连接方式
内嵌Hive:
使用时无需额外操作,但实际生产中很少使用。
外部Hive:
在虚拟机下载相关配置文件,在spark-shell中连接需将hive-site.xml拷贝到conf/目录并修改url、将MySQL驱动copy到jars/目录、把core-site.xml和hdfs-site.xml拷贝到conf/目录,最后重启spark-shell。

(++sz, rz这俩作用不一样,一个是输送到本地文件,一个是本地输到远程服务器的当前目录++)
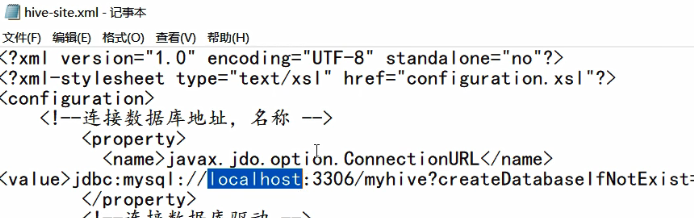
将url中的localhost改为node01

重新启动后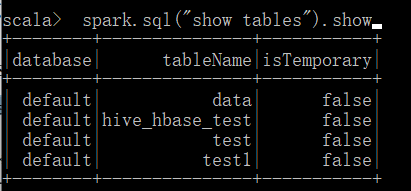
运行Spark-SQL CLI:
可在本地运行Hive元数据服务和执行查询任务。
将mysql驱动放入jars/、hive-site.xml文件放入conf/,运行bin/目录下的spark-sql.cmd即可执行SQL语句。
代码操作Hive:
导入spark-hive_2.12和hive-exec依赖,将hive-site.xml拷贝到项目resources目录。
若执行时出错,可设置HADOOP_USER_NAME解决。
默认数据库在本地仓库,可通过配置修改数据库仓库地址。
1.导入依赖。
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>3.0.0</version></dependency><dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>2.3.3</version></dependency>
可能出现下载jar包的问题:D:\maven\repository\org\pentaho\pentaho-aggdesigner-algorithm\5.1.5-jhyde
2.将hive-site.xml 文件拷贝到项目的 resources 目录中。
3.代码实现。
val sparkConf = new SparkConf().setMaster("local\*").setAppName("hive")
val spark:SparkSession = SparkSession.builder()
.enableHiveSupport()
.config(sparkConf)
.getOrCreate()
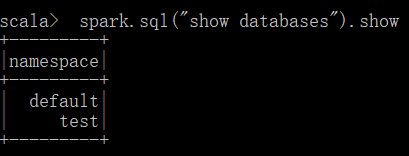
spark.sql("show databases").show()
spark.sql("create database spark_sql")
spark.sql("show databases").show()