Vivado HLS(High-Level Synthesis ,高层次综合)是赛灵思(Xilinx)在其 Vivado 设计套件 中提供的一款工具,用于将 高级编程语言(如 C、C++、SystemC) 直接转换为 硬件描述语言(HDL,如 VHDL 或 Verilog),从而快速生成可编程逻辑(如 FPGA 或 SoC)的硬件电路设计。
HLS 的核心作用
传统的硬件设计需手动编写 RTL(寄存器传输级)代码(如 Verilog/VHDL),而 HLS 允许开发者:
- 用更抽象的软件语言描述算法或功能。
- 自动生成优化的 RTL 代码,显著提升开发效率。
- 尤其适合算法密集型任务(如信号处理、图像处理、AI加速等)。
HLS 的主要功能与特点
-
支持高级语言
用 C/C++/SystemC 描述硬件行为,无需手动编写 HDL 代码。
-
自动化硬件优化
通过添加编译指令(如
#pragma HLS),指导工具优化流水线、并行性、资源分配等。 -
仿真与验证
在软件层面验证功能正确性,减少后期硬件调试时间。
-
与 Vivado 无缝集成
生成的 RTL 可直接用于 Vivado 进行综合、布局布线,并生成比特流文件下载到 FPGA。
-
灵活生成 IP 核
输出为可重用的 IP 核,方便在更大系统中调用。
HLS 的典型应用场景
- 算法加速:将计算密集型算法(如矩阵运算、加密解密)硬件化,提升性能。
- 快速原型开发:软件工程师无需精通 HDL 即可参与 FPGA 开发。
- 异构计算:在 FPGA 上实现与 CPU/GPU 协同的定制加速模块。
- 复杂控制逻辑:简化状态机、接口协议(如 AXI)的开发。
HLS 的优势 vs 传统 RTL 开发
| 优势 | 说明 |
|---|---|
| 开发速度快 | 减少手动编码和调试时间。 |
| 易于维护 | 修改软件代码后重新综合即可。 |
| 跨平台复用 | C/C++ 代码可同时用于软件和硬件。 |
| 降低门槛 | 软件工程师也能参与硬件开发。 |
适用人群
- 需要硬件加速的算法工程师。
- 希望快速实现 FPGA 功能的开发团队。
- 希望减少 HDL 编码工作的硬件工程师。
一:(两个向量对应元素相加工程)
1:创建工程
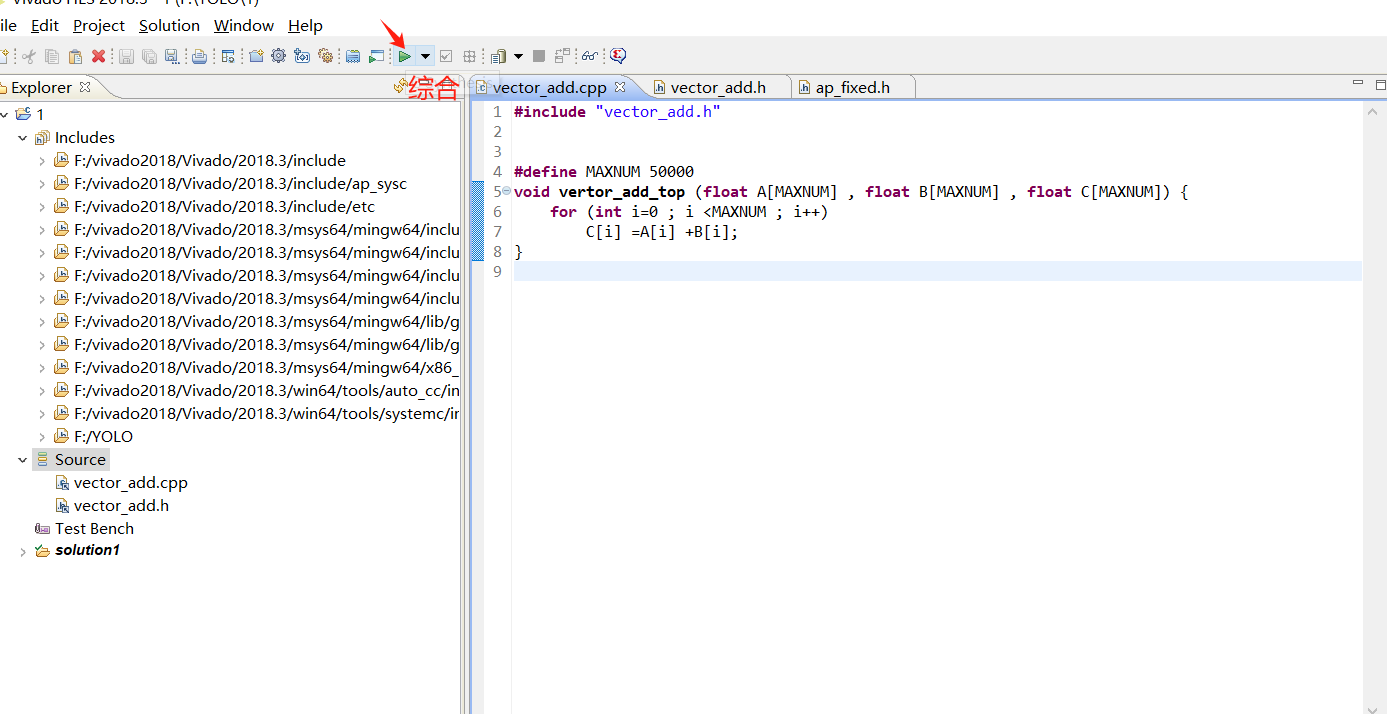
2 加法运算创建文本 写代码
点击综合 将c语言转化成verilog
加法运算代码如下
#include "vector_add.h" #define MAXNUM 50000 void vertor_add_top (float A[MAXNUM] , float B[MAXNUM] , float C[MAXNUM]) { for (int i=0 ; i <MAXNUM ; i++) C[i] =A[i] +B[i]; }
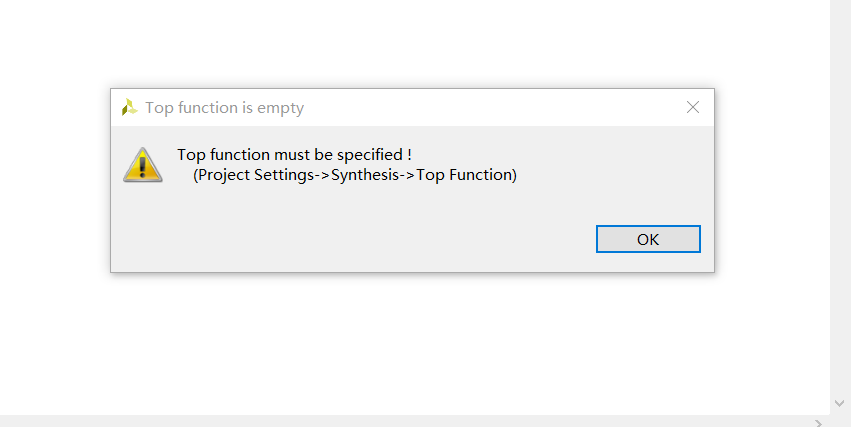
会报错
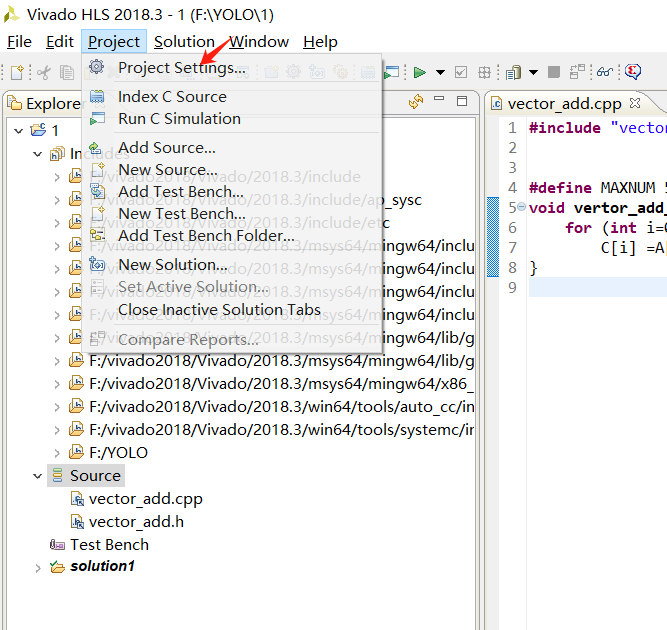
将文件设置为顶层
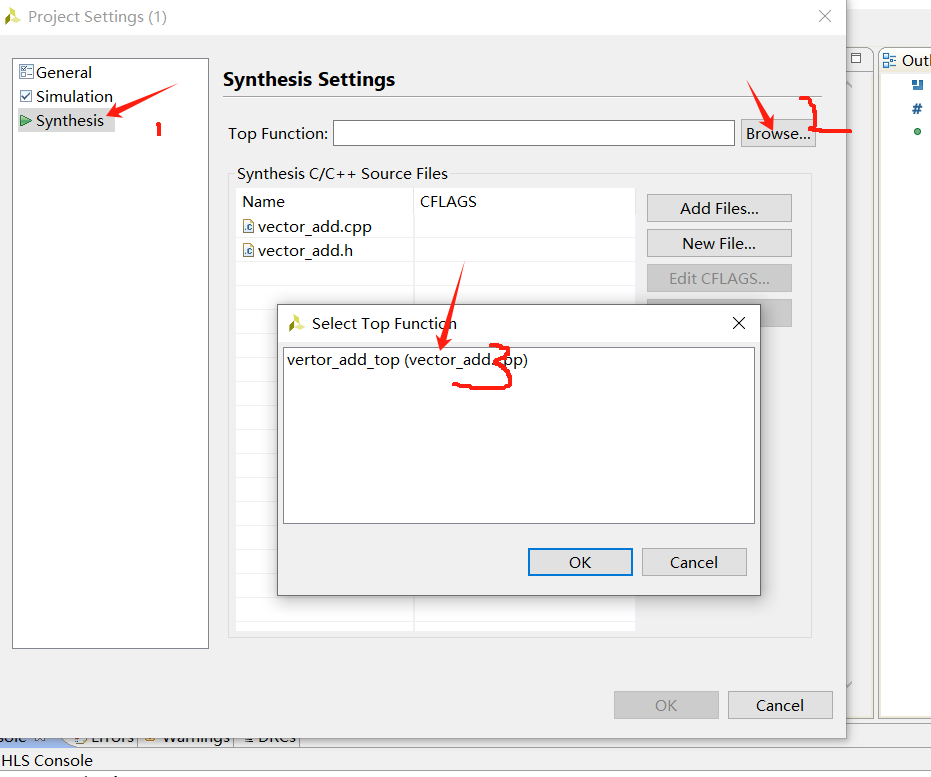
依次点击即可将刚刚写的设置为顶层
3:分析报告
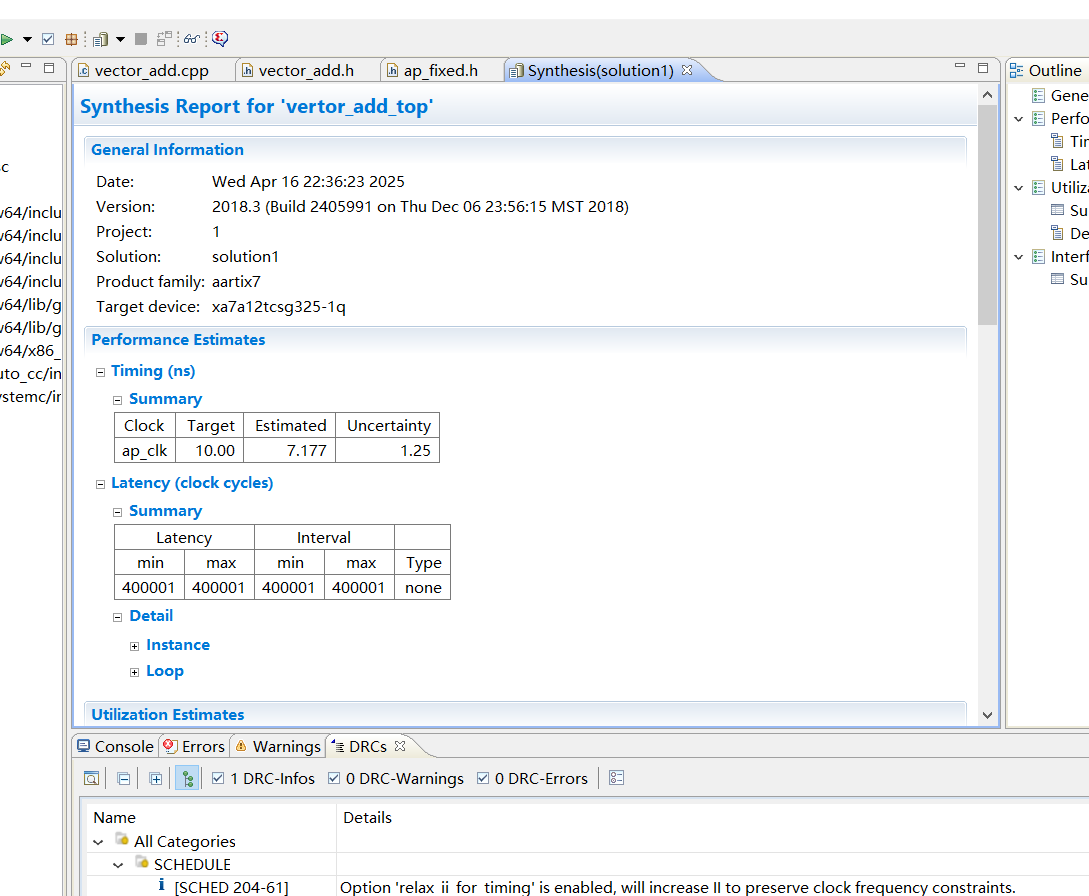
如上图
这依次是布局的时钟(我认为就是写代码然后映射verilog的时间),目标的时间10,预估的时间7.177ns
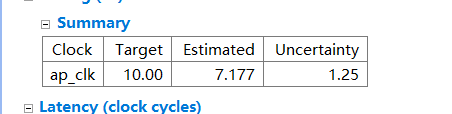
总的时间 从开始输入到输出的时间400001 代表多少个时钟周期,一个时钟周期7.177ns,400001*7.177/10^9 大约3ms能够计算完50000个浮点数相加。
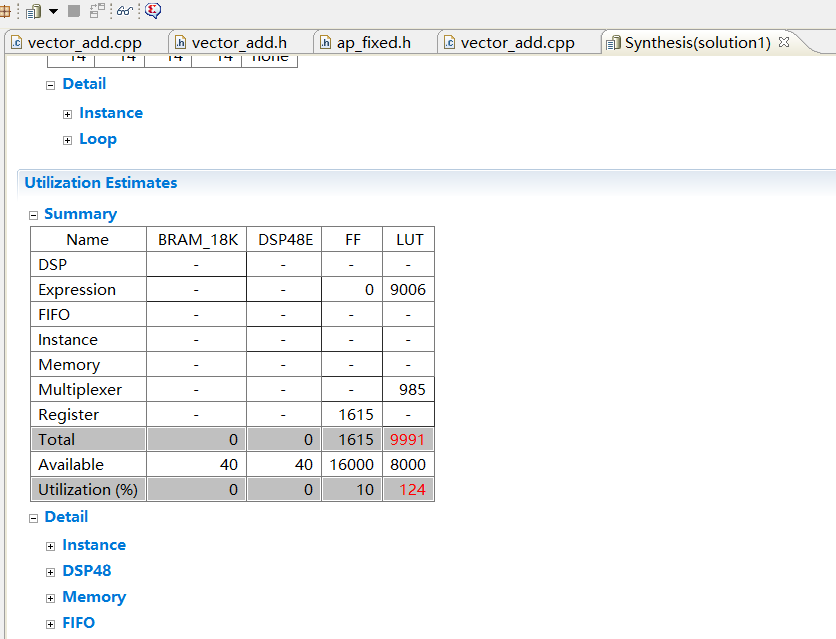
下图是资源占用情况

3.1 DSP 、LUT 和 FF是什么
在 FPGA/SoC 设计 中,DSP 、LUT 和 FF 是三种核心硬件资源的缩写,它们直接影响设计的性能、功耗和资源占用率。以下是它们的定义和作用:
1. DSP(Digital Signal Processor,数字信号处理器块)
-
用途 :
专为高效执行 数学运算(乘法、乘累加、浮点运算等) 设计的硬件模块。
适用于信号处理、滤波器、AI加速、矩阵运算等场景。
-
特点:
- 高并行性:单时钟周期完成乘法或乘累加(MAC)。
- 低延迟:比用 LUT/FF 手动搭建等效电路更快更省资源。
-
示例 :
实现
C = A * B + C的乘累加操作时,优先占用 DSP 资源,而非 LUT/FF。 -
FPGA中的位置 :
DSP 块通常以阵列形式分布在 FPGA 的逻辑单元中。
2. LUT(Look-Up Table,查找表)
-
用途 :
FPGA 中最基础的 组合逻辑单元 ,用于实现任意逻辑函数。
相当于一个真值表,通过配置存储的值定义输入到输出的映射关系。
-
结构:
- 通常为 4~6 输入、1 输出的可编程查找表(如 Xilinx 的 6 输入 LUT)。
- 可分割为更小的 LUT 以实现更复杂的逻辑。
-
特点:
- 灵活性高:可配置为实现与、或、非等逻辑功能。
- 资源敏感:复杂逻辑会消耗大量 LUT,可能制约整体设计规模。
-
示例 :
实现一个加法器时,除了进位链外,逻辑运算由 LUT 完成。
3. FF(Flip-Flop,触发器)
-
用途 :
用于存储 时序逻辑的当前状态 (1 比特数据)。
通过时钟信号同步更新数据,是设计 寄存器、状态机、流水线 的关键元件。
-
结构 :
与 LUT 常绑定为 Slice (例如 Xilinx 的 CLB 每个 Slice 包含多个 LUT 和 FF)。
FF 包括触发条件(如上升沿/下降沿)和复位/置位功能。
-
特点:
- 时序控制:保证数据在时钟边沿稳定传输。
- 资源平衡:FF 的利用率直接影响时序收敛(如时钟频率)。
-
示例 :
流水线架构中,每级流水线需要 FF 暂存中间结果。
4.三者的资源占用关系
-
算法决定资源分配
- 计算密集型任务(如矩阵乘法)会消耗大量 DSP。
- 复杂逻辑和条件判断依赖 LUT。
- 时序控制和数据缓冲需要 FF。
-
资源总量限制
FPGA 芯片中 DSP/LUT/FF 的数量是固定的 ,设计需确保不超过目标芯片的可用资源。
资源冲突会导致布局布线失败或降低时钟频率。 -
资源优化策略
优化手段 目的 使用 DSP 代替 LUT 实现运算 降低功耗,提升速度 逻辑简化(如状态机优化) 减少 LUT 和 FF 的消耗 流水线设计 平衡 FF 利用率与时钟频率 代码重构(HLS中) 避免生成冗余逻辑
5.在 Vivado HLS 中的应用
-
DSP 的使用 :
若代码中的循环或函数包含乘法/累加操作,HLS 会优先调用 DSP,也可通过
#pragma HLS BIND_OP强制指定实现方式。 -
LUT 与 FF 的平衡 :
HLS 会根据代码生成组合逻辑(LUT)和时序逻辑(FF),通过
#pragma HLS PIPELINE或调节时钟频率优化两者的分配。 -
资源报告 :
综合后查看资源利用率报告,分析是否需重构代码或调整约束。
6.总结
- DSP 是高性能运算的"加速引擎",用于数学密集型任务。
- LUT 是实现灵活逻辑的基础单元,但易成为性能瓶颈。
- FF 是时序逻辑的基石,影响设计的时钟频率和稳定性。
合理规划和优化这三者的使用,是 FPGA 设计的关键!
4.修改数据的类型
4.1 将float 改为 int
代码如下将float 改为 int
#include "vector_add.h"
#define MAXNUM 50000
void vertor_add_top (int A[MAXNUM] , int B[MAXNUM] , int C[MAXNUM]) {
for (int i=0 ; i <MAXNUM ; i++)
C[i] =A[i] +B[i];
}下面是报告
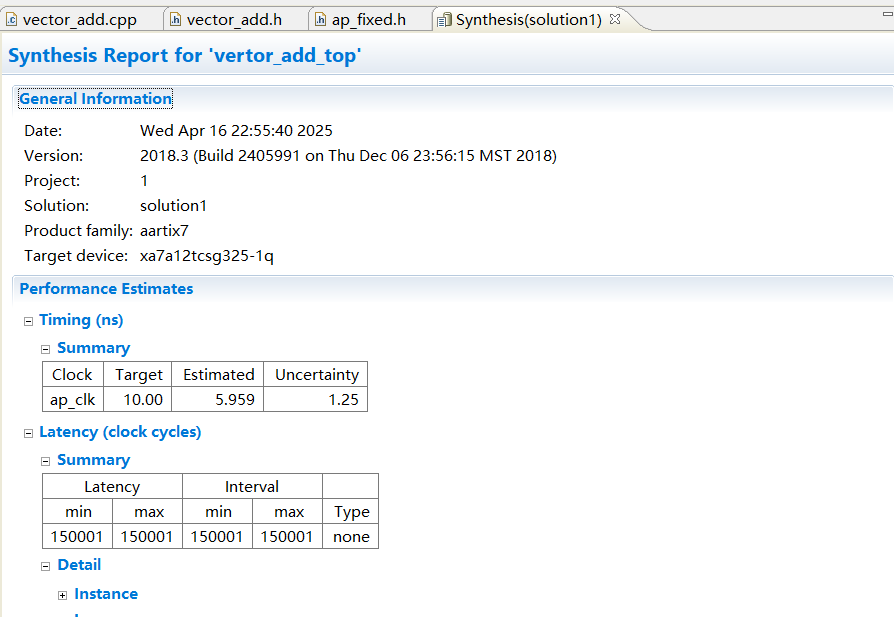
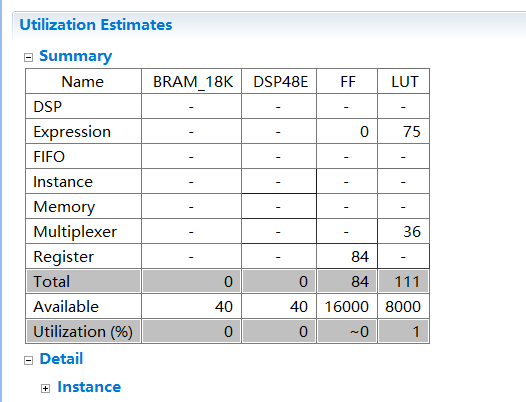
根据上图可以计算总得时间连1ms都不到
4.2 将int改为自定义的定点型数据
代码如下:
#include "ap_fixed.h"
typedef ap_fixed<32 , 16 , AP_RND,AP_SAT> D32;
#include "vector_add.h"
#define MAXNUM 50000
void vertor_add_top (D32 A[MAXNUM] , D32 B[MAXNUM] , D32 C[MAXNUM]) {
for (int i=0 ; i <MAXNUM ; i++)
C[i] =A[i] +B[i];
}这里是 typedef ap_fixed<32 , 16 , AP_RND,AP_SAT> D32;
typedef是自定义类型 名字叫ap_fixed 总共有32为 16位的整数,剩下的AP_RND为小数部分,AP_SAT这个是溢出类型应该,归一。
分析报告
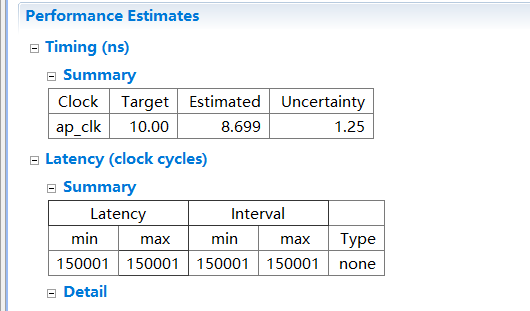
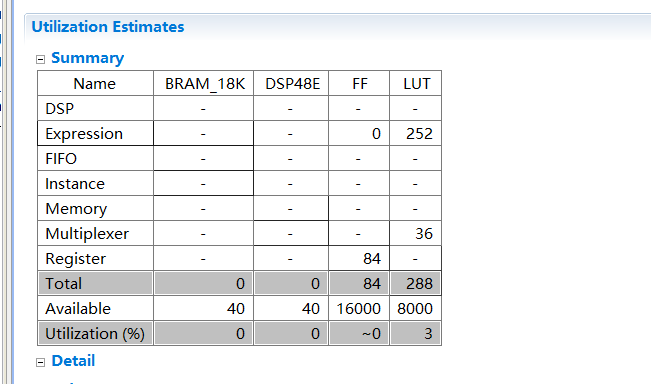
可以算出时间比int多,但是比float少
总结:根据上述实验可以知道,int和自定义的类型没有用到dsp 浮点数用到了dsp、时间dloat > d32>int
二(并行加速)
1代码unroll
选中代码,然后点开右边的directive
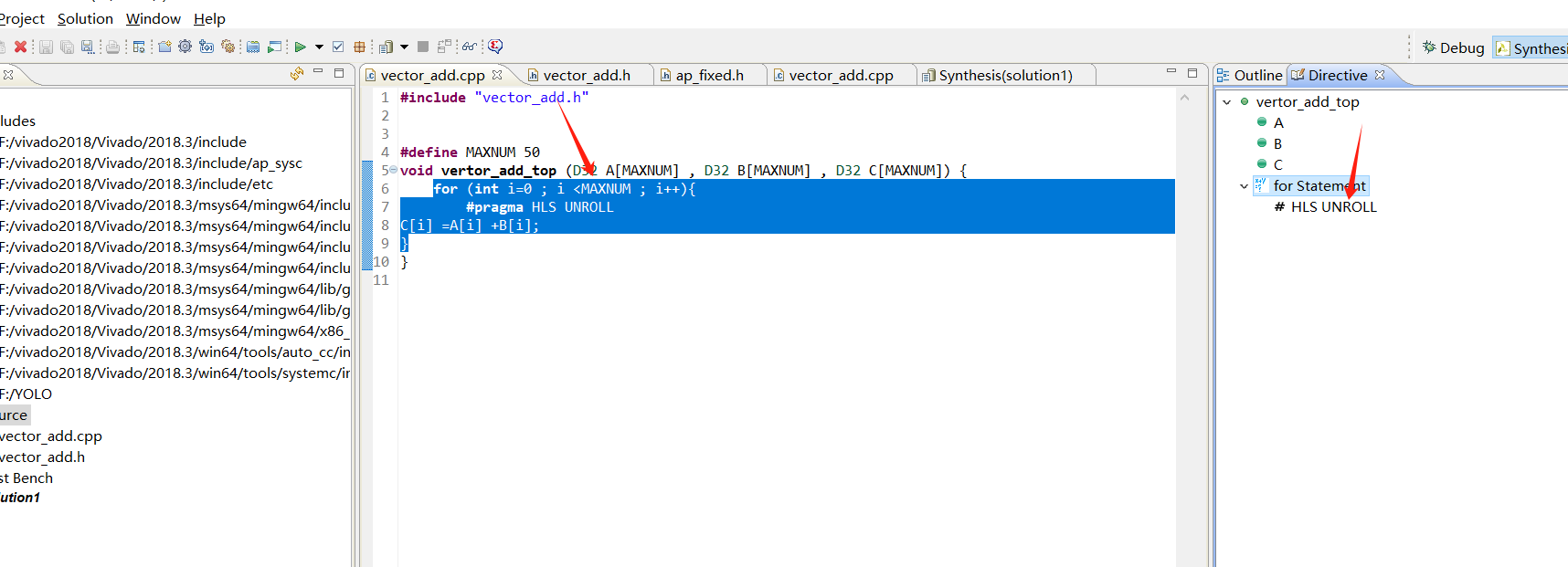
然后找到for statement 右击
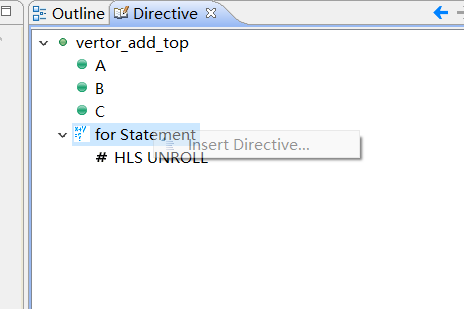
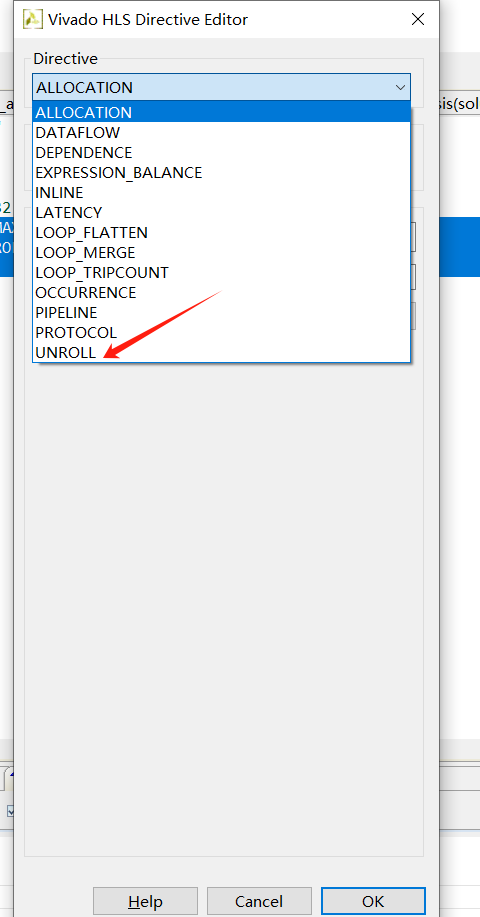
选择 将并行插入到代码中点击ok
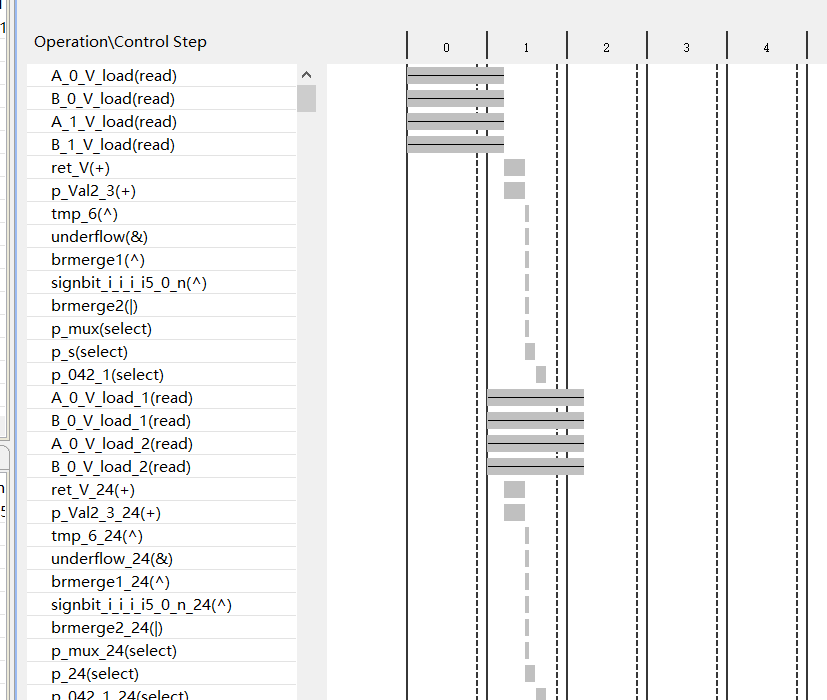
可以看到一部分并行一部分串行还是在串行
可以看到在read还是串行,应为ram 最大就是双端口,50个数很大所以得串行。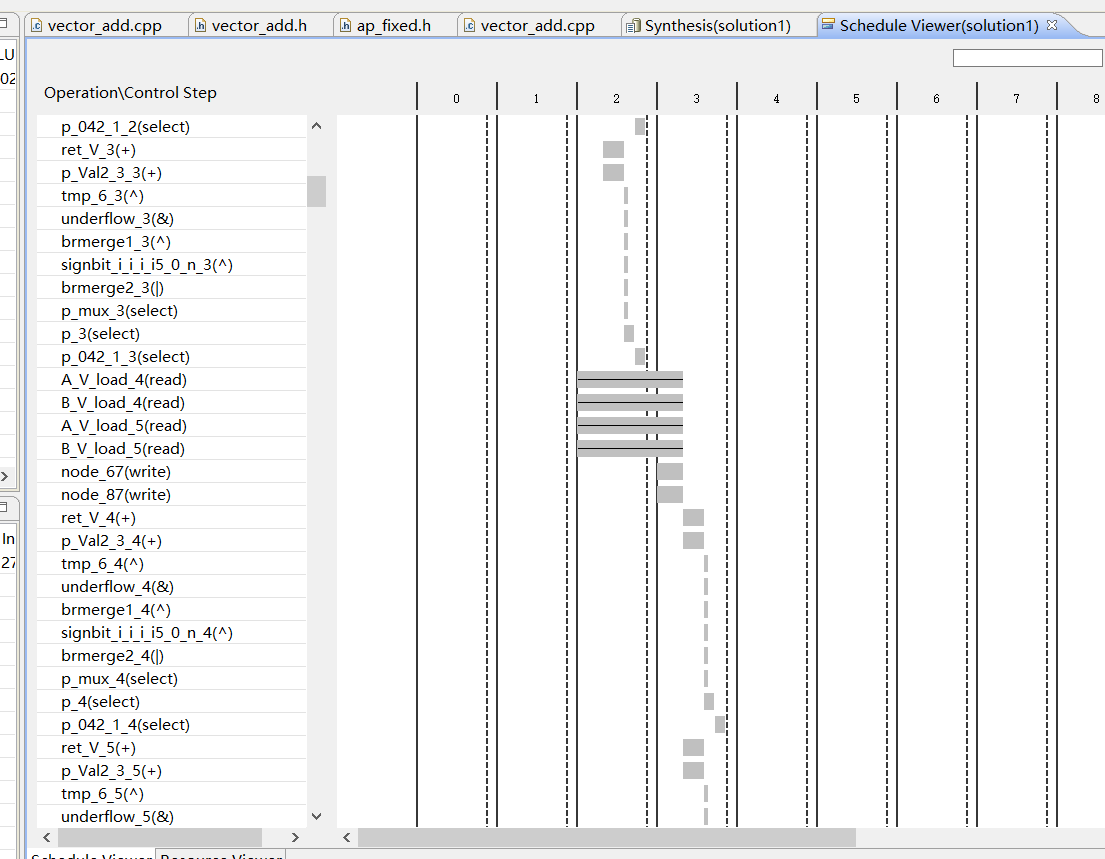
多了一个时钟周期

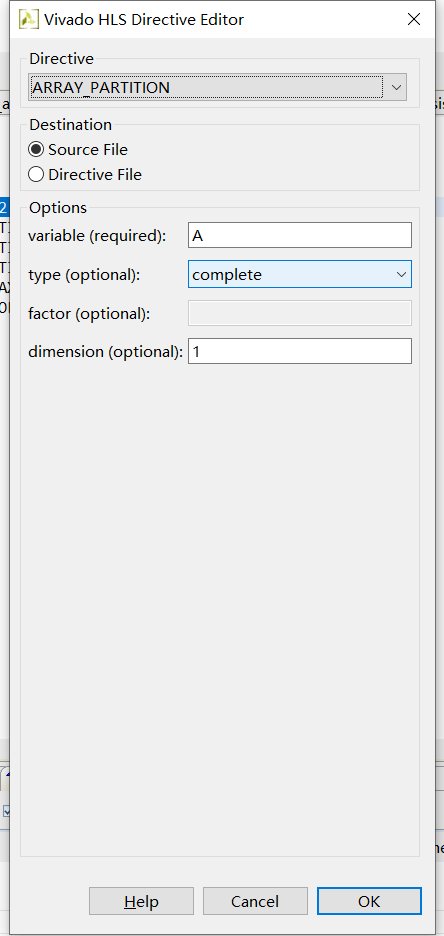
2整个完全展开 代码#pragma HLS ARRAY_PARTITION variable=A complete dim=1
完整代码如下
#include "vector_add.h"
#define MAXNUM 50
void vertor_add_top (D32 A[MAXNUM] , D32 B[MAXNUM] , D32 C[MAXNUM]) {
#pragma HLS ARRAY_PARTITION variable=A complete dim=1
#pragma HLS ARRAY_PARTITION variable=B complete dim=1
#pragma HLS ARRAY_PARTITION variable=C complete dim=1
for (int i=0 ; i <MAXNUM ; i++){
#pragma HLS UNROLL
C[i] =A[i] +B[i];
}
}操作:
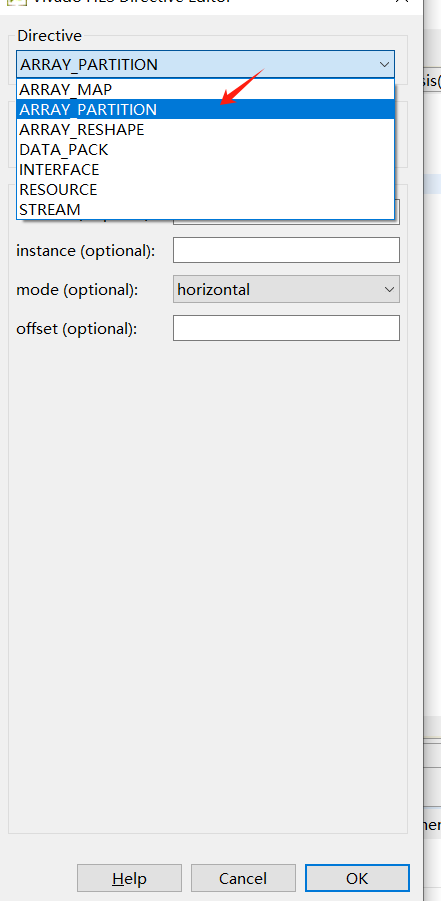
如下找到ABC右击A
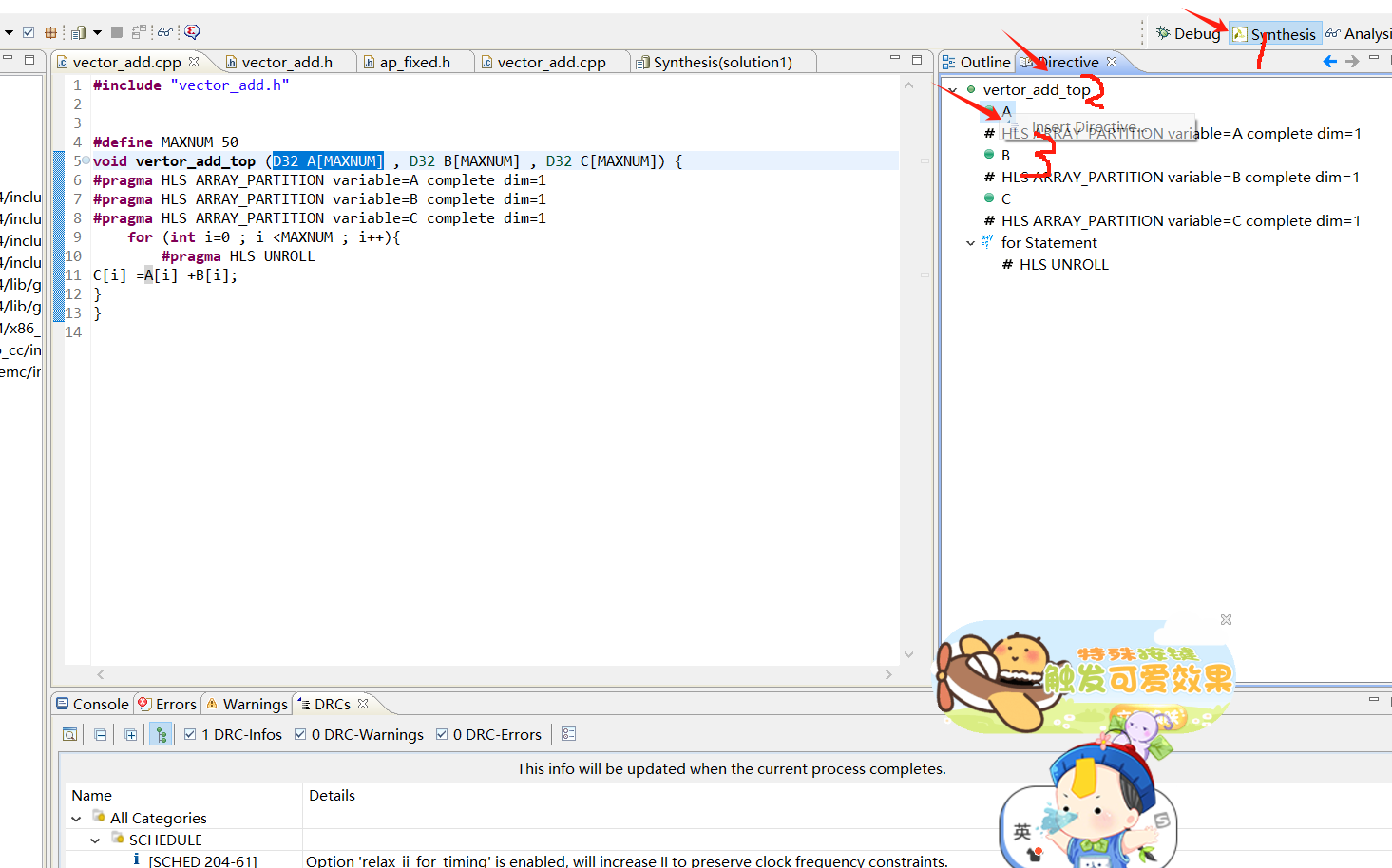
找到ARRAY_PARTITION函数 然后compelte是整体展开
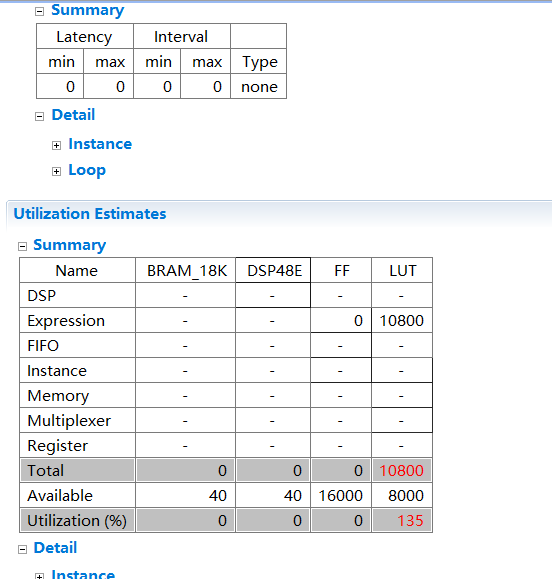
报告分析
我们可以看到只用了组合逻辑电路,其他的都没有用到
3.分块展开
#pragma HLS ARRAY_PARTITION variable=A block factor=2 dim=1
完整代码
#include "vector_add.h" #define MAXNUM 50 void vertor_add_top (D32 A[MAXNUM] , D32 B[MAXNUM] , D32 C[MAXNUM]) { #pragma HLS ARRAY_PARTITION variable=A block factor=2 dim=1 #pragma HLS ARRAY_PARTITION variable=B block factor=2 dim=1 #pragma HLS ARRAY_PARTITION variable=C block factor=2 dim=1 for (int i=0 ; i <MAXNUM ; i++){ #pragma HLS UNROLL C[i] =A[i] +B[i]; } }
选择block 分块因子为2

报告分析
并不是只用了组合逻辑