1 Schema
Schema 定义了 Collections 的数据结构。在创建一个 Collection 之前,你需要设计出它的 Schema。本页将帮助你理解 Collections 模式,并自行设计一个示例模式。
在 Zilliz Cloud 上,Collection Schema 是关系数据库中一个表的组合,它定义了 Zilliz Cloud 如何组织 Collection 中的数据。设计良好的 Schema 至关重要,因为它抽象了数据模型,并决定能否通过搜索实现业务目标。此外,由于插入 Collections 的每一行数据都必须遵循 Schema,因此有助于保持数据的一致性和长期质量。从技术角度看,定义明确的 Schema 会带来组织良好的列数据存储和更简洁的索引结构,从而提升搜索性能。 一个 Collection Schema 有一个主键、最多四个向量字段和几个标量字段。
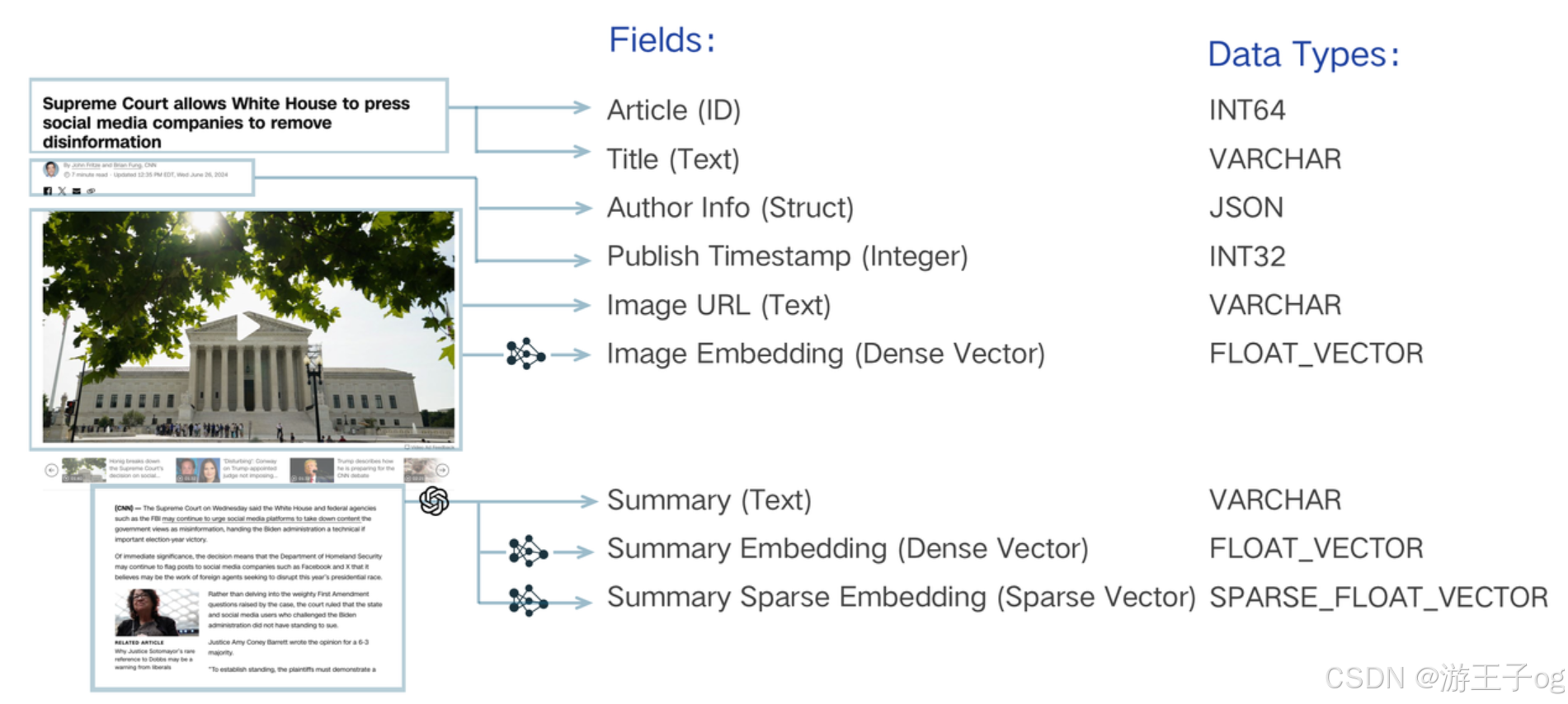
搜索系统的数据模型设计包括分析业务需求,并将信息抽象为模式表达的数据模型。例如,搜索一段文本必须通过 "嵌入 "将字面字符串转换为向量并启用向量搜索,从而实现 "索引"。除了这一基本要求外,可能还需要存储出版时间戳和作者等其他属性。有了这些元数据,就可以通过过滤来完善语义搜索,只返回特定日期之后或特定作者发表的文本。您还可以检索这些标量与主文本,以便在应用程序中呈现搜索结果。每个标量都应分配一个唯一标识符,以整数或字符串的形式组织这些文本片段。这些元素对于实现复杂的搜索逻辑至关重要。
1.1 创建 Schema
以下代码片段演示了如何创建模式。
python
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()1.2 添加主字段
Collections 中的主字段唯一标识一个实体。它只接受Int64 或VarChar值。以下代码片段演示了如何添加主字段。
python
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
# highlight-start
is_primary=True,
auto_id=False,
# highlight-end
)添加字段时,可以通过将is_primary 属性设置为True 来明确说明该字段是主字段。主字段默认接受Int64 值。在这种情况下,主字段值应为整数,类似于12345 。如果选择在主字段中使用VarChar 值,则其值应为字符串,类似于my_entity_1234 。也可以将autoId 属性设置为True ,使 Zilliz Cloud 在插入数据时自动分配主字段值。
1.3 添加向量字段
向量字段接受各种稀疏和密集向量嵌入。在 Zilliz Cloud 上,您可以向 Collections 添加四个向量字段。以下代码片段演示了如何添加向量字段。
python
schema.add_field(
field_name="my_vector",
datatype=DataType.FLOAT_VECTOR,
# highlight-next-line
dim=5
)上述代码片段中的dim 参数表示向量字段中要保存的向量嵌入的维数。FLOAT_VECTOR 值表示向量字段持有 32 位浮点数列表,通常用于表示反比例。除此之外,Zilliz Cloud 还支持以下类型的向量嵌入:
FLOAT16_VECTOR:这种类型的向量场保存一个 16 位半精度浮点数列表,通常适用于内存或带宽受限的深度学习或基于 GPU 的计算场景。BFLOAT16_VECTOR:这种类型的向量字段保存 16 位浮点数列表,精度有所降低,但指数范围与 Float32 相同。这种类型的数据常用于深度学习场景,因为它能在不明显影响精度的情况下减少内存使用量。BINARY_VECTOR:这种类型的向量场保存着一个 0 和 1 的列表。它们是图像处理和信息检索场景中表示数据的紧凑特征。SPARSE_FLOAT_VECTOR:这种类型的向量场可保存非零数字及其序列号列表,用于表示稀疏向量嵌入。
1.4 添加标量字段
在常见情况下,可以使用标量字段来存储存储在 Milvus 中的向量嵌入的元数据,并通过元数据过滤进行 ANN 搜索,以提高搜索结果的正确性。Zilliz Cloud 支持多种标量字段类型,包括VarChar 、Boolean 、Int 、Float 、Double 、Array 和JSON。
1.4.1 添加字符串字段
在 Milvus 中,您可以使用 VarChar 字段来存储字符串。
python
schema.add_field(
field_name="my_varchar",
datatype=DataType.VARCHAR,
# highlight-next-line
max_length=512
)1.4.2 添加数字字段
Milvus 支持的数字类型有Int8,Int16,Int32,Int64,Float 和Double 。
python
schema.add_field(
field_name="my_int64",
datatype=DataType.INT64,
)1.4.3 添加布尔字段
Milvus 支持布尔字段。以下代码片段演示了如何添加布尔字段。
python
schema.add_field(
field_name="my_bool",
datatype=DataType.BOOL,
)1.4.4 添加 JSON 字段
JSON 字段通常存储半结构化的 JSON 数据。
python
schema.add_field(
field_name="my_json",
datatype=DataType.JSON,
)1.4.5 添加数组字段
数组字段存储元素列表。数组字段中所有元素的数据类型应相同。
python
schema.add_field(
field_name="my_array",
datatype=DataType.ARRAY,
element_type=DataType.VARCHAR,
max_capacity=5,
max_length=512,
)2 主字段和自动识别
主字段唯一标识一个实体。本页介绍如何添加两种不同数据类型的主字段,以及如何启用 Milvus 自动分配主字段值。在 Collections 中,每个实体的主键都应该是全局唯一的。添加主字段时,需要显式地将其数据类型设置为VARCHAR 或INT64 。将其数据类型设置为INT64 表示主键应为整数,类似于12345 ;将其数据类型设置为VARCHAR 表示主键应为字符串,类似于my_entity_1234 。
你也可以启用AutoID ,让 Milvus 自动为进入的实体分配主键。在集合中启用AutoID后,插入实体时不要包含主键。Collections 中的主字段没有默认值,也不能为空。
2.1 使用 Int64 主键
要使用 Int64 类型的主键,需要将datatype 设置为DataType.INT64 ,将is_primary 设置为true 。如果还需要 Milvus 为进入的实体分配主键,还需要将auto_id 设置为true 。
python
from pymilvus import MilvusClient, DataType
schema = MilvusClient.create_schema()
schema.add_field(
field_name="my_id",
datatype=DataType.INT64,
# highlight-start
is_primary=True,
auto_id=True,
# highlight-end
)2.2 使用 VarChar 主键
要使用 VarChar 主键,除了将data_type 参数值更改为DataType.VARCHAR 外,还需要为字段设置max_length 参数。
python
schema.add_field(
field_name="my_id",
datatype=DataType.VARCHAR,
# highlight-start
is_primary=True,
auto_id=True,
max_length=512,
# highlight-end
)