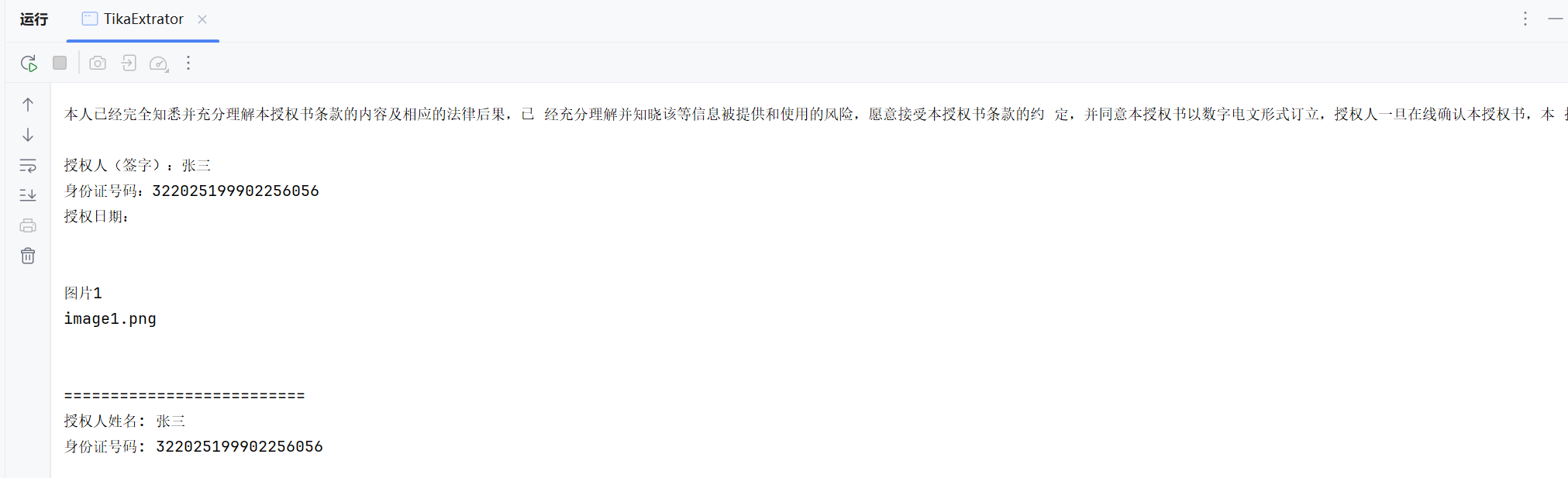
本文介绍如何通过apache tika从文档(pdf、doc、docx、txt)中 提取特征数据,比如文档中有身份证、姓名等信息。【全部是经本人实际测试过的功能】
1、需引入相关pom依赖
<!-- apache tika 包,用于解析pdf、word文本文档-->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-core</artifactId>
<version>2.8.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.tika/tika-parsers-standard-package -->
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers-standard-package</artifactId>
<version>2.8.0</version>
</dependency>2、编写相关代码
package org.example.wordcontent;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import java.io.File;
import java.io.IOException;
import java.io.InputStream;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 通过apache tika从 pdf、doc、docx、txt中提取数据
* 核心依赖jar【tika-core 2.8.0、tika-parsers-standard-package 2.8.0(解析word时,需另外外依赖xmlbeans 5.1.1)】
* 假定文档中的内容具有下列属性:
* [授权人(签字):张三
* 身份证号码: 322025199902256056 ]
* 待提取的内容为张三 和 322025199902256056。张三和322025199902256056的值会变
*/
public class TikaExtrator {
public static void main(String[] args) {
try {
//// 替换为实际的PDF文件路径 测试例子: 如 测试.xlsx.
InputStream input = TikaExtrator.class.getClassLoader().getResourceAsStream("综合信息查询授权书测试.docx");
String text = extractTextFromFile(input);
System.out.println("text: " + text);
String name = extractName(text);
String idNumber = extractIdNumber(text);
System.out.println("授权人姓名: " + name);
System.out.println("身份证号码: " + idNumber);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
*
* @param inputStream
* @return
* @throws IOException
*/
private static String extractTextFromFile(InputStream inputStream) throws IOException {
Tika tika = new Tika();
try {
return tika.parseToString(inputStream);
} catch (TikaException e) {
throw new RuntimeException(e);
}
}
private static String extractName(String text) {
Pattern pattern = Pattern.compile("授权人(签字)[::]([\\u4e00-\\u9fa5]+)");
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
return matcher.group(1);
}
return "";
}
private static String extractIdNumber(String text) {
Pattern pattern = Pattern.compile("身份证号码[::](\\d{18}|\\d{15})");
Matcher matcher = pattern.matcher(text);
if (matcher.find()) {
return matcher.group(1);
}
return "";
}
}3、执行效果