TimeDiff
- [**1. 背景与动机**](#1. 背景与动机)
- [**2. 扩散模型基础**](#2. 扩散模型基础)
- [**3. TimeDiff 模型**](#3. TimeDiff 模型)
-
-
-
- [**3.1 前向扩散过程**](#3.1 前向扩散过程)
- [**3.2 后向去噪过程**](#3.2 后向去噪过程)
-
-
- 4、TimeDiff(架构)
- DDPM(相关数学)
-
- 1、正态分布
- 2、条件概率
-
-
- [1. **与多个条件相关**(依赖所有前置条件)](#1. 与多个条件相关(依赖所有前置条件))
- [2. **仅与上一个条件相关**(马尔可夫性质)](#2. 仅与上一个条件相关(马尔可夫性质))
-
- 2、联合概率分布和马尔可夫
-
- [一、联合概率分布(Joint Probability Distribution)](#一、联合概率分布(Joint Probability Distribution))
-
- [1. **离散随机变量的联合概率分布**](#1. 离散随机变量的联合概率分布)
- [2. **连续随机变量的联合概率分布**](#2. 连续随机变量的联合概率分布)
- 二、马尔可夫性质与马尔可夫链的公式表示
-
- [1. **马尔可夫性质(Markov Property)**](#1. 马尔可夫性质(Markov Property))
- [2. **马尔可夫链(Markov Chain)的联合概率分布**](#2. 马尔可夫链(Markov Chain)的联合概率分布)
- 三、联合概率分布与马尔可夫的联系
- [2、 N ( x k ; 1 − β k x k − 1 , β k I ) \mathcal{N}(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I) N(xk;1−βk xk−1,βkI) 中为啥加**变量 x k x_k xk**](#2、 N ( x k ; 1 − β k x k − 1 , β k I ) \mathcal{N}(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I) N(xk;1−βk xk−1,βkI) 中为啥加变量 x k x_k xk)
-
- 一、正态分布的符号约定:区分变量与参数
-
- [1. **符号结构**](#1. 符号结构)
- [2. **示例对比**](#2. 示例对比)
- 二、条件概率中的必要性:明确变量依赖关系
-
- [1. **条件概率的本质**](#1. 条件概率的本质)
- [2. **避免符号混淆**](#2. 避免符号混淆)
- [3、 q ( x k ∣ x k − 1 ) = N ( x k ; 1 − β k x k − 1 , β k I ) q(x_k | x_{k-1}) = \mathcal{N}\left(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I\right) q(xk∣xk−1)=N(xk;1−βk xk−1,βkI)解释](#3、 q ( x k ∣ x k − 1 ) = N ( x k ; 1 − β k x k − 1 , β k I ) q(x_k | x_{k-1}) = \mathcal{N}\left(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I\right) q(xk∣xk−1)=N(xk;1−βk xk−1,βkI)解释)
-
- [一、条件概率 q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}) q(xk∣xk−1) 的含义](#一、条件概率 q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}) q(xk∣xk−1) 的含义)
-
- [1. **条件概率的定义**](#1. 条件概率的定义)
- [2. **条件概率的作用**](#2. 条件概率的作用)
- [二、 N ( ⋅ ; μ , Σ ) \mathcal{N}(\cdot; \mu, \Sigma) N(⋅;μ,Σ) 中";"的含义](#二、 N ( ⋅ ; μ , Σ ) \mathcal{N}(\cdot; \mu, \Sigma) N(⋅;μ,Σ) 中“;”的含义)
-
- [1. **正态分布的符号约定**](#1. 正态分布的符号约定)
- [2. **均值项 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1**](#2. 均值项 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1)
- [3. **协方差矩阵 β k I \beta_k I βkI**](#3. 协方差矩阵 β k I \beta_k I βkI)
- 三、公式与扩散模型的联系(结合文档内容)
-
- [1. **前向扩散过程的数学推导**](#1. 前向扩散过程的数学推导)
- [2. **训练目标的基础**](#2. 训练目标的基础)
- 四、举例说明
- [DDPM和 Conditional DDPM(原理)](#DDPM和 Conditional DDPM(原理))
-
-
- [2.1. Diffusion Models 原理详解](#2.1. Diffusion Models 原理详解)
-
- 核心思想
- [前向扩散过程(Forward Diffusion)](#前向扩散过程(Forward Diffusion))
- [反向去噪过程(Reverse Denoising)](#反向去噪过程(Reverse Denoising))
- [反向去噪过程(Backward Denoising Process)](#反向去噪过程(Backward Denoising Process))
-
- [1. **条件概率分布**](#1. 条件概率分布)
- [2. **训练目标:最小化 KL 散度**](#2. 训练目标:最小化 KL 散度)
- [两种训练策略:噪声预测 vs 数据预测](#两种训练策略:噪声预测 vs 数据预测)
- [1. **噪声预测(Noise Prediction,如 DDPM)**](#1. 噪声预测(Noise Prediction,如 DDPM))
- [2. **数据预测(Data Prediction)**](#2. 数据预测(Data Prediction))
- 示例说明
- [2.2条件扩散模型(Conditional Diffusion Models)](#2.2条件扩散模型(Conditional Diffusion Models))
- [2.3. Conditional DDPMs for Time Series Prediction (时间序条件扩散模型)](#2.3. Conditional DDPMs for Time Series Prediction (时间序条件扩散模型))
-
-
- 0、核心思想
- [1. **条件分布建模**](#1. 条件分布建模)
- [2. **核心挑战**](#2. 核心挑战)
- 现有时间序列扩散模型分析
-
- [1. **TimeGrad(自回归模型,Rasul et al., 2021)**](#1. TimeGrad(自回归模型,Rasul et al., 2021))
- [2. **CSDI(非自回归模型,Tashiro et al., 2021)**](#2. CSDI(非自回归模型,Tashiro et al., 2021))
- [3. **SSSD(CSDI 改进版,Alcaraz & Strodthoff, 2022)**](#3. SSSD(CSDI 改进版,Alcaraz & Strodthoff, 2022))
- [4. **与 NLP 模型的对比**](#4. 与 NLP 模型的对比)
- 四、核心问题总结
-
-
4.17
论文:https://arxiv.org/abs/2306.05043
Non-autoregressive Conditional Diffusion Models for Time Series Prediction
1. 背景与动机
时间序列预测在经济学、交通、能源等领域有广泛应用。近年来,去噪扩散模型(denoising diffusion models)在图像、音频和文本生成领域取得了显著突破,但如何将这种强大的建模能力应用于时间序列预测仍是一个开放问题。
时间序列数据通常具有复杂的动态特性、非线性模式和长期依赖关系,这使得预测(尤其是长预测范围)变得非常具有挑战性。现有的时间序列扩散模型主要分为两类:
- 自回归模型(如 TimeGrad):逐时间步生成未来预测,但因误差累积和推理速度慢而受限。
- 非自回归模型 (如 CSDI 和 SSSD):通过条件化去噪网络的中间层引入归纳偏置,但其长期预测性能仍不如其他时间序列预测模型(如 Fedformer 和 NBeats)。
现有模型的不足- 自回归模型(如 TimeGrad):逐时刻生成,误差累积且推理慢。
- 非自回归模型(如 CSDI、SSSD):借用图像/文本条件策略,未针对时间序列设计,长程预测性能弱,存在边界不和谐问题。
论文提出 TimeDiff,一种非自回归条件扩散模型,通过引入两种新颖的条件机制(future mixup 和 autoregressive initialization)来提高时间序列预测的性能。
2. 扩散模型基础
扩散模型由前向扩散过程和后向去噪过程组成。前向扩散过程 通过逐渐添加噪声,前向扩散过程将输入 x 0 x^{0} x0 转换为 K 扩散步骤中的高斯白噪声矢量 x K x^{K} xK,最终变成 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)纯噪声。后向去噪过程 向后降噪过程是马尔可夫过程,给定纯噪声 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)还原到 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H。
扩散模型由前向扩散过程和后向去噪过程组成:
- 前向扩散过程 :通过逐步添加噪声,将输入数据 x 0 x_0 x0 转换为高斯噪声 x K x_K xK。
- 后向去噪过程:通过神经网络学习逐步去除噪声,恢复原始数据。
条件扩散模型通过条件输入 c c c 指导去噪过程,适用于时间序列预测任务。
3. TimeDiff 模型
TimeDiff 的核心在于两种条件机制:
-
Future Mixup:
- 在训练阶段,将过去的观测信息 F ( x − L + 1 : 0 ) F(x_{-L+1:0}) F(x−L+1:0) 和未来的真值 x 1 : H x_{1:H} x1:H 混合,形成条件信号 z mix z_{\text{mix}} zmix。
- 在推理阶段,仅使用过去的观测信息 F ( x − L + 1 : 0 ) F(x_{-L+1:0}) F(x−L+1:0)。
- 这种机制类似于教师强迫(teacher forcing),但在非自回归条件下工作。
-
Autoregressive Initialization:
- 使用线性自回归模型 M AR M_{\text{AR}} MAR 对未来的粗略估计 z AR z_{\text{AR}} zAR 进行初始化。
- 该模型捕获时间序列的基本模式(如短期趋势),避免边界不和谐问题。
这两种机制的输出沿通道维度拼接,形成最终的条件信号 c = concat ( z mix , z AR ) c = \text{concat}(z_{\\text{mix}}, z_{\\text{AR}}) c=concat(zmix,zAR)。
3.1 前向扩散过程
TimeDiff 的前向扩散过程与标准扩散模型一致,通过逐步添加噪声将未来的真值 x 1 : H x_{1:H} x1:H 转换为噪声向量。
3.2 后向去噪过程
去噪网络结合扩散步长嵌入 p k p_k pk 和条件信号 c c c,通过多层卷积网络生成去噪后的样本。
4、TimeDiff(架构)
(请先了解DDPM原理:链接)
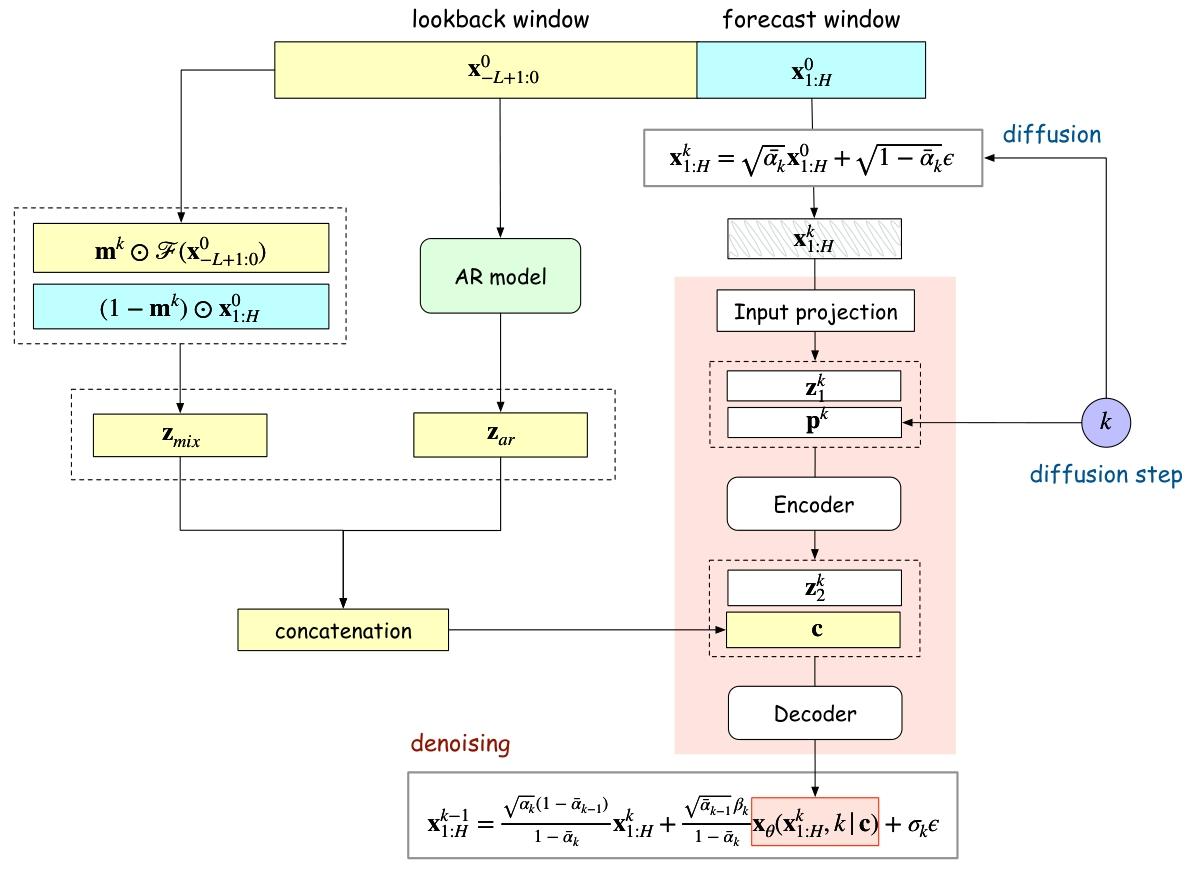 图 1.建议的 TimeDiff 的图示。 x L + 1 : 0 0 x^{0}{L+1: 0} xL+1:00 包含过去的观测值, x 1 : H 0 x{1: H}^{0} x1:H0 包含未来的真实输出。
图 1.建议的 TimeDiff 的图示。 x L + 1 : 0 0 x^{0}{L+1: 0} xL+1:00 包含过去的观测值, x 1 : H 0 x{1: H}^{0} x1:H0 包含未来的真实输出。
原理
给定 历史观测 x − L + 1 : 0 0 ∈ R d × L x_{-L+1:0}^0 \in \mathbb{R}^{d \times L} x−L+1:00∈Rd×L(包含 d d d 个变量,长度为 L L L 的历史窗口),预测 未来值 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H(长度为 H H H 的预测窗口)。核心是建模条件分布 p θ ( x 1 : H 0 ∣ x − L + 1 : 0 0 ) p_\theta(x_{1:H}^0 | x_{-L+1:0}^0) pθ(x1:H0∣x−L+1:00),其中:
- 前向扩散过程:向预测值 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H
(训练集中真实值已知)中不断加噪 x 1 : H k ∈ R d × H x_{1:H}^k \in \mathbb{R}^{d \times H} x1:Hk∈Rd×H(k步扩散),最终变成 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)纯噪声。 - 后向去噪过程: 历史观测 x − L + 1 : 0 0 ∈ R d × L x_{-L+1:0}^0 \in \mathbb{R}^{d \times L} x−L+1:00∈Rd×L经过F获得条件c, p θ ( x 1 : H k − 1 ∣ x 1 : H k , c ) p_\theta(x_{1:H}^{k-1} | x_{1:H}^k, c) pθ(x1:Hk−1∣x1:Hk,c)反向去噪分布,在第 k k k 次去噪步骤中, x 1 : H k x_{1:H}^k x1:Hk 被去噪为 x 1 : H k − 1 x_{1:H}^{k-1} x1:Hk−1。给定纯噪声 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)还原到 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H。
模型架构
- 前向扩散 :与 DDPM 一致,通过逐步加噪生成含噪样本 x k = α ˉ k x 0 + 1 − α ˉ k ϵ x^k = \sqrt{\bar{\alpha}_k}x^0 + \sqrt{1-\bar{\alpha}_k}\epsilon xk=αˉk x0+1−αˉk ϵ。
- 去噪网络 :
- 输入:含噪样本 x k x^k xk、扩散步长嵌入 p k p^k pk、条件信号 c = concat ( z mix , z ar ) c = \text{concat}(z_{\text{mix}}, z_{\text{ar}}) c=concat(zmix,zar)。
- 结构:卷积编码器提取特征,解码器融合条件信号,直接预测数据 x θ x_\theta xθ 而非噪声,提升对非线性噪声的鲁棒性。
训练
训练流程如算法 1 所示。对于每个 x 1 : H 0 x_{1:H}^0 x1:H0,我们首先随机采样一批扩散步骤 k k k,然后最小化公式 (10) 的条件变体:
min θ L ( θ ) = min θ E x 1 : H 0 , ϵ ∼ N ( 0 , I ) , k L k ( θ ) , \min_\theta \mathcal{L}(\theta) = \min_\theta \mathbb{E}{x{1:H}^0, \epsilon \sim \mathcal{N}(0, I), k} \mathcal{L}_k(\theta), θminL(θ)=θminEx1:H0,ϵ∼N(0,I),kLk(θ),
其中
L k ( θ ) = ∥ x 1 : H 0 − x θ ( x 1 : H k , k ∣ c ) ∥ 2 . ( 19 ) \mathcal{L}k(\theta) = \left\| x{1:H}^0 - x_\theta \left( x_{1:H}^k, k \mid c \right) \right\|^2. \quad (19) Lk(θ)= x1:H0−xθ(x1:Hk,k∣c) 2.(19)
推理
在推理阶段(算法 2),我们首先生成一个大小为 d × H d \times H d×H 的噪声向量 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)。通过重复运行去噪步骤 (18) 直至 k = 1 k = 1 k=1(当 k = 1 k = 1 k=1 时 ϵ \epsilon ϵ 设为 0),最终得到时间序列 x ^ 1 : H 0 \hat{x}_{1:H}^0 x^1:H0 作为最终预测。
其他关键点解释
-
位置编码 p k p^k pk
位置编码融入:去噪网络如图 1 中红色部分所示。对 x 1 : H k ∈ R d × H x_{1:H}^k \in \mathbb{R}^{d \times H} x1:Hk∈Rd×H 进行去噪时,首先将扩散步长嵌入 p k p^k pk 与扩散输入 x 1 : H k x_{1:H}^k x1:Hk 的嵌入 z 1 k ∈ R d ′ × H z_1^k \in \mathbb{R}^{d' \times H} z1k∈Rd′×H 结合,其中 z 1 k z_1^k z1k 由包含多个卷积层的输入投影模块生成。

-
⊙哈达玛积(Hadamard product):矩阵按位相乘,
- 示例 :
若
A = a 11 a 12 a 21 a 22 , B = b 11 b 12 b 21 b 22 , \mathbf{A} = \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{bmatrix}, \quad \mathbf{B} = \begin{bmatrix} b_{11} & b_{12} \\ b_{21} & b_{22} \end{bmatrix}, A=a11a21a12a22,B=b11b21b12b22,
则
A ⊙ B = a 11 b 11 a 12 b 12 a 21 b 21 a 22 b 22 . \mathbf{A} \odot \mathbf{B} = \begin{bmatrix} a_{11}b_{11} & a_{12}b_{12} \\ a_{21}b_{21} & a_{22}b_{22} \end{bmatrix}. A⊙B=a11b11a21b21a12b12a22b22.
- 示例 :
DDPM(相关数学)
扩散模型由前向扩散过程和后向去噪过程组成。前向扩散过程 通过逐渐添加噪声,前向扩散过程将输入 x 0 x^{0} x0 转换为 K 扩散步骤中的高斯白噪声矢量 x K x^{K} xK,最终变成 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)纯噪声。后向去噪过程 向后降噪过程是马尔可夫过程,给定纯噪声 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)还原到 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H。

1、正态分布
https://baike.baidu.com/item/正态分布/829892
正态分布(Normal distribution),又称为常态分布或高斯分布,通常记作X~N(μ ,σ2)。其中, μ是正态分布的数学期望(均值), σ2是正态分布的方差。μ = 0,σ = 1的正态分布被称为标准正态分布 1。


2、条件概率
https://baike.baidu.com/item/条件概率/4475278
- 条件概率
条件概率是指事件A在事件B发生的条件下发生的概率。条件概率表示为:P(A|B),读作"A在B发生的条件下发生的概率"。若只有两个事件A,B,那么,。 - 联合概率
表示两个事件共同发生的概率。A与B的联合概率表示为 P(AB) 或者P(A,B),或者P(A∩B)。 2 - 边缘概率
是某个事件发生的概率,而与其它事件无关。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。
条件概率,多条件Xn,与多个条件相关和只与上一个条件相关:
当事件序列 X 1 , X 2 , ... , X n X_1, X_2, \dots, X_n X1,X2,...,Xn 的条件概率依赖关系不同时,联合概率的计算方式也会不同。
1. 与多个条件相关(依赖所有前置条件)
• 定义 :每个事件 X i X_i Xi 的条件概率依赖于之前所有事件 X 1 , X 2 , ... , X i − 1 X_1, X_2, \dots, X_{i-1} X1,X2,...,Xi−1 的发生。
• 链式法则 :
联合概率可分解为一系列条件概率的乘积,公式为:
P ( X 1 , X 2 , ... , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 1 , X 2 ) ⋅ ⋯ ⋅ P ( X n ∣ X 1 , ... , X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_1,X_2) \cdot \dots \cdot P(X_n|X_1,\dots,X_{n-1}) P(X1,X2,...,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X1,X2)⋅⋯⋅P(Xn∣X1,...,Xn−1)
- 概率计算:在这种情况下,计算事件 A 发生的概率 P(A|B,C,D) 可以用联合概率除以边缘概率的方法,即 P(A|B,C,D) = P(A,B,C,D)/P(B,C,D),其中 P(B,C,D) > 0。联合概率 P(A,B,C,D) 表示事件 A、B、C、D 同时发生的概率,边缘概率 P(B,C,D) 表示事件 B、C、D 同时发生的概率。
2. 仅与上一个条件相关(马尔可夫性质)
• 定义 :每个事件 X i X_i Xi 的条件概率仅依赖于前一个事件 X i − 1 X_{i-1} Xi−1,即 P ( X i ∣ X 1 , ... , X i − 1 ) = P ( X i ∣ X i − 1 ) P(X_i|X_1,\dots,X_{i-1}) = P(X_i|X_{i-1}) P(Xi∣X1,...,Xi−1)=P(Xi∣Xi−1)。
• 简化形式 :
联合概率可简化为:
P ( X 1 , X 2 , ... , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 2 ) ⋅ ⋯ ⋅ P ( X n ∣ X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) \cdot P(X_2|X_1) \cdot P(X_3|X_2) \cdot \dots \cdot P(X_n|X_{n-1}) P(X1,X2,...,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X2)⋅⋯⋅P(Xn∣Xn−1)
这种形式常见于时序模型(如马尔可夫链),例如网页 6 提到的股票价格预测中,当前价格可能仅依赖前一时段的价格。
- 概率计算:在这种情况下,条件概率可以简化为 P(A|B),而不必考虑更前面的条件。例如,在一个二阶马尔可夫链中,事件 A 发生的概率只与前两个事件有关,即 P(A|B,C),但与更早的事件无关。不过,对于一阶马尔可夫链,就只考虑前一个事件,即 P(A|B)。
2、联合概率分布和马尔可夫
以下是联合概率分布与马尔可夫性质/马尔可夫链的具体公式表示:
一、联合概率分布(Joint Probability Distribution)
1. 离散随机变量的联合概率分布
设 X 1 , X 2 , ... , X n X_1, X_2, \dots, X_n X1,X2,...,Xn 为离散随机变量,其联合概率质量函数(Joint PMF)为:
P ( X 1 = x 1 , X 2 = x 2 , ... , X n = x n ) P(X_1 = x_1, X_2 = x_2, \dots, X_n = x_n) P(X1=x1,X2=x2,...,Xn=xn)
- 边缘概率分布 :单个变量的概率分布,通过对其他变量求和得到,例如:
P ( X 1 = x 1 ) = ∑ x 2 ∑ x 3 ⋯ ∑ x n P ( X 1 = x 1 , X 2 = x 2 , ... , X n = x n ) P(X_1 = x_1) = \sum_{x_2} \sum_{x_3} \cdots \sum_{x_n} P(X_1 = x_1, X_2 = x_2, \dots, X_n = x_n) P(X1=x1)=x2∑x3∑⋯xn∑P(X1=x1,X2=x2,...,Xn=xn) - 条件概率分布 :给定 X 2 , ... , X n X_2, \dots, X_n X2,...,Xn 时 X 1 X_1 X1 的条件概率:
P ( X 1 = x 1 ∣ X 2 = x 2 , ... , X n = x n ) = P ( X 1 = x 1 , X 2 = x 2 , ... , X n = x n ) P ( X 2 = x 2 , ... , X n = x n ) P(X_1 = x_1 \mid X_2 = x_2, \dots, X_n = x_n) = \frac{P(X_1 = x_1, X_2 = x_2, \dots, X_n = x_n)}{P(X_2 = x_2, \dots, X_n = x_n)} P(X1=x1∣X2=x2,...,Xn=xn)=P(X2=x2,...,Xn=xn)P(X1=x1,X2=x2,...,Xn=xn) - 链式法则(Chain Rule) :联合概率可分解为条件概率的乘积:
P ( X 1 , X 2 , ... , X n ) = P ( X 1 ) ⋅ P ( X 2 ∣ X 1 ) ⋅ P ( X 3 ∣ X 1 , X 2 ) ⋅ ⋯ ⋅ P ( X n ∣ X 1 , X 2 , ... , X n − 1 ) P(X_1, X_2, \dots, X_n) = P(X_1) \cdot P(X_2 \mid X_1) \cdot P(X_3 \mid X_1, X_2) \cdot \cdots \cdot P(X_n \mid X_1, X_2, \dots, X_{n-1}) P(X1,X2,...,Xn)=P(X1)⋅P(X2∣X1)⋅P(X3∣X1,X2)⋅⋯⋅P(Xn∣X1,X2,...,Xn−1)
2. 连续随机变量的联合概率分布
设 X 1 , X 2 , ... , X n X_1, X_2, \dots, X_n X1,X2,...,Xn 为连续随机变量,其联合概率密度函数(Joint PDF)为 f ( x 1 , x 2 , ... , x n ) f(x_1, x_2, \dots, x_n) f(x1,x2,...,xn),
- 边缘概率密度 :
f X 1 ( x 1 ) = ∫ − ∞ ∞ ⋯ ∫ − ∞ ∞ f ( x 1 , x 2 , ... , x n ) d x 2 ⋯ d x n f_{X_1}(x_1) = \int_{-\infty}^{\infty} \cdots \int_{-\infty}^{\infty} f(x_1, x_2, \dots, x_n) \, dx_2 \cdots dx_n fX1(x1)=∫−∞∞⋯∫−∞∞f(x1,x2,...,xn)dx2⋯dxn - 条件概率密度 :
f X 1 ∣ X 2 , ... , X n ( x 1 ∣ x 2 , ... , x n ) = f ( x 1 , x 2 , ... , x n ) f X 2 , ... , X n ( x 2 , ... , x n ) f_{X_1 \mid X_2, \dots, X_n}(x_1 \mid x_2, \dots, x_n) = \frac{f(x_1, x_2, \dots, x_n)}{f_{X_2, \dots, X_n}(x_2, \dots, x_n)} fX1∣X2,...,Xn(x1∣x2,...,xn)=fX2,...,Xn(x2,...,xn)f(x1,x2,...,xn)
二、马尔可夫性质与马尔可夫链的公式表示
1. 马尔可夫性质(Markov Property)
对于随机过程 { X t } t = 0 , 1 , 2 , ... \{X_t\}{t=0,1,2,\dots} {Xt}t=0,1,2,...,若在任意时刻 n n n,未来状态 X n + 1 X{n+1} Xn+1 仅依赖于当前状态 X n X_n Xn,与历史状态 X 0 , X 1 , ... , X n − 1 X_0, X_1, \dots, X_{n-1} X0,X1,...,Xn−1 无关,则称该过程具有一阶马尔可夫性质 ,数学表达式为:
P ( X n + 1 = x n + 1 ∣ X 0 = x 0 , X 1 = x 1 , ... , X n = x n ) = P ( X n + 1 = x n + 1 ∣ X n = x n ) P(X_{n+1} = x_{n+1} \mid X_0 = x_0, X_1 = x_1, \dots, X_n = x_n) = P(X_{n+1} = x_{n+1} \mid X_n = x_n) P(Xn+1=xn+1∣X0=x0,X1=x1,...,Xn=xn)=P(Xn+1=xn+1∣Xn=xn)
一般地,若过程满足 k k k 阶马尔可夫性质,则未来状态仅依赖于前 k k k 个历史状态(如 k = 1 k=1 k=1 为一阶,最常见)。
2. 马尔可夫链(Markov Chain)的联合概率分布
设马尔可夫链的状态空间为 S \mathcal{S} S,初始分布为 π ( x 0 ) = P ( X 0 = x 0 ) \pi(x_0) = P(X_0 = x_0) π(x0)=P(X0=x0),转移概率矩阵为 P ( X t + 1 = j ∣ X t = i ) = p i , j P(X_{t+1} = j \mid X_t = i) = p_{i,j} P(Xt+1=j∣Xt=i)=pi,j(时间齐次情况下转移概率与时间 t t t 无关)。
- 有限时间步的联合概率 :对于状态序列 x 0 , x 1 , ... , x n x_0, x_1, \dots, x_n x0,x1,...,xn,其联合概率可利用马尔可夫性质分解为:
P ( X 0 = x 0 , X 1 = x 1 , ... , X n = x n ) = π ( x 0 ) ⋅ ∏ k = 0 n − 1 P ( X k + 1 = x k + 1 ∣ X k = x k ) P(X_0 = x_0, X_1 = x_1, \dots, X_n = x_n) = \pi(x_0) \cdot \prod_{k=0}^{n-1} P(X_{k+1} = x_{k+1} \mid X_k = x_k) P(X0=x0,X1=x1,...,Xn=xn)=π(x0)⋅k=0∏n−1P(Xk+1=xk+1∣Xk=xk)
若时间齐次,则转移概率 P ( X k + 1 = j ∣ X k = i ) = p i , j P(X_{k+1} = j \mid X_k = i) = p_{i,j} P(Xk+1=j∣Xk=i)=pi,j,联合概率简化为:
P ( X 0 = x 0 , X 1 = x 1 , ... , X n = x n ) = π ( x 0 ) ⋅ ∏ k = 0 n − 1 p x k , x k + 1 P(X_0 = x_0, X_1 = x_1, \dots, X_n = x_n) = \pi(x_0) \cdot \prod_{k=0}^{n-1} p_{x_k, x_{k+1}} P(X0=x0,X1=x1,...,Xn=xn)=π(x0)⋅k=0∏n−1pxk,xk+1 - n 步转移概率 :从状态 i i i 经过 n n n 步转移到状态 j j j 的概率 P i , j ( n ) P^{(n)}{i,j} Pi,j(n),可通过 Chapman-Kolmogorov 方程计算:
P i , j ( n + m ) = ∑ k ∈ S P i , k ( n ) ⋅ P k , j ( m ) P^{(n+m)}{i,j} = \sum_{k \in \mathcal{S}} P^{(n)}{i,k} \cdot P^{(m)}{k,j} Pi,j(n+m)=k∈S∑Pi,k(n)⋅Pk,j(m)
三、联合概率分布与马尔可夫的联系
在马尔可夫链中,联合概率分布的链式法则因马尔可夫性质而简化:
- 一般链式法则 : P ( X 0 , X 1 , ... , X n ) = P ( X 0 ) ⋅ P ( X 1 ∣ X 0 ) ⋅ P ( X 2 ∣ X 0 , X 1 ) ⋅ ⋯ ⋅ P ( X n ∣ X 0 , ... , X n − 1 ) P(X_0, X_1, \dots, X_n) = P(X_0) \cdot P(X_1 \mid X_0) \cdot P(X_2 \mid X_0, X_1) \cdot \cdots \cdot P(X_n \mid X_0, \dots, X_{n-1}) P(X0,X1,...,Xn)=P(X0)⋅P(X1∣X0)⋅P(X2∣X0,X1)⋅⋯⋅P(Xn∣X0,...,Xn−1)
- 马尔可夫链链式法则 : P ( X 0 , X 1 , ... , X n ) = P ( X 0 ) ⋅ ∏ k = 0 n − 1 P ( X k + 1 ∣ X k ) P(X_0, X_1, \dots, X_n) = P(X_0) \cdot \prod_{k=0}^{n-1} P(X_{k+1} \mid X_k) P(X0,X1,...,Xn)=P(X0)⋅∏k=0n−1P(Xk+1∣Xk)(仅依赖前一状态)
2、 N ( x k ; 1 − β k x k − 1 , β k I ) \mathcal{N}(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I) N(xk;1−βk xk−1,βkI) 中为啥加变量 x k x_k xk
N ( ⋅ ; μ , Σ ) \mathcal{N}(\cdot; \mu, \Sigma) N(⋅;μ,Σ) 中";"的含义 :
- 正态分布的符号约定
N ( x k ; 1 − β k x k − 1 , β k I ) \mathcal{N}(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I) N(xk;1−βk xk−1,βkI) 表示 多元正态分布,其中:
- 分号";" 用于分隔 随机变量 和 分布参数 (均值和协方差)。
- 左侧 x k x_k xk 是随机变量(待生成的样本)。
- 右侧 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1 是 均值向量 μ \mu μ , β k I \beta_k I βkI 是 协方差矩阵 Σ \Sigma Σ。
一、正态分布的符号约定:区分变量与参数
1. 符号结构
- 一般形式 :
- 无条件分布: N ( μ , Σ ) \mathcal{N}(\mu, \Sigma) N(μ,Σ),其中 μ \mu μ 是均值, Σ \Sigma Σ 是协方差矩阵(无明确变量时,默认变量为任意随机变量)。
- 条件分布或带变量的分布 : N ( x ; μ , Σ ) \mathcal{N}(x; \mu, \Sigma) N(x;μ,Σ),其中 分号";"左侧的 x x x 是 随机变量 ,右侧是 分布参数(均值和协方差)。
- 作用 :明确指出"哪个变量 服从以 μ \mu μ 为均值、 Σ \Sigma Σ 为协方差的正态分布",避免歧义。
2. 示例对比
- 若写为 N ( 1 − β k x k − 1 , β k I ) \mathcal{N}(\sqrt{1 - \beta_k} x_{k-1}, \beta_k I) N(1−βk xk−1,βkI),可能被误解为"均值是 x k x_k xk,协方差是其他参数",而实际均值是 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1。
- 加入变量 x k x_k xk 后,清晰表达为"变量 x k x_k xk 服从均值为 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1、协方差为 β k I \beta_k I βkI 的正态分布"。
二、条件概率中的必要性:明确变量依赖关系
1. 条件概率的本质
公式 q ( x k ∣ x k − 1 ) = N ( x k ; 1 − β k x k − 1 , β k I ) q(x_k | x_{k-1}) = \mathcal{N}(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I) q(xk∣xk−1)=N(xk;1−βk xk−1,βkI) 描述的是 在给定 x k − 1 x_{k-1} xk−1 的条件下,变量 x k x_k xk 的分布。
- 左侧 q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}) q(xk∣xk−1) :条件概率密度函数,变量是 x k x_k xk,条件是 x k − 1 x_{k-1} xk−1。
- 右侧 N ( x k ; ... ) \mathcal{N}(x_k; \dots) N(xk;...) :显式指出随机变量是 x k x_k xk,其分布参数(均值、协方差)依赖于 x k − 1 x_{k-1} xk−1 和 β k \beta_k βk。
2. 避免符号混淆
在条件概率中,若省略变量 x k x_k xk,可能导致以下歧义:
- 误认为参数 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1 是另一个随机变量。
- 无法区分"分布关于 x k x_k xk"还是"分布关于 x k − 1 x_{k-1} xk−1"。
加入 x k x_k xk 后,明确了分布的主体是 当前步变量 x k x_k xk ,而 x k − 1 x_{k-1} xk−1 是条件输入(已知值,非随机变量)。
3、 q ( x k ∣ x k − 1 ) = N ( x k ; 1 − β k x k − 1 , β k I ) q(x_k | x_{k-1}) = \mathcal{N}\left(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I\right) q(xk∣xk−1)=N(xk;1−βk xk−1,βkI)解释
一、条件概率 q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}) q(xk∣xk−1) 的含义
1. 条件概率的定义
q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}) q(xk∣xk−1) 表示 在已知第 k − 1 k-1 k−1 步样本 x k − 1 x_{k-1} xk−1 的条件下,第 k k k 步样本 x k x_k xk 的概率分布。
- 这是 马尔可夫过程 的核心特征:当前状态仅依赖于前一步状态,与更早的状态无关,即 q ( x k ∣ x k − 1 , x k − 2 , ... , x 0 ) = q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}, x_{k-2}, \dots, x_0) = q(x_k | x_{k-1}) q(xk∣xk−1,xk−2,...,x0)=q(xk∣xk−1)(文档段落 )。
- 在扩散模型的 前向扩散过程 中,它描述了从 x k − 1 x_{k-1} xk−1 到 x k x_k xk 的噪声添加过程,是逐步将初始数据 x 0 x_0 x0 转换为高斯白噪声 x K x_K xK 的基础(文档段落 )。
2. 条件概率的作用
- 前向扩散的核心机制 :每一步通过该条件概率添加噪声,实现"信号衰减 + 噪声累加"。例如:
x k = 1 − β k x k − 1 + β k ϵ x_k = \sqrt{1 - \beta_k} x_{k-1} + \sqrt{\beta_k} \epsilon xk=1−βk xk−1+βk ϵ - β k \beta_k βk 是噪声的方差(随步骤 k k k 递增,如从 1 0 − 4 10^{-4} 10−4 到 1 0 − 1 10^{-1} 10−1,文档段落 )。
- 1 − β k \sqrt{1 - \beta_k} 1−βk 是缩放因子,其中 β k ∈ 0 , 1 \beta_k \in 0, 1 βk∈0,1 是第 k k k 步的 噪声方差参数(文档段落 )。
- 噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I)
- 若 x k − 1 x_{k-1} xk−1 是干净样本(接近初始数据),则 x k x_k xk 是 x k − 1 x_{k-1} xk−1 缩放后叠加噪声的结果(文档段落 )。
- 随着 k k k 增大,噪声占比逐渐增加,最终 x K x_K xK 接近纯高斯噪声( N ( 0 , I ) \mathcal{N}(0, I) N(0,I))。
二、 N ( ⋅ ; μ , Σ ) \mathcal{N}(\cdot; \mu, \Sigma) N(⋅;μ,Σ) 中";"的含义
1. 正态分布的符号约定
N ( x k ; 1 − β k x k − 1 , β k I ) \mathcal{N}(x_k; \sqrt{1 - \beta_k} x_{k-1}, \beta_k I) N(xk;1−βk xk−1,βkI) 表示 多元正态分布,其中:
- 分号";" 用于分隔 随机变量 和 分布参数 (均值和协方差)。
- 左侧 x k x_k xk 是随机变量(待生成的样本)。
- 右侧 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1 是 均值向量 μ \mu μ , β k I \beta_k I βkI 是 协方差矩阵 Σ \Sigma Σ。
- 这是数学上的标准符号约定,不同于逗号","(通常用于分隔同一类参数,如 N ( μ , Σ ) \mathcal{N}(\mu, \Sigma) N(μ,Σ))。
2. 均值项 1 − β k x k − 1 \sqrt{1 - \beta_k} x_{k-1} 1−βk xk−1
- 物理意义 :对前一步样本 x k − 1 x_{k-1} xk−1 进行缩放,保留"信号"部分。
- 1 − β k \sqrt{1 - \beta_k} 1−βk 是缩放因子,其中 β k ∈ 0 , 1 \beta_k \in 0, 1 βk∈0,1 是第 k k k 步的 噪声方差参数(文档段落 )。
- 若 β k = 0 \beta_k = 0 βk=0,则均值为 x k − 1 x_{k-1} xk−1(不添加噪声);若 β k = 1 \beta_k = 1 βk=1,则均值为 0(完全丢弃信号,仅保留噪声)。
3. 协方差矩阵 β k I \beta_k I βkI
- 物理意义 :定义当前步添加的 独立高斯噪声 。
- β k \beta_k βk 是噪声的方差(随步骤 k k k 递增,如从 1 0 − 4 10^{-4} 10−4 到 1 0 − 1 10^{-1} 10−1,文档段落 )。
- I I I 是单位矩阵,表示噪声在各维度上 独立同分布(适用于多元时间序列,每个变量的噪声互不相关)。
- 噪声生成方式 :噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I),当前步样本可表示为:
x k = 1 − β k x k − 1 + β k ϵ x_k = \sqrt{1 - \beta_k} x_{k-1} + \sqrt{\beta_k} \epsilon xk=1−βk xk−1+βk ϵ
即"信号部分" + "噪声部分",其中噪声的标准差为 β k \sqrt{\beta_k} βk (文档段落 公式推导)。
三、公式与扩散模型的联系(结合文档内容)
1. 前向扩散过程的数学推导
文档段落 指出,通过递推可证明 x k x_k xk 与初始数据 x 0 x_0 x0 的关系为:
x k = α ˉ k x 0 + 1 − α ˉ k ϵ , α ˉ k = ∏ s = 1 k ( 1 − β s ) x_k = \sqrt{\bar{\alpha}_k} x_0 + \sqrt{1 - \bar{\alpha}_k} \epsilon, \quad \bar{\alpha}k = \prod{s=1}^k (1 - \beta_s) xk=αˉk x0+1−αˉk ϵ,αˉk=s=1∏k(1−βs)
- 这一结果正是基于条件概率 q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}) q(xk∣xk−1) 的逐步应用,其中 α ˉ k \sqrt{\bar{\alpha}_k} αˉk 是累计信号保留系数,对应多次缩放后的均值项。
2. 训练目标的基础
扩散模型的反向去噪过程(文档段落 )依赖前向过程的高斯假设,通过神经网络估计均值 μ θ ( x k , k ) \mu_\theta(x_k, k) μθ(xk,k) 和方差 σ k 2 \sigma_k^2 σk2,实现从噪声恢复原始数据。
- 条件概率 q ( x k ∣ x k − 1 ) q(x_k | x_{k-1}) q(xk∣xk−1) 的均值和协方差为反向过程提供了明确的优化目标(如最小化 KL 散度,文档段落 )。
四、举例说明
假设初始数据 x 0 = 1.0 , 0.5 x^0 = 1.0, 0.5 x0=1.0,0.5(二维向量),扩散步长 β 1 = 0.1 \beta_1 = 0.1 β1=0.1:
- 计算均值 :
1 − β 1 ⋅ x 0 = 0.9 ⋅ 1.0 , 0.5 ≈ 0.9487 , 0.4743 \sqrt{1-\beta_1} \cdot x^0 = \sqrt{0.9} \cdot 1.0, 0.5 \approx 0.9487, 0.4743 1−β1 ⋅x0=0.9 ⋅1.0,0.5≈0.9487,0.4743 - 协方差矩阵 :
β 1 I = 0.1 ⋅ 1 0 0 1 \beta_1 I = 0.1 \cdot \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} β1I=0.1⋅1001 - 采样 x 1 x^1 x1 :
从 N ( 0.9487 , 0.4743 , 0.1 I ) \mathcal{N}(0.9487, 0.4743, 0.1I) N(0.9487,0.4743,0.1I) 中随机采样,例如:
x 1 ≈ 0.9487 + ϵ 1 , 0.4743 + ϵ 2 x^1 \approx 0.9487 + \\epsilon_1, 0.4743 + \\epsilon_2 x1≈0.9487+ϵ1,0.4743+ϵ2
其中 ϵ 1 , ϵ 2 ∼ N ( 0 , 0.1 ) \epsilon_1, \epsilon_2 \sim \mathcal{N}(0, 0.1) ϵ1,ϵ2∼N(0,0.1)。
扩散过程的作用
通过逐步增大 β k \beta_k βk,前向过程将数据 x 0 x^0 x0 逐渐变为纯噪声:
• 初始步 ( k = 0 k=0 k=0): x 0 x^0 x0 是原始数据。
• 中间步 ( k = 1 , 2 , . . . , K − 1 k=1,2,...,K-1 k=1,2,...,K−1):数据逐渐模糊化。
• 最终步 ( k = K k=K k=K): x K x^K xK 近似为标准高斯噪声 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)。
DDPM和 Conditional DDPM(原理)
扩散模型由前向扩散过程和后向去噪过程组成。前向扩散过程 通过逐渐添加噪声,前向扩散过程将输入 x 0 x^{0} x0 转换为 K 扩散步骤中的高斯白噪声矢量 x K x^{K} xK,最终变成 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)纯噪声。后向去噪过程 向后降噪过程是马尔可夫过程,给定纯噪声 x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I)还原到 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H。

扩散模型由前向扩散过程和后向去噪过程组成:
- 前向扩散过程 :通过逐步添加噪声,将输入数据 x 0 x_0 x0 转换为高斯噪声 x K x_K xK。
- 后向去噪过程:通过神经网络学习逐步去除噪声,恢复原始数据。
条件扩散模型通过条件输入 c c c 指导去噪过程,适用于时间序列预测任务。
2.1. Diffusion Models 原理详解
核心思想
扩散模型通过两个过程学习数据分布:
- 前向扩散过程:逐步对数据添加噪声,最终将数据转化为纯噪声。
- 反向去噪过程:训练神经网络从噪声中逐步恢复原始数据。
前向扩散过程(Forward Diffusion)
数学定义 :
给定原始数据 x 0 x^0 x0,通过 K K K 步逐步添加高斯噪声。第 k k k 步的噪声强度由方差计划 β k \beta_k βk 控制:
q ( x k ∣ x k − 1 ) = N ( x k ; 1 − β k x k − 1 , β k I ) q(x^k | x^{k-1}) = \mathcal{N}\left(x^k; \sqrt{1-\beta_k} x^{k-1}, \beta_k I\right) q(xk∣xk−1)=N(xk;1−βk xk−1,βkI)
重参数化技巧 :
可直接从 x 0 x^0 x0 计算任意第 k k k 步的噪声数据:
x k = α ˉ k x 0 + 1 − α ˉ k ϵ 其中 ϵ ∼ N ( 0 , I ) x^k = \sqrt{\bar{\alpha}_k} x^0 + \sqrt{1-\bar{\alpha}_k} \epsilon \quad \text{其中} \quad \epsilon \sim \mathcal{N}(0, I) xk=αˉk x0+1−αˉk ϵ其中ϵ∼N(0,I)
其中:
• α k = 1 − β k \alpha_k = 1 - \beta_k αk=1−βk
• α ˉ k = ∏ s = 1 k α s \bar{\alpha}k = \prod{s=1}^k \alpha_s αˉk=∏s=1kαs
直观解释 :
随着 k k k 增大, α ˉ k → 0 \sqrt{\bar{\alpha}_k} \to 0 αˉk →0,数据逐渐被噪声淹没。例如,若 β k \beta_k βk 线性增加,第 500 步时数据几乎变为纯噪声。
公式推导过程:
-
单步扩散公式
在第 k k k 步,噪声方差为 β k ∈ 0 , 1 \beta_k \in 0,1 βk∈0,1,扩散过程为:
q ( x k ∣ x k − 1 ) = N ( x k ; 1 − β k x k − 1 , β k I ) q(x^{k} | x^{k-1}) = \mathcal{N}\left(x^{k}; \sqrt{1-\beta_k} x^{k-1}, \beta_k I\right) q(xk∣xk−1)=N(xk;1−βk xk−1,βkI)其中, 1 − β k \sqrt{1-\beta_k} 1−βk 是保留因子, β k I \beta_k I βkI 是添加的高斯噪声。
-
累积扩散公式
通过递归展开,可直接从 x 0 x^0 x0 生成 x k x^k xk:
q ( x k ∣ x 0 ) = N ( x k ; α ˉ k x 0 , ( 1 − α ˉ k ) I ) q(x^k | x^0) = \mathcal{N}\left(x^k; \sqrt{\bar{\alpha}_k} x^0, (1-\bar{\alpha}_k) I\right) q(xk∣x0)=N(xk;αˉk x0,(1−αˉk)I)其中 α k = 1 − β k \alpha_k = 1-\beta_k αk=1−βk, α ˉ k = ∏ s = 1 k α s \bar{\alpha}k = \prod{s=1}^k \alpha_s αˉk=∏s=1kαs。通过
重参数化技巧,采样可表示为:
x k = α ˉ k x 0 + 1 − α ˉ k ϵ , ϵ ∼ N ( 0 , I ) x^k = \sqrt{\bar{\alpha}_k} x^0 + \sqrt{1-\bar{\alpha}_k} \epsilon, \quad \epsilon \sim \mathcal{N}(0,I) xk=αˉk x0+1−αˉk ϵ,ϵ∼N(0,I)
反向去噪过程(Reverse Denoising)
目标 :学习一个神经网络 μ θ \mu_\theta μθ,从 x k x^k xk 预测 x k − 1 x^{k-1} xk−1 的均值:
p θ ( x k − 1 ∣ x k ) = N ( x k − 1 ; μ θ ( x k , k ) , σ k 2 I ) p_\theta(x^{k-1} | x^k) = \mathcal{N}\left(x^{k-1}; \mu_\theta(x^k, k), \sigma_k^2 I\right) pθ(xk−1∣xk)=N(xk−1;μθ(xk,k),σk2I)
两种训练目标:
- 预测噪声(Noise Prediction) :
模型预测添加到数据中的噪声 ϵ \epsilon ϵ:
μ ϵ ( ϵ θ ) = 1 α k x k − 1 − α k 1 − α ˉ k α k ϵ θ ( x k , k ) \mu_\epsilon(\epsilon_\theta) = \frac{1}{\sqrt{\alpha_k}} x^k - \frac{1-\alpha_k}{\sqrt{1-\bar{\alpha}k} \sqrt{\alpha_k}} \epsilon\theta(x^k, k) μϵ(ϵθ)=αk 1xk−1−αˉk αk 1−αkϵθ(xk,k)
损失函数:
L ϵ = E k , x 0 , ϵ ∥ ϵ − ϵ θ ( x k , k ) ∥ 2 \mathcal{L}\epsilon = \mathbb{E}{k, x^0, \epsilon} \left \\\| \\epsilon - \\epsilon_\\theta(x\^k, k) \\\|\^2 \\right Lϵ=Ek,x0,ϵ∥ϵ−ϵθ(xk,k)∥2 - 预测数据(Data Prediction) :
模型直接预测原始数据 x 0 x^0 x0:
μ x ( x θ ) = α k ( 1 − α ˉ k − 1 ) 1 − α ˉ k x k + α ˉ k − 1 β k 1 − α ˉ k x θ ( x k , k ) \mu_x(x_\theta) = \frac{\sqrt{\alpha_k}(1-\bar{\alpha}_{k-1})}{1-\bar{\alpha}k} x^k + \frac{\sqrt{\bar{\alpha}{k-1}} \beta_k}{1-\bar{\alpha}k} x\theta(x^k, k) μx(xθ)=1−αˉkαk (1−αˉk−1)xk+1−αˉkαˉk−1 βkxθ(xk,k)
损失函数:
L x = E k , x 0 , ϵ ∥ x 0 − x θ ( x k , k ) ∥ 2 \mathcal{L}x = \mathbb{E}{k, x^0, \epsilon} \left \\\| x\^0 - x_\\theta(x\^k, k) \\\|\^2 \\right Lx=Ek,x0,ϵ∥x0−xθ(xk,k)∥2
关键区别 :
• 预测噪声适合处理简单噪声模式(如图像),而时间序列常含复杂噪声,直接预测数据可能更有效。
反向去噪过程(Backward Denoising Process)
目标 :从噪声 x k x_k xk 恢复初始数据 x k − 1 x_{k-1} xk−1,通过神经网络学习去噪分布 p θ ( x k − 1 ∣ x k ) p_\theta(x_{k-1} | x_k) pθ(xk−1∣xk)。
1. 条件概率分布
p θ ( x k − 1 ∣ x k ) = N ( x k − 1 ; μ θ ( x k , k ) , Σ θ ( x k , k ) ) p_\theta(x_{k-1} | x_k) = \mathcal{N}\left(x_{k-1}; \mu_\theta(x_k, k), \Sigma_\theta(x_k, k)\right) pθ(xk−1∣xk)=N(xk−1;μθ(xk,k),Σθ(xk,k))
- 均值 : μ θ ( x k , k ) \mu_\theta(x_k, k) μθ(xk,k),由神经网络参数 θ \theta θ 建模,依赖当前噪声样本 x k x_k xk 和扩散步长 k k k。
- 协方差 : Σ θ ( x k , k ) \Sigma_\theta(x_k, k) Σθ(xk,k),实际中常固定为 σ k 2 I \sigma_k^2 I σk2I(简化训练,文档段落 )。
2. 训练目标:最小化 KL 散度
-
原始目标 :
L k = D KL ( q ( x k − 1 ∣ x k ) ∥ p θ ( x k − 1 ∣ x k ) ) \mathcal{L}k = D{\text{KL}}\left(q(x_{k-1} | x_k) \parallel p_\theta(x_{k-1} | x_k)\right) Lk=DKL(q(xk−1∣xk)∥pθ(xk−1∣xk))衡量真实
后验分布q q q 与模型分布 p θ p_\theta pθ 的差异(文档段落 )。 -
简化目标(基于前向过程可逆性) :
利用前向过程的对称性,引入
近似后验q ( x k − 1 ∣ x k , x 0 ) q(x_{k-1} | x_k, x_0) q(xk−1∣xk,x0),导出均方误差(MSE)损失(文档段落 ):
L k = 1 2 σ k 2 ∥ μ ~ k ( x k , x 0 , k ) − μ θ ( x k , k ) ∥ 2 \mathcal{L}_k = \frac{1}{2\sigma_k^2} \left\| \tilde{\mu}k(x_k, x_0, k) - \mu\theta(x_k, k) \right\|^2 Lk=2σk21∥μ~k(xk,x0,k)−μθ(xk,k)∥2其中 μ ~ k \tilde{\mu}_k μ~k 是基于前向过程的解析均值(公式 5-6)。
两种训练策略:噪声预测 vs 数据预测
扩散模型的核心差异在于 如何定义均值函数 μ θ \mu_\theta μθ,对应两种主流训练策略(文档段落 ):
1. 噪声预测(Noise Prediction,如 DDPM)
- 模型 :训练神经网络 ϵ θ ( x k , k ) \epsilon_\theta(x_k, k) ϵθ(xk,k) 预测前向过程中添加的噪声 ϵ \epsilon ϵ。
- 均值计算 :
μ ϵ ( ϵ θ ) = 1 α k x k − 1 − α k 1 − α ˉ k α k ϵ θ ( x k , k ) \mu_\epsilon(\epsilon_\theta) = \frac{1}{\sqrt{\alpha_k}} x_k - \frac{1 - \alpha_k}{\sqrt{1 - \bar{\alpha}k} \sqrt{\alpha_k}} \epsilon\theta(x_k, k) μϵ(ϵθ)=αk 1xk−1−αˉk αk 1−αkϵθ(xk,k) - 损失函数 :
L ϵ = E ∥ ϵ − ϵ θ ( x k , k ) ∥ 2 \mathcal{L}_\epsilon = \mathbb{E}\left \\left\\\| \\epsilon - \\epsilon_\\theta(x_k, k) \\right\\\|\^2 \\right Lϵ=E∥ϵ−ϵθ(xk,k)∥2
直接最小化预测噪声与真实噪声的差异,训练更稳定,生成质量更高(Ho et al., 2020,文档段落 )。
2. 数据预测(Data Prediction)
- 模型 :训练神经网络 x θ ( x k , k ) x_\theta(x_k, k) xθ(xk,k) 直接预测初始数据 x 0 x_0 x0。
- 均值计算 :
μ x ( x θ ) = α k ( 1 − α ˉ k − 1 ) 1 − α ˉ k x k + α ˉ k − 1 β k 1 − α ˉ k x θ ( x k , k ) \mu_x(x_\theta) = \frac{\sqrt{\alpha_k}(1 - \bar{\alpha}_{k-1})}{1 - \bar{\alpha}k} x_k + \frac{\sqrt{\bar{\alpha}{k-1}} \beta_k}{1 - \bar{\alpha}k} x\theta(x_k, k) μx(xθ)=1−αˉkαk (1−αˉk−1)xk+1−αˉkαˉk−1 βkxθ(xk,k) - 损失函数 :
L x = E ∥ x 0 − x θ ( x k , k ) ∥ 2 \mathcal{L}_x = \mathbb{E}\left \\left\\\| x_0 - x_\\theta(x_k, k) \\right\\\|\^2 \\right Lx=E∥x0−xθ(xk,k)∥2
直接优化数据重建误差,适用于噪声复杂或数据结构明确的场景(文档段落 )。
示例说明
场景 :预测未来 24 小时温度序列( x 0 ∈ R 24 x^0 \in \mathbb{R}^{24} x0∈R24)。
-
前向过程 :
初始温度序列 x 0 = 25 , 26 , 24 , . . . x^0 = 25, 26, 24, ... x0=25,26,24,...,通过 100 步扩散逐渐变为噪声 x 100 ∼ N ( 0 , I ) x^{100} \sim \mathcal{N}(0, I) x100∼N(0,I)。
-
反向过程 :
若使用噪声预测模型,第 50 步的输入 x 50 x^{50} x50 是带噪声的温度序列,模型预测当前步的噪声 ϵ θ \epsilon_\theta ϵθ,通过公式计算 x 49 x^{49} x49。
-
扩散过程
假设初始数据 x 0 = 1.0 , 0.5 x^0 = 1.0, 0.5 x0=1.0,0.5(二维向量),扩散步长 β 1 = 0.1 \beta_1 = 0.1 β1=0.1:
- 计算均值 :
1 − β 1 ⋅ x 0 = 0.9 ⋅ 1.0 , 0.5 ≈ 0.9487 , 0.4743 \sqrt{1-\beta_1} \cdot x^0 = \sqrt{0.9} \cdot 1.0, 0.5 \approx 0.9487, 0.4743 1−β1 ⋅x0=0.9 ⋅1.0,0.5≈0.9487,0.4743 - 协方差矩阵 :
β 1 I = 0.1 ⋅ 1 0 0 1 \beta_1 I = 0.1 \cdot \begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} β1I=0.1⋅1001 - 采样 x 1 x^1 x1 :
从 N ( 0.9487 , 0.4743 , 0.1 I ) \mathcal{N}(0.9487, 0.4743, 0.1I) N(0.9487,0.4743,0.1I) 中随机采样,例如:
x 1 ≈ 0.9487 + ϵ 1 , 0.4743 + ϵ 2 x^1 \approx 0.9487 + \\epsilon_1, 0.4743 + \\epsilon_2 x1≈0.9487+ϵ1,0.4743+ϵ2
其中 ϵ 1 , ϵ 2 ∼ N ( 0 , 0.1 ) \epsilon_1, \epsilon_2 \sim \mathcal{N}(0, 0.1) ϵ1,ϵ2∼N(0,0.1)。
扩散过程的作用
通过逐步增大 β k \beta_k βk,前向过程将数据 x 0 x^0 x0 逐渐变为纯噪声:
• 初始步 ( k = 0 k=0 k=0): x 0 x^0 x0 是原始数据。
• 中间步 ( k = 1 , 2 , . . . , K − 1 k=1,2,...,K-1 k=1,2,...,K−1):数据逐渐模糊化。
• 最终步 ( k = K k=K k=K): x K x^K xK 近似为标准高斯噪声 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)。
- 计算均值 :
2.2条件扩散模型(Conditional Diffusion Models)
条件扩散模型(Conditional Diffusion Models)当存在额外条件输入 c c c(如时间序列中的历史观测)时,将其注入反向过程(文档段落 ):
p θ ( x k − 1 ∣ x k , c ) = N ( x k − 1 ; μ θ ( x k , k ∣ c ) , σ k 2 I ) p_\theta(x_{k-1} | x_k, c) = \mathcal{N}\left(x_{k-1}; \mu_\theta(x_k, k|c), \sigma_k^2 I\right) pθ(xk−1∣xk,c)=N(xk−1;μθ(xk,k∣c),σk2I)
- 条件均值 : μ θ ( x k , k ∣ c ) \mu_\theta(x_k, k|c) μθ(xk,k∣c),同时依赖噪声样本 x k x_k xk、扩散步长 k k k 和条件 c c c。
- 应用 :在时间序列预测中, c c c 可为历史数据编码,引导模型生成与历史相关的未来序列(如 TimeDiff 的核心创新,见文档 3.2 节)。
核心公式总结表
| 过程 | 公式 | 物理意义 |
|---|---|---|
| 前向扩散(分步) | x k = 1 − β k x k − 1 + β k ϵ x_k = \sqrt{1 - \beta_k} x_{k-1} + \sqrt{\beta_k} \epsilon xk=1−βk xk−1+βk ϵ | 每一步缩放前序样本并添加噪声,逐步破坏数据结构。 |
| 前向扩散(直接) | x k = α ˉ k x 0 + 1 − α ˉ k ϵ x_k = \sqrt{\bar{\alpha}_k} x_0 + \sqrt{1 - \bar{\alpha}_k} \epsilon xk=αˉk x0+1−αˉk ϵ | 直接从初始数据生成任意步噪声样本,避免分步计算(重参数化技巧)。 |
| 反向去噪分布 | $p_\theta(x_{k-1} | x_k) = \mathcal{N}(\mu_\theta, \sigma_k^2 I)$ |
| 噪声预测损失 | L ϵ = E ∣ ϵ − ϵ θ ∣ 2 \mathcal{L}\epsilon = \mathbb{E}\left| \epsilon - \epsilon\theta \right|^2 Lϵ=E∣ϵ−ϵθ∣2 | 最小化预测噪声与真实噪声的差异,训练稳定,生成质量高(DDPM 采用)。 |
| 数据预测损失 | L x = E ∣ x 0 − x θ ∣ 2 \mathcal{L}x = \mathbb{E}\left| x_0 - x\theta \right|^2 Lx=E∣x0−xθ∣2 | 直接优化初始数据重建误差,适用于结构化数据(如时间序列)。 |
2.3. Conditional DDPMs for Time Series Prediction (时间序条件扩散模型)
0、核心思想
给定 历史观测 x − L + 1 : 0 0 ∈ R d × L x_{-L+1:0}^0 \in \mathbb{R}^{d \times L} x−L+1:00∈Rd×L(包含 d d d 个变量,长度为 L L L 的历史窗口),预测 未来值 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H(长度为 H H H 的预测窗口)。核心是建模条件分布 p θ ( x 1 : H 0 ∣ x − L + 1 : 0 0 ) p_\theta(x_{1:H}^0 | x_{-L+1:0}^0) pθ(x1:H0∣x−L+1:00),其中:
- 前向扩散过程:向预测值 x 1 : H 0 ∈ R d × H x_{1:H}^0 \in \mathbb{R}^{d \times H} x1:H0∈Rd×H
(训练集中真实值已知)中不断加噪 x 1 : H k ∈ R d × H x_{1:H}^k \in \mathbb{R}^{d \times H} x1:Hk∈Rd×H(k步扩散) - 后向去噪过程: 历史观测 x − L + 1 : 0 0 ∈ R d × L x_{-L+1:0}^0 \in \mathbb{R}^{d \times L} x−L+1:00∈Rd×L经过F获得条件c, p θ ( x 1 : H k − 1 ∣ x 1 : H k , c ) p_\theta(x_{1:H}^{k-1} | x_{1:H}^k, c) pθ(x1:Hk−1∣x1:Hk,c)反向去噪分布,在第 k k k 次去噪步骤中, x 1 : H k x_{1:H}^k x1:Hk 被去噪为 x 1 : H k − 1 x_{1:H}^{k-1} x1:Hk−1。
联合分布 :(文中没说明其作用)
给定条件 c = F ( x − L + 1 : 0 0 ) c = F(x_{-L+1:0}^0) c=F(x−L+1:00)(历史观测编码),联合分布 p θ ( x 1 : H 0 : K ∣ c ) p_\theta (x_{1:H}^{0:K} | c) pθ(x1:H0:K∣c) 描述了 未来序列在扩散过程中所有中间状态(从初始数据 x 1 : H 0 x_{1:H}^0 x1:H0 到最终噪声 x 1 : H K x_{1:H}^K x1:HK)的联合概率分布 。其分解为两部分(遵循马尔可夫链性质):
p θ ( x 1 : H 0 : K ∣ c ) = p θ ( x 1 : H K ) ⏟ 初始噪声分布 × ∏ k = 1 K p θ ( x 1 : H k − 1 ∣ x 1 : H k , c ) ⏟ 反向去噪步骤的条件分布乘积 p_\theta (x_{1:H}^{0:K} | c) = \underbrace{p_\theta (x_{1:H}^K)}{\text{初始噪声分布}} \times \underbrace{\prod{k=1}^K p_\theta (x_{1:H}^{k-1} | x_{1:H}^k, c)}_{\text{反向去噪步骤的条件分布乘积}} pθ(x1:H0:K∣c)=初始噪声分布 pθ(x1:HK)×反向去噪步骤的条件分布乘积 k=1∏Kpθ(x1:Hk−1∣x1:Hk,c)
- 下标 1 : H 1:H 1:H :未来序列的时间范围(预测窗口,长度为 H H H);
- 上标 0 : K 0:K 0:K :扩散过程的步骤( 0 0 0 为初始真实数据, K K K 为最终噪声)。
1. 条件分布建模
- 联合分布 :
p θ ( x 1 : H 0 : K ∣ c ) = p θ ( x 1 : H K ) ∏ k = 1 K p θ ( x 1 : H k − 1 ∣ x 1 : H k , c ) p_\theta(x_{1:H}^{0:K} | c) = p_\theta(x_{1:H}^K) \prod_{k=1}^K p_\theta(x_{1:H}^{k-1} | x_{1:H}^k, c) pθ(x1:H0:K∣c)=pθ(x1:HK)k=1∏Kpθ(x1:Hk−1∣x1:Hk,c) - x 1 : H K ∼ N ( 0 , I ) x_{1:H}^K \sim \mathcal{N}(0, I) x1:HK∼N(0,I):初始噪声(第 K K K 步扩散后的样本,完全随机);
- c = F ( x − L + 1 : 0 0 ) c = F(x_{-L+1:0}^0) c=F(x−L+1:00):历史观测通过条件网络 F F F(如卷积网络)编码的条件信号;
- p θ ( x 1 : H k − 1 ∣ x 1 : H k , c ) p_\theta(x_{1:H}^{k-1} | x_{1:H}^k, c) pθ(x1:Hk−1∣x1:Hk,c):反向去噪分布,均值由神经网络 μ θ ( x 1 : H k , k ∣ c ) \mu_\theta(x_{1:H}^k, k|c) μθ(x1:Hk,k∣c) 建模,方差固定为 σ k 2 I \sigma_k^2 I σk2I。
2. 核心挑战
如何设计高效的 去噪网络 μ θ \mu_\theta μθ (从噪声中恢复信号)和 条件网络 F F F (提取历史观测的有效特征),尤其是在长程预测( H H H 较大)和多变量( d d d 较大)场景下。
现有时间序列扩散模型分析
1. TimeGrad(自回归模型,Rasul et al., 2021)
- 核心思路 :逐时刻生成未来值(自回归解码),每个时刻 t t t 的扩散过程独立建模。
- 联合分布 :
p θ ( x 1 : H 0 : K ∣ c ) = ∏ t = 1 H p θ ( x t 0 : K ∣ c = F ( x − L + 1 : t − 1 0 ) ) p_\theta(x_{1:H}^{0:K} | c) = \prod_{t=1}^H p_\theta(x_t^{0:K} | c = F(x_{-L+1:t-1}^0)) pθ(x1:H0:K∣c)=t=1∏Hpθ(xt0:K∣c=F(x−L+1:t−10))
p θ ( x 1 : H 0 : K ) p_{\theta}(x_{1: H}^{0: K}) pθ(x1:H0:K) , where x 1 : H 0 : K = x 1 : H 0 ∪ x 1 : H k k = 1 , . . . , K x_{1: H}^{0: K}={x_{1: H}^{0}} \cup {x_{1: H}^{k}}{k=1, ..., K} x1:H0:K=x1:H0∪x1:Hkk=1,...,K
p θ ( x 1 : H 0 : K ∣ c = F ( x − L + 1 : 0 0 ) ) = ∏ t = 1 H p θ ( x t 0 : K ∣ c = F ( x − L + 1 : t − 1 0 ) ) = ∏ t = 1 H p θ ( x t K ) ∏ k = 1 K p θ ( x t k − 1 ∣ x t k , c = F ( x − L + 1 : t − 1 0 ) ) . \begin{aligned} p{\theta} & \left(x_{1: H}^{0: K} | c=\mathcal{F}\left(x_{-L+1: 0}^{0}\right)\right) \\ & =\prod_{t=1}^{H} p_{\theta}\left(x_{t}^{0: K} | c=\mathcal{F}\left(x_{-L+1: t-1}^{0}\right)\right) \\ & =\prod_{t=1}^{H} p_{\theta}\left(x_{t}^{K}\right) \prod_{k=1}^{K} p_{\theta}\left(x_{t}^{k-1} | x_{t}^{k}, c=\mathcal{F}\left(x_{-L+1: t-1}^{0}\right)\right) . \end{aligned} pθ(x1:H0:K∣c=F(x−L+1:00))=t=1∏Hpθ(xt0:K∣c=F(x−L+1:t−10))=t=1∏Hpθ(xtK)k=1∏Kpθ(xtk−1∣xtk,c=F(x−L+1:t−10)).
- 联合分布 :
其中 F F F 是循环神经网络(RNN),用隐藏状态 h t h_t ht 作为条件 c c c。
- 训练目标 :类似噪声预测损失(文档公式 8),预测每个时刻 t t t 的噪声 ϵ \epsilon ϵ。
- 优缺点 :
- ✅ 适用于短期预测,利用 RNN 捕捉时序依赖;
- ❌ 自回归解码导致 误差累积 (前一时刻的错误影响后续)和 推理速度慢(需逐个生成时刻),长程预测性能差。
2. CSDI(非自回归模型,Tashiro et al., 2021)
- 核心思路 :对整个时间序列(历史 + 未来)加噪并去噪,通过 掩码机制 区分观测和未观测部分(类似图像修复)。
- 输入与掩码 :
- 输入: x − L + 1 : H 0 x_{-L+1:H}^0 x−L+1:H0(历史 + 未来真实值)和二进制掩码 m m m( m i , t = 0 m_{i,t}=0 mi,t=0 表示观测到的位置, 1 1 1 表示待预测的未来位置);
- 训练时,模型接收 观测部分 x observed k = ( 1 − m ) ⊙ x − L + 1 : H k x_{\text{observed}}^k = (1-m) \odot x_{-L+1:H}^k xobservedk=(1−m)⊙x−L+1:Hk 和 待预测部分 x target k = m ⊙ x − L + 1 : H k x_{\text{target}}^k = m \odot x_{-L+1:H}^k xtargetk=m⊙x−L+1:Hk。
- 损失函数 :预测待预测部分的噪声,条件 c = F ( x observed k ) c = F(x_{\text{observed}}^k) c=F(xobservedk)。
- 输入与掩码 :
- 优缺点 :
- ✅ 非自回归解码,一次性生成所有未来值,避免误差累积;
- ❌ ① 去噪网络基于 Transformer,复杂度随变量数 d d d 和序列长度 L + H L+H L+H 呈 二次增长 ( O ( ( d ( L + H ) ) 2 ) O((d(L+H))^2) O((d(L+H))2)),处理长多元序列时内存溢出;② 掩码导致 边界不和谐(预测段与历史段的连接处趋势不连续,类似图像修复的边界模糊问题)。
3. SSSD(CSDI 改进版,Alcaraz & Strodthoff, 2022)
- 改进点 :用 结构化状态空间模型 替代 Transformer,降低复杂度至线性( O ( d ( L + H ) ) O(d(L+H)) O(d(L+H))),解决内存问题。
- 局限:仍依赖掩码条件策略,未解决边界不和谐问题,长程预测精度受限。
4. 与 NLP 模型的对比
NLP 中的非自回归扩散模型(如 DiffuSeq)处理规则序列(文本),而时间序列具有 不规则性、高非线性、强噪声,需更针对性的时序依赖建模(如捕捉短期趋势、周期性),现有 NLP 方法无法直接套用。
四、核心问题总结
| 模型 | 解码方式 | 条件策略 | 优势 | 缺陷 |
|---|---|---|---|---|
| TimeGrad | 自回归 | RNN 隐藏状态 | 短期预测有效 | 误差累积、推理慢(长程差) |
| CSDI | 非自回归 | 掩码(类似图像修复) | 并行生成未来值 | 高复杂度(Transformer)、边界不和谐 |
| SSSD | 非自回归 | 状态空间模型 | 低复杂度 | 边界不和谐问题仍存在 |
现有模型的核心痛点:
- 自回归模型的效率与误差问题;
- 非自回归模型的条件策略不适配时序特性(掩码导致边界问题,未利用时序先验)。
这为 TimeDiff 的创新(未来混合 + 自回归初始化,见文档 3.2 节)提供了设计方向:通过定制化条件机制,融合历史信息与未来先验,提升长程预测精度和效率。