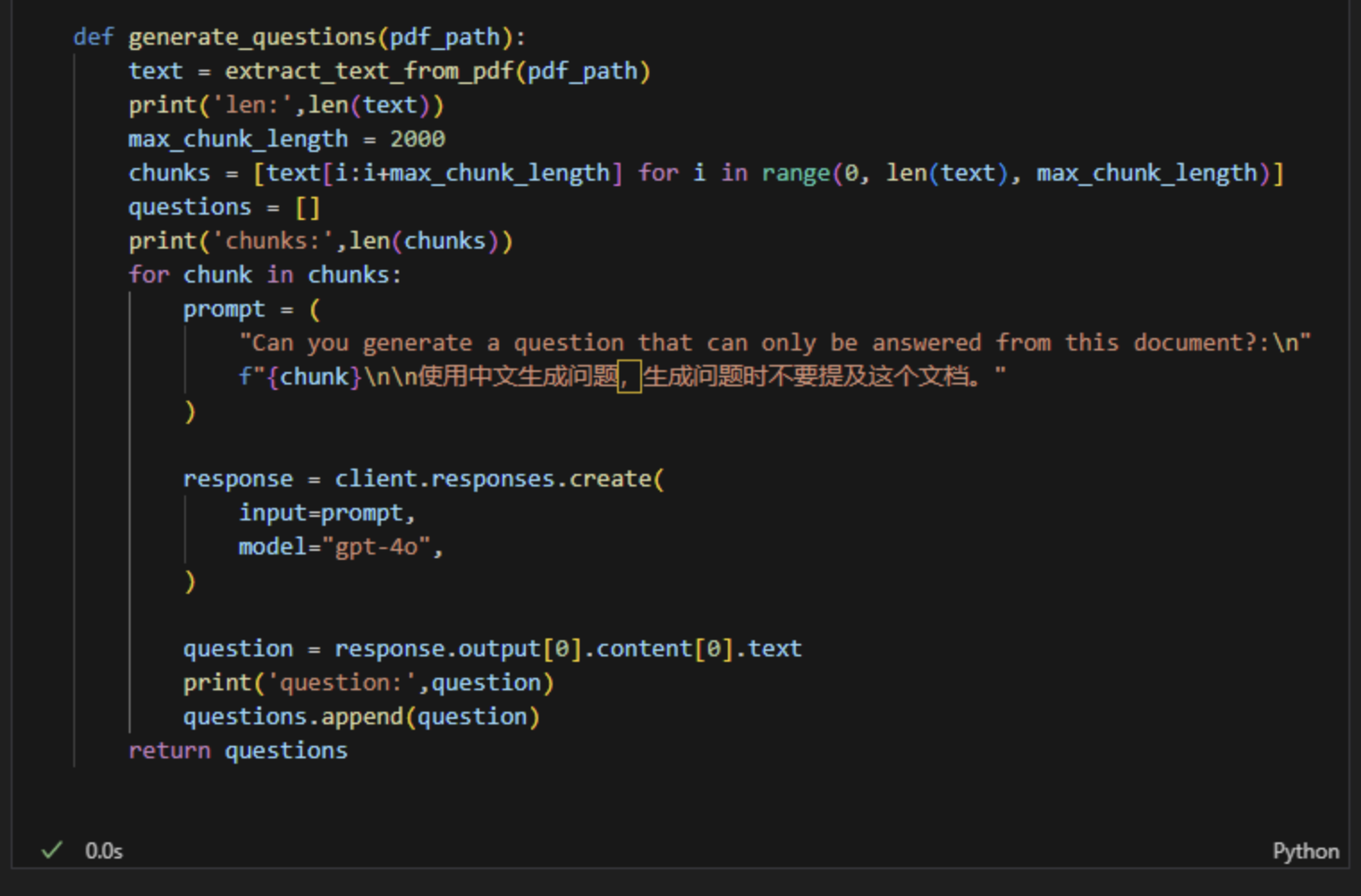
6、单个文档生成问题的过程
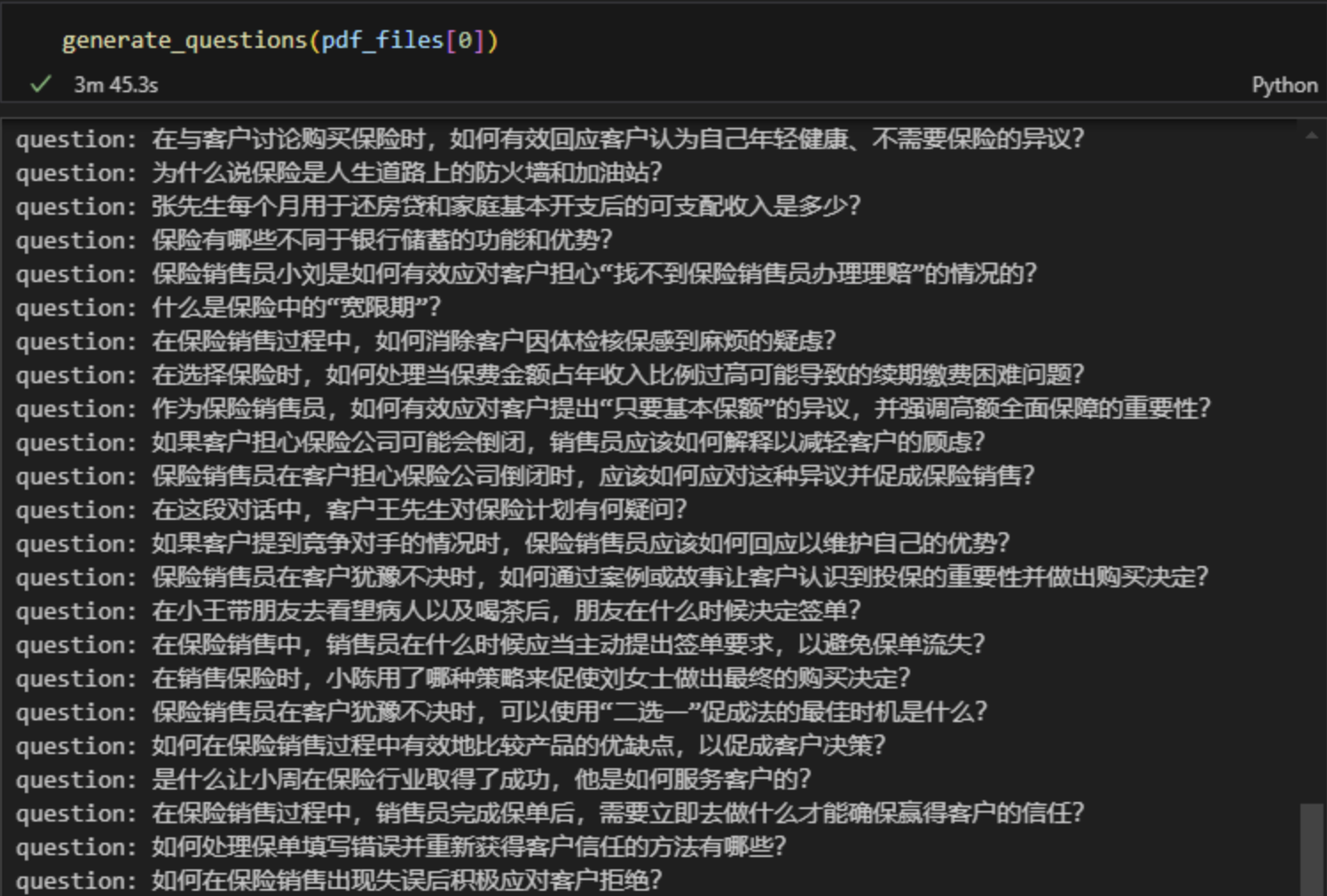
7、把所有文档的问题存在字典中
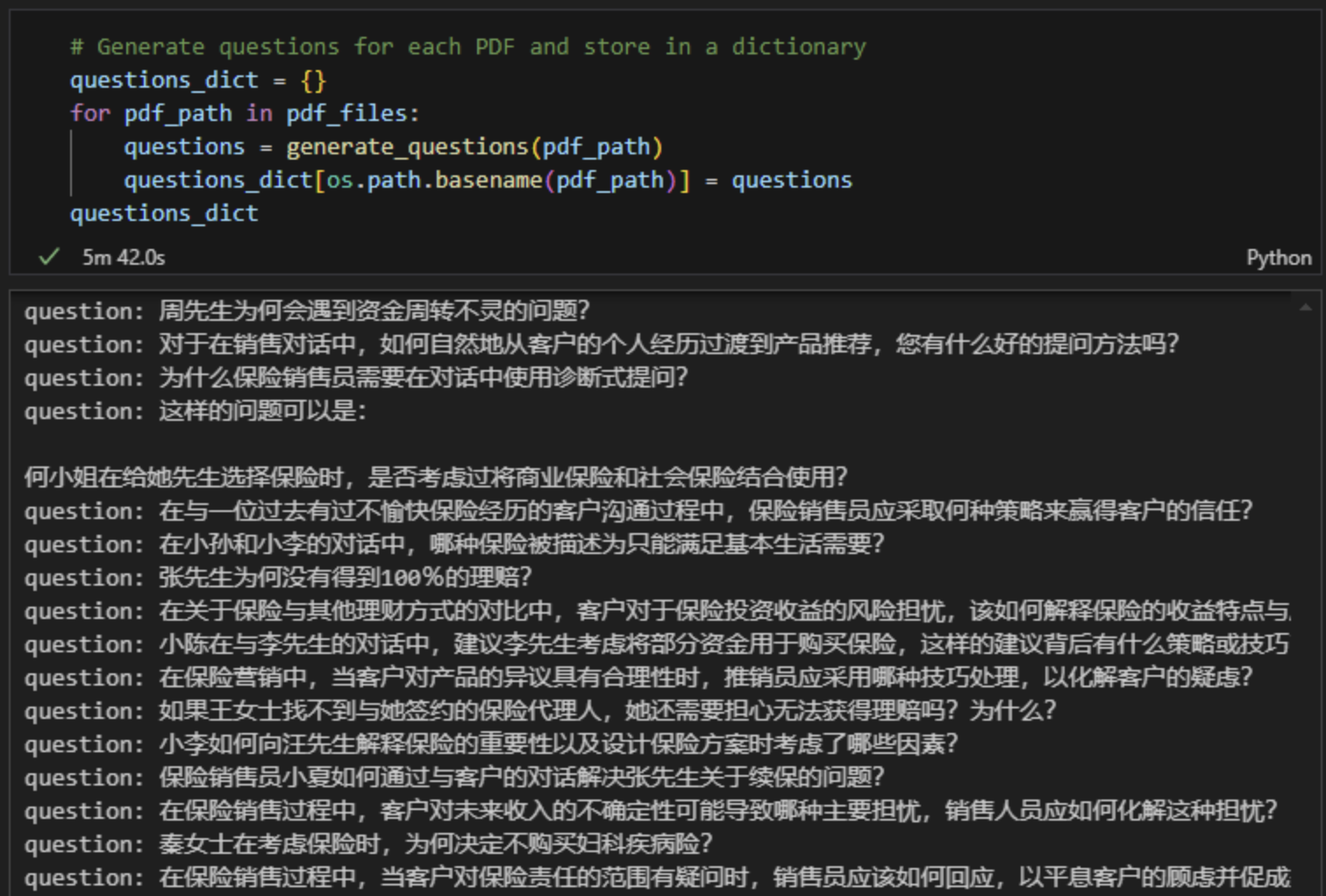
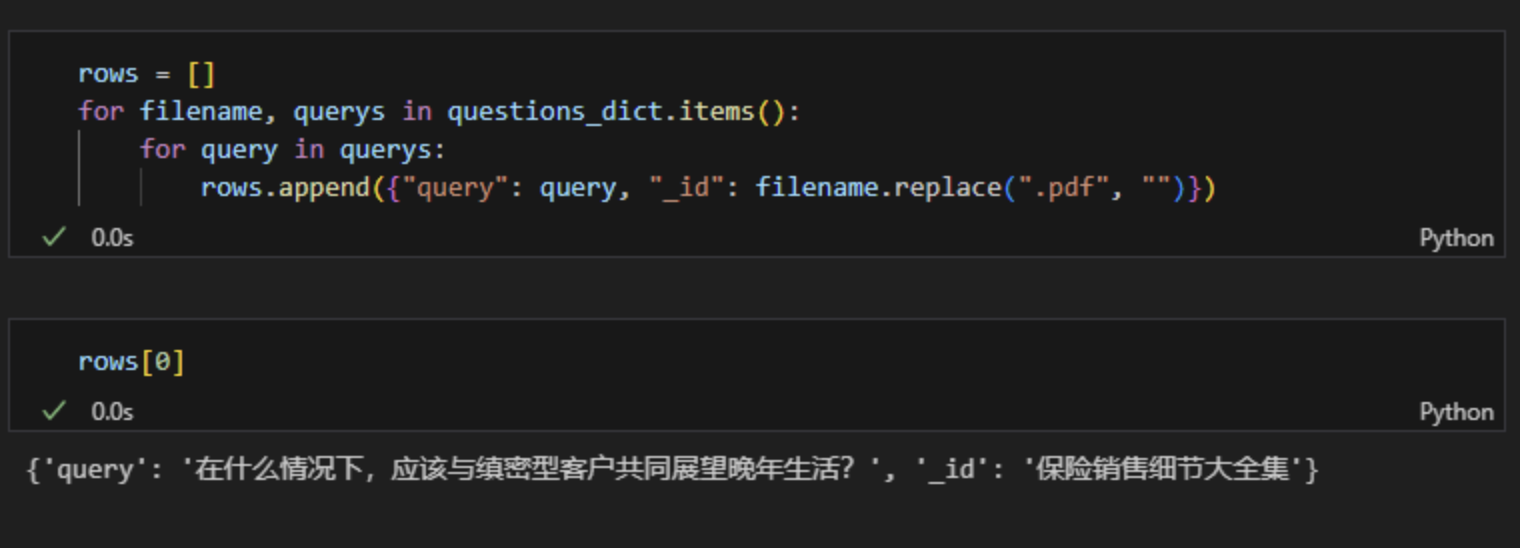
8、把所有问题存储在rows列表中
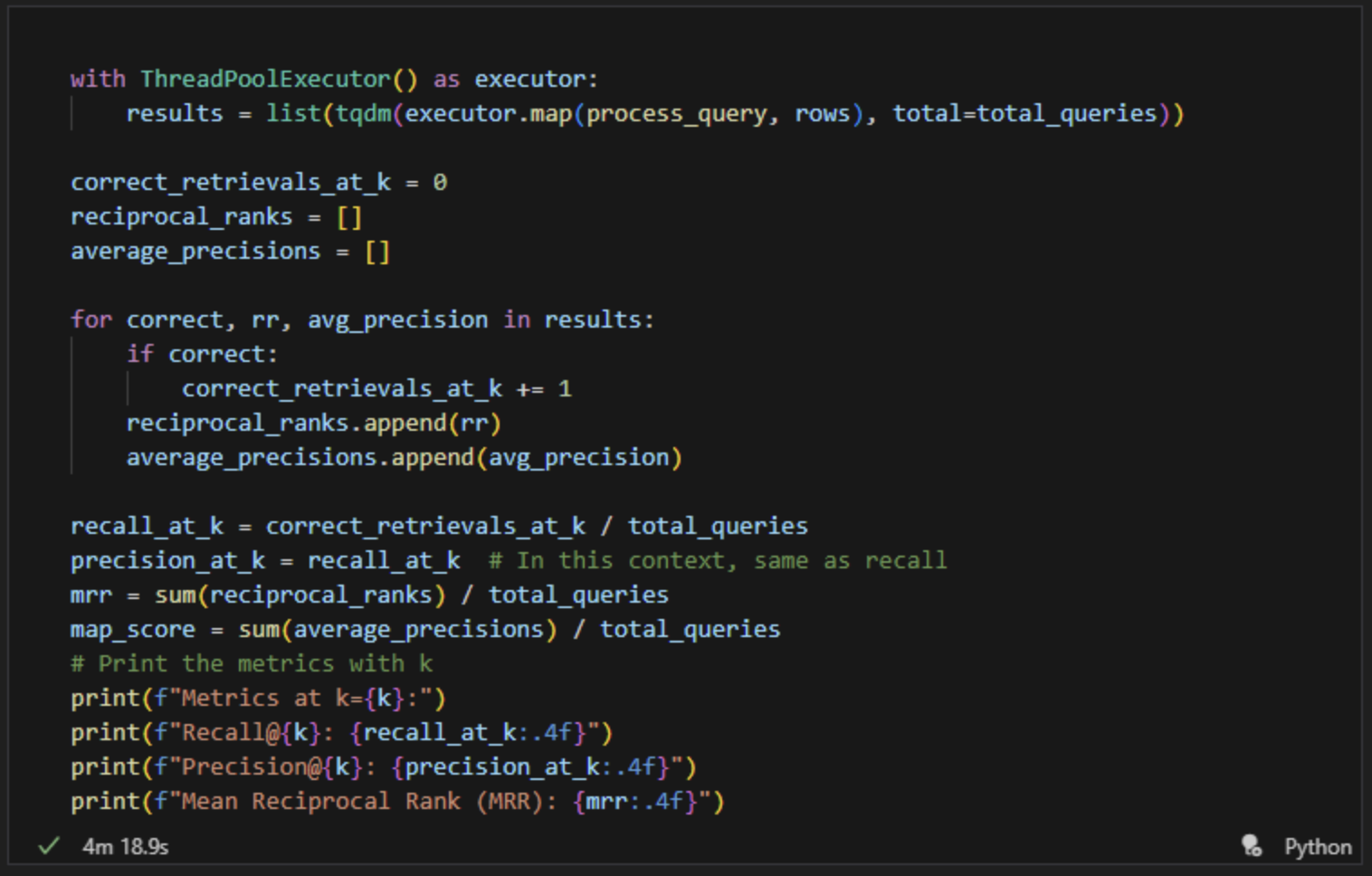
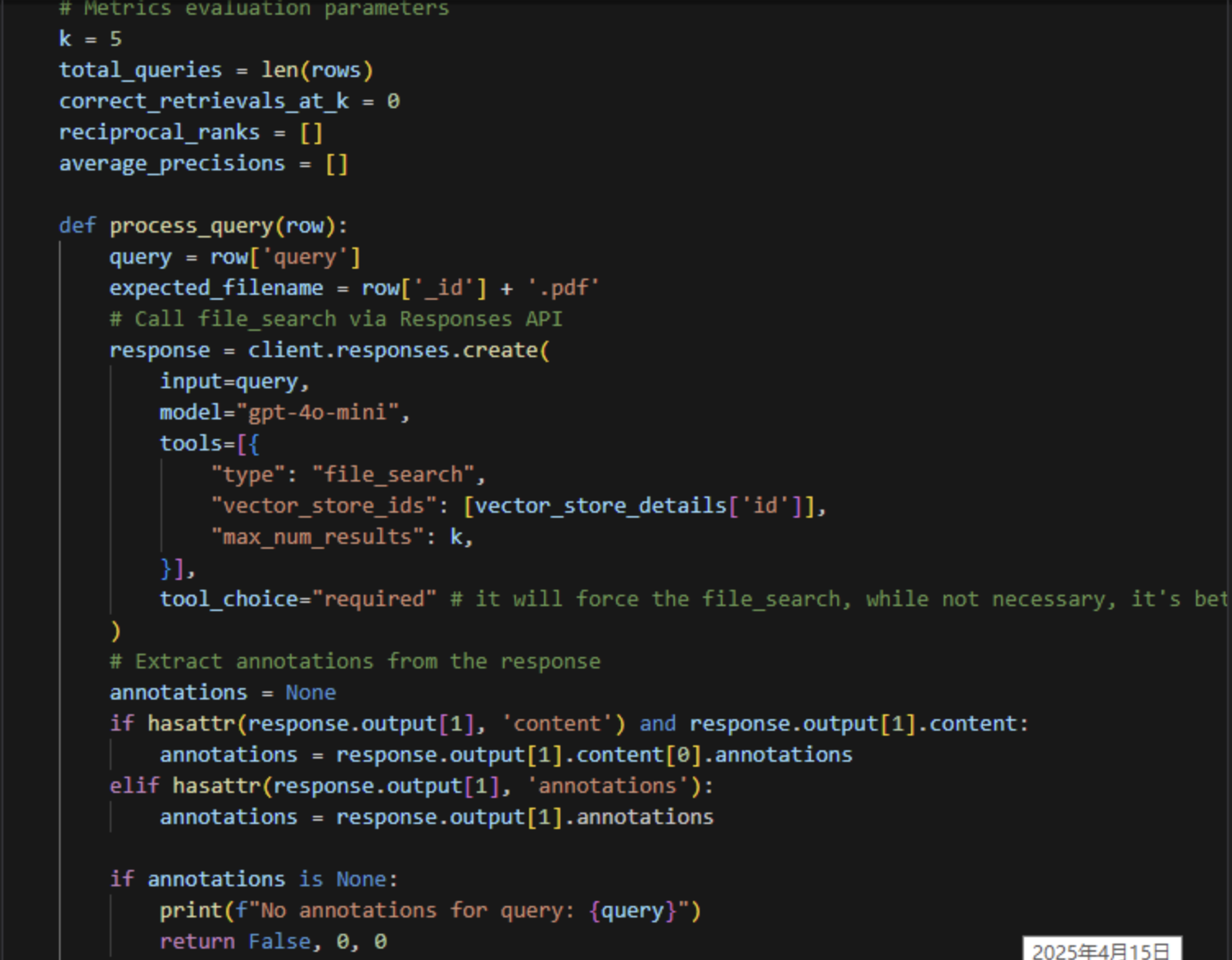
9、问答评估实现
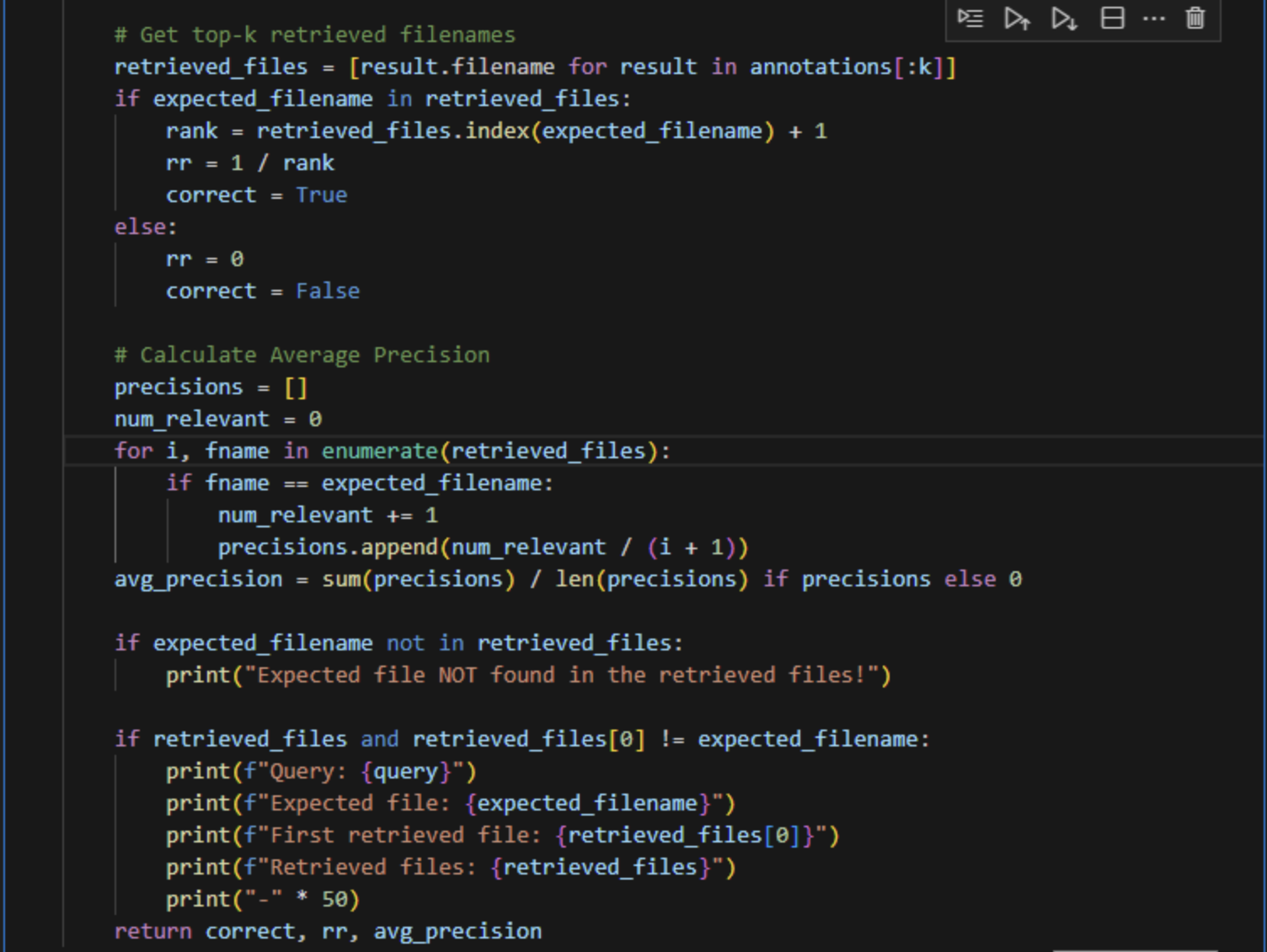
10、单个评估验证

11、迭代评估问答