es索引结构和数据实例
这里提供索引结构和数据实例提供给大家使用练习,希望大家能够一起成长进步~~~~
java
#添加索引
PUT /ecommerce_products
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"custom_lowercase": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase"]
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"product_id": { "type": "keyword" },
"name": {
"type": "text",
"fields": {
"keyword": { "type": "keyword", "ignore_above": 256 }
},
"analyzer": "custom_lowercase"
},
"description": { "type": "text" },
"price": { "type": "scaled_float", "scaling_factor": 100 },
"in_stock": { "type": "boolean" },
"categories": { "type": "keyword" },
"tags": {
"type": "keyword",
"eager_global_ordinals": true
},
"created_at": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"last_updated": { "type": "date" },
"rating": { "type": "half_float" },
"reviews": {
"type": "nested",
"properties": {
"user_id": { "type": "keyword" },
"score": { "type": "byte" },
"comment": { "type": "text" },
"created_at": { "type": "date" },
"responses": {
"type": "nested",
"properties": {
"admin_id": { "type": "keyword" },
"response_text": { "type": "text" }
}
}
}
},
"warehouse_location": { "type": "geo_point" },
"supplier_info": {
"properties": {
"name": { "type": "keyword" },
"ip_address": { "type": "ip" }
}
},
"suggest": { "type": "completion" },
"attributes": {
"type": "object",
"dynamic": true
},
"name_translations": {
"type": "object",
"properties": {
"en": { "type": "text" },
"zh": { "type": "text", "analyzer": "ik_max_word" },
"es": { "type": "text" }
}
}
}
}
}
#查询索引
GET /ecommerce_products
#添加文档数据
#POST/索引库名/_doc/文档id
POST /ecommerce_products/_doc/1
{
"product_id": "P123456",
"name": "无线蓝牙耳机",
"description": "高端降噪耳机,30小时超长续航",
"price": 199.99,
"in_stock": true,
"categories": ["电子产品", "音频设备"],
"tags": ["无线", "降噪", "新款"],
"created_at": "2023-10-05T08:23:45Z",
"last_updated": "2024-02-15",
"rating": 4.5,
"reviews": [
{
"user_id": "U1001",
"score": 5,
"comment": "音质非常出色",
"created_at": "2023-12-01",
"responses": [
{
"admin_id": "ADM001",
"response_text": "感谢您的反馈!"
}
]
}
],
"warehouse_location": {
"lat": 40.7128,
"lon": -74.0060
},
"supplier_info": {
"name": "音科技术公司",
"ip_address": "192.168.1.100"
},
"suggest": {
"input": ["耳机", "蓝牙", "无线"],
"weight": 34
},
"attributes": {
"颜色": "黑色",
"重量_kg": 0.25
},
"name_translations": {
"en": "Wireless Headphones",
"zh": "无线蓝牙耳机",
"es": "Audífonos inalámbricos Bluetooth"
}
}
POST /ecommerce_products/_doc/2
{
"product_id": "P789012",
"name": "智能健身手环",
"description": "防水运动手环,支持心率监测和睡眠追踪",
"price": 79.99,
"in_stock": false,
"categories": ["可穿戴设备", "运动健康"],
"tags": ["防水", "心率监测", "入门款"],
"created_at": "2023-11-20",
"last_updated": "2024-03-10T14:30:00",
"rating": 4.2,
"reviews": [
{
"user_id": "U2002",
"score": 4,
"comment": "性价比不错,但APP需要改进",
"created_at": "2024-01-15",
"responses": [
{
"admin_id": "ADM002",
"response_text": "我们会持续优化软件体验"
}
]
}
],
"warehouse_location": "31.2304,121.4737",
"supplier_info": {
"name": "智动科技",
"ip_address": "10.20.30.40"
},
"suggest": {
"input": ["手环", "运动", "健康"],
"weight": 28
},
"attributes": {
"腕带材质": "硅胶",
"屏幕类型": "OLED"
}
}
POST /ecommerce_products/_doc/3
{
"product_id": "P345678",
"name": "智能温控水杯",
"description": "支持APP控制的保温水杯,12小时长效保温",
"price": 149.5,
"in_stock": true,
"categories": ["生活家电", "智能硬件"],
"tags": ["保温", "智能控制", "礼品"],
"created_at": "2024-02-01T09:15:30Z",
"rating": 4.8,
"reviews": [
{
"user_id": "U3003",
"score": 5,
"comment": "冬天保持水温效果非常好",
"created_at": "2024-03-01",
"responses": []
}
],
"warehouse_location": "22.3193,114.1694",
"supplier_info": {
"name": "智联家居",
"ip_address": "172.16.0.100"
},
"suggest": {
"input": ["水杯", "保温杯", "智能"],
"weight": 42
},
"attributes": {
"容量_ml": 500,
"材质": "不锈钢"
},
"name_translations": {
"en": "Smart Thermos Cup",
"zh": "智能温控水杯",
"es": "Taza termo inteligente"
}
}
POST /ecommerce_products/_doc/4
{
"product_id": "P456789",
"name": "健康监测智能手表",
"description": "1.5英寸AMOLED屏,支持血氧心率监测,50米防水",
"price": 899.0,
"in_stock": true,
"categories": ["可穿戴设备", "健康监测"],
"tags": ["防水", "长续航", "新品"],
"created_at": "2024-03-20T10:00:00Z",
"rating": 4.7,
"reviews": [
{
"user_id": "U4004",
"score": 5,
"comment": "游泳监测非常准确",
"created_at": "2024-04-05",
"responses": [
{
"admin_id": "ADM003",
"response_text": "感谢选择我们的产品!"
}
]
},
{
"user_id": "U3003",
"score": 5,
"comment": "喜欢",
"created_at": "2024-04-05",
"responses": [
{
"admin_id": "ADM003",
"response_text": "感谢选择我们的产品!"
}
]
}
],
"warehouse_location": "22.2833,114.1667",
"supplier_info": {
"name": "健康科技集团",
"ip_address": "10.88.10.25"
},
"attributes": {
"颜色": "曜石黑",
"表带材质": "氟橡胶",
"电池容量_mAh": 450
},
"name_translations": {
"en": "Health Monitoring Smart Watch",
"zh": "健康监测智能手表",
"es": "Taza termo inteligente"
}
}
POST /ecommerce_products/_doc/5
{
"product_id": "P567890",
"name": "静音空气净化器",
"description": "CADR 600m³/h,智能感应PM2.5,适用80㎡空间",
"price": 2499.0,
"in_stock": true,
"categories": ["生活家电", "环境电器"],
"tags": ["智能感应", "静音"],
"created_at": "2023-12-15",
"rating": 4.3,
"reviews": [
{
"user_id": "U3003",
"score": 4,
"comment": "睡眠模式确实安静",
"created_at": "2024-01-10",
"responses": []
}
],
"warehouse_location": {
"lat": 30.5728,
"lon": 104.0668
},
"supplier_info": {
"name": "清洁科技公司",
"ip_address": "172.20.10.5"
},
"attributes": {
"滤芯类型": "复合滤网",
"噪音分贝": 28,
"适用面积_㎡": 80
},
"name_translations": {
"en": "Health Monitoring Smart Watch",
"zh": "空气净化器",
"es": "Taza termo inteligente"
}
}
POST /ecommerce_products/_doc/6
{
"product_id": "P678901",
"name": "全掌气垫跑步鞋",
"description": "轻量透气网面,ZOOM AIR缓震技术",
"price": 699.0,
"in_stock": false,
"categories": ["运动服饰", "鞋类"],
"tags": ["促销", "限量款"],
"created_at": "2024-02-28T14:30:00Z",
"rating": 4.6,
"reviews": [
{
"user_id": "U6006",
"score": 2,
"comment": "尺码偏小建议买大一码",
"created_at": "2024-03-15",
"responses": [
{
"admin_id": "ADM002",
"response_text": "已反馈给质检部门改进"
}
]
}
],
"warehouse_location": "23.1291,113.2644",
"supplier_info": {
"name": "运动装备制造",
"ip_address": "192.168.2.200"
},
"attributes": {
"颜色": "荧光绿/黑",
"尺码": "42",
"重量_g": 320
},
"name_translations": {
"en": "Health Monitoring Smart Watch",
"zh": "全掌气垫跑步鞋",
"es": "Taza termo inteligente"
}
}
POST /ecommerce_products/_doc/8
{
"product_id": "P890123",
"name": "4K全景云台摄像头",
"description": "360°全景追踪,红外夜视,支持AI人形检测",
"price": 399.0,
"in_stock": true,
"categories": ["智能硬件", "安防"],
"tags": ["夜视", "AI识别"],
"created_at": "2024-01-10T08:00:00Z",
"rating": 4.0,
"reviews": [
{
"user_id": "U8008",
"score": 2,
"comment": "夜间画质有待提升",
"created_at": "2024-02-01",
"responses": []
}
],
"warehouse_location": "39.9042,116.4074",
"supplier_info": {
"name": "智能安防科技",
"ip_address": "192.168.5.100"
},
"attributes": {
"原价": "599",
"存储方式": ["云存储", "本地SD卡"],
"夜视距离_米": 15
},
"name_translations": {
"en": "Health Monitoring Smart Watch",
"zh": "4K全景云台摄像头",
"es": "Taza termo inteligente"
}
}
#查询文档
#GET/索引库名/_doc/文档id
GET /ecommerce_products/_doc/1
#增量修改文档
#POST/索引库名/_update/文档id
POST /ecommerce_products/_update/8
{
"doc": {
"tags": ["夜视", "AI识别","促销"]
}
}相关性算分专线练习
一、function_score 的核心作用
function_score 允许您通过自定义规则修改文档的原始相关性评分 (_score),实现以下目标:
-
提升特定文档的排名(如促销商品、高库存商品)
-
降低无关文档的排名(如过期内容)
-
完全自定义排序逻辑(如结合价格、评分、时间等多因素)
二、基础语法结构
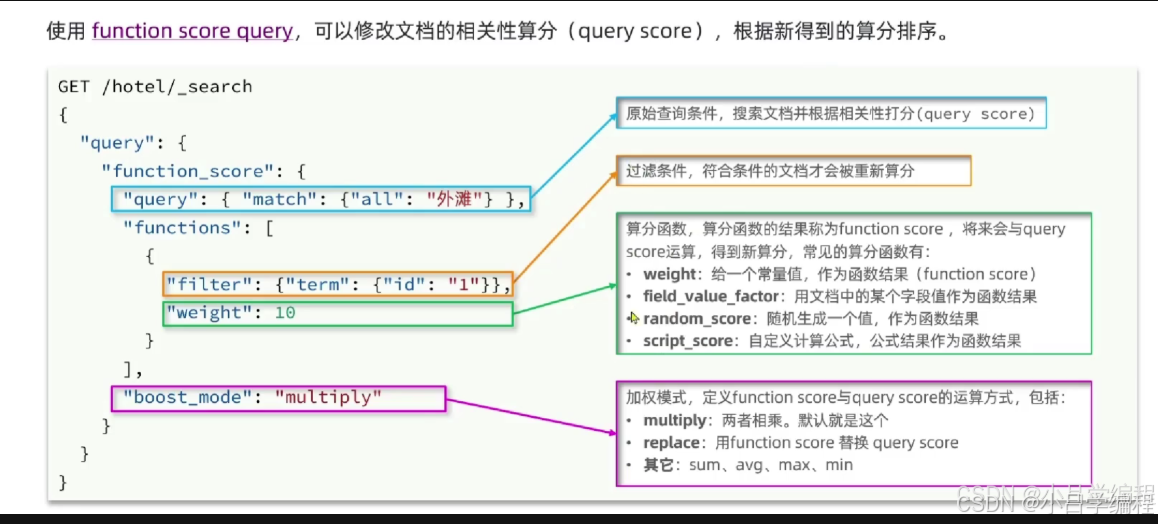
GET /索引名/_search
{
"query": {
"function_score": {
"query": { ... }, // 主查询(基础结果集)
"functions": [ ... ], // 评分函数列表
"score_mode": "sum", // 函数评分的组合方式
"boost_mode": "sum", // 最终评分与原始评分的组合方式
"max_boost": 10.0, // 函数评分的最大限制
"min_score": 2.0 // 结果过滤阈值(评分低于此值的文档被排除)
}
},
"sort": [ { "_score": "desc" } ]
}三、核心参数详解
1. query (主查询)
-
作用:定义基础查询,决定哪些文档会被处理。
-
示例:匹配所有文档或特定条件。
java
"query": { "match_all": {} }2. functions (评分函数)
支持多种函数类型,可同时使用多个函数:
| 函数类型 | 作用 | 示例 |
|---|---|---|
weight |
固定权重值 | { "weight": 2.0, "filter": { "term": { ... } } } |
field_value_factor |
基于字段值的评分计算 | { "field": "rating", "factor": 1.5 } |
random_score |
随机评分(需指定种子) | { "random_score": { "seed": 用户ID } } |
script_score |
自定义脚本计算评分 | { "script": "doc['price'].value * 0.1" } |
decay |
按距离/时间衰减评分(如高斯衰减) | 见下文详细示例 |
3. score_mode (函数评分组合方式)
| 模式 | 说明 |
|---|---|
sum |
所有函数评分相加(默认) |
avg |
取平均值 |
max |
取最大值 |
min |
取最小值 |
multiply |
所有函数评分相乘 |
4. boost_mode (最终评分计算方式)
| 模式 | 公式 |
|---|---|
sum |
最终分 = 原始分 + 函数评分 |
replace |
最终分 = 函数评分 |
multiply |
最终分 = 原始分 × 函数评分 |
avg |
最终分 = (原始分 + 函数评分)/2 |
四、实战练习
java
#需求:
#搜索所有商品,但为有库存(in_stock=true)的商品评分增加 50% 权重,同时为评分≥4 的商品额外增加 30% 权重。最终评分按加权值排序。
GET /ecommerce_products/_search
{
"query": {
"function_score": {
"query": {"match_all": {}},
"functions": [
{
"filter": {
"term": {
"in_stock": "true"
}
},
"weight": 1.5
},
{
"filter": {
"range": {
"rating": {
"gte": 4.2
}
}
},
"weight": 1.3
}
],
"score_mode": "sum",
"boost_mode": "replace"
}
},
"sort": [ { "_score": "desc" } ]
}random_score的运用练习····
Aggs聚合
大白话的理解就是:
你让他aggs一下type,他就把不同类型type以及数量返回给你
一、聚合的核心概念
聚合(Aggregations) 是 Elasticsearch 中用于对数据进行统计分析的功能,类似于 SQL 的 GROUP BY + 统计函数(如 COUNT、AVG)。
核心用途:
-
数据分组统计(如按分类统计商品数量)
-
计算指标(如平均价格、最高评分)
-
多维度交叉分析(如时间+地域的销售分布)
二、基础语法
java
{
"aggs": {
"agg_name": {
"agg_type": {
"field": "field_name",
"size": 10 (可选参数,具体取决于聚合类型)
}
}
}
}- agg_name: 自定义的聚合名称,用于标识聚合结果。
- agg_type : 聚合的类型,例如
terms、avg、sum等。 - field_name: 指定要进行聚合操作的字段。
三、常见聚合类型
Terms Aggregation (按值分组)
- 用于根据字段的唯一值对文档进行分组。
- 适用于分析离散值,如标签、类别等。
java
{
"aggs": {
"group_by_status": {
"terms": {
"field": "status.keyword"
}
}
}
}Range Aggregation (范围分组)
- 用于根据数值区间对文档进行分组。
java
{
"aggs": {
"price_ranges": {
"range": {
"field": "price",
"ranges": [
{ "to": 100 },
{ "from": 100, "to": 200 },
{ "from": 200 }
]
}
}
}
}Date Histogram Aggregation (日期直方图)
- 按时间间隔对文档进行分组。
java
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "sale_date",
"calendar_interval": "month"
}
}
}
}Avg, Sum, Min, Max Aggregations (统计计算)
- 用于计算字段的平均值、总和、最小值、最大值。
java
{
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}Nested Aggregation (嵌套聚合)
- 在嵌套字段上进行聚合。
java
{
"aggs": {
"nested_comments": {
"nested": {
"path": "comments"
},
"aggs": {
"comment_authors": {
"terms": {
"field": "comments.author"
}
}
}
}
}
}组合聚合
- 可以将多个聚合嵌套在一起,以得到更复杂的查询。例如,首先对一个字段进行分组,然后对每个分组进行统计计算。
java
{
"aggs": {
"group_by_status": {
"terms": {
"field": "status.keyword"
},
"aggs": {
"average_price": {
"avg": {
"field": "price"
}
}
}
}
}
}四、实战练习
java
#需求:
#统计每个商品的评论回复率(有回复的评论数 / 总评论数),按回复率降序排列
GET /ecommerce_products/_search
{
"size": 0,
"aggs": {
"products": {
"nested": { "path": "reviews" },
"aggs": {
"total_comments": { "value_count": { "field": "reviews.user_id" } },
"replied_comments": {
"nested": { "path": "reviews.responses" },
"aggs": { "response_count": { "value_count": { "field": "reviews.responses.admin_id" } } }
}
}
}
}
}五、字段详解
bucket_script
作用:对于已有的聚合结果进行二次计算,应用于计算比例、差值等
基础语法:
java
{
"aggs": {
"自定义聚合名称": {
"bucket_script": {
"buckets_path": {
"变量1": "聚合路径1",
"变量2": "聚合路径2"
},
"script": "params.变量1 + params.变量2"
}
}
}
}脚本
doc'field'的通用规则
适用字段类型
-
适用字段类型 :仅适用于非文本字段(如
integer、long、double、date、keyword等)。 -
不支持文本字段 :如果字段是
text类型且未设置fielddata=true,直接访问doc['text_field']会报错。 -
返回值类型 :返回一个
FieldValues对象,需通过特定方法获取值。
常用方法
(1) .value
-
作用 :获取字段的第一个值(单值字段直接取值,多值字段取第一个值)。
-
示例:
bash
// 单值字段:直接返回数值
double score = doc['score'].value;
// 多值字段:返回第一个值(如 [80, 90] 返回 80)
int firstScore = doc['scores'].value;(2) .values
-
作用 :获取字段的所有值(返回数组形式)。
-
示例:
java
// 多值字段:返回数组 [80, 90]
double[] scores = doc['scores'].values;
// 遍历多值字段
for (double s : doc['scores'].values) {
total += s;
}(3) .size()
-
作用 :获取字段值的数量 (单值字段返回
1,多值字段返回实际数量)。 -
示例:
java
if (doc['score'].size() > 0) { // 判断字段是否存在且非空
return doc['score'].value;
} else {
return 0;
}(4) .empty
-
作用:检查字段是否为空(无值)。
-
示例:
java
if (!doc['score'].empty) {
return doc['score'].value;
}(5) .get(int index)
-
作用 :获取数组字段的指定索引值。
-
示例:
bash
// 获取多值字段的第二个值
if (doc['scores'].size() >= 2) {
double secondScore = doc['scores'].get(1);
}(6) .count()
-
作用 :统计字段中非空值的数量(与
.size()不同,可能过滤空值)。 -
示例:
java
int validScores = doc['scores'].count();(7) 聚合方法
-
适用场景:对多值字段进行聚合计算。
-
常用方法:
java
.min() // 最小值
.max() // 最大值
.sum() // 总和
.average() // 平均值| 方法 | 用途 | 示例场景 |
|---|---|---|
.value |
获取单值字段值或多值字段的第一个值 | 单值数值计算 |
.values |
获取多值字段的所有值 | 遍历求和、求平均 |
.size() |
获取值的数量(包括空值) | 判断字段是否为空 |
.empty |
检查字段是否为空 | 空值保护逻辑 |
.get(index) |
获取多值字段的指定索引值 | 访问特定位置的元素 |
.min()/.max() |
多值字段的最小值/最大值 | 统计范围筛选 |
补充
size()、.count()和.empty方法
以下是针对 Elasticsearch Painless 脚本中
doc['field']的.size()、.count()和.empty方法在处理 空值、数组、字段不存在 时的具体行为示例。
示例数据
假设 Elasticsearch 中有如下文档:
java
{
"id": 1,
"name": "Alice",
"scores": [85, 90, null], // 多值字段,包含 null
"empty_array": [], // 空数组
"nullable_field": null // 单值字段,值为 null
}- 注意:字段
missing_field不存在。
Painless 脚本示例
java
// 检查 scores 字段
def scores_size = doc['scores'].size(); // 返回 3
def scores_count = doc['scores'].count(); // 返回 2(过滤 null)
def scores_empty = doc['scores'].empty; // 返回 false
// 检查 empty_array 字段
def empty_array_size = doc['empty_array'].size(); // 返回 0
def empty_array_count = doc['empty_array'].count();// 返回 0
def empty_array_empty = doc['empty_array'].empty; // 返回 true
// 检查 nullable_field 字段
def nullable_size = doc['nullable_field'].size(); // 返回 1(单值 null)
def nullable_count = doc['nullable_field'].count();// 返回 0(过滤 null)
def nullable_empty = doc['nullable_field'].empty; // 返回 false(字段存在)
// 检查 missing_field 字段
def missing_size = doc['missing_field'].size(); // 抛出异常(字段不存在)
def missing_empty = doc['missing_field'].empty; // 抛出异常(字段不存在)| 字段类型 | .size() |
.count() |
.empty |
|---|---|---|---|
多值带 null (如 scores: [85, 90, null]) |
返回 总数量(含 null) 示例:3 |
返回 非 null 值数量 示例:2 |
false(存在且非空数组) |
空数组 (如 empty_array: []) |
0 |
0 |
true(存在但无值) |
单值 null (如 nullable_field: null) |
1(单值字段视为数组 null) |
0(过滤 null) |
false(字段存在) |
字段不存在 (如 missing_field) |
报错 | 报错 | 报错 |
2.判空处理
java
// 正确做法:先检查字段是否存在
if (doc.containsKey('score') && !doc['score'].empty) {
return doc['score'].value;
} else {
return 0;
}Scroll滚动查询
POST /your_index/_search?scroll=5m
{
"size": 100,
"query": { "match_all": {} }
}