我自己的原文哦~ https://blog.51cto.com/whaosoft/13878933
#DETR->DETR3D->Sparse4D
走向长时序稀疏3D目标检测
一、DETR
图1 DETR架构
DETR是第一篇将Transformer应用到目标检测方向的算法。DETR是一个经典的Encoder-Decoder结构的算法,它的骨干网络是一个卷积网络,Encoder和Decoder则是两个基于Transformer的结构。DETR的输出层则是一个MLP。它使用了一个基于二部图匹配(bipartite matching)的损失函数,这个二部图是基于ground truth和预测的bounding box进行匹配的。最终性能与Faster-RCNN持平。
图2 DETR网络结构
Backbone:
当我们利用卷积神经网络时,会有两个假设:
平移不变性 :kernel 的参数在图像任何地方时一致的。局部性:要找某一个特征只需要在一个区域的周围检索,不需要全局观察。
而detr则是从0开始学起的,所以它的backbone采用经典的ResNet101网络对图像提取特征,为下面的Encoder获取先验知识。
流程如下:
(1)假设我的图像输入为:3 * 800 * 1066 (CHW)。
(2)通过CNN提取特征后,得到了 2058 * 25 * 34的feature map。
(3)为了减少计算量,下采样feature得到 256 * 25 * 34。
Encoder:
在这里需要把 数据转化为序列化数据,直接把hw合并,维度转化为 256 * 850.
在这里作者采用二维sin、cos的位置编码(通过实验各位置编码方法结果相差不大),具体公式本文不在展示。
Detr与Transformer相比,后者是直接在Encoder之前做 position encoder,然后在生成 qkv,然而Detr则是只对 key 与 query 编码。我认为key query 是负责取检索特征计算注意力分数,而value只负责提供对应位置的值,从而不需要位置编码。
把位置编码与feature结合的方式主要是add操作,所以我们要把位置编码的维度与feature的维度一致。其中我们的编码方式是根据feature的x、y两个方向的编码。
操作如下:
由于相应的feature map 的 H * W 为 25 * 34
(1)在H方向上为每个对应点赋予 128 * 25 * 34
(2)在W方向上为每个对应点赋予128 * 25 * 34
(3)add 成 256 * 25 * 34
(4)与feature map add
(5)把数据转化为序列化数据
(6)用 没有position的feature生成 V,有的生成KQ,执行attention
(7)通过Encoder后,feature map 与input一致,还是 256 * 850
Decoder:
图3 DETR的Decoder结构
decoder的输入主要有两个:
(1)Encoder的输出
(2)object queries
首先我们说一下object queries,在代码中,它的本质实际就是一个 learnable Embedding position。这里假设 初始化100(远远大于 num_classes)个object queries,每个的维度为256(方便与encoder输出矩阵乘法),所以它的维度为 256 * 100.
这里说个番外~,为什么object queries是一个 learnable position Embedding 呢?,我们知道,初始化要先通过一个Embedding层后才能输入后面的注意力层,而这个embedding层我们可以把它理解为全连接层,权重矩阵为w,这里的w是就是代码中用来学习object query的"learnable position embedding",代码如下:
self.query_embed = nn.Embedding(num_queries, hidden_dim)
模型通过学习会把它图像分成100个区域,每个queries负责关注特定的区域。到这里你会发现:Object queries充当的其实是位置编码的作用。
图四 DETR基本概括
这里要着重说明一下,DETR的核心是Decoder,Decoder的核心是这100个输入的可学习向量,Decoer训练的过程可以理解成就是训练这100个query向量的过程。
非常有意思的一点在于,在作者的源码中,这100个可学习query向量都被初始化为0,然后加上位置编码作为输入,在此基础上对这100个向量进行学习。
另一个值得注意的点是,论文中提到的Decoder部分是M层的,但事实上,这M层的decoder只有一部分被重复了M次(图5红框部分);
图5 DETR decoder结构解析
出框最后的一步也是最常规的一步,通过添加FFN检测头来进行预测,这里是做两个预测,一个是物体出框预测(四个值,中心点坐标x, y, 以及框的width, height) ,一个是物体类别预测。
在得到预测后,这100个预测框会和Ground Truth框一起通过匈牙利算法进行匹配(Bipartite 匹配)。
给定一个二分图G,在G的一个子图M中,M的边集{E}中的任意两条边都不依附于同一个顶点,则称M是一个匹配。求二分图最大匹配可以用匈牙利算法。
可参考:二分图最大匹配问题与匈牙利算法的核心思想 | 始终 (liam.page)
与VIT的区别:
总体上我认为,DETR和ViT非常类似,都是针对于图像的任务,一个是图像分类 ,一个是目标检测 ,二者区别主要在于将图像序列化的方式不同(当然,毕竟这二者是不同任务,后处理部分也肯定是不一样的,但是可以看到的是,后处理部分使用的都是很常规的分类或检测手段,因此这里不纳入本文的考虑)。
基本思想:
(1)将图片切分为一个个的16×16的patch;
(2)这个部分是用来获取每一个patch的Embedding,这里包含两个小步骤:
i. 将16×16的patch展平;
ii. 将得到的256长度的向量,映射为Transformer所需要的长度;
NB:很明显,这里可以通过线性层进行映射,也可以通过设置卷积核的方式直接得出Embedding
(3) 位置编码与第二部中获得的Embedding相加;
(4) 也就是直接向TRM encoder的输入与输出,将得到的多个维数为768的向量的第一个作为分类输入,使用常规的多分类方法进行分类。
二、DETR3D
这是一篇多视角(多目 )3D目标检测的工作,非LiDAR,也非单目,而且纯粹地基于nuScenes数据集。本质上,这就是一篇将DETR拓展到3D检测中的工作,所以重点在于,如何将DETR中bipartite loss的思想应用在3D任务上。
DETR的大致过程是提取图像特征→编码辅助输入→结合queries获得values→得到queries的检测结果,并做损失。DETR3D在此基础上,除了将bipartite loss拓展到了三维空间中,还另外引入了Deformable DETR的iterative bounding box refinement模块,即构建多层layer对query进行解码
图6 DETR和DETR3D对比
set-to-set loss:
先来看最简单的部分,作者是如何把bipartite loss拓展到3D空间的。在文中,这个loss被称作是set-to-set loss,对于loss的研究,其实我们只要搞清楚预测与GT就可以了。
这里的pred是prediction set,GT则称作GT set 。
了使中间层也获得较好的学习效果,作者这里使用了一个常用的coarse2fine的手段,即在training阶段每层的loss都会被计算,但是在inference时只取最后一层作为输出。
图7 set-to-set loss计算过程
总而言之,这里的argmin鼓励我们找到一种预测的排列,使得anchor的顺序尽可能与GT匹配,当GT类别非空时寻找预测类标置信度最大者,当GT类别为空时寻找bbox最接近的。
这里又有问题了:
GT类别非空时,单纯看寻找预测概率最大似乎是不合理的吧。比如预测有两个同类bbox,如何确定谁排在前面、后面?这样就会出现bbox错位匹配的情况吧。我们看DETR里是怎么写的: ,DETR这里的matching loss,两个示性函数都是非空的啊喂,必须要在非空的时候加以bbox的约束才能避免出现错位的情况(即又要匹配的类别对,又要匹配的类别好),并且空集的时候在这里其实是不关注的。
也正是因为他把后面那个项的示性函数改成等于了,这就引申出一个问题,在padding空集的时候,你这里也需要padding bounding box了,而这怎么padding呢?在DETR当中是不必为补充的空集也补充一个bounding box,因为你无论怎么补充,你都无法指望预测的空bounding box匹配上你的补充,所以这一点也是比较令人迷惑的。
如果以上你听得一知半解,我们再来看找到排列之后的损失计算,就更能理解这种诡谲了:这里也基本是和DETR类似的,不考虑符号上使用上的区别,就只有示性函数中把不等号变成了等号这样严肃的区别,于是这就造成了:当类别非空时,你不做bounding box上的loss,而现在类别空了你反而来做bounding box的loss。所以我强烈怀疑应该是论文中两处都打错了,否则结果应该不会还能排到SOTA。不知道是不是因为arxiv版本挂错了,还是真的审稿人粗心不看公式。
argue: 如果以上推断成立,那么就算我们脑补修改一下这个loss,其实也有值得商榷的地方:我本来期待着他的loss至少是什么IoU loss之类的,结果就是简简单单的L1。在KITTI-object那边的工作中,其实涌现了很多类似mIoU loss等创新性的工作。这样不考虑parameters在3D空间中的实际的bounding box意义,而直接做L1 loss,这样的学习效果是否会好、是否合理?
2d-to-3d feature转换
图8 2d转3d特征过程
重点便在于如何解读这里的几条虚线了。起初,我是按照图例中给出的红色在最上、黄色在最下的顺序来解读的,以为是要先对特征进行操作,然后对query再加工提取,在feature space中去做loss......我还纳闷呢,明明人家说是在3D空间中做loss,这咋回事呢,而且transformer的黑色框框里,向右的黑色箭头也对不上啊......
纠结了好久才明白正确的理解方式是从蓝色开始看到红色,实际上所有虚线加起来的操作就是向右黑线......由于文中图例文字太小,这里按照虚线的顺序依次解读下以上的操作:
- 首先明确,object queries是类似DETR那样,即先随机生成 个bounding box,类似先生成一堆anchor box,只不过这里的box是会被最后的loss梯度回传的。
- (蓝线)然后通过一个子网络,来对query预测一个三维空间中的参考点 (实际上就是3D bbox的中心)。通过角标我们可以看出,这个操作是layer-wise、query-wise的。这两个wise的概念参见下文的讨论。
- (绿线)利用相机参数,将这个3D参考点反投影回图像中,找到其在原始图像中对应的位置。
- (黄线)从图像中的位置出发,找到其在每个layer中对应的特征映射中的部分。
- (红线)利用多头注意力机制,将找出的特征映射部分对queries进行refine。这种refine过程是逐层进行的,理论上,更靠后的layer应该会吸纳更多的特征信息。
- (黑色虚线框之后)得到新的queries之后,再通过两个子网络分别预测bounding box和类别,然后就进入我们之前讨论的loss部分了。
这里一定要注意,从蓝线开始,就像deformable DETR一样,queries是划分为了多个layer输入的(去查了一下代码,这里应该是6个layer),这个layer和FPN得到的feature layer是不同的(所以为免歧义,我在前后文都称之为feature level了),feature的level是四层,所以总结一下是:每一个level的feature都应该对应输入每个layer的queries,所以实际上应该会有4*6=24个输入(当然实际运算要更复杂一些)。
总结
最后来总结,回答一下一开始提出的几个疑惑。
- 关于bipartite loss和使用特征的方式,在此就不再赘述了,诸多细节与疑惑均已在讨论中提出。
- multi-view体现在query对同一时刻的六张图像同时进行了学习,单就这一点而言其思路就是比较超前的。传统的Monocular方法都是单张图像输入输出、multiview方法大家考虑的也是时间序列上的长序列,而并没有拓展到多视角上。
- 关于注意力机制的问题,我们可以回忆一下,DETR令人震撼的地方其实是在于decoder attention可以关注到bounding box中的特征:
DETR decoder attention
而在这里,文中其实是没有给出什么可视化的效果,或者类似"all box predictions"这种grid可视化图。强行分析的话,我认为亮点反而可能在于,这种多目图像之间特征的求和(简单的1x1conv)并对query的refine,其实是替代了传统的多目匹配工作,使得这种3D-to-2D Queries可以有效跨越多目图像,更应该是本文的落脚点和关注之处。
总的来讲,还有很多疑惑,也还有很多可发展的地方。
三、Sparse4d
在自动驾驶视觉感知系统中,为了获得环绕车辆范围的感知结果,通常需要融合多摄像头的感知结果。比较早期的感知架构中,通常采用后融合的范式,即先获得每个摄像头的感知结果,再进行结果层面的融合。后融合范式主要的问题在于难以处理跨摄像头的目标(如大卡车),同时后处理的负担也比较大。而目前更加主流的感知架构则是选择在特征层面进行多摄像头融合。其中比较有代表性的路线就是这两年很火的BEV方法,继Tesla Open AI Day公布其BEV感知算法之后,相关研究层出不穷,感知效果取得了显著提升,BEV也几乎成为了多传感器特征融合的代名词。但是,随着大家对BEV研究和部署的深入,BEV范式也逐渐暴露出来了一些缺陷:
i.感知范围、感知精度、计算效率难平衡:从图像空间到BEV空间的转换,是稠密特征到稠密特征的重新排列组合,计算量比较大,与图像尺寸以及BEV特征图尺寸成正相关。在大家常用的nuScenes 数据中,感知范围通常是长宽 -50m, +50m 的方形区域,然而在实际场景中,我们通常需要达到单向100m,甚至200m的感知距离。若要保持BEV Grid 的分辨率不变,则需要大大增加BEV 特征图的尺寸,从而使得端上计算负担和带宽负担都过重;若保持BEV特征图的尺寸不变,则需要使用更粗的BEV Grid,感知精度就会下降。因此,在车端有限的算力条件下,BEV 方案通常难以实现远距离感知和高分辨率特征的平衡;
ii.无法直接完成图像域的2D感知任务:BEV 空间可以看作是压缩了高度信息的3D空间,这使得BEV范式的方法难以直接完成2D相关的任务,如标志牌和红绿灯检测等,感知系统中仍然要保留图像域的感知模型;
实际上,我们感兴趣的目标(如动态目标和车道线)在空间中的分布通常很稀疏,BEV范式中有大量的计算都被浪费了。因此,基于BEV的稠密融合算法或许并不是最优的多摄融合感知框架 。同时特征级的多摄融合也并不等价于BEV。这两年,PETR系列(PETR, PETR-v2,StreamPETR) 也取得了卓越的性能,并且其输出空间是稀疏的。在PETR系列方法中,对于每个instance feature,采用global cross attention来实现多视角的特征融合。由于融合模块计算复杂度仍与特征图尺寸相关,因此其仍然属于稠密算法的范畴,对高分辨率的图像特征输入不够友好。
因此,我们希望实现一个高性能高效率的长时序纯稀疏融合感知算法 ,一方面能加速2D->3D 的转换效率,另外一方面在图像空间直接捕获目标跨摄像头的关联关系更加容易,因为在2D->BEV的环节不可避免存在大量信息丢失。这条技术路线代表性的方法是基于deformable attention 的DETR3D算法。然而从开源数据集指标来看,DETR3D的性能距离其他稠密类型的算法存在较大差距。为了Make 纯稀疏感知 Great Again,我们近期提出了Sparse4D及其进化版本Sparse4D v2,从Query构建方式、特征采样方式、特征融合方式、时序融合方式等多个方面提升了模型的效果。当前,Sparse4D V2 在nuScenes detection 3d排行榜来看,达到了SOTA的效果,超越了包括SOLOFusion、BEVFormer v2和StreamPETR在内的一众最新方法,并且在推理效率上也具备显著优势。本文主要介绍了Sparse4D 和 Sparse4D V2 方案的细节实践。
源码:https://link.zhihu.com/?target=https%3A//github.com/linxuewu/Sparse4D
https://link.zhihu.com/?target=https%3A//github.com/HorizonRobotics/Sparse4D
图9 DETR3D回顾
由于上述的这些原因,DETR3D 网络整体的学习能力偏弱,指标在当前显著弱于BEV 范式的方法。在Sparse4D-V1 中,我们主要通过instance 构建方式,特征采样、特征融合和时序融合等方面改进了现有的框架。
图11 sparse4d 框架
如图1所示,Sparse4D 也采用了Encoder-Decoder 结构。其中Encoder 包括image backbone和neck,用于对多视角图像进行特征提取,得到多视角多尺度特征图。同时,我们会cache 多历史帧的图像特征,用于在decoder 中提取时序特征;Decoder 为多层级联形式,输入时序多尺度图像特征图和初始化instance,输出精细化后的instance,每层decoder包含self-attention 、deformable aggregation 和refine module三个主要部分。
学习2D检测领域DETR改进的经验,我们也重新引入了Anchor的使用,并将待感知的目标定义为instance,每个instance主要由两个部分构成:
基于以上定义,我们可以初始化一系列instance,经过每一层decoder都会对instance 进行调整,包括instance feature的更新,和anchor的refine。基于每个instance 最终预测的bounding box,Sparse4D 中同样通过Bipartite 匹配的方式与真值进行匹配并计算损失函数。
图12 deformerable aggregation模块结构图
在Sparse4D 的decoder 中,最重要的是Deformable 4D Aggreagation 模块。这个模块主要负责instance 与时序图像特征之间的交互,如图3所示,主要包括三个步骤:
4D 关键点生成: 首先,基于每个instance 的3D anchor信息, 我们可以生成一系列3D关键点,分为固定关键点和可学习关键点。我们将固定关键点设置为anchor box的各面中心点及其立体中心点,可学习关键点坐标通过instance feature接一层全连接网络得到。在Sparse4D 中,我们采用了7个固定关键点 + 6个可学习关键点的配置。然后,我们结合instance 自身的速度信息以及自车的速度信息,对这些3D关键点进行运动补偿,获得其在历史时刻中的位置。结合当前帧和历史帧的3D关键点,我们获得了每个instance 的4D 关键点。
**4D 特征采样:**在获得每个instance 在当前帧和历史帧的3D关键点后,我们根据相机的内外参将其投影到对应的多视角多尺度特征图上进行双线性插值采样。从而得到Multi-Keypoint,Multi-Timestamp, Multi-Scale, Multi-View 的特征表示;
**层级化特征融合:**在采样得到多层级的特征表示后,需要进行层级化的特征融合,我们分为了三层:
- Fuse Multi-Scale/View:对于一个关键点在不同特征尺度和视角上的投影,我们采用了加权求和的方式,权重系数通过将instance feature和anchor embed输入至全连接网络中得到;
- Fuse Multi-Timestamp:对于时序特征,我们采用了简单的recurrent策略(concat + linear)来融合;
- Fuse Multi-Keypoint:最后,我们采用求和的方式融合同一个instance 不同keypoint 的特征
运动补偿: Sparse4D针对自车运动和instance运动都进行了补偿。目前,大多数算法仅显式考虑了自车运动。我们通过实验分析了运动补偿的作用,如下表所示。对于NDS指标来说,自车运动和他车运动分别带来了6.4%和0.7%的提升,他车运动补偿对检测精度无提升,但是对速度估计精度的提升非常显著(mAVE指标)
**多层次特征融合:**在deformable aggregation中,我们需要对多尺度、多视角和多关键点的特征进行融合。为了分析各个层级融合的重要程度,我们分别将各层的加权方式改为直接求和,可以看到多尺度的影响小于多视角,而多关键点的融合最为重要。此外,将三个层级的融合全部改为求和的形式,模型将难以收敛,指标也会显著降低
**采样时序融合帧数:**Spase4D v1中,采用多帧采样的方式实现时序融合,其中采样帧数对感知性能的影响显著。我们将帧数从0逐步增加至10,感知性能一直在稳步提升,说明长时序融合对检测性能有很大帮助。但是由于显存限制,我们仅验证到了10帧。
#端到端自动驾驶通用感知架构的前世今生
研究背景及现状
CVPR2023 best paper(商汤上海AI lab):UniAD
来源:星球内部资料,文末扫码领取!
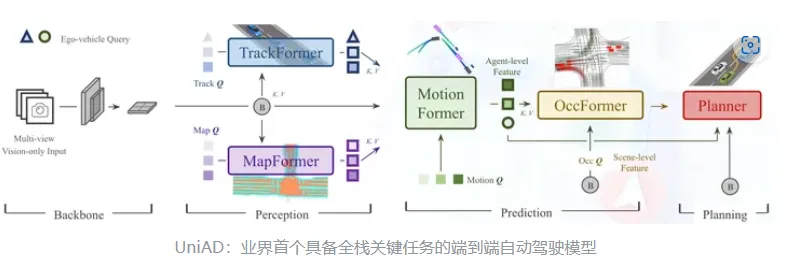
首先从端到端自动驾驶说起。端到端自动驾驶是目前自动驾驶领域最受关注的方向之一。UniAD提出一个端到端的感知决策一体框架,融合了多任务联合学习的新范式,使得进行更有效的信息交换,协调感知预测决策,以进一步提升路径规划能力。 首次将感知、预测、规划等三大类主任务、六小类子任务(目标检测、目标跟踪、场景建图、轨迹预测、栅格预测和路径规划)整合到统一的端到端网络框架下,实现了全栈 关键任务驾驶通用模型。在 nuScenes 真实场景 数据集下,所有任务均达到领域最佳性能(State-of-the-art),尤其是预测和规划效果远超之前最好方案。
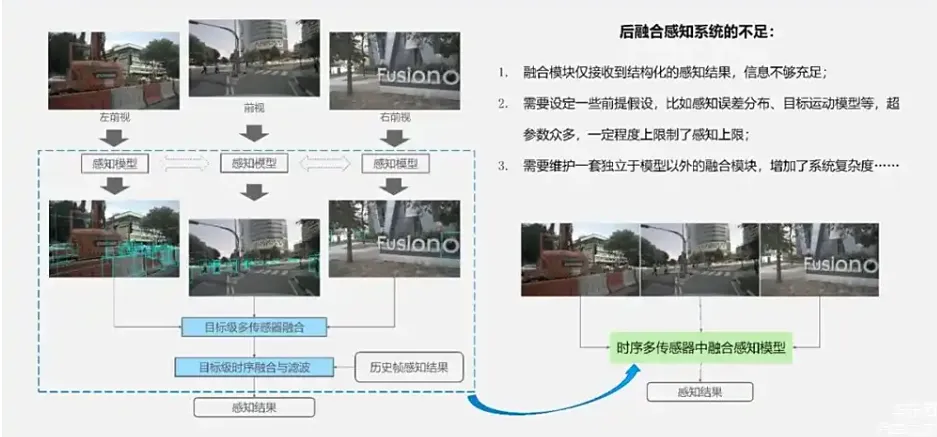
传统的自动驾驶系统通常会采用级联式的架构,在模块与模块之间通常传递的是结构化信息,同时在系统内存在着海量人工设计的复杂规则。这使得整体的自动驾驶系统复杂性高、难以联合优化以及迭代周期比较长。而端到端的设计思路则带来了全新的可能性。在端到端架构中,首先各个主要的模块都是基于神经网络的形式设计;其次模块间也不再只是传递结构化信息,而是同时传递稀疏实例特征表示,这使得从感知到规控的整体系统可以进行联合优化;最终的planning模块也能从更加靠前的阶段获得更丰富的信息。但这里会带来一个问题,就是在端到端自动驾驶系统中,我们是否需要显式的去做感知的模块? 目前也存在着一些方法是不产生中间结果,可以直接通过图像输入,直接输出控制信号的彻底端到端技术路线。这种技术路线会存在彻底黑盒、解释性差的问题。 而从自动驾驶产品安全性的角度来看,把每个模块都网络化并串联在一起的技术路线,会更加可靠可行 ,也就是UniAD技术路线 。因此,还是非常有必要去做显式的感知结果的输出 。在这样的架构设计下,主要讨论的问题是:对于一个面向落地的端到端纯视觉驾驶系统,我们需要怎么样的通用的感知后端呢? 我个人认为主要包括这四个方面:1、需要具备强大的感知性能,能够输出高质量的实例化特征;2、需要高效的融合多视角+时序的视觉信息 ,速度快,且对于板端芯片比较友好;3、感知的范围方面能够具备All in One的能力,不需要多个模型去补充不同范围的视野 ;4、需要有可靠多任务能力,能够适配并良好的支持动态、静态,像HDMap的高精地图重建等各种任务。在更早期的阶段,自动驾驶系统中通常会采用后融合感知系统,如这张图所示。对于不同视角图像,我们会分别检测里面的物体。这样显而易见会带来两个问题:一个是摄像头之间有重叠的区域,一个目标可能会被检测到两次 ;第二就是有一些很大的目标,比如大卡车,它会跨多摄像头,使得每个视角中都没有办法完整的检测到整体的检测框 。为了解决这两个问题,这类方法就需要有一个目标级的多传感器融合、目标级的时序融合和滤波模块,这样就构成了我们常说的后融合感知系统。
来源:星球内部资料,文末扫码领取!
后融合感知系统会有几个明显的不足:1、融合模块,仅仅收到了结构化的感知结果,信息不够充足 ;2、需要有一些前提假设,比如说感知误差分布、目标运动模型,需要很多超参数进行调优,一定程度上限制了整个感知系统的上限 ;3、需要维护一套独立于模型以外的融合模块,这使得系统的复杂度偏高 。因此,这两年业界更多地在推行的是中融合方案 ,即先对不同视角的图像提取特征,然后在一个统一的特征空间下融合这些特征,最后再产出感知结果。这个坐标系,一般指自车的EGO 3D坐标系。这张图演示的是相关方法的演进。
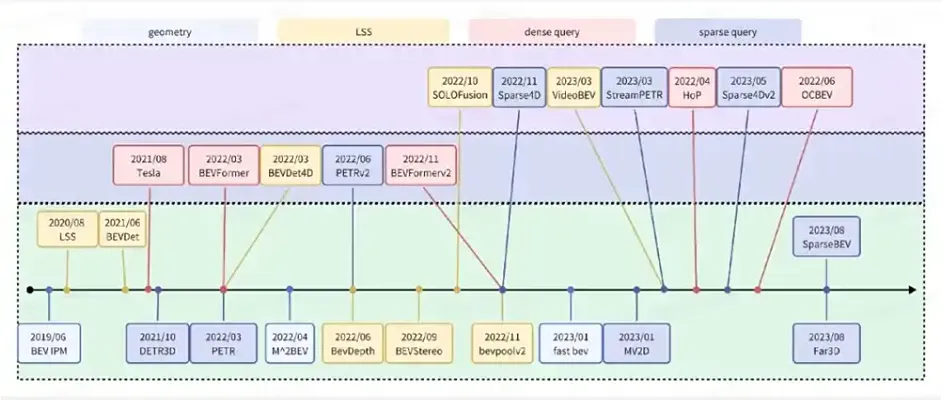
这其中大部分都是基于BEV的方法,上图就是BEV-based相关方法的相关演进, 用某种方式将图像视角特征转到BEV特征空间,也就是一个高度方向拍扁的自车3D坐标系空间下,再用一个检测的Head实现目标检测。BEV这张图的尺寸通常比较大,比如一般常见的论文里面会用128×128 size,但在实际中,我们甚至会用两倍大小的BEV特征图。从图像特征空间向BEV层空间转换过程,是一个非常密集的计算过程。有很多的方法也是在优化这部分的速度,比如说Fast-BEV 、BEVPoolv2 等。而另外一类方法没有提取显式的BEV特征,比如 PETR 系列工作和我们的Sparse4D 系列工作。它的关键思想就是构造3D空间下Query,用3D空间的Query去获取不同视角的特征,去聚合不同视角的特征,再传出检测的结果。下面先介绍一下比较有代表性的BEV和稀疏的方法。
BEV-based方法
IPM 方法

IPM是应用广泛落地最多的自动驾驶视觉感知方案,多用于parking场景。这类方法中,我们先会设定3D空间中的一系列点。比如,将BEV空间中地面的某个点,根据相机内外参投影到多视角图像上,再去采样对应的特征作为3D空间点的特征表示。个人认为是一个最简单快速的BEV算法。它的做法是将每个BEV Grid看作所有物体在地面上,假设所有物体的高度为1,即Z轴的值都是1,等价于地平面假设,把BEV Grid的地面道路上的点投影到图像上去,获得BEV Grid的特征。可以看出,IPM依赖的一个前提是所有物体都在地面高度上,但实际场景中的高于地面的物体其实是不符合假设的,会存在很多的特征畸变。如果大家开车的时候会看360影像,会对这一点非常熟悉。因为360影像其实就是比较小范围的基于IPM的BEV。那么如何去优化IPM的效果,有很多改进方法。像去年非常有影响力的工作BEVFormer,我认为在某种程度上可以看作是一种IPM的改进。本质上IPM四张图拼接的过程应该类似与BEV-Det多v拼接的过程,只是一种是离线拼接,一种是隐式的基于learning的方式拼接特征进行feature extract learning。
LSS 方法
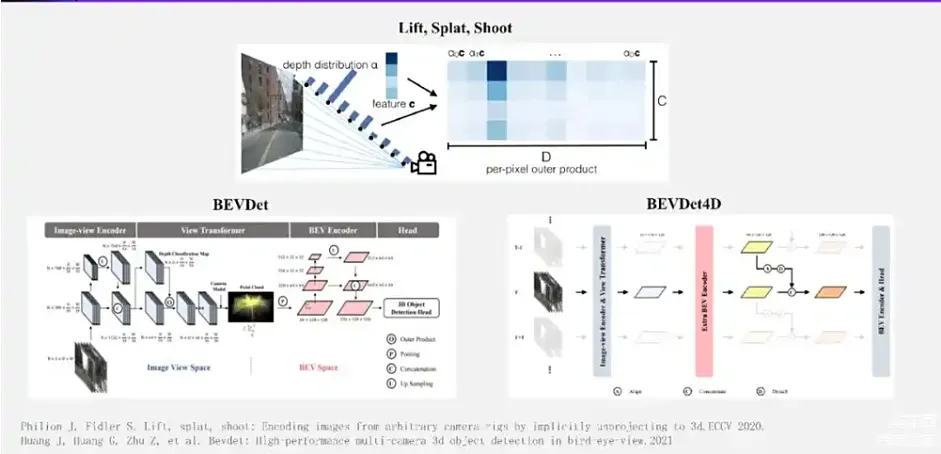
上图所示为LSS变化过程,也是BEV方法中一种重要的2d转3d特征的方式,BEV-Det是利用LSS进行BEV视觉感知的通用框架,也是应用最为广泛的自动驾驶视觉感知落地方案。LSS将2D 图像上的特征向3D 空间投影。最早的工作是Lift,Splat,Shoot。它的核心思想,是将图像上的每个点看作是一条射线。这条射线在3D空间中具体位置可以根据相机内外参获得,在这条射线上会去采样很多点,对于每个点去估计一个深度的置信度(即这个深度位置有物体的概率)。射线整体上的深度置信度,通过softmax可以规划为1。我们将图像上这个点的特征乘上射线上每个点的置信度,就可以获得射线上每个点的特征。基于这个思想,BEVDet 进一步实现了BEVPool算子,能够比较高效地实现升维后的视锥多视角图像特征向BEV 特征的快速转换,获得了很好的效果。 在BEVDet基础上进一步发展的BEVDet4D算法,引入了时序能力。具体做法比较简单,就是把上一帧的图像特征和单点帧图像特征拼接在一起,再过一个卷积进行融合,这就是我们称之为一种两帧短时序的时序融合方式。它能够比较简单地去获得视频时序流动的运动信息。通过刚才的介绍可以知道,BEVDet 特征投影方式效果是十分依赖于视锥深度估计的效果,那么如何去提升这个特征点投影效果呢?我们就需要获得更精准的深度估计。
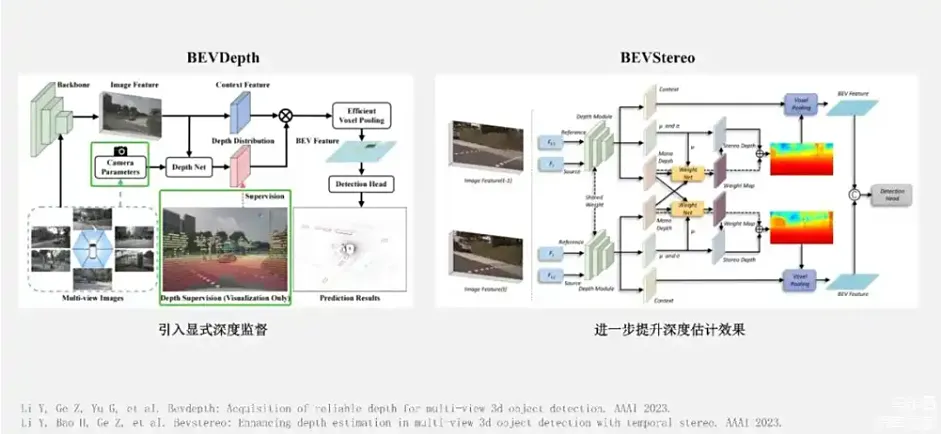
来源:星球内部资料,文末扫码领取!
上图是对LSS深度估计不准问题提出的解决方案,LSS方案得到的BEV-feature只能生成离散且稀疏的BEV表示。一个比较直观的做法就是给深度估计加显式的监督,也就是BEVDepth的做法 。BEVDepth的监督是来自于稀疏Lidar 点云 。那么再进一步如何再去提升深度估计效果呢?BEVStereo这个方法,就是将时序上的前后帧看作是一组双目图像,引入了双目深度估计中的思想去进一步提升深度估计的效果 。后续的像SOLOFusion工作,就更进一步将多视角的几何的深度估计和长时序的策略融合结合在一起 。它核心就包括两个模块,一个是高分辨率短时序模块 ,主要是基于前后帧的多视角几何的思想 ,去获得更加精确的深度估计,并初步获得BEV特征 ;再用BEV空间下的低分辨率长时序模块去融合,最多达到16帧的较长时序的BEV特征,这样它就获得了一个很好的效果。
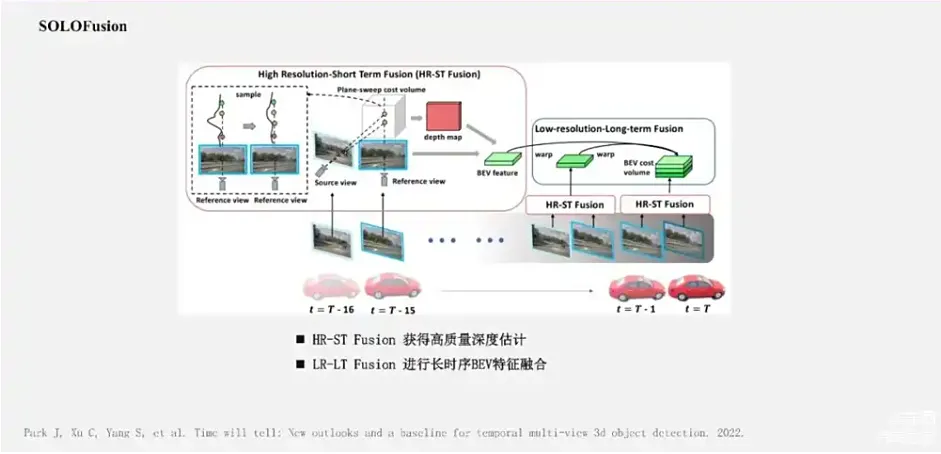
上图是SOLOFusin的基本网络时序融合框架,随着帧数越来越多,时序方法也出现了低效率问题。以SOLOFusion为例子,在每帧的前向过程中都需要融合过去16帧的特征。这样做的问题是:一方面整体网络中存在着很多的冗余计算,另一方面系统中需要缓存非常多的历史BEV特征。又因为BEV特征图通常比较大,这样的做法在系统带宽比较低的车端,自动驾驶系统是很难使用的。今年,VideoBEV提出了一种更加简单的Recurrent时序工作方式。
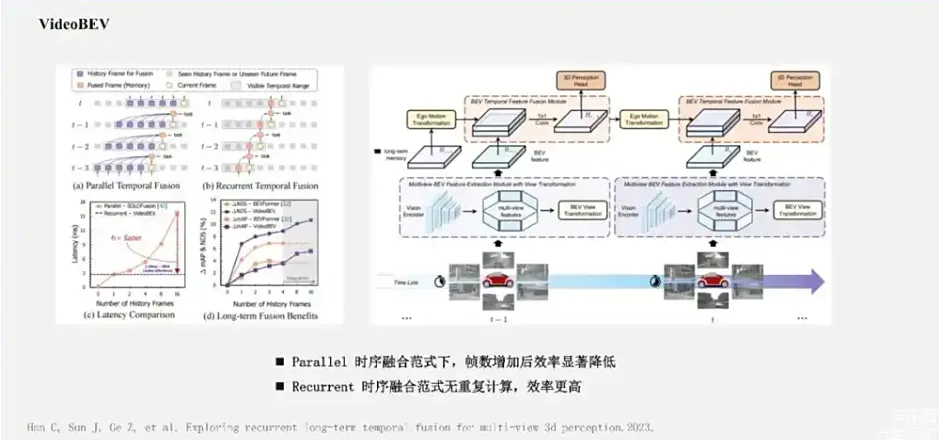
来源:星球内部资料,文末扫码领取!
简单来说就是将当前帧提取的BEV特征和上一帧融合后的BEV特征进行融合,再将融合后的BEV特征传递到下一帧 。这种有点类似于RNN的形式 ,可以让帧间传递的融合BEV特征,理论上能够保留较长时序的特征信息。当然这种循环神经结构也会存在着很强的遗忘特性,因此实际上传递的长时序信息是比较有限的。 VideoBEV这种形式对于实际车端使用是比较友好的,因为它的计算量始终是恒定的,指标提升也非常明显。这张实验对比图是来自于VideoBEV。
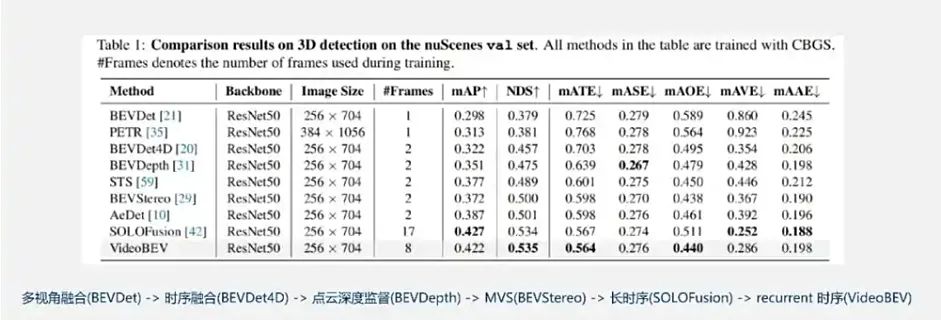
这张图片展示了基于Lift-Splat 2D到3D的BEV生成方式的技术发展路线。从多视角的特征融合,到时序的短时序融合,再到点云深度监督,再到多视角几何的估计,再到SOLOFusion长时序,再到VideoBEV Recurrent时序的形式,一步步的把这个方法框架的效果提升,使它更加适合真实场景的使用。另外一条与2D到3D路线相对的,叫做3D到2D的特征投影技术路线(reverse-project road)。
反向投影方法
其实IPM方法也是一种3D到2D反向投影的方式,只是这种方式区别于接下来要讲的基于隐式深度学习的投影。

BEVFormer方案主要包括两个主要的模块:一个Spatial Attention,另一个是Temporal Attention。我们先看Spatial Attention。它的做法是对于BEV Grid上的每个点视为Query,每个Query会在对应的grid的高度方向上划分多个voxel,每个voxel里面去用Deformable Attention采样多点,然后全部融合在一起去作为Query也就是 BEV Grid的特征。如果说刚刚的IPM是一个BEV Grid采样一个点,BEVFormer就是一个Grid采样了非常多的点。远远更加充分的点采样和特征融合,使得BEVFormer获得了比IPM好很多的效果。时序方面,BEVFormer用的也是一个两帧的短时序融合方式,采用的也是Deformable Attention的形式进行融合。BEV类的方法可以算是当前多视角3D感知的一个主流路线,但是在实践中BEV方法也存在很多的问题。**我觉得各类问题的根源在于,需要感知的目标在三维空间中通常是十分稀疏的,存在着非常多的无效区域。**而从图像空间到BEV空间转换,是一个稠密特征到稠密特征的重新排列组合。它计算量非常大,而且计算量与图像尺寸以及BEV的图像尺寸是成正相关的,这使得BEV模型的感知范围、感知精度以及计算效率其实是非常难平衡的。在我们常用的nuScenes数据集中,一般感知范围会设置为长宽 -50m, +50m 的方形区域,但在实际场景中,我们通常会需要达到单向100米,甚至200米的感知距离。如果说我们想要保持BEV Grid的分辨率不变,那么就需要去增加BEV特征图的尺寸,这会使得端上的计算负担和带宽负担都非常重。如果要保持BEV特征图的尺寸不变,就需要更加粗粒度的BEV Grid,那么它的感知精度就会下降。因此在车端有限的算力以及带宽条件下,BEV方案的一个常见难点是比较难以实现远距离感知与高分辨率感知的平衡。这个问题怎么解决?业界一个比较常见的做法是补充一个或者若干个前视或者前视窄角模型,比如2D模型,专门去做特别远距离的感知。但是这又带来一个问题,如果有好几个3D检测的感知来源,就还得再去做后融合,这使得模型又变得复杂起来了,没有真正消除掉后融合,也很难真正去做到端到端。另外一个问题是BEV空间是一个压缩高度信息的三维空间,这使得它对于一些高度方向上敏感的任务比较难完成。一类任务是标志牌、红绿灯检测。好在标志灯、标志牌、红绿灯检测可以通过2D任务来解决。另外一类,比如异形车,它不同高度,形状不一样,用拍扁的方式,很多时候不一定能够很好地解决。那么,与这种生成密集特征相对应的就是我们称之为稀疏感知方法,比较早的有代表性的就是DETR3D。
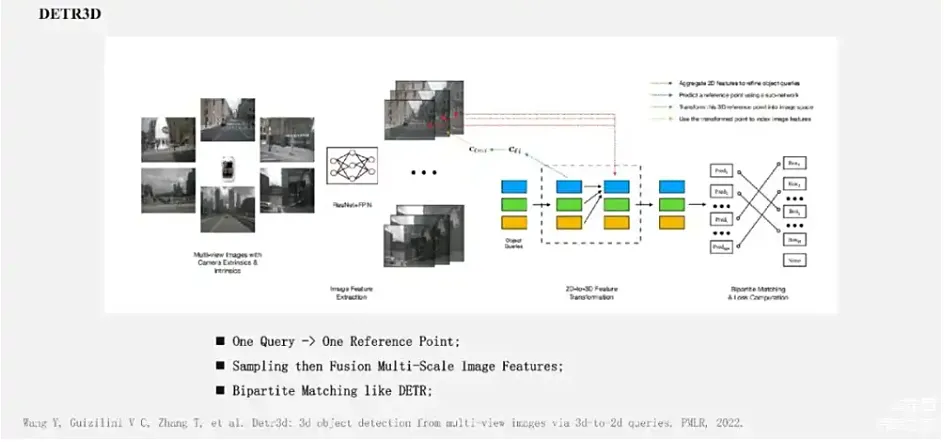
它的稀疏体现在,并没有像BEV一样对BEV 3D空间中所有点都去转换特征,而是只对我们感兴趣的目标进行了3D特征的转换和融合,主要流程包括以下几步:
- 和大部分方法一样,也是提取多视角的特征;
- 初始化Query,用特征编码方式初始化若干的Object Queries;
- 将Query特征通过MLP映射到3D空间的参考点坐标,将这个点通过相机内外参投影到图像平面上,并去采样多尺度特征,融合后采样特征来作为Query的特征更新;
- 通过更新后的特征,迭代式地去更新Query的信息,并去预测目标框信息;最后用二分匹配方式去跟真值进行关联,再进行训练。
另外一个比较有代表性的方法是PETR系列。
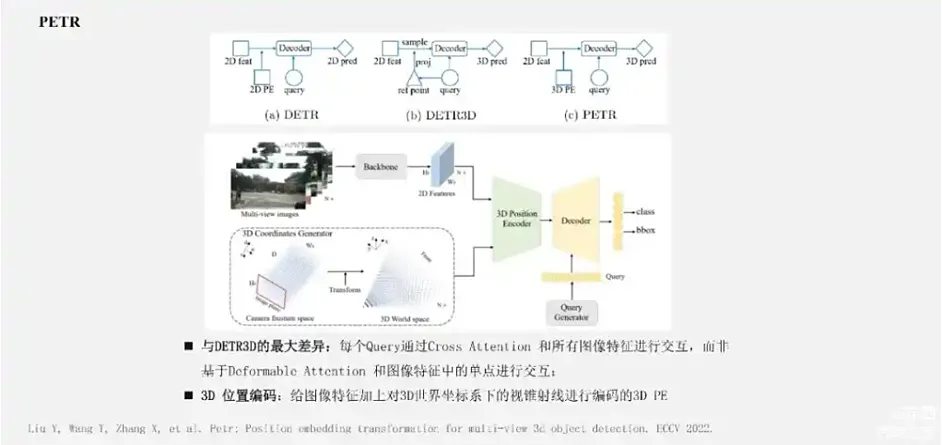
来源:星球内部资料,文末扫码领取!
PETR系列方法与DETR3D的一个最大区别在于:PETR里面Query特征是通过Cross Attention直接和所有的图像特征进行交互,而非类似Deformable Attention这种基于采样的方式与图像中的特征进行稀疏性的交互。 在PETR这种形式下,关键的问题在于:如何将图像特征跟3D的信息关联上?PETR的方法是将相机的视锥射线基于内外参投影到3D的自车坐标系下,基于这些点的坐标进行编码,得到3D的位置编码,然后加到图像特征上去做。在此基础上,PETR-V2进一步引入了两帧形式的时序融合,和一个更加优秀的3D的位置编码策略。
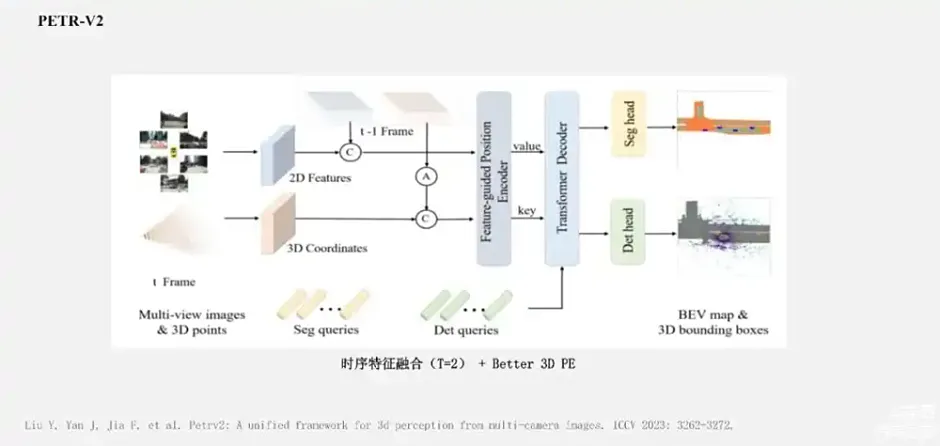
PETR-V2更进一步,近期StreamPETR方法,类似于VideoBEV引入了Recurrent的时序融合策略。
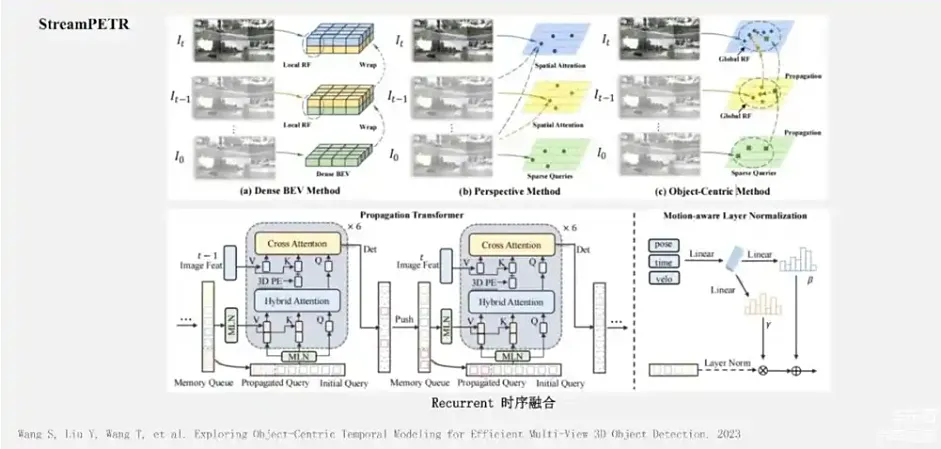
但不同的点是采用Recurrent时序融合策略是实例级别的融合。具体做法是把t-1帧获得的检测结果作为Query,通过一定的隐式的运动变换后,把它推到第t帧作为一部分的输入Query。来自上一帧的Query和这一帧新初始化的Query,一起进入Decoder 模型,得到新一帧的感知结果。我们的Sparse4D-V2版本方法,也采用了一个类似的实例级别的Recurrent时序融合策略,后面我会介绍两者之间的设计上的差异。在上面的几个方法中, DETR3D是稀疏Query加上稀疏的特征交互;PETR则是稀疏的Query加上密集的特征交互;PETR-V2 和StreamPETR 则分别引入了两帧的时序和Recurrent的时序形式。
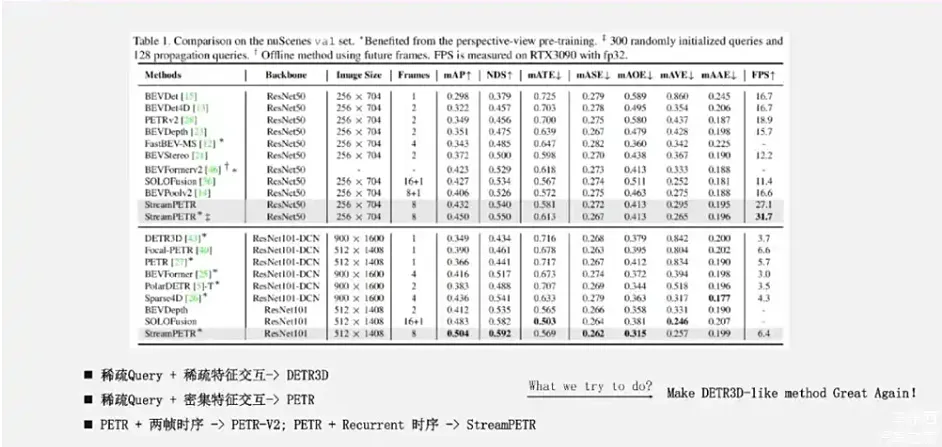
PETR系列方法效果非常好,但可能存在一个问题是稠密的特征交互,特别是在板端算力有限的情况下,对于比较高分辨率的图像特征输入不够友好,耗时会随着输入图像分辨率的增加而非常快地增长。 我们这一系列研究出发点是,希望实现一个高性能、高效率的长时序纯稀疏融合感知算法。这条技术路线比较代表性的方法是刚刚提到DETR3D算法。但是,从开源数据及指标来看,DETR3D的性能距离其他稠密类型的算法有比较大的差距。为了让纯稀疏感知或者DETR3D感知再次把性能达到这种算法水平,这两年相继提出了Sparse4D 以及它的改进版本Sparse4D-V2,从Query的构建方式、特征采样方式、特征融合方式以及时序融合方式等多方面提升了模型效果。当前 Sparse4D-V2 在nuScenes Detection 3D的榜单上也达到了比较SOTA的效果,超越了像SOLOFusion、BEVFormer-V2和StreamPETR在内的一些方法,而且在推理效率上也有明显的优势。接下来我主要会介绍Sparse4D和Sparse4D-V2方案的一些细节的实践。
前向-反向投影结合的方法

视觉转换模块(VTM),主要作用在视图转换过程,将多视图特征转换为BEV特征表示,是基于视觉的 BEV 感知系统的关键部件。**目前,VTM 存在两种主流的方法模式:前向投影和反向投影。**前向投影以 NVIDIA 提出的 BEV 感知算法 LSS(Lift, Splat, Shoot)为代表,在不借助后处理操作,直接产生稀疏的 BEV 特征。反向投影以 BEVFormer 为例,投影匹配时易于产生假阳性 BEV 特征,主要由于缺少统一的深度信息。
如上图所示,前向投影是将相机特征投射到BEV平面上最为直观的方法,其中涉及图像平面上每个像素深度值的估计,并且使用相机标定参数来确定每个像素在3D空间中的对应关系。称这一过程为前向投影(IPM、BEVFormer)。
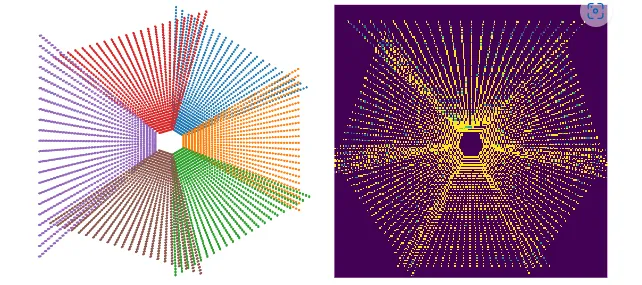
其中2D像素主动投影,而3D空间被动接收来自图像空间的特征。这一过程中,预测每个像素深度的准确性,是获得高质量BEV特征的关键。为了解决预测像素深度这一难题,NVIDIA提出的BEV感知算法LSS(Lift, Splat, Shoot)首先使用深度分布来建模每个像素的不确定性,但LSS有一点不足:它只能生成离散且稀疏的BEV表示。
BEV特征的密度随着距离变大而减小。当在nuScenes数据集上使用LSS的默认配置,即为同通过将图像"抬升(Lift)"为3D点云,并将所有截头锥体"拍扁(splats)"到参考平面上时,那么在投射过程中,仅有50%的3D网格可以接收到有效的图像特征。
在动机方面,反向投影和前向投影完全相悖。在反向投影机制之下,3D空间的点占据主动。例如,BEVFormer会预先设定要填充的3D空间坐标,然后将这些3D点投射回2D图像上,具体如图1中间所示。因此,每个预设定的3D空间位置都可以获得与之对应的图像特征。反向投影获得的BEV表示特征,会比LSS稠密得多,因为每个BEV网格都填充了与之对应的图像特征。然而,反向投影的缺陷也尤为明显,如图3所示:虽然获得了稠密的BEV特征表示,然而因为遮挡和深度误匹配,会产生很多错误的3D到2D空间的对应关系,这一错误匹配造成的主要原因是投影过程中的深度信息的丢失。近来,前向投影领域得到进一步发展,借助更多的深度监督信息辅助提高深度分布的准确性,这有助于3D感知。
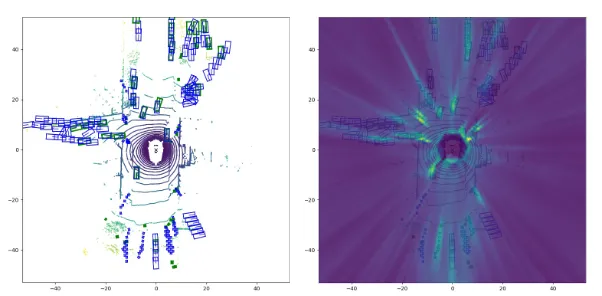
为解决前向投影中的稀疏BEV特征表示问题,我们使用反向投影提炼前向投影中的稀疏区域。针对反向投影由于缺失深度信息的指导,而产生假阳性特征的问题,FB-BEV提出一个深度感知的反向投影,借助深度一致性,衡量每个投影关系的质量,来抑制假阳性特征。
何为深度一致性?是通过一个3D点和与之对应的2D投影点的深度分布距离来确定的,即为深度一致性。基于这一深度感知的方法,不匹配的反向投影会被给定一个较低的权重,从而减少由于假阳性BEV特征导致的推理。
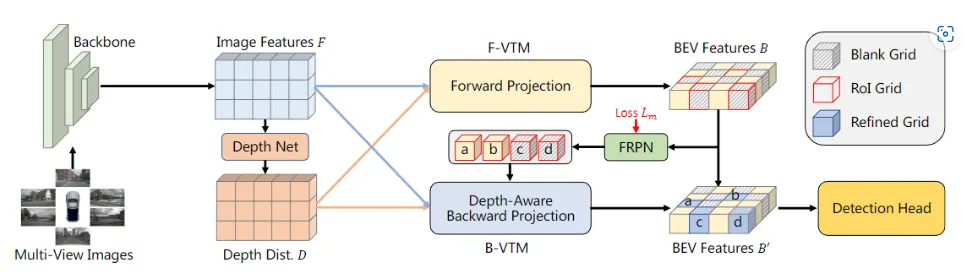
FB-BEV主要包含三个关键模块:
i. 带有前向投影的视图转换模块F-VTM
ii. 前景区域推荐网络FRPN
iii. 带有深度感知的反向投影视图转换模块B-VTM
长时序稀疏方法
首先,我们再去回顾一下DETR3D上面存在的问题。
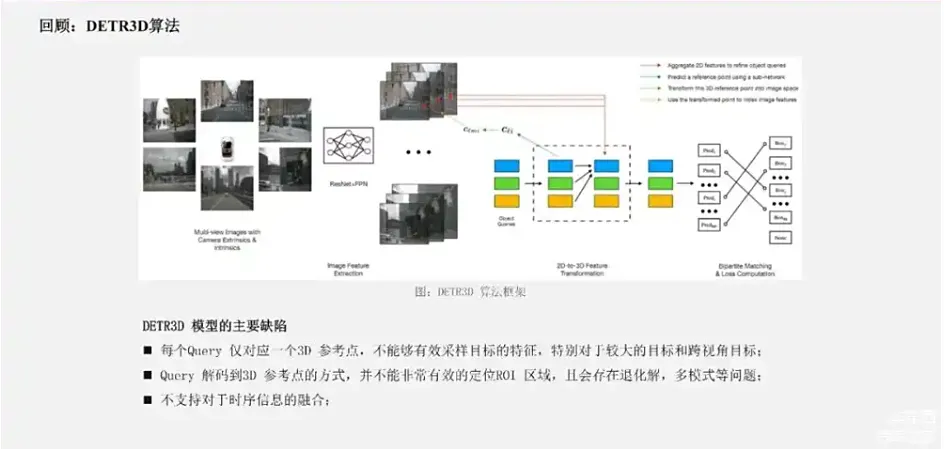
作为一个比较早期的算法,DETR3D的设计比较简单,存在几个问题。第一点是它的每个Query只对应一个3D参考点,不能够非常有效的去采样目标特征,特别是对于比较大的目标以及一些跨视角目标,可能就投到一个点,但不能把这个目标都覆盖到;第二点是Query解码到3D参考点的形式,并不能非常有效地定位ROI区域,会存在退化解,多模式的问题。这个问题其实在2D的DETR改进方法里面有很多讨论,类似于DAB-DETR也讨论了Query到参考点解码形式的存在问题;第三点是DETR3D里面没有引入时序信息融合。在Sparse4D的第一版本中,我们主要通过Instance的构建方式,特征采用、特征融合和时序融合等方面去对DETR3D进行了改进。我们在改进过程中学习了非常多2D检测领域DETR改进的经验。
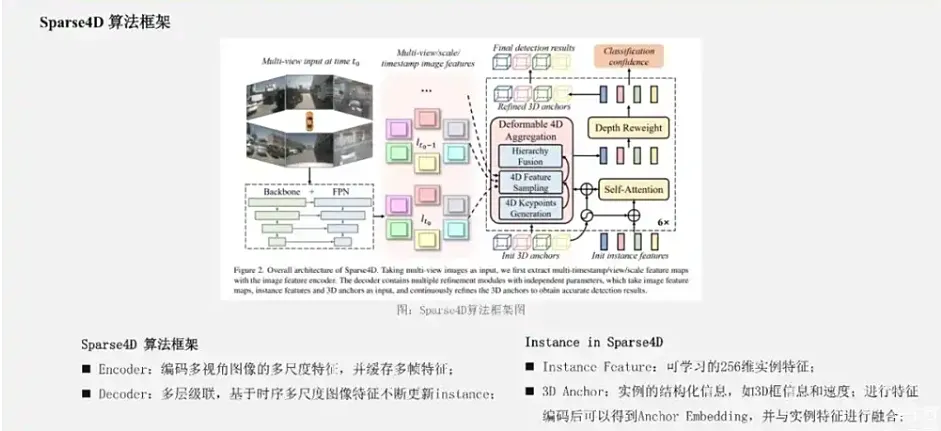
首先,最大区别是sparse4D重新引入了Anchor的使用。对于待感知的目标我们定义为Instance,每个Instance会由两个部分构成:第一部分是Instance的 Feature。它在Decoder中会不断由来自于图像特征的采样特征所更新;第二个部分3D Anchor 是目标结构化的状态信息,我们会显式地把Anchor的参数作为Anchor的信息,它会包括很多具体的值,包括目标框的位置、长宽高、yaw角、速度信息,我们都会作为Anchor的一部分。在Sparse4D-V1里面,Anchor本身我们通过K-Means算法来进行初始化的,同时在网络中基于一个 MLP网络来对Anchor的结构化信息进行高维空间映射,得到Anchor Embed的概念,并与前面说到可学习的Instance feature相加得到更加综合的特征表示。基于以上定义,我们可以初始化一系列的Instance,经过每一层Decoder都会对Instance进行调整,包括Instance特征的更新和Anchor box的refine,对于每层预测的bounding box中,Sparse4D同样会通过二分匹配的方式与真值进行匹配,并计算损失函数。在Sparse4D中,最重要的一个模块是Deformable 4D Aggregation可并行的4D特征聚合模块。这个模块主要负责Instance和时序图像特征之间交互。
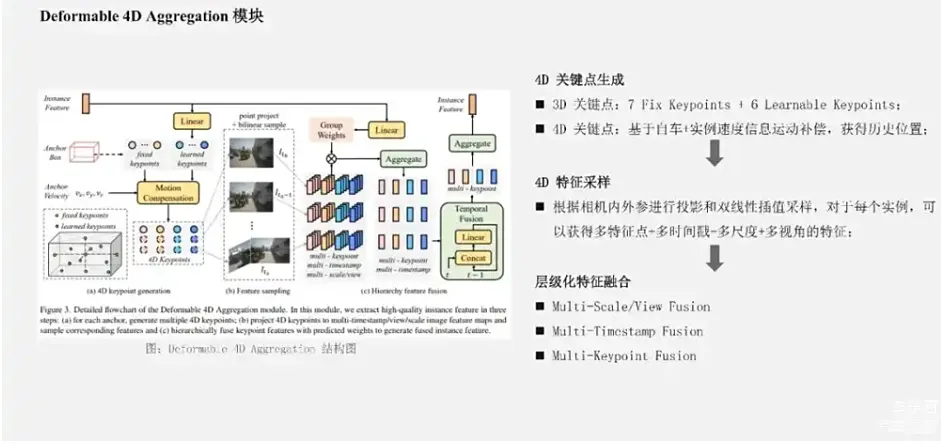
如图所示,主要包括三个步骤:第一点是4D关键点生成。基于每个实例的3D Anchor信息,首先可以生成一系列的3D关键点,分为固定的关键点和可学习的关键点。将固定的关键点设置为Anchor box的每个面的中心点,以及其立体的中心点;可学习的关键点,通过实例的特征接入一层全链接的MLP网络来得到。在 Sparse4D-V1的版本中,sparse4D采用了7个固定关键点 + 6个可学习关键点的配置,一共13个关键点。然后,sparse4D会结合每个实例自身的速度信息,以及自车的速度信息,对这些3D关键点的位置进行时序的运动补偿,获得它们在每一个历史帧中的位置,相当于把当前帧的一系列关键点投影到了每一个历史帧上。那么,结合当前帧和历史帧的3D关键点,就获得了每个实例的4D的关键点。下一步是4D特征采样。在获得每个Instance的当前帧和历史帧这个关键点之后,我们会根据内外参将这些点投影到对应的多视角图像上去,进行双线性的插值采样,从而得到多关键点、多时间戳、多尺度和多视角的特征表示。这其实是一个比较大的特征表示。得到多层级特征表示之后,做层次化的特征融合,sparse4D分为了三层:首先,对每个关键点去融合在不同特征尺度和视角上投影特征,采用了加权求和的形式。权重系数是通过将实例特征输入到全连接网络中去预测到的,是一种动态加权的方式;第二点是做时序特征的融合,sparse4D采用的是一个简单的,类似于RNN的网络来做融合;最后一点会用求和的方式将一个实例不同关键点特征加在一起,作为一个融合。这页展示的是 Sparse4D中的Ablation Study。
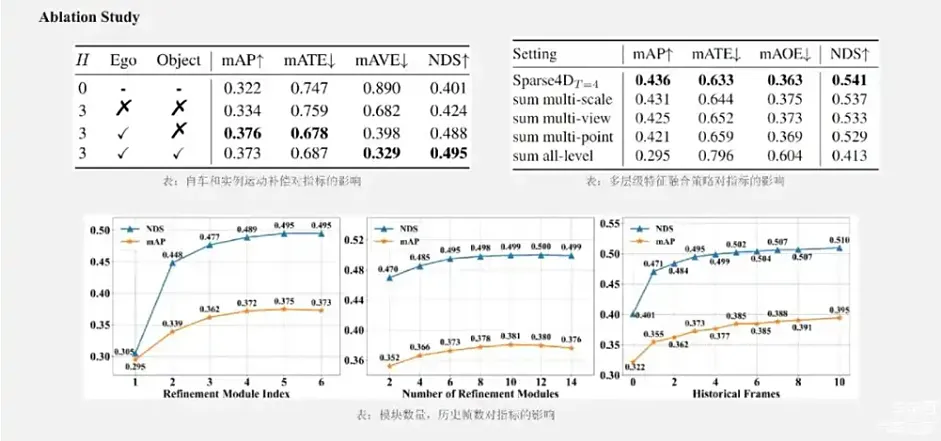
左上角是我们在刚刚的4D关键点中做运动补偿的必要性,对自车运动以及目标实例的运动做运动补偿,对于网络的效果都是有明显提升,特别是对于速度估计的提升是非常的巨大的。其次,我们的融合策略比起直接简单的去加权多尺度的多级别特征,效果要好一些。在Sparse4D中的时序方面,我们发现跟SOLOFusion类似的结论,时序增加的越多,效果就越好,但后面的提升可能会逐步收敛。效率方面,Sparse4D单帧的版本的速度是略慢于DETR3D,这是一个预期内的情况,因为采样点变得更多了,而且有很多融合的模块。
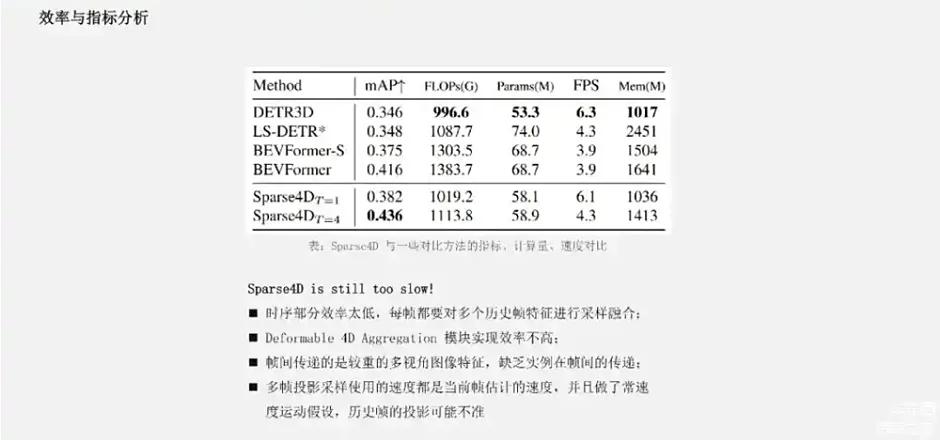
来源:星球内部资料,文末扫码领取!
但在多帧的情况下,Sparse4D的速度下降了很多,主要是因为多帧推理的时候,在Sparse4D框架里面类似于SOLOFusion,对每一个历史帧的特征都要进行一次采样融合。在Deformable 4D Aggregation这个模块中,由于要采用多视角、多尺度、多关键点,再按多帧特征去融合,中间有很多的读写操作,效率也不是很理想。此外,Sparse4D帧间传递的是比较重的多视角的图像特征,缺乏实例间的帧间传递。这些点就使得Sparse4D特别是在多帧的情况下, FPS下降比较明显。比起一些对比的方法,它在速度和显式量上其实并没有很大的优势,并没有很好体现出稀疏框架的优点。**同时Sparse4D时序采样的一个问题是:它的速度采用的是实例在当前时间节点估计的速度,而且我们用了常速度的运动假设,对于变速度的目标历史帧投影很可能是不准的。**那么,针对Sparse4D-V1里面存在的这些问题,我们做了很多改进。
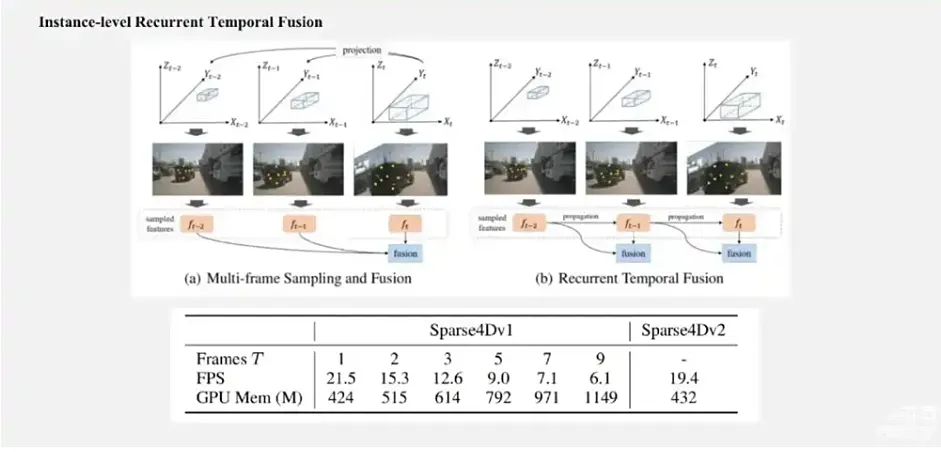
总体来说,可以归为两方面:第一点是我们引入了Recurrent的实例级别的时序方案;第二点是我们对网络中的非常多的模块进行了速度和效率地优化,使得整体的FPS和显式占用都得到了极大优化。具体而言,如上面这张图所示,我们会把上一帧的Instance传到下一帧作为Query的输入。接下来介绍一下具体的框架。
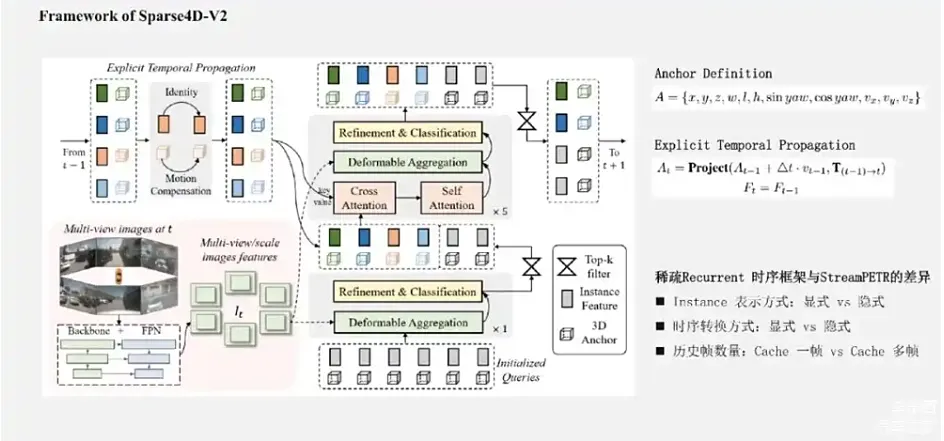
来源:星球内部资料,文末扫码领取!
这张图展示了Sparse4D-V2的整体框架图,Encoder部分与V1版本一致,这边就不展开。Decoder 部分为了非时序层和时序层。其中非时序层有1层,时序层有5层。非时序层全部是新初始化的Instance作为输入,输出一部分高置信度的Instance到时序层。时序层的Instance除了来自于单帧层的输出以外,大部分来自于历史帧,也就是上一帧。我们的做法是将历史帧的Instance投影到当前帧,在这个过程中保持实例的特征是不变的,但Anchor box会通过自车运动和目标速度投影到当前帧,Anchor embed通过对投影后的Anchor box进行编码得到。可以看出非时序帧的作用主要是先简单检测一下场景中的目标,去做一个比较好的新出现的目标的初始化。其实,大家如果熟悉MOTR以及MUTR3D ,会觉得这个框架跟MOTR有点相似,都有历史帧的实例进入当前这一帧,也有当前帧新的实例一起进行检测。主要区别在于,Sparse4D-V2中,目前在真值关联部分没有区分历史帧和新Instance的匹配。因为在MOTR里面,是有一套比较独特的匹配策略,它的历史帧已经贯穿目标,会继续跟历史帧关联。我们这边没有做针对tracking的关联策略的调整,还是全部放在一起进行一个关联形式。Sparse4D-V2和StreamPETR都采用了实例级别的Query的时序框架,两者之间有什么差别?主要有几点:第一点,是Instance表示方式。在PETR里面Query Instance 采用的是将均匀分布在3D 空间中的可学习 Anchor point,用MLP编码成Query特征。Sparse4D中则是更加显式的做法,会把Instance分离成Feature和3D Anchor,PETR的Instance的形式就更加隐式一些了。我们的观点是特征跟Anchor box的分离的表示方式,在稀疏3D检测任务中可能是更加有效、简洁的方式,也更加易于训练更新检测结果。第二点,我们将历史帧投影到当前帧这个时序转换的方式,其实是跟前面刚刚说到的Instance的表示方式相对应的。在StreamPETR中,采用了隐式的Query时序特征表示,既把目标的速度、自车的速度、时间戳都编码成特征,然后再和每个Query的特征做adaptive的normalization来进行隐式的更新。Sparse4D-V2 如刚刚说的是一种非常显式的时序转换方式,直接把Instance基于运动信息的Anchor box投影到当前帧,特征是保持不变的,因为希望这个特征更多的保留它的一些语义信息。第三点,StreamPETR和Sparse4D-V2中历史帧的数量不同,从PETR里面会保留多帧的信息,再去那一帧做Attention。Sparse4D-V2只cache了一帧,StreamPETR也可以只cache一帧,但是效果会略有下降。在实际的业务实践中,比较少的cache历史帧有助于减少端上的带宽占用,进一步提升系统整体的性能。此外,在Sparse4D-V2中一个比较大的改进是,我们还对Deformable Aggregation模块进行了底层的分析和优化,让其并行计算效率显著提升,显存占用大幅降低。
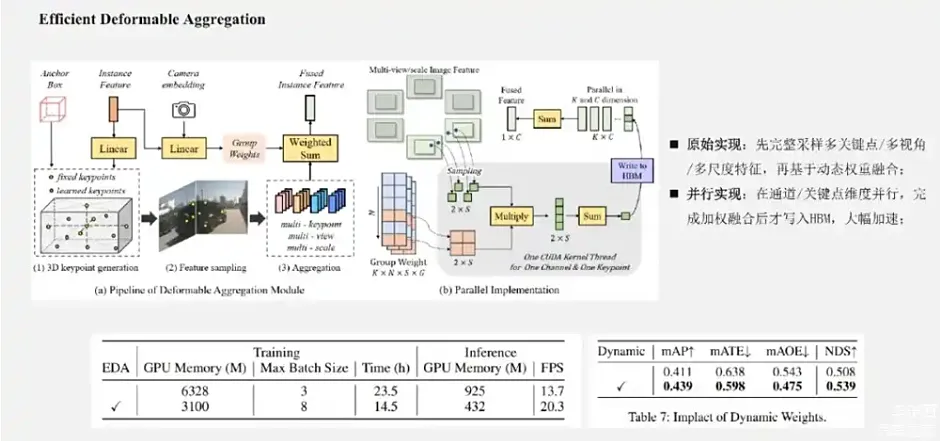
来源:星球内部资料,文末扫码领取!
左上图展示的是Deformable Attention基本的计算流程,在原始的流程中我们会先采样得到多关键点、多视角、多尺度的中间特征,把这个特征和group weight进行融合,得到融合后的特征。在这个过程中,需要对显存进行很多次的访问和读写操作,降低了推理速度,而且中间的特征尺度比较大,有好几个维度,使得显存占用量会显著增加,且使得反向传播过程中的显存消耗比较明显的提升。那么,为了提升op的计算效率,降低显式占用,我们将上述实现中的双线性特征插值采样和加权求和融合,合并在一起做了一个算子。就像右边这张图所示,我们称之为Efficient Deformable Aggregation(EDA)模块。这个模块关键在于将采样所有特征再融合的形式,变成了并行地边采样边融合的形式,它能够在关键点k的维度和特征的c维度上实现比较完全地并行化。每个线程或者每个cuda线程的计算复杂度仅与这个相机数量n和特征尺度s有关。此外,在大多数情况下,特别是在自动驾驶的多视角图像的情况下,3D空间中的一个点,一般最多就被投影到两个视图上,这使得我们可以进一步将计算的复杂度降低为2×s。EDA作为一种比较基础性的算子操作,可以适用于需要多图像和多尺度融合的各种应用。目前这个算子的实现,也已经在我们的官方代码库上开源了。我们在3090上对EDA模块进行了性能测试,可以看出来EDA对显存占用和推理速度都有一个比较明显的优化。在加入EDA模块之前,在这个配置下,它的推理FPS只能达到13.7FPS,但加入EDA之后就可以有50%的提升,到20FPS。而且整体的训练速度也降低了非常多。此外,我们还提了一个Ablation Study,在Sparse4D-V2上再次去检验了动态特征加权的有效性,可以看出它能够带来三个点的MVP的提升,还是比较有效的一种做法。这页展示了更多的关键设计的Ablation Study。
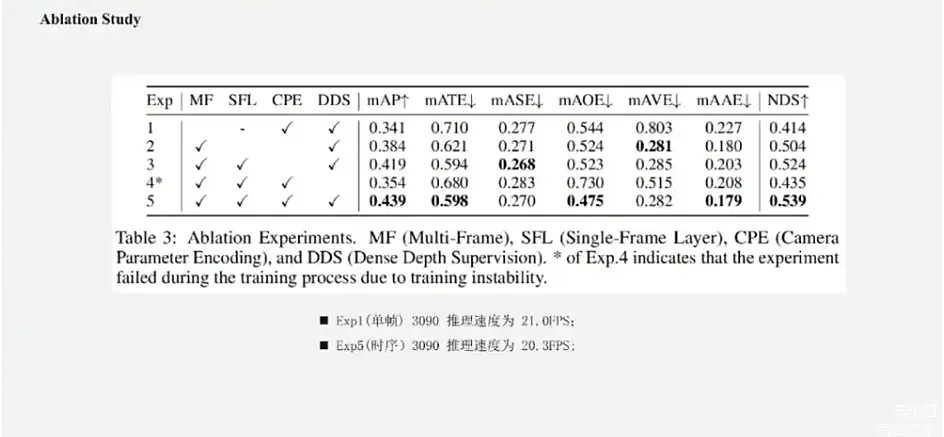
我们对比实验1和实验5可以看出,采用Recurrent Instance的形式来实现长时序融合,相比单帧的提升非常大,有将近10个点提升。对比实验4、实验5可以看出,在Sparse4D-V2中深度监督模块比较重要,能够比较明显降低Sparse4D-V2的收敛难度。如果去掉这个模块, V2版本的模型可能会出现一定的梯度崩溃的情况,使其指标有一定的降低。可能很多时候,在业务场景不具备深度监督条件,这时候也可以用一些其他的 head去辅助,比如FCOS Head、YoloX等去做辅助监督,都能够有效改善训练情况。实验2和实验3去做对比,可以看出我们刚刚提到的单帧层 + 时序层的组合,先用单帧层去初始化一些检测的Instance,它会比全部用未初始化的 Instance+时序Instance方式的效果好很多。实验3、实验5对比是展示了我们的另外一个小的改动,在特征聚合的模块里面加了相机参数编码,它也有比较可观的提升。此外就是实验1单帧模型,它在3090上推理速度是21FPS,实验5的推理速度是20.3FPS,基本上是保持一致的,它时序的速度稳定性还是非常好的。另外,我们也在nuScenes validation上面去更新一些参考方法,和一些比较SOTA的新的3D感知方法做了对比。
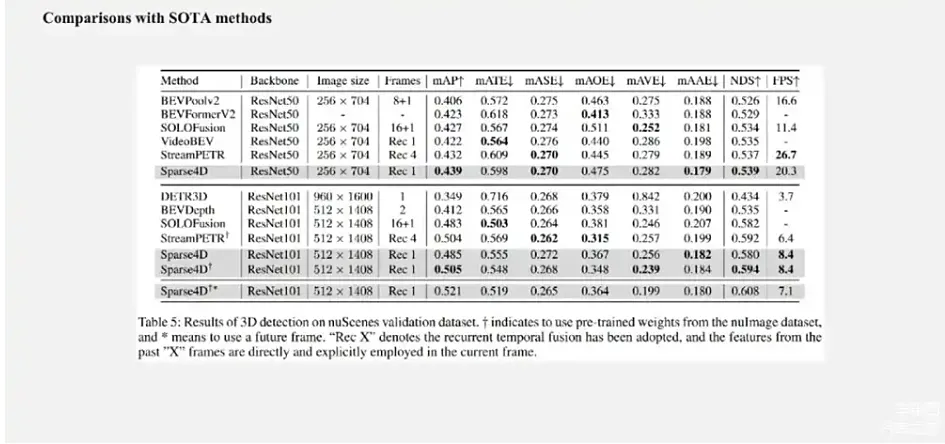
来源:星球内部资料,文末扫码领取!
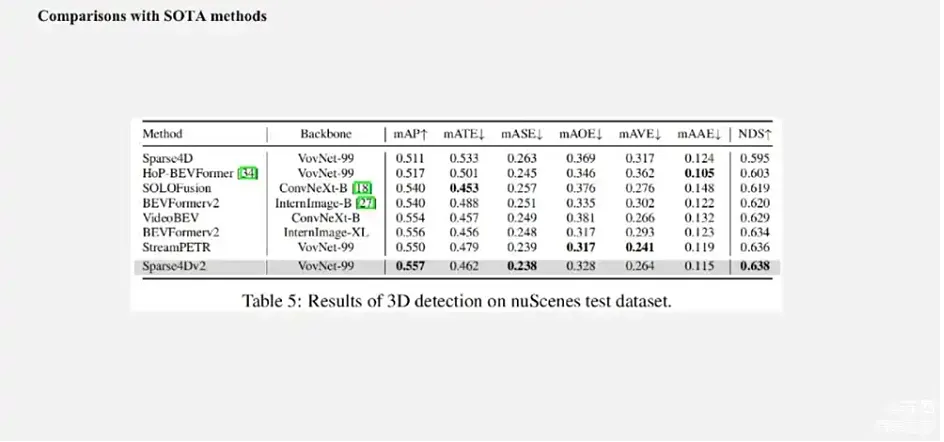
可以看出,无论在低分辨率+ResNet50或者是高分率+ResNet101的配置下,Sparse4D-V2都获得一个比较好的效果,超过了像SOLOFusion、VideoBEV、StreamPETR等算法,当然也比较明显的超过了Sparse4D-V1版本,不过这个表格里面没有写 V1的效果。Sparse4D-V2在256×704的低分率下,速度要比StreamPETR慢,但是会快于LSS-Based,类似于BEVPoolv2。但当图像分辨率提升到512之后,Sparse4D-V2反而会快一些。这主要是因为在低分辨率下直接做Global Attention的代价会比较低,但随着特征图尺寸的上升,它的效率会比较明显下降。Sparse4D head部分的理论计算量和特征图尺寸是无关的,都是通过grid sample去实现特征采样,这也展示了稀疏算法的优势。实际设定中当图像分辨率从256×704提升到512×1408的时候,Sparse4D-V2 Decoder部分的耗时只会增加15%左右,但这是因为从一个比较高分辨率图像的特征上去采样特征,虽然说计算量是一样,但它会比低分辨率图像上的测量会慢一点,这跟特征的访问效率有关。另外,我们也在测试集上面去做了对比,由图可见,也获得了比较好的效果。
总的来说,对于Sparse4D-V2,我们的结论包括三方面:第一点是显式的稀疏实例的表示方式。把Instance表示为3D Anchor和特征结合,并不断地进行迭代更新,是一种比较简洁有效的方式。同时这种方式在时序框架里面,也很容易去做时序运动补偿 。第二点是对于稀疏架构,它的特征采样和聚合的算子效率是非常重要的,如果是一个直接基于PyTorch实现算子,它的效率可能并没有那么高,并没有理论计算量那么高效 。因此,我们就提出了针对多视角、多视图像的层级化的采样策略,也提出了一个非常高效率的算子。第三点是Recurrent的时序稀疏融合框架。它使得时序模型基本具备了与单帧模型相同的推理速度,且帧间占用的带宽非常少。这样轻量且有效的时序方案,是非常适合在一个真实的车端场景去处理多摄视频流的数据。这里还有没有写的一个结论是:Sparse4D-V2的时序框架,是非常容易去做端到端的跟踪。我们后面做了一个实验,发现将检测结果直接根据帧间的Instance对应关系,加上track id,不额外去添加一个tracker,比如一些移植的tracker,就能够得到非常好的跟踪效果。**由此可以看出, Sparse4D-V2去做端到端跟踪的潜力是非常大的。**这页还进一步展示了我们最新的一个实验的结果Sparse4D-V3,目前代码和报告还没有release。
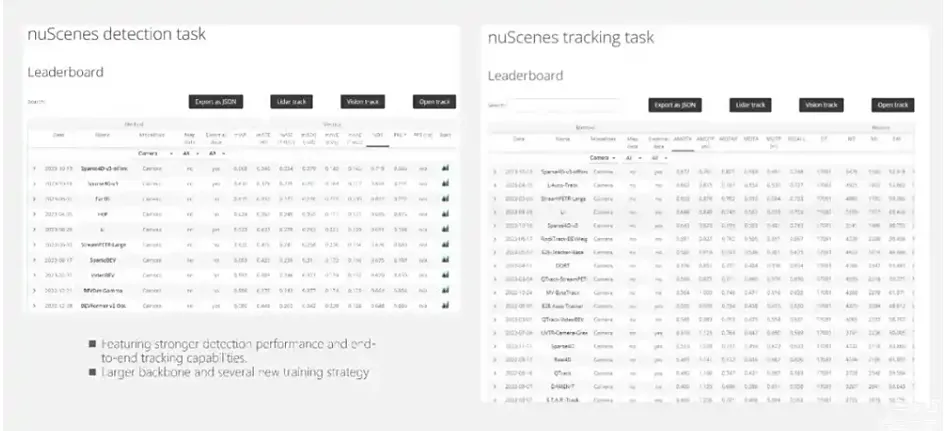
在Sparse4D-V3中,进一步加入了一些新的特性,比如更大的backbone以及更优秀的训练策略,也实现了刚刚说的端到端的跟踪能力,获得了比较好的效果。这是前几天的一个比较新的实验结果。Offline版本的Sparse4D-V3到了0.719的NDS。Offline的版本是指在这个实验中用到的未来帧信息。正好聊一下这个问题,对于这种比较大Backbone的多视角感知模型,它的业务价值到底在什么地方?因为实际上在端上可以跑的模型,一般跑不了很大的Demo,比如说像刷榜大家会问到VIT-Large这种级别的Demo,它在业务场景下很难使用。因为端上的算力可能有限,可能只能用到ResNet34或者ResNet50这种小模型。**那么,我们认为这种大模型的最大价值就是尽可能地追求它的指标上限,拿来作为云端真值系统的预刷模型,产生4D的真值。这些真值再拿去作为车端模型的训练。**这种离线的真值系统里面一个比较重要的策略是我们要用到未来帧的图像,或者在后处理跟踪过程中,用未来帧信息去优化跟踪结果,目标是尽可能提升它的感应效果,以找到比较好的真值,作为真值系统的输入。
来源:星球内部资料,文末扫码领取!
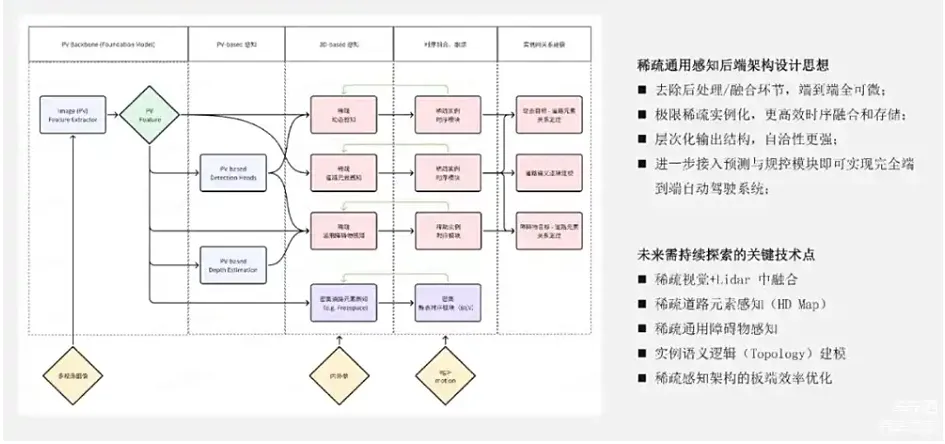
**如何在端到端自动驾驶系统中构建一个可靠可用的稀疏的通用感知后端?**这是我们认为未来非常有价值的技术方向。因为只是把检测这个事情做稀疏化,其实并不够。一个真实的系统中,不止检测,还有Online Mapping、障碍物感知,还有freespace等各种各样的任务。我们想要彻底去做稀疏化,就需要把各个任务都做优化改进。这张图是最近我画的,分为5个部分,是一个我对于稀疏通用感知架构设想的框架。
第一个部分是图像特征的提取。左上角写了Foundation Model ,后续可以和Foundation Model的预训练的方式相结合,在图像特征提取上面得到更加强大的特征表示。第二部分是PV-based 感知。在图像上去做检测任务,或者一些深度估计任务的时候有很多作用。第一点是PV检测的结果,可以作为后续3D感知Query的初始化,这一点在BEVFormer-V2等几个最近的工作中都有采用。Sparse4D目前还没有用上这个策略,应该也会是一个比较有效的策略。第二点是PV的一些任务,包括深度的任务或检测任务,它也有助于图像特征的收敛,使得网络整体上训练得更好一些。第三点是认为基于图像PV特征的一些检测深度,乃至于分割结果,有助于挖掘一些场景中存在的通用障碍物。第三部分是3D感知部分,包括动态感知(也就是检测)、道路元素感知(也就是HD map的在线预测)以及通用障碍物感知。我还画了一个BEV的模块,这是因为可能有些任务需要在一个相对可能比较小的发展范围内去输出密集的结果。比如freespace就是要道路面上的密集的结果,它是没办法去做Instance表示的形式。所以,在这种框架里面还是不可避免的要加上一个BEV模块。但这里的BEV模块可以使用一个较小的size,更加轻量的设计。最右的两个模块指的是时序融合模块和实例语义关系模块。总的来说,在架构设计中出发点包括四个部分:
- 尽可能会去除后处理和规则融合模块,使得网络整体是端到端完全可微;
- 尽可能将大部分的任务稀疏实例化,实现更加高效的时序融合和存储;
- 整体架构是一个层次化的架构。从2D的检测结果级别,到3D的级别,到时序的级别,到语义关系的级别,整体有一个比较好的自洽性;
- 这个框架进一步加入预测模块和规控模块,就能够实现完整的端到端自动驾驶能力。
在这个框架里面,很多也是比较初步的设想,有很多地方都不太成熟,值得我们未来去探索。比如第一点,在稀疏范式下的视觉跟Lidar的中融合的结合。虽然我这张图片没有画Lidar,但是后面在类似Sparse4D的框架下做和Lidar的融合,也是一个很好的话题。因为Lidar的稀疏化是一个更加自然的事情。第二点和第三点是如何去做完全稀疏化的道路元素感知和通用障碍物感知,这两点我接下来会展开讲一下。第四点是实例化的语义逻辑建模,就是对Topology的建模。这个方向研究工作也比较多,像Tesla也在Workshop上面也展示过一些相关效果。最后一点也是最重要的一点,就是要做好稀疏感知架构在芯片端的效率优化。因为所有的模块都要建立在一个良好的芯片端的效率上,才能够成立。
对于具体的三个方向,首先想讨论一下稀疏高精地图建模。
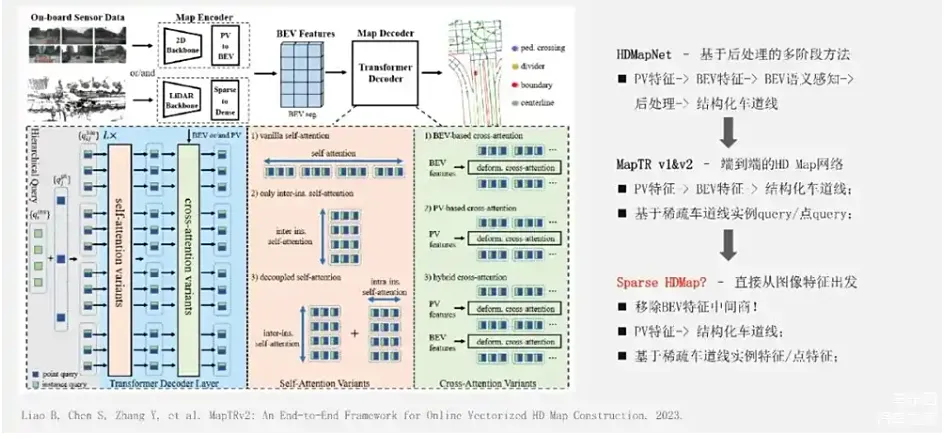
早期的方法,比如HDMapNet,可以认为是模型和后处理相结合的多阶段方法。一般会先获得BEV特征,在BEV特征上做语义感知类任务,在后处理阶段对BEV特征做聚类等的一些后处理,得到结构化车道线。后续的MapTR V1&V2等方法就实现了端到端的HD map网络。它的特点是基于BEV特征直接预测结构化车道线,省去了后处理步骤,通常是会构造稀疏车道线实例的Query,以及一些车道线中关键控制点的Query,去和BEV层做Attention交互,去迭代修正车道线的结果。那么,进一步的形势可能是怎么样的呢?刚刚我们提到了MapTR是用稀疏的Query和BEV特征去交互,BEV特征又是来自于图像特征。**理论上可以移除掉BEV这个特征的中间商,直接从图像特征出发,预测结构化车道线,我们认为这是一条完全可行的技术路线。**另外一个方向是关于通用障碍物感知,这个问题可能就更加开放性一些。

来源:星球内部资料,文末扫码领取!
通用障碍物的感知是自动驾驶感知系统里面比较重要的一个问题。传统方法一般就是不断地扩充白名单,也就是需要增加感知的目标种类。当遇到一类新的corner case,就可能需要去标很多数据,扩充相关的系统。但这样的做法比较缺乏泛化能力,成本也比较高。去年Tesla AI DAY之后,Occupancy又成为了解决这类方法的一种可能性。通过识别空间中的通用的障碍物情况,来定位到一些此前没见过的障碍物在3D空间中的占用。但Occupancy在实际系统中存在一些问题,比如计算效率比较低,因为3D Occupancy的输出空间很大,有效的点也很稀疏,这使得下游的模块想去解析并使用Occupancy的时候,是非常困难的一件事情,要真正用起来并不是一件很容易的事情。那么,是否有一种可行的路线呢?我也不是很确定,是否能去做稀疏的Occupancy是一种我们的预期想法。即只对感兴趣的目标或区域去做Occupancy,而不把所有地方都给估计出来。因为在一个整体的驾驶场景中,很多区域的Occupancy并不太重要,比如左图所示,一些距离道路可能20米之外的树木的Occupancy,估计出来对于系统来说并没什么意义。如果只挖掘对自车驾驶重要的区域,就可以避免算力的浪费。最近有一篇非常相关的工作叫Occupancy DETR,我觉得就有点这个意思,就是把前景物体跟背景的Occupancy分开估计,前景是用一种类似于DETR的方式去做估计,对于前景物体Occupancy估计效果会提升非常多。我觉得这个方法是一个挺有趣的工作。对于通用障碍物感知的事情而言,另外一个可能比较困难或者说比较重要的事情是:如何从图像视角去挖掘出有可能是一个障碍物的 Queries,再用DETR去做估计。总的来说,前面介绍了很多端到端自动驾驶的想法,以及稀疏感知的一些内容。第一点,以端到端自动驾驶为目标,稀疏感知范式在稀疏实例化表示、计算效率、模型带宽和感知范围等方面,都存在优势,有比较大的潜力。第二点,对于稀疏感知,虽然我前面对比很多稀疏感知和BEV的形式,但其实它跟BEV并不是互斥的形式,在整体的模型框架中还需要根据具体的子任务目标和感知范围去合理地选择,至少可以共享图像特征提取器。第三点,是在稀疏感知的范式下,有很多任务和难题还有待解决。
reference:
- FB-BEV: BEV Representation from Forward-Backward View Transformations
- DETR->DETR3D->Sparse4D: 长时序稀疏3D目标检测进化之路:https://zhuanlan.zhihu.com/p/1442634734
#LongCLIP
研究背景
- 研究问题:这篇文章要解决的问题是CLIP模型在处理长文本输入时的局限性。CLIP模型的文本输入长度被限制在77个标记以内,实际有效长度甚至小于20个标记,这限制了其在处理详细描述时的能力,特别是在图像检索和文本到图像生成任务中。
- 研究难点:该问题的研究难点包括:简单地微调CLIP会导致其性能显著下降;用支持更长上下文的语言模型替换文本编码器需要大量数据预训练,成本高昂。
- 相关工作:CLIP模型基于对比学习,广泛应用于零样本分类、文本图像检索和文本到图像生成任务。然而,CLIP缺乏提取细粒度信息的能力,现有工作通过对齐输入文本和图像的完整区域来改进这一点,但仍未能充分捕捉长文本中的细节信息。
研究方法
这篇论文提出了Long-CLIP作为CLIP的插件式替代方案,支持长文本输入,保持甚至超越CLIP的零样本泛化能力,并对齐CLIP潜在空间。具体来说,Long-CLIP引入了两种新颖的策略来实现这一目标:知识保留的位置嵌入拉伸和CLIP特征的主要成分匹配。
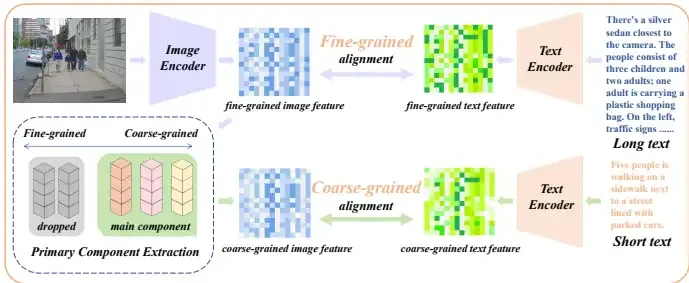
- 知识保留的位置嵌入拉伸:
- 通过对CLIP的实际有效长度进行实证研究,发现其有效长度仅为20个标记。
- 保留前20个训练良好的位置嵌入,并对剩余的57个训练不足的位置嵌入进行更大比例的插值。
- 插值公式如下:
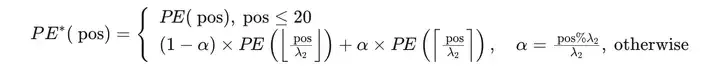
其中,PE(pos)表示第 posth 位置的位置嵌入,α 是一个0到1之间的比率,决定插值后的位置嵌入是更接近前一个位置还是后一个位置。
- 主要成分匹配:
- 在长文本微调过程中,不仅对齐细粒度的图像特征与长详细标题,还从细粒度图像特征中提取粗粒度信息,并与短摘要标题对齐。
- 设计了三个核心模块:组件分解函数 FF、组件过滤函数 EE 和组件重构函数 F−1F−1。
- 组件分解函数 FF 将特征分解为多个表示不同属性的向量,并分析每个属性的重要性。
- 组件过滤函数 EE 基于属性的重要性过滤掉不重要的属性。
- 组件重构函数 F−1F−1 使用选定的关键属性向量和其重要性重构图像特征。
实验设计
- 数据集:使用ShareGPT4V数据集作为训练数据,包含约100万个(长文本,图像)对。随机分离出1k个数据作为评估数据集。
- 评估数据集:在零样本图像分类任务中使用ImageNet-1K、ImageNet-V2、ImageNet-O、CIFAR-10和CIFAR-100数据集。在短文本图像检索任务中使用COCO2017和Flickr30k数据集。在长文本图像检索任务中使用从ShareGPT4V数据集中分离的随机1k个(图像,长文本)对,并手动收集200个描述城市场景的相似图像,使用GPT-4V生成长文本标题。
- 训练设置:在ShareGPT4V数据集上微调1个epoch,批量大小为2048。
结果与分析
- 长文本图像检索:在1k ShareGPT4V验证集和Urban-200数据集上,Long-CLIP在长文本图像检索任务中的召回率分别提高了25%和6%。
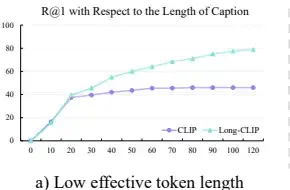
- 短文本图像检索:在COCO2017的5k验证集和Flickr30k的整个30k数据集上,Long-CLIP在短文本图像检索任务中的R@1分别提高了6%和7%。
- 零样本图像分类:在五个验证集上,Long-CLIP的零样本分类准确率没有显著下降。
- 图像生成:Long-CLIP在Stable Diffusion模型中替换CLIP文本编码器后,能够无缝集成并增强长文本生成能力。

总体结论
这篇论文提出了Long-CLIP,一种具有长文本能力的强大且灵活的CLIP模型。Long-CLIP支持长达248个标记的文本输入,并在检索任务中显著提高了性能。此外,Long-CLIP保持了零样本分类的性能,并可以在图像生成任务中以插件方式替换CLIP编码器。尽管存在输入标记长度的上限,但通过大量数据的利用,模型的扩展潜力巨大。
优点与创新
- 长文本输入支持:Long-CLIP通过知识保留的位置嵌入拉伸和主要成分匹配策略,实现了对长文本输入的支持,显著提高了长文本图像检索和传统文本图像检索任务的性能。
- 零样本泛化能力:Long-CLIP在保持CLIP的零样本泛化能力的同时,扩展了其输入长度,显示出其在各种基准测试中的优越性。
- 无缝替换CLIP:Long-CLIP与CLIP的潜在空间对齐,使得在不进行任何下游框架进一步适应的情况下,可以轻松替换CLIP。
- 高效微调:通过仅使用额外的一百万对长文本-图像对进行0.25小时的8 GPUs训练,Long-CLIP实现了高效的微调。
- 增强的图像生成能力:Long-CLIP通过替换CLIP的文本编码器,以即插即用的方式提供了从详细文本描述生成图像的增强能力。
- 新的评估数据集:提出了用于评估长文本细粒度能力的Urban-200数据集,并进一步扩展到Urban-1k数据集。
#DriveDreamer4D
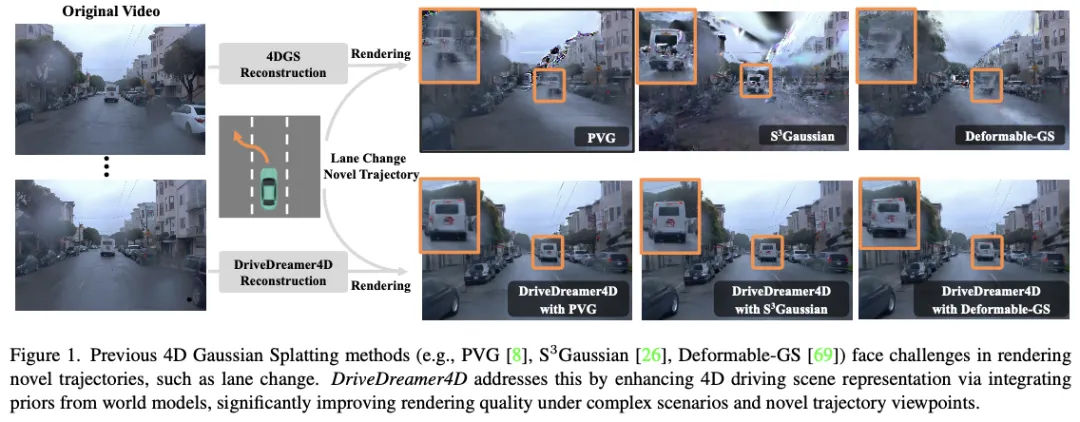
首个利用视频生成改善驾驶重建的世界模型方法
闭环仿真对于推进端到端自动驾驶系统至关重要。当代的传感器仿真方法,如NeRF和3DGS,主要依赖于与训练数据分布紧密一致的条件,这些条件在很大程度上局限于前向驾驶场景。因此,这些方法在渲染复杂的机动动作(如变道、加速、减速)时面临局限性。自动驾驶世界模型的最新进展已经证明了生成多样化驾驶视频的潜力。然而,这些方法仍然局限于2D视频生成,固有地缺乏捕捉动态驾驶环境复杂性所需的时空连贯性。本文介绍了DriveDreamer4D,它利用世界模型先验增强了4D驾驶场景表示。具体来说,我们利用世界模型作为数据机器,基于现实世界的驾驶数据合成新的轨迹视频。值得注意的是,我们明确地利用结构化条件来控制前景和背景元素的时空一致性,因此生成的数据与流量约束密切相关。据我们所知,DriveDreamer4D是第一个利用视频生成模型来改善驾驶场景中4D重建的工作。实验结果表明,DriveDreamer4D显著提高了新轨迹视图下的生成质量,与PVG、S3高斯和可变形GS相比,FID相对提高了24.5%、39.0%和10.5%。此外,DriveDreamer 4D显著增强了驱动代理的时空一致性,这得到了综合用户研究的验证,NTA-IoU度量的相对增加了20.3%、42.0%和13.7%。
总结来说,本文的主要贡献如下:
- 提出了DriveDreamer4D,这是第一个利用世界模型先验来推进自动驾驶4D场景重建的框架;
- NTGM旨在自动生成各种结构化条件,使DriveDreamer4D能够生成具有复杂机动的新颖轨迹视频。通过明确地结合结构化条件,DriveDreamer4D确保了前景和背景元素的时空一致性;
- 进行了全面的实验,以验证DriveDreamer4D显著提高了新轨迹视点的生成质量,以及驾驶场景元素的时空连贯性。
相关工作回顾驾驶场景表示
NeRF和3DGS已成为3D场景表示的主要方法。NeRF模型使用多层感知器(MLP)网络构建连续的体积场景,实现了具有卓越渲染质量的高度详细的场景重建。最近,3DGS引入了一种创新方法,通过在3D空间中定义一组各向异性高斯分布,利用自适应密度控制从稀疏点云输入中实现高质量的渲染。有几项工作将NeRF或3DGS扩展到了自动驾驶场景。鉴于驾驶环境的动态特性,在建模4D驾驶场景表示方面也做出了重大努力。一些方法将时间编码为参数化4D场景的额外输入,而另一些方法将场景表示为运动对象模型与静态背景模型的组合。尽管取得了这些进步,但基于NeRF和3DGS的方法仍面临着与输入数据密度相关的局限性。只有当传感器数据与训练数据分布非常匹配时,这些技术才能有效地渲染场景,而训练数据分布通常仅限于前方驾驶场景。
世界模型
世界模型模块根据参与者提出的想象动作序列预测未来可能的世界状态。通过自由文本动作控制的视频生成来仿真环境等方法。处于这一进化最前沿的是Sora,它利用先进的生成技术来生成尊重物理基本定律的复杂视觉序列。这种深入理解和仿真环境的能力不仅提高了视频生成质量,而且对现实世界的驾驶场景也有重大影响。自动驾驶世界模型采用预测方法来解释驾驶环境,从而生成现实的驾驶场景,并从视频数据中学习关键的驾驶要素和政策。尽管这些模型成功地生成了基于复杂驾驶动作的多样化驾驶视频数据,但它们仍然局限于2D输出,缺乏准确捕捉动态驾驶环境复杂性所需的时空一致性。
3D表示的扩散先验
从有限的观测中构建全面的3D场景需要生成先验,特别是对于看不见的区域。早期的研究将文本到图像扩散模型中的知识提炼成3D表示模型。具体而言,采用分数蒸馏采样(SDS)从文本提示合成3D对象。此外,为了增强3D一致性,有几种方法将多视图扩散模型和视频扩散模型扩展到3D场景生成。为了在复杂、动态、大规模的驾驶场景之前扩展扩散以进行3D重建,SGD、GGS和MagicDrive3D等方法采用生成模型来拓宽训练视角的范围。尽管如此,这些方法主要针对稀疏的图像数据或静态背景元素,缺乏充分捕捉4D驾驶环境中固有复杂性的能力。
DriveDreamer4D方法详解
整体架构
DriveDreamer4D的整体流程如图2所示。在上半部,提出了一种新的轨迹生成模块(NTGM),用于调整转向角和速度等原始轨迹动作,以生成新的轨迹。这些新颖的轨迹为提取3D盒子和HDMap细节等结构化信息提供了新的视角。随后,可控视频扩散模型从这些更新的视点合成视频,并结合与修改后的轨迹相关的特定先验。在下半部分,整合了原始和新颖的轨迹视频,以优化4DGS模型。在接下来的部分中,我们将深入研究新轨迹视频生成的细节,然后介绍使用视频扩散先验的4D重建。
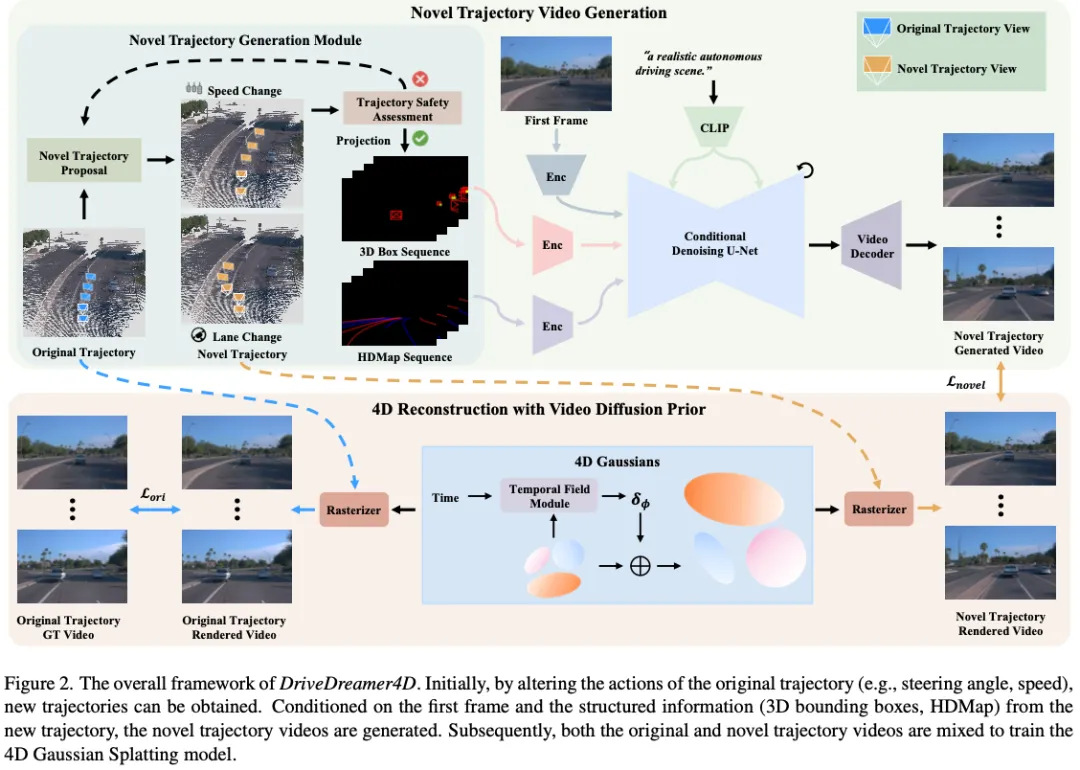
新轨迹视频生成
如前所述,传统的4DGS方法在渲染复杂机动动作方面存在局限性,这主要是由于训练数据主要由直接的驾驶场景主导。为了克服这一点,DriveDreamer4D利用世界模型先验来生成不同的视点数据,增强了4D场景表示。为了实现这一目标,我们提出了NTGM,该模型旨在创建新的轨迹作为世界模型的输入,从而能够自动生成复杂的机动数据。NTGM包括两个主要组成部分:(1)新的轨道方案,(2)轨道安全评估。在新的轨迹建议阶段,可以采用文本到轨迹来自动生成各种复杂的轨迹。此外,轨迹可以定制设计以满足特定要求,从而可以根据精确需求生成量身定制的数据。Algo 1中显示了定制设计的轨迹建议(例如变道)和轨迹安全评估的概述。在特定的驾驶场景中,世界坐标系中的原始轨迹可以很容易地获取为。为了提出新的轨迹,将原始轨迹转换为第一帧的自车辆坐标系,并计算如下:
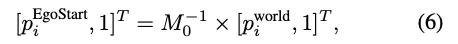

在自车辆坐标系中,车辆的航向与正x轴对齐,y轴指向车辆的左侧,z轴垂直向上,垂直于车辆平面。因此通过沿x轴和y轴调整值,可以分别表示车辆速度和方向的变化。对新生成的轨迹点进行最终安全评估,包括验证车辆轨迹p是否保持在可驾驶区域Broad内,并确保不会与行人或其他车辆发生碰撞。
一旦生成了符合交通规则的新轨迹,道路结构和3D边界框就可以从新轨迹的角度投影到相机视图上,从而生成与更新轨迹相关的结构化信息。这种结构化信息,连同初始帧和文本,被输入到世界模型中,以生成遵循新轨迹的视频。
基于视频扩散先验的4D重建
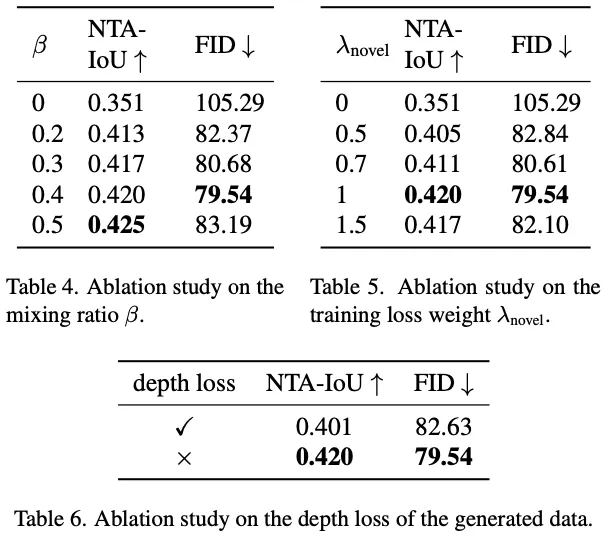
基于视频扩散先验,我们可以生成具有不同轨迹的新颖视频,增强跨不同基线的4D重建能力。具体来说,为了使用视频扩散先验训练4DGS,必须构建一个混合数据集Dhybrid,该数据集将原始轨迹数据集Dori与新的轨迹数据集Dnovel相结合。这些数据集之间的平衡可以通过超参数β进行调整,使我们能够控制原始和新轨迹的4DGS场景重建性能。这种关系被表述为Dhybrid。
使用生成的数据优化4DGS的损失函数Lnovel,定义如下:
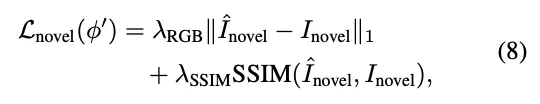
值得注意的是,在使用生成的数据集Dnovel时,深度图不作为4DGS优化的约束。限制源于LiDAR点云数据仅针对原始轨迹收集。当这些激光雷达点投影到新的轨迹上时,它无法为新的视角生成完整的深度图,因为新轨迹中可见的东西可能在原始视图中被遮挡了。因此,合并这样的深度图不利于4DGS模型的优化。混合训练的总体损失函数定义如下:
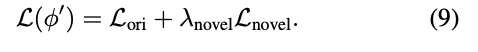
实验实验设置
数据集。我们使用Waymo数据集进行实验,该数据集以其全面的真实世界驾驶日志而闻名。然而,大多数日志捕捉的场景具有相对直接的动态,缺乏对密集、复杂的车辆交互场景的关注。为了解决这一差距,我们特别选择了八个以高度动态交互为特征的场景,其中包括许多具有不同相对位置和复杂驾驶轨迹的车辆。每个选定的片段包含大约40帧,片段ID在补充中有详细说明。
实施细节。为了证明DriveDreamer4D的多功能性和鲁棒性,我们将各种4DGS基线纳入我们的管道,包括可变形GS、S3Gaussian和PVG。为了进行公平的比较,LiDAR监控被引入到Deformable GS中。在训练过程中,场景被分割成多个片段,每个片段包含40帧,与生成模型的输出长度对齐。我们只使用前置摄像头数据,并将不同方法的分辨率标准化为640×960。我们的模型使用Adam优化器进行了50000次迭代训练,遵循用于3D高斯散斑的学习率计划。训练策略和超参数与每个基线的原始设置保持一致,每个模型训练了50000次迭代。
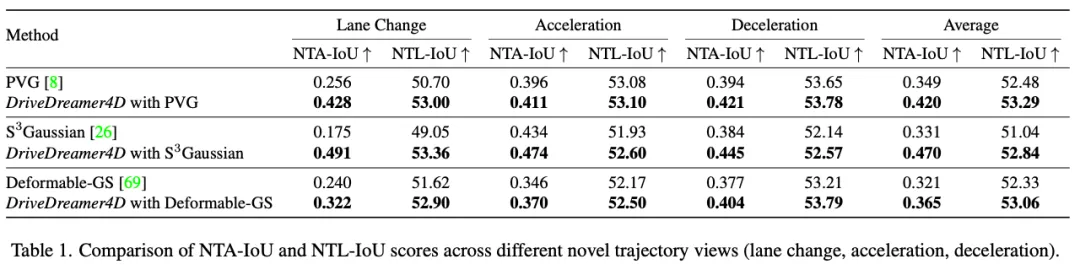
指标。传统的3D重建任务通常采用PSNR和SSIM指标进行评估,验证集与训练数据分布非常匹配(即,从视频序列中均匀采样帧进行验证,其余用于训练)。然而,在闭环驾驶仿真中,重点转移到评估新轨迹下的模型渲染性能,在这种轨迹下,相应的传感器数据不可用,使得PSNR和SSIM等指标不适用于评估。因此,我们提出了新的轨迹代理IoU(NTA-IoU)和新的轨迹车道IoU(NTL-IoU),它们评估了新轨迹视点中前景和背景交通分量的时空一致性。
对于NTA IoU,我们使用YOLO11在从新的轨迹视图渲染的图像中识别车辆,从而产生2D边界框。同时,对原始的3D边界框应用几何变换,将其投影到新的视点上以生成相应的2D边界框。对于每个投影的2D框,我们然后识别最接近的探测器生成的2D框并计算它们的交点(IoU)。为了确保精确匹配,引入了距离阈值dthresh:当最近检测到的框Bdet和正确投影的框Bproj之间的中心到中心距离超过此阈值时,它们的NTA IoU被分配为零值:
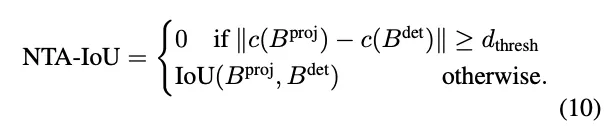
对于NTL IoU,我们使用TwinLiteNet从渲染图像中提取2D车道。地面真实车道也被投影到2D图像平面上。然后,我们计算渲染车道Ldet和GT车道Lproj之间的平均交点(mIoU):
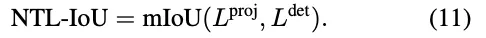
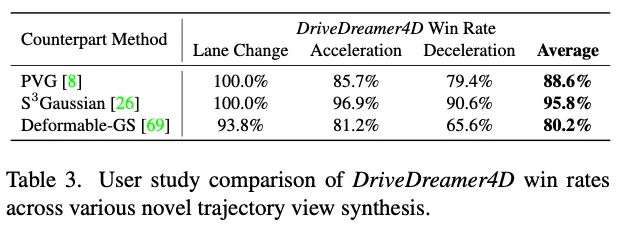
此外在变道场景中,我们观察到相对定位的不准确,以及飞行点和重影等伪影的频繁出现,这些伪影会显著降低图像质量。为了评估这一点,我们采用了FID度量,该度量量化了渲染的新轨迹图像和原始轨迹图像之间的特征分布差异。该指标有效地反映了视觉质量,对飞行点和重影等伪影特别敏感,为这些复杂场景中的图像保真度提供了强有力的衡量标准。最后,我们进行了一项用户研究来评估发电质量。具体来说,我们比较了每种基线方法及其DriveDreamer4D增强版本在三种不同的新轨迹上的视觉结果。评估标准侧重于整体视频质量,特别关注车辆等前景物体。对于每次比较,参与者被要求选择他们认为最有利的选项。


讨论和结论
在这篇论文中,我们提出了DriveDreamer4D,这是一个新的框架,旨在通过利用世界模型中的先验来推进4D驾驶场景表示。DriveDreamer4D利用世界模型生成新的轨迹视频,以补充现实世界的驾驶数据,解决了当前传感器仿真方法的关键局限性,即它们对前向驾驶训练数据分布的依赖性以及无法对复杂机动进行建模。通过明确采用结构化条件,我们的框架保持了前景和背景元素的时空一致性,确保生成的数据与现实世界交通场景的动态密切相关。我们的实验表明,DriveDreamer4D在生成各种仿真视角方面实现了卓越的质量,在场景组件的渲染保真度和时空一致性方面都有显著提高。值得注意的是,这些结果突出了DriveDreamer4D作为闭环仿真基础的潜力,闭环仿真需要动态驾驶场景的高保真重建。
#国内外高校具身智能实验室盘点(香港、新加坡篇)
1 香港(含内地与香港政府、科研机构联合实验室)
OpenDriveLab
------香港大学和上海人工智能实验室合作研究
导师:Yi Ma、Hongyang Li、Li Chen等人
研究方向:端到端自动驾驶、具身智能
OpenDriveLab 主要聚焦于机器人和自动驾驶领域。其研究方向包括但不限于:机器人操纵的闭环视觉运动控制,致力于通过反馈机制提升自适应机器人控制能力;自动驾驶的世界模型构建,追求高保真、通用且可控的模型;多智能体行为拓扑研究,用于交互式自动驾驶中的运动预测和规划;还有融合语言能力的自动驾驶研究等。
研究成果:
来源:https://arxiv.org/abs/2409.09016 , Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulation.
图 1 展示了 CLOVER 基于逆动力学模型(IDM)框架生成未来子目标以建立闭环策略。在背景干扰存在的情况下,行为克隆(BC)方法(如 ACT、RT - 1)无法抵抗视觉干扰,而 CLOVER 由于其闭环属性,表现出较强的鲁棒性。
来源:https://arxiv.org/pdf/2406.00439 , Learning Manipulation by Predicting Interaction.
图 1 展示了 MPI 这种面向交互的机器人操作表征学习管道。与基于(a)对比学习、(b)掩码信号建模或(c)使用随机帧的视频预测的现有技术不同,MPI 以关键帧为输入,指导模型预测过渡帧和检测被操作对象,从而促进对 "如何交互" 和 "在哪里交互" 的更好理解,在预训练中获取更具信息量的表征,并在下游任务中取得显著改进。
论文:
Closed-Loop Visuomotor Control with Generative Expectation for Robotic Manipulation , https://arxiv.org/abs/2409.09016
DriveLM: Driving with Graph Visual Question Answering , https://arxiv.org/abs/2312.14150
Planning-oriented Autonomous Driving , https://openaccess.thecvf.com/content/CVPR2023/html/Hu_Planning-Oriented_Autonomous_Driving_CVPR_2023_paper.html
Multimedia Lab (MMLab)
主页:http://mmlab.ie.cuhk.edu.hk/
导师:刘希慧等人(https://xh-liu.github.io/)
研究方向:计算机视觉、生成式模型、多模态人工智能、具身智能、AI for Science
来源:Empowering 3D Visual Grounding with Reasoning Capabilities , https://arxiv.org/pdf/2407.01525 .
图 1 展示了一个具身智能体在面对寻找舒适看电视地点的问题时的相关情况。对于具身智能体来说,它不仅需要理解 3D 环境和复杂的人类指令,还需要定位目标对象以进行交互和导航。图中对比了 GPT - 4(GPT - 4V)和作者提出的 ReGround3D 方法。GPT - 4(GPT - 4V)虽有很强的文本(多模态)推理能力,但缺乏直接感知 3D 场景、理解 3D 空间关系以及输出相应目标对象位置的能力。而作者提出的 ReGround3D 方法在真实的 3D 环境中具备 3D 感知、推理和定位能力。
来源:TC4D: Trajectory-Conditioned Text-to-4D Generation, https://arxiv.org/pdf/2403.17920 .
图 1 展示了使用轨迹条件 4D 生成(TC4D)方法生成的场景。这些场景由多个动态对象组成,是根据文本提示生成并合成在一起的。图中展示了不同的视点和时间步下的场景,其运动是通过沿给定轨迹对场景边界框进行刚性变换合成的,并利用视频扩散模型的监督来优化局部变形,从而提高了生成的 4D 场景中运动的数量和真实感。
来源:EgoPlan-Bench: Benchmarking Multimodal Large Language Models for Human-Level Planning , https://arxiv.org/abs/2312.06722 .
EgoPlan - Bench 评估规划能力,即模型像人类一样,将展示任务进展的视频、当前的视觉观察以及开放式任务目标作为输入,预测下一个可行的行动计划。相比之下,现有基准中基于以自我为中心的视频的问答示例主要评估理解能力,即模型基于对整个视频的空间和时间理解来回答问题。
论文:
DiM: Diffusion Mamba for Efficient High-Resolution Image Synthesis , https://www.arxiv.org/abs/2405.14224
4Diffusion: Multi-view Video Diffusion Model for 4D Generation , https://arxiv.org/abs/2405.20674
Divide and Conquer: Language Models can Plan and Self-Correct for Compositional Text-to-Image Generation , https://arxiv.org/abs/2401.15688
香港大学机械工程系机器人实验室
主页:https://www.mech.hku.hk/robotics
研究方向:软体机器人(如柔顺性可控制的软体机器人抓手/手部)、高性能柔性连续体机器人系统(用于介入式机器人和成像系统等,适用于微创手术、腔内内窥镜检查以及救援任务等)以及仿生机器人和执行器(从自然界获取灵感进行设计和制造,具有探索和与自然地形交互的能力)。
香港大学Hengshuang Zhao老师实验室
赵行爽老师是香港大学计算机科学系助理教授,研究方向包括计算机视觉(如场景理解、表征学习等)、生成式建模(涉及视觉内容创作、生成与操纵)、自动驾驶(涵盖环境感知、决策规划等环节)以及具身人工智能(包括机器人学习和 LLM 应用等)。
研究成果:
来源:https://depth-anything-v2.github.io/ , Depth Anything V2
来源:https://xavierchen34.github.io/LivePhoto-Page/ , LivePhoto: Real Image Animation with Text-guided Motion Control
来源:https://happinesslz.github.io/projects/LION/ .
LION 主要由几个 LION 模块组成,每个模块都配有一个用于特征增强的体素生成和一个用于沿高度维度下采样特征的体素合并。LION 模块包含用于长距离特征交互的 LION 层、用于捕获局部 3D 空间信息的 3D 空间特征描述符、用于特征下采样的体素合并以及用于特征上采样的体素扩展。
论文:
Zero-shot Image Editing with Reference Imitation , https://arxiv.org/abs/2406.07547
LARM: Large Auto-Regressive Model for Long-Horizon Embodied Intelligence , https://arxiv.org/pdf/2405.17424
Pixel-GS: Density Control with Pixel-aware Gradient for 3D Gaussian Splatting , https://arxiv.org/abs/2403.15530
香港大学Liwei Wang老师实验室:Language and Vision (LaVi) Lab
主页:https://lwwangcse.github.io/
Liwei Wang老师的研究方向集中在自然语言处理(NLP)和计算机视觉的交叉领域。具体包括语言与视觉的结合,探索如何让模型更好地理解和处理视觉与语言信息;大型语言模型相关研究,挖掘其在多模态场景下的应用潜力;多模态大模型的构建和优化;以及具身人工智能方面的研究,旨在使智能体在环境中更好地感知、理解和行动。
研究成果:
来源:https://arxiv.org/pdf/2312.02010 , Towards Learning a Generalist Model for Embodied Navigation.
先前方法学习特定任务的导航智能体,在域外视觉语言导航(VLN)成功率较低,面对未见过的任务(如问答和总结)时表现欠佳。而作者提出的 NaviLLM 不仅在具身导航所需的各种任务中表现出色,在未见过的任务上也展现出良好的泛化能力。图中不同颜色用于代表不同的示例,例如橙色代表来自域内 VLN 的示例。
来源:https://arxiv.org/pdf/2403.18252 , Beyond Embeddings: The Promise of Visual Table in Visual Reasoning.
文章提出视觉表(Visual Table)这一视觉表示形式,它由场景描述和多个对象描述构成,包含类别、属性和知识。研究通过收集小规模注释数据训练生成器创建视觉表,并在 11 个视觉推理基准上进行实验,结果表明视觉表优于以往的结构和文本表示形式,且能提升多模态大语言模型性能。
来源:https://aclanthology.org/2023.emnlp-main.570.pdf , Learning Preference Model for LLMs via Automatic Preference Data Generation.
文章提出通过自动偏好数据生成(AutoPM)学习大型语言模型(LLM)的偏好模型。AutoPM 包含广度数据生成和深度数据生成,通过遵循 HHH 标准从 LLM 中获取成对偏好数据,无需人工注释。
论文:
Multi-View Transformer for 3D Visual Grounding , S. Huang*, Y. Chen, J. Jia, L. Wang, CVPR 2022
Stratified Transformer for 3D Point Cloud Segmentation, X. Lai*, J. Liu, L. Jiang, L. Wang, H. Zhao, S. Liu, X. Qi, J. Jia, CVPR 2022
Voxel Field Fusion for 3D Object Detection, Y. Li*, X. Qi, Y. Chen, L. Wang, Z. Li, J. Sun, J. Jia, CVPR 2022
Probing Structured Pruning on Multilingual Pre-trained Models: Settings, Algorithms, and Efficiency, Y. Li*, F. Luo, R. Xu, S. Huang, F. Huang, L. Wang, ACL 2022
香港大学潘佳老师实验室
主页:https://cs.hku.hk/index.php/people/academic-staff/jpan
https://sites.google.com/site/panjia/
研究方向:智能算法、传感器和机器,以实现完全自主的机器人
研究成果:
来源:https://arxiv.org/pdf/2403.11186, NetTrack: Tracking Highly Dynamic Objects with a Net.
图 1 展示了 NetTrack 的可视化类似网,其通过细粒度网络解决传统跟踪方法因物体动态性导致内部关系扭曲的问题,还介绍了具有挑战性的 BFT 基准及相关场景。
来源:https://arxiv.org/pdf/2406.10093 , BiKC: Keypose-Conditioned Consistency Policy for Bimanual Robotic Manipulation.
图 1 展示了 BiKC 的工作流程,包含以关键姿态为条件的轨迹生成器和关键姿态预测器,关键姿态可以表示多阶段任务的各个阶段及子任务的完成情况。
来源:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=\&arnumber=10506641, Heterogeneous Targets Trapping With Swarm Robots by Using Adaptive Density-Based Interaction.
图 1 展示了使用自适应的单层或多层环形结构的群体机器人捕获多个包含弱、强和群体移动个体的异构目标的过程,体现了与单点捕获设置相对的群体机器人对异构目标的捕获方式。
论文:
- Hao Xu, Jia Pan*, HHD-GP: Incorporating Helmholtz-Hodge Decomposition into Gaussian Processes for Learning Dynamical Systems. In Neural Information Processing Systems (NeurIPS), 2024 Hao Xu, Ph.D. 2024
- Dongjie Yu, Hang Xu, Yizhou Chen, Yi Ren, Jia Pan*. BiKC: Keypose-Conditioned Consistency Policy for Bimanual Robotic Manipulation, in Workshop on Algorithmic Foundations of Robotics (WAFR), 2024
- Linhan Yang, Lei Yang, Haoran Sun, Zeqing Zhang, Haibin He, Fang Wan, Chaoyang Song, Jia Pan, in Workshop on Algorithmic Foundations of Robotics (WAFR), 2024 Linhan Yang, Ph.D. 2024
- Dawei Wang, Weizi Li, Lei Zhu, Jia Pan*. Learning to Control and Coordinate Mixed Traffic Through Robot Vehicles at Complex and Unsignalized Intersections. International Journal of Robotics Research (IJRR), to appear Dawei Wang, Ph.D. 2023
香港中文大学(CUHK)机器人与自动化研究中心
主页:https://www4.mae.cuhk.edu.hk/research/robotics-and-automation/
研究方向:设计和制造、能源 / 建筑 / 环境技术、智能系统、MEMS / 纳米 / 材料技术、机器人和自动化、系统和控制
该机构在机器人与自动化领域的研究方向包括:缆索驱动机器人、机器人的计算机视觉与图像处理、移动机器人的分布式控制、外骨骼与假肢、人类技能获取、工业机器人自动化、运动学与动力学、医疗机器人、微纳机器人、运动规划与优化、机器人设计与控制、传感器与执行器、传感器、控制与接口、服务与空间机器人、服务机器人、软体机器人、步行机器人设计与控制。
香港中文大学机器人与人工智能实验室
主页:https://rail.cuhk.edu.cn/zh-hans
香港中文大学机器人与人工智能实验室(Robotics & AI Lab)由国际知名机器人与人工智能专家徐扬生院士带领,在围绕着航天机器人、工业机器人、服务机器人、特种机器人、医疗机器人、智能汽车机器人等多个领域已经成功研制了30多个机器人和智能系统,研究成果世界领先且具有广阔的应用前景。
研究成果:
- 模块化自重构机器人:具备自适应性和自愈能力,可应对复杂环境任务。当前研究拟对非结构化场景下的关键技术进行研究,为群体机器人、野外作业机器人等发展奠定基础,可应用于抢险搜救、反恐侦察、太空探索等领域。
- 海洋机器人:涉及流体力学、自动控制、人工智能、计算机仿真、传感等技术,在多种技术的交叉与融合的基础上,海洋机器人真正实现了自主的、远程的控制。
- 书法机器人:采用示教学习方式,可帮助老年人学习书法,对中风病人有康复作用。
- 智能全方位混合动力车:是解决能源和污染问题的较好办法,开发的关键技术分三类:(1)智能能量管理和控制技术,用来在油耗、动力和污染排放三个指标中取得平衡 (2)四轮驱动和四轮转向的轮系控制系统,用来实现多方向运动 (3)集合了自动泊车、智能资讯平台和智能安全功能的智能电子系统
论文:
- Huifeng Guan, Yuan Gao, Min Zhao, Yong Yang, Fuqin Deng, Tin Lun Lam, "AB-Mapper: Attention and BicNet based Multi-agent Path Planning for Dynamic Environment," Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, October 23-27, 2022. (Accepted)
- Jingtao Tang, Yuan Gao, Tin Lun Lam, "Learning to Coordinate for a Worker-Station Heterogeneous Multi-robot System in Planar Coverage Task," Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, October 23-27, 2022. (Accepted)
- Chongxi Meng, Tianwei Zhang, Tin Lun Lam, "Fast and Comfortable Interactive Robot-to-Human Object Handover," Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, October 23-27, 2022. (Accepted)
深圳市人工智能与机器人研究院
简介:深圳市人工智能与机器人研究院(Shenzhen Institute of Artificial Intelligence and Robotics for Society,简称AIRS)是深圳市政府依托香港中文大学(深圳),联合多个世界顶级研究机构建立的十大基础研究机构之一。AIRS致力于研究多种应用场景的机器人,研究方向包括群体智能、特种机器人、智能机器人、医疗机器人、智能控制、微纳机器人、具身智能、通用机器人、多智能体协作、软体机器人等。
导师:徐扬生、丁宁、黄建伟、韩龙、Takeo Kanade、黄铠等人
研究成果:
图注:来源:Snail-inspired robotic swarms: a hybrid connector drives collective adaptation in unstructured outdoor environments, https://www.nature.com/articles/s41467-024-47788-2
图注:来源:PepperPose: Full-Body Pose Estimation with a Companion Robot, https://dl.acm.org/doi/full/10.1145/3613904.3642231
图注:来源:A magnetic multi-layer soft robot for on-demand targeted adhesion, https://www.nature.com/articles/s41467-024-44995-9
论文:
- Snail-inspired robotic swarms: a hybrid connector drives collective adaptation in unstructured outdoor environments, https://www.nature.com/articles/s41467-024-47788-2
- PepperPose: Full-Body Pose Estimation with a Companion Robot, https://dl.acm.org/doi/full/10.1145/3613904.3642231
- A magnetic multi-layer soft robot for on-demand targeted adhesion, https://www.nature.com/articles/s41467-024-44995-9
- Federated Learning While Providing Model as a Service: Jointly Training and Inference Optimization, https://arxiv.org/pdf/2312.12863
香港科技大学(广州)Precognition Lab
主页:https://precognition.team/#bio
导师:Prof. Junwei Liang等人
智能感知与预测实验室(Precognition Lab),致力于构建人类水平的具身人工智能系统,这些系统能够有效地感知、推理并与现实世界进行交互,从而造福人类。
研究成果:
来源:https://zeying-gong.github.io/projects/falcon/ , From Cognition to Precognition: A Future-Aware Framework for Social Navigation
来源:https://jiaming-zhou.github.io/projects/HumanRobotAlign/ , Mitigating the Human-Robot Domain Discrepancy in Visual Pre-training for Robotic Manipulation.
来源:https://www.youtube.com/watch?v=xE6M6WKw-0k , Open-vocabulary Mobile Manipulation in Unseen Dynamic Environments with 3D Semantic Maps
论文:
Contrastive Imitation Learning for Language-guided Multi-Task Robotic Manipulation , https://arxiv.org/pdf/2406.09738
Prioritized Semantic Learning for Zero-shot Instance Navigation , https://arxiv.org/pdf/2403.11650
Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models , https://arxiv.org/pdf/2407.13642.pdf
香港科技大学Cheng Kar-Shun Robotics Institute (CKSRI)
导师:張福民、李澤湘、沈劭劼、施凌、楊瓞仁、馮雁等人
香港科技大学的郑家纯机器人研究院(CKSRI)是一个多学科平台。其研究方向包括自主飞行(如无人机技术)、海洋机器人、智能建造、智能制造、人形机器人、视觉智能、机器人操作、柔性电子、软体机器人、智能传感器、微型机器人系统以及自动驾驶等多个领域。
研究成果:
无人机起源于军事,现应用广泛。大疆由汪滔在港科大宿舍创立,在李泽湘教授培育下发展,其研究成果使无人机可应对复杂地形,公司发展良好且支持港科大研究。
施柏荣教授与德国法兰克福高等研究院的特里施教授团队合作开发了主动高效编码(AEC)框架。该框架结合多学科知识,解释了动物和人类在婴儿期共同发展的感知和行为机制,其受神经启发的设计可使机器人更具适应性和自主性,在医学和工业等领域有广泛应用。
香港科技大学在无人机技术方面处于全球领先。电子与计算机工程系的沈劭劼教授是推动者之一。他因港科大与行业联系紧密而回校,他致力于让无人机摆脱 GPS 控制,使其能感知环境并智能应对飞行任务中的情况,而市场上的无人机仍需人保障空中安全。
论文:
- An Efficient Spatial-Temporal Trajectory Planner for Autonomous Vehicles in Unstructured Environments , IEEE Transactions on Intelligent Transportation Systems, v. 25, (2), February 2024, article number 10285583, p. 1797-1814. Han, Zhichao; Wu, Yuwei; Li, Tong; Zhang, Lu; Pei, Liuao; Xu, Long; Li, Chengyang; Ma, Changjia; Xu, Chao; Shen, Shaojie; Gao, Fei
- D(2)SLAM: decentralized and distributed collaborative visual-inertial SLAM system for aerial swarm , IEEE Transactions on Robotics, v. 40, July 2024, article number 10582478, p. 1-20
Xu, Hao; Liu, Peize; Chen, Xinyi; Shen, Shaojie. - FM-Fusion: Instance-Aware Semantic Mapping Boosted by Vision-Language Foundation Models , IEEE Robotics and Automation Letters, v. 9, (3), March 2024, article number 10403989, p. 2232-2239. Liu, Chuhao; Wang, Ke; Shi, Jieqi; Qiao, Zhijian; Shen, Shaojie
香港科技大学机器人研究所
主页:https://seng.hkust.edu.hk/zh-hans/node/7013
研究方向:移动机器人、无人机、智能制造、机器人感知与控制、医疗机器人等
下分实验室:
- 郑家纯机械人研究所 (CKSRI)
- 香港科技大学-Bright Dream Robotics 联合研究院
- 香港科技大学协同创新中心
- 香港科技大学-DJI 联合创新实验室
- 香港科技大学-生产力局工业人工智能及机械人技术联合实验室
- 香港科技大学-华为联合实验室
- 香港科技大学-小一机器学习与认知推理联合实验室
- 香港建筑机械人研究中心
- 智能自动驾驶中心 (IADC)
香港科技大学Jun MA老师实验室
主页:https://facultyprofiles.hkust-gz.edu.cn/faculty-personal-page/MA-Jun/eejma
研究方向:机器人学,自动驾驶,运动规划与控制,优化,强化学习
研究成果:
来源:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=\&arnumber=10510603 , Improved Consensus ADMM for Cooperative Motion Planning of Large-Scale Connected Autonomous Vehicles with Limited Communication
来源:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=\&arnumber=10417140 , Geometry-Aware Safety-Critical Local Reactive Controller for Robot Navigation in Unknown and Cluttered Environments
论文:
Cooperative autonomous driving in urban traffic scenarios by parallel optimization enforcing hard safety constraints, 2024 IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13-17 May 2024
Alternating Direction Method of Multipliers-Based Parallel Optimization for Multi-Agent Collision-Free Model Predictive Control , https://ieeexplore.ieee.org/document/10431550
Learning-Based High-Precision Tracking Control: Development, Synthesis, and Verification on Spiral Scanning With a Flexure-Based Nanopositioner , https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10443724
香港科技大学范明明老师实验室
主页:https://www.mingmingfan.com/
范明明,香港科技大学(广州)信息枢纽计算媒体与艺术学域与物联网学域助理教授、博士生导师、无障碍人机交互(APEX)课题组创始人。研究领域为人机交互,方向包括:1)智能无障碍与"适老化"交互技术设计;2)人智协同;3)虚拟与增强现实的交互技术与应用。
研究成果:
来源:FetchAid: Making Parcel Lockers More Accessible to Blind and Low Vision People With Deep-learning Enhanced Touchscreen Guidance, Error-Recovery Mechanism, and AR-based Search Support. https://arxiv.org/abs/2402.15723
来源:https://dl.acm.org/doi/pdf/10.1145/3613904.3642546 , Designing Unobtrusive Modulated Electrotactile Feedback on Fingertip Edge to Assist Blind and Low Vision (BLV) People in Comprehending Charts.
论文:
Toward Facilitating Search in VR With the Assistance of Vision Large Language Models , Chao Liu, Clarence Chi San Cheung, Mingqing Xu, Zhongyue Zhang, Mingyang Su, Mingming Fan*. https://www.mingmingfan.com/papers/VRST24_VR_Search_Framework.pdf
Investigating Size Congruency Between the Visual Perception of a VR Object and the Haptic Perception of Its Physical World Agent , Wenqi Zheng, Dawei Xiong, Cekai Weng, Jiajun Jiang, Junwei Li, Jinni Zhou, Mingming Fan*. https://www.mingmingfan.com/papers/VINCI24_VR_Size_Congruency.pdf
Designing Unobtrusive Modulated Electrotactile Feedback on Fingertip Edge to Assist Blind and Low Vision (BLV) People in Comprehending Charts. Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI '24), May 11--16, 2024, Honolulu, HI, USA.
香港城市大学机器人与自动化研究中心
主页:https://www.cityu.edu.hk/cra/
研究方向:医疗机器人(如手术机器人、机器人视觉、细胞手术机器人、电磁机器人系统)、人机交互(如抓取新物体的众包、社交机器人、基于云的个人机器人系统、基于视觉的传感技术、服务机器人)、微 / 纳 / 生物机器人(如机器人辅助的微 / 纳操作、光致电动力学、纳米医学、微飞行机器人)以及智能自动化(如多机器人系统、机器学习、人工智能机器人)。
研究项目:
香港理工大学机器人与机械智能实验室-The Robotics and Machine Intelligence (ROMI) Laboratory
导师:Dr David Navarro-Alarcon
研究方向:基于传感器的规划 / 控制、智能机器人运动、长期任务、医疗和手术机器人、自主操作、集体灵巧性、任务划分、编队与共识、理论基础、多机器人系统、软物体操作、视觉形状伺服、形态模型、潜在形状表示、反馈形状控制、多模态传感器融合、人机接口、医疗机器人感知、计算传感器模型、机器人感知。
2 新加坡
NUS AI LAB
主页:https://nusail.comp.nus.edu.sg/
NUS AI Lab 隶属于新加坡国立大学,研究方向几乎涵盖 AI 的所有领域,包括建模与表示、推理与规划、机器学习与数据科学、计算机视觉和自然语言处理以及学习理论。具体涉及具身 AI(如移动机器人、自动驾驶车辆等领域)、交互式 AI(开发用于改善人机交互的方法和系统)以及可信 AI(考虑 AI 系统部署的伦理、法律和社会影响)。
研究成果:
来源:https://nusail.comp.nus.edu.sg/intelligent-systems-in-balance-sheet-forecasting/
图注:交互式人工智能:从粗到精的动物姿态和形状估计:大多数现有的动物姿态和形状估计方法使用参数化的 SMAL 模型重建动物网格。然而,SMAL 模型是从姿态和形状变化有限的玩具动物扫描中学习得到的,因此可能无法很好地表示变化很大的真实动物。为了缓解这个问题,我们提出了一种从粗到精的方法,从单张图像中重建 3D 动物网格。
来源:https://nusail.comp.nus.edu.sg/occupational-impact-of-ai/
图注:多模态鲁棒强化学习:此工作专注于使用多个可能不可靠的传感器学习有用且鲁棒的深度世界模型。发现当前方法不能充分鼓励模态间的共享表示,会导致下游任务表现不佳以及对特定传感器过度依赖。提出了一种新的多模态深度潜在状态空间模型,使用互信息下限进行训练,关键创新是一种专门设计的密度比估计器,鼓励每种模态的潜在代码之间的一致性。该方法在多模态 Natural MuJoCo 基准和具有挑战性的擦桌子任务中以自我监督的方式学习策略,实验表明该方法显著优于现有的深度强化学习方法,特别是在存在缺失观测的情况下。
论文:
- Coarse-to-fine Animal Pose and Shape Estimation , https://arxiv.org/pdf/2111.08176
- Self-supervised 3D hand pose estimation through training by fitting, https://openaccess.thecvf.com/content_CVPR_2019/papers/Wan_Self-Supervised_3D_Hand_Pose_Estimation_Through_Training_by_Fitting_CVPR_2019_paper.pdf#:\~:text=Abstract. We present a self-supervision method for 3D hand pose
- Towards Effective Tactile Identification of Textures using a Hybrid Touch Approach, Tasbolat Taunyazov, Hui Fang Koh, Yan Wu, Caixia Cai and Harold Soh, IEEE International Conference on Robotics and Automation (ICRA), 2019
Advanced Robotics Centre - NUS
Advanced Robotics Centre 是新加坡国立大学下属的一个机构,研究方向涵盖多个方面,包括:(1)智能抓取技术相关:有关于软机器人智能抓取器(Smart Grippers for Soft Robotics - SGSR)的项目研究。例如举办相关的研讨会,探讨液体堵塞抓取器(Liquid Jamming Gripper)的设计、建模和模拟等内容。(2)机器人技术的发展历程及应用场景研究:有相关研讨会阐述机器人如何从工业制造技术发展到当前的服务机器人,以及从仿生组件和仿生系统的基础研究到当前机器人伴侣和工业 5.0 的场景。
研究成果:
论文:
Model-based reinforcement learning for closed-loop dynamic control of soft robotic manipulators , TG Thuruthel, E Falotico, F Renda, C Laschi. IEEE Transactions on Robotics 35 (1), 124-134.
Synteraction Lab
导师:Shengdong Zhao
交互实验室由Shengdong Zhao博士于 2009 年成立,现已发展成为亚洲及世界上最活跃的人机交互研究中心之一。它在开发新的界面工具和应用方面有经验,并定期在顶级人机交互会议和期刊上发表文章。该实验室的愿景是抬头计算,旨在通过可穿戴平台和多模式交互方法改变我们与技术交互的方式。
研究成果:
来源:PANDALens: Towards AI-Assisted In-Context Writing on OHMD During Travels, https://synteraction.org/assets/files/Cai, R et al. - 2024 - PANDALens Towards AI-Assisted In-Context Writing on OHMD.pdf
来源:GPTVoiceTasker: LLM-Powered Virtual Assistant for Smartphone, https://synteraction.org/assets/files/Vu et al. - 2024 - GPTVoiceTasker LLM-Powered Virtual Assistant for Smartphone.pdf
来源:VidAdapter: Adapting Blackboard-Style Videos for Ubiquitous Viewing, https://synteraction.org/assets/files/Ram-2023-VidAdapter-Adapting-Blackboard-Style-Videos-for-Ubiquitous-Viewing_compressed.pdf
论文:
What's this? Understanding User Interaction Behaviour with Multimodal Input Information Retrieval System. Silang Wang, Hyeongcheol Kim, Nuwan Janaka, Kun Yue, Hoang-Long Nguyen, Shengdong Zhao, Haiming Liu, Khanh-Duy Le. Keywords: Information Retrieval, Multimodal Interaction, User Search Behaviour, Heads-up Computing
Navigating Real-World Challenges: A Quadruped Robot Guiding System for Visually Impaired People in Diverse Environments. Shaojun Cai, Ashwin Ram, Zhengtai Gou, Mohd Alqama Wasim Shaikh, Yu-An Chen, Yingjia Wan, Kotaro Hara, Shengdong Zhao, David Hsu. Keywords: visual impairment, orientation and mobility, assistive technology, navigation, robot guide dog
Heads-Up Multitasker: Simulating Attention Switching On Optical Head-Mounted Displays. Yunpeng Bai, Aleksi Ikkala, Antti Oulasvirta, Shengdong Zhao, Lucia J. Wang, Pengzhi Yang, Peisen Xu. Keywords: multitasking, heads-up computing, computational rationality, deep reinforcement learning, bounded optimal control
Microsystem Engineering and Robotics
主页:https://guppy.mpe.nus.edu.sg/peter_chen/
导师:**Peter C. Y. Chen**
Peter C.Y.Chen的实验室,从事微系统和机器人技术的研究与开发。研究重点是对从微观到宏观尺度的物理和生物系统进行机械操作,以产生实用的工程解决方案。他们积极寻求合作,并欢迎对微系统工程和机器人技术感兴趣的学生。
研究成果:
论文:
- Du, Herath, Wang, Wang, Asada, and Chen, Three-dimensional characterization of mechanical interactions between endothelial cells and extracellular matrix during angiogenic sprouting. Scientific Reports, 2016.
- Herath, Du, Shi, Kim, Wang, Wang, Van Vliet, Asada, and Chen, Quantification of magnetically induced changes in ECM local apparent stiffness. Biophysical Journal, 2014.
- Zhou, Chen, and Ong, Force control of a cellular tensegrity structure with model uncertainties and partial state measurability. Asian Journal of Control, 2014.
- Herath, Du, Wang, Wang, Liao, Asada, and Chen, Characterization of uniaxial stiffness of extracellular matrix embedded with magnetic beads via bio-conjugation and under the influence of an external magnetic field. Journal of the Mechanical Behavior of Biomedical Materials, 2014.
Multimodal AI and Robotic Systems (MARS) Lab
导师:Dr. Jianfei Yang
南洋理工大学的多模态人工智能与机器人系统(MARS)实验室研究物理人工智能,重点关注人工智能如何使机器人、物联网和工业系统等物理系统感知、理解并与物理世界交互,涉及多模态感知、具身人工智能、AIoT 系统等多个方面。
研究成果:
来源:Diffusion Model is a Good Pose Estimator from 3D RF-Vision, https://arxiv.org/pdf/2403.16198 .
图 1 主要展示了毫米波雷达点云(mmWave PCs)在人体姿态估计(HPE)中的相关情况。左侧毫米波雷达点云稀疏且分散,导致生成的样条和肩部不准确。右侧对比了现有 SOTA 方法(P4Transformer)和本文提出方法(mmDiff)的性能:现有 SOTA 方法的预测结果存在姿态振动和严重漂移,性能不理想。本文提出的 mmDiff 方法基于扩散模型进行姿态估计,具有更高的准确性和稳定性,图中以黑色表示真实值(GTs),彩色表示预测值。
来源:Reliable Spatial-Temporal Voxels For Multi-Modal Test-Time Adaptation , https://arxiv.org/abs/2403.06461 .
多模态测试时间适应(MM - TTA)旨在通过利用多模态输入来使模型适应无标签目标域。现有方法在进行 3D 分割的 MM - TTA 时,依赖于每个输入帧中跨模态信息的预测,忽略了连续帧内几何邻域的预测是高度相关的这一事实,导致跨时间的预测不稳定。本文提出了 Latte 方法来解决这些问题:首先,给定连续帧的合并输入(例如点云帧和其估计的姿态),通过一种滑动窗口的方式聚合连续帧,并将同一体素内的点视为时空对应关系。然后构建空间 - 时间(ST)体素,通过这种方式来捕获每个模态在时间上局部的预测一致性。
论文:
Diffusion Model is a Good Pose Estimator from 3D RF-Vision, https://arxiv.org/pdf/2403.16198
Reliable Spatial-Temporal Voxels For Multi-Modal Test-Time Adaptation , https://arxiv.org/abs/2403.06461
MoPA: Multi-Modal Prior Aided Domain Adaptation for 3D Semantic Segmentation , https://arxiv.org/pdf/2309.11839****
Perception and Embodied Intelligence (PINE) Lab
主页:https://pine-lab-ntu.github.io/team.html
导师:Ziwei Wang
Pine Lab位于南洋理工大学。其主要研究方向包括:1. 具身指令跟随,旨在使智能系统在未知环境中理解并执行人类指令,通过多模态感官融合等方法,其系统能在大型房屋级场景完成204项复杂人类指令;2. 通用机器人操作的生成式模型,目标是为日常机器人操作任务构建生成式基础模型,借鉴相关经验,其机器人可完成多种操作任务且泛化能力高;3. 通用机器人包装系统,为解决包装系统面临的挑战,开发了相关框架和管道,其系统能包装12类日常物品,成功率86.7%;4. 基础模型压缩,解决在机器人上部署大型基础模型受计算资源限制的问题,提出相关技术、框架和引擎,可在特定硬件中部署用于多种任务;5. 实时在线3D场景感知,建立通用框架实现实时高效场景感知,将离线模型转换为在线模型,构建的相关模型能处理视频并输出实时3D重建和分割结果,在一些数据集上性能领先。
研究成果:
来源:Towards Accurate Data-free Quantization for Diffusion Models , https://pine-lab-ntu.github.io/data/APQ-DM.pdf.
文章提出了一种用于扩散模型的准确的训练后量化框架(APQ - DM)以实现高效的图像生成。
来源:Memory-based Adapters for Online 3D Scene Perception , https://pine-lab-ntu.github.io/data/Onine-3D.pdf .
文章提出一种用于在线 3D 场景感知的新框架,通过基于记忆的适配器赋予现有离线模型在线感知能力。图1展示了所提出的在线 3D 场景感知的通用框架,体现了该框架在不同 3D 场景感知任务(如语义分割、目标检测和实例分割)中的应用价值,这些任务对于机器人应用很重要。
论文:
3D Small Object Detection with Dynamic Spatial Pruning , Xiuwei Xu*, Zhihao Sun*, Ziwei Wang , Hongmin Liu, Jie Zhou, Jiwen Lu , European Conference on Computer Vision ( ECCV ), 2024.
ManiGaussian: Dynamic Gaussian Splatting for Multi-task Robotic Manipulation , Guanxing Lu, Shiyi Zhang, Ziwei Wang , Changliu Liu, Jiwen Lu, Yansong Tang , European Conference on Computer Vision ( ECCV ), 2024.
StableLego: Stability Analysis of Block Stacking Assembly , Liu, Kangle Deng, Ziwei Wang , Changliu Liu , IEEE Robotics and Automation Letters ( RAL ) , 2024.
S-Lab for Advanced Intelligence
主页:https://www.ntu.edu.sg/s-lab
S-Lab for Advanced Intelligence 是南洋理工大学 2020 年成立的实验室。其研究方向包括计算机视觉、自然语言处理、强化学习、深度学习和分布式计算等前沿 AI 技术。具体涉及深度学习中的内容编辑和生成、分布式学习、超分辨率、图像和视频理解、媒体取证、自然语言处理以及 3D 场景理解等。
研究成果:
来源:Exploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer , https://arxiv.org/pdf/2208.05216 .
本文提出了用于 3D 点云目标跟踪的方法,包括 PTTR 和 PTTR++。图 1(a)展示了 3D 点云的鸟瞰图(BEV)的优势,以及模板点和搜索区域点的关系。图 1(b)呈现了 PTTR 和 PTTR++ 的结构,PTTR++ 在 PTTR 基础上增加了 BEV 特征匹配,以利用两种表示的互补信息提高跟踪性能。
来源:GAO et al.: UNISCHED: A UNIFIED SCHEDULER FOR DLT JOBS WITH DIFFERENT USER DEMANDS. https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=\&arnumber=10454114 .
图 2 展示了 UniSched 的工作流程,它由 Estimator 和 Selector 两个组件构成。Estimator 用于预测作业时长,Selector 用于作业选择和资源分配,每个作业都经历 profiling 和 execution 两个阶段。
论文:
- Unified 3D and 4D Panoptic Segmentation via Dynamic Shifting Network
F. Hong, L. Kong, H. Zhou, X. Zhu, H. Li, Z. Liu
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI) - Flare7K++: Mixing Synthetic and Real Datasets for Nighttime Flare Removal and Beyond
Y. Dai, C. Li, S. Zhou, R. Feng, Y. Luo, C. C. Loy
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI) - TOPIQ: A Top-down Approach from Semantics to Distortions for Image Quality Assessment
C. Chen, J. Mo, J. Hou, H. Wu, L. Liao, W. Sun, Q. Yan, W. Lin
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI)
MMLab@NTU
MMLab@NTU 主要研究方向包括低级别视觉、图像和视频理解、创意内容创作、3D 场景理解与重建等。涉及超分辨率、内容编辑与创作、图像和视频理解、3D 生成式 AI、深度学习、媒体取证等多个领域。
研究成果:
来源:Gaussian3Diff: 3D Gaussian Diffusion for 3D Full Head Synthesis and Editing, https://arxiv.org/abs/2312.03763 .
图1展示了GAUSSIAN3DIFF的核心特点,它采用3D Gaussians(定义在UV空间)作为3D表示基础,这种表示支持高质量的新视角合成、基于3DMM的动画以及用于无条件生成的3D扩散。
来源:StyleGANEX: StyleGAN-Based Manipulation Beyond Cropped Aligned Faces , https://arxiv.org/pdf/2303.06146 .
图 1 展示了 StyleGANEX 在多种人脸操作任务上的应用,包括风格转换、面部属性编辑、超分辨率、从草图或遮罩生成人脸以及视频人脸卡通化等,体现了其突破 StyleGAN 对裁剪对齐人脸限制的能力。
论文:
- Efficient Diffusion Model for Image Restoration by Residual Shifting
Z. Yue, J. Wang, C. C. Loy
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI) - Talk-to-Edit: Fine-Grained 2D and 3D Facial Editing via Dialog
Y. Jiang, Z. Huang, T. Wu, X. Pan, C. C. Loy, Z. Liu
IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024 (TPAMI) - 4D Panoptic Scene Graph Generation
J. Yang, J. Cen, W. Peng, S. Liu, F. Hong, X. Li, K. Zhou, Q. Chen, Z. Liu
in Proceedings of Neural Information Processing Systems, 2023 (NeurIPS, Spotlight) - L4GM: Large 4D Gaussian Reconstruction Model
J. Ren, K. Xie, A. Mirzaei, H. Liang, X. Zeng, K. Kreis, Z. Liu, A. Torralba, S. Fidler, S. W. Kim, H. Ling
in Proceedings of Neural Information Processing Systems, 2024 (NeurIPS)
MReaL
主页:https://mreallab.github.io/index.html
MReaL Lab 致力于研究结合现代深度神经网络和传统符号操作的推理算法,研究方向包括多模态编辑、零样本模型优化、3D 内容生成、场景图生成等多个领域。
研究成果:
来源:https://github.com/SkyworkAI/Vitron , Vitron: A Unified Pixel-level Vision LLM for Understanding, Generating, Segmenting, Editing.
论文:
- Towards Unified Multimodal Editing with Enhanced Knowledge Collaboration
- Enhancing Zero-Shot Vision Models by Label-Free Prompt Distribution Learning and Bias Correcting
- Robust Fine-tuning of Zero-shot Models via Variance Reduction
- Unified Generative and Discriminative Training for Multi-modal Large Language Models
- Vitron: A Unified Pixel-level Vision LLM for Understanding, Generating, Segmenting, Editing
- MVGamba: Unify 3D Content Generation as State Space Sequence Modeling
Rapid-Rich Object Search Lab (ROSE)
主页:https://www.ntu.edu.sg/rose
该实验室的研究方向包括:利用深度学习等技术进行对象识别与检索,开发适用于移动设备的紧凑且创新的特征编码、可扩展索引和视觉搜索算法;利用传统及机器学习方法进行视频分析;以及针对图像和视频取证应用的生物识别技术,包括生物特征及软生物特征、人脸伪造与活体检测、反射去除等。
研究成果:
论文:
- Suppress and Rebalance: Towards Generalized Multi-Modal Face Anti-Spoofing
Xun Lin, Shuai Wang, Rizhao Cai, Yizhong Liu, Ying Fu, Zitong Yu, Wenzhong Tang, Alex Kot, The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024) - Flexible-Modal Deception Detection with Audio-Visual Adapter
Zhaoxu Li, Zitong Yu, Xun Lin, Nithish Muthuchamy Selvaraj, Xiaobao Guo, Bingquan Shen, Adams Wai-Kin Kong, Alex Kot, 2024 IEEE International Joint Conference on Biometrics (IJCB) - Semantic Deep Hiding for Robust Unlearnable Examples
Ruohan Meng, Chenyu Yi, Yi Yu, Siyuan Yang, Bingquan Shen, Alex C Kot, IEEE Transactions on Information Forensics and Security (TIFS)
#地平线提出DEMO
扩散和Occ双管齐下,打造超真实世界模型!
在任何一组东西中,最重要的只占其中一小部分,约20%,其余80%尽管是多数,却是次要的,这就是著名的"二八定律"。而自动驾驶发展至今,解决剩余20%的"重要的"长尾问题和极端案例一直是一件比较棘手的事情。即使是最先进的SOTA和最广泛的数据收集工作也难以解决。而解决这些挑战的一个有希望的方法在于世界模型。世界模型结合了历史上下文和其它智能体的行动来预测环境观察的未来演变。这允许自动驾驶模型更深入地预测未来,改进行动可行性的评估。
世界模型可以分为几种类型:包括基于2D视频的模型和基于3D表示的模型,比如利用LiDAR和占用框架的模型。前者基于视频的世界模型在维持跨视图和跨时间一致性方面会面临一些挑战,从而阻碍了它们在现实世界场景中的应用。而基于占用的世界模型避免了这个问题。这些模型以历史占用序列作为输入,并预测未来的占用观察,用原始的3D表示确保了内在的3D一致性。另外,占用标注相对容易获得,因为它们可以有效地从稀疏的LiDAR标注中学习,或者可能通过时间帧的自监督学习获得。基于占用的模型也是模态不确定的,表明它们可以从单目或环视相机生成,或者从LiDAR传感器生成。
现有的基于占用的世界模型可以分为两种类型:基于自回归的和基于扩散的:
基于自回归的方法以自回归的方式使用离散标记预测未来的占用。然而,由于这些方法依赖于离散标记器,量化过程导致信息丢失,限制了预测高保真占用的能力。此外,自回归方法难以生成真实的长时间占用序列。
基于扩散的方法将空间和时间信息展平为一维的标记序列,而不是单独处理它们,导致在有效捕获空间时间信息方面存在困难。因此,将历史占用信息整合到模型中变得困难,因为空间和时间数据被结合在一起。这种限制意味着模型可以生成输出,但不能预测,限制了其在现实世界场景中的适用性。此外,作者发现大多数占用世界模型对细粒度控制的探索不足,导致过度拟合特定场景,限制了它们对下游任务的适用性。
为了解决上述问题,作者提出了一种预测未来占用帧的新方法,称为DOME。具体来说,作者的方法包括两个组件:Occ-VAE和DOME。为了克服离散标记的限制,作者的Occ-VAE使用连续的潜在空间来压缩占用数据。这允许有效的压缩,同时保留高保真细节。作者世界模型展示了两个关键特征:
- 高保真度和长时生成。作者采用时空扩散变换器来预测未来的占用帧。通过利用上下文占用条件,作者将历史占用信息作为输入。时空架构有效地捕获了空间和时间信息,实现了精细细节,并能够生成长时预测(32秒)。
- 细粒度可控性。作者通过引入轨迹重采样方法来解决预测中的精确控制挑战,这显著提高了模型生成更精确和多样化占用预测的能力。
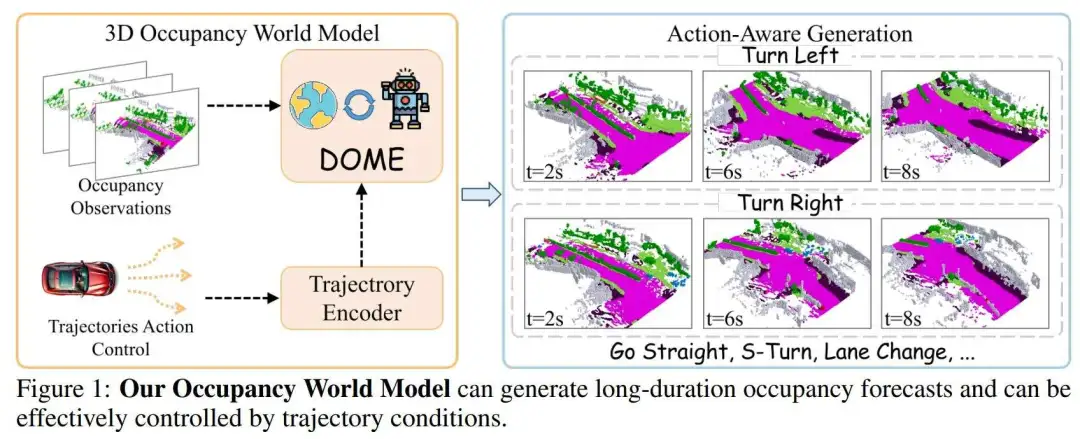
相关工作3D 占用预测
3D 占用预测任务涉及预测每个3D体素的占用状态和语义标签。最近的方法专注于基于视觉的占用预测,使用图像作为输入。这些方法可以根据它们的特征增强分为三种主流类型:鸟瞰图(BEV)、三视角图(TPV)和基于体素的方法。
基于BEV的方法在BEV空间中学习特征,对遮挡不太敏感。它首先使用主干网络提取2D图像特征,应用视点变换以获得BEV特征,最后使用3D占用头进行预测。然而,由于其自上而下的投影,BEV方法难以传达详细的3D信息。为了解决这个限制,基于TPV的方法利用三个正交投影平面,增强了描述细粒度3D结构的能力。这些方法同样提取2D图像特征,然后将它们提升到三个平面上,然后将投影的特征相加以形成3D空间表示。与这些基于投影的方法相对,基于体素的方法直接从原始3D空间学习,有效地捕获了全面的空间信息。这些方法从主干网络提取2D图像特征,并将它们转换为3D表示,然后由3D占用头处理以进行占用预测。
自动驾驶世界模型
世界模型是智能体周围环境的表示。给定智能体的行动和历史观察,它预测下一个观察,帮助智能体对其环境有一个全面的了解。最近的方法旨在通过整合不同的模态,如点云或3D占用,来扩展自动驾驶世界模型。基于LiDAR的世界模型预测4D LiDAR点云。Copilot4D是一种使用VQVAE和离散扩散来预测未来观察的世界建模方法。它在几个数据集上提高了50%以上的预测精度,展示了GPT类无监督学习在机器人技术的潜力。另一种方法是基于占用的世界模型,它通过3D占用预测未来场景。OccWorld是一个用于自动驾驶的3D世界模型,它使用3D占用预测自我车辆的运动和周围场景的演变。OccSora是一个基于扩散的模型,用于模拟自动驾驶中3D世界的演变。它使用4D场景标记器和DiT世界模型进行占用生成,辅助自动驾驶中的决策。
模型框架
作者介绍了DOME,一个基于扩散的占用世界模型。作者的方法由两个主要组件组成:Occ-VAE和DOME。为了使世界模型与轨迹条件对齐,作者提出了轨迹编码器和轨迹重采样技术,专门设计用于增强模型的可控性。
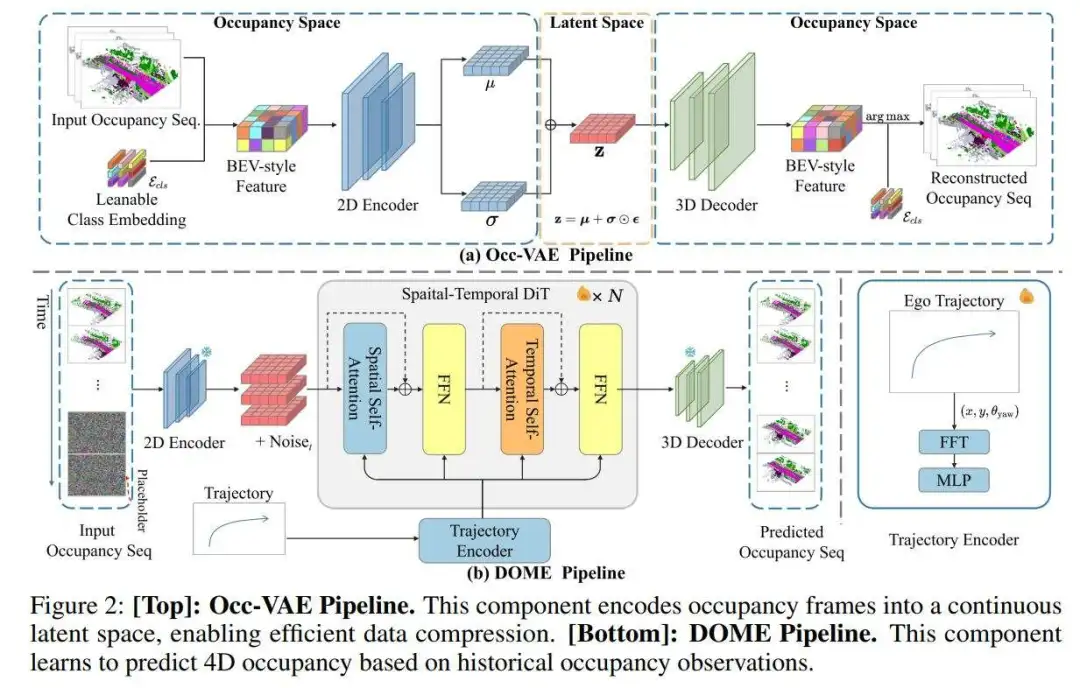
Occ-VAE
Occ-VAE是作者模型的核心组件,它使用变分自编码器(VAE)将占用数据压缩到潜在空间,这对于提高表示的紧凑性和世界模型预测的效率至关重要。注意到离散标记器通常无法保留占用帧的精细细节,作者提出将密集的占用数据编码到连续的潜在空间中,以更好地保留复杂的空间信息。如图2所示的提出的架构,细节如下:
占用数据:由于Occ-VAE专门设计用于占用数据,作者首先讨论这种3D场景表示。3D占用数据 将自我车辆周围的环境体素化为一个 体素网格,每个网格单元根据其所包含的物体分配语义标签。
编码器:受基于图像的VAE方法的启发,作者提出了一个特别为占用数据设计的连续VAE。为了处理由离散语义ID组成的3D占用数据 ,作者首先将其转换为鸟瞰图(BEV)风格的张量 ,通过索引一个可学习的类别嵌入 。这个过程将占用数据展平为一致的特征维度。随后,一个编码器网络 将转换后的数据编码为压缩表示。这个表示然后沿通道维度分割为 和 ,其中 和 表示编码数据的空间维度, 表示通道维度。编码后,连续潜在变量 使用重参数化技巧进行采样,遵循VAEs的方法:,其中 是从标准正态分布中采样的噪声向量, 表示逐元素乘法。
编码器包括2D卷积层和注意力块。类别嵌入 是随机初始化的,并与Occ-VAE一起训练。
解码器:解码器网络 负责从采样的潜在变量 重建输入占用。它使用3D反卷积层对潜在表示进行上采样,确保改善时间一致性。上采样的特征 然后重塑为 。通过与类别嵌入的点积计算逻辑分数 ,逻辑分数的arg max确定最终的类别预测。
训练损失:在Occ-VAE的训练中,作者的损失函数由两个组件组成:重建损失和KL散度损失,遵循标准的VAE框架。作者使用交叉熵损失作为重建损失。此外,为了解决预测中的类别不平衡问题,作者额外加入了Lovasz-softmax损失,这有助于缓解不平衡问题。总损失定义如下:
其中 和 分别是Lovasz-softmax损失和KL散度损失的损失权重。训练完成后,Occ-VAE模型被冻结,其编码器作为特征提取器用于DOME训练,其解码器从DOME重建潜在表示以生成占用数据。
DOME:基于扩散的占用世界模型
占用世界模型基于智能体的历史数据()预测未来的占用观察 ,其中 表示占用观察, 表示智能体的行动。为了实现这一点,作者采用了一个具有时间感知层的潜在扩散模型,使模型能够有效地从时间变化中学习。使用时间掩码整合历史占用观察,鼓励模型基于条件帧预测未来帧。此外,为了给世界模型提供增强的运动先验和可控性,作者的轨迹编码器整合了自我车辆的行动,允许精确的下一帧预测,由给定的摄像机姿态控制。具体来说,作者的模型以编码的潜在 和自我车辆的轨迹作为输入,其中 表示对应于4D占用数据中帧数的时间维度。潜在部分被掩码遮盖,只允许 帧()可见,模型被训练以预测剩余的掩码帧。
时空扩散变换器:为了预测具有时间感知的未来占用,作者采用了一个受基于视频方法启发的时空潜在扩散变换器。作者首先将潜在表示 分割为 帧的序列标记,每个序列包含 个标记,其中 表示patch大小。然后向空间和时间维度添加位置嵌入。如图2所示,作者的模型由两种基本类型的块组成:空间块和时间块。空间块捕获共享相同时间索引的帧之间的空间信息,而时间块在固定的空间索引处沿时间轴提取时间信息。这些块以交错的方式排列,有效地捕获空间和时间依赖性。
历史占用条件:为了使模型能够预测未来的占用特征,必须根据历史占用数据对生成进行条件化。这是通过条件掩码实现的。给定占用数据的多帧上下文和表示上下文帧数的超参数 ,从历史占用观察中编码潜在 。然后作者构建一个条件掩码 ,确保模型根据可用的上下文帧进行预测。在训练期间,噪声标记 根据条件掩码部分替换为上下文潜在,对于任何使用上下文帧的训练迭代:。
为了使模型能够在没有条件的情况下生成,作者应用了dropout机制,其中 的比例时间内,模型在没有上下文帧的情况下进行训练。
损失函数:作者将普通的扩散损失扩展为时空版本,使其与上下文占用条件兼容。由于作者预测一系列特征占用,总体损失是跨所有帧计算的。在上下文占用条件下, 噪声潜在被替换为真实值(如上所述),因此,这些帧的损失使用条件掩码 忽略。训练扩散模型的损失函数定义如下:
其中 是第 个扩散时间戳的第 帧, 是去噪网络,特别是作者的DOME模型。
轨迹作为条件
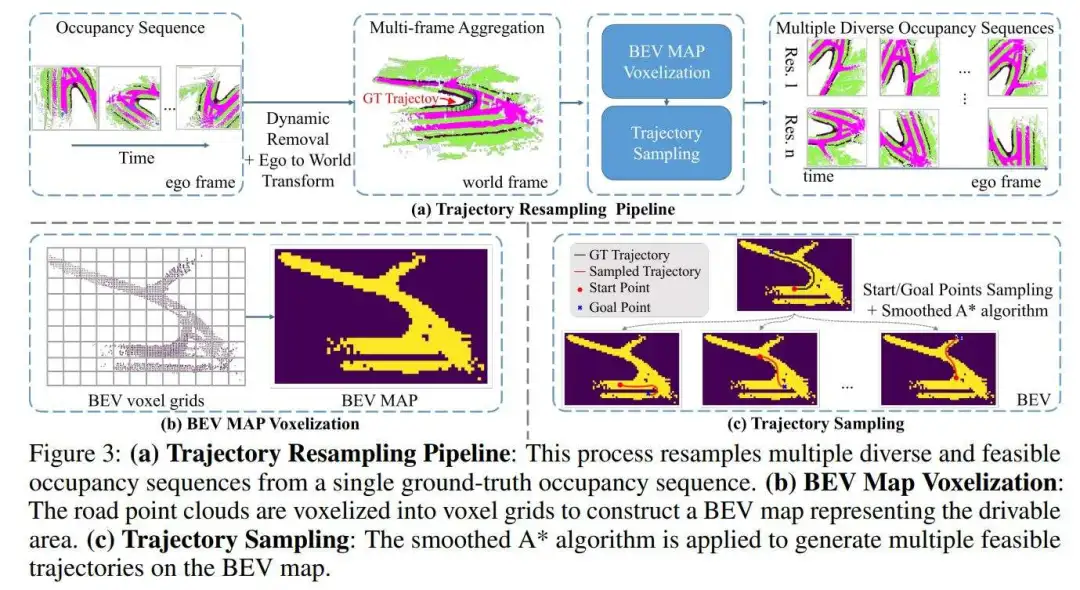
轨迹条件注入:对于世界模型来说,动作条件注入是必不可少的,因为世界观察 应该根据智能体在 的最后动作合理且连贯地变化。作者将轨迹信息注入模型以进行条件生成。具体来说,给定自我车辆的姿态,作者首先计算相对平移 和相对旋转 。从 ,作者提取 ,从 ,作者获得偏航角 ,代表自我车辆的朝向。然后作者对 应用位置编码,使用线性层将编码值投影到隐藏大小,并与时间嵌入结合。这些组合值随后被传递到自适应层归一化(adaLN)块。
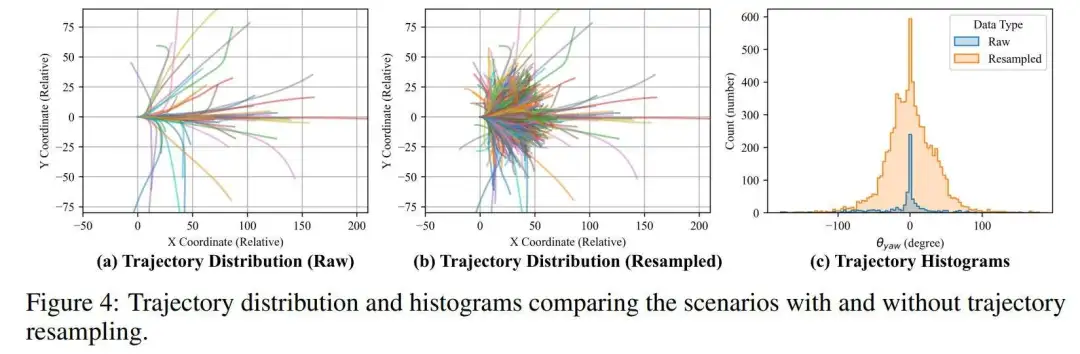
轨迹重采样:这个问题源于训练数据集中的不平衡和有限多样性。例如,在nuScenes数据集中,训练集包含700个场景,但大多数涉及车辆直行(大约87%,见图4(c)),突出了不平衡问题。此外,在同一场景中,车辆只通过一次,导致在相同场景下不同轨迹条件下缺乏多样化的3D占用样本。这导致模型过度拟合场景,仅根据上下文观察学习基于真实特征的观察。原始轨迹分布如图4(a)所示。
为了解决这个问题,作者提出了一种轨迹重采样方法,如图3(a)所示。作者的目标是多样化自我车辆的动作和每个场景中采样的占用。该过程包括以下步骤:(1)多帧点云聚合:作者首先将自我框架中的占用序列转换为3D点云,然后使用自我姿态将其转换为世界框架。通过选择点云的语义标签来过滤潜在的动态对象(例如,汽车,行人)。(2)获取可行驶区域:为了生成多样化的观察,作者根据场景的可行驶区域创建各种可行的轨迹。在聚合所有点云到世界框架后,作者过滤道路类别,并从俯视图体素化道路点云以产生鸟瞰图(BEV)地图(见图3(b))。(3)生成多样化和可行的轨迹:使用BEV地图,作者随机采样两个点代表起始和目标位置。作者应用平滑的A*算法生成连接这些点的轨迹,模拟自我车辆的驾驶轨迹。得到的轨迹被转换为 姿态,z坐标设置为0。(4)提取重采样占用:使用轨迹姿态,作者应用类似于Tian et al.(2023)的占用真实值提取方法,从点云中重新采样占用。
作者的重采样轨迹分布如图4(b)所示。与图4(a)相比,它填补了轨迹分布的空白,表明作者的方法增强了多样性并减轻了不平衡。图4(c)所示的驾驶方向直方图进一步支持了这种改进。
总之,作者的轨迹重采样方法既简单又有效。据作者所知,作者是第一个探索世界模型预测的占用数据增强。这种方法具有很高的通用性,可以应用于所有类型的占用数据,包括机器标注的、LiDAR收集的或自监督的数据。它只需要姿态和占用数据,而不需要LiDAR数据或3D边界框。
世界模型的应用
4D占用预测:在推理过程中,作者从对应于帧缓冲区大小的随机噪声开始(要预测的帧数),并通过Occ-VAE编码上下文占用帧以获得上下文潜在。作者将随机噪声中的帧替换为这些上下文潜在,然后将输入传递给作者的时空DiT(见图2底部)。在去噪循环过程中,上下文潜在保持不变,因为它们在每次迭代中都被重新引入。获得去噪潜在后,作者将其传递给Occ-VAE的解码器以生成最终的占用预测。超参数可以根据不同的要求进行调整。作者设置 = 4以进行精确的占用预测,因为更长的历史帧提供了更多的场景和运动信息。当需要更大的可控性时,如轨迹信号所要求的,作者设置 = 1以减少占用运动信息的影响,同时保持可控的起始观察。
长期生成的滚动:由于计算资源和内存限制,作者的模型在训练和推理过程中仅处理帧占用数据。为了生成更长期的占用预测,作者实施了类似于自回归方法的滚动策略。具体来说,在生成前帧后,作者重用最后一个预测帧作为上下文帧以预测接下来的帧。一个偏移量将相应的轨迹切片与上下文帧对齐。这种策略可以迭代应用以实现长期占用预测。
实验结果实验设置
作者在nuScenes数据集上进行实验,使用IoU(交并比)和mIoU(平均交并比)指标来评估占用重建和4D占用预测。更高的IoU和mIoU值表明在压缩过程中信息丢失较少,反映了更好的重建性能,并展示了对未来周围环境更准确的理解。
占用重建
尽可能压缩的同时精确重建占用对于下游任务如预测和生成至关重要。在这里,作者将Occ-VAE与使用占用标记器的现有方法进行比较,并评估它们的重建精度。占用重建的定量结果如表1所示。作者在IoU和mIoU指标上都实现了最先进的重建性能,分别为83.1%的mIoU和77.3%的IoU。
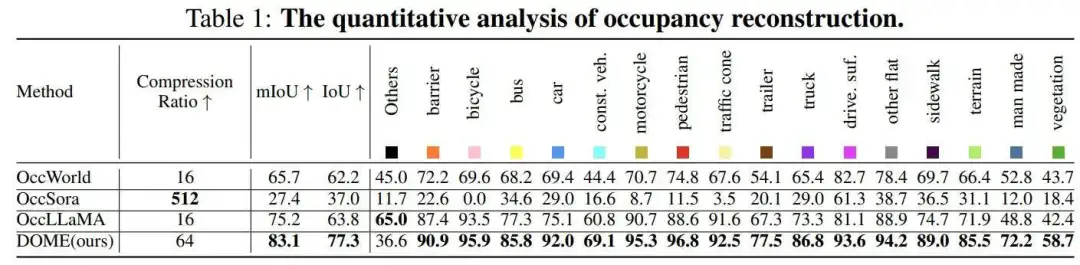
4D占用预测
作者在各种设置下将其方法与现有的4D占用预测方法进行比较。这些设置包括使用地面实况3D占用数据(-O)作为输入,以及使用现成的3D占用预测器(-F)的预测结果作为输入。按照Wei et al.(2024)的实验设置,作者使用FB-OCC作为占用提取器,利用来自相机输入的预测。
定性结果如图5所示。定量结果如表2所示,表明作者的DOME-O实现了最先进的性能,mIoU为27.10%,IoU为36.36%。作者观察到与现有方法相比,在短期(1秒)和长期(3秒)预测方面都有显著改进,表明作者的模型有效地捕获了场景随时间的基本演变。DOME-F可以被认为是一种端到端的基于视觉的4D占用预测方法,因为它仅使用周围的相机捕获作为输入。尽管任务具有挑战性,作者的方法仍然实现了有竞争力的性能,进一步证明了DOME具有很强的泛化能力。
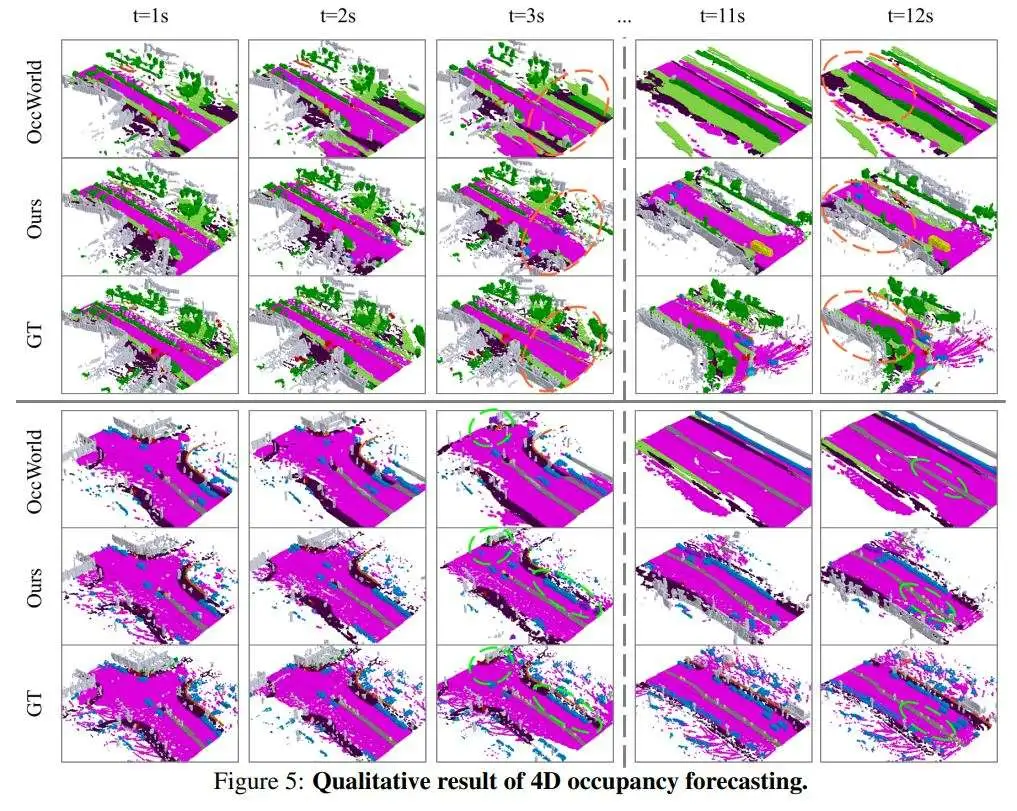
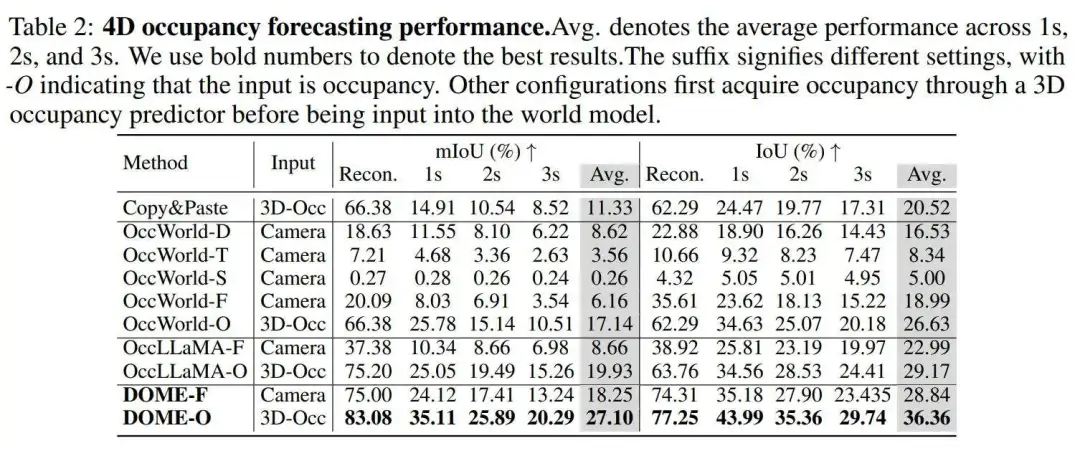
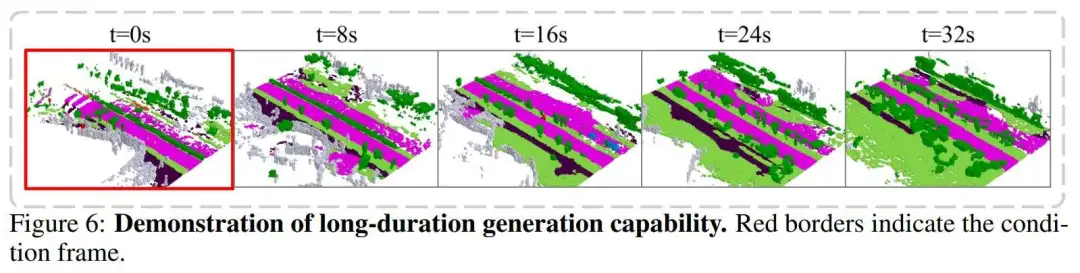
作者还展示了模型的长期生成能力,如图6所示,以及在给定相同起始帧的情况下,通过轨迹条件进行操作的能力,如图7所示。此外,作者还在表4中将其方法的生成能力与现有的占用世界模型进行了比较,作者的方法能够生成的持续时间是OccWorld的两倍,是OccSora的两倍。
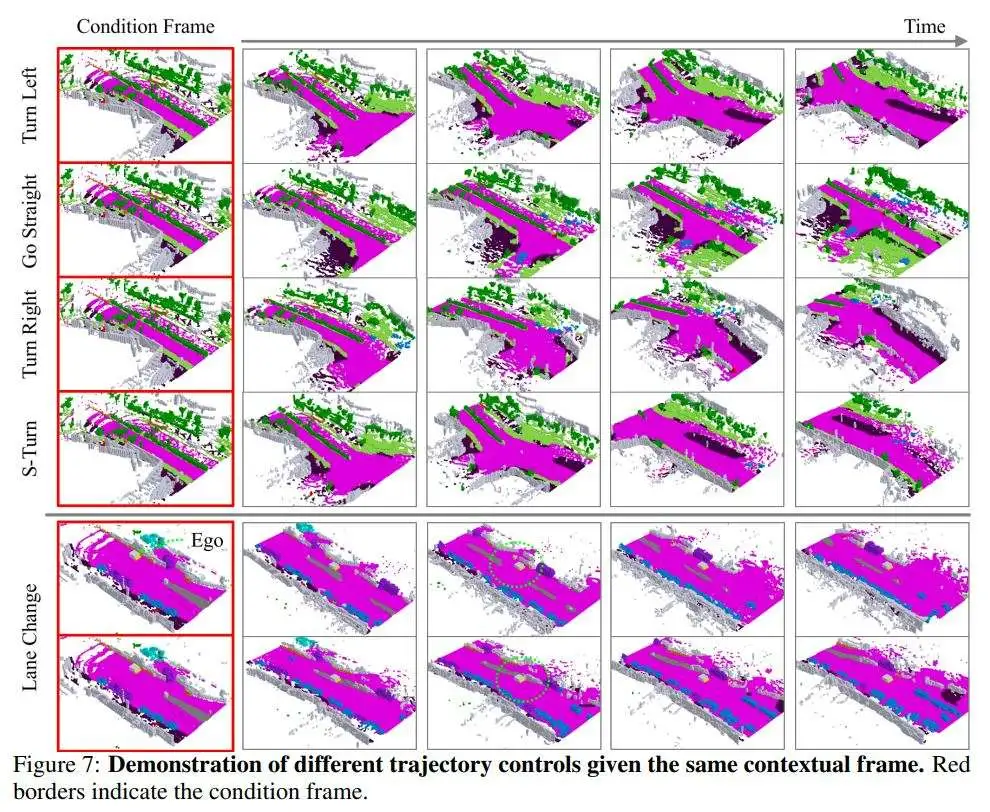
消融研究
不同的轨迹条件:作者测试了轨迹条件的不同设置,结果如表3所示。Traj.表示是否使用姿态条件进行预测,Res.表示是否使用作者的轨迹重采样增强,Yaw表示是否添加偏航角嵌入。即使不使用任何姿态条件,作者发现其模型优于OccWorld。轨迹信息通过为模型提供场景变化的明确方向而不是要求它从多种可能性中推断出来,显著改善了预测。偏航角嵌入在IoU方面提供了轻微的改进。
上下文帧的数量:作者发现在预测过程中提供更多的上下文帧可以带来更好的预测(见表5),因为额外的帧为模型提供了关于其他车辆和场景的运动和变化的更明确信息。然而,作者也观察到增加帧的数量不如使用轨迹信息高效,因为模型必须导航模糊的帧历史来预测未来的运动。对于基于智能体确定的运动进行预测的世界模型来说,这种歧义是不必要的。
结论和展望
作者提出了一个基于扩散的世界模型DOME,它根据历史数据预测未来的占用帧。它整合了带有轨迹编码器和重采样技术的Occ-VAE,以增强可控性。DOME展示了高保真度生成,有效地预测了占用空间中未来场景的变化,并且可以生成比以前方法长两倍的占用序列。这种方法在自动驾驶的端到端规划中具有应用前景。不过作者发现训练作者的模型仍然需要大量的计算资源。在未来,作者将探索更轻量级和计算效率高的方法,或者采用微调范式以减少资源需求。
#Depth Any Video
开启视频深度估计新纪元
本篇分享论文Depth Any Video with Scalable Synthetic Data,基于多样的仿真数据集和强大的视频生成模型,Depth Any Video在真实视频数据上展现了超强的泛化能力,并且在视频深度一致性和精度上超越了之前所有生成式的深度估计方法!
,时长01:29

摘要
我们提出了一种新颖的视频深度估计模型:Depth Any Video,它主要包含两大关键创新: 1. 我们开发了一套可扩展的合成数据采集流程,从多样化的虚拟环境中实时捕获视频深度数据,采集了约4万段5秒长的视频片段,每段都具有精准的深度标注。2. 我们利用强大的视频生成模型的先验来高效处理真实世界视频,并集成了旋转位置编码和流匹配等先进技术,进一步增强灵活性和效率。 此外,我们引入了一种新颖的混合时长训练策略,能够在不同长度、不同帧率的视频下表现出色。在推理阶段,我们提出了一种深度插值方法,使模型能够同时处理长达150帧的高分辨率视频。我们的模型在深度一致性和精度方面均超越了之前所有的生成式深度估计方法。
动机
视频深度估计是理解三维世界的基础问题,在自主导航、增强现实和视频编辑等具有广泛的应用。现有的方法面临的主要瓶颈在于缺乏多样且大规模的视频深度数据,导致模型在不同场景下难以有效泛化。为了解决这个问题,本文提出了两大关键创新: • 我们构建了一个大规模的合成视频深度数据集,利用现代虚拟环境的高逼真视觉效果,从虚拟环境中提取大规模且精确的视频深度数据,既具可扩展性又低成本。 • 我们设计了一个全新的视频深度估计框架,借助视频生成模型的强大视觉先验,提升对真实视频的泛化能力。该框架引入混合时长训练策略和深度插值模块,确保模型能在不同视频长度下保证深度估计的精确性和一致性。 我们的模型在生成式的深度估计方法中实现了最先进的性能,树立了视频深度估计的准确性和鲁棒性的新标杆。
方法
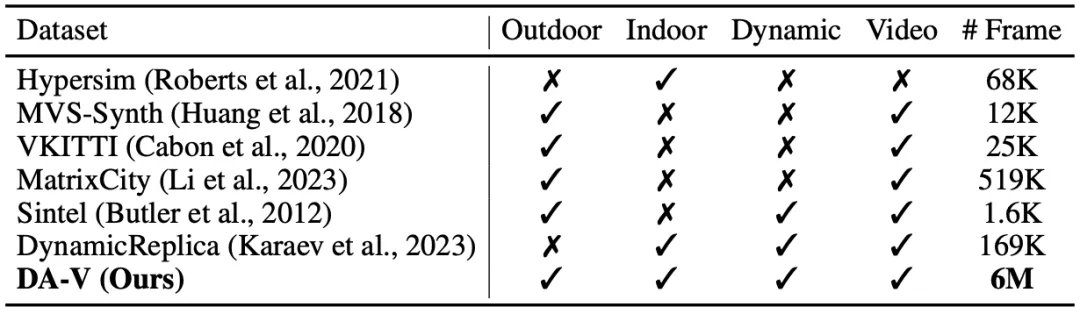
Game Data Workflow 实时数据收集:为解决深度数据的挑战,我们收集了由40,000个视频片段组成的大规模仿真数据集DA-V。该数据集主要通过先进的虚拟环境引擎生成逼真的环境,并提供准确的深度信息。我们在多款热门虚拟环境中提取深度数据,并精心选择以涵盖广泛的场景和环境条件,如:广阔的城市景观、细致的室内场景、丰富的动作场面,以及科幻的建筑设计。它不仅为我们提供精准的深度信息,还让模型接触多样的光照条件、天气效果和复杂的几何结构,使得模型能够泛化到真实环境中。在表1中,我们将DA-V与以往的公开仿真数据集进行了比较。据我们所知,这是目前覆盖真实场景范围最广的合成视频深度数据集。
数据过滤:在收集初始仿真视频后,我们发现图像与深度信息之间偶尔会出现不一致现象,例如:切换到菜单界面时。为过滤这些帧,首先使用场景切割方法检测场景转换。然后,利用在人工挑选的仿真数据子集上训练过的深度估计模型过滤掉得分较低的视频序列。然而,这种方法可能导致未见数据的过度过滤。因此,我们借助CLIP模型计算实际和预测深度之间的语义相似度,均匀抽取每个视频片段的10帧。如果语义和深度得分的中位数均低于设定阈值,则移除该片段。
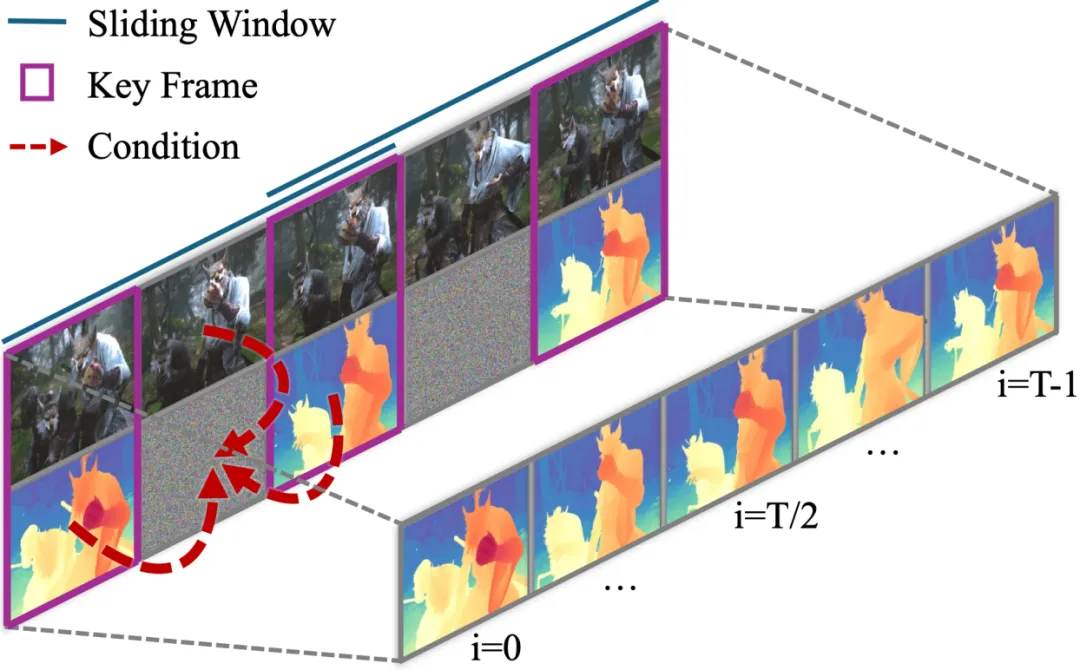
Generative Video Depth Model 模型设计:我们基于视频生成模型Stable Video Diffusion (SVD),将深度估计框架转化为条件去噪过程。整体框架如图1所示,训练流程包括一个前向过程,通过添加高斯噪声逐步扰乱真实深度数据,然后将视频作为条件输入去噪模型进行反向去噪。一旦模型完成训练,推理流程就从纯噪声开始,逐步去噪,逐步得到深度预测结果。与之前的扩散模型类似,该生成过程在变分自编码器的潜空间中进行,使模型能处理高分辨率输入而不牺牲计算效率。为了让去噪器以输入视频为条件,我们也将视频转换到潜空间中,然后将其与潜空间下的深度逐帧连接,作为去噪模型的输入。
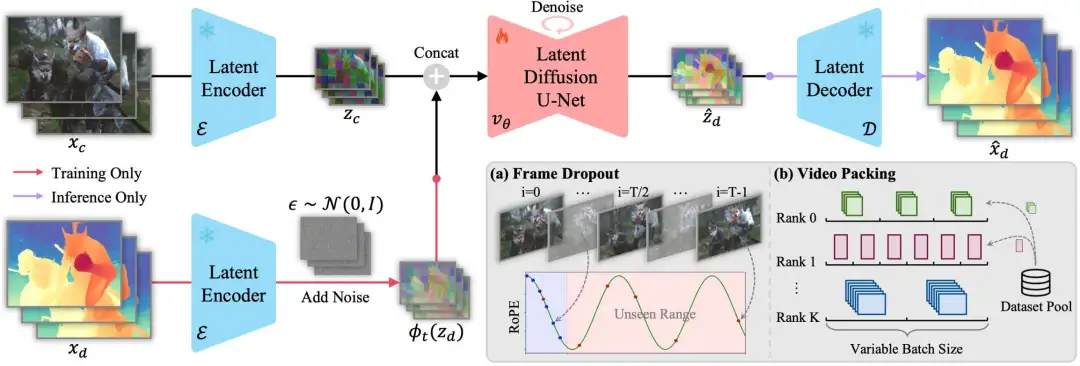
条件流匹配:为了加速去噪过程,我们将SVD中的去噪方法替换为条件流匹配。相比于原本的25步,新方法只需1步即可获得满意的深度预测结果。具体来说,我们通过高斯噪声与数据之间的线性插值来建模数据加噪过程,然后通过预测速度矢量场和常微分方程来进行去噪求解。 混合时长训练:为了增强模型在不同视频长度下深度估计的泛化能力,我们采用了一种混合时长训练策略,以确保对各种输入的鲁棒性。这一策略包括:帧丢弃数据增强(图1a):提升长视频序列的训练效率,并通过旋转位置编码增强模型在长视频下的泛化能力。视频打包技术(图1b):将相同长度、分辨率的视频打包在同一个训练批次中,优化变长视频训练过程中的内存使用。 长视频推理:上述经过训练的模型,在单个80GB A100 GPU上可同时处理分辨率为960 x 540的32帧视频。为处理更长的高分辨率视频序列,我们首先预测全局一致的关键帧,然后使用帧插值网络生成关键帧之间的中间帧,以确保深度分布的尺度和偏移对齐。如图2所示,我们将关键帧的预测结果与视频序列同时作为帧插值网络的条件输入。
实验结果
表2展示了我们的模型与当前最先进的单帧输入的深度估计模型的性能比较。我们的模型在各个数据集上显著超越了先前所有的生成模型,同时在某些情况下,其表现甚至优于之前的判别模型。
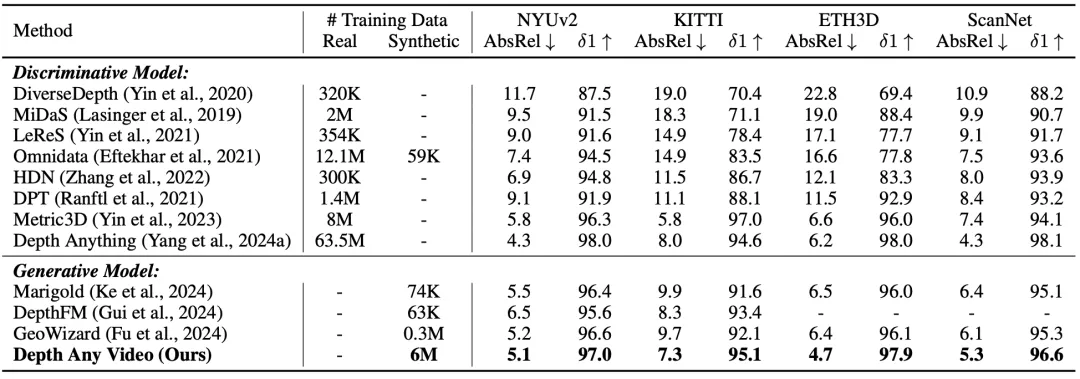

图3展示了我们的模型在不同数据集下的可视化结果,我们的方法能够捕捉细致的细节,并在自然环境数据上实现有效的泛化性。
表3展示了我们的模型与之前的视频深度估计模型的性能比较。我们的模型在ScanNet++数据集上展示了更好的时间一致性和预测精度,突显其在视频深度估计中的有效性。
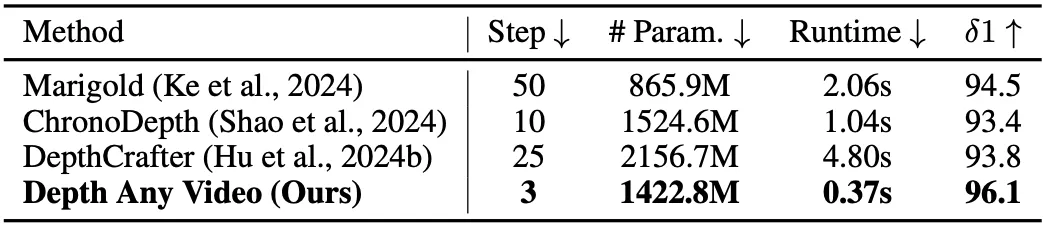
表4展示了与之前生成方法的性能和效率比较。我们的模型参数少于先前的视频深度估计方法。此外,与所有的生成式深度估计方法相比,我们实现了更低的推理时间和更少的去噪步骤,同时获得了更好的预测精度。

表5展示了所提模块对模型测试时间、训练时间、显存利用率和平均精度的影响。可以看到,这些模块均对各项指标产生了积极影响。
#GCSLAM
上交最新GCSLAM!迈向自主室内停车:全局一致的语义SLAM系统
上交的工作:本文提出了一种全局一致的语义SLAM系统(GCSLAM)和语义融合定位子系统(SF-Loc),在复杂的停车场中实现了精确的语义建图和鲁棒的定位。视觉相机(前视和环视)、IMU和车轮编码器构成了我们系统的输入传感器配置。我们工作的第一部分是GCSLAM。GCSLAM引入了一种新的因子图来优化位姿和语义图,该图结合了基于多传感器数据和BEV(鸟瞰图)语义信息的创新误差项。此外,GCSLAM还集成了一个全局停车位管理模块,用于存储和管理停车位观测值。SF-Loc是我们工作的第二部分,它利用GCSLAM构建的语义图进行基于地图的定位。SF-Loc将配准结果和里程计位姿与一个新的因子图相结合。我们的系统在两个真实世界的数据集上表现出了优于现有SLAM的性能,在鲁棒的全局定位和精确的语义建图方面表现出了出色的能力。
总结来说,本文的主要贡献如下:
提出了一种全局一致的语义SLAM系统GCSLAM,该系统基于因子图优化,具有创新的车位表示和新的几何语义组合误差项约束。
引入了一个停车位管理模块,该模块存储停车位观测值并更新全局停车位,同时有效地处理噪声和错误检测。
提出了一种基于地图的定位子系统SF-Loc,该子系统使用因子图优化将语义ICP结果和里程计约束融合在一起。
在复杂的现实世界室内停车场验证了我们的系统,表明我们的系统实现了实时、高精度的定位和语义建图性能。
相关工作回顾
早期的视觉SLAM方法是基于滤波方法实现的。随后,利用BA优化的SLAM系统出现了。DSO在估计稠密或半稠密几何体之前引入了光度误差和几何误差。ORB-SLAM采用ORB特征和滑动窗口来实现精确的位姿估计。与滤波方法相比,基于优化的方法提供了更高的精度和更好的全局一致性。
尽管如此,具有单个摄像头的SLAM无法恢复规模,并且容易受到视觉模糊的影响。为了提高系统的鲁棒性和准确性,开发了将视觉数据与其他传感器相结合的多传感器融合方法。MSCKF使用视觉信息构建观测模型,并使用惯性测量单元(IMU)数据更新状态。VINS Mono提出了一种紧密耦合、基于优化的视觉惯性系统。VIWO开发了一种基于MSCKF的位姿估计器,该估计器集成了IMU、相机和车轮测量。DM-VIO通过延迟边缘化和位姿图束调整来增强IMU初始化。Ground-Fusion引入了一种自适应初始化策略来解决多个角点情况。
然而,由于室内环境的复杂条件,如有限的独特特征和复杂的照明条件,这些方法无法在室内停车位内执行AVP任务的SLAM。为了解决这些问题,一些工作都利用鸟瞰(BEV)图像作为输入,可以提供丰富的地面特征,以解决停车场独特特征有限的问题。AVP-SLAM使用语义分割来注释图像中的停车位、地面标记、减速带和其他信息,因为分割方法可以有效地适应复杂的照明条件。该语义信息被添加到全局图中,然后用于注册辅助定位。然而,他们的地图是用于注册的纯点云图,没有独立记录每个停车场,也缺乏每个停车位的位置和角度等重要属性信息。赵等人利用停车位检测器检测停车位的入口点,并将停车位的观测与里程计相结合,构建新的定位因子。然而,这种方法并不能维护一个完整的停车位地图。相反,它主要使用地图作为定位的辅助工具。VISSLAM在停车位之间添加了约束,结合里程计信息提出了一种改进建图结果的停车位管理算法。后续工作MOFISSLAM结合了滑动窗口优化,实现了更高的定位精度和改进的建图结果。
然而,现有的方法对噪声很敏感,在复杂的停车场表现不佳。为了解决这个问题,我们提出了一种新的室内停车SLAM因子图,提高了鲁棒性和准确性。
方法详解
我们的系统采用多个传感器作为输入,包括一个前视摄像头、IMU、车轮编码器和四个全景摄像头。我们工作的总体框架如图2所示。我们工作的第一部分是SLAM系统GCSLAM。GCSLAM集成了三个模块:全局时隙管理模块、里程计和因子图优化。里程计模块与其他模块松散耦合,使其可替换,增强了系统的灵活性和可用性。本文采用VIW作为里程计模块。全局时隙管理模块包括BEV感知模块和时隙关联。我们的BEV感知模块是一个基于多任务框架。它以BEV图像为输入,实时生成语义分割结果(地面标记)和时隙检测结果(停车边界端点),使用统一的骨干网络,为每个特定任务提供不同的输出头。此外,该全局时隙管理模块将检测结果注册到全局时隙并执行时隙关联。基于里程计位姿、语义信息和时隙关联结果,因子图优化可以实现精确的位姿估计和全局语义图构建。在建立全局语义图后,我们工作的第二部分,定位子系统SF-Loc,将里程计位姿与语义配准结果融合在一起,用于基于地图的定位。
带语义车位节点的因子图
我们将SLAM任务视为一个因子图优化问题,旨在估计关键帧的精确位姿。基于里程计提供的帧间距离来选择关键帧。因子图由节点和边组成,其中节点表示要优化的变量,边是约束节点的误差项。如图3所示,GCSLAM使用两种类型的节点和四种类型的边构建因子图
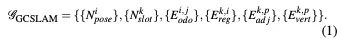
节点和误差术语的定义将具体介绍如下。
1)位姿节点:由于我们的SLAM系统假设一个平面停车场,姿势节点在世界坐标系中存储了第i帧的3自由度(DoF)车辆位姿(x,y,θ)。我们使用里程计模块提供的估计位姿位姿来初始化位姿节点。此模块作为单独的线程运行。
2)车位节点:当BEV感知模块检测到停车位时,它会在像素坐标中输出其入口边缘的端点坐标和方向。我们首先使用BEV图像的虚拟固有K和当前帧位姿Ti将入口边缘的中点注册到世界坐标。Ti的方程为:
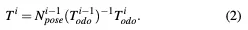
3)里程表误差项(OET):我们基于里程表模块在之间构建OET。OET的具体形式是:
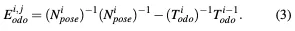
4)配准误差项(RET):RET限制了和之间的关系。
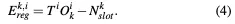
5)Adjacent Error Term (AET):
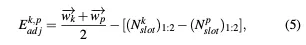
6)Global Vertical Error Term (GVET):
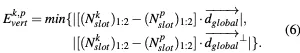
全局车位管理
在因子图优化过程中,自车位姿不断优化。在自车位姿优化后,从自车位姿和车位观察配准的全局车位位姿也需要更新。因此,我们使用全局车位管理模块来存储和管理多个车位观测帧。当新的观测帧到达时,管理系统将当前观测与现有的全局时隙相关联。否则,它将创建一个新的全局车位。当自车的位姿优化或新的观察帧到达时,管理系统会更新全局停车位。
1)车位关联:为了确定车位观测值是否与之前观测到的现有全局车位相关联,我们首先将当前观测值配准到世界坐标,表示为Sobs。然后,我们使用kd树来找到最近的全局车位。根据它们中点之间的距离d,我们确定它们是否相关。如图4所示,如果S不与任何现有的obs全局车位相关联,则它将被创建为新的停车位或作为错误检测被丢弃。具体参数如图4所示。
一旦全局车位Sk与Sobs相关联,我们就增加该时隙的观测帧计数。通过记录每个全局时隙的观测频率,我们可以排除低频时隙作为错误检测。这种滤波策略可以有效地减轻BEV感知模块的噪声。具体的过滤逻辑如Alg 1所示。
2)车位更新:由于因子图是实时优化的,因此每个位姿节点对应的汽车位姿都在不断变化。由于全局车位是根据汽车位姿Ti和车位观测配准的,因此当因子图中每一帧的位姿发生变化时,它应该相应地更新。
基于地图的定位子系统
GCSLAM将车位和其他语义信息转换为点云,并获得全局图。基于该全局图,我们提出了一个融合里程计位姿和配准结果的定位子系统SF-Loc。SF-Loc和GCSLAM不会同时激活。GCSLAM仅在首次进入未知停车场时执行,而SF-Loc仅在使用已建立的全局地图重新访问停车场时激活。如图5所示,SF-Loc由因子图GSF-Loc构建:
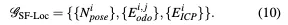
我们的语义ICP配准算法在局部地图和当前点云之间进行配准。局部地图是基于之前的姿势从全局地图中提取的30m×30m的地图。当前点云是从BEV语义转换而来的。在语义ICP过程中,使用kd树识别每个点具有相同语义的最近邻。基于语义点对的匹配关系,计算当前点云与局部地图之间的转换。此过程迭代执行,直到收敛,提供精确的姿势
语义ICP误差项是一元边,提供配准的绝对位姿结果:
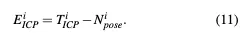
由于一元边施加的强约束和语义分割的高噪声,我们降低了添加ICP一元边的频率。我们每10帧添加一次ICP错误项,并在添加之前进行跳跃检测。我们计算当前帧的ICP配准结果与前一帧的ICP注册结果之间的距离。如果距离超过2米的阈值,则认为当前帧的配准结果不准确。在这种情况下,我们不会为当前帧添加ICP错误项。
语义ICP误差项有效地纠正了里程计的累积漂移,而OET减轻了ICP中的不稳定跳跃。因此,SF-Loc提高了定位的精度和鲁棒性。
实验结果
结论
本文介绍了一种新型的室内停车跟踪和建图系统GCSLAM。GCSLAM结合了创新的因子图和新颖的误差项,在复杂的停车环境中实现了稳健和高精度的建图。此外,我们还开发了一个基于地图的定位子系统SF-Loc。SF-Loc基于一种新的因子图将配准结果和里程计位姿融合在一起,有效地提高了定位精度。我们通过真实世界的数据集验证了我们的算法,证明了我们系统的有效性和鲁棒性。
#从小鹏、理想、蔚来布局看自动驾驶发展趋势
随着智能驾驶技术在全球范围内快速发展,汽车产业正迎来巨大变革。自动驾驶,作为汽车智能化的核心部分,不仅影响着未来出行的方式,更推动着整个汽车行业的升级和转型。在这场变革中,中国的新势力造车企业,小鹏、理想和蔚来,凭借其创新的技术路线和市场策略,逐渐成为行业内的重要力量。与传统车企不同,这些新兴企业通过对智能驾驶技术的探索与应用,试图在全球市场上占据主动权,进而引领自动驾驶的未来发展方向。
小鹏:端到端大模型的全面落地
1.1端到端大模型加速自动驾驶进程
小鹏汽车近年来在自动驾驶领域的发展备受关注,其2024年量产落地的端到端大模型被视为行业内的重大突破。这种大模型是基于神经网络的结构,通过高度的数据驱动方式,解决了传统自动驾驶系统中人工规则过多、更新维护复杂的问题。小鹏的技术架构由三大核心模块组成:神经网络XNet、规划大模型XPlanner以及大语言模型XBrain。这三者的协同工作使得小鹏的自动驾驶系统不仅能够快速适应不同场景,还能不断通过数据迭代提高系统的智能化水平。
小鹏端到端大模型组成
与传统的自动驾驶方案相比,端到端大模型的最大优势在于其极大减少了人工参与的过程。在传统方案中,开发者需要通过大量的手工编码,定义每一种可能遇到的道路情况和驾驶行为,这种做法在复杂的城市路况下容易遇到瓶颈。而小鹏的端到端模型通过大规模数据训练,将感知、规划和控制环节全部交由AI完成,显著提升了系统的适应能力。神经网络XNet作为感知模块,可以通过摄像头和传感器的信息,构建出高精度的3D地图,能够精准识别50个以上的动态目标,并预测其行为。这种强大的感知能力使小鹏的自动驾驶系统在面对复杂的交通状况时仍能做出准确的决策。
与此同时,规划大模型XPlanner的加入使得系统能够生成更加人性化的驾驶行为。与传统系统中依靠预设规则进行规划不同,XPlanner能够通过对大量实际驾驶数据的学习,自主生成符合交通规则和用户习惯的驾驶策略。例如,在处理拥堵路段或狭窄道路时,XPlanner能够更加灵活地选择最优路径,并减少车辆不必要的加减速,提升乘坐舒适性。
大语言模型XBrain则为系统提供了类似于人类大脑的认知能力。它不仅可以理解复杂的交通标志、路牌信息,还能根据周围环境变化做出适时的调整。例如,在面对潮汐车道或特殊交通信号时,XBrain能够快速判断其含义,并调整车辆的行驶策略,从而进一步提升系统的安全性和可靠性。
利用大模型,小鹏智驾能"看懂"更多路标等信息
1.2 XNGP的全量推送与无图化演进
小鹏的全感知驾驶系统XNGP(全景导航驾驶系统)于2024年7月实现了全量推送,这标志着该系统在全国范围内的广泛应用。XNGP系统的特别之处在于其不再依赖于高精地图,这一技术突破为自动驾驶的普及扫清了障碍。传统自动驾驶系统需要依赖高精度地图提供详细的道路信息,但这些地图的获取和更新成本高昂,并且只能覆盖有限的区域。小鹏通过无图XNGP系统,摆脱了这种依赖,系统能够依靠车载传感器和AI模型实现对道路环境的实时感知和判断,从而实现自动驾驶。
端到端技术的使用使得小鹏自动驾驶的进步大大加速
无图XNGP的推出不仅提升了自动驾驶的覆盖范围,也大大提高了用户的使用体验。得益于端到端大模型的支撑,无图XNGP在各种复杂的城市环境中表现优异,例如在狭窄的小巷、拥堵的市区道路以及环形交叉路口等场景中,系统都能够流畅应对。特别是在环岛或掉头等传统自动驾驶系统难以处理的场景下,无图XNGP通过实时学习和推理,能够快速生成安全的行驶路径,并确保车辆稳定通过。
小鹏计划在2024年第四季度实现"门到门"的自动驾驶体验,即车辆从用户家门口出发,直至目的地,全程不需要人工接管。这个目标的实现将标志着自动驾驶技术的又一次飞跃,不仅能够提升出行效率,还能为用户提供更加便捷的驾驶体验。这一举措也是小鹏未来在全球市场推广自动驾驶技术的关键一环。
1.3小鹏的全球化战略与未来展望
除了在中国市场的积极布局,小鹏汽车也在大力推进其全球化战略。凭借无图XNGP技术的优势,小鹏计划在2025年将其自动驾驶技术推广至全球多个国家和地区。与传统依赖高精地图的系统不同,小鹏的端到端大模型能够有效降低跨国市场的技术推广成本。这种技术架构使得小鹏能够迅速适应不同国家和地区的道路环境,尤其是在欧洲和北美等高标准的发达市场,小鹏的无图技术将成为其竞争的关键优势。
通过全球化战略,小鹏不仅可以扩展其市场份额,还能进一步优化其自动驾驶系统。随着更多的用户和车辆在全球范围内投入使用,系统将能够获取更多的驾驶数据,进一步提升其AI模型的泛化能力。这种数据驱动的全球迭代模式,将帮助小鹏在未来的自动驾驶竞争中占据有利地位。
理想:双系统架构引领自动驾驶第一梯队
2.1理想无图NOA的全量推送与快速迭代
理想汽车作为中国"造车新势力"中的佼佼者,其在自动驾驶领域的布局同样引人注目。2024年,理想汽车推出了其无图NOA(自动驾驶导航辅助)系统,并在全国范围内实现了全量推送。理想的无图NOA系统依靠其强大的感知与决策能力,能够在不依赖高精地图的情况下,完成各种复杂的驾驶任务。尤其是在城市道路上,无图NOA展现出了卓越的自动驾驶能力,得到了市场和用户的广泛认可。
理想将在三年内实现L4级别无监督自动驾驶
理想的自动驾驶系统采用了分段式的端到端模型,即在系统的感知、规划和控制环节中均实现了高度模型化。通过这一技术架构,理想能够有效减少对人工规则的依赖,进一步提高系统的迭代速度。感知模块通过车辆的摄像头、雷达等传感器获取道路信息,规划模块则根据实时环境生成最佳行驶路线,控制模块负责将这些指令转化为具体的驾驶操作。得益于这种分段式端到端架构,理想的自动驾驶系统在多种复杂场景中表现优异,包括自动变道、红绿灯识别、障碍物绕行等。
理想的无图NOA系统特别适用于中国复杂的城市道路环境。在这种环境下,车辆经常会遇到突发的行人、自行车以及复杂的交通标志,而高精地图的更新往往无法及时跟上城市发展的步伐。理想通过实时的环境感知和动态决策,使车辆能够灵活应对各种情况。这种灵活性不仅提高了自动驾驶的安全性,也为用户提供了更为流畅的驾驶体验。
2.2端到端+VLM的双系统架构
理想汽车的自动驾驶系统不仅依赖于端到端的AI模型,还通过引入视觉语言模型(VLM),形成了独特的双系统架构。这一架构模仿了人类驾驶员的决策机制,即分为"快系统"和"慢系统"。快系统负责处理大部分常见的驾驶场景,例如常规的城市道路驾驶和高速公路驾驶;而慢系统则用于处理复杂、未知或罕见的场景,例如突发的交通事故、异常天气条件或复杂的路口等。
端到端模型作为快系统,通过大量的驾驶数据进行训练,能够快速识别道路上的目标物并生成行驶路线。而视觉语言模型(VLM)则是慢系统,通过引入多模态数据(包括视觉、语言和环境信息),VLM能够在复杂场景中进行深度推理,帮助系统在遇到未曾见过的情况时仍能做出合理的决策。例如,当系统在城市中遇到临时的交通管制或施工区域时,VLM可以通过识别标志和路面情况,判断出最佳的绕行路线,确保行车的安全性。
视觉大语言模型可以很好的识别驾驶场景并做出决策
这种双系统架构不仅提高了理想汽车自动驾驶系统的安全性和可靠性,还使得系统具备了更强的场景适应能力。在未来,随着更多数据的积累和AI模型的迭代,理想的端到端+VLM系统有望进一步提升自动驾驶的水平,为实现L4级别的自动驾驶奠定基础。
2.3面向L4级别的自动驾驶演进
理想汽车的长远目标是实现L4级别的无监督自动驾驶,这意味着车辆将能够在各种复杂的道路环境中,完全依靠自身的决策系统进行驾驶,而不需要驾驶员的干预。为了实现这一目标,理想正在逐步提升其自动驾驶系统的智能化水平,通过数据闭环、模型优化和场景验证等手段,加速系统的迭代。
L4级别的自动驾驶不仅要求系统具备极高的感知和决策能力,还要求其能够处理海量的复杂场景和突发事件。为此,理想汽车正在不断扩展其自动驾驶车队的规模,并通过这些车辆收集大量的驾驶数据。这些数据不仅帮助系统识别常见的驾驶场景,还能够通过生成式仿真和模型训练,提升系统在应对长尾场景时的表现。
此外,理想还计划通过视觉语言模型的持续优化,进一步提升系统的认知和推理能力。未来的L4级别自动驾驶系统将不仅依靠感知和决策能力,还能够通过对环境的深度理解,预测潜在的风险并提前做出应对。理想的这一战略不仅展示了其在技术上的前瞻性,也为未来的自动驾驶市场竞争打下了坚实的基础。
蔚来:群体智能与长期主义战略
3.1 NOP+系统的全量推送
蔚来在2024年全量推送了其增强版领航辅助系统NOP+,这一系统的推出不仅为蔚来的自动驾驶布局增添了亮点,也展示了其"群体智能"技术的巨大潜力。NOP+系统基于蔚来全栈自研的自动驾驶算法,能够在高速公路和城市道路上实现自动驾驶功能。不同于其他车企通过大范围推开"开城"的方式推广自动驾驶,蔚来选择了逐步优化特定道路的策略,确保其系统在每一条特定路段都能提供稳定、安全的自动驾驶体验。
NOP+系统通过不断的迭代与优化,已经在中国多个城市实现了全面覆盖。蔚来车队在不同城市的道路上进行大量的实地测试,并通过群体智能技术不断收集数据、优化算法。这种多车协同的群体智能模式使得蔚来的自动驾驶系统能够快速应对各种复杂的路况,并通过实时数据反馈,不断提高系统的智能化水平。
蔚来计划在2024年下半年推出"点到点"的全域领航辅助功能,这将进一步拓展NOP+系统的应用场景,使其不仅能够在城市和高速道路上使用,还能在不同类型的道路之间实现无缝切换。这一升级将使蔚来的自动驾驶技术更加完善,并为其未来的市场拓展打下坚实的基础。
蔚来NOP+已在2024年4月全量推送
3.2 世界模型与数据闭环的结合
蔚来的自动驾驶技术依赖于强大的数据闭环系统,通过构建世界模型,蔚来能够在云端模拟现实世界中的各种复杂场景,并通过仿真技术进行验证和优化。世界模型的引入大大提高了蔚来系统的迭代速度,尤其是在处理长尾场景时,生成式仿真能够为系统提供更加全面的训练数据,使其能够应对现实世界中可能遇到的罕见情况。
世界模型能够进行空间理解与时间理解
蔚来的群体智能系统还能够通过多车协同,不断优化其自动驾驶算法。每辆车在实际道路上行驶时,都会将遇到的复杂场景反馈至云端,系统通过这些数据不断迭代优化。这种闭环式的数据反馈机制不仅提高了系统的安全性,还加速了自动驾驶功能的全面落地。
3.3长期主义:软硬结合的布局
蔚来一直以来秉持着软硬结合的长期主义战略,通过自主研发的硬件和软件平台,确保其自动驾驶系统的稳定性和可持续发展。在硬件方面,蔚来自主研发了神经网络处理单元,并通过搭建强大的云端计算平台,为自动驾驶系统提供了充足的算力支持。蔚来的计算平台能够处理海量的数据,并通过这些数据不断优化系统的算法,使其能够在复杂的路况下做出精准的决策。
在软件方面,蔚来依托全栈自研的自动驾驶算法,确保其系统能够高效运行,并在不同的应用场景中保持稳定。通过对系统的不断迭代和优化,蔚来的自动驾驶技术已经达到了行业领先水平。未来,蔚来将继续通过软硬结合的方式,推动自动驾驶技术的发展,并在全球市场上保持竞争力。
自动驾驶行业的未来趋势
4.1从"能用"到"好用"的快速过渡
自动驾驶技术的发展已经进入了从"能用"向"好用"过渡的关键阶段。早期的自动驾驶系统更多依赖于高精地图和预设规则,虽然能够在特定的场景中实现自动驾驶功能,但覆盖范围有限,用户体验也有待提升。而随着小鹏、理想和蔚来的技术突破,自动驾驶系统开始向更高的安全性和舒适性迈进。
小鹏的无图XNGP系统和理想的无图NOA系统通过大规模数据驱动和AI模型的优化,能够在复杂的城市道路中实现流畅的自动驾驶。这种技术的进步不仅提升了用户体验,也为未来的自动驾驶普及提供了技术支撑。未来,随着自动驾驶技术的不断成熟,用户对自动驾驶的需求将不仅限于基本的功能实现,还将期待更高水平的驾驶体验和服务。
4.2数据驱动的AI大模型成为主流
端到端大模型和数据驱动的算法正在成为自动驾驶技术发展的主流。通过大规模车队的数据训练,AI模型能够快速学习并适应不同的驾驶场景和复杂路况。小鹏、理想和蔚来都通过构建庞大的数据闭环系统,提升了其自动驾驶系统的迭代效率和泛化能力。
未来,随着更多的车企加入这一行列,数据驱动的AI大模型将成为自动驾驶技术的核心推动力。通过对海量数据的训练和验证,自动驾驶系统将能够在更短的时间内实现性能的提升,并在全球范围内快速推广。
4.3城市级无图自动驾驶的普及
无图自动驾驶技术正在逐渐成为行业发展的新趋势。小鹏和理想通过无图NOA的技术突破,证明了自动驾驶系统可以在没有高精地图的情况下,依靠AI模型和数据反馈实现高效驾驶。未来,随着技术的进一步优化,城市级无图自动驾驶将成为主流应用场景之一,特别是在复杂的城市道路和多变的路况下,无图化技术将展现出更强的适应能力。
结论
从小鹏、理想到蔚来,三家车企的技术布局展示了中国自动驾驶行业的巨大潜力。通过端到端大模型、双系统架构以及世界模型等技术突破,自动驾驶技术正在快速走向成熟。未来,随着技术的持续迭代和数据驱动的进一步深化,自动驾驶将在全球范围内迎来更广泛的应用和普及。这不仅将改变未来的出行方式,也为整个汽车产业的升级和转型注入新的活力。
#盘一盘端到端自动驾驶主要玩家
1、主机厂
小鹏汽车
2024年5月20日,小鹏汽车举办AIDay发布会,董事长、CEO何小鹏宣布端到端大模型上车。小鹏的端到端大模型有三个组成部分:神经网络XNet+控大模型XPlanner+大语言模型XBrain。小鹏汽车在发布会上表示,端到端大模型上车后,18个月内小鹏智能驾驶能力将提高30倍,每2天内部将做次智驾模型的送代。
鸿蒙智行(类主机厂)
2024年4月24日,华为智能汽车解决方案发布会上,华为发布了以智能驾驶为核心的全新智能汽车解决方案品牌一一乾崑,并发布了并发布了ADS3.0。乾崑ADS3.0的技术架构,感知部分采用GOD(GeneralObjectDetection,通用障碍物识别)的大感知网络,决策规划部分采用PDP(Prediction-Decision-Planning,预测决策规控)网络实现预决策和规划一张网。ADS3.0在ADS2.0基础上实现了决策规划的模型化,为端到端架构的持续演进莫定了基础。
蔚来汽车
蔚来在高阶辅助驾驶研发领域一直保持领先。据晚点Auto报逆,自2023年下半年开始,蔚来已经投入几十人团队研发端到端自动驾驶,并计划于2024年上半年上线基于端到端的主动安全功能。蔚来智能驾驶研发副总裁任少卿认为,自动驾驶的大模型需要拆解成若干个层级,第二步是模型化,行业基本已经完成了感知的模型化,但是规控的模型化方面头部公司也没有完全做好,第二步是端到端,去掉不同模块间人为定义的接口,第三步是大模型。
零一汽车
零一汽车是一家新能源重卡科技公司。零一致力于在核心动力总成、集成式热臂理、自动驾驶技术等核心系统上实现全裁自研,并通过软件定义硬件,利用数据和技术重构供应链,实现自主安全可控与结构性成本优化。2024年5月,零一汽车成功发布了两款量产纯电牵引车"惊整与"小满"。
近期,零一也推出了基于大模型的端到端自动驾驶系统。整个系统使用摄像买和导航信息作为输人,经过多模态大诺言模型的解码产生规控信号和辑推理信息,将系统复杂度降低90%。通过模拟人类的驾驶行为与思考过程,模型在仅使用视觉信息的情况下展现了丰常强的泛化能力,并在多个数据集中获得世界第一的成绩。零一计划在2024年底实现端到端自动驾驶的部署上年,2025年在商用年与乘用车平合上同时实现量产,并计划于2026年实现高阶自动驾驶的大规模商业化运营。
2、自动驾驶算法和系统公司
元戎启行
2023年3月,元戎启行推出国内首款不依赖高精度地图、可实现全域点到点功能的高阶智能驾驶解决方案DeepRoute-Driver3.0。DeepRoute-Driver3.0发布的同时,元我启行已经在进行端到端模型研发。2023年8月,元戎启行运用端到端模型完成了道路测试。在道路测试中端到端模型表现惊艳,该车会顾虑后车需求主动礼让后车。在路况复杂的城中村狭窄路段,搭载端到端模型的车辆行驶流畅,无顿挫感;在2024年4月25日的北京车展上,元戎启行对外展示了即将量产的高阶智驾平台DeepRouteIO以及基于DeepRouteIO的端到端解决方案。该方案采用NVIDIADRIVEOrin-X系统级芯片,200+TOPS算力,并配备1颗固态激光雷蕾达,11颗摄像头。元戎启行CEO周光在2024年GTC大会上表示:"未来人工智能技术将在物理世得到产泛应用。端到端模型会重塑物理世界的人工智能技术,终结一个以"规则驱动,为主导的原始人工智能时代,开启一个以深度学习,为引擎的通用人工智能时代。
商汤绝影
2024年4月举办的北京车展上,商汤绝影推出面向量产的端到端自动驾驶解决案"UniAD"。本次车展上,商汤绝影展示的端到端自动驾驶系统,无需高精度图通过数据学习和驱动就可以像人一样观察并理解外部环境,然后基于足够丰富的感信息,UniAD能够自己思考并作出决策,像人一样开车,流畅进行无保护左转、快通行人车混行的红绿灯路口,自主解决各种高难度的城市复杂驾驶场景。
商汤的"端到端UniAD"归属于"模块化端到端"类型,与决策规划模型化的技术架构(即两段式端到端网络")相比,不需要对感知数据进行抽象和逐级传递,实现了感知决策一体化和系统的联合优化。同时,商汤绝影也发布了其下代自动驾驶技术DriveAGI,即基于多模态大模型对端到端智驾方案进行改进和升级的"OneModel端到端"。
小马智行
基于此前在模块化自动驾驶技术上的深远积累和技术优势,小马智行开始研发端到端自动驾驶模型为自动驾驶更大范围使用、更快覆盖速度做准备。2023年8月,小马智行将感知、预测、规控三大传统模块打通,统一成端到端自动驾驶模型,自前已同步搭载到L4级自动驾驶出租车和L2级辅助驾驶乘用车。
智行端到端自动驾驶模型既可作为L4级车辆的冗余系统,也可作为L2级车辆的解决方案。小马智行端到端自动驾驶模型具有四大优势:一、多维度的数据来源:L4级自动驾驶车辆行驶数据,L2级量产车中人类驾驶员数据,V2X路段摄像头数据,日常生活中的数据等都可作为数据来源;二、全面的数据处理工具:基于在L4级自动驾驶上的多年积累,小马智行已拥有一套完整的数据评估体系,包含前期高质量数据挖掘清洗,测试使用的大规模仿真系统等;三、模型具有可解释性,不再是黑盒状态:小马智行结合驾驶意图、应用场景融入规则性指令,例如交通法规、驾驶偏好等;四、出色安全的驾驶技术:小马智行自动驾驶测试里程已达到3500万公里,安全性比人类司机高10倍;不仅向不同场景中的优秀人类驾驶员学习,还帮助其他驾驶员减少错误,从而提高我们自身的安全性。
鉴智机器人
在2024北京车展期间,鉴智机器人联合创始人、CCTO都大龙表示,鉴智机器人原创的自动驾驶端到端模型GraphAD已经可量产部署,并正与头部车企进行联合开发。在主流端到端开环规划评测上,GraphAD在各项任务上均达到领域最佳性能,规划任务上拟合误差和避障指标更是远超此前的最佳方案。
英伟达
作为AI生态赋能者,英伟达可以提供从芯片、工具链到智驾解决方案的全栈产品,将AI领域最前端的技术赋能至智驾。
2023年夏季,吴新宙加盟英伟达成为汽车业务负责人。此后,英伟达加大对智驾业务的投入,强化英伟达对于自身全栈软硬件方案提供商的定义。2024北京车展前夕,吴新宙展示了英伟达自动驾驶业务从L2到L3的发展规划,其中提到规划的第二步为"在L2++系统上达成新突破,LLM(Large Language Model,大语言模型)和VLM(Visual Language Model,视觉语言模型)大模型上车,实现端到端的自动驾驶"。吴新宙认为,端到端是自动驾驶的最终一步,接下来几年端到端模型和原有模型会在自动驾驶中相辅相成,端到端模型提供更拟人且灵活的处理,而原来的模型和方法则可以保证安全性。
地平线
地平线早在2016年便率先提出了自动驾驶端到端的演进理念,并持续取得技术创新与突破:在2022年提出行业领先的自动驾驶感知端到端算法Sparse4D;2023年,由地平线学者一作发表的业界首个公开发表的端到端自动驾驶大模型UniAD,荣获CVPR2023最佳论文。同时,地平线积累了基于交互学习的端到端深度学习算法,大幅提升智驾系统在复杂交通环境中的通过率、安全性和舒适度。在硬件技术上,地平线专为大参数Transformer而生的新一代智能计算架构BPU纳什,能够以高度的软硬协同打造业界领先的计算效率,为自动驾驶端到端和交互学习提供智能计算最优解。
3、自动驾驶生成式AI公司
光轮智能
光轮智能致力于为企业落地AI提供合成数据解决方案,结合生成式AI和仿真技术,为行业提供多模态、高真实度、可泛化、全链路的合成数据。解决自动驾驶、具身智能行业中真实数据采集难、CornerCase数据缺乏、标注成本高、回环周期长、利用率低等问题。
光轮智能由谢晨博士创立,结合生成式AI和仿真技术提供合成数据解决方案。谢晨曾在英伟达(美国)、Cruise(美国)、蔚来汽车等企业担任自动驾驶仿真负责人,国际首创将生成式AI融入仿真。清华大学智能产业研究院助理教授赵昊担任光轮智能首席科学家。赵昊深耕基于生成式AI的仿真、自动驾驶与具身智能算法,曾主导研发全球首个开源的模块化真实感自动驾驶仿真器MARS。光轮团队拥有国内外最多次从0-1合成数据生成和落地经验,汇聚国际顶级生成式AI算法专家、英伟达传感器仿真负责人、国内领先自动驾驶感知负责人、阿里P8、机器人国际大赛
冠军、清华特奖、多次创业者等。员工来自英伟达、华为、Cruise、蔚来、百度、达摩院等,拥有多项国内外技术专利。公司2023年初成立,已完成种子轮、天使轮、天使+轮、PreA轮四轮融资,累计融资上亿元。
面对市场上迅猛增长的合成数据需求,光轮智能坚持高质量高效率地交付合成数据,现已交付多家国内外头部主机厂、Tier1、自动驾驶公司数万商业订单,服务量产落地以及端到端算法预研。在自动驾驶端到端方面,光轮作为引领者,开发了首创的端到端数据与仿真的全链路解决方案,积累了大量自动驾驶端到端实战经验。2024年3月,光轮智能与上海人工智能实验室联合推出并开源自动驾驶3DOccupancy合成数据集"LightwheelOcc",用于CVPR2024自动驾驶挑战赛,本届挑战赛包含了以端到端为代表的众多自动驾驶领域关键技术赛题的比赛。除自动驾驶领域外,光轮智能也开始服务具身智能、多模态大模型等领域,目前国内合成数据领域市场份额稳居第一。
极佳科技
极佳科技是一家专注于世界模型技术和视频生成应用的公司。2023年9月极佳科技推出了全球首个物理世界驱动的自动驾驶世界模型DriveDreamer,在业界引起了广泛的关注。
DriveDreamer是一个生成与理解统一的世界模型架构,基于其高真实度、高效率以及高可扩展性的特点,首先能够实现自动驾驶场景的高效数据生成,用于解决自动驾驶训练的数据短缺,特别是CornerCase难以收集的问题;其次通过与驾驶控制信号的结合,DriveDreamer可以实现高效的数据生成、编辑与交云,从而用于实现端到端自动驾驶的全链路闭环仿真;同时DriveDreamer所具备的场景理解能力,可以扩展实现直接输出端到端的动作指令,成为新一代端到端方案的重要环节。目前,基于DriveDreamer的产品与方案已经在多个主机厂和自动驾驶科技公司实现定点落地,成为广受认可的自动驾驶世界模型方案。
4、学术研究型机构
上海人工智能实验室
上海人工智能实验室近年来为自动驾驶技术的发展做出了很大的贡献。2022年,上海人工智能实验室开源了BEVFormer架构,时至今日依然是自动驾驶行业内最通用的视觉感知算法架构。2023年6月,上海人工智能实验室、武汉大学及商汤科技联合提出的端到端自动驾驶算法UniAD,获得CVPR2023最佳论文,是近十年来计算机视觉顶级会议中第一篇以中国学术机构作为第一单位的最佳论文。受到BEVFormer和UniAD的启发,自动驾驶行业在BEV感知、端到端自动驾驶方面的研究大大加速。
近半年来,上海人工智能实验室还推出利用大语言模型进行闭环端到端自动驾驶的工作LMDrive、自动驾驶视频生成模型GenAD等,上海人工智能实验室从多个技术维度对自动驾驶技术进行探索,从而多方位提升其智能性。同时,上海人工智能实验室还主导了DriveLM(语言+自动驾驶数据集)、GenAD(驾驶视频数据集)、OpenLane(车道线数据集)、OpenScene(3D占用空间预测数据集)多个自动驾驶开源数据集建设,主办了CVPR2023自动驾驶挑战赛、CVPR2024自动驾驶挑战赛,对自动驾驶研究生态的发展起到重要推动作用。
清华大学MARSLab
清华大学MARSLab由前Waymo科学家赵行成立和主导。2021年初,MARSLab提出了视觉为中心的自动驾驶框架VCAD,发表了一系列BEV和端到端自动驾驶的基石研究论文和工作:首个基于Transformer的视觉BEV检测模型DETR3D、首个视觉BEV3D物体跟踪模型MUTR3D、首个基于Transformer的多传感器前融合3D物体检测模型FUTR3D、首个端到端轨迹预测模型ViP3D、首个3D占用网络的评测基准数据集Occ3D等。MARSLab也是最早发表"无图"自动驾驶方案的团队:2021年初,发布首个在线高精度地图模型HDMapNet;2022年初,发布首个矢量高精度地图模型VectorMapNet;
2023年初,开创性地提出了基于众包的先验神经网络的地图模型,实现了自动驾驶地图的记忆、更新、感知一体化。该系列工作为行业指明了技术落地方向,其中合作企业理想汽车将相关技术在其新能源车产品中进行了广泛应用落地:
#爆某Tier1员工退股无门?
近日,据南方一线城市某知名汽车电子Tier1企业多名员工反映,公司内部员工持股平台存在诸多问题,已严重影响员工的合法权益,引发持股员工高度关注与不安情绪。
据悉,该公司自2017年起,以"筹备上市"为契机,面向管理层及核心骨干员工筹集资金,推动设立内部持股计划,意在通过股权激励增强团队凝聚力。然而,截至2025年,公司上市进展始终不顺,相关计划长期搁置,企业前景亦趋于不明朗。
令员工感到忧虑的是,尽管公司在协议中明确规定"在职员工不得退股",却未就未来若无法上市或上市受阻的情况下,如何处理员工持股资金作出具体安排。在缺乏清晰退出机制的背景下,员工投入的资金被长期占用,既未获得股息红利,也无法实现流动退出,利益受损明显。
有部分已离职员工反映,在完成全部离职手续后数月,仍未收到公司按协议退还的股本。也有离职员工表示,即使已签署退股协议,且协议明确规定股本应在限期内返还,公司仍未依约履行相关义务,退股时间严重超期。
据员工提供的内部协议条款显示:"上述财产份额转让或****(公司名字)股份转让均须在相关事实发生或被认定之日起 60 日内完成,该期限的起算日具体如下:退休或工作调动的,为办理完毕退休离职手续或调任手续之日;主动离职的(包括工作满五年或未满五年的),为公司批准其离职申请之日... ..."但多名已离职超过6个月的员工指出,公司并未按照上述约定予以办理退股,相关诉求多次协商无果,公司管理人员仅表示"已上报",却迟迟未有具体答复或进展。
提供的协议截图
另有在职员工透露,目前公司董事会将精力集中于处理部分涉嫌违规代持股权的清理问题,对于离职员工的退股事项,并未列入近期的议程,短期内难有结果。
除股权纠纷外,公司还存在绩效工资发放迟缓等问题。据多位员工反映,公司实行年度绩效考核机制,但截至目前,2024年度绩效工资仍未发放,公司亦未就此作出明确解释或时间安排。
多名员工表示,对自身投入的"血汗钱"能否收回表示深切担忧。一方面,持股多年无任何收益;另一方面,在缺乏合法退出通道的前提下,资金安全和权益保障毫无保障。目前,部分离职员工正持续与公司就退股事宜进行沟通协商,但至今尚无实质性进展。
该事件其实也揭示出企业在员工持股机制设计与治理执行上的重大漏洞。员工资金被长期占用、缺乏清晰的退出机制,且未享受相应收益,已引发广泛不满与信任危机。在资本市场尚未明朗、公司经营压力加大的背景下,若不能依法依约妥善处理员工持股与退股问题,明确回应员工关切,将严重损害企业治理形象与组织稳定性,甚至对未来融资与上市进程形成掣肘。这不仅是一起公司内部治理危机,更是对企业社会责任与法治意识的现实考验,呼吁该公司要深入了解员工心声,及时回应员工关切,稳定队伍,凝心聚力,长期主义,稳健经营,重塑信誉,从而赢得市场,方能保护员工利益,基业长青。
#Phoenix
机器人动作校正自反思框架
构建一个具有泛化能力的自校正系统对于机器人从故障中恢复至关重要。尽管多模态大语言模型(MLLMs)的发展赋予了机器人对故障进行语义反思的能力,但将语义反思转化为 "如何校正" 细粒度的机器人动作仍然是一个重大挑战。为了填补这一空白,我们构建了 Phoenix 框架,该框架利用运动指令作为桥梁,将高级语义反思与低级机器人动作校正联系起来。在这个基于运动的自反思框架中,我们首先采用双过程运动调整机制和多模态大语言模型,将语义反思转化为粗粒度的运动指令调整。为了利用这些运动指令来指导 "如何校正" 细粒度的机器人动作,我们提出了一种多任务运动条件扩散策略,该策略结合视觉观察来实现高频次的机器人动作校正。通过结合这两个模型,我们可以将对泛化能力的需求从低级操纵策略转移到由多模态大语言模型驱动的运动调整模型上,从而实现精确、细粒度的机器人动作校正。利用这个框架,我们进一步开发了一种终身学习方法,通过与动态环境的交互自动提升模型的能力。在 RoboMimic 仿真环境和现实场景中进行的实验证明了我们的框架在各种操纵任务中具有卓越的泛化性和鲁棒性。我们的论文已被CVPR2025接收,相应的代码将会在https://github.com/GeWuLab/Motion-based-Self-Reflection-Framework上发布。
人类具备通过反思失败行为来纠正自身行为的能力,能从高级语义反思和低级动作校正角度分析失败情况以适应动态环境,研究人员为模仿这种能力,试图开发能让机器人从失败交互中恢复并学习的自反思系统。现有的一些自校正系统利用强化学习指导机器人执行低级动作,但因训练不稳定和需先验知识,在长周期操纵任务中泛化能力受限。最近研究借助多模态大语言模型推理能力提出故障校正的闭环高级语义反思框架,虽能分解故障校正过程,但因主要依赖预定义技能库执行子目标,使多模态大语言模型在细粒度机器人动作校正中的泛化能力未充分发挥。为最大化多模态大语言模型在动作校正中的泛化潜力,提出将运动指令(如 "向后移动手臂""调整夹爪位置" 等粗粒度机器人运动命令)作为桥梁,将高级语义反思转化为细粒度机器人动作校正,运动指令作为中间层可提供通用低频决策信息,是融入知识的理想媒介 。如图 1 所示,我们将语义反思知识分解为粗粒度的运动指令调整,以指示低级策略执行时 "如何校正" 细粒度动作。这一转变将感知和决策要求从低级机器人策略转移到由多模态大语言模型驱动的运动调整模型上,从而实现具有泛化性的细粒度机器人动作校正。
因此,在这项工作中,我们构建了基于运动的自反思框架 Phoenix,目的是将多模态大语言模型的语义反思转化为细粒度机器人动作校正。我们开发了双过程运动调整机制,包括运动预测模块和运动校正模块。前者通过专家演示轨迹训练,能高效生成运动指令,但处理故障场景能力不足;后者收集全面故障校正数据集并微调,以思维链方法提供调整后的运动指令,二者整合保证了鲁棒性和效率,有助于生成准确运动指令。我们还设计了多任务运动条件扩散策略,因粗粒度运动指令提供的是通用低频指导,该策略结合视觉观察,将运动指令转化为操纵任务的精确高频动作校正。最后,我们提出了终身学习方法,利用校正轨迹,通过交互迭代增强模型能力,确保性能持续提升和对动态环境的适应。
为了验证我们框架的有效性,我们在 RoboMimic 仿真环境中对 9 个需要频繁接触的机器人操纵任务进行了实验。结果表明,我们的方法可以通过自我反思更精确地从故障中校正动作,并通过与环境的交互实现自我提升。此外,我们进行了两个具有颜色干扰和位置分布干扰的新操纵任务,证明了我们框架的泛化能力。实际场景中的实验也证明了我们方法的适用性和鲁棒性。
基于运动的自反思框架
机器人自校正模型面临的挑战
构建一个具有泛化性和鲁棒性的自校正系统是实现机器人故障校正的关键组成部分。多模态大语言模型已被应用于机器人自反思框架的构建,以帮助机器人从故障中恢复。然而,现有系统主要侧重于语义反思,将其应用于细粒度动作校正仍面临以下两个问题:
- 如何使多模态大语言模型理解操纵任务并提供详细的校正信息?
- 如何将多模态大语言模型提供的校正信息转化为精确的高频机器人动作?
为了解决这些问题,我们提出了 Phoenix 框架,这是一个基于运动的自反思框架,它集成了双过程运动调整机制和多任务运动条件扩散策略。
双过程运动调整机制
过程运动调整机制旨在通过运动预测模块确保高效的运动预测,同时利用运动校正模块全面处理故障情况。给定观察值 o 和任务描述 T,我们首先使用专家演示数据集训练运动预测模块(MPM),以生成初始运动指令。然而,在专家演示数据上训练的运动预测模块在处理故障情况时存在困难。因此,我们构建了一个全面的故障校正数据集,对运动校正模块(MCM)进行微调,使其能够分析故障情况,并通过思维链的方法调整。如果被认为是正确的,我们将其作为决策运动指令,用于进一步的机器人动作预测。否则,我们使用运动校正模块分析故障情况,并生成调整后的运动指令作为决策运动指令。在的指导下,我们基于运动的扩散策略可以生成对机器人动作的高频校正。
运动预测模块(MPM)
为了充分利用多模态大语言模型的感知和决策能力来高效预测运动指令,我们从专家演示数据集中开发了一个运动指令数据集,对多模态大语言模型进行微调,以适应机器人操纵任务。为了构建专家数据集,我们通过阈值过滤机器人动作,从专家演示中获取主导运动,生成一组包括手臂方向和夹爪控制的运动指令。在实践中,我们发现将手臂方向指令和夹爪控制指令分开会导致文本运动指令与细粒度机器人动作之间的不一致。为了解决这个问题,我们将方向运动与夹爪控制相结合,形成统一的运动指令格式,如 "夹爪闭合时向右移动手臂"。此外,我们添加了 "对夹爪位置进行轻微调整" 的指令,以模拟低于阈值的微小机器人动作。通过这种自动构建方法,我们构建了 37 种运动指令,为进一步的机器人动作预测提供指导。通过在专家数据集上进行训练,运动预测模块能够理解机器人操纵任务,并可以高效地生成初始运动指令。
运动校正模块(MCM)
机器人在与环境交互时可能执行错误动作致任务失败,在成功专家数据上训练的运动预测模块难从失败场景恢复,因此,我们开发了运动校正模块,用于识别失败场景并纠正行为。如图 2(a)所示,该模块会评估初始运动指令,遇到失败情况时先分析失败类型得出语义校正目标,再利用故障校正知识调整运动指令,最终通过分层思维链生成准确指令。
为使运动校正模块具备故障检测和校正能力,构建了全面校正数据集,如图 3 所示。这个数据集包含三种反馈数据:
- 在线人工干预:采用人在回路方法收集轨迹数据,在智能体失败时手动干预校正指令,能收集高质量数据确保任务完成,但需频繁人工交互,耗时且难收集大规模数据。
- 离线人工标注:用运动预测模型收集轨迹数据并采样,标注语义反思和运动校正信息,虽准确性无法保证,但能提供大量标注数据。
- 专家演示:对专家轨迹自动标注,这些成功轨迹提供准确运动信息增强模型运动预测能力。
在数据集上微调运动校正模块,增强其对失败情况的理解及指令校正能力,整合运动预测模块和运动校正模块,使双过程运动调整机制既能高效生成指令,又能在失败时全面校正。
运动条件扩散策略
由于运动指令只为操纵提供通用和低频的指导,我们训练了一种多任务运动条件扩散策略 π,将运动指令转化为精确的高频机器人动作。该策略以观察值 o 和决策运动指令作为输入,输出机器人动作 a。为了确保该策略遵循运动指令,我们进行了如图 2(b)所示的调整: 首先,我们发现现有的预训练语言模型往往难以捕捉各种运动指令的判别特征。这一限制阻碍了它们遵循不同运动指令的能力。为了解决这个问题,我们引入了一个可学习的运动码本,旨在为运动指令提供判别特征。对于给定的决策运动指令,码本会检索相应的运动特征,以促进准确的机器人动作预测。
此外,我们发现直接连接观察表示和运动指令特征会导致扩散策略更倾向于依赖视觉信息进行动作预测,从而阻碍了运动指令指导的有效性。为了解决这个问题,我们在扩散策略的不同阶段将观察表示和运动指令特征作为单独的条件,使模型能够更好地学习运动指令的指导信息,进而促进精确的动作校正。
通过整合这两个调整,我们使用以下损失函数训练用于动作预测的扩散策略:
其中 O 是观察表示,M 是运动指令特征,是真实的机器人动作,表示去噪迭代 k 时的随机噪声。通过最小化公式 1 中的损失函数,扩散策略 π 可以有效地预测由运动指令指导的精确高频机器人动作。
用于终身学习的动作校正
双过程运动调整机制利用运动预测模块高效预测运动指令,并利用运动校正模块通过全面的思维链方法对其进行调整。然而,由于思维链方法耗时,对其的依赖给适应实时场景带来了挑战。此外,操纵数据和校正数据的收集非常耗费人力。因此,我们提出了一种终身学习方法,通过从优化后的交互轨迹中学习,使运动预测模块同时具备运动预测和故障校正能力,如图 2(c)所示。这增强了我们的模型在无需人工干预的情况下适应环境并快速反应的能力。
得益于运动条件扩散策略能够遵循运动指令生成任务感知的机器人动作,我们可以通过仅改进由优化后的交互轨迹提供信息的运动预测模块来提升机器人的能力。为了解决灾难性遗忘的问题,我们将优化后的交互轨迹与专家演示混合进行联合微调,使模型能够同时学习故障校正并增强运动预测能力。通过优化后的交互轨迹的更新,我们的模型可以从运动校正模块的知识中学习,实现自我提升,从而在需要频繁接触的操纵任务中实现快速准确的操纵。
实验分析
为了全面评估我们的框架,我们设计实验来回答以下问题:
- 我们的运动引导自反思模型是否提高了动作校正的精度?
- 我们的模型能否通过与环境的交互实现终身学习?
- 我们的框架能否在新任务中实现泛化?
- 我们的框架能否在现实场景中确保可靠性和鲁棒性?
实验设置
在这项工作中,我们在 RoboMimic 中对 9 个需要频繁接触的操纵任务进行了实验,涵盖从像 "三件套组装" 这样的长周期任务到像 "穿线" 这样的细粒度操纵任务。为了将高级语义信息转化为运动指令,我们过滤专家演示,获得了超过 160,000 对运动指令和观察值。该数据集包含 37 种运动指令,用于对 LLaVA-v1.5 模型进行微调,将其作为运动预测模块。此外,为了开发集成语义理解和运动指令调整的运动校正模块,我们收集了校正数据,包括 3,644 个在线人工干预数据、7,365 个离线人工标注数据和 6,378 个专家演示数据。我们对校正数据集进行筛选,以平衡各种失败情况的比例,提升模型的校正能力。最后,为了将运动指令转化为精确的机器人动作,我们使用一个可学习的运动指令码本训练了一个多任务运动条件扩散策略,每个任务包含 500 个演示数据。在仿真推理过程中,我们的双过程运动调整机制将以 5Hz 的频率提供运动指令,扩散策略会结合视觉观察将运动指令扩展为 20Hz 的动作序列来控制机器人。对于每个任务,我们进行了 50 次试验,并报告平均成功率。
运动自反思模型的性能
对比结果。 为了评估我们基于运动的自反思框架,我们将其与其他方法进行比较。为确保公平性,所有对比方法均在仿真环境的专家数据上进行训练,决策模型使用 LLaVA-v1.5,底层策略采用扩散策略。
- OpenVLA:对 OpenVLA 模型微调,为多任务实验提供基线性能。
- 任务条件策略:将任务描述作为扩散策略的条件,不使用反思框架,是 RT-1 和 Octo 的变体。
- 子目标条件策略:对 LLaVA-v1.5 微调,以 5Hz 频率预测子目标并作为扩散策略条件,不使用反思框架,借助多模态大语言模型语义理解能力,是 PaLM-E 的变体,采用单独扩散策略。
- 运动条件策略:对 LLaVA-v1.5 微调作为运动预测模型,以 5Hz 频率提供运动指令并作为扩散策略条件,不使用反思框架,利用多模态大语言模型感知和推理能力,是 RT-H 的变体,采用单独扩散策略。
- 人工干预:手动校正运动条件策略中错误的运动指令,为自反思方法性能提供上限,结果以 10 次试验平均成功率呈现。
- 子目标自反思:对 LLaVA-v1.5 微调作为子目标自反思模型并应用于子目标条件策略,验证语义自反思模型的有效性。
如表 1 所示,我们首先比较了三种不同的条件设定方法。借助多模态大语言模型的感知和推理能力,子目标条件策略和运动条件策略优于任务条件策略。结果证明了多模态大语言模型在各种复杂机器人操纵任务中的潜在应用。
聚焦于特定任务,我们观察到运动条件策略在诸如 StackThree D0 和 ThreePieceAssembly D0 等长周期任务中表现出色。然而,该策略依赖于一致且准确的运动指令预测,这在像 Threading D0 这样的细粒度操纵任务中面临挑战 。
通过提供校正子目标,子目标自反思方法始终优于子目标条件策略,特别是在诸如 "StackThree D0" 这样的长周期操纵任务中,这证明了自反思框架的有效性。
OpenVLA 模型在某些长周期任务中表现出强大的性能,利用其端到端的动作令牌预测能力。然而,缺乏观察历史和动作分块在处理像 Threading D0 这样复杂的细粒度操纵任务时带来了重大挑战。
值得注意的是,我们的 Phoenix 方法比子目标自反思方法取得了更大的改进,证明了运动条件方法在长周期顺序任务和细粒度操纵任务中的有效性。受益于我们基于运动的校正方法,智能体可以通过运动指令调整来校正细粒度动作,而子目标条件自反思模型在大多数失败情况下无法恢复。此外,人工干预方法在多个任务中实现了高成功率,表明我们的运动条件扩散策略可以有效地遵循运动指令进行操纵任务。这一结果表明我们的方法在正确的运动指令下可以表现良好,展示了运动条件自反思的巨大潜力。
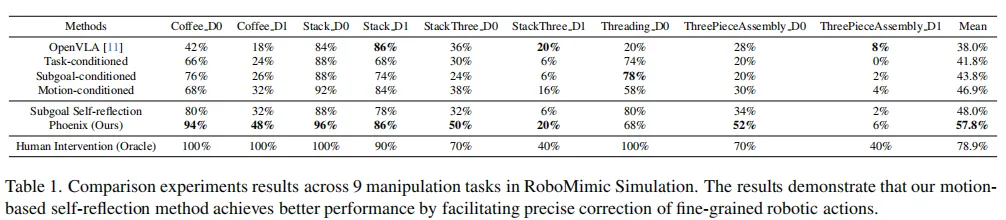
消融实验结果
在这项工作中,我们提出了一个运动预测模块来提供初始运动指令,以及一个运动校正模块来提供细粒度的运动校正。根据先前的研究,数据混合比例可能会影响大语言模型的效果。在本节中,我们研究将专家演示与校正数据集相结合,是否也能增强多模态大语言模型在机器人操纵中的感知和决策能力,采用以下消融实验方法:
- 专家 - 校正混合:我们将专家演示和校正数据混合,共同训练运动预测模型。
- 带自反思的专家 - 校正混合:我们将专家演示和校正数据混合,共同训练一个统一的模型,以提供初始运动指令并调整指令。
如表 2 所示,结果表明,与仅在专家演示数据上训练的模型相比,使用混合数据进行联合训练的模型性能更优。这表明结合各种类型的反馈数据可以增强多模态大语言模型的决策和感知能力。这也验证了我们通过交互实现自我提升方法的可行性。
此外,带有自反思的混合训练模型比没有自反思的模型表现更好,这表明我们设计的基于运动的自反思方法可以增强机器人的决策能力,并有助于校正细粒度动作。
然而,我们发现,与我们分离的运动校正模块相比,使用混合数据训练一个统一的模型,同时作为运动预测模块和运动校正模块,无法提供准确的校正信息。这表明在数据规模差异较大(160,000 个专家演示数据与 16,000 个反馈数据)的情况下,混合训练策略可能无法充分利用每个数据集的优势来实现更好的校正效果。结果表明,我们的双过程运动调整机制可以有效地利用专家演示和校正数据集,实现准确的运动指令调整。

终身学习的性能
我们探索我们的 Phoenix 框架是否可以通过交互促进终身学习。具体操作是部署运动自反思模型在环境中交互,在 10 次、30 次和 50 次滚动后,利用成功轨迹迭代微调运动预测模型,为避免灾难性遗忘,结合 20 个专家演示共同微调运动预测模块。
实验比较了基于运动的自反思模型和基于子目标的自反思模型的终身学习能力,测试时记录 50 次试验的平均成功率。如图 4 所示,结果表明,基于子目标的终身学习在探索阶段因无法提供细粒度动作校正而不能提升模型性能,而基于运动的方法(Phoenix 框架)能在交互中校正底层动作执行,让机器人更好地从优化后的轨迹中学习实现自我提升。
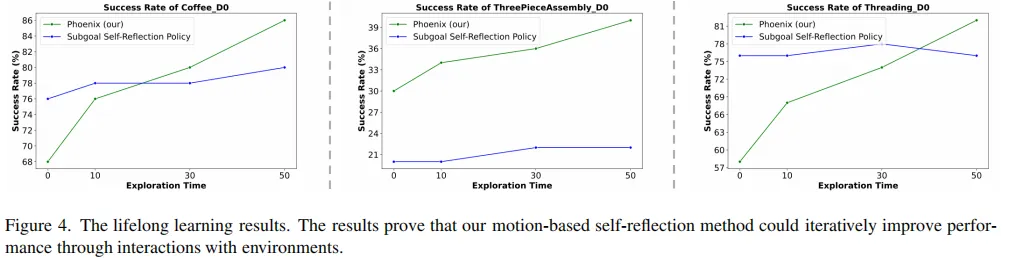
对新任务的泛化能力
在本节中,我们评估我们的 Phoenix 框架在颜色干扰和位置干扰新任务中的泛化能力,如图 5 所示。在颜色干扰设置中,我们将 Stack D0 任务中的红色方块替换为蓝色方块,以验证我们的模型是否可以泛化到具有不同视觉特征的物体操纵任务。在位置干扰设置中,我们将 Coffee D0 任务中咖啡机的固定位置更改为特定区域内的随机位置,以验证我们的方法是否可以泛化到未见过的场景。
对于这些新任务,尽管子目标条件策略可以预测正确的高级语义子目标用于操纵,但该方法无法预测精确的机器人动作来完成任务。由于提供高级语义校正信息的局限性,子目标自反思方法无法有效地利用多模态大语言模型的知识进行操纵任务的动作校正。相比之下,如图 5(c)所示,我们的运动条件策略受益于多模态大语言模型的感知和推理能力,可以生成细粒度的运动指令,实现泛化操纵。此外,我们的方法通过基于运动的自反思框架全面优化运动指令,在新任务中可以实现更好的性能。
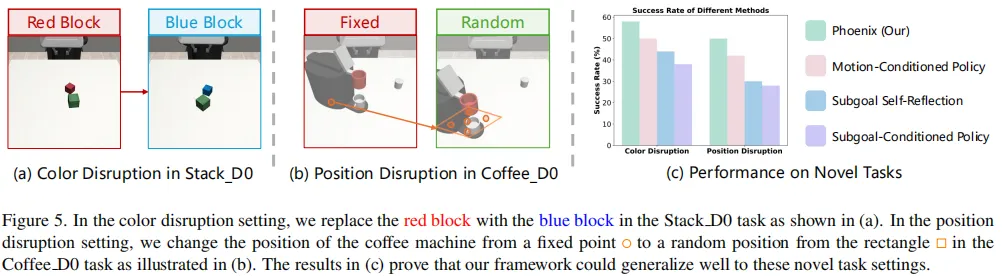
现实世界实验
在现实世界场景中,我们进行了具有挑战性的 "打开抽屉" 关节物体操纵任务,如图 6(a)所示,机器人需要通过精确的旋转使夹爪与把手对齐来打开抽屉。我们使用空间鼠标设备收集了 100 个带有 14 种运动指令(例如 "向右移动手臂"、"绕 x 轴旋转")的专家演示。我们训练了一个运动条件扩散策略,将指令转化为机器人动作。在推理过程中,我们引入人在回路的干预,手动校正失败情况,收集 20 个相应的优化交互轨迹,以训练我们的运动校正模块。所有模型仅在现实世界数据上进行微调。

为了验证泛化能力,我们设计了 4 种设置,如图 6(b - e)所示。在姿态干扰设置中,我们改变抽屉的姿态分布。在背景干扰设置中,背景颜色被修改为绿色。在纹理干扰设置中,改变抽屉的纹理,以评估在显著视觉变化下的性能。表 3 中的结果证明了我们方法的泛化能力。我们还评估了终身学习,表 4 中的结果表明我们的模型在现实世界中实现了自我提升。
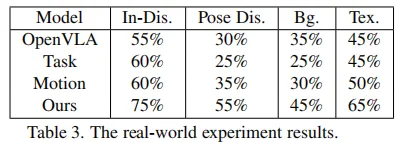
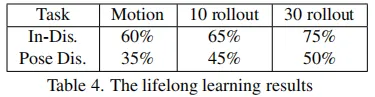
总结
在这项工作中,我们提出了一种基于运动的自反思框架,将多模态大语言模型的语义反思转化为细粒度的机器人动作校正。基于这个框架,我们进一步通过交互自动提升模型的能力。我们希望这个基于运动的自反思框架能够为通过集成多模态大语言模型来增强机器人操纵任务中智能体的泛化能力带来启发。
参考
1 Phoenix: A Motion-based Self-Reflection Framework for Fine-grained Robotic Action Correction
#ARTEMIS
爆拉Hydra-MDP++!:混合专家模型MoE问鼎端到端轨迹规划SOTA~
本文提出了 ARTEMIS,这是一种结合自回归轨迹规划与专家混合(Mixture-of-Experts, MoE)的端到端自动驾驶框架。传统的模块化方法存在误差传播问题,而现有的端到端模型通常采用静态的一次性推理范式,难以捕捉环境的动态变化。ARTEMIS 通过按顺序生成轨迹航点的方法,保留了关键的时间依赖性,同时将场景特定的查询动态路由到专门的专家网络。这种方法有效缓解了引导信息模糊时遇到的轨迹质量退化问题,并克服了单一网络架构在处理多样化驾驶场景时固有的表示能力限制。此外,我们还使用了一种轻量级的批量重分配策略,显著提高了专家混合模型的训练速度。通过在 NAVSIM 数据集上的实验,ARTEMIS 展示了优越的竞争性能,在 ResNet-34 主干网络下实现了 87.0 PDMS 和 83.1 EPDMS,表现出SOTA性能。
文章简介
自动驾驶在过去几十年中经历了快速发展。传统的模块化方法将自动驾驶任务划分为诸如感知、预测和规划等离散模块。然而,这些模块之间的累计误差和复杂的相互依赖关系可能会受到预定义接口的限制。端到端模型通过直接将原始传感器数据映射到计划轨迹或控制信号来克服这些问题 。
然而,它们静态的一次性推理范式通常无法捕捉环境的动态变化(图 1(a))。相比之下,自回归方法按顺序生成轨迹,保留了时间一致性,并允许根据先前计划的片段进行适应性决策。自回归模型已广泛应用于轨迹预测领域。最近的研究已经开始探索统一框架,该框架通过自回归建模方法同时完成世界模型构建和完整或部分轨迹规划任务。
然而,目前的问题是单网络端到端模型仍然难以充分捕捉和适应多样化的驾驶场景。为了解决轨迹规划中的固有复杂性,研究人员越来越多地采用诸如专家混合(Mixture of Experts, MoE)框架等复杂架构。
MoE 利用多个专业专家网络以及智能路由机制,动态分配和处理输入------这一策略在大规模语言模型中取得了显著成功。在自动驾驶中,端到端模型生成的规划轨迹本质上包含了多种潜在的行为模式,反映了驾驶行为的根本不确定性。驾驶员可以在相同环境条件下选择几种合理的未来行动(图 1(b)) ,而传统单网络架构难以准确表征这种内在的行为多样性。相反,MoE 使得专家模块能够专注于特定的驾驶场景或行为模式,从而在不依赖预定义指导信号的情况下学习驾驶行为的特征分布。
这种内生多模态建模方法有效地避免了当指导信息偏离实际情况时可能出现的轨迹质量退化问题。最近,扩散模型(图 1(c))向自动驾驶引入了新颖的生成建模范式,展示了增强的轨迹多样性。尽管这些方法在端到端自动驾驶中建立了最先进的性能,但它们通常采用静态范式,同时生成所有轨迹点(或通过多次去噪迭代),限制了它们准确捕捉轨迹发展的动态演化特征的能力。
相比之下,利用 MoE 的自回归方法展示了优越的时间序列捕捉能力、环境适应性和实用性,因为它们可以在不需要强先验约束的情况下运行。为了解决这些问题,我们提出了 ARTEMIS,即自回归端到端轨迹规划与专家混合在自动驾驶中的应用,如图 2 所示。ARTEMIS 包括三个主要组件:感知模块、具有 MOE 的自回归规划模块和轨迹优化模块。
感知模块采用 Transfuser,利用单独的骨干网络处理图像和 LiDAR 数据,最终将其融合成 BEV 特征表示。具有 MOE 的自回归规划模块通过顺序决策过程逐步生成轨迹航点,同时动态选择最适合当前驾驶场景的专家网络。此外,它还基于专家激活模式实施批量重新分配。最后,轨迹优化模块处理并优化自回归轨迹输出。我们使用 NAVSIM 数据集对 ARTEMIS 进行了全面评估。我们的贡献可总结如下:
- (1) 据我们所知,本文首次将专家混合(MoE)引入端到端自动驾驶,在动态路由机制和专业化专家网络划分的帮助下,有效缓解了传统方法在指导信息模糊时遇到的轨迹质量退化问题,以及单一网络架构在处理多样化驾驶场景时固有的表示能力限制。
- (2) 我们提出了一种自回归端到端规划方法,该方法通过迭代决策过程逐步构建轨迹,实现轨迹航点之间强时间依赖性的精确建模。
- (3) 我们的方法在大规模真实世界的 NAVSIM 数据集上取得了显著结果。使用相同的 ResNet-34 主干网络,我们的方法在标准指标下达到 87.0 PDMS,在扩展评估指标下达到 83.1 EPDMS。
ARTEMIS算法详解
A. 预备知识 1) 端到端自动驾驶
端到端自动驾驶系统旨在将原始传感器数据直接映射到车辆轨迹。形式上,我们将端到端自动驾驶定义为一个条件序列生成问题,其中输入是一系列历史传感器观测值 ,其中 表示历史时间范围。模型需要生成未来时间点的轨迹序列 ,其中 表示预测时间范围。每个点 ,其中 表示每个航路点的维度,包含位置和方向等信息。端到端模型的目标是学习条件概率分布 。
对于自回归模型,我们可以将条件概率分布分解如下:
其中 表示在时间 之前生成的所有轨迹点。这种分解使得模型在生成每个新航路点时能够考虑先前生成的轨迹,从而保持轨迹的时间一致性。
在一个典型的端到端模型中,传感器数据 首先通过特征提取网络 转换为潜在表示 ,然后使用轨迹生成网络 映射到最终轨迹 。
2) 专家混合(Mixture of Experts, MoE)
MoE 设计用于通过利用多个专家网络和智能路由机制来动态处理复杂输入数据,使计算资源和网络模型能够动态分配。在这项研究中,我们采用了类似于 Deepseek-MoE 的设计 20,其中一些专家被指定为共享专家以捕捉可泛化的知识,并减少路由专家的冗余性。给定输入 ,其中 表示序列长度, 表示特征维度,我们的 MoE 输出可以形式化为:
其中 表示共享专家, 表示领域特定专家, 表示专家网络总数。第 个专家的计算函数由 给出,门控神经网络通过函数 为第 个专家分配权重。
B. 模型架构
1) 感知模块
感知模块遵循 Transfuser 的设计 14,负责从原始传感器数据中提取特征。该模块采用多模态融合策略同时处理图像和点云数据,从而构建统一的环境表示。具体而言,该模块包括两个并行的特征提取器,通过 Transformer 在不同阶段进行特征融合。
该模块利用点云数据 和前视图图像数据 ,并通过一系列卷积层和 ResNet-34 主干网络提取视觉特征(例如 和 )。最后,采用多模态融合机制将这些特征整合为鸟瞰图(Bird's-Eye View, BEV)特征表示 。
2) 带有专家混合的自回归规划模块
与传统的一次性方法不同,本研究采用自回归策略逐步构建轨迹,同时集成专家混合(Mixture-of-Experts, MoE)架构。这种设计结合了先前轨迹信息以及基于场景特征动态选择的专业专家网络。
对 navtrain 数据集的分析显示,驾驶命令的分布存在显著不平衡(左转命令超过 20,000 个样本,右转命令少于 10,000 个样本,直行驾驶命令超过 50,000 个样本)。此外,我们观察到一小部分训练样本中的驾驶命令与专家轨迹之间存在差异(如图3所示)。仅依赖驾驶命令进行专家选择可能导致某些专家缺乏足够的训练数据,并且无法捕捉驾驶策略的多样性。最终,我们采用了一种内生路由多模态建模方法,以有效缓解这些问题。
为了避免模型偏向于直接从历史自我轨迹学习规划,这可能导致因果混淆等问题 25,26。我们仅将当前自我状态 (包括控制命令、二维速度和加速度)编码到特征空间 中,通过 MLP 实现。
位置和时间嵌入
通知模型轨迹点计划的具体时间步长至关重要。对于未来规划时间步长 ,我们使用嵌入层获得规划时间嵌入,记作 。类似地,我们使用位置嵌入将位置信息纳入规划序列,记作 。需要注意的是,我们在第一次自回归步骤期间仅向初始化的规划序列添加位置嵌入,以避免因重复添加嵌入信息而引入额外噪声。
自回归生成
首先,我们向完整的当前规划序列添加位置嵌入以实现初始化。然后,该序列被输入带有填充掩码 的 Transformer 编码器,以更新规划查询 。填充掩码确保规划查询在当前时间步只与序列中的历史规划查询交互。通过构造一个集成规划时间信息、自我状态以及当前和历史规划查询的连接查询,我们得到 。这个连接查询随后被输入带有批次重分配的 MoEBlock,与 BEV 特征交互,以获取当前时间步的规划查询。
最后,为了进一步刻画驾驶行为的内在不确定性,我们采用了一种概率建模方法。一个多层次的 MLP 网络用于预测多模态轨迹点的分布,包括位置和航向。最终,通过从预测分布中采样生成当前规划时间步的轨迹点 。在生成轨迹点后,在规划查询序列中更新对应于当前时间步的最新规划查询。最后,将各个轨迹点串联形成初始轨迹。
批次重分配 MoE
如图 4 所示,该模块包括共享专家 和领域特定专家 。我们使用一种高效的批次重分配策略,显著提高了大规模数据处理时的计算效率。为了确保路由网络的固定查询维度,我们从连接查询中移除历史规划查询,形成路由查询 。路由网络 包括两个 MLP,用于计算专家分配得分 。第一个 MLP 对输入特征进行降维,第二个 MLP 将压缩后的特征映射到专家得分。这种两阶段设计有效地平衡了计算成本与路由决策质量。
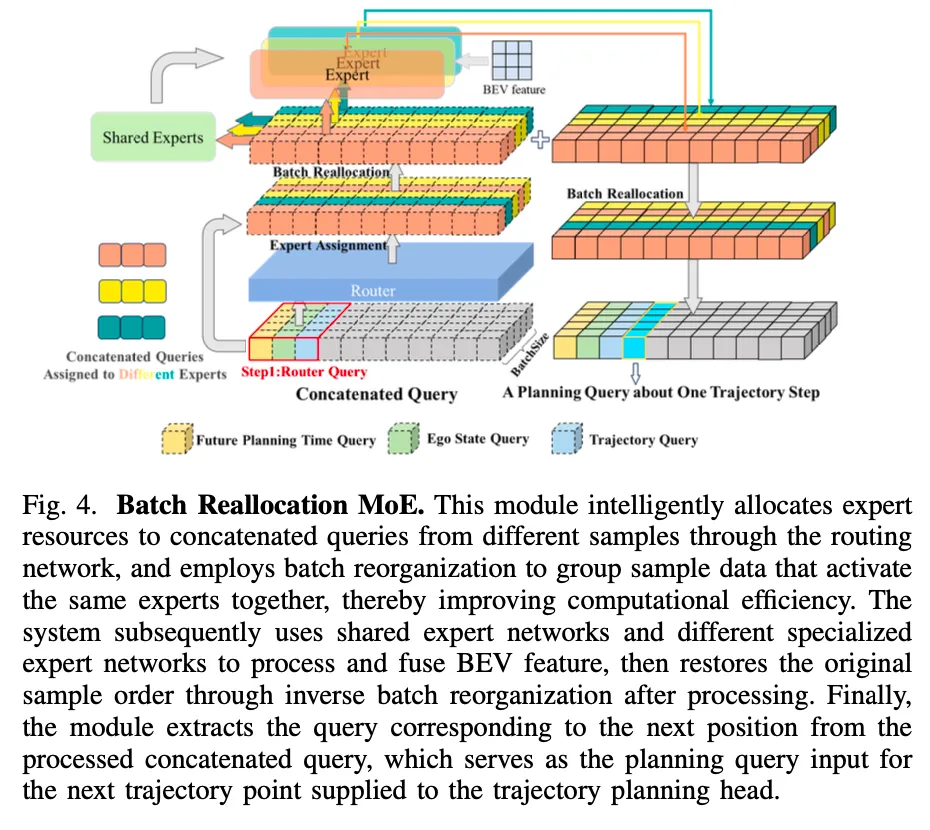
为了使模型在训练期间专注于最相关的专家,我们还采用了一种稀疏激活策略,仅选择得分最高的 个专家。对于每个选定的专家索引序列向量 ,我们执行一系列操作,包括批排序、数据重组和块识别。具体而言,我们根据专家索引对批量样本进行排序,得到排序函数 。随后,根据此排序函数重新构造 BEV 特征和连接查询如下:
基于专家索引模式,连续相同专家索引的块被识别并匹配:
其中 表示块的总数, 表示第 个专家在第 个专家索引序列向量中的连续块, 表示通过唯一连续函数确定的相应块大小。适用于每个块的适当专家网络,其中 和 构成块 在专家索引序列向量 下的重组专家输入数据。
其中 表示第 个专家在第 个专家索引序列向量中对应的连续块的起始位置。
最后,专家处理结果恢复到其原始批次顺序,并根据不同专家的相应权重 融合输出,以得出最终合成输出 。
3) 轨迹优化模块
考虑到驾驶场景本质上复杂且通常包含与规划无关甚至构成噪声的信息,我们引入了一个轨迹优化模块。优化过程确保最终轨迹 满足运动学约束、避障并保持平滑性。此过程分为两个阶段:语义运动学优化和交叉注意力优化。
语义运动学优化
在语义优化阶段,我们从 BEV 语义地图 中提取特征以获得语义特征 ,其中 是主要通过多层卷积网络实现的语义编码器。我们使用 GRU 网络编码初始轨迹以获得轨迹特征 ,随后将语义特征 和 输入优化器网络 ,以获得联合表示 。
解码部分通过融合特征逐点优化轨迹点。对于每个轨迹点,使用 GRU 和输出层 生成优化点 。在运动学优化阶段,采用多种显式约束来优化生成的轨迹点,包括平滑性约束和运动学约束,并为这些约束分配可学习的权重。从语义运动学优化中获得的最终优化点记为 。
交叉注意力优化
我们利用级联交叉注意力模块进一步增强轨迹与场景上下文之间的交互,使轨迹特征能够与代理特征和自我规划特征交互。
其中 表示代理查询特征, 表示自我规划查询特征, 是优化函数。
4) 训练损失
与一些端到端自动驾驶方法一致,我们采用分阶段训练方法以减轻训练不稳定性 4,5,15,27。具体而言,首先训练感知网络及其辅助任务,包括语义映射和目标检测。随后,整个网络以端到端方式进行训练。这种训练策略显著提高了模型的稳定性和整体性能。此外,我们选择不采用 MoE 架构中常用的专家平衡损失,因为其在具有不平衡特征分布的数据集中应用可能会阻碍个别专家获取专业战略知识。
感知阶段损失
在第一阶段,我们专注于优化感知相关的辅助任务。总损失定义为:
其中 是 BEV 语义地图的交叉熵损失, 和 是使用匈牙利匹配算法计算的代理分类和定位损失。
端到端训练损失
在此阶段,整个网络以端到端方式进行训练。总体损失定义为:
其中 表示规划 L1 损失, 表示负对数似然损失。
实验结果分析
A. 数据集
我们在 NAVSIM 数据集上进行训练和测试。NAVSIM 从 OpenScene 数据集 中选取了具有挑战性的场景,排除了简单的驾驶情境。训练集包含 1192 个场景,测试集包含 136 个场景。数据集中的每个样本包括来自 8 个视角的相机图像、融合自 5 个传感器的 LiDAR 数据、地图标注信息以及 3D 目标边界框等其他数据。
在 NAVSIM 数据集中,模型需要使用 4 帧(共 2 秒)的历史与当前数据来规划一个由未来 8 帧组成的 4 秒轨迹。
B. 评估指标
已有众多研究表明,仅通过简单的开环评估不足以全面衡量模型性能,而闭环评估由于计算成本高昂及仿真器与真实世界存在差异,应用受到限制。NAVSIM 提供了一种介于两者之间的评估方案,即预测驾驶模型评分(Predictive Driving Model Score, PDMS),该评分与闭环指标高度相关。PDMS 基于五个指标计算:无碰撞(No-Collision, NC)、可行驶区域合规性(Drivable Area Compliance, DAC)、碰撞时间(Time-to-Collision, TTC)、舒适度(Comfort, C)和自车进展(Ego Progress, EP)。
除了 PDMS,NAVSIM 还提供了一个扩展基准------扩展预测驾驶模型评分(Extended Predictive Driving Model Score, EPDMS)。该扩展评分引入两个新的加权指标(车道保持 LK 和扩展舒适度 EC)、两个新的乘法指标(行驶方向合规性 DDC 和交通灯合规性 TLC),以及一个误报惩罚机制。
C. 实现细节
我们采用 Transfuser作为感知网络,以 ResNet-34 作为特征提取主干。感知模块输入包括前左、前、前右摄像头拼接的图像,以及覆盖 64m × 64m 区域的点云数据。
在集成 MoE 的自回归规划模块中,我们配置了 E_private = 5 个领域特定专家和 E_shared = 1 个共享专家。在前向传播过程中,选择得分最高的 K = 2 个专家进行激活。
模型在 navtrain 分割上使用两块 A100 GPU 进行训练,批量大小为 128。初始学习率为 2×10⁻⁴,权重衰减为 1×10⁻⁴。模型执行 8 次自回归步骤,每步输出一个轨迹点(x, y 和航向)。所有自回归步骤完成后,生成的轨迹将被优化为 2Hz 的 4 秒规划轨迹。
在感知模块训练阶段,损失权重系数 λ_sem、λ_class 和 λ_box 分别设置为 10、10 和 5。在端到端训练阶段,权重系数 λ_sem、λ_class、λ_box、λ_traj、λ_var 和 λ_NLL 分别设置为 2、2、1、15、0.01 和 0.5。
D. 主要实验结果
定量结果
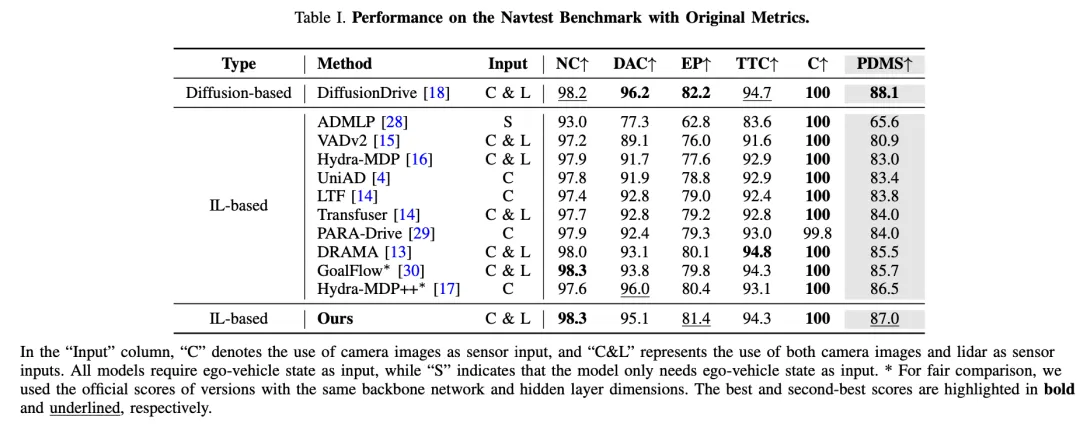
在 Navtest 基准上,我们将 ARTEMIS 与多个最先进的方法进行了对比,结果总结在表 I 中。使用 ResNet-34 主干时,ARTEMIS 在 navtest 分割上达到了 87.0 PDMS,在大多数模型中表现出竞争力。值得注意的是,ARTEMIS 在 EP、NC 和 C 指标上显著优于其他方法,表明其强大的轨迹规划能力和环境适应能力。
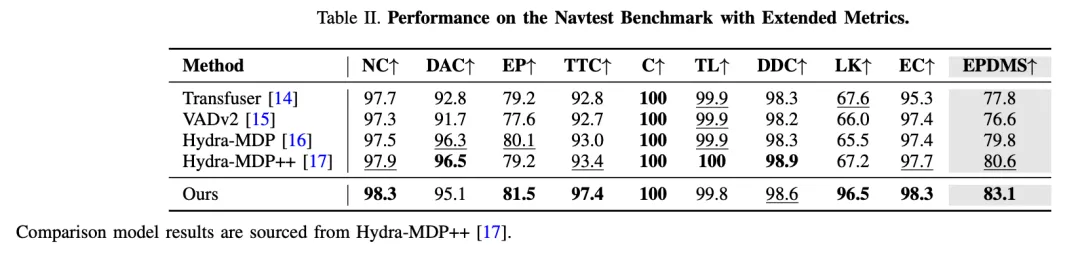
我们进一步在 Navtest 基准上使用扩展指标对 ARTEMIS 进行了评估(见表 II)。结果显示,在使用同样 ResNet-34 主干的情况下,我们的方法显著优于所有基线模型,达到最先进的性能(SOTA)。特别是,我们的方法在 TTC 和 EP 等关键指标上明显优于其他方法,这些结果突出了 ARTEMIS 在多种评估标准下的鲁棒性和优越性能。
定性结果
图 5 展示了从 navtest 数据集中采样的四个代表性驾驶场景,用于定性评估所提出的方法。为了突出不同专家对同一场景的响应,每个领域特定专家生成的轨迹用不同颜色绘制。
第一个例子(图 5a)展示了自车通过交叉路口的情景,专家行为分为左转或直行两种情况。经过路由网络融合处理后的轨迹优先选择了橙色专家的直线路径。
图 5b 中,当自车接近 T 形路口时,黄色专家选择右转,而其余专家选择继续直行。经过路由网络融合处理后的轨迹则融合了黄色专家的结果。
图 5c 和图 5d 展示了另外两个场景:绕行环岛和车道入口选择。在图 5c 中,除红色专家外,其他专家错误地选择向右前方行驶,而红色专家成功捕捉到了环岛道路特征并正确绕行。最终的规划轨迹主要参考了红色专家的解决方案,体现了内在路由机制的有效性和合理性。车道入口选择场景的可视化(图 5d)也清晰地展示了不同专家在当前上下文中对不同入口车道位置的偏好。

此外,我们还在不同场景下对 ARTEMIS 和 Transfuser 的轨迹规划性能进行了视觉对比,结果如图 6 所示。
E. 消融实验
组件影响分析
为了评估每个架构组件的贡献,我们构建了三个变体模型,分别移除了以下组件:
- 自回归规划模块 + MoE(AME)
- MoE 模块本身(MoE)
- 轨迹优化模块(TR)
结果总结在表 III 中,显示移除任何单一组件都会导致性能下降,确认了这三部分的必要性。具体来说,移除自回归模块使 PDMS 下降 3.0 分,说明自回归范式对于捕捉航点之间的时间依赖性和准确应对变化的环境背景至关重要。
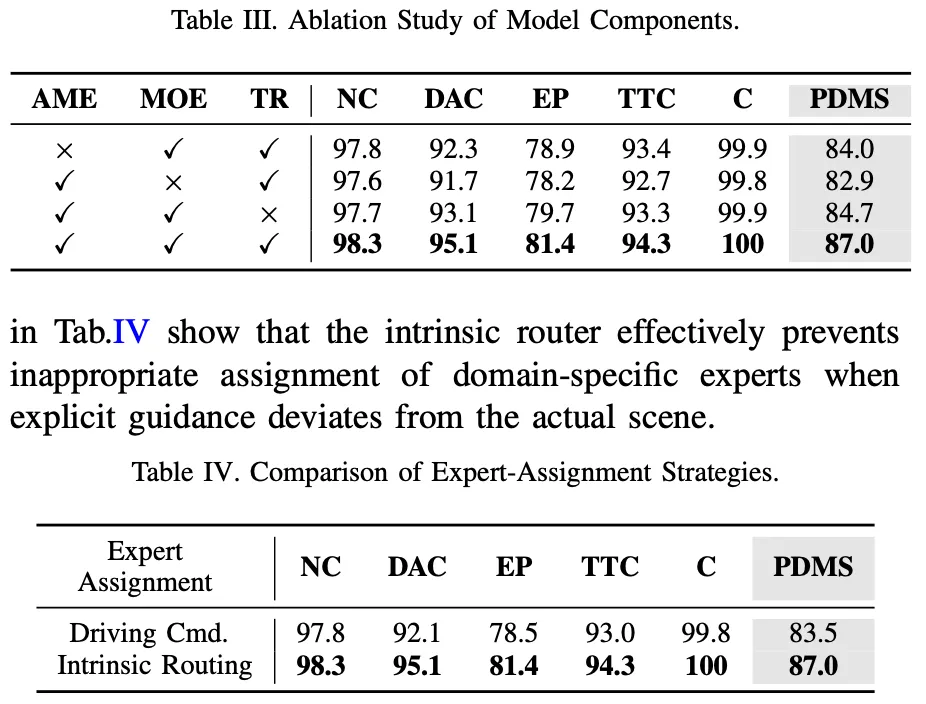
移除 MoE 模块会导致 PDMS 下降 4.1 分,强调了 MoE 架构在动态适应多样化驾驶场景和行为模式方面的优势。最后,移除级联优化模块会使 PDMS 下降 2.3 分,表明该阶段有效缓解了自回归轨迹生成过程中的采样不稳定性。
路由网络有效性验证
为了验证内置路由机制的有效性,我们将其与显式的驾驶命令引导策略进行了比较。实验结果(见表 IV)显示,内置路由机制在显式引导偏离实际场景时能有效避免对领域特定专家的不当分配。
级联优化层数的影响
表 V 报告了优化层数对模型性能的影响。增加级联深度最多提升两层效果,超过此数后性能趋于饱和。
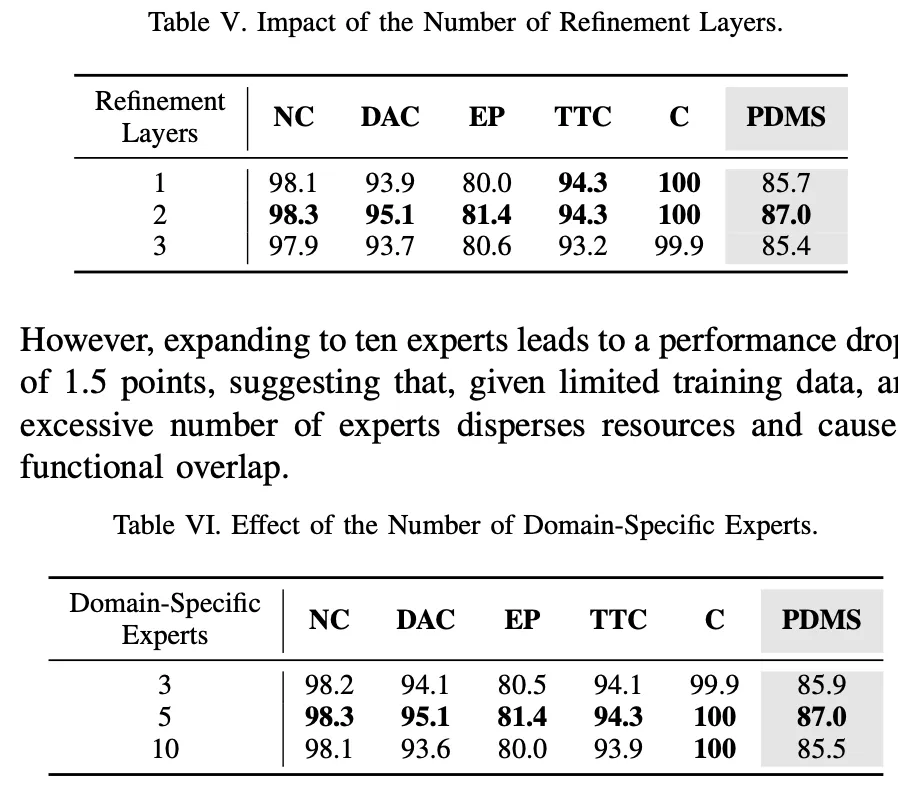
领域特定专家数量的影响
表 VI 探索了专家数量变化的影响。将专家数量从 3 个增加到 5 个逐步提升了模型性能,表明增强了处理复杂场景的能力。然而,扩展到 10 个专家时性能下降 1.5 分,表明在有限训练数据下,过多专家会分散资源并导致功能重叠。
批次重分配对训练速度的影响
为了评估批次重分配的贡献,我们在不同批量大小下比较了有无该策略的训练速度。如表 VII 所示,在相同硬件条件下,批次重分配显著加快了训练速度,随着批量大小从 64 增加到 256,每秒处理的训练样本从 19.2 提升到 43.5。尽管重分配引入了一些额外开销,但相对于专家网络计算而言微不足道,并且被并行效率的提升所抵消。
结论
本文提出了 ARTEMIS ------ 一种结合自回归端到端轨迹规划与专家混合(Mixture-of-Experts, MoE)的自动驾驶框架。不同于传统一次性静态范式合成完整轨迹的方法,ARTEMIS 实现了顺序决策过程,从而能够对轨迹演化进行建模。
通过集成具有专用路由网络的专家混合架构,ARTEMIS 动态捕捉驾驶行为的内在动态特性,并有效适应多样化的驾驶环境。在 NAVSIM 基准上进行的大量定量评估表明,ARTEMIS 表现出高度竞争力的性能。鉴于其灵活性和适应性,该框架在复杂场景中展现出巨大的部署潜力,并为未来自动驾驶研究确立了一个有前景的方向。
#关于 VLM 一些实现点
当前主流 VLM 似乎是下面这样:
- vision encoder 一般用 ViT,用 MLP 桥接到 LLM 上(llava 开启用 MLP,相比于 BLIP 所用的复杂的 q-former)。vision encoder 上施加 2d-位置编码。
- 为了支持 input image 可以是各种分辨率,一种方式是(比如 deepseek-VL-2)把图片切块成固定大小,然后用 ViT 编码成固定数量 tokens,然后分多个子图灌注给 LLM。另一种(感觉更高级的)方式是,vit 本身支持各种分辨率(根本在于2d 绝对位置编码)基础上,LLM 的位置编码也能关注到图片、video 的patch 坐标。
- LLM 集成了 vision 后,仍然用 1d-Rope 位置编码也是能 work 的。这是因为 vision encoder 都有 2D 位置编码,也就是 vision token 已经自带位置编码了。另外有些做法会对 img patch token 的行尾,加一个 换行 token,这样 LLM 也能识别出换行。
- LLM 集成了 vision 后,用能反映出 patch 坐标的多维位置编码,直观上是更有道理的。qianwen-VL-2 与 2.5 就用到了这样的位置编码。
察看几个较新 VLM 后,总结如上,简析如下。
Kimi-VL
乃一只激活 2.8B 参数(总十几B)的 MOE VL thinking 小钢炮模型。
vision encoder
支持任意分辨率的图片与视频。所用 vision encoder 为 ViT 结构,从已有的 SigLIP-SO-400M 预训练 model 上扩展来的(用它初始化参数并继续 pretrain)。原 SigLIP 没用 2D-rope 而是用了绝对位置编码,为此 kimi 把它插值化,从而支持任意分辨率的图片。另外,kimi 还额外给它补充了 2D rope(从左上角开始排布位置id,一路随着图片分辨率延伸下去,从而也支持各种分辨率)。即一共用了两种位置编码。
主体 model 部分
- 用了 MOE。代码上直接引用到了 deepseekV3, 乃 deepseek 版本的 MOE。
- 图文两模态的关联:自从 llava 之后都用 MLP,它也不例外。
- LLM 上的位置编码:没有给 vision 模态 token 特别设计位置编码(这和 qianwen2-vl 是不同的),而是直接用 1d位置编码。vision token 的行列位置关系,靠 vision encoder 编码得到。
所用强化学习
因为是 think model,所以用了 RL。和 《Mkimi k1.5》中方法一样
千文系列
qw-VL-1(千文-VL-1)
======
qw-VL-1 还用的blip 那样的 q-former 样的东西。且 input 图片必须先剪切成固定大小,经过 q-former-adapter 转化成固定的 256 个 token,然后参与到 LLM 中。adapter 处用到了 2D 绝对位置编码,img 和 text 在 LLM 中仍用 1d-Rope。
它的亮点之一,支持 Bounding Box 可作为 text 的 input 或 text 的 output。这一特点在后续版本都延续了下来。它还只是个 10B 的小模型。
qw-VL-2 2024.09
======
vision encoder 变成到了 675M(VL-1 是 1.9B),但整个model 变大到了 72B。主要变化是,input 支持了任意分辨率的图片,支持了视频。
假设原始图片分别率是 (a, b), 则最终token 数是 (a/28)* (b/28)------它的 ViT encoder 是 14x14 切块,并最终把 2x2 的 patch 合一,所以是28. 上图的3 个 img,1个 video 即满足此点。不像 VL-1,用 q-former,而是像 LLava 一样,用 MLP 连接 Vit encoding 与 LLM(相邻的 2x2=4 个块作 MLP即为 vision token)。
位置编码:
- 训练ViT的时候,用了 2D-Rope(d维向量,分一半编码x,一半编码y)。
- 拼到 LLM 后,用 M-Rope 3d 位置编码把 text 与 vision 统一处理:每一token 用 (frame_idx, height, width) 三个位置 id 表示。下面讲 VL-2.5 再详述。
**训练时,img 与 video 怎么与text 拼一起的(训练数据长啥样):**
qw-VL-2.5 2025.02
====
model 大体上和 VL-2 简直一模一样。仍然是 axb 的 img 转成了 (a/28)* (b/28) 个 vision token,用 MLP 桥接 img 与 LLM。且 vision encoder 内部仍是用了 2D-RoPE。为了很好处理video,还有某些特别操作(For video data, two consecutive frames are grouped together, significantly reducing the number of tokens fed into the language model),不论。
关于 MRope 位置编码
MRope 位置编码把 text, image, video 三种模态统一作位置编码,作用于LLM。每个token 用 t, h, w == (frame_idx, height_idx, width_idx) 三个位置 id 表示。
- 对于 text 三个 id 取值一样,且顺序增一。
- 对于同一个 img 的多个patch 所形成的 token 序列:height_idx, width_idx 如实填写, 他们共用一个 frame_idx = 0. 然后对此 shape = 1, H, W 的数组,每个元素统一加上 offset= max(img的前一token 的 t, h, w)值.
- 对于 video 的多个frame 形成的 token序列:height_idx, width_idx 如实填写, 而 frame_idx 则是帧序列。然后对此 shape = frame_cnt, H, W 的数组,每个元素统一加上 offset= max(img的前一token 的 t, h, w)值.
例子:
messages = [
{
"role": "user",
"content":[{"type": "text", "text": "hello"}],
},
{
"role": "assistant",
"content": [{"type": "text", "text": "what can i do for you?"}],
},
{
"role": "user",
"content": [
{"type": "image", "image": "img1.png", },
{"type": "image", "image": "img2.png",},
{"type": "text", "text": "what do you see in the picture?"},
{"type": "video", "video": "video1.mov",},
{"type": "text", "text": "what text do you see in the movie?"},
],
}
]转成 M-Rope位置编码 id 后是(修改代码,实测打印出):
# text: hello , what can i do for you?
1 [0, 0, 0] # 方括号数字含义:[frame_idx, height_idx, width_idx]
1 [1, 1, 1]
1 [2, 2, 2]
1 [3, 3, 3]
...
1 [28, 28, 28]
1 [29, 29, 29]
1 [30, 30, 30]
1 [31, 31, 31]
1 [32, 32, 32]
-----
# img: img1.png
1 [33, 33, 33] # 统一加了前一 token 中的 32
2 [33, 33, 34]
3 [33, 33, 35]
4 [33, 33, 36]
....
3574 [33, 81, 102] # 这张图的第 3574 个 token
3575 [33, 81, 103]
3576 [33, 81, 104]
3577 [33, 81, 105] # 3577:这张图有 3577 个token
----
# text
1 [106, 106, 106] #<vision_end> token# 从 前面105开始
1 [107, 107, 107] # <vision_start> token
----
# img: img2.png
1 [108, 108, 108] # 从前面107开始。统一加了107得到img2.png 的 位置编码 id
2 [108, 108, 109]
3 [108, 108, 110]
4 [108, 108, 111]
...
884 [108, 144, 127]
885 [108, 144, 128]
886 [108, 144, 129]
887 [108, 144, 130]
888 [108, 144, 131]
-----
# text: what do you see in the picture?
1 [145, 145, 145]
1 [146, 146, 146]
1 [147, 147, 147]
...
1 [153, 153, 153]
1 [154, 154, 154]
------
# video: video1.mov
# - frame 1
1 [155, 155, 155]
2 [155, 155, 156]
3 [155, 155, 157]
4 [155, 155, 158]
...
717 [155, 190, 171]
718 [155, 190, 172]
719 [155, 190, 173]
720 [155, 190, 174]
# - frame 2
1 [157, 155, 155] # frame_id=155+2。注意不同 frame 相同位置,用了同样的 (h, w),和第一帧一样 ,从 155,155 开始
2 [157, 155, 156]
3 [157, 155, 157]
4 [157, 155, 158]
5 [157, 155, 159]
...
716 [157, 190, 170]
717 [157, 190, 171]
718 [157, 190, 172]
719 [157, 190, 173]
720 [157, 190, 174]
# - frame 3:
1 [159, 155, 155] # frame_id = 155+2+2
2 [159, 155, 156]
3 [159, 155, 157]
4 [159, 155, 158]
...
717 [159, 190, 171]
718 [159, 190, 172]
719 [159, 190, 173]
720 [159, 190, 174]
-----
# text: what text do you see in the movie?
1 [191, 191, 191]
1 [192, 192, 192]
1 [193, 193, 193]
...
1 [203, 203, 203]
1 [204, 204, 204]
1 [205, 205, 205]一般感觉中,横竖坐标都应该是从0或者1开始,如果从某一个随机的值开始,当做左上角坐标起点(正如上面 m-rope),还有意义吗?因为rope其实起作用的时候,使用的位置差,所以加这样的偏移是没问题的。上面这样,反而能刻画出这个img/video/text 三者之间的前后顺序。
(1)、上面这样子的位置编码,其实sujianlin 大神有专文论述: "闭门造车"之多模态思路浅谈(三):位置编码 - 科学空间|Scientific Spaces 给出了一个好的 3D repo 应该满足的 3 个属性:
- 兼容性:如果input只有text,应该退化成 1d-RoPE
- 对称性:两段文字text1, text2 中间夹一个img(或video). 则对于(t,h,w) 三个维度id都应该满足:img.first_token text1.last_token == text2.first_token - img.last_token
- 也就是说前后两段文字和图片的距离应该一样
- 等价性:两段文字text1, text2 中间夹一个img. 应该:text2.first_token - text1.last_token == img.token_cnt
- 也就是说,两段text之间的距离,应该正好等于 img.token_cnt
以上三点甚为有理。他还给出了解,大体上说,一个 img/video 的(t,h,w) 三者的每种位置 id 需要是某种等差数列形式,才可满足这三点。而qianwen-vl 的 M-Rope 只保留了兼容性。
(2)、关于 attention mask: 纯 text 的 LLM, 无疑是用三角 attn 矩阵即可。对于有图片或 video 的多模 LM,里面的 text 部分,无疑还需要 casual 三角 mask,对于里面的 img 或 video------特别是位置编码都是3D的了------因为只用于 input,不用于 output,是不是可以不用三角 attn mask呢?------也就是只text部分是三角mask矩阵, vision 部分用全 mask。就 qianwen-vl-2.5 代码看,是全部用了三角 attn mask 矩阵。
视频支持动态帧率与帧绝对时间编码
VL-2.5 的一个重要特色是对于 video,会把 frame 的绝对时间(指的是相对于视频开始的绝对时间偏移)编码。处理方式是:本来也不可能把每一帧都最终放进 LLM,需要采样某些帧。一般做法是每 n 帧抽一,这样如果原始的 FPS 帧率不固定,所抽出的 第 i 个 frame 的时间就指不定是哪一秒的了。于是 VL-2.5 定义好一个标准的帧率,标准帧率的每一帧对应的是位置编码id 的 1,2,3,4,5..。要想用别的采样帧率,则选用位置编码 id {1,2,3,4,..} 中的某些等差序列子集即可。见下图:
训练的时候,会各种帧率的都出现,这样 inference 的时候,给任意帧率的video 都支持。注意图中,是选某一种帧率,而不是一个 video 一次要把各种帧率都放进 model 里。
deepseek-VL-2 2024.12
- vision encoder: 用了接收固定大小图片的 SigLIP model。 SigLIP 本身用了2D 绝对位置编码。
- 怎么支持的任意分辨率图片:大图切片,patch 尾部加换行 token:
- 位置编码:图片的位置编码只是用了 vision encoder 里的位置编码。然后LLM 里,仍用 1d-rope。但是用特殊换行符号分隔图片的不同patch 行。
internVL-3 2025.04 (上海AI实验室)
========
它用的是 "ViT-MLP-LLM" 架构。
LLM 中的位置编码:
用所谓的 V2PE( https://arxiv.org/pdf/2412.09616 )方法。
仍然用 1d 位置编码,但是对于一个img的多个tokens,它们的位置顺序id的递增不再是1(text 就是1),而是一个小于1的 。 这样好处是,通过间隔能区分出这一块儿时 img,且img占用的位置空间较小,从而能节约有限的 LLM context size(这个size 是由支持的最大位置编码id决定的)。训练时,delta 可以取用各种值, infer 时就支持不同的 delta 了。
是否只能固定分辨率
从它所用的 vision encoder ( https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5 ) 看:
As in the previous version, we applied a pixel unshuffle operation, reducing the number of visual tokens to one-quarter of the original. Besides, we adopted a similar dynamic resolution strategy as InternVL 1.5, dividing images into tiles of 448×448 pixels. The key difference, starting from InternVL 2.0, is that we additionally introduced support for multi-image and video data.
也就是大图切分成多个448x448 的固定图的方式,支持了任意大小的图。所用 vision encoder 内部应该有(不确,未考) 2d 位置编码, 否则 LLM 中的 1d位置编码怎么区分出img tokens 的位置坐标呢.
其他:经高人指点,还有一类 Encoder-Free VLM
顾名思义,不用 vision encoder。以 https://arxiv.org/pdf/2502.06788 eve2 来看,是用了patch emb layer提取视觉特征,也可以说这就是一种 vision encoder:不过作者说了,For visual embeddings, we construct a minimalist (尽量小的) patch embedding layer from scratch,在"尽量小" 意义上------除非裸像素直接 feed 否则必不可少的转化------乃 encoder-free。
另外,此文给出的各路 VLM 的总结图很好:
其他:关于 VLM 作 OCR。无疑 VLM 直接做长篇 OCR,已被证明很成功。
有说 ViT 更偏向低频特征,对高频细节不敏感:ViT 更偏向低频特征,对高频细节不敏感: 在CV界,传统卷积已经彻底输给Transformer了吗?有狮子的那个回答, 以及里面有所提及的 https://arxiv.org/pdf/2202.06709。那么为啥 ViT 用于多模 LM,作 OCR 效果还很好?是这里所说的高频,对于文字细节纹路,并不算高频,也就是高频频段定义不同?或者强大数据加持暴力训练下,一个 vit 的patch 内有啥内容,直接记住了?待究