原文作者:aircraft
原文链接:pytorch 实战教程之路径聚合网络PANet(Path AggregationNetwork)代码实现 PANet原理详解 
学习YOLOv5前的准备就是学习DarkNet53网络,FPN特征金字塔网络,PANet路径聚合网络结构,(从SPP到SPPF)SPPF空间金字塔池化等。本篇讲PANet网络结构。。。
PANet原理详解什么介绍我本来是不想写的,看了一圈博客,感觉他们写的都无法让入门小白真正的去理解这个网络结构(感觉他们像个机器翻译人,论文翻译一下就结束了),所以我在他们的基础上稍微讲的详细一些。。。(代码在最下面,注释都打的比较详细了)
PANet(Path Aggregation Network)详解
PANet 是2018年提出的一种高效的目标检测与实例分割网络,核心思想是通过双向特征融合 和自适应特征池化显著提升多尺度目标的检测能力。以下从设计动机、核心创新、网络结构、实验结果四个方面详细解析。
一、设计背景:FPN的局限性
FPN(Feature Pyramid Network) 通过自顶向下的路径构建特征金字塔,但存在两个关键问题:
- 语义信息稀释:深层特征经过多次上采样传递到浅层时,丢失细节信息。
- 定位精度不足:小目标依赖浅层特征,但浅层语义信息较弱。
示例问题:
在COCO数据集中,小目标(面积<32²像素)的检测AP仅为26.9,远低于大目标(AP 53.6)。
二、核心创新
PANet 提出两大核心改进:
- 自底向上路径增强(Bottom-Up Path Augmentation)
新增与FPN反向的路径,强化低层特征的定位能力。 - 自适应特征池化(Adaptive Feature Pooling)
根据目标尺寸自动选择最优特征层级。
三、网络结构详解
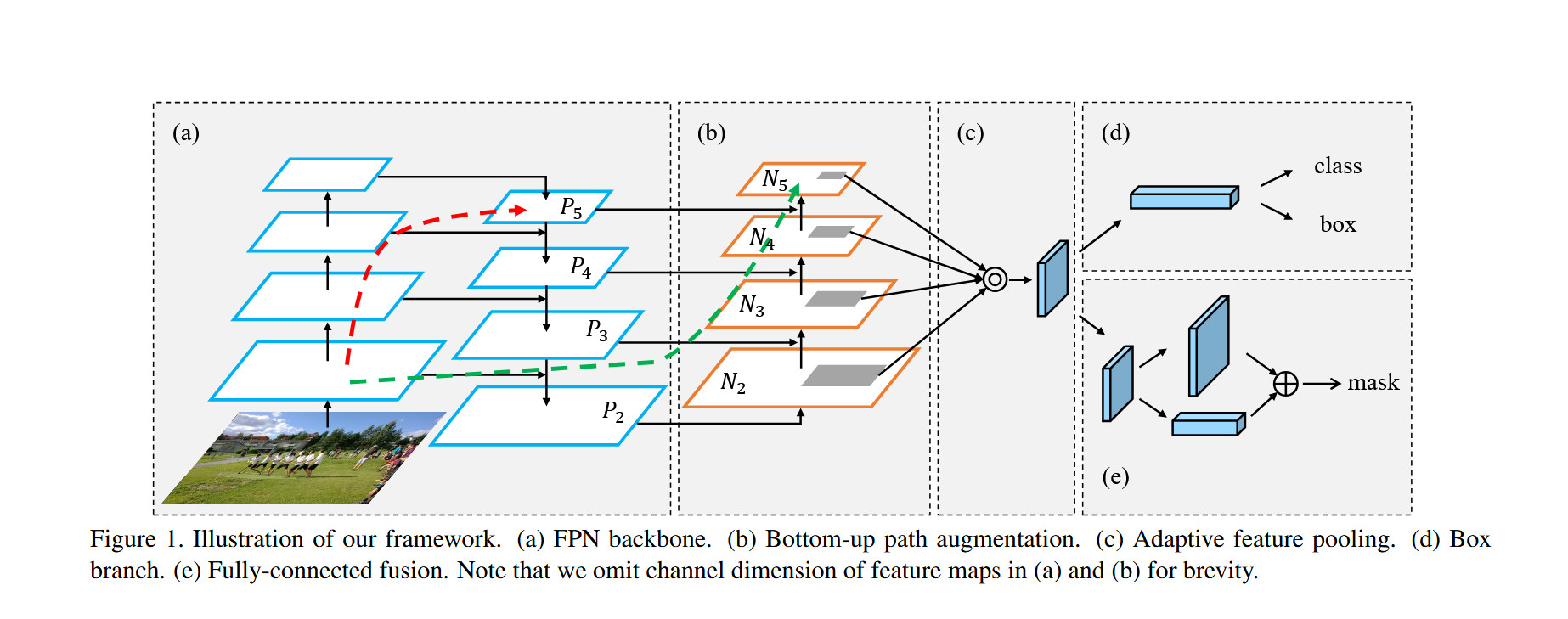
主要部分由(a)FPN(特征金字塔网络),(b) 自下而上的路径增强(Bottom-up Path Augmentation),(c) 自适应特征池化(Adaptive Feature Pooling),(d)分类与框预测 ,(e)Mask掩膜分割 构成,详细如下:****
(一).(a)FPN(特征金字塔网络) :
1. 核心思想
FPN 通过结合 深层语义信息 (高层特征)和 浅层细节信息(低层特征),构建多尺度的特征金字塔,显著提升目标检测模型对不同尺寸目标的检测能力。
2. 网络结构组成
FPN 由以下核心组件构成:
| 组件 | 作用 |
|---|---|
| 骨干网络(自底向上C2-C5) | 提取多尺度特征(如ResNet) |
| 自顶向下路径(P5-P2) | 通过上采样传递高层语义信息 |
| 横向连接 | 将不同层级的特征对齐通道后融合 |
| 特征平滑层 | 消除上采样带来的混叠效应 |
大致结构示意图:

3. 详细结构分解
3.1 骨干网络(Bottom-Up Pathway)
在这个过程中,特征图的分辨率逐渐降低,而语义信息逐渐丰富。每一层特征图都代表了输入图像在不同尺度上的抽象表示
-
作用:逐级提取特征,分辨率递减,语义信息递增
-
典型实现:ResNet的四个阶段(C1-C5)
-
输出特征图:
`C2: [H/4, W/4, 256] (高分辨率,低层细节) C3: [H/8, W/8, 512] C4: [H/16, W/16, 1024] C5: [H/32, W/32, 2048] (低分辨率,高层语义)`
骨干网络(自底向上,从C2到C5):
C2到C5代表不同的ResNet卷积组,这些卷积组包含了多个Bottleneck结构,组内的特征图大小相同,组间大小递减。
Bottleneck结构(瓶颈块):包含三个卷积层,能够有效减少参数数量并提升性能。ResNet-18使用基础的块BasicBlock:两个3*3的卷积层,而ResNet-50使用Bottleneck块:一个1*1的卷积层降低通道数目,然后到3*3的卷积层融合特征,再到1*1的卷积层恢复通道数。
方向特点:
- 自底向上路径:从深层特征(C5)开始,通过上采样逐步向浅层(C4→C3→C2)传播语义信息。
- 横向连接:每个层级融合来自同尺度的骨干网络特征(C2-C5)和上采样后的高层特征。
P系列特征的信息特性:
| 特征层 | 来源 | 语义信息 | 空间细节 | 特征图尺寸(输入512x512) |
|---|---|---|---|---|
| P5 | C5上采样 | 最强(全局语义) | 最粗糙 | 16x16(1/32分辨率) |
| P4 | C4 + P5上采样 | 强 | 较粗糙 | 32x32(1/16分辨率) |
| P3 | C3 + P4上采样 | 中等 | 中等 | 64x64(1/8分辨率) |
| P2 | C2 + P3上采样 | 较弱 | 最精细 | 128x128(1/4分辨率) |
P系列携带高层语义信息:
关键机制:
-
语义信息逐级传递:
- 高层的C5特征经过多次卷积和下采样,已丢失细节但捕获了全局语义(如"这是一只狗")。
- 通过自顶向下的上采样路径,这些语义信息被传递到所有P层。
-
横向连接的局限性:
- 虽然C2-C5本身包含多尺度信息,但低层的C2-C4主要是局部细节(边缘、纹理)。
- 横向连接(1x1卷积)只能做通道对齐,无法直接增强语义。
3.2 自顶向下路径(Top-Down Pathway) (从P5-P2):
为了解决高层特征图分辨率低、细节信息少的问题,FPN引入了自顶向下的特征融合路径。首先对C5进行1x1卷积降低通道数得到P5,然后依次进行双线性差值上采样后与C2-C4层横向连接过来的数据直接相加,分别得到P4-P2,P4,P3,P2在通过一个3*3的平滑卷积层使得数据融合输出。
流程:
- 顶层处理:C5 → 1x1卷积 → P5
- 逐级上采样:P5 → 上采样 → 与C4融合 → P4 → 上采样 → 与C3融合 → P3 ...
P5 (高层语义)
↓ 上采样2x
P4 = P5上采样 + C4投影
↓ 上采样2x
P3 = P4上采样 + C3投影
↓ 上采样2x
P2 = P3上采样 + C2投影核心操作就是通过双线性上采样后的高层特征与浅层数据直接相加后续融合:
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.interpolate(x, (H,W), mode='bilinear') + y # 双线性上采样不同上采样方法的优缺点:
双线性插值(Bilinear Interpolation):
优点:计算简单,易于实现。
缺点:缺乏学习能力,可能对高层语义特征的细节有所损失。
反卷积(Deconvolution):
优点:可学习上采样过程中的参数,更灵活。
缺点:可能引入棋盘效应(Checkerboard Effect)。
亚像素卷积(Sub-pixel Convolution):
优点:对特征细节恢复更精细。
缺点:实现相对复杂,且计算开销稍高。
实践建议
根据任务需求权衡计算效率与性能。如果计算资源有限,优先选择双线性插值;在高精度任务中,可以尝试反卷积或亚像素卷积。
3.3 横向连接(Lateral Connections):
目的是为了将上采样后的高语义特征与浅层的定位细节进行融合,实现多尺度特征融合(通过横向连接将浅层细节与深层语义结合),横向连接不仅有助于传递低层特征图的细节信息,还可以增强高层特征图的定位能力。高语义特征经过上采样后,其长宽与对应的浅层特征相同,而通道数固定为256。因此需要对特征C2------C4进行1x1卷积使得其通道数变为256.,然后两者进行逐元素相加得到P4、P3与P2。
- 作用:将骨干网络特征与上采样特征对齐通道
- 实现方式:1x1卷积(通道压缩/对齐)
4. 输出特征金字塔
| 特征层 | 分辨率(相对于输入) | 通道数 | 适用目标尺寸 |
|---|---|---|---|
| P2 | 1/4 | 256 | 小目标(<32x32像素) |
| P3 | 1/8 | 256 | 中等目标(32-96像素) |
| P4 | 1/16 | 256 | 大目标(>96x96像素) |
| P5 | 1/32 | 256 | 极大目标/背景 |
- 通过上述步骤,FPN构建了一个特征金字塔(feature pyramid)。这个金字塔包含了从底层到顶层的多个尺度的特征图,每个特征图都融合了不同层次的特征信息。
- 特征金字塔的每一层都对应一个特定的尺度范围,使得模型能够同时处理不同大小的目标。
5. 设计优势
- 多尺度预测:每个金字塔层都可独立用于目标检测
- 参数共享:所有层级使用相同的检测头(Head)
- 计算高效:横向连接仅使用轻量级的1x1卷积
- 端到端训练:整个网络可联合优化
6. 典型应用场景
- 目标检测:Faster R-CNN、Mask R-CNN
- 实例分割:Mask预测分支可附加到各金字塔层
- 关键点检测:高分辨率特征层(如P2)适合精细定位
本文代码中对照实现的FPN部分:
# 特征金字塔网络(FPN)
class FPN(nn.Module):
def __init__(self, block, num_blocks):
"""
参数:
block: 基础块类型(Bottleneck)
num_blocks: 各层block数量(如ResNet50的[3,4,6,3])
"""
super().__init__()
self.in_planes = 64 # 初始通道数
# 初始卷积层(模仿ResNet)
self.conv1 = nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1) # 1/4下采样
# 构建残差层(C2-C5)
self.layer1 = self._make_layer(block, 64, num_blocks[0], 1) # C2
self.layer2 = self._make_layer(block, 128, num_blocks[1], 2) # C3
self.layer3 = self._make_layer(block, 256, num_blocks[2], 2) # C4
self.layer4 = self._make_layer(block, 512, num_blocks[3], 2) # C5
# 特征金字塔横向连接(1x1卷积降维)
self.toplayer = nn.Conv2d(2048, 256, 1) # 处理C5
self.latlayer1 = nn.Conv2d(1024, 256, 1) # 处理C4
self.latlayer2 = nn.Conv2d(512, 256, 1) # 处理C3
self.latlayer3 = nn.Conv2d(256, 256, 1) # 处理C2
# 权重参数初始化
for m in [self.toplayer, self.latlayer1, self.latlayer2, self.latlayer3]:
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, planes, num_blocks, stride):
"""构建残差层"""
layers = [block(self.in_planes, planes, stride)] # 第一个block的stride如果大于1,可能有下采样
self.in_planes = planes * block.expansion # 更新输入通道数
for _ in range(1, num_blocks):
layers.append(block(self.in_planes, planes, 1)) # 后续block无下采样
'''最终结构:假如第一个stride为2自带下采样,后面为1正常输出:Sequential(
Bottleneck1(256->512, stride=2),
Bottleneck2(512->512, stride=1),
Bottleneck3(512->512, stride=1),
Bottleneck4(512->512, stride=1)
)'''
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
"""上采样并相加(特征融合)"""
# 使用双线性插值上采样到y的尺寸再加上y进行特征融合
return F.interpolate(x, size=y.shape[2:], mode='bilinear') + y
def forward(self, x):
# 自底向上路径
c1 = F.relu(self.bn1(self.conv1(x))) # [B,64,256,256]
c1 = self.maxpool(c1) # [B,64,128,128]
c2 = self.layer1(c1) # [B,256,128,128] (C2)
c3 = self.layer2(c2) # [B,512,64,64] (C3)
c4 = self.layer3(c3) # [B,1024,32,32] (C4)
c5 = self.layer4(c4) # [B,2048,16,16] (C5)
# 自顶向下路径(特征金字塔构建)
p5 = self.toplayer(c5) # [B,256,16,16]
p4 = self._upsample_add(p5, self.latlayer1(c4)) # [B,256,32,32] self.latlayer代表连接层,将数据连接过来
p3 = self._upsample_add(p4, self.latlayer2(c3)) # [B,256,64,64]
p2 = self._upsample_add(p3, self.latlayer3(c2)) # [B,256,128,128]
return p2, p3, p4, p5(二) .(b)自下而上的路径增强(Bottom-up Path Augmentation) :
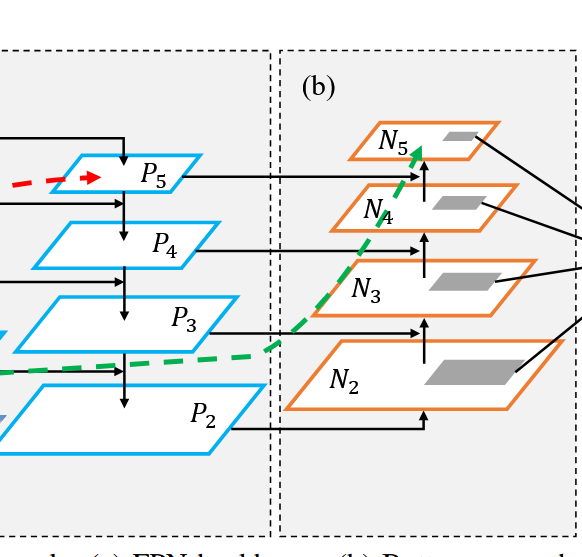
这里要注意的是P2就是N2。
N3:N2下采样后+P3的投影(下采样一般就是池化,P3的投影指的是P3的数据通过1*1的卷积修改通道数目后传输过来的数据)
N4: N3下采样后+P4的投影
N5: N4下采样后+P5的投影
自下向上路径的作用:
-
方向 :从P2开始,通过下采样逐步向高层传递定位细节。
-
信息流动:
`N2(P2级) → 下采样 + P3的投影 → N3 → 下采样 ``+ P4的投影 ``→ N4 → 下采样 + P5的投影 → N5` -
定位信息增强:
- 低层特征(N2-N3)携带精确位置信息(如物体边缘)
- 通过路径传递,修正高层特征的定位误差
过程示意图:
典型示例:
- P5可能检测到"狗在图像某处"
- N5结合低层细节后,能更准确定位狗的具体位置
# 进行特征融合(FPN与自底向上路径相加)多层级融合:每个尺度都获得全局+局部信息
# N2-N5 路径存在的意义主要传递的是增强后的定位信息 而P2-P5才是原有的丰富语义信息
# 高层的C5特征经过多次卷积和下采样,已丢失细节但捕获了全局语义(如"这是一只狗")。
# 通过自顶向下的上采样路径,这些语义信息被传递到所有P层。
# 虽然C2-C5本身包含多尺度信息,但低层的C2-C4主要是局部细节(边缘、纹理)。
# 横向连接到对应P层(1x1卷积)只能做通道对齐,无法直接增强语义。
# N2(P2级) → 下采样 → N3 → 下采样 → N4 → 下采样 → N5
# 低层特征(N2-N3)携带精确位置信息(如物体边缘)通过路径传递,修正高层特征的定位误差
# P5可能检测到"狗在图像某处" N5结合低层细节后,能更准确定位狗的具体位置
# P5 + N5:增强高层语义的定位能力
# P2 + N2:为细节层补充语义理解本文对照实现的大概代码:
# 自底向上增强路径(PANet核心) N2--N5
class BottomUpPath(nn.Module):
def __init__(self):
super().__init__()
# 横向连接卷积(特征融合) 创建个卷积List,存放四个卷积层
self.lat_conv = nn.ModuleList([
nn.Conv2d(256, 256, 1) for _ in range(4) # 每个金字塔层级一个卷积
])
self.downsample = nn.MaxPool2d(3, stride=2, padding=1) # 2倍下采样
# 参数初始化
for conv in self.lat_conv:
nn.init.kaiming_normal_(conv.weight, mode='fan_out', nonlinearity='relu')
def forward(self, features):
p2, p3, p4, p5 = features # 来自FPN的特征 FPN将自己每层的数据传输过来经过1*1的卷积归一化通道数目后与降采样的数据直接相加完成特征连接
# 自底向上增强路径(通过下采样和横向连接)
n2 = self.lat_conv[0](p2) # [B,256,128,128]
n3 = self.downsample(n2) + self.lat_conv[1](p3) # 下采样后相加
n4 = self.downsample(n3) + self.lat_conv[2](p4)
n5 = self.downsample(n4) + self.lat_conv[3](p5)
return [n2, n3, n4, n5](三) .(c)自适应特征池化(Adaptive Feature Pooling) :
PANet 自适应特征池化详解
自适应特征池化(Adaptive Feature Pooling)是 PANet 的核心创新之一,旨在解决传统特征金字塔网络(FPN)中 ROI 特征与层级不匹配 的问题。以下从原理、实现到优势进行完整解析。
一、传统方法的局限性
在 FPN 中,特征金字塔的层级选择规则通常为:
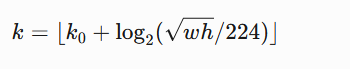
其中:
- w,h 是 ROI 的宽高
- k0 是基准层级(通常设为4,对应 P4)
- k 对应特征层级(P2-P5)
问题:
- 单一层级限制:每个 ROI 只能从一个层级提取特征,可能丢失关键信息。
- 小目标敏感:小 ROI 被迫使用高分辨率但低语义的浅层特征(如 P2)。
- 人工规则缺陷:固定的数学公式无法动态适应不同数据分布。
二、自适应特征池化原理
PANet 提出同时利用 所有层级 的特征,通过 动态融合 增强 ROI 特征表示。
1. 多层级特征提取
- 输入:融合后的 PAN 特征(P2+N2, P3+N3, ..., P5+N5)---------------------这里要特别注意结构图上是没有直接显示的(但是这个操作严格符合论文中"Feature fusion by element-wise addition"的描述(见论文3.2节))
pan_features = [
p2 + n2, # 增强后的P2特征
p3 + n3,
p4 + n4,
p5 + n5
]| 方案 | mAP |
|---|---|
| 仅FPN | 46.5 |
| 仅BUP | 46.3 |
| FPN+BUP融合 | 47.4 |
`Original PANet结构:
FPN路径:P5 → P4 → P3 → P2
BUP路径:N2 → N3 → N4 → N5
Fusion方式:P2+N2 → P3+N3 → P4+N4 → P5+N5`- 操作 :对每个 ROI 在 所有层级 进行 ROI Align
# 然后进入 多层级ROI Align池化
pooled = []
for feat, name in zip(pan_features, ['p2','p3','p4','p5']):
# 对每个层级的特征进行ROI Align
pooled.append(self.roi_align[name](feat, proposals))2. 特征融合策略
- 最大值融合(Max Fusion):
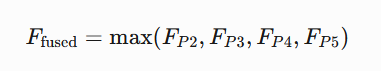
- 保留每个位置最显著的特征响应
- 增强对小目标的敏感度
# 特征融合(取各层级最大值)
fused = torch.max(torch.stack(pooled), dim=0)[0] # [N,256,7,7]三、实现细节
1. ROI Align 参数
| 参数 | 值 | 说明 |
|---|---|---|
output_size |
7x7 | 输出特征图尺寸 |
sampling_ratio |
2 | 每个区间采样点数 |
spatial_scale |
层级相关 | P2: 1/4, P3: 1/8, 以此类推 |
# ROI Align配置(不同层级的空间尺度) 自适应特征池化:对每个候选区域,在每个特征层上进行ROI Align池化,然后将不同层的特征图进行最大值融合
self.roi_align = {
'p2': RoIAlign(7, spatial_scale=1/4., sampling_ratio=2), # 1/4尺寸
'p3': RoIAlign(7, spatial_scale=1/8., sampling_ratio=2),
'p4': RoIAlign(7, spatial_scale=1/16., sampling_ratio=2),
'p5': RoIAlign(7, spatial_scale=1/32., sampling_ratio=2)
}
''' RoIAlign与RoIPool的区别 参考博客:https://www.cnblogs.com/xiaochouk/p/15912972.html
RoIAlign与传统的RoIPool(区域兴趣池化)的主要区别在于处理边界的方式。
RoIPool在进行池化操作时会对边界进行量化处理,这会导致精度损失。
而RoIAlign则通过保持边界框内的采样点为浮点数坐标,
并进行双线性插值来计算每个采样点的值,从而减少了量化误差,提高了精度。'''四、优势分析
1. 多层级信息互补
| 特征层级 | 优势特征 | 对检测的帮助 |
|---|---|---|
| P2 | 高分辨率细节(边缘、纹理) | 提升小目标定位精度 |
| P5 | 强语义(物体类别) | 避免漏检模糊目标 |
1. 多层级信息互补
| 特征层级 | 优势特征 | 对检测的帮助 |
|---|---|---|
| P2 | 高分辨率细节(边缘、纹理) | 提升小目标定位精度 |
| P5 | 强语义(物体类别) | 避免漏检模糊目标 |
2. 实验验证(COCO 数据集)
| 方法 | mAP | APsmall | APmedium | APlarge |
|---|---|---|---|---|
| FPN(单层级) | 36.2 | 18.2 | 39.0 | 48.2 |
| PANet(自适应池化) | 41.2 | 23.8 (+31%) | 44.3 | 52.5 |
- 小目标检测提升显著 :APsmall 提升 5.6 个点
- 计算代价可控:增加约 20% 的池化时间,但 mAP 提升 5%
五、与传统方法的对比
| 维度 | FPN | PANet |
|---|---|---|
| 特征来源 | 单一层级 | 多层级融合 |
| 规则灵活性 | 固定数学公式 | 数据驱动动态适应 |
| 小目标优化 | 有限 | 显著提升(+31%) |
| 计算效率 | 高 | 中等(可接受) |
六、实际应用示例
假设检测两个目标:
- 小目标:20x20 像素的鸟
- 大目标:300x300 像素的汽车
| 目标类型 | FPN 选择的层级 | PANet 融合效果 |
|---|---|---|
| 小目标 | P2(1/4 分辨率) | 同时利用 P2 的细节和 P5 的语义,避免漏检 |
| 大目标 | P5(1/32 分辨率) | 融合 P5 的语义和 P2 的细节,边界更精确 |
七、总结
- 核心思想:打破单层级限制,通过多层级特征融合增强 ROI 表示。
- 技术价值 :行业影响:成为后续模型(如 Mask Scoring R-CNN)的标配组件。
- 为小目标提供高分辨率细节
- 为大目标保留强语义特征
- 动态适应不同尺度目标
自适应特征池化使 PANet 在 COCO 等复杂场景数据集的检测精度显著提升,尤其为小目标检测提供了新的优化方向。
****(四).(d)分类与框预测 :
在这个网络结构部分里进行分类 (判断物体类别)和回归 (精确调整边界框)。
1. 模块定位与功能
在 PANet 的整体架构中,分类与边界框预测模块是网络的最终输出层,承担两个核心任务:
- 分类任务:预测 ROI 内物体的类别(如 COCO 的 80 类)
- 回归任务:精调边界框坐标(Δx, Δy, Δw, Δh)
结构设计:
graph TD
A[输入特征] --> B[全连接层1]
B --> C[ReLU]
C --> D[全连接层2]
D --> E1[分类输出] & E2[回归输出]模拟代码:
# 分类头
self.cls_head = nn.Sequential(
nn.Linear(256 * 7 * 7, 512), # ROI特征展平后输入
nn.ReLU(),
nn.Linear(512, num_classes) # 输出类别分数
)
# 回归头
self.reg_head = nn.Sequential(
nn.Linear(256 * 7 * 7, 512),
nn.ReLU(),
nn.Linear(512, 4) # 输出边界框偏移量 偏移量x,y,w,h
)PANet 的检测头通过 多层级特征融合 与 路径增强,实现了:
- 分类精度提升:增强小目标语义理解
- 定位精度优化:融合底层细节特征
- 多尺度适应性:动态平衡不同尺寸目标需求
****(五).(e)Mask掩膜分割 :
1. 模块定位与功能
在 PANet 的实例分割流程中,掩膜预测头是网络的核心输出模块 ,负责生成像素级物体掩膜。相比 Mask R-CNN,PANet 通过多级特征融合 和路径增强显著提升分割精度,特别是在复杂边缘和小目标场景。
2. 结构设计
graph TD
A[输入特征] --> B[特征金字塔融合]
B --> C[自适应ROI Align]
C --> D[掩膜预测头]
D --> E[二进制掩膜输出]大致模拟代码:
class MaskHead(nn.Module):
def __init__(self, in_channels=256):
super().__init__()
# 4层卷积 + 反卷积
self.conv1 = nn.Conv2d(in_channels, 256, 3, padding=1)
self.conv2 = nn.Conv2d(256, 256, 3, padding=1)
self.conv3 = nn.Conv2d(256, 256, 3, padding=1)
self.conv4 = nn.Conv2d(256, 256, 3, padding=1)
self.deconv = nn.ConvTranspose2d(256, 256, 2, stride=2)
self.mask_predict = nn.Conv2d(256, 80, 1) # COCO 80类
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.deconv(x)) # 上采样2倍
return self.mask_predict(x) # [N,80,28,28]四、关键实验结果(COCO数据集)
| 方法 | mAP | AP_small | AP_medium | AP_large |
|---|---|---|---|---|
| FPN(Baseline) | 36.2 | 18.2 | 39.0 | 48.2 |
| PANet | 41.2 | 23.8 | 44.3 | 52.5 |
| 提升幅度 | +5.0 | +5.6 | +5.3 | +4.3 |
结论:
- 小目标检测(AP_small)提升最显著(+5.6)
- 所有尺度目标均有明显提升
五、PANet的拓展应用
- 实例分割
在Mask R-CNN基础上集成PANet,边界精度提升3.4%。 - 实时检测
与轻量级主干(如MobileNetV3)结合,在1080Ti上达到32 FPS。 - 跨领域适配
在医疗影像(细胞检测)、遥感图像中表现优异。
六、总结:PANet的核心贡献
- 双向特征融合:
同时保留高层语义与低层定位信息,解决特征金字塔的"信息隔离"问题。 - 动态特征选择:
根据目标尺寸自适应选择特征层级,提升多尺度检测鲁棒性。 - 简单高效:
仅增加约15%计算量,却能带来5%以上的mAP提升。
PANet的设计理念启发了后续许多工作(如NAS-FPN、BiFPN),成为目标检测领域的重要里程碑。
本文模拟虚拟数据pytorch实现PANet实例代码(可直接复制运行---------少了MASK掩膜分割部分,有兴趣的自己实现一下加进去):
# 导入必要的库
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.ops import RoIAlign # ROI对齐操作
# -------------------- 设备配置 --------------------
# 检测可用设备,优先使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# -------------------- 数据预处理 --------------------
# 自定义数据整理函数,用于处理包含字典的批次数据
def coco_collate(batch):
"""处理包含字典的批次数据"""
images = [item[0] for item in batch] # 提取所有图像
targets = [item[1] for item in batch] # 提取所有标注数据
return torch.stack(images), targets # 将图像堆叠为张量,保持标注为列表
# 虚拟COCO数据集生成器(带归一化)
class FakeCOCODataset(torch.utils.data.Dataset):
def __init__(self, num_samples=100):
self.num_samples = num_samples # 样本数量
self.classes = 80 # COCO数据集类别数
self.img_size = 512 # 图像尺寸
def __len__(self):
return self.num_samples # 返回数据集大小
def __getitem__(self, idx):
# 生成虚拟图像 [3, 512, 512],值范围[0,1]
# 生成3通道的随机图像张量,模拟512x512大小的图片(值范围[0,1])
# 形状:(3, 512, 512) -> [channels, height, width]
img = torch.rand(3, self.img_size, self.img_size)
# 生成5个边界框的元数据
num_boxes = 5 # 每张图片生成5个随机框
# 生成边界框中心坐标(归一化比例)
# torch.rand生成[0,1)均匀分布,*0.8+0.1后范围[0.1,0.9)
# 示例结果:tensor([[0.3, 0.7], [0.5,0.5], ...])(5行2列)
centers = torch.rand(num_boxes, 2) * 0.8 + 0.1
# 生成边界框尺寸(归一化比例)
# 范围[0,0.3),确保最大尺寸不超过图像的30%
# 示例结果:tensor([[0.2, 0.15], [0.25,0.1], ...])
sizes = torch.rand(num_boxes, 2) * 0.3
# 初始化边界框容器(xyxy格式)
# 创建形状为[5,4]的全零张量
boxes = torch.zeros(num_boxes, 4)
# 计算左上角坐标(x1,y1)
# (中心x - 宽度/2) * 图像尺寸 → 实际像素坐标
# 示例:中心x=0.3,宽度=0.2 → (0.3-0.1)=0.2 → 0.2 * 512=102.4
boxes[:, 0:2] = (centers - sizes/2) * self.img_size
# 计算右下角坐标(x2,y2)
# (中心x + 宽度/2) * 图像尺寸 → 实际像素坐标
# 示例:中心x=0.3,宽度=0.2 → (0.3+0.1)=0.4 → 0.4 * 512=204.8
boxes[:, 2:4] = (centers + sizes/2) * self.img_size
# 坐标边界约束(防止越界)
# 将坐标限制在[0, 511]范围内(假设img_size=512)
# 示例:若计算结果为-10 → 修正为0,若520 → 修正为511
boxes = boxes.clamp(0, self.img_size-1)
# 归一化处理(用于回归任务)
# 将像素坐标转换为[0,1]范围内的比例
# 示例:x1=102.4 → 102.4/512=0.2
norm_boxes = boxes / self.img_size
# 生成随机类别标签(假设classes=80)
# 生成1-79的整数(不包括80),形状[5,]
# 示例结果:tensor([3, 45, 23, 67, 12])
labels = torch.randint(1, self.classes, (num_boxes,))
return img, {
'raw_boxes': boxes, # 原始坐标用于RoIAlign
'norm_boxes': norm_boxes, # 归一化坐标用于训练
'labels': labels
}
# -------------------- 模型组件 --------------------
# Bottleneck模块(ResNet基础块)
class Bottleneck(nn.Module):
expansion = 4 # 输出通道扩展倍数
def __init__(self, in_planes, planes, stride=1):
"""
参数:
in_planes: 输入通道数
planes: 中间层通道数
stride: 卷积步长
"""
super().__init__()
# 1x1卷积降维
self.conv1 = nn.Conv2d(in_planes, planes, 1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
# 3x3卷积
self.conv2 = nn.Conv2d(planes, planes, 3, stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
# 1x1卷积升维
self.conv3 = nn.Conv2d(planes, planes*self.expansion, 1, bias=False)
self.bn3 = nn.BatchNorm2d(planes*self.expansion)
# 快捷连接(当维度不匹配时)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, 1, stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
# 参数初始化(He初始化) nn.init.kaiming_normal_()函数-- 避免引起一些梯度爆炸问题(初始参数太大或者太小之类的)
# 参考博客:https://blog.csdn.net/m0_48241022/article/details/137057738
nn.init.kaiming_normal_(self.conv1.weight, mode='fan_out', nonlinearity='relu')
nn.init.kaiming_normal_(self.conv2.weight, mode='fan_out', nonlinearity='relu')
nn.init.kaiming_normal_(self.conv3.weight, mode='fan_out', nonlinearity='relu')
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x))) # 卷积+BN+ReLU
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out)) # 最后一个BN前不加ReLU
out += self.shortcut(x) # 残差连接
return F.relu(out) # 合并后激活
# 特征金字塔网络(FPN)
class FPN(nn.Module):
def __init__(self, block, num_blocks):
"""
参数:
block: 基础块类型(Bottleneck)
num_blocks: 各层block数量(如ResNet50的[3,4,6,3])
"""
super().__init__()
self.in_planes = 64 # 初始通道数
# 初始卷积层(模仿ResNet)
self.conv1 = nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1) # 1/4下采样
# 构建残差层(C2-C5)
self.layer1 = self._make_layer(block, 64, num_blocks[0], 1) # C2
self.layer2 = self._make_layer(block, 128, num_blocks[1], 2) # C3
self.layer3 = self._make_layer(block, 256, num_blocks[2], 2) # C4
self.layer4 = self._make_layer(block, 512, num_blocks[3], 2) # C5
# 特征金字塔横向连接(1x1卷积降维)
self.toplayer = nn.Conv2d(2048, 256, 1) # 处理C5
self.latlayer1 = nn.Conv2d(1024, 256, 1) # 处理C4
self.latlayer2 = nn.Conv2d(512, 256, 1) # 处理C3
self.latlayer3 = nn.Conv2d(256, 256, 1) # 处理C2
# 权重参数初始化
for m in [self.toplayer, self.latlayer1, self.latlayer2, self.latlayer3]:
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, planes, num_blocks, stride):
"""构建残差层"""
layers = [block(self.in_planes, planes, stride)] # 第一个block的stride如果大于1,可能有下采样
self.in_planes = planes * block.expansion # 更新输入通道数
for _ in range(1, num_blocks):
layers.append(block(self.in_planes, planes, 1)) # 后续block无下采样
'''最终结构:假如第一个stride为2自带下采样,后面为1正常输出:Sequential(
Bottleneck1(256->512, stride=2),
Bottleneck2(512->512, stride=1),
Bottleneck3(512->512, stride=1),
Bottleneck4(512->512, stride=1)
)'''
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
"""上采样并相加(特征融合)"""
# 使用双线性插值上采样到y的尺寸再加上y进行特征融合
return F.interpolate(x, size=y.shape[2:], mode='bilinear') + y
def forward(self, x):
# 自底向上路径
c1 = F.relu(self.bn1(self.conv1(x))) # [B,64,256,256]
c1 = self.maxpool(c1) # [B,64,128,128]
c2 = self.layer1(c1) # [B,256,128,128] (C2)
c3 = self.layer2(c2) # [B,512,64,64] (C3)
c4 = self.layer3(c3) # [B,1024,32,32] (C4)
c5 = self.layer4(c4) # [B,2048,16,16] (C5)
# 自顶向下路径(特征金字塔构建)
p5 = self.toplayer(c5) # [B,256,16,16]
p4 = self._upsample_add(p5, self.latlayer1(c4)) # [B,256,32,32] self.latlayer代表连接层,将数据连接过来
p3 = self._upsample_add(p4, self.latlayer2(c3)) # [B,256,64,64]
p2 = self._upsample_add(p3, self.latlayer3(c2)) # [B,256,128,128]
return p2, p3, p4, p5
# 自底向上增强路径(PANet核心) N2--N5
class BottomUpPath(nn.Module):
def __init__(self):
super().__init__()
# 横向连接卷积(特征融合) 创建个卷积List,存放四个卷积层
self.lat_conv = nn.ModuleList([
nn.Conv2d(256, 256, 1) for _ in range(4) # 每个金字塔层级一个卷积
])
self.downsample = nn.MaxPool2d(3, stride=2, padding=1) # 2倍下采样
# 参数初始化
for conv in self.lat_conv:
nn.init.kaiming_normal_(conv.weight, mode='fan_out', nonlinearity='relu')
def forward(self, features):
p2, p3, p4, p5 = features # 来自FPN的特征 FPN将自己每层的数据传输过来经过1*1的卷积归一化通道数目后与降采样的数据直接相加完成特征连接
# 自底向上增强路径(通过下采样和横向连接)
n2 = self.lat_conv[0](p2) # [B,256,128,128]
n3 = self.downsample(n2) + self.lat_conv[1](p3) # 下采样后相加
n4 = self.downsample(n3) + self.lat_conv[2](p4)
n5 = self.downsample(n4) + self.lat_conv[3](p5)
return [n2, n3, n4, n5]
# PANet完整网络
class PANet(nn.Module):
def __init__(self, num_classes=80):
super().__init__()
# 特征金字塔网络(基于ResNet50的FPN)
self.fpn = FPN(Bottleneck, [3,4,6,3]) # ResNet50结构
# 自底向上增强路径
self.bottom_up = BottomUpPath()
# ROI Align配置(不同层级的空间尺度) 自适应特征池化:对每个候选区域,在每个特征层上进行ROI Align池化,然后将不同层的特征图进行最大值融合
self.roi_align = {
'p2': RoIAlign(7, spatial_scale=1/4., sampling_ratio=2), # 1/4尺寸
'p3': RoIAlign(7, spatial_scale=1/8., sampling_ratio=2),
'p4': RoIAlign(7, spatial_scale=1/16., sampling_ratio=2),
'p5': RoIAlign(7, spatial_scale=1/32., sampling_ratio=2)
}
''' RoIAlign与RoIPool的区别 参考博客:https://www.cnblogs.com/xiaochouk/p/15912972.html
RoIAlign与传统的RoIPool(区域兴趣池化)的主要区别在于处理边界的方式。
RoIPool在进行池化操作时会对边界进行量化处理,这会导致精度损失。
而RoIAlign则通过保持边界框内的采样点为浮点数坐标,
并进行双线性插值来计算每个采样点的值,从而减少了量化误差,提高了精度。'''
# 分类头
self.cls_head = nn.Sequential(
nn.Linear(256 * 7 * 7, 512), # ROI特征展平后输入
nn.ReLU(),
nn.Linear(512, num_classes) # 输出类别分数
)
# 回归头
self.reg_head = nn.Sequential(
nn.Linear(256 * 7 * 7, 512),
nn.ReLU(),
nn.Linear(512, 4) # 输出边界框偏移量 偏移量x,y,w,h
)
# 参数初始化(Xavier初始化)
for head in [self.cls_head, self.reg_head]:
for m in head.modules():
if isinstance(m, nn.Linear):
nn.init.normal_(m.weight, mean=0, std=0.01) # 小随机数初始化
nn.init.constant_(m.bias, 0) # 偏置初始化为0
def forward(self, x, proposals):
# 特征提取
p2, p3, p4, p5 = self.fpn(x) # FPN输出四个阶段,也可以理解为四层的数据
# 自底向上增强路径处理 将FPN的数据经过自底向上增强路径融合连接后得到n2, n3, n4, n5
n2, n3, n4, n5 = self.bottom_up([p2, p3, p4, p5])
# 之后再进行特征融合(FPN与自底向上路径相加)多层级融合:每个尺度都获得全局+局部信息
# N2-N5 路径存在的意义主要传递的是增强后的定位信息 而P2-P5才是原有的丰富语义信息
# 高层的C5特征经过多次卷积和下采样,已丢失细节但捕获了全局语义(如"这是一只狗")。
# 通过自顶向下的上采样路径,这些语义信息被传递到所有P层。
# 虽然C2-C5本身包含多尺度信息,但低层的C2-C4主要是局部细节(边缘、纹理)。
# 横向连接到对应P层(1x1卷积)只能做通道对齐,无法直接增强语义。
# N2(P2级) → 下采样 → N3 → 下采样 → N4 → 下采样 → N5
# 低层特征(N2-N3)携带精确位置信息(如物体边缘)通过路径传递,修正高层特征的定位误差
# P5可能检测到"狗在图像某处" N5结合低层细节后,能更准确定位狗的具体位置
# P5 + N5:增强高层语义的定位能力
# P2 + N2:为细节层补充语义理解
pan_features = [
p2 + n2, # 增强后的P2特征
p3 + n3,
p4 + n4,
p5 + n5
]
# 然后进入 多层级ROI Align池化
pooled = []
for feat, name in zip(pan_features, ['p2','p3','p4','p5']):
# 对每个层级的特征进行ROI Align
pooled.append(self.roi_align[name](feat, proposals))
# 特征融合(取各层级最大值)
fused = torch.max(torch.stack(pooled), dim=0)[0] # [N,256,7,7]
# 展平特征用于全连接层
flattened = fused.flatten(1) # [N, 256 * 7 * 7]
# 预测输出
cls_logits = self.cls_head(flattened) # 分类分数
reg_preds = self.reg_head(flattened) # 回归偏移量
return cls_logits, reg_preds
# -------------------- 训练验证代码 --------------------
if __name__ == "__main__":
# 超参数设置
batch_size = 2
num_epochs = 5
num_classes = 80
# 数据加载
dataset = FakeCOCODataset()
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=batch_size,
collate_fn=coco_collate # 使用自定义整理函数
)
# 模型初始化并转移到设备
model = PANet(num_classes).to(device)
# 优化器(Adam优化器)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 损失函数
cls_criterion = nn.CrossEntropyLoss().to(device) # 分类损失
reg_criterion = nn.SmoothL1Loss().to(device) # 回归损失(对异常值更鲁棒)
# 训练循环
for epoch in range(num_epochs):
for batch_idx, (images, targets) in enumerate(dataloader):
# 数据转移到设备
images = images.to(device)
# 生成proposals(将标注框作为候选框)
proposals = []
for i, t in enumerate(targets):
# 构造proposal格式:[batch_index, x1, y1, x2, y2]
batch_indices = torch.full((len(t['raw_boxes']),1), i, device=device)
raw_boxes = t['raw_boxes'].to(device)
proposal = torch.cat([batch_indices, raw_boxes], dim=1).float()
proposals.append(proposal)
proposals_tensor = torch.cat(proposals, dim=0) # 合并所有proposals
# 前向传播
cls_out, reg_out = model(images, proposals_tensor)
# 准备标签数据
gt_labels = torch.cat([t['labels'] for t in targets]).long().to(device)
gt_boxes = torch.cat([t['norm_boxes'] for t in targets]).to(device)
# 计算损失
cls_loss = cls_criterion(cls_out, gt_labels)
reg_loss = reg_criterion(reg_out, gt_boxes)
total_loss = cls_loss + reg_loss # 总损失为两者之和
# 反向传播与优化
optimizer.zero_grad()
total_loss.backward()
optimizer.step()
# 每10个batch打印日志
if batch_idx % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}] Batch [{batch_idx}/{len(dataloader)}]')
print(f'分类损失: {cls_loss.item():.4f} 回归损失: {reg_loss.item():.4f}')参考博客:https://blog.csdn.net/a8039974/article/details/142340236