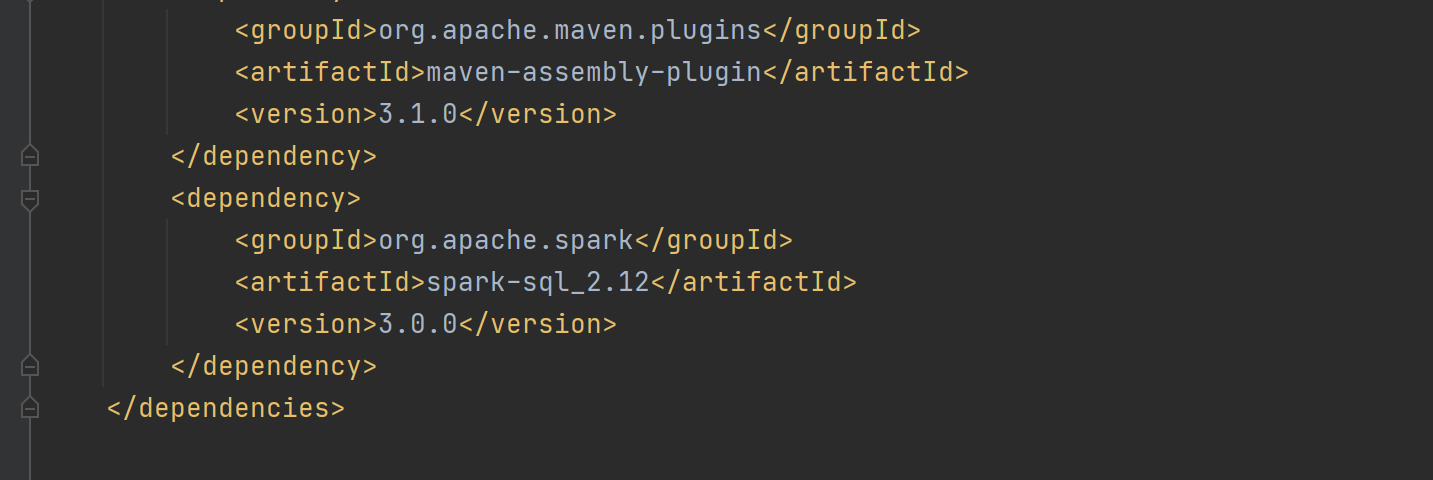
创建子模块Spark-SQL,并添加依赖
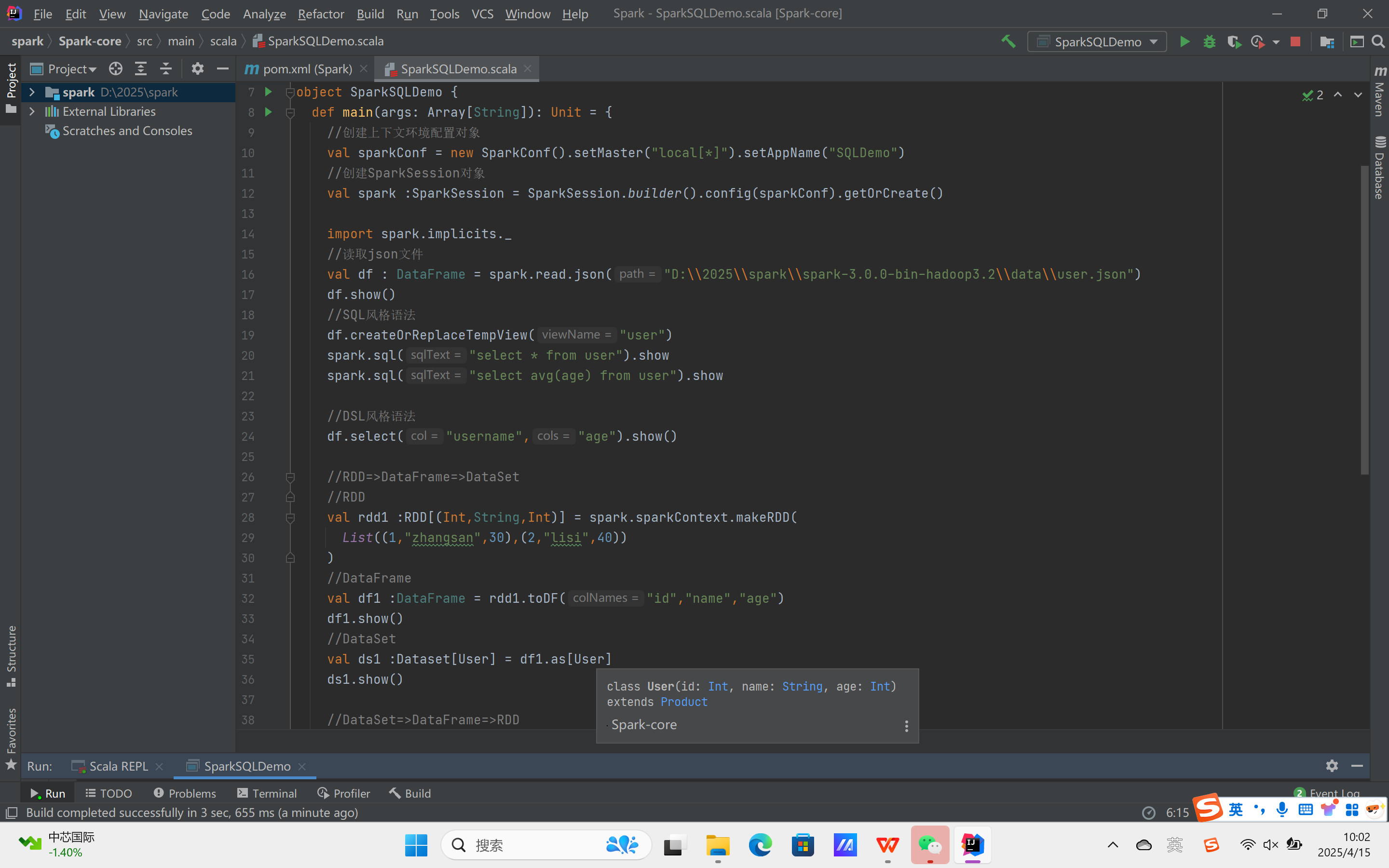
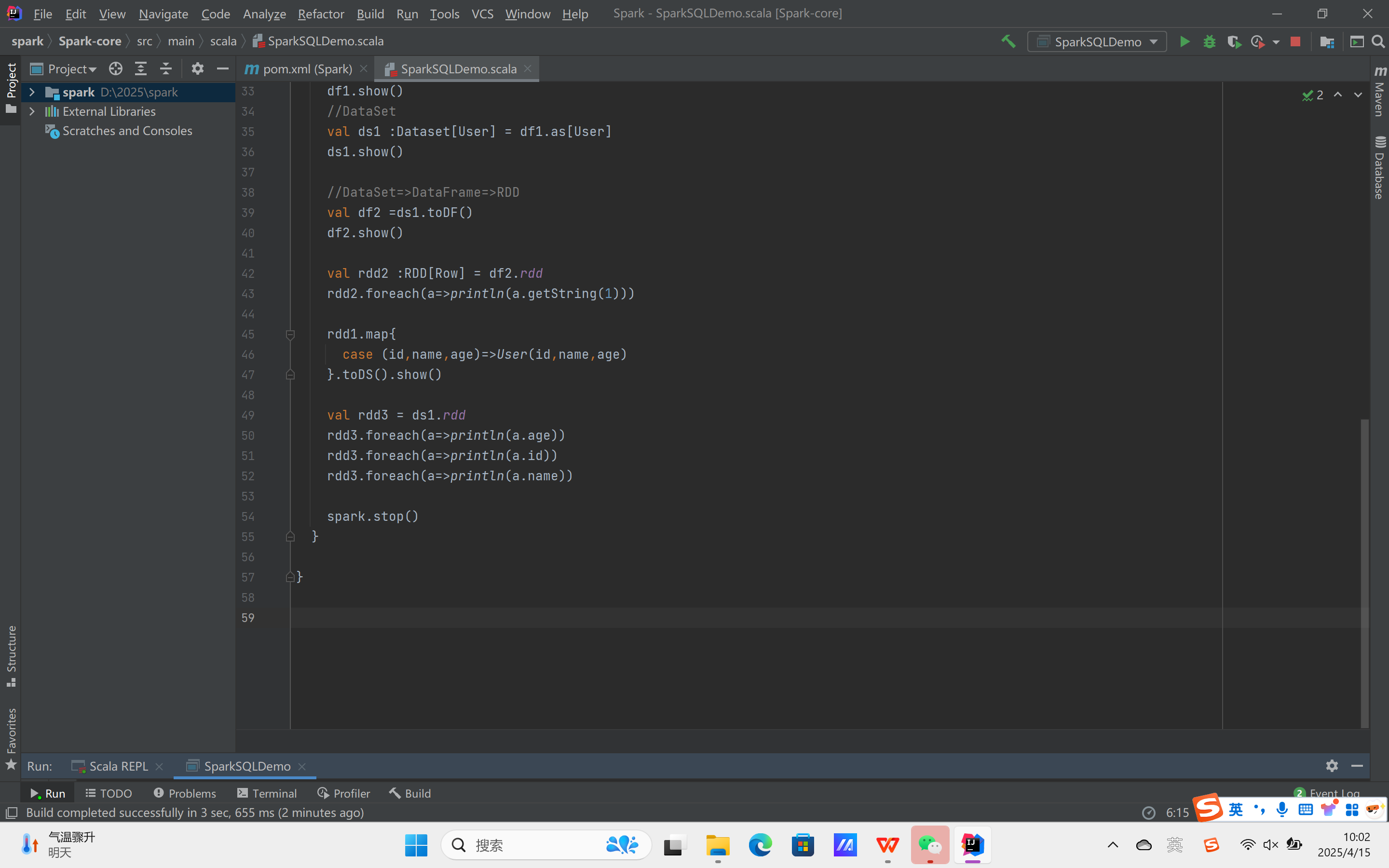
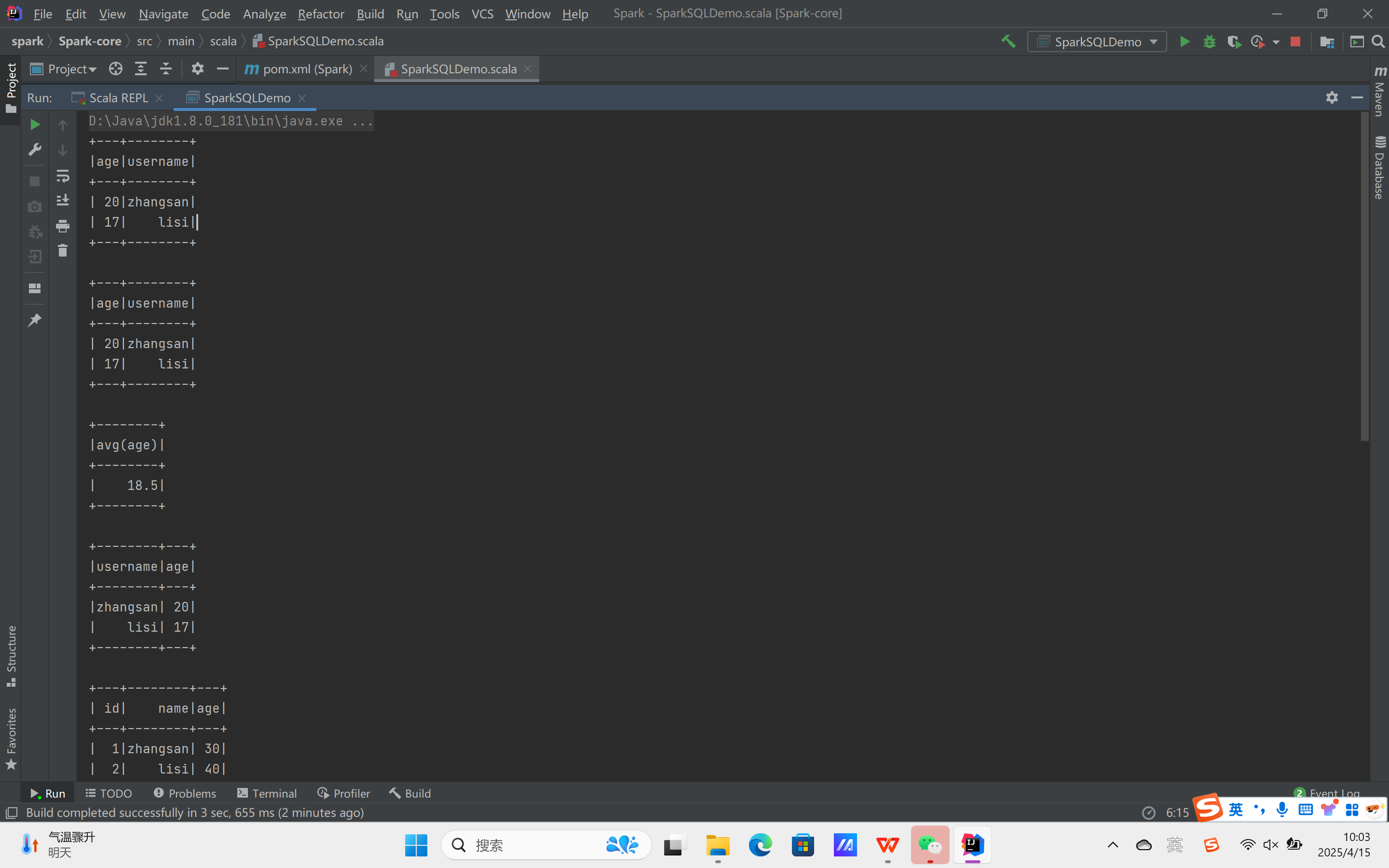
创建Spark-SQL的测试代码:
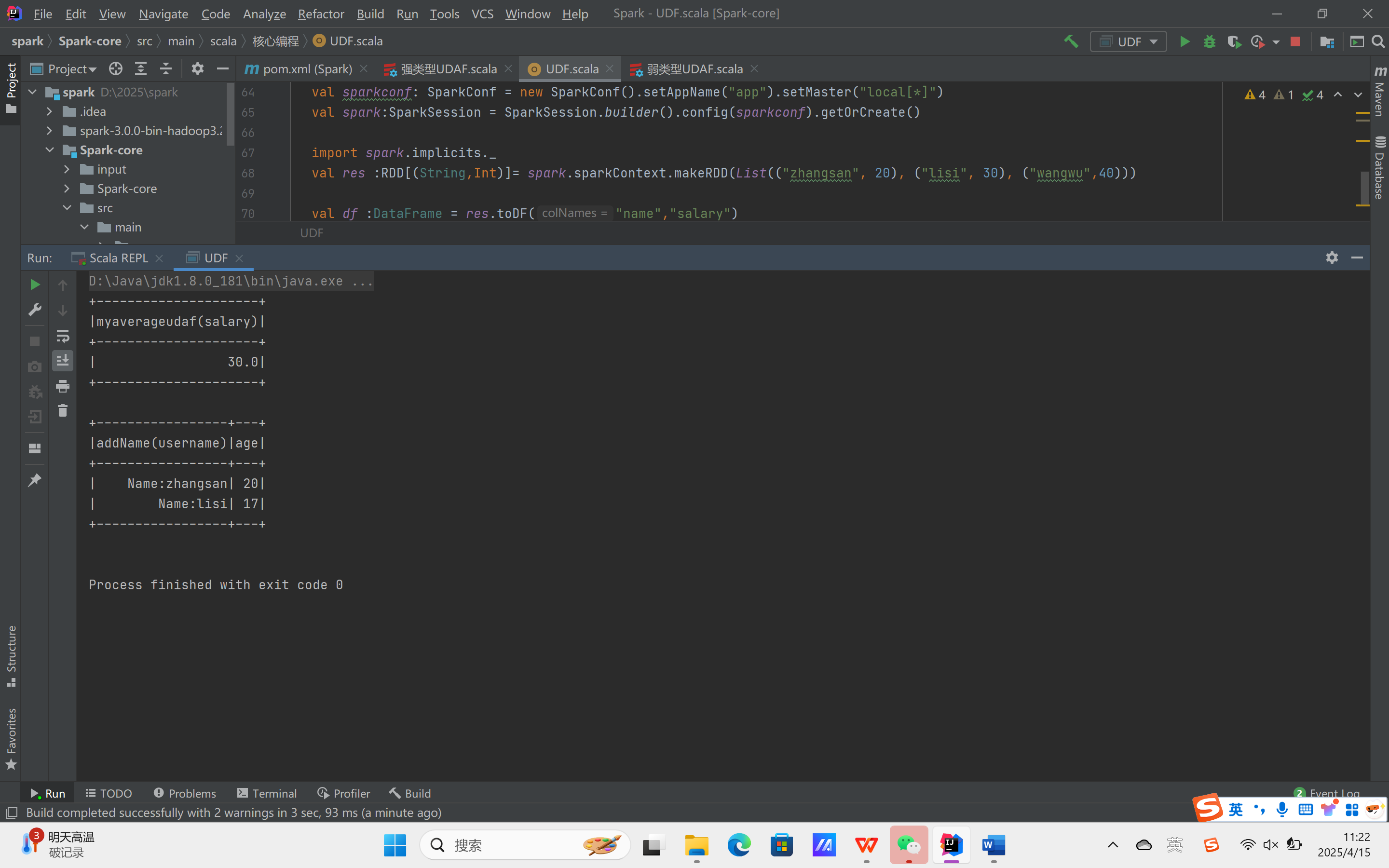
运行结果:
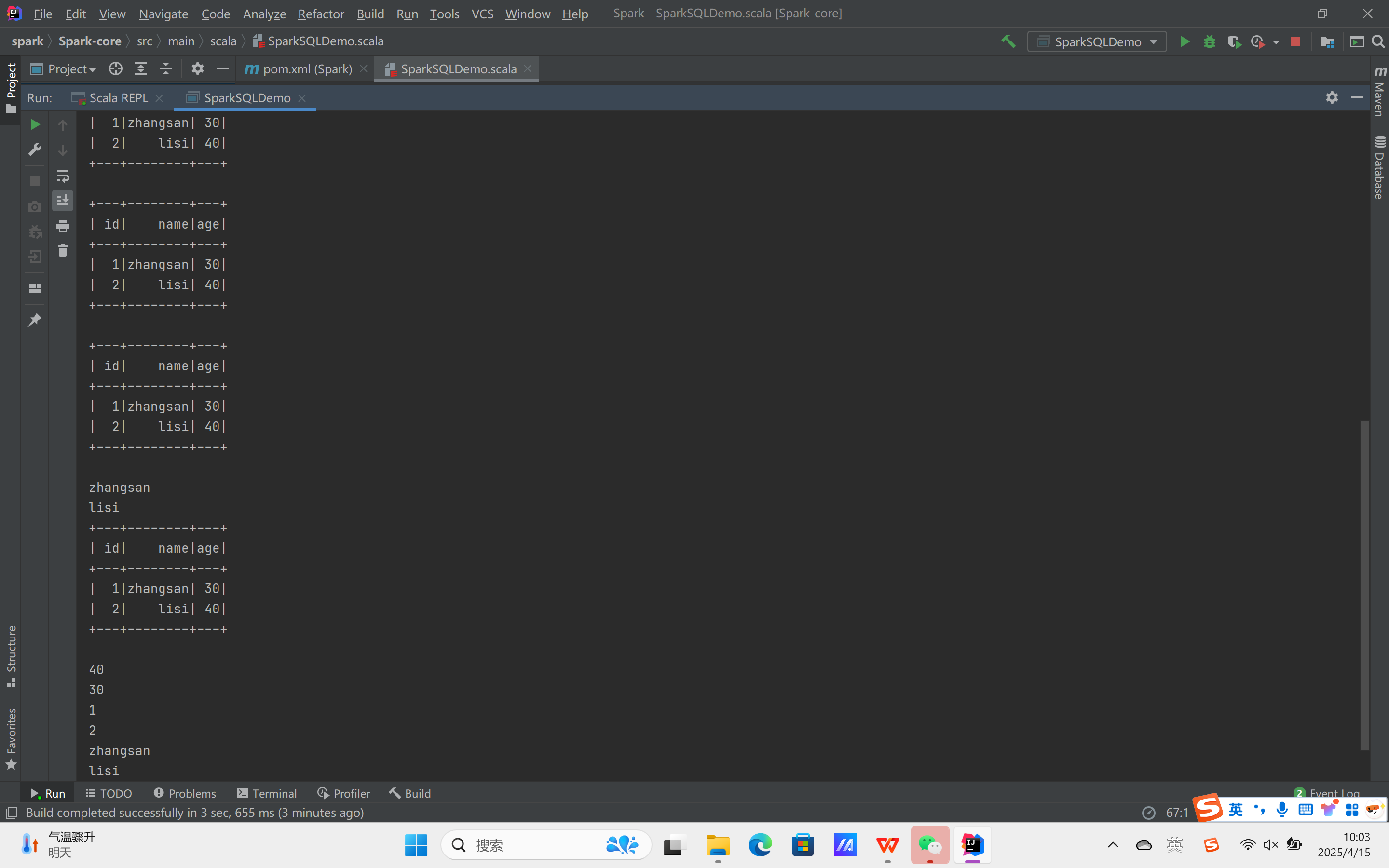
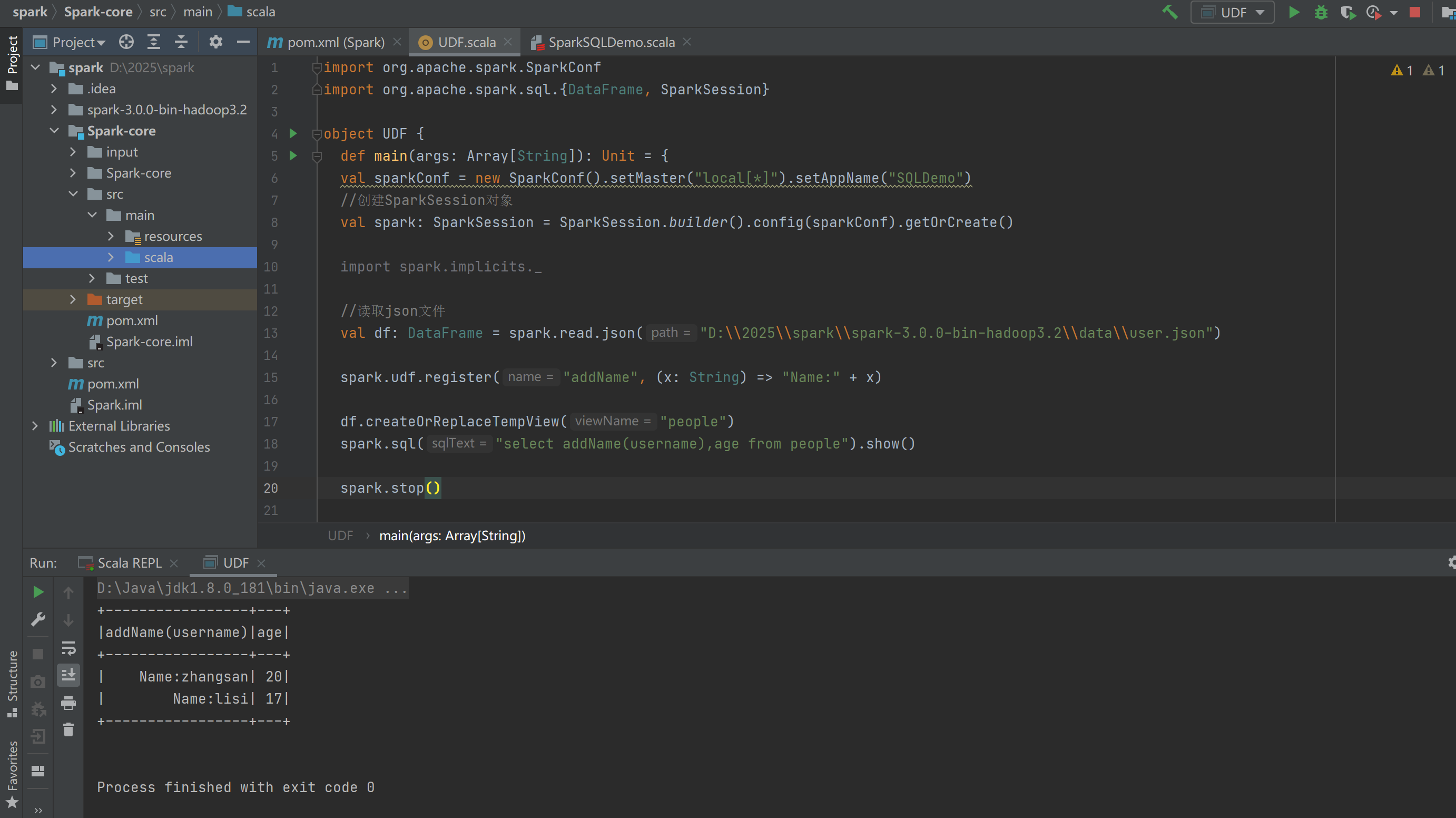
自定义函数:
UDF:
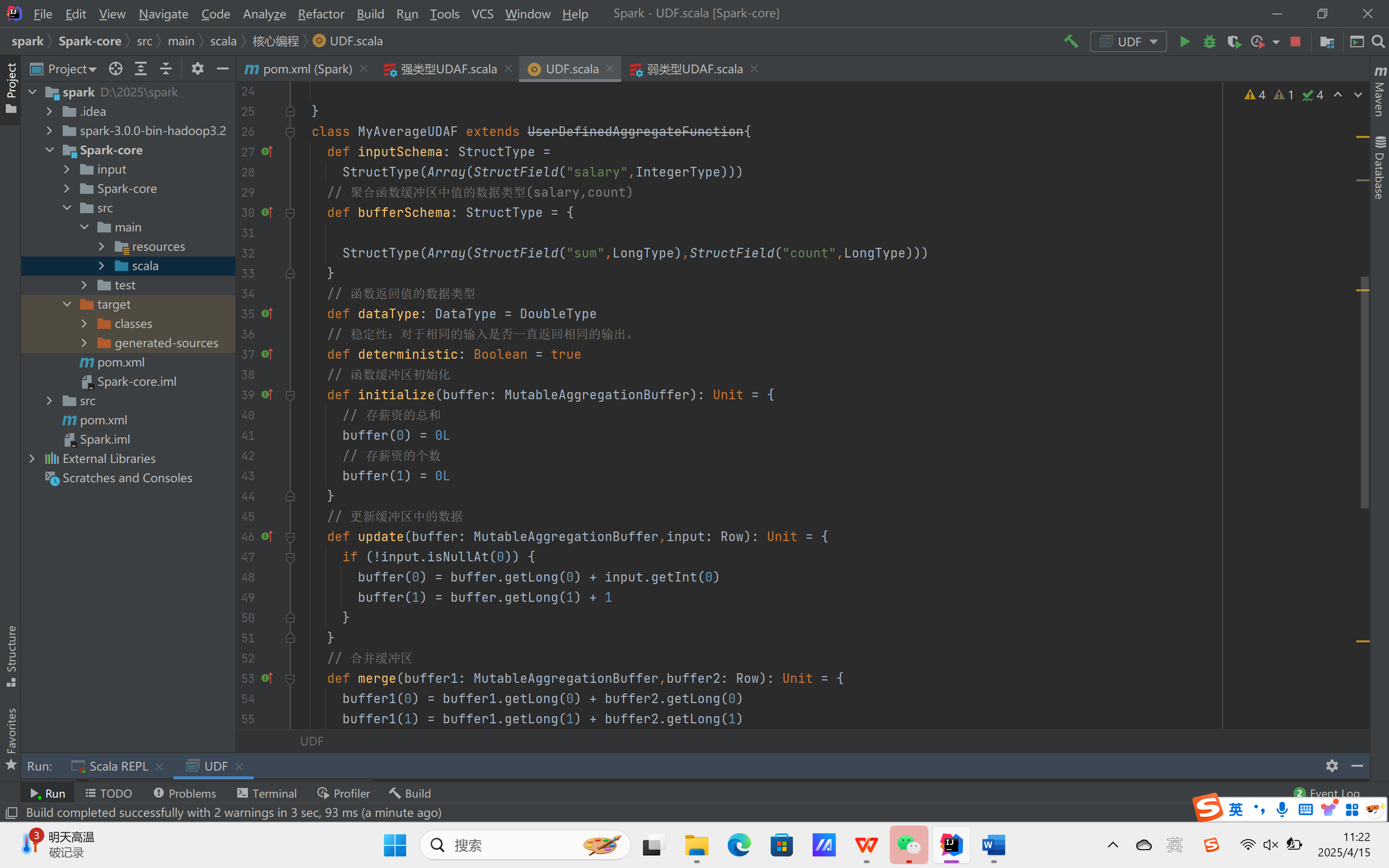
UDAF(自定义聚合函数)
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),
countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。Spark3.0之前我们使用的是UserDefinedAggregateFunction作为自定义聚合函数,从 Spark3.0 版本后可以统一采用强类型聚合函数 Aggregator
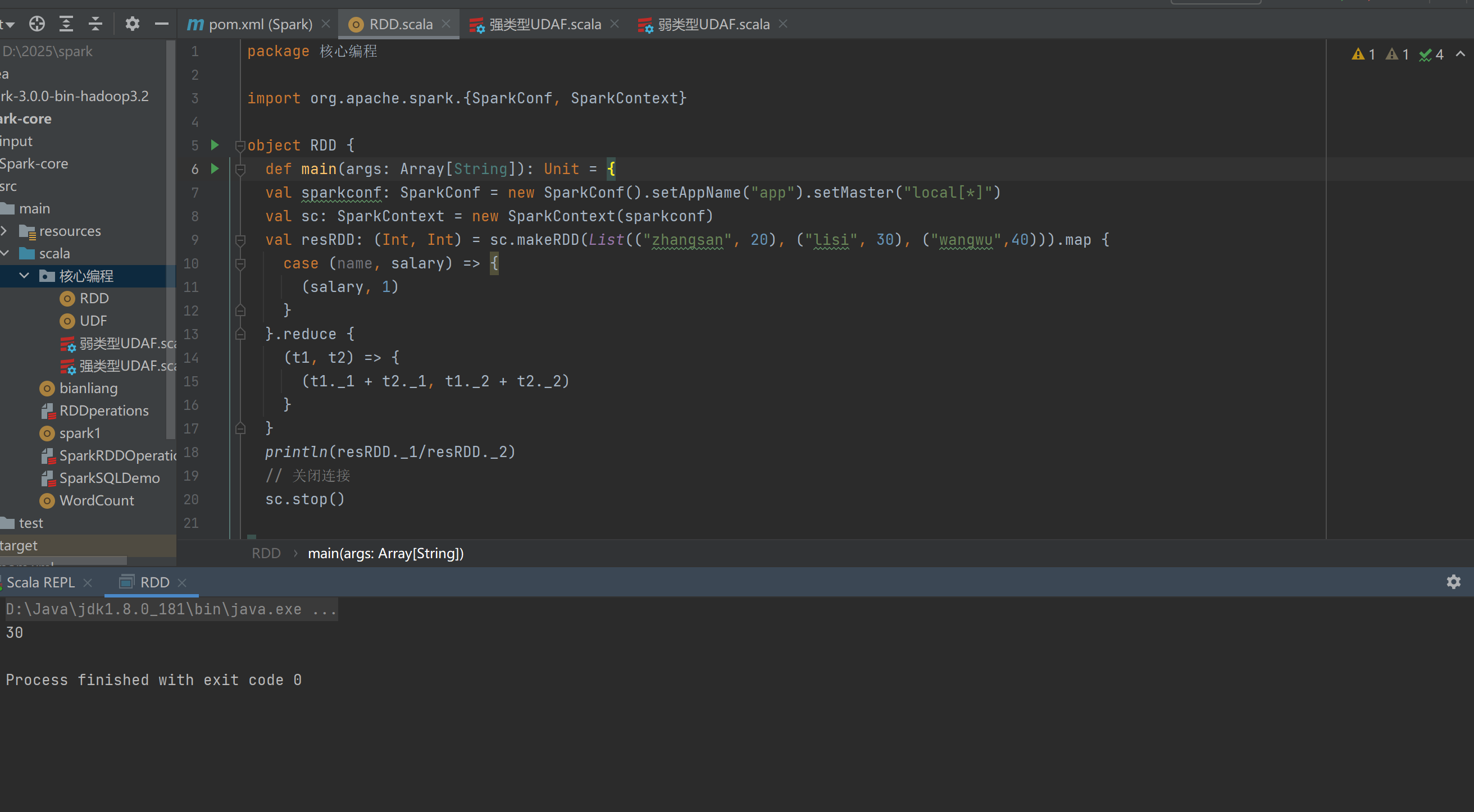
实验需求:计算平均工资
实现方式一:RDD
实现方式二:弱类型UDAF
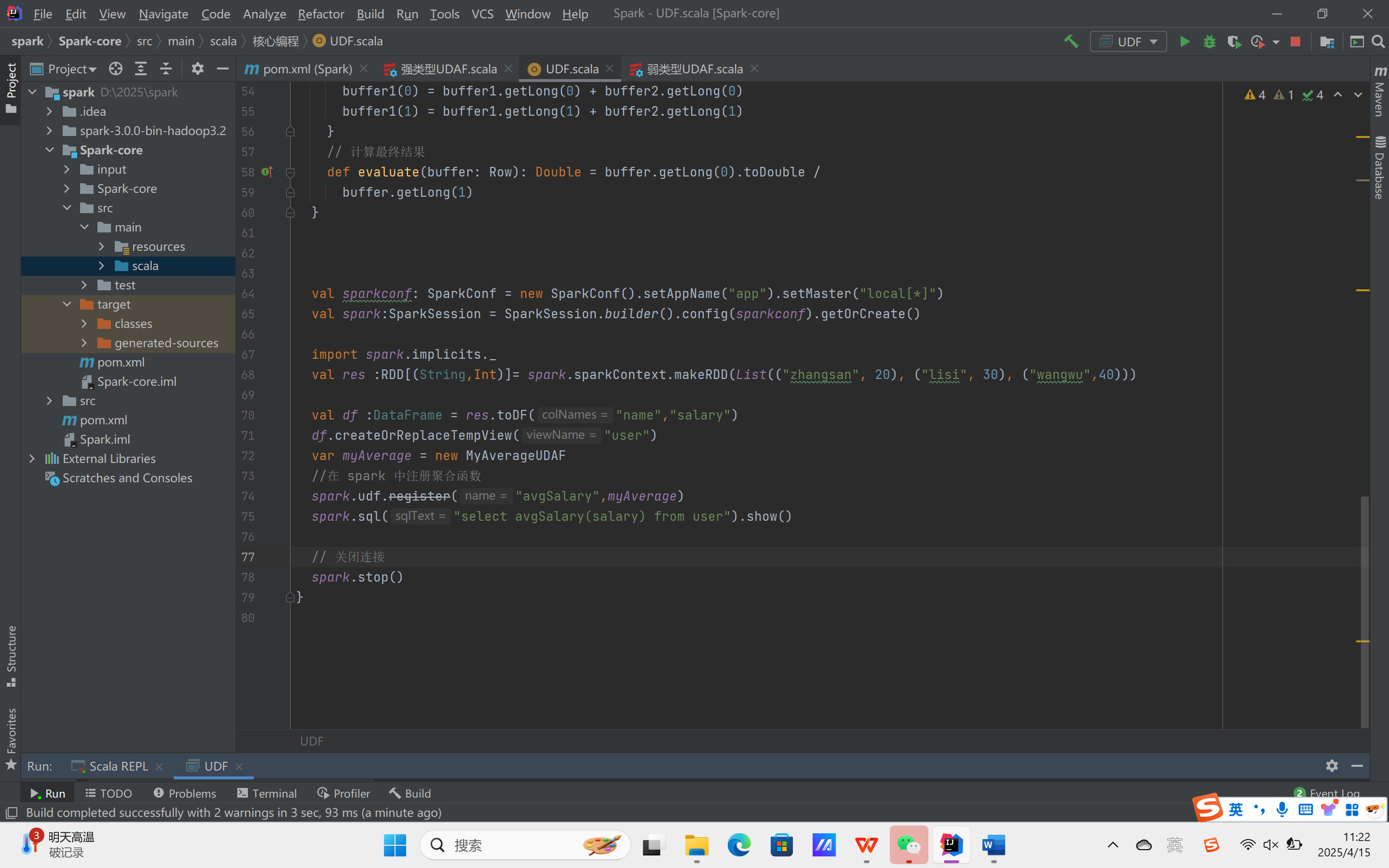
运行结果: