简介

EMO2(End-Effector Guided Audio-Driven Avatar Video Generation)是由HumanAIGC团队开发的一个音频驱动的人像视频生成框架,旨在生成富有表现力的面部表情和手势动作的肖像视频。该项目扩展了原EMO(Emote Portrait Alive)项目,增加了手部动作生成功能,显著提升了视频的真实性和动态感。本报告从项目背景、技术架构和性能表现等方面进行详细分析,结合相关技术报告提供全面见解。
项目背景
EMO2的开发背景是解决传统音频驱动视频生成方法在捕捉全息手势和身体动作时的局限性。研究表明,现有方法(如CyberHost和Vlogger)往往聚焦于生成全身体或半身体姿态,但音频特征与全身体动作之间的对应关系较弱,导致生成结果不够自然。EMO2通过引入"像素先验逆运动学"(pixels prior IK)的概念,重新定义任务为两阶段过程:首先从音频生成手部动作,利用音频与手部动作的强相关性;然后将手部动作作为控制信号,引导视频生成中的面部表情和身体动作。
EMO2的应用场景非常广泛,包括:
-
歌唱:支持多种语言和节奏的歌曲,生成逼真的演唱视频,如使用Unholy - Sam Smith, Kim Petras或Yonezu Kenshi 「LOSER」┃Cover by Raon Lee的音频。
-
说话:支持多种语言和语气,适用于虚拟主持人或讲师,如Musk's Speech或Trevor's Talkshow。
-
手舞:生成富有表现力的手部动作,增强视频的动态感。
-
角色扮演(Cosplay):适用于电影或游戏角色,确保动作与角色特征一致,如AI Marilyn Monroe或Arthur Morgan from Red Dead Redemption。
技术架构
EMO2采用了两阶段框架,具体如下:
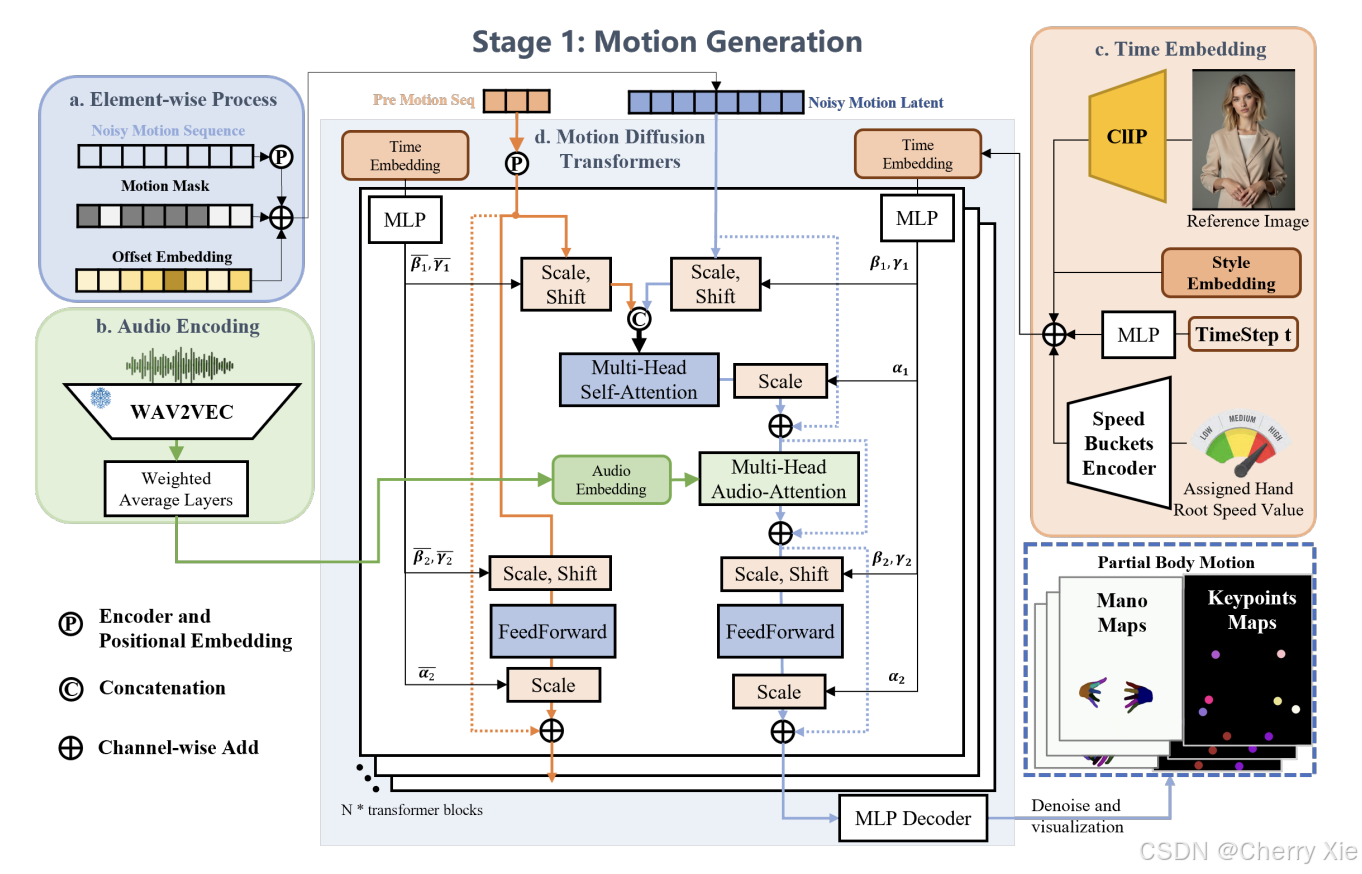
阶段1:部分身体动作生成
-
模型:使用Diffusion Transformer (DiT)作为主干网络,包含24个DiT块,隐藏层大小为512。
-
手部动作表示:使用MANO模型表示手部动作,每只手有48个关节旋转值(转换为64个四元数参数)和3个平移值,总共134个参数。
-
序列处理:手部参数序列填充到300帧,使用前12帧确保平滑过渡,避免动作突变。
-
训练细节:在A100 GPU上训练,批量大小为8,训练400k步,从头开始训练。
-
额外特征:
** 手部动作掩码:用于聚焦手部区域。
** 偏移嵌入:调整动作的时空位置。
** 风格/速度嵌入:控制动作的风格和速度。
** 可选的参考图像嵌入:使用CLIP生成类别嵌入,增强个性化。
阶段2:共语视频生成
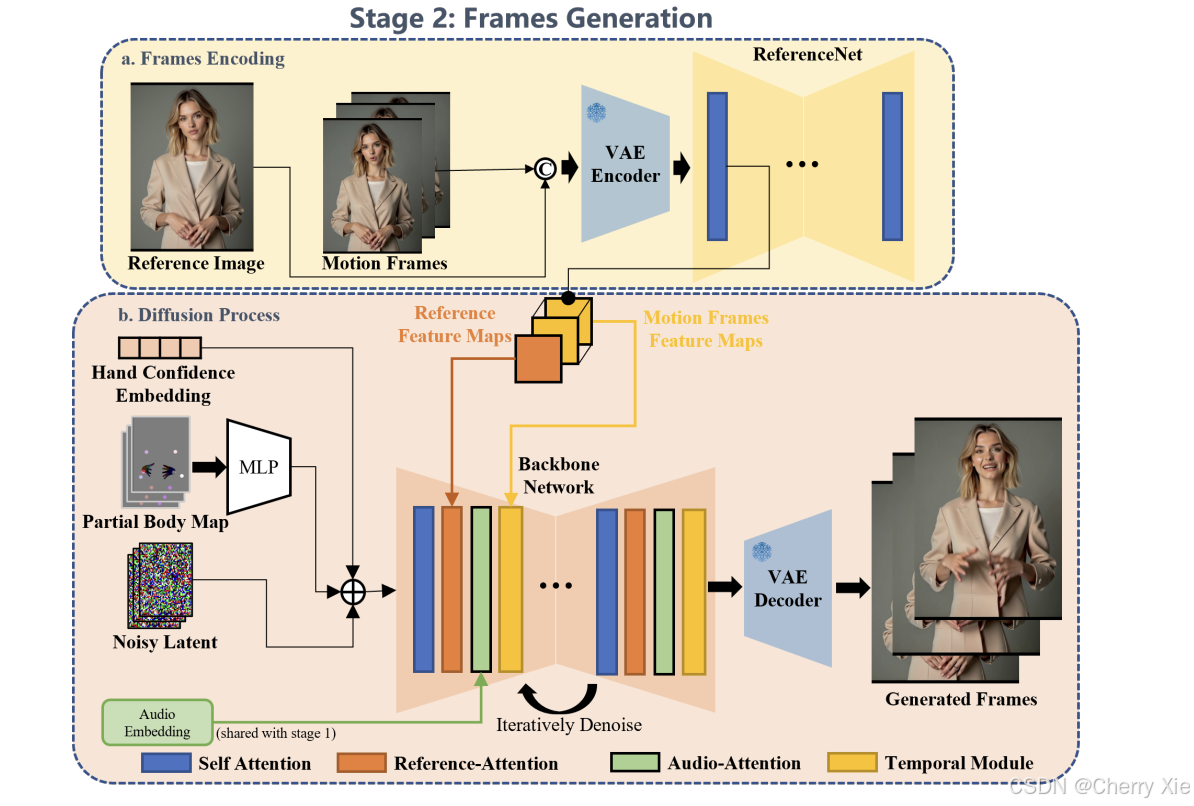
-
模型:基于原EMO,使用ReferenceNet-based diffusion架构,结合AnimateDiff的时间模块,确保帧间连续性。
-
训练阶段:
** 图像训练:分辨率704×512,批量大小32,训练100k步。
** 音频-视频训练:分辨率704×512,24帧,12个动作帧,批量大小4,训练100k步。
-
硬件:使用4个A100 GPU,学习率为1×10⁻⁵。
-
数据集:包括MOSEI、AVSPEECH和互联网视频,总计约275小时,涵盖演讲、电影、电视节目和唱歌等多种内容。
-
额外组件:
** MANO图:表示手部姿态。
** 关键点图:增强身体结构。
** 手部置信度嵌入:提高手部动作的准确性。
** 姿态判别器:基于ResNet,在潜在空间预训练,用于优化身体结构。
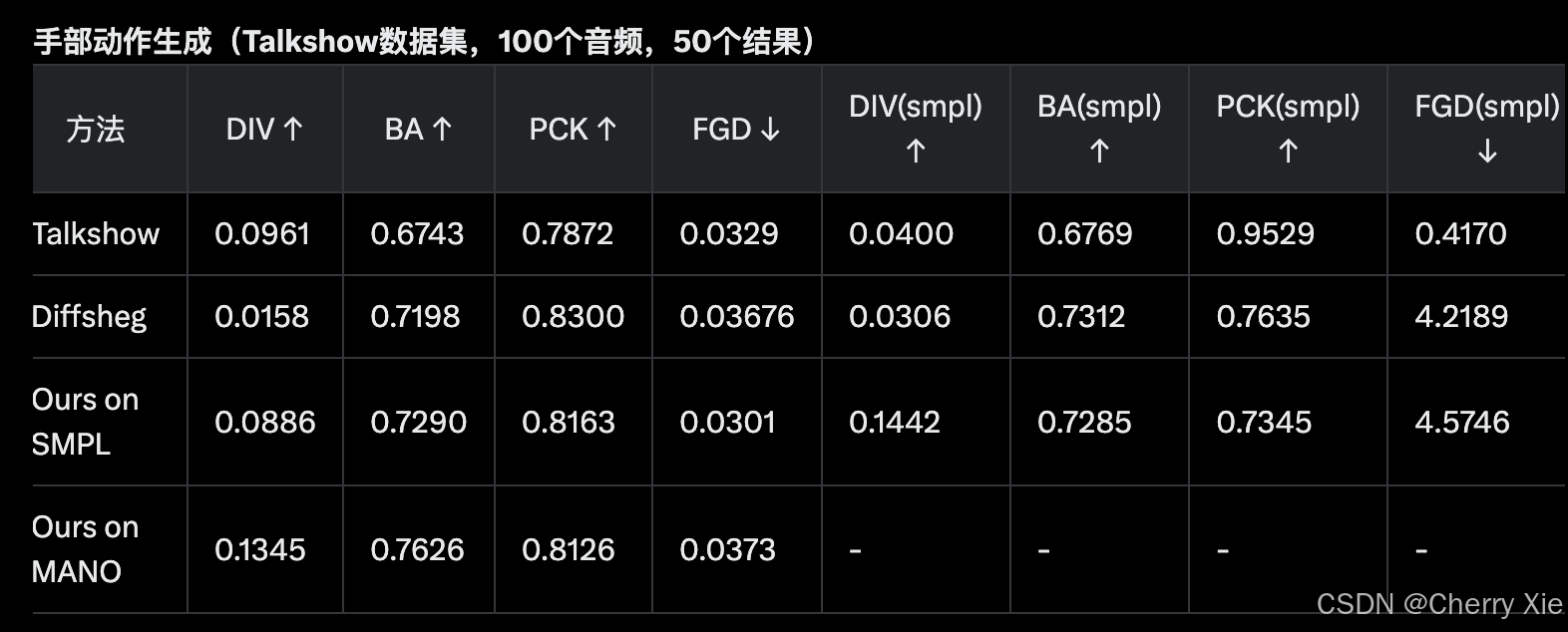
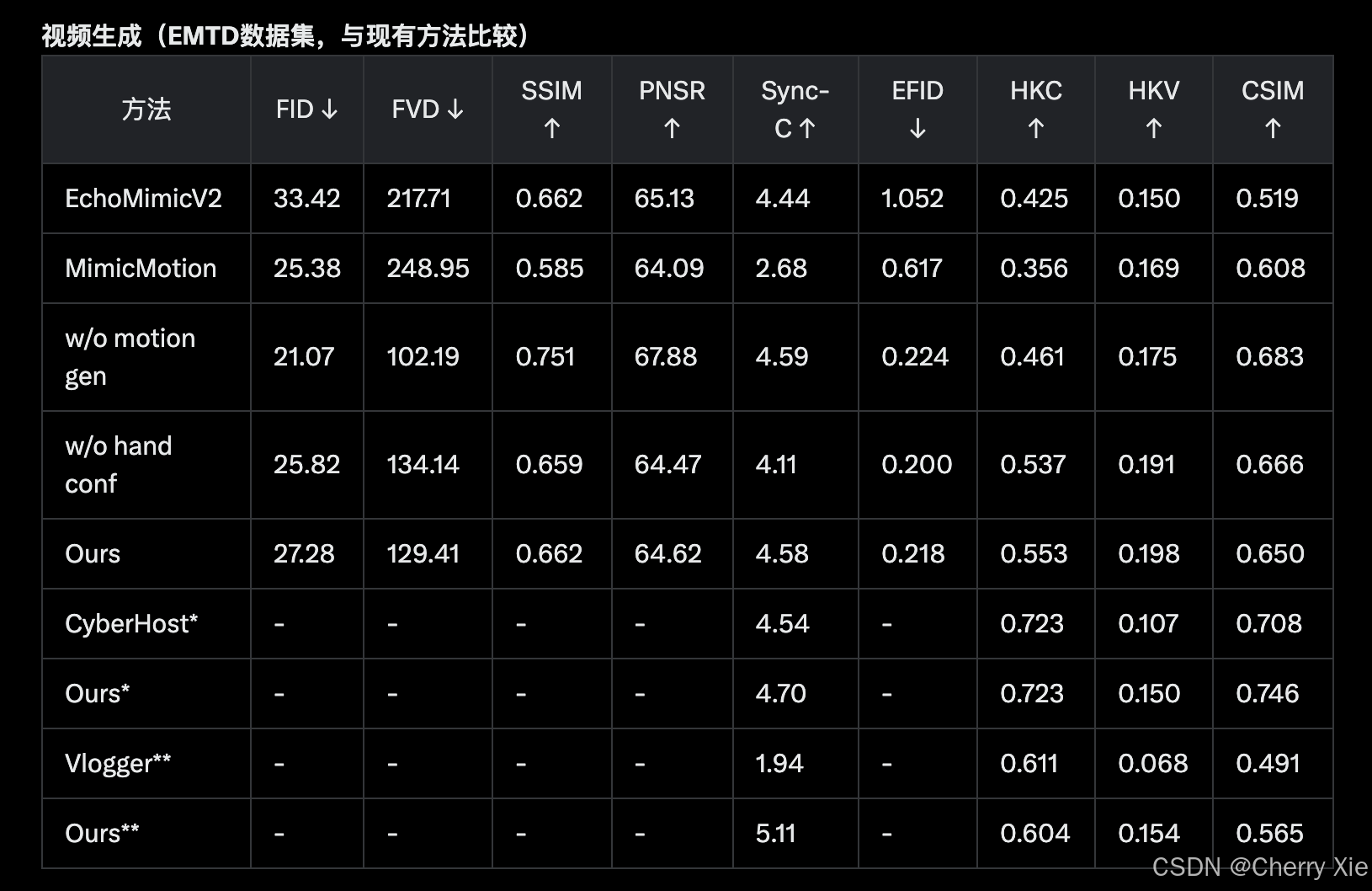
性能表现
详见技术报告