一、三剑客的定义
grep、sed、awk是linux操作文本的三剑客,也是必须掌握的linux命令之一。三者的功能都是处理文本,但侧重点各不相同,其中属awk功能最强大,但也最复杂。grep更适合单纯的查找或匹配文本,sed更适合编辑匹配到的文本,awk更适合格式化文本,对文本进行较复杂格式处理。
二、绕不开的正则表达式
正则表达式是由一些普通字符和一些元字符组成的模板。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义。具体如下:
1、元字符
| 元字符 | 功能介绍 | 含义 |
| ^ | 匹配行首 | 表示以某个字符开头 |
| | 匹配行尾 | 表示以某个字符结尾 |
| \^ | 空行的意思 | 表示空行的意思 |
| . | 匹配任意单个字符 | 表示任意一个字符 |
| * | 字符* 匹配0或多个此字符 | 表示重复的任意多个字符 |
| \ | 屏蔽一个元字符的特殊含义 | 表示去掉有意义的元字符 的含义 |
| \[\] | 匹配中括号内的字符 | 表示过滤括号内的字符 |
| .* | 代表任意多个字符 | 就是代表任意多个字符 |
| he\{n\} | 用来匹配h后出现n次e的字符串。 | n为次数 就是统计前面e出现的次数 |
| he\{n,\} | 含义同上,但次数最少为n | |
| he\{n,m\} | 含义同上,但e重复次数为n,m |
|---|
2、实例说明
bash
[root@localhost start]# grep -n '^2' 2.txt
1:22
[root@localhost start]# grep -n '2$' 2.txt
1:22
7:hee2
[root@localhost start]# grep -n '^$' 2.txt
11:
[root@localhost start]# grep -n '.q' 2.txt
5::wq!
bash
[root@localhost start]# grep -n '\!' 2.txt
5::wq!
[root@localhost start]# vi 2.txt
[root@localhost start]# grep -n 'm[aeo]n' 2.txt
11:man
12:men
13:mon
bash
[root@localhost start]# grep 'he\{2\}' 2.txt
hee2
heee3
heeee4
heeeee5
[root@localhost start]# grep 'he\{2,\}' 2.txt
hee2
heee3
heeee4
heeeee5
[root@localhost start]# grep 'he\{2,3\}' 2.txt
hee2
heee3
heeee4
heeeee5
# 可以自己测试一下,匹配的字符串的颜色是不一样的。三、grep命令
1、定义
用于过滤/搜索的特定字符。可使用正则表达式能多种命令配合使用。
2、语法
bash
grep [option] pattern file3、选项
- -A<行数 x>:除了显示符合样式的那一列之外,并显示该行之后的 x 行内容。
- -B<行数 x>:除了显示符合样式的那一行之外,并显示该行之前的 x 行内容。
- -C<行数 x>:除了显示符合样式的那一行之外,并显示该行之前后的 x 行内容。
- -c:统计匹配的行数。
- -e :实现多个选项间的逻辑or关系。
- -E:扩展的正则表达式
- -f 文件名:从文件获取 PATTERN 匹配。
- -F :相当于fgrep
- -i --ignore-case #忽略字符大小写的差别。
- -l:只显示包含匹配行的文件的文件名。
- -n:显示匹配的行号。
- -o:仅显示匹配到的字符串。
- -q: 静默模式,不输出任何信息。
- -s:不显示错误信息。
- -v:显示不被 pattern 匹配到的行,相当于\^ 反向匹配。
- -w :匹配整个单词。
4、举例说明
bash
# 匹配dog,并显示此行之后的2行。
[root@localhost start]# grep -A 2 dog 1.txt
dog
you cat is love.
--
dog
cat
# 匹配dog,并显示此行之前的2行。
[root@localhost start]# grep -B 2 dog 1.txt
11
22
dog
--
us
dog
# 匹配dog,并显示此行前后的2行。
[root@localhost start]# grep -C 2 dog 1.txt
11
22
dog
you cat is love.
--
us
dog
cat
# 统计配置的次数
[root@localhost start]# grep -c dog 1.txt
2
#-e是或的关系 -n是显示行号
[root@localhost start]# grep -n -e dog -e cat 1.txt
3:dog
4:you cat is love.
11:dog
12:cat
# 不区分大小写的匹配
[root@localhost start]# grep -ni -e dog -e cat 1.txt
3:dog
4:you cat is love.
11:dog
12:cat
13:CAT
14:doG
# 不区分大小写,只显示匹配的文件名
[root@localhost start]# grep -il dog 1.txt 2.txt
1.txt四、sed命令
1、定义
sed 是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为"模式空间"(patternspace ),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。然后读入下行,执行下一个循环。如果没有使诸如'D' 的特殊命令,那会在两个循环之间清空模式空间,但不会清空保留空间。这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出或-i。功能:主要用来自动编辑一个或多个文件, 简化对文件的反复操作。
2、语法
bash
sed [options] '[地址定界] command' file(s)3、选项
options
- -n:不输出模式空间内容到屏幕,即不自动打印,只打印匹配到的行
- -e:多点编辑,对每行处理时,可以有多个Script
- -f:把Script写到文件当中,在执行sed时-f 指定文件路径,如果是多个Script,换行写
- -r:支持扩展的正则表达式
- -i:直接将处理的结果写入文件
- -i.bak:在将处理的结果写入文件之前备份一份
4、举例说明
bash
[root@localhost name]# sed -n 'p' 1.txt # -n 打印匹配的行 p打印当前模式空间的内容
aaa
bbb
AABBCC
[root@localhost name]# sed -n '/aaa/p' 1.txt # -n 打印匹配的行
aaa
[root@localhost name]# sed -n '1,2p' 1.txt # -n 打印匹配的行 1到2行打印
aaa
bbb
[root@localhost name]# sed -e '/aaa/p' -e '3p' 1.txt # -e 多点编辑,因为没有-n所以在匹配后面打印一遍
aaa
aaa
bbb
AABBCC
AABBCC
[root@localhost name]# sed -n -e '/aaa/p' -e '3p' 1.txt # -n 只打印出来匹配的行
aaa
AABBCC
[root@localhost name]# cat script.txt
s/A/a/g
[root@localhost name]# sed -f script.txt 1.txt # -f 使用脚本匹配行
aaa
bbb
aaBBCC
[root@localhost name]# sed -i "s/aaa/ccc/" 1.txt # -i 直接将处理结果写在文件中
[root@localhost name]# cat 1.txt
ccc
bbb
AABBCC
[root@localhost name]# sed -i.bak "s/ccc/888/" 1.txt # -i.bak 备份原来的文件,直接将处理结果写在文件中
[root@localhost name]# cat 1.txt
888
bbb
AABBCC
[root@localhost name]# cat 1.txt.bak
ccc
bbb
AABBCC5、地址定界
- 1.不给地址:对全文进行处理
- 2.单地址:
- n:指定的第n行,$:最后一行
- /pattern/:被此模式所能够匹配到的每一行
- 3.地址范围:
- n,m :定位从第n行开始至第m行(都是闭区间)
- n,+k :定位从第n行开始,包括往后的k行
- n,/pattern/ :定位从第n行开始,至指定模式匹配到的那一行
- /pattern1/,/pattern2/ :定位从 pattern1 模式匹配开始,直到 pattern2 模式匹配之间的范围
- 4.步进方式:
- 1~2 :以1为起始行,然后步进2行向下匹配,即所有的奇数行
- 2~2 :以2为起始行,然后步进2行向下匹配,即所有的偶数行
6、举例说明
bash
[root@localhost name]# cat 1.txt
888
bbb
AABBCC
[root@localhost name]# sed -n 'p' 1.txt # 打印全部匹配的行
888
bbb
AABBCC
[root@localhost name]# sed -e '2p' 1.txt # 在第2行之后再打印一遍第2行的内容
888
bbb
bbb
AABBCC
[root@localhost name]# sed -n '2p' 1.txt # 只打印第2行内容
bbb
[root@localhost name]# sed -n '1,2p' 1.txt # 打印1、2行的内容
888
bbb
[root@localhost name]# sed -n '1,+2p' 1.txt # 打印1到3行的内容
888
bbb
AABBCC
[root@localhost name]# sed -n '/888/,/bbb/p' 1.txt # 打印匹配 888/bbb的内容
888
bbb
[root@localhost name]# sed -n '1,/bbb/p' 1.txt # 打印第一行和匹配888的内容
888
bbb
[root@localhost name]# sed -n '1~2,/bbb/p' 1.txt # 打印奇数行和匹配bbb的行
888
bbb
AABBCC
[root@localhost name]# sed -n '2~2p' 1.txt # 打印偶数行
bbb
[root@localhost name]# sed "1~2s/[aA]/E/g" 1.txt # 将奇数行的a/A替换成E
888
bbb
EEBBCC7、编辑命令command
- d:删除模式空间匹配的行,并立即启用下一轮循环
- p:打印当前模式空间内容,追加到默认输出之后
- a:在指定行后面追加文本,支持使用\n实现多行追加
- i:在行前面插入文本,支持使用\n实现多行追加
- c:替换行为单行或多行文本,支持使用\n实现多行追加
- w:保存模式匹配的行至指定文件
- r:读取指定文件的文本至模式空间中匹配到的行后
- =:为模式空间中的行打印行号
- !:模式空间中匹配行取反处理
- s///:查找替换,支持使用其它分隔符,如:s@@@,s###;
- 加g表示行内全局替换;
- 在替换时,可以加一下命令,实现大小写转换
- \l:把下个字符转换成小写。
- \L:把replacement字母转换成小写,直到\U或\E出现。
- \u:把下个字符转换成大写。
- \U:把replacement字母转换成大写,直到\L或\E出现。
- \E:停止以\L或\U开始的大小写转换
8、举例说明
bash
[root@localhost name]# cat 1.txt
888
bbb
AABBCC
[root@localhost name]# sed -e '/bbb/d' 1.txt # 删除匹配的行,再打印出来
888
AABBCC
[root@localhost name]# sed -e '/bbb/p' 1.txt # 在匹配行之后再打印匹配行
888
bbb
bbb
AABBCC
[root@localhost name]# sed -n '/bbb/p' 1.txt # 只打印匹配行
bbb
[root@localhost name]# sed -e '/bbb/a\222' 1.txt # 在匹配行之后追加内容
888
bbb
222
AABBCC
[root@localhost name]# sed -e '/bbb/a\222\n333' 1.txt # 在匹配行之后追加内容,可以换行
888
bbb
222
333
AABBCC
[root@localhost name]# sed -e '/bbb/i\111' 1.txt # 插入
888
111
bbb
AABBCC
[root@localhost name]# sed -e '/bbb/c\111' 1.txt # 替换
888
111
AABBCC
[root@localhost name]# sed -e '/bbb/w./b.txt' 1.txt # 写入新的文件
888
bbb
AABBCC
[root@localhost name]# cat b.txt
bbb
[root@localhost name]# sed '1r./b.txt' 1.txt # 读取文件内容到第1行之后
888
bbb
bbb
AABBCC
[root@localhost name]# sed -n '=' 1.txt # 显示行号
1
2
3
[root@localhost name]# sed -n '2!p' 1.txt # 除了第2行之后打印
888
AABBCC
[root@localhost name]# sed 's@[a-z]@\u&@g' 1.txt # a-z的字母,全部大写。
888
BBB
AABBCC
[root@localhost name]# sed "1~2s/[aA]/E/g" 1.txt # a/A替换成E
888
bbb
EEBBCC9、sed高级编辑命令
(1)格式
- h:把模式空间中的内容覆盖至保持空间中
- H:把模式空间中的内容追加至保持空间中
- g:从保持空间取出数据覆盖至模式空间
- G:从保持空间取出内容追加至模式空间
- x:把模式空间中的内容与保持空间中的内容进行互换
- n:读取匹配到的行的下一行覆盖 至模式空间
- N:读取匹配到的行的下一行追加 至模式空间
- d:删除模式空间中的行
- D:删除 当前模式空间开端至\n 的内容(不再传 至标准输出),放弃之后的命令,但是对剩余模式空间重新执行sed
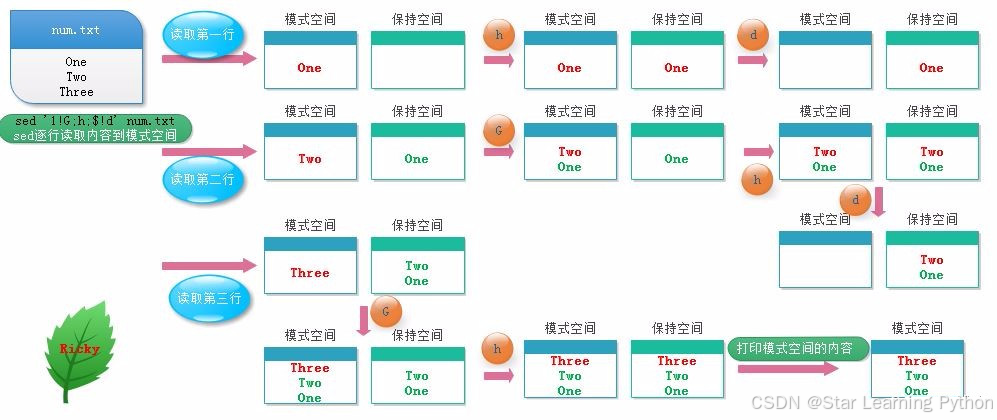
(2)倒序输出文本内容
bash
[root@localhost name]# cat num.txt
One
Two
Three
[root@localhost name]# sed '1!G;h;$!d' num.txt
Three
Two
One(3)图解sed命令
10、举例说明
(1)、显示偶数行
bash
[root@localhost name]# seq 9 | sed -n 'n;p'
2
4
6
8(2)、显示奇数行
bash
[root@localhost name]# seq 9 | sed 'H;n;d'
1
3
5
7
9(3)、倒序显示行
bash
[root@localhost name]# seq 9 | sed '1!G;h;$!d'
9
8
7
6
5
4
3
2
1(4)、显示最后一行
bash
[root@localhost name]# seq 9 | sed "N;D"
9五、awk命令
1、定义
awk是一种编程语言,用于在Linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是Linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。 awk其实不仅仅是工具软件,还是一种编程语言。不过,本文只介绍它的命令行用法,对于大多数场合,应该足够用了。
2、语法
bash
awk [options] 'program' var=value file...
awk [options] -f programfile var=value file...
awk [options] 'BEGIN{ action;... } pattern{ action;... } END{ action;... }' file ...3、选项
- -F fs:fs指定输入拆分的分隔符,fs可以是字符串或正则表达式,如-F:
- -v var=value:赋值一个用户定义变量,将外部变量传递给awk
- -f scripfile:从脚本文件中读取awk命令
4、内置变量
- FS :输入字段分隔符,默认为空白字符,一般需要加 -F
- OFS :输出字段分隔符,默认为空白字符,一般需要加 -v
- RS :输入记录分隔符,指定输入时的换行符,原换行符仍有效
- ORS :输出记录分隔符,输出时用指定符号代替换行符
- NF :字段数量,共有多少字段, NF引用最后一列,(NF-1)引用倒数第2列
- NR :行号,后可跟多个文件,第二个文件行号继续从第一个文件最后行号开始
- FNR :各文件分别计数, 行号,后跟一个文件和NR一样,跟多个文件,第二个文件行号从1开始
- FILENAME :当前文件名
- ARGC :命令行参数的个数
- ARGV :数组,保存的是命令行所给定的各参数,查看参数
5、举例说明
bash
[root@localhost name]# cat number.txt
1:one:Frist
2:two:second
3:three:third
[root@localhost name]# awk -v FS=':' '{print $1,$2,$3}' number.txt # 以:为分隔符,输出空白格
1 one Frist
2 two second
3 three third
[root@localhost name]# awk -v FS=':' -v OFS='@' '{print $1,$2,$3}' number.txt # 以:为分隔符,以@为输出连接符
1@one@Frist
2@two@second
3@three@third
[root@localhost name]# awk -v RS=':' -v OFS='@' '{print $1,$2,$3}' number.txt # 以:为换行符,替换成@,原来的换行符也替换成@
1@@
one@@
Frist@2@
two@@
second@3@
three@@
third@@
[root@localhost name]# awk -v RS=':' '{print $1,$2,$3}' number.txt 以:为换行符
1
one
Frist 2
two
second 3
three
third
[root@localhost name]# awk -v FS=':' -v ORS='&' '{print $1,$2,$3}' number.txt # 以:为分隔符,&为换行符
1 one Frist&2 two second&3 three third&[root@localhost name]#
bash
[root@localhost name]# cat number.txt # 查看number.txt内容
1:one:Frist
2:two:second
3:three:third
[root@localhost name]# awk -F: '{print NF}' number.txt # 可以拆分成多少字段,
3
3
3
[root@localhost name]# awk -F: '{print $(NF-1)}' number.txt # $NF引用最后一列,$(NF-1)引用倒数第2列
one
two
three
[root@localhost name]# awk '{print NR}' number.txt num.txt # 显示连续行号,可以多个文件
1
2
3
4
[root@localhost name]# cat num.txt
One
[root@localhost name]# awk '{print FNR}' number.txt num.txt # 分别显示每个文件的行号
1
2
3
1
[root@localhost name]# awk END'{print NR}' number.txt num.txt # 显示最后的行号
4
[root@localhost name]#
bash
[root@localhost name]# awk '{print FILENAME}' number.txt # 显示文件名
number.txt
number.txt
number.txt
[root@localhost name]# awk 'BEGIN {print ARGC}' number.txt # 显示有多少参数
2
[root@localhost name]# awk 'BEGIN {print ARGV[0]}' number.txt # 显示参数1
awk
[root@localhost name]# awk 'BEGIN {print ARGV[1]}' number.txt # 显示参数2
number.txt