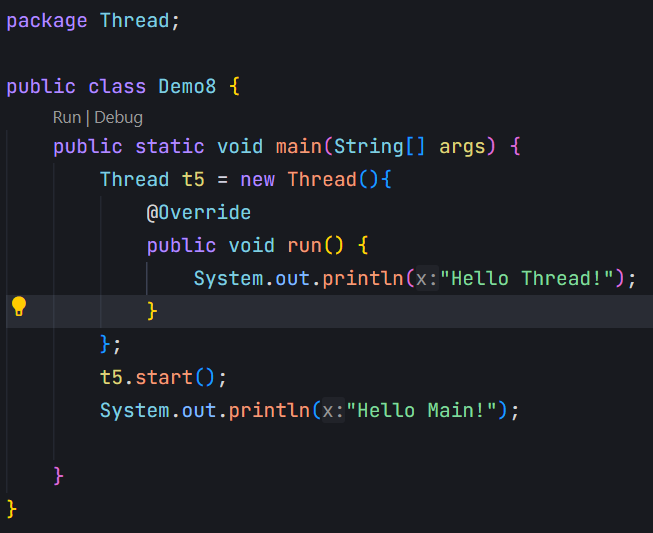
1.在图中代码,我们调用了start方法,真正让系统调用api创建了一个新线程,而在这个线程跑起来之后,就会自动执行到run。调用start方法动作本身速度非常快,一旦执行,代码就会立即往下走,不会产生任何的阻塞等待。因此我们看到的输出为:

然而,看到的是hello main在前的情况并不是唯一的,可能会有例外。因为当我们调用start之后,main线程和t5线程,他们两个执行,是一个"并发执行"的关系。而对于线程调度,操作系统具有随机性,所以结果顺序并不是唯一的。
如果执行完start恰好被调度出cpu(概率性时间),此时,cpu下次限制性main还是先执行t5就不确定了。

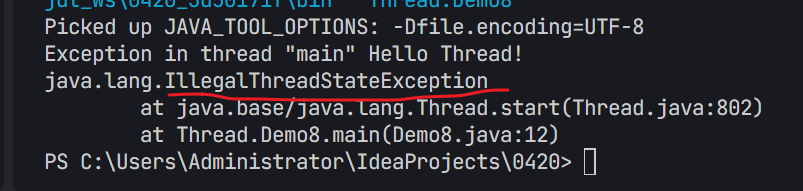
2.一个线程对象只能start一次。
如上图所示,我调用了两次t5.start();然后就出现了图中所示的错误,错误显示为"非法的线程状态"。原因是设计java的人约定了Thread对象只能start一次,一个Thread对象,只能对应到操作系统中的一个线程。如果需要多个线程,可以多创建几个Thread对象。
在创建线程的时候,start方法对线程状态做了判定,线程,在执行了start方法之后,就是就绪状态/阻塞状态了,对于就绪状态(阻塞状态下)的线程,我们不能够再次start。
3.中断一个线程。
中断:中断,也是操作系统中的一个专用术语。即"打断"、"终止"。意思是正常情况下,一个线程需要把入口方法执行完才能够使线程结束。(如果希望线程在没有执行完的情况下就结束,那么就需要通过"打断线程"的操作,也需要线程本身,代码做出配合)。这种情况一般发生在线程在sleep的过程中。
中断线程的几种方法:
(1)通过变量。
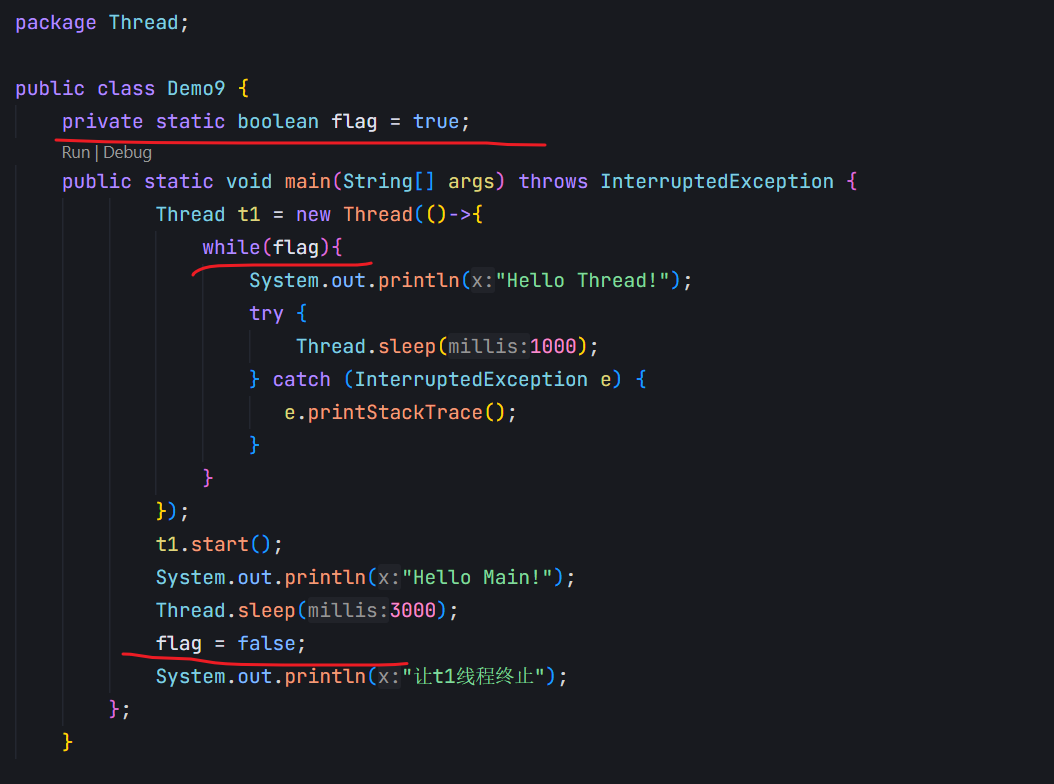
(2)直接就使用线程内置的标志位is interruptted()
Thread对象中,包含了一个boolean变量。如果该变量为false,说明没有人去尝试终止这个线程,如果为true,说明有人尝试终止。
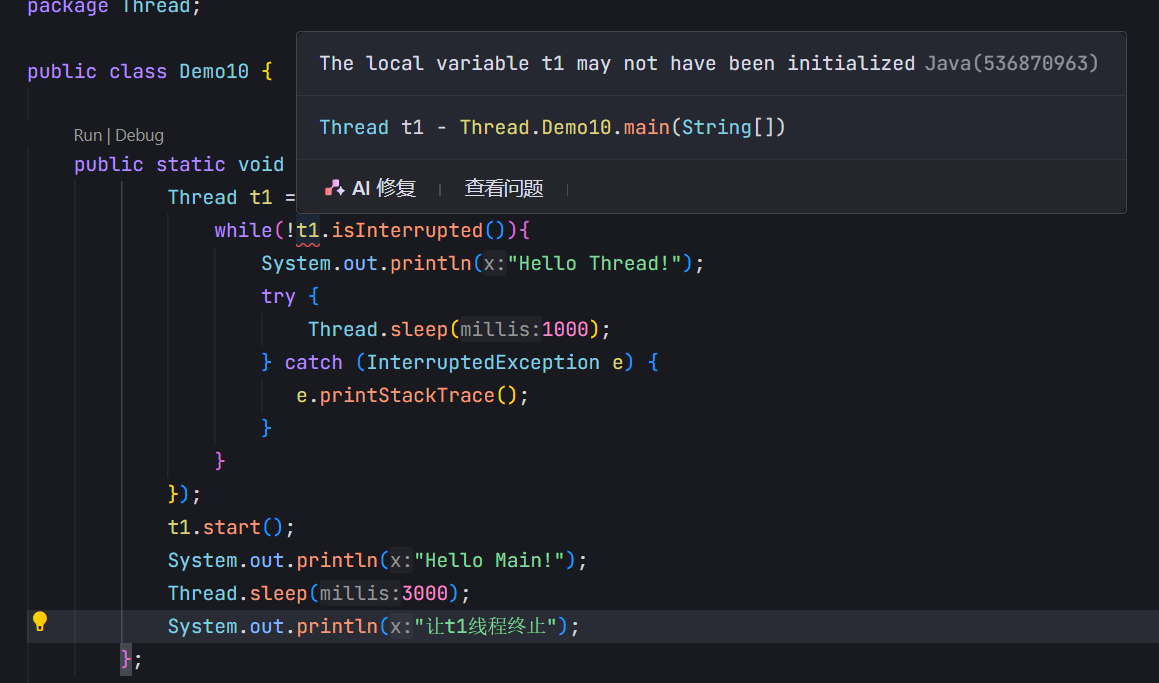
此处会报错的原因:此处针对lambda表达式的定义,其实是在new Thread之前的。因此t1还没有被初始化完成,是没办法进行方法的调用的。
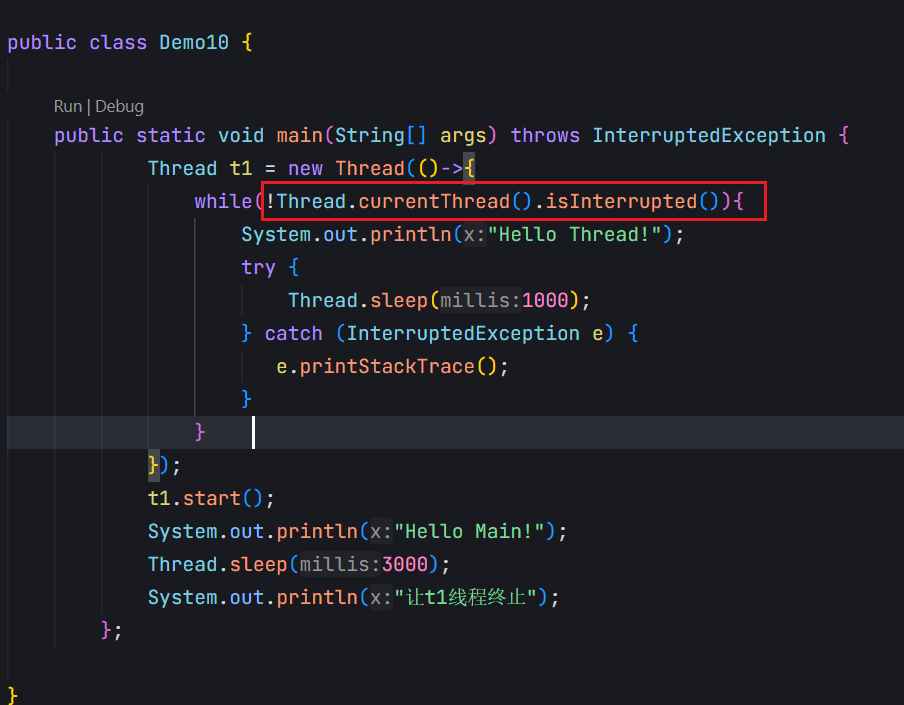
currentTread也是Thread类提供的一个静态方法,哪个线程调用这个方法,就返回哪个线程对象的引用。
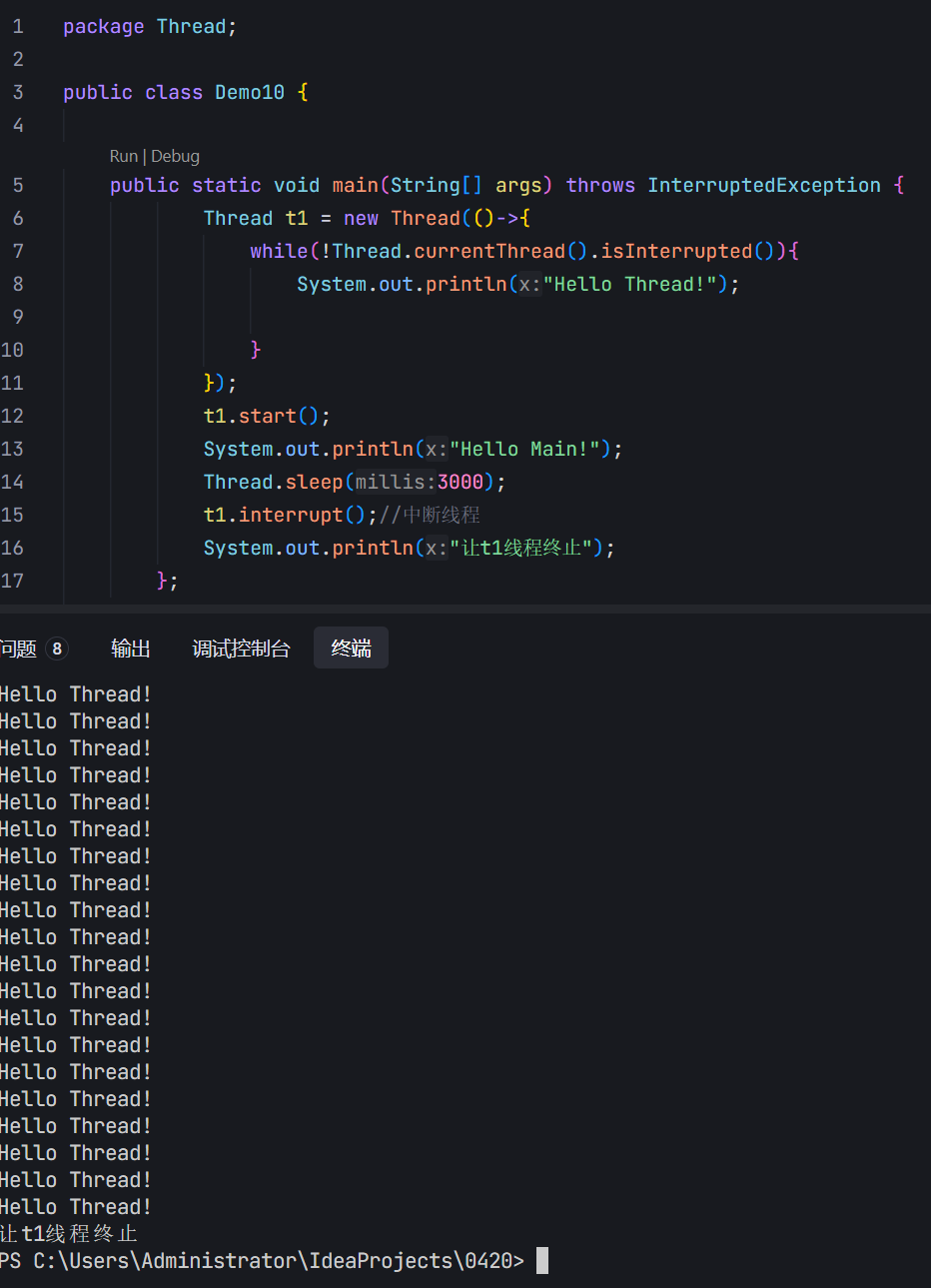
通过t.interrupt();我们可以来终止t线程。
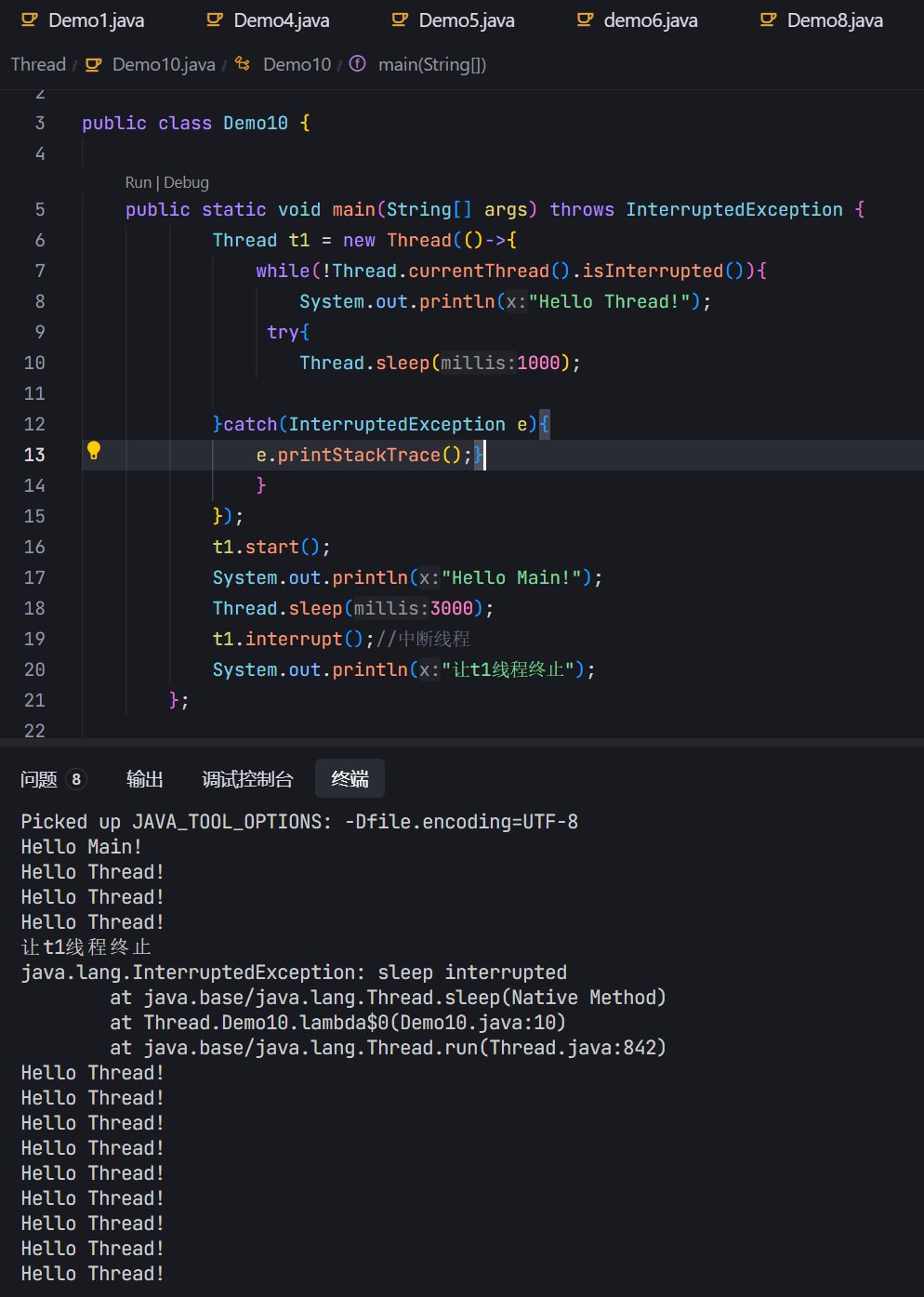
线程终止这里,有一个奇怪的设定。如果t线程正在sleep,此时main中调用Interrupt方法,就会把sleep提前唤醒。

这个异常支持sleep提前唤醒,通过异常,区分sleep是睡足了还是提前醒了。
sleep提前唤醒,触发异常之后,sleep就会把isinterrupted标志位重置为false。
于是输出继续打印Hello Thread。
上述奇怪的设定,主要是为了给程序员更多的操作空间。还没睡饱,就唤醒了,可能会存在一些"还没做完"的工作。于是java希望让程序员自行决定线程t是要继续执行,还是立即结束,还是稍等一会儿再结束。
如何结束这种现象?------>在抛出异常之后添加一个break;我们也就跳出循环了。
几种情况的对比:
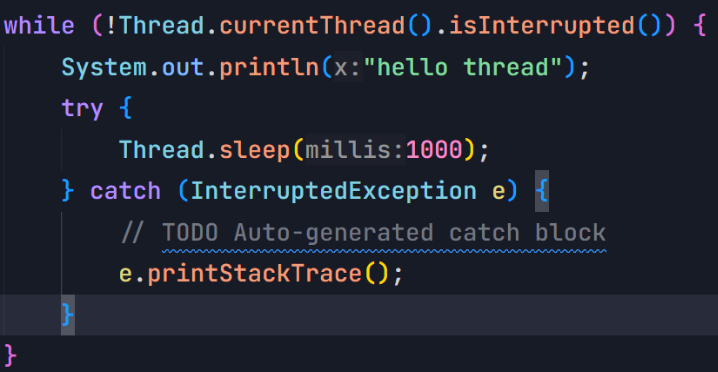
相当于完全忽视了请求
让线程立即结束。
在break之前去完成其他的事情,添加其他的善后逻辑,就相当于"稍后再结束"。
小结:
上述几种方式,本质上,都是t线程自己决定自己是否要终止,相当于main只是给t提供了一个"提醒"建议,而不是强制执行的。
如果采取强制终止的手段,很可能t线程的某个逻辑没有执行完,可能就会造成一些"脏数据"的输出,e.g.t执行过程中针对数据库的数据进行多次增删改查操作,结果由于上述强制中断,导致对数据库的数据修改操作只进行了一半,留下了脏数据。
使用Interrupt方法的时候,
1.t线程没有进行sleep等阻塞操作,t的isInterrupted()方法返回true,通过循环条件结束t线程。
2.t线程中进行了sleep等阻塞操作,t的isInterrupted()方法还是会返回true,但是sleep如果是被提前唤醒,抛出InterruptException,同时也会把isInterrupted()的返回结果设为false。此时就需要手动决定是否要结束线程了。
二、线程等待
一般情况下,系统是随机调度的(抢占式执行),如我们之前所说的hello main和hello thread哪一个先开始打印问题。当启动两个线程之后,这两个线程的执行顺序不确定。而对于程序员来说,程序员并不喜欢"随机"的东西。有些时候,程序员是希望顺序能够固定下来。
那么就引出了线程等待的概念------线程等待:约定了两个线程结束的先后顺序,让"后结束"的线程阻塞,等待"先结束"的线程执行完
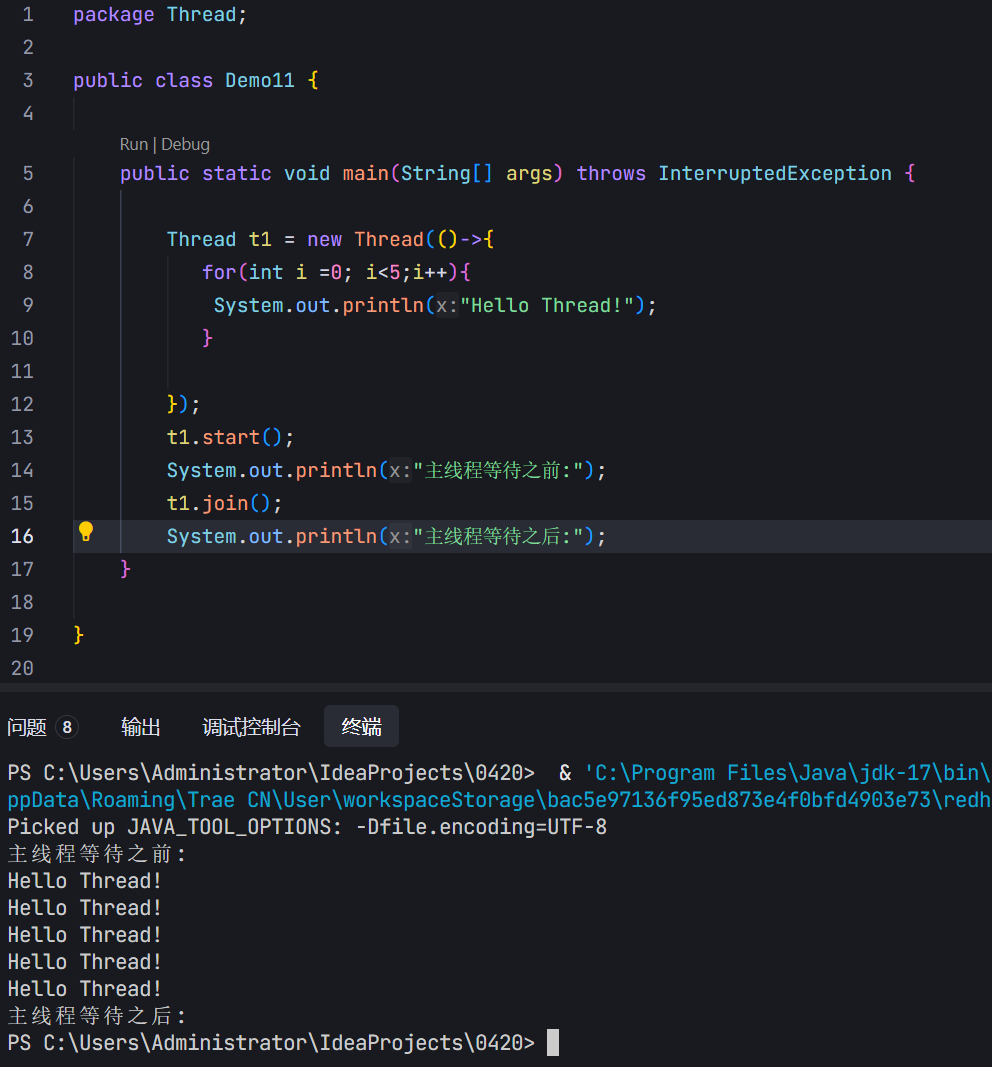
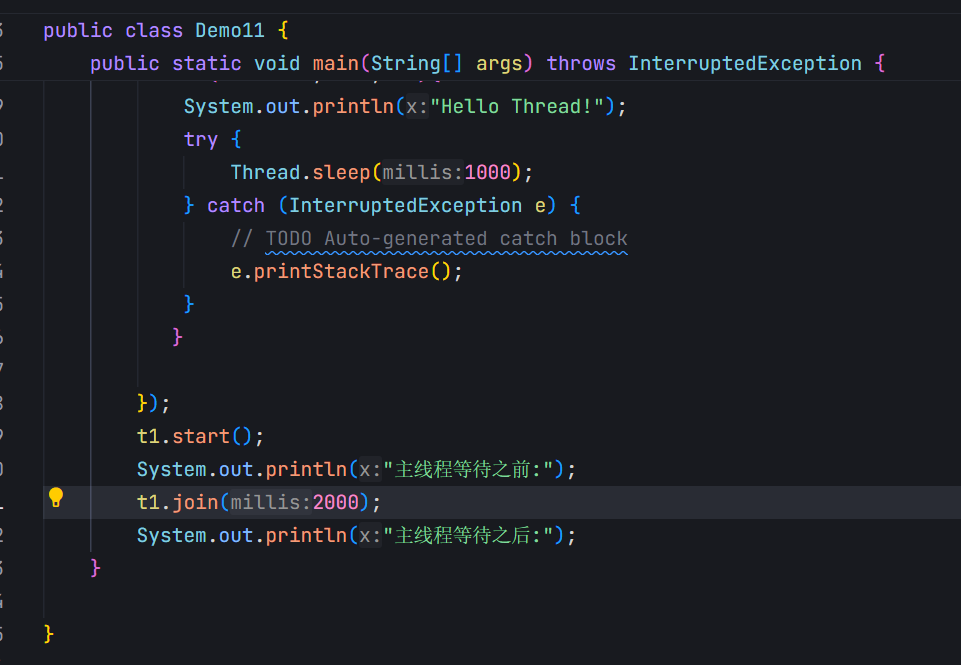
join()方法:t.join()。哪个线程中调用的join,这个线程就是"等的一方"(此处就是main线程)。join前面是哪个引用,对应的线程就是"被等的一方"(此处就是t)。main线程等待t线程结束。从字面上去理解,t要加入到"main"中,加入到main中,前提是main要存在,所以main的存在时间就要比t长。
*Java多线程当中,只要这个方法会产生"阻塞"(就可能被Interrupt提前唤醒),就都会抛出InterruptedException异常。
join等待是"死等""不见不散",只要被等待的线程t没有结束,join都会始终阻塞。
main可以等待t,t同样也可以等待main.
是否可以同时让main也等待t,让t也等待main?
代码完全可以这么写,但是这么些是没有意义的。这种情况下就会出现两个线程都无法结束,都无法完成对方的等待操作。
*使用join的前提是,我们需要明确知道当前这里的线程结束顺序。
join在一定情况下不会触发阻塞,例如:main等待t,如果main的join之前,t就已经结束了,此时join就不会阻塞。
join默认的情况是死等,但是join还有一个重载的版本,可以指定"等待的最大时间"(超时时间)。
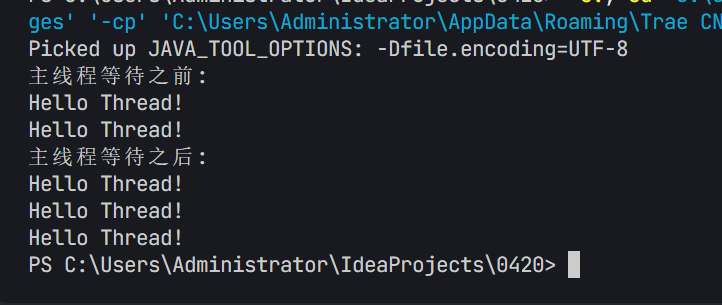


这次执行大概有12ms的误差
*网络编程中,超时时间非常重要,网络通信中数据传输时丢包是很常见的情况。
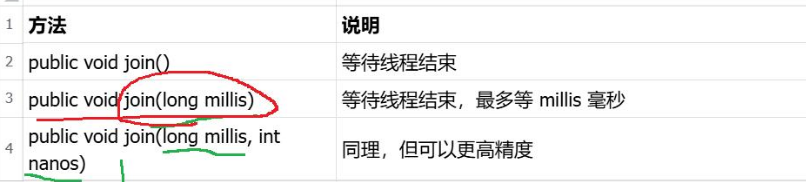
计算机在衡量时间的时候,是可能存在误差的,误差范围就是在ms级别。
*实际开发中,优先使用带有超时时间的版本。
哪个线程调用currentThread,就能获取到哪个线程对象的引用。
通过Thread.sleep()控制线程休眠。
Thread.sleep本质就是让线程的状态变成了"阻塞"状态,此过程就不参与cpu的调度了。直到时间到,这个线程的状态再次恢复成就绪状态,才能参与cpu调度(*此处只是恢复"就绪",而不是立即执行)
三、线程的状态
1.NEW状态
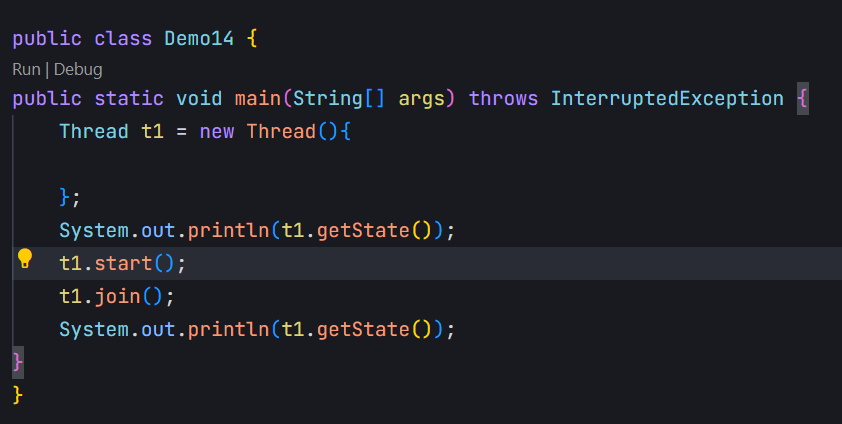
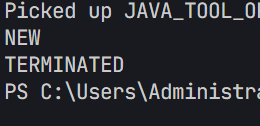
NEW:安排了工作,但还未开始行动。(Thread对象创建了,但是还没开始start。)

2.TERMINATED状态
TERMINATED:工作完成了。(线程执行完了(入口方法结束了),但是Thread对象还在)
3.RUNNABLE:可工作的,又可以分成正在工作中的和即将开始工作的。
就绪状态,随时可拿去cpu上执行。
代码中不触发阻塞类操作,都是RUNNABLE状态。
*操作系统中的线程,生命周期和Thread对象不完全一致。什么是生命周期:什么时候创建,什么时候销毁之间的一段周期。
阻塞状态:
1.BLOCKED:这几个都表示排队等着其他事情 (由于"加锁"产生的阻塞)
2.WAITING:这几个都表示排队等着其他事情(无超时时间的阻塞) join无参数版本
3.TIMED_WAITING:这几个都表示排队等着其他事情(有超时时间的阻塞)join有参数版本,或者是sleep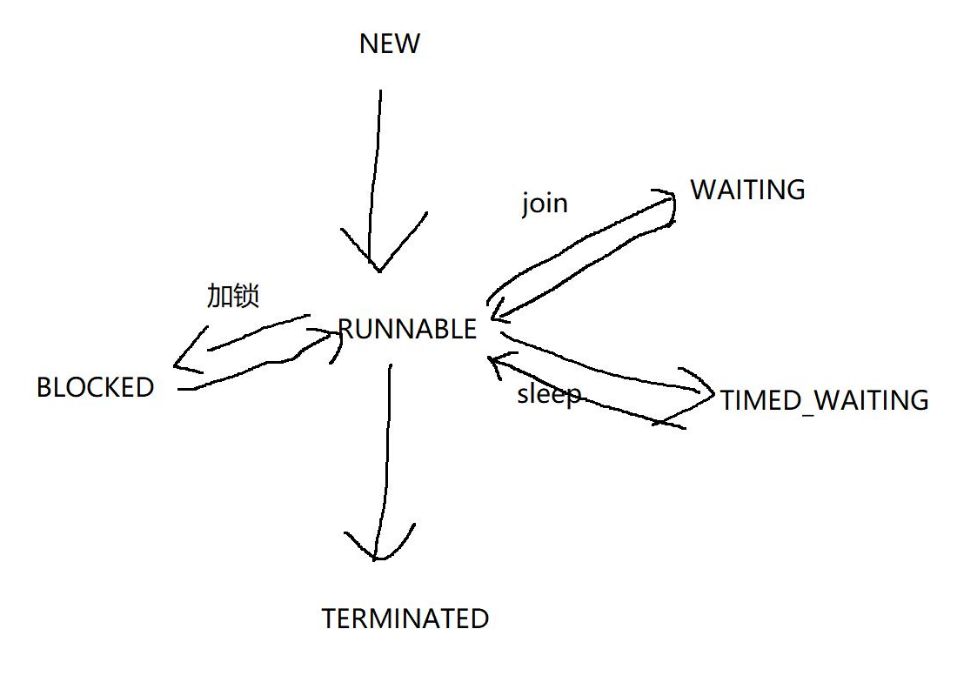
四、线程安全
某一段代码,在单线程环境下执行是正确的,但是放到多线程环境下去执行,就会产生bug。这就是线程安全问题:
e.g.
java
package Thread;
public class Demo15 {
public static int count = 0; // 共享变量,多个线程共同修改的变量,称为共享变量
public static void main(String[] args) {
Thread t1 = new Thread(() -> { // 线程t1
for (int i = 0; i < 5000; i++) { // 循环5000次
count++; // 自增操作,相当于count = count + 1
}
});
Thread t2 = new Thread(() -> { // 线程t2
for (int i = 0; i < 5000; i++) { // 循环5000次
count++; // 自增操作,相当于count = count + 1
}
});
t1.start(); // 启动线程t1
t2.start(); // 启动线程t2
try { // 等待线程t1和线程t2执行完毕
t1.join(); // 等待线程t1执行完毕
t2.join(); // 等待线程t2执行完毕
} catch (InterruptedException e) { // 捕获异常
e.printStackTrace(); // 打印异常信息
}
System.out.println(count); // 打印count的值,应该是10000,因为每个线程都自增了5000次
}
}
输出并不是10000(输出与预期不符合,这就是Bug)
t1和t2两个线程,在同时修改count这个变量,并且修改操作不是"原子的"*,这就会产生bug。
count++这样的操作,如果站在cpu指令的角度来说,其实是三个指令(指令就是机器语言,cpu执行的任务的具体细节,cpu会一条一条的读取指令,解析指令,执行指令)对于cpu来说,每个指令都是执行的最基本的单位。由于操作系统调度线程是"随机的",某个线程执行到任意一个指令的时候,都可能会触发cpu的调度。
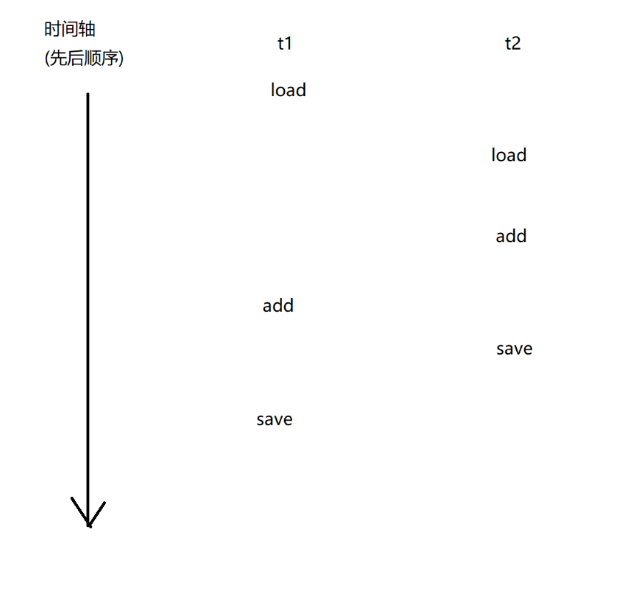
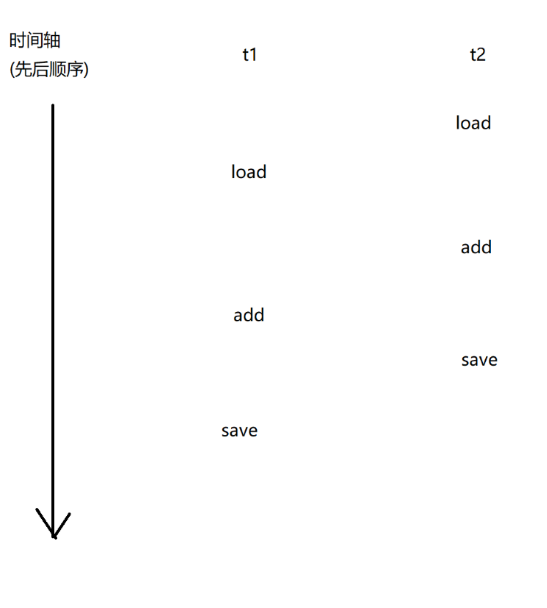
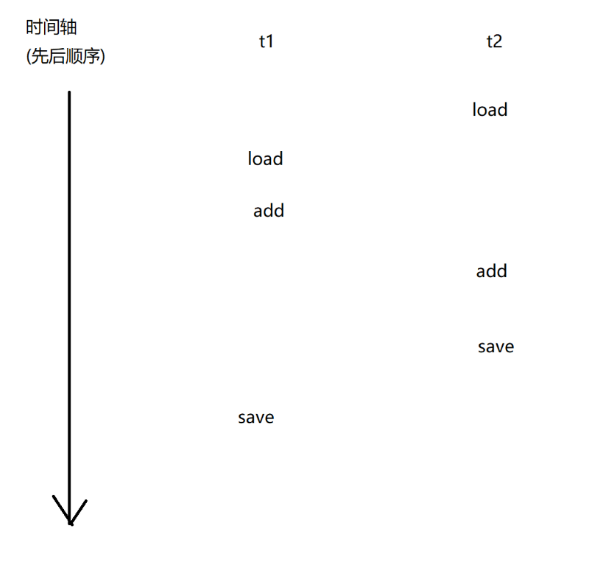
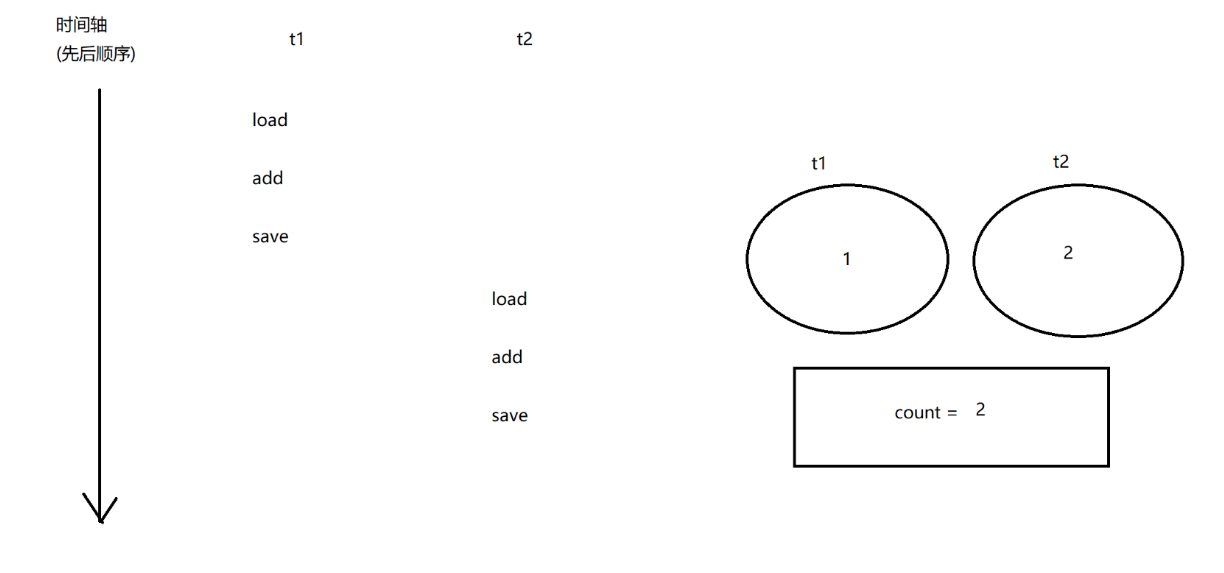
count++本质上对应三个指令:
1.load:把内存中的数值,加载到cpu寄存器中
2.add:把寄存器中的数据进行加1操作,结果还是放到寄存器里面
3.save:把寄存器中的值写回到内存中
上述过程在多线程中进行执行的时候,会出现以下几种情况:
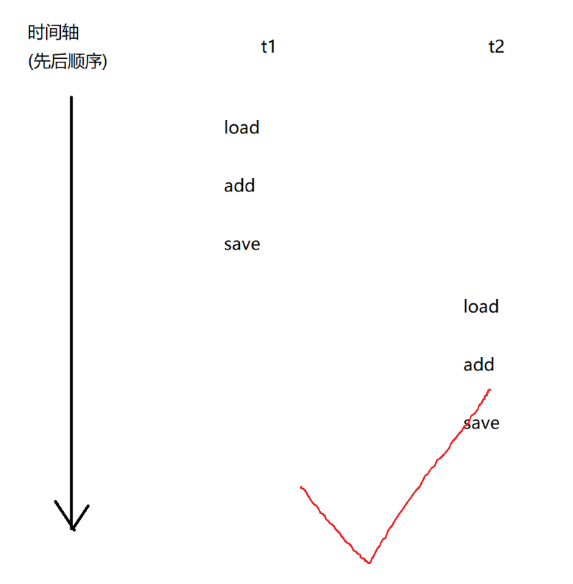
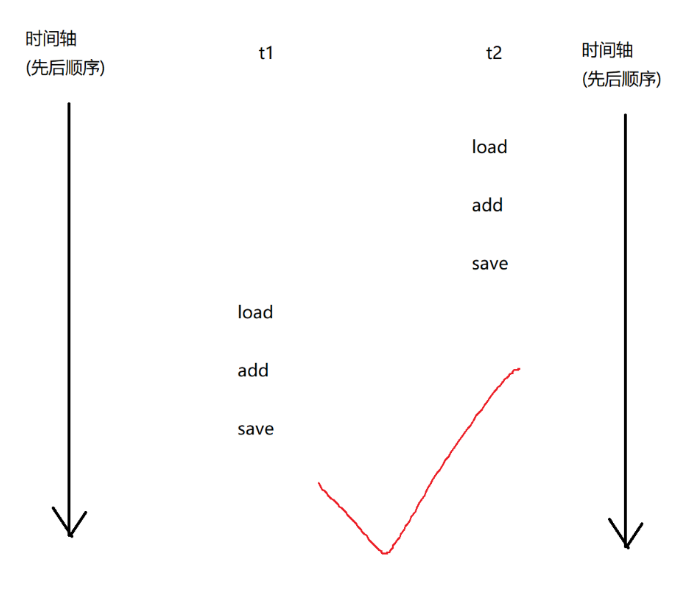
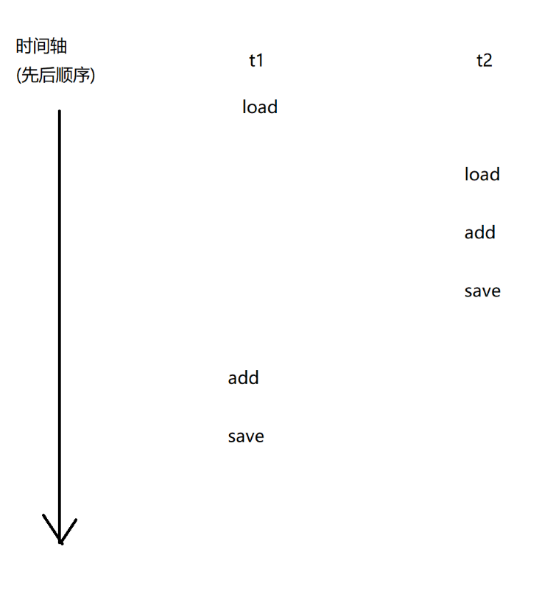
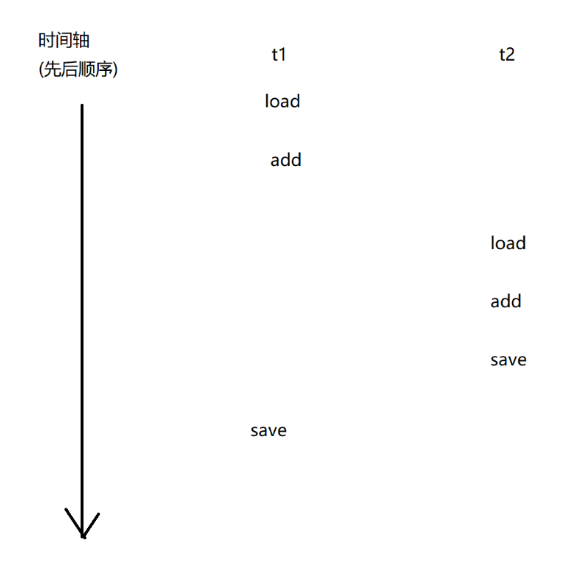
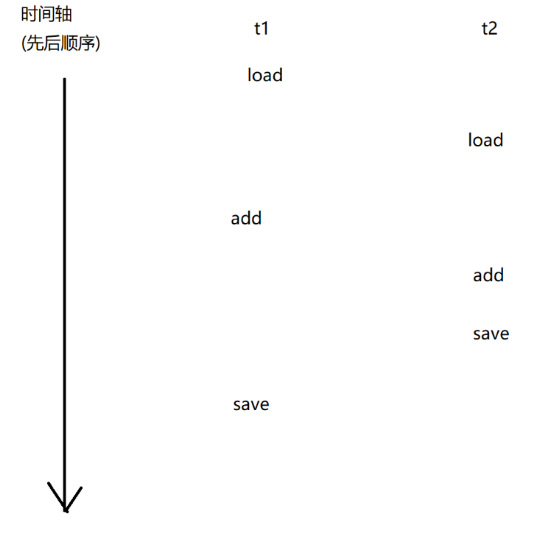
最后输出值为2的正确程序:
而其他的情况,最后结果并不正确!!
在整个循环5w次的过程中,也不知道有多少次是"正确"的情况,多少是"错误"的情况(线程调度顺序是随机的)。因此在宏观上,我们看到的最终结果肯定比10w次少,或者等于10w次。
出现错误的结果一定是<10w次,但是整个错误的结果,是否一定是>=5w次呢?------答案是可能的。