一、定义
Spark SQL 是 Spark 用于结构化数据处理的模块,对于开发人员来讲,Spark SQL 可以简化 RDD 的开发,提高开发效率,且执行效率非常快,所以实际工作中,基本上采用的就是 Spark SQL。Spark SQL 为了简化 RDD 的开发,提高开发效率,提供了两个编程抽象,类似 Spark Core 中的 RDD。即 DataFrame 和 DataSet。
1.1 DataFrame
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame 和 RDD 的主要区别在于,DataFrame 带有 schema 元信息,即 DataFrame 所表示的二维表格数据集的每一列都带有名称和类型。这使得 Spark SQL 得以获取更多的结构信息,从而对数据源以及 DataFrame 的操作进行针对性的优化,提升运行时的效率。而 RDD 由于无法获取数据元素的具体内存结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
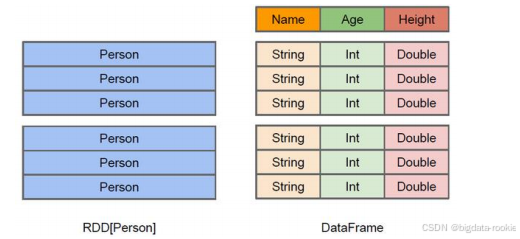
上图直观地体现了 DataFrame 和 RDD 的区别。
DataFrame 也是懒执行的,但性能上比 RDD 要高,主要原因是:优化的执行计划,即查询计划通过 Spark catalyst optimiser 进行优化。比如下面一个例子:
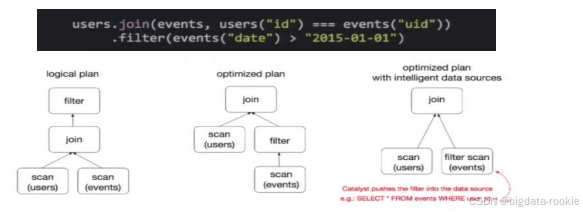
图中构造了两个 DataFrame,将它们 join 之后又做了一次 filter 操作。如果原封不动地执行这个执行计划,最终的执行效率是不高的。因为 join 是一个代价较大的操作,可能会产生一个较大的数据集。如果能将 filter 下推到 join 下方,先对 DataFrame 进行过滤,再 join 过滤后的较小的结果集,便可以有效缩短执行时间。而 Spark SQL 的查询优化器正是这样做的。
使用 DataFrame 不用必须注册临时表或者生成 SQL 表达式就可以直接进行 transform 操作 和 action 操作。
1.2 DataSet
DataSet 是分布式数据集合,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换操作(map、flatMap、filter 等等)。
- DataSet 是 DataFrame API 的一个扩展,是 Spark SQL 最新的数据抽象;
- 既具有类型安全检查也具有 DataFrame 的查询优化特性;
- 用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名字直接映射到 DataSet 中的字段名称;
- DataFrame 是 DataSet 的特例,DataFrame = DataSetRow,可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,所有的表结构信息都用 Row 来表示,获取数据时需要指定顺序;
二、RDD、DataFrame、DataSet
2.1 三者的共性
- 三者都有惰性机制,在进行创建、转换时,不会立即执行,只有在遇到 action 算子时才会开始遍历运算;
- 三者都会根据 Spark 的内存情况自动缓存运算,这样即使数据量很大,也不用担心会内存溢出;
- 在对 DataFrame 和 DataSet 进行操作时需要导入这个包:import spark.implicits._ ;
- DataFrame 和 DataSet 均可使用模式匹配获取各字段的值和类型;
2.2 三者的区别
2.2.1 RDD
- RDD 不支持 Spark SQL
2.2.2 DataFrame
- DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过解析才能获取各个字段的值;
2.2.3 DataSet
- DataSet 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同;
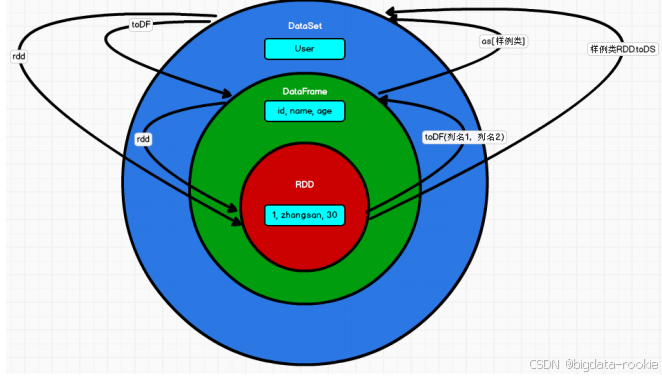
2.3 三者的互相转换