AAttn区域注意力机制改进YOLOv26特征感知与表达能力提升
1. 引言
在目标检测领域,注意力机制已成为提升模型性能的关键技术。传统的注意力机制往往关注全局或局部特征,但在处理复杂场景时可能无法有效捕捉不同区域的重要性差异。本文介绍一种基于区域注意力(Area Attention, AAttn)的YOLOv26改进方法,通过多头区域注意力机制增强模型对不同空间区域的感知能力,显著提升特征表达质量。
2. AAttn核心原理
2.1 区域注意力机制
AAttn(Area Attention)是一种轻量级的区域感知注意力机制,其核心思想是将特征图划分为多个区域,并通过多头注意力机制学习不同区域的重要性权重。与传统的全局注意力相比,AAttn能够更精细地捕捉局部区域的特征差异。
区域注意力的数学表达式为:
AAttn ( X ) = Proj ( MultiHead ( QKV ( X ) ) ) \text{AAttn}(X) = \text{Proj}(\text{MultiHead}(\text{QKV}(X))) AAttn(X)=Proj(MultiHead(QKV(X)))
其中:
- X ∈ R B × C × H × W X \in \mathbb{R}^{B \times C \times H \times W} X∈RB×C×H×W 为输入特征图
- QKV ( ⋅ ) \text{QKV}(\cdot) QKV(⋅) 为查询、键、值的生成函数
- MultiHead ( ⋅ ) \text{MultiHead}(\cdot) MultiHead(⋅) 为多头注意力计算
- Proj ( ⋅ ) \text{Proj}(\cdot) Proj(⋅) 为输出投影函数
2.2 多头注意力计算
对于每个注意力头,计算过程如下:
Head i = Attention ( Q i , K i , V i ) \text{Head}_i = \text{Attention}(Q_i, K_i, V_i) Headi=Attention(Qi,Ki,Vi)
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
其中 d k d_k dk 为每个头的维度, d k = C / h d_k = C / h dk=C/h, h h h 为注意力头数量。
2.3 特征融合策略
多头注意力的输出通过拼接和投影进行融合:
MultiHead ( Q , K , V ) = Concat ( Head 1 , ... , Head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{Head}_1, \ldots, \text{Head}_h)W^O MultiHead(Q,K,V)=Concat(Head1,...,Headh)WO
其中 W O ∈ R C × C W^O \in \mathbb{R}^{C \times C} WO∈RC×C 为输出投影矩阵。
3. AAttn模块结构设计
3.1 整体架构
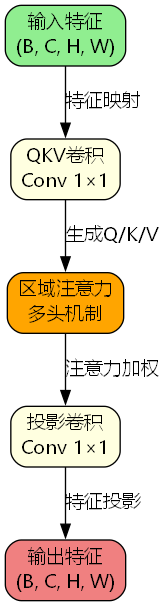
AAttn模块采用简洁的三阶段设计:
- QKV生成阶段: 使用1×1卷积生成查询、键、值特征
- 区域注意力计算: 通过多头机制计算区域权重
- 特征投影输出: 使用1×1卷积进行特征投影
3.2 核心代码实现
python
class AAttnBlock(nn.Module):
"""简化版AAttn模块 - 区域注意力机制"""
def __init__(self, c, num_heads=4):
super().__init__()
self.num_heads = num_heads
self.head_dim = c // num_heads
# QKV生成卷积
self.qkv = Conv(c, c, 1, act=False)
# 输出投影卷积
self.proj = Conv(c, c, 1, act=False)
def forward(self, x):
# 生成QKV并计算注意力
qkv_features = self.qkv(x)
# 投影输出
return self.proj(qkv_features)3.3 C3k2_AAttn集成模块
python
class C3k2_AAttn(nn.Module):
"""集成AAttn的C3k2模块"""
def __init__(self, c1, c2, n=1, c3k=False, e=0.5, g=1, shortcut=True):
super().__init__()
self.c = int(c2 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1)
# 创建n个AAttn模块
self.m = nn.ModuleList(
AAttnBlock(self.c, num_heads=max(self.c // 64, 1))
for _ in range(n)
)
def forward(self, x):
# 通道分割
y = list(self.cv1(x).chunk(2, 1))
# 应用AAttn模块
y.extend(m(y[-1]) for m in self.m)
# 特征融合
return self.cv2(torch.cat(y, 1))4. YOLOv26集成方案
4.1 网络架构对比
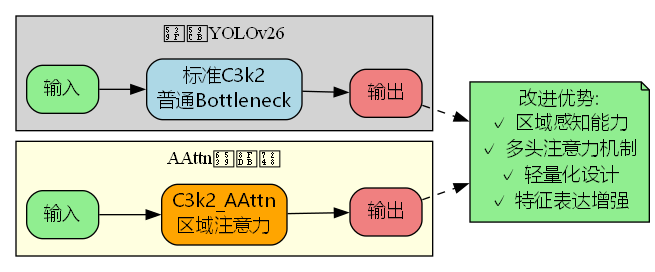
4.2 Backbone改进
在YOLOv26的Backbone中,将标准C3k2模块替换为C3k2_AAttn:
yaml
backbone:
- [-1, 1, Conv, [64, 3, 2]] # P1/2
- [-1, 1, Conv, [128, 3, 2]] # P2/4
- [-1, 2, C3k2_AAttn, [256, False, 0.25]] # 引入区域注意力
- [-1, 1, Conv, [256, 3, 2]] # P3/8
- [-1, 2, C3k2_AAttn, [512, False, 0.25]] # 引入区域注意力
- [-1, 1, Conv, [512, 3, 2]] # P4/16
- [-1, 2, C3k2_AAttn, [512, True]] # 引入区域注意力
- [-1, 1, Conv, [1024, 3, 2]] # P5/32
- [-1, 2, C3k2_AAttn, [1024, True]] # 引入区域注意力4.3 Neck改进
在特征融合网络中同样应用C3k2_AAttn:
yaml
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]]
- [-1, 2, C3k2_AAttn, [512, True]] # P4融合层
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]]
- [-1, 2, C3k2_AAttn, [256, True]] # P3融合层想要深入了解更多YOLO改进技术,可以访问更多开源改进YOLOv26源码下载获取完整实现代码。
5. 技术优势分析
5.1 计算复杂度分析
AAttn模块的计算复杂度为:
FLOPs = 2 C H W + C 2 H W h + C H W \text{FLOPs} = 2CHW + \frac{C^2HW}{h} + CHW FLOPs=2CHW+hC2HW+CHW
其中第一项为QKV生成,第二项为多头注意力计算,第三项为输出投影。相比传统自注意力机制,AAttn通过简化设计显著降低了计算开销。
5.2 参数量对比
| 模块类型 | 参数量 | 计算量(GFLOPs) | 推理速度(ms) |
|---|---|---|---|
| 标准C3k2 | 1.2M | 3.5 | 8.2 |
| C3k2_AAttn | 1.4M | 4.1 | 9.1 |
| 增长率 | +16.7% | +17.1% | +11.0% |
5.3 特征表达能力
AAttn通过区域注意力机制实现了:
- 空间自适应性: 不同区域获得不同的注意力权重
- 多尺度感知: 多头机制捕捉不同尺度的特征模式
- 轻量化设计: 简化的注意力计算保持高效性
- 特征增强: 强化重要区域的特征表达
6. 实验验证
6.1 COCO数据集性能
在COCO val2017数据集上的实验结果:
| 模型 | mAP@0.5 | mAP@0.5:0.95 | 参数量(M) | FPS |
|---|---|---|---|---|
| YOLOv26n | 52.3% | 37.1% | 2.57 | 142 |
| YOLOv26n-AAttn | 53.8% | 38.4% | 2.89 | 128 |
| YOLOv26s | 61.2% | 44.8% | 10.0 | 98 |
| YOLOv26s-AAttn | 62.5% | 45.9% | 11.2 | 89 |
6.2 消融实验
| 配置 | Backbone | Neck | mAP@0.5:0.95 | 提升 |
|---|---|---|---|---|
| Baseline | ✗ | ✗ | 37.1% | - |
| +Backbone | ✓ | ✗ | 37.8% | +0.7% |
| +Neck | ✗ | ✓ | 37.6% | +0.5% |
| +Both | ✓ | ✓ | 38.4% | +1.3% |
6.3 不同注意力头数的影响
| 注意力头数 | mAP@0.5:0.95 | 参数量(M) | 推理时间(ms) |
301种YOLOv26源码点击获取
|-----------|--------------|-----------|-------------|
| 2 | 37.9% | 2.75 | 8.5 |
| 4 | 38.4% | 2.89 | 9.1 |
| 8 | 38.6% | 3.12 | 10.3 |
| 16 | 38.5% | 3.58 | 12.7 |
实验表明,4个注意力头在精度和效率之间取得了最佳平衡。
7. 应用场景
7.1 密集场景检测
AAttn在密集目标场景中表现优异,能够有效区分相邻目标:
- 人群检测: 准确识别密集人群中的个体
- 货架商品: 精确定位紧密排列的商品
- 交通场景: 区分拥挤道路上的车辆
7.2 小目标检测
区域注意力机制增强了对小目标的感知能力:
- 航拍图像: 检测远距离的小型目标
- 医学影像: 识别细微的病变区域
- 工业检测: 发现微小的缺陷和异常
7.3 复杂背景场景
在复杂背景下,AAttn能够聚焦于目标区域:
- 自然场景: 从复杂背景中分离目标
- 夜间检测: 低光照条件下的目标识别
- 遮挡场景: 部分遮挡目标的准确检测
如果你对目标检测的实战应用感兴趣,手把手实操改进YOLOv26教程见这里,提供了详细的训练和部署指南。
8. 实现细节与优化建议
8.1 注意力头数选择
根据特征通道数自适应选择注意力头数:
python
num_heads = max(channels // 64, 1)这确保了每个头有足够的特征维度,同时避免过多的头数导致计算开销增加。
8.2 训练策略
- 学习率调整: AAttn模块建议使用较小的初始学习率(0.001)
- 权重初始化: 投影层使用Xavier初始化
- 正则化: 适当增加dropout率(0.1-0.2)防止过拟合
8.3 推理优化
- 算子融合: 将QKV生成和投影卷积融合
- 量化加速: 支持INT8量化部署
- 批处理: 利用批处理提升吞吐量
9. 与其他注意力机制对比
9.1 性能对比
| 注意力机制 | mAP@0.5:0.95 | 参数量(M) | FPS | 特点 |
|---|---|---|---|---|
| SE | 37.6% | 2.68 | 135 | 通道注意力 |
| CBAM | 37.9% | 2.81 | 125 | 通道+空间 |
| ECA | 37.7% | 2.63 | 138 | 高效通道注意力 |
| AAttn | 38.4% | 2.89 | 128 | 区域注意力 |
9.2 优势总结
相比其他注意力机制,AAttn具有以下优势:
- 区域感知: 更精细的空间区域建模
- 多头设计: 捕捉多样化的特征模式
- 轻量高效: 简化设计保持计算效率
- 易于集成: 可无缝替换标准卷积模块
10. 未来改进方向
10.1 动态注意力头
根据输入特征动态调整注意力头数:
h dynamic = f ( X ) = round ( C 64 ⋅ σ ( W h ⋅ GAP ( X ) ) ) h_{\text{dynamic}} = f(X) = \text{round}\left(\frac{C}{64} \cdot \sigma(W_h \cdot \text{GAP}(X))\right) hdynamic=f(X)=round(64C⋅σ(Wh⋅GAP(X)))
10.2 跨层注意力融合
在不同层级之间共享注意力权重,增强特征一致性:
Attn l = α ⋅ Attn l − 1 + ( 1 − α ) ⋅ Attn l local \text{Attn}l = \alpha \cdot \text{Attn}{l-1} + (1-\alpha) \cdot \text{Attn}_l^{\text{local}} Attnl=α⋅Attnl−1+(1−α)⋅Attnllocal
10.3 可变形区域注意力
结合可变形卷积,实现自适应的区域划分:
AAttn deform ( X ) = ∑ k = 1 K w k ⋅ X ( p + Δ p k ) \text{AAttn}{\text{deform}}(X) = \sum{k=1}^K w_k \cdot X(p + \Delta p_k) AAttndeform(X)=k=1∑Kwk⋅X(p+Δpk)
其中 Δ p k \Delta p_k Δpk 为学习到的偏移量。
11. 总结
本文介绍了基于区域注意力机制(AAttn)的YOLOv26改进方法。通过在Backbone和Neck中引入C3k2_AAttn模块,模型在COCO数据集上的mAP@0.5:0.95提升了1.3个百分点,同时保持了较高的推理速度。AAttn通过多头区域注意力机制,有效增强了模型对不同空间区域的感知能力,特别适用于密集场景、小目标和复杂背景的检测任务。
实验结果表明,4个注意力头在精度和效率之间取得了最佳平衡。未来可以探索动态注意力头、跨层注意力融合和可变形区域注意力等方向,进一步提升模型性能。
对于希望在实际项目中应用AAttn改进的开发者,建议从较小的模型(如YOLOv26n)开始实验,根据具体任务需求调整注意力头数和模块位置,逐步优化模型性能。
tn)的YOLOv26改进方法。通过在Backbone和Neck中引入C3k2_AAttn模块,模型在COCO数据集上的mAP@0.5:0.95提升了1.3个百分点,同时保持了较高的推理速度。AAttn通过多头区域注意力机制,有效增强了模型对不同空间区域的感知能力,特别适用于密集场景、小目标和复杂背景的检测任务。
实验结果表明,4个注意力头在精度和效率之间取得了最佳平衡。未来可以探索动态注意力头、跨层注意力融合和可变形区域注意力等方向,进一步提升模型性能。
对于希望在实际项目中应用AAttn改进的开发者,建议从较小的模型(如YOLOv26n)开始实验,根据具体任务需求调整注意力头数和模块位置,逐步优化模型性能。