当学习成为了习惯,知识也就变成了常识。 感谢各位的 关注 、点赞 、收藏 和评论。
新视频和文章会第一时间在微信公众号发送,欢迎关注:李永宁lyn
文章已收录到 github 仓库 liyongning/blog,欢迎 Watch 和 Star。
创建项目
基于 Vite + Vue3 创建最简前端项目 ------ file-upload,并在项目根目录下基于 express 创建 Node Server,如何已熟悉,可以直接进入下一节。
前端项目
通过 Vite 来创建项目,然后选择自己熟悉的技术栈,比如 Vue、React,只需要创建一个最简单的项目即可,比如:
shell
npm create vite@latest file-upload
执行 npm run dev 启动前端项目

清空 /src/App.vue 文件,并输入如下内容
vue
<script setup>
</script>
<template>
<div>
我是 App.vue
</div>
</template>
<style scoped>
</style>效果:

Node Server
在项目根目录下创建 ./server/index.js 文件,作为服务端项目,并安装 express 作为框架
shell
npm i express代码如下:
javascript
import express from 'express'
const app = express()
app.get('/', (req, res) => {
res.send('Hello World!')
})
app.listen(3000, () => {
console.log('Server listening on port 3000')
})启动 node server
shell
nodemon server/index.js
浏览器访问 http://localhost:3000

好了,到这里,基本准备工作就完成了,接下来就进入本文重点 ------ 文件上传。
最简单的文件上传
首先安装以下三个 npm 包
shell
npm i axios cors multer- axios 是为了发送网络请求
- cors 是为了处理跨域问题
- 是一个 node.js 中间件,用于处理 multipart/form-data 类型的表单数据,它主要用于上传文件
前端 ------ /src/App.vue:
vue
<script setup>
import { ref } from 'vue'
import axios from 'axios'
const inputRef = ref(null)
async function handleUpload() {
// 获取文件对象
const file = inputRef.value.files[0]
const formData = new FormData()
formData.append('file', file)
const { data } = await axios.request({
url: 'http://localhost:3000/uplaod',
method: 'POST',
data: formData,
// 上传进度,这个是通过 XMLHttpRequest 实现的能力
onUploadProgress: function (progressEvent) {
// 当前已上传完的大小 / 总大小
const percentage = Math.round((progressEvent.loaded * 100) / progressEvent.total)
console.log('Upload Progress: ', `${percentage}%`)
}
})
console.log('data = ', data)
}
</script>
<template>
<div>
<input type="file" ref="inputRef" />
<button @click="handleUpload">Upload</button>
</div>
</template>逻辑很简单
- 一个文件选择输入框,并通过 inputRef 获取到该 DOM
- 一个上传按钮,选择文件后,点击上传
- 通过 inputRef 获取到文件对象,并添加到 FormData 对象中,文件上传一般都通过该对象完成
- 通过 axios 发送请求,并监听上传进度
后端 ------ /server/index.js:
javascript
import express from 'express'
import cors from 'cors'
import multer from 'multer'
import { dirname, resolve } from 'path'
import { fileURLToPath } from 'url'
import { existsSync, mkdirSync } from 'fs'
// 解决 ESM 无法使用 __dirname 变量的问题
const __filename = fileURLToPath(import.meta.url)
const __dirname = dirname(__filename)
const app = express()
// 解决跨域问题
app.use(cors())
/**
* Multer 是一个 node.js 中间件,用于处理 multipart/form-data 类型的表单数据,它主要用于上传文件
* 注意: Multer 不会处理任何非 multipart/form-data 类型的表单数据。
*/
const uplaod = multer({
// 存储,上传的文件落盘
storage: multer.diskStorage({
// 将文件放到 /server/uploads 目录下
destination: (_, __, cb) => {
const uploadsDir = resolve(__dirname, 'uploads')
if (!existsSync(uploadsDir)) {
mkdirSync(uploadsDir)
}
cb(null, uploadsDir)
},
// 文件名使用原始文件名
filename: (_, file, cb) => {
cb(null, file.originalname)
}
})
})
app.get('/', (_, res) => {
res.send('Hello World!')
})
app.post('/uplaod', uplaod.single('file'), (_, res) => {
res.send('File uploaded successfully')
})
app.listen(3000, () => {
console.log('Server listening on port 3000')
})关键地方都写了注释,核心逻辑主要在 multer 配置项中。multer 是一个 node.js 中间件,用于处理 multipart/form-data 类型的表单数据,其主要用来处理文件上传。
效果展示:

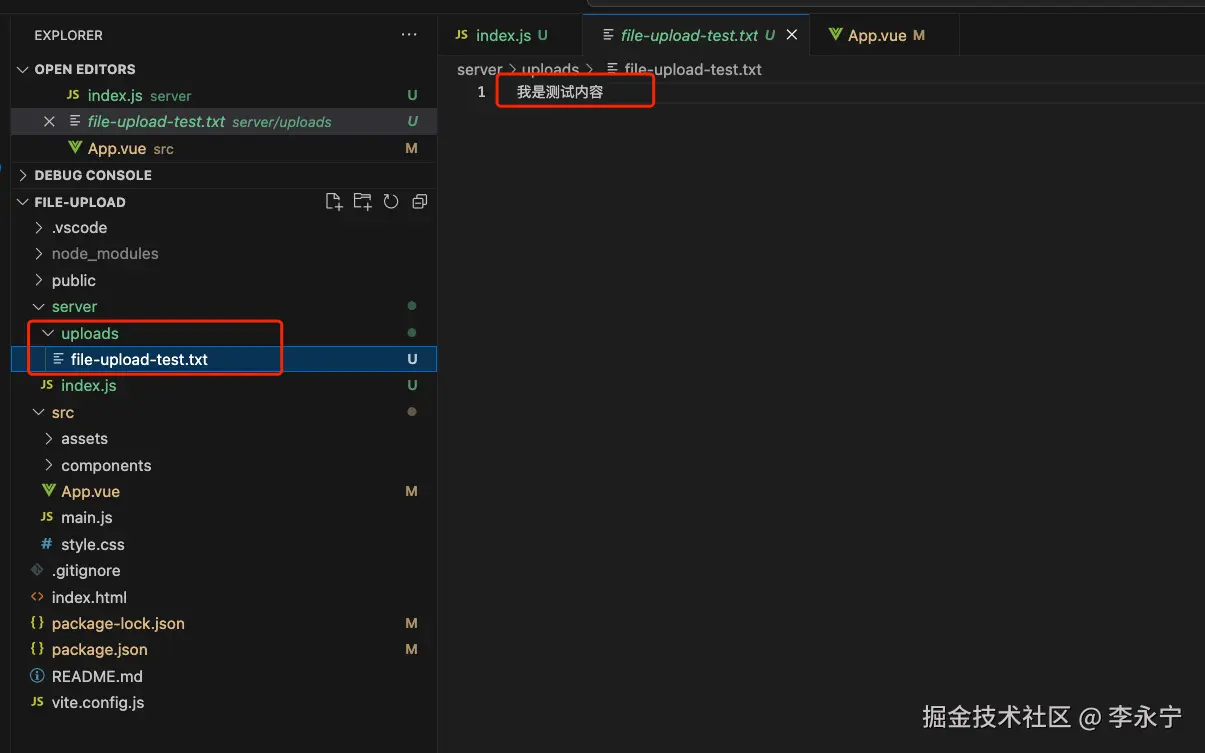
数据提交格式科普
提交 POST 请求时,我们一般会使用三种类型的 Content-Type:multipart/form-data、x-www-urlencoded、application/json,这三种类型有什么区别呢?
multipart/form-data
multipart/form-data 是一种 MIME 类型,用于在 HTTP 请求中传输表单数据,这种类型的请求通常用于文件上传,因为它允许将文件作为请求的一部分进行传输。当然,multipart/form-data 也可以用于传输其他类型的数据,例如文本字段、单选按钮、复选框等。
它表示的数据是以多部分的形式进行编码的,每个部分都有自己的 Content-Type 和 Content-Disposition 头,用于描述数据的类型和文件信息,比如,以当前的上传请求为例:

其中的 ----WebKitFormBoundary 来自于 Request Header 中的 Content-Type,用来分割每一部分的数据,就是一个分隔符,这在服务端解析数据的时候会用到。

x-www-urlencoded
x-www-urlencoded 是另一种 MIME 类型,也用于在 HTTP 请求中传输表单数据。
和 multipart/form-data 区别在于,它通常用户传输简单的文本数据,如表单字段中的文本输入框、单选按钮、复选框等的值,它不适合传输文件或二进制数据。
当 Content-Type 为 x-www-form-urlencoded 格式时,表单数据会被编码为 URL 编码(类似于在 URL 中的查询字符串使用的编码),并放在请求体中,服务器接收到请求后,会解析请求体,提取其中的表单字段和值。
示例:
javascript
const formData = new URLSearchParams();
formData.append('username', 'your_username');
formData.append('password', 'your_password');
axios.post('/your_api_url', formData, {
headers: {
'Content-Type': 'application/x-www-form-urlencoded',
},
})
.then(response => {
// 处理响应
})
.catch(error => {
// 处理错误
});
javascript
import express from 'express'
import bodyParser from 'body-parser'
const app = express();
// 使用 body-parser 中间件来解析 x-www-form-urlencoded 类型的数据
app.use(bodyParser.urlencoded({ extended: true }));
app.post('/your-route', (req, res) => {
// 现在你可以访问 req.body 来获取解析后的数据
console.log(req.body);
res.send('Data received');
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});application/json
application/json 用于传输 JSON 格式的数据,JSON 是一种轻量级的数据交换格式,通常用于 Web API,比如:
javascript
import axios from 'axios'
axios.request({
url: 'your-route',
method: 'POST',
data: {
key1: 'value1',
key2: 'value2'
}
})所以,总的来说,multipart/form-data用于复杂表单数据,包括文件上传;x-www-urlencoded用于简单表单数据;而application/json用于 Web API 的数据传输,特别是需要传输结构化数据的时候。
分片(大文件上传)
为什么要支持分片上传??
- 提高上传稳定性和可靠性。文件在上传过程中,网络链接可能会出现中断,如果不分片上传,一旦链接中断,整个文件就需要重新上传。而采用分片上传后,即使中途连接断开,只需要重新上传未完成的部分即可(断点续传),大大提高了上传的成功率和效率
- 降低网络压力和带宽占用。分片上传可以人为控制每一片的大小,避免出现单次上传占用过多带宽的情况,从而减轻对网络的压力;同时,也可以人为的控制上传速度,不至于当其它应用受影响时束手无策。
说了理论,接下来就进入实战阶段了。大致思路是:
- 前端将上传的文件按照一定大小进行切片,然后并发上传
- 切片可能会涉及主线程的长时间占用,可以采用通过 web worker 来完成
- 并发上传涉及并发控制,这是一道常见的面试题
- 服务端需要维护已上传的分片列表,从而支持断点续传的能力,待所有分片都上传后,将所有分片合并成一个完整的文件
分片上传
代码量比较少,就直接全部列出来了,都是基于之前的代码进行迭代改造的
前端 ------ App.vue
逻辑还是以点击上传按钮为开始(handleUpload)
- 定义了一个 allFileChunks 数组,用来存放所有的文件切片
- 调用 splitChunkForFile 方法对文件进行切片,并将切片放到 allFileChunks 数组中,等待上传
- splitChunkForFile 方法的逻辑很简单,通过 file.slice 方法从文件的 start 位置切到 end 位置(不包含 end)
- 然后将产生的切片通过 new File 重新封装为一个 File 对象,并存放到 allFileChunks 数组中
- 遍历 allFileChunks 数组,上传所有切片,这里有一些需要注意的点
- 在 formData 对象中增加了一些 key,比如 uuid、index、total,都是为了辅助服务端做切片的分类、维护和合并,具体作用可以看代码注释
- 另外就是 uuid 这块儿,Demo 中直接使用的文件名,但在实际使用时需要确保唯一性,比如可以对文件做 hash
- 可以看到,上传切片时没有做并发控制,目前的逻辑是不论有多少切片都一股脑的扔给浏览器做上传,后面我们会在 并发控制 章节完善这部分内容
vue
<script setup>
import { ref } from 'vue'
import axios from 'axios'
const inputRef = ref(null)
// 分片大小,单位字节
// const chunkSize = 1024
const chunkSize = 4
/**
* 文件切片
* @param { File } file 文件对象
* @param { number } start 开始位置
* @param { number } end 结束位置
* @param { Array } allFileChunks 所有文件切片
* @returns void
*/
function splitChunkForFile(file, start, end, allFileChunks) {
const { name, size, type, lastModified } = file
// 说明文件已经切割完毕
if (start > size) {
return
}
const chunk = file.slice(start, Math.min(end, size))
const newFileChunk = new File([chunk], name + allFileChunks.length, {
type,
lastModified,
})
allFileChunks.push(newFileChunk)
splitChunkForFile(file, end, end + chunkSize, allFileChunks)
}
// 上传文件
async function handleUpload() {
// 获取文件对象
const file = inputRef.value.files[0]
// 存放所有切片
const allFileChunks = []
// 文件切片
splitChunkForFile(file, 0, chunkSize, allFileChunks)
// 遍历所有切片并上传
for (let i = 0; i < allFileChunks.length; i++) {
const fileChunk = allFileChunks[i]
const formData = new FormData()
formData.append('file', fileChunk)
// 标识当前 chunk 属于哪个文件,方便服务端做内容分类和合并,实际场景中这块儿需要考虑唯一性
formData.append('uuid', file.name)
// 标识当前 chunk 是文件的第几个 chunk,即保证 chunk 顺序
formData.append('index', i)
// 标识总共有多少 chunk,方便服务端判断是否已经接收完所有 chunk
formData.append('total', allFileChunks.length)
axios.request({
url: 'http://localhost:3000/uplaod',
method: 'POST',
data: formData,
// 上传进度,这个是通过 XMLHttpRequest 实现的能力
onUploadProgress: function (progressEvent) {
// 当前已上传完的大小 / 总大小
const percentage = Math.round((progressEvent.loaded * 100) / progressEvent.total)
console.log('Upload Progress: ', `${percentage}%`)
}
}).then(res => {
console.log('result = ', res.data)
})
}
}
</script>
<template>
<div>
<input type="file" ref="inputRef" />
<button @click="handleUpload">Upload</button>
</div>
</template>服务端 ------ index.js
相比于前面的代码,所有的改动都在 /upload API 中,主要是结合前端给到的相关字段做切片的维护和合并,整体逻辑为:
- 通过 allFiles 对象来维护所有文件的所有切片,其数据结构为
{ fileName: [chunk1 路径, chunk2 路经, ...] },以文件名为 key,文件的所有 chunk 的存放路径组成的数组为 value,就像上面说的,实际应用中不能以文件名为 key,可以使用文件的 hash 为key,以保证其唯一性。这里我们只以演示原理为目的 - 各个 chunk 的落盘(存储)还是上面 multer 的逻辑,没有改动
- 如果发现当前文件的所有 chunk 均已上传完毕 ------ allFilesuuid.length === total 时(total 是前端给的),就认为当前文件的所有 chunk 都上传完了,开始合并 chunk
- 接下来就是按顺序同步读取每个 chunk 的内容,并依次写入文件,顺便删掉磁盘上存放的临时 chunk 文件
- 到此,分片上传就完成了
javascript
import express from 'express'
import cors from 'cors'
import multer from 'multer'
import { dirname, resolve } from 'path'
import { fileURLToPath } from 'url'
import { existsSync, mkdirSync, unlinkSync, readFileSync, appendFileSync } from 'fs'
// 解决 ESM 无法使用 __dirname 变量的问题
const __filename = fileURLToPath(import.meta.url)
const __dirname = dirname(__filename)
const app = express()
// 解决跨域问题
app.use(cors({
maxAge: 86400
}))
/**
* Multer 是一个 node.js 中间件,用于处理 multipart/form-data 类型的表单数据,它主要用于上传文件
* 注意: Multer 不会处理任何非 multipart/form-data 类型的表单数据。
*/
const uplaod = multer({
// 存储,上传的文件落盘
storage: multer.diskStorage({
// 将文件放到 /server/uploads 目录下
destination: (_, __, cb) => {
const uploadsDir = resolve(__dirname, 'uploads')
if (!existsSync(uploadsDir)) {
mkdirSync(uploadsDir)
}
cb(null, uploadsDir)
},
// 文件名使用原始文件名
filename: (_, file, cb) => {
cb(null, file.originalname)
}
})
})
app.get('/', (_, res) => {
res.send('Hello World!')
})
// 以 uuid 为 key,文件所有的 chunks 组成的数组为 value
const allFiles = {}
app.post('/uplaod', uplaod.single('file'), (req, res) => {
const { uuid, index, total } = req.body
// chunk 的存储路径
const { path } = req.file
if (!allFiles[uuid]) allFiles[uuid] = []
allFiles[uuid][index] = path
if (allFiles[uuid].filter(item => item).length === +total) {
// 说明已经接收完了所有的 chunk
const destFilePath = resolve(__dirname, 'uploads', uuid)
// 合并临时文件并将其删除
allFiles[uuid].forEach(async filePath => {
const content = readFileSync(filePath)
appendFileSync(destFilePath, content)
unlinkSync(filePath)
})
allFiles[uuid] = []
res.send(`file ------ ${uuid} uploaded successfully`)
return
}
res.send(`chunk ------ ${uuid + index} uploaded successfully`)
})
app.listen(3000, () => {
console.log('Server listening on port 3000')
})效果展示


如果文件足够大(上传需要一定的时间)或者在服务端的文件合并逻辑处打个断点,就可以看到 /server/uploads 目录下有很多很临时的 chunk 文件。
切片优化 + 并发控制
为什么要做切片优化?现在的切片逻辑有什么问题吗?
- 递归逻辑致使栈溢出
- 主线程被切片逻辑长时间占用
换一个大点的文件,点击上传,出现如下报错,很明显栈溢出了。回顾逻辑,可以知道 splitChunkForFile 方法是一个递归函数,这就意味着,如果文件比较大,切片比较多,递归层级就会很深,自然就出现了栈溢出的问题。


另外,即使抛开溢出问题不谈,当前切片逻辑是同步执行的,当切片数量很大时,主线会被长时间占用,甚至浏览器被卡死。这点可以将切片逻辑换成循环执行来验证(递归无法验证,因为会先出现栈溢出的情况):
javascript
/**
* 文件切片
* @param { File } file 文件对象
* @returns Array<File> 文件的所有切片组成的 File 对象
*/
function splitChunkForFile(file) {
const { name, size, type, lastModified } = file
// 存放所有切片
const allFileChunks = []
// 每一片的开始位置
let start = 0
// 循环切每一片,直到整个文件切完
while (start <= size) {
const chunk = file.slice(start, Math.min(start + chunkSize, size))
const newFileChunk = new File([chunk], name + allFileChunks.length, {
type,
lastModified,
})
start += chunkSize
allFileChunks.push(newFileChunk)
}
return allFileChunks
}
// 文件切片
const allFileChunks = splitChunkForFile(file)效果如下:


为什么需要并发控制?现在没有并发控制有什么问题吗?
现在的逻辑是:先获取文件的所有切片,然后遍历切片数组,将所有切片一股脑全部发送给服务端。
- 没有几个服务器能扛住上万的 QPS
- 可以看到有太多的请求处于连接等待状态,也有大量请求直接就失败了

优化思路
- 将切片任务放到 Web Worker 中去完成,从而解决主线程被长时间占用问题
- 增加并发控制,从而解决 QPS 过高的问题
实战
/src/App.vue
点击 Upload 按钮之后,逻辑如下:
- 将文件交给 Web Worker,由 Web Worker 执行切片操作,然后等待 Web Worker 回传文件切片
- 收到 Worker 回传的文件切片之后,将切片存入 allFileChunks 数组,并调用 uploadChunk 上传切片文件
- uploadChunk 方法是一个支持并发控制的上传方法,并发控制的核心思路是
- 在请求开始之前时当前并发数的检测 和 是否已全部上传完的检测,这保证了请求数量不超过并发数
- 后续请求的触发是通过 Promise.then 的回调来完成的,即每完成一个请求,就发送下一个请求
- 文件上传的相关逻辑和之前一样,没有变化
vue
<script setup>
import { ref } from 'vue'
import axios from 'axios'
import WebWorker from './web-worker.js?worker'
const inputRef = ref(null)
// 分片大小,单位 MB
const chunkSize = 1024 * 1024
// 分片大小,单位字节
// const chunkSize = 4
// 存放所有的文件切片
let allFileChunks = []
// WebWorker 实例
let worker = null
// 记录当前文件已经切了多少片了
let hasBeenSplitNum = 0
// 当前上传的 chunk 在 allFileChunks 数组中的索引
let allFileChunksIdx = 0
// 当前并发数
let curConcurrencyNum = 0
// 最大并发数
const MAX_CONCURRENCY_NUM = 6
// 上传文件
async function handleUpload() {
// 上传开始前的数据初始化
allFileChunksIdx = 0
allFileChunks = []
hasBeenSplitNum = 0
curConcurrencyNum = 0
// 获取文件对象
const file = inputRef.value.files[0]
// 实例化 WebWorker,用来做文件切片
worker = new WebWorker()
// 将文件切片工作交给 web worker 来完成
worker.postMessage({ operation: 'splitChunkForFile', file, chunkSize })
// 总 chunk 数
const total = Math.ceil(file.size / chunkSize)
// 接收 worker 发回的切片(持续发送,worker 每完成一个切片就发一个)
worker.onmessage = function (e) {
const { data } = e
const { operation } = data
if (operation === 'splitChunkForFile') {
hasBeenSplitNum += 1
pushFileChunk(data.file)
// 说明整个文件已经切完了,释放 worker 实例
if (hasBeenSplitNum === total) {
this.terminate()
}
}
}
}
/**
* 将 worker 完成切片存放到 allFileChunks 中,并触发上传逻辑
* @param { File } file 文件切片的 File 对象
*/
function pushFileChunk(file) {
allFileChunks.push(file)
uploadChunk()
}
/**
* 并发上传文件切片,并发数 6(同一域名浏览器最多有 6个并发)
*/
function uploadChunk() {
if (curConcurrencyNum >= MAX_CONCURRENCY_NUM || allFileChunksIdx >= allFileChunks.length) return
// 获取文件对象
const file = inputRef.value.files[0]
const { name, size } = file
// 总 chunk 数
const total = Math.ceil(size / chunkSize)
// 并发数 + 1
curConcurrencyNum += 1
// 从 allFileChunks 中获取指定索引的 fileChunk,这个索引的存在还是为了保证按顺序取和上传 chunk
const fileChunk = allFileChunks[allFileChunksIdx]
const formData = new FormData()
formData.append('file', fileChunk)
// 标识当前 chunk 属于哪个文件,方便服务端做内容分类和合并,实际场景中这块儿需要考虑唯一性
formData.append('uuid', name)
// 标识当前 chunk 是文件的第几个 chunk,即保证 chunk 顺序
formData.append('index', allFileChunksIdx)
// 标识总共有多少 chunk,方便服务端判断是否已经接收完所有 chunk
formData.append('total', total)
axios.request({
url: 'http://localhost:3000/uplaod',
method: 'POST',
data: formData,
// 上传进度,这个是通过 XMLHttpRequest 实现的能力
onUploadProgress: function (progressEvent) {
// 当前已上传完的大小 / 总大小
const percentage = Math.round((progressEvent.loaded * 100) / progressEvent.total)
console.log('Upload Progress: ', `${percentage}%`)
}
}).then(res => {
console.log('result = ', res.data)
}).finally(() => {
/**
* 当前请求完成,
*/
// 并发数 - 1
curConcurrencyNum -= 1
// 上传下一个切片
uploadChunk()
})
// 更新 chunk 索引,方便取下一个 chunk
allFileChunksIdx += 1
uploadChunk()
}
</script>
<template>
<div>
<input type="file" ref="inputRef" />
<button @click="handleUpload">Upload</button>
</div>
</template>/src/web-worker.js
Worker 是独立于主线程运行的线程,有自己独立的执行上下文和事件循环。当然了,如果系统资源有限,还是回和其它线程(比如主线程)产生竞争。
它在这里负责完成上面的同步切片操作,每切完一个,就回传给主线程,由主线程完成上传。所以,整个文件上传是由主线程和 Worker 线程异步协同完成的。
javascript
/**
* 文件切片
* 通过循环将整个文件切片,在切的过程中每切一片,就当切好的分片发给主线程,当真个文件切完之后告诉主线程已完成
* @param { File } file 文件对象
* @param { number } chunkSize 单个切片的大小,单位字节
*/
function splitChunkForFile(file, chunkSize) {
const { name, size, type, lastModified } = file
// 每一片的开始位置
let start = 0
// chunk 索引,用来将序号添加到文件名上
let chunkIdx = 0
// 循环切每一片,直到整个文件切完
while (start < size) {
const chunk = file.slice(start, Math.min(start + chunkSize, size))
const newFileChunk = new File([chunk], name + chunkIdx++, {
type,
lastModified,
})
start += chunkSize
// 将当前切片发给主线程
this.postMessage({ operation: 'splitChunkForFile', file: newFileChunk })
}
}
// 接收主线程的消息
onmessage = function (e) {
const { data } = e
const { operation } = data
if (operation === 'splitChunkForFile') {
// 表示给对文件切片操作
splitChunkForFile.apply(this, [data.file, data.chunkSize])
}
// 还可以扩展其它操作
}效果展示
可以发现切片不在卡主线程、请求也更早的开始了(不需要等到全部切片完成)、并发也只有 6个。

断点续传
断点续传是在分片上传的基础上来实现的,当上传过程中出现故障时,能够从上次中断的地方继续上传,而不是从头开始。这点对于大文件的上传尤为重要,因为上传时间较长,出现中断的概率较高。
实战
断点续传的实现,和分片一样,也需要前后端一起配合,具体调整如下。
/src/App.vue
- 在上传逻辑开始执行前先通过
getFileChunksByFileName方法获取当前文件已经上传的切片列表,然后执行后续的切片逻辑 - 在上传切片之前,检测一下当前切片是否已经上传,如果已经上传,则直接结束当前切片的上传,进入下一个切片的上传逻辑
这就是前端侧改造的核心逻辑。
javascript
/**
* 获取文件已上传的切片
* @param { string } fileName 文件名
*/
async function getFileChunksByFileName(fileName) {
const { data } = await axios.request({
url: 'http://localhost:3000/get-file-chunks-by-uuid',
method: 'GET',
params: {
uuid: fileName
}
})
return data
}

/server/index.js
增加一个获取指定文件已上传切片列表的接口,供前端调用。
javascript
// 获取指定文件的切片列表,即获取该文件已上传的切片,用于断点续传
app.get('/get-file-chunks-by-uuid', (req, res) => {
// 这里的 uuid 就是文件名
const { uuid } = req.query || {}
res.send(allFiles[uuid] || [])
})效果
当前文件我先提前上传了一部分,就是看到的前 6 个切片,然后刷新页面打断执行。接着再次上传该文件,前 6 个切片瞬间完成(不需要重新上传)。

切片大小
可以看到,文中的切片大小有两种,一是 4B,二是 1MB。一直没有提及切片的大小的设计,但这里还是要简单说明一下。
大家都知道 HTTP1.1 对于带宽的利用率是很糟糕的,这是 HTTP1.1 的一个核心问题,其中一个原因就是 TCP 的慢启动。一旦一个 TCP 连接建立之后,就进入了发送数据的状态,刚开始 TCP 协议回采用一个非常慢的速度去发送数据,然后慢慢加快发送数据的速度,知道发送数据的速度达到一个理想状态,这个过程就叫慢启动。很像一辆车启动加速的过程。
但慢启动是 TCP 为了减少网络拥塞的一种策略,这个没办法改变。所以,这里提到切片大小的设计,意思是切片大小不可设置的过小,但设置过大也不可取。关于切片大小其实没有一个固定的标准,通常需要根据实际大小和网络环境进行调整,以下是一些常见的策略:
- 小文件(几百MB以下):切片大小可以设置为10MB到20MB之间
- 中等大小文件(几百MB到几GB):切片大小可以设置为5MB到10MB之间
- 大文件(几十GB以上):切片大小可以设置为1MB到5MB之间
总的来说,对于较小的文件,切片可以较大,以减少分片数量和控制开销;对于大文件,可以适当减小切片大小,以确保每个分片都在合理的时间内上传完成,并支持更细粒度的断点续传。
总结
本文的目标是:一文搞透文件上传。当你读到这里,希望不负初衷。现在回顾一下文章的整体内容
- 从最简单的创建项目开始,前端用 Vite + Vue3 + axios,服务端用 express + multer(处理文件上传的中间件)
- 写了最简单的文件上传
- 前端一个 file 类型的 input 输入框,然后取到 file 对象放到 FormData 对象中,通过 axios 完成上传
- 服务端基于 multer 中间件完成文件的落盘
- 顺便普及了下三种常见的 Content-Type ------ multipart/form-data、x-www-urlencoded、application/json 之间的异同点和使用场景
- 有了上面基础知识的地基,接下来就进入了文件上传的核心难点,也是文件上传场景常见的面试题 ------ 大文件上传
- 我们从分片开始,这是实现后面断点续传的基础
- 前端将一个大文件切成一个个片段,然后将这些片段依次上传给服务端
- 服务端接收前端给到的分片,当所有分片上传完成之后,合并所有分片得到最终文件
- 后来解决了第一版存在的两个问题
- 对大文件切片,导致主线程被长时间占用。这点通过将切片操作放到 Web Worker 来解决
- 大量并发,导致 QPS 过高,这里通过并发控制的方式来实现,并结合 Worker 实现切片 + 上传协同完成
- 有了分片逻辑,接下来实现了断点续传,提升上传效率。逻辑很简单,就是上传前获取到当前文件已上传的切片列表,然后在上传切片之前查看该切片是否已经上传,如果已上传,直接跳过,从而避免文件从头上传
- 最后,通过 HTTP1.1 慢启动问题,引出了切片大小的设计,一般是 5MB 左右
当学习成为了习惯,知识也就变成了常识。 感谢各位的 关注 、点赞 、收藏 和评论。
新视频和文章会第一时间在微信公众号发送,欢迎关注:李永宁lyn
文章已收录到 github 仓库 liyongning/blog,欢迎 Watch 和 Star。