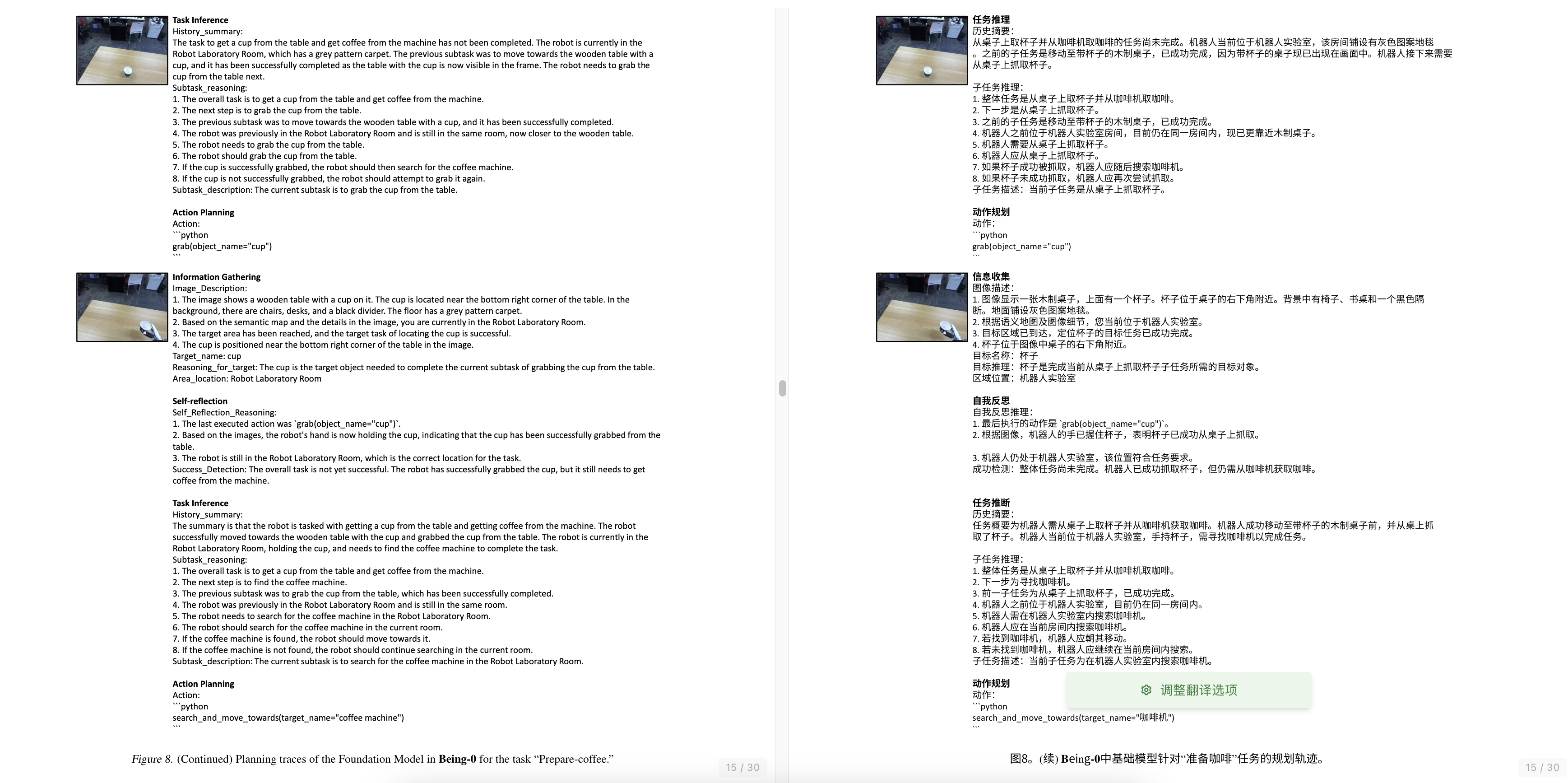
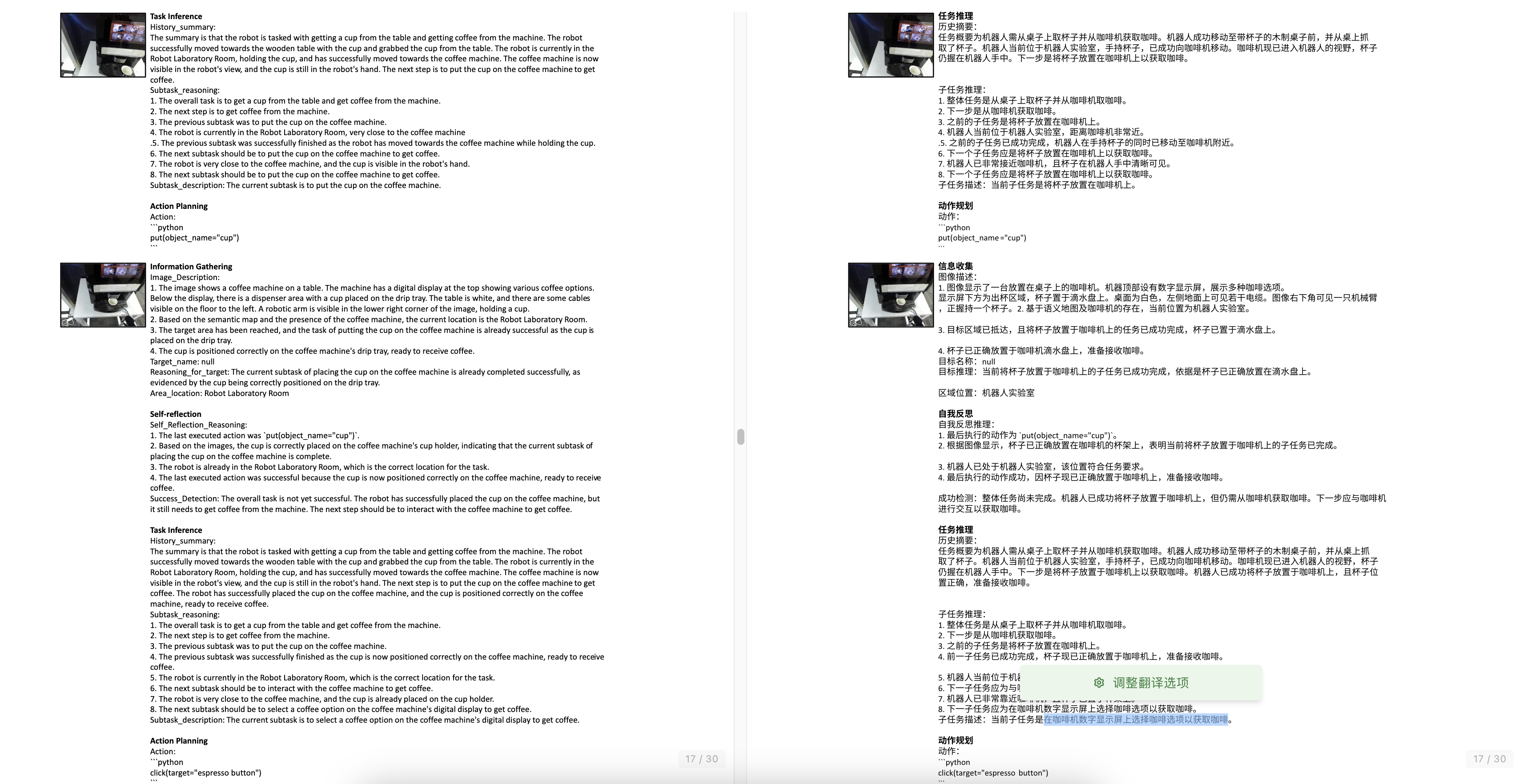
双手操作manipulation Ze等,2024a,即iDP3,Generalizable humanoid manipulation with improved 3d diffusion policies
Li等,2024a,即Okami : Teaching humanoid robots manipulation skills through single video imitation,详见此文《基于人类视频的模仿学习与VLM推理规划:从DexMV、MimicPlay、SeeDo到人形OKAMI、Harmon(含R3M的详解)》的第五部分 OKAMI:从单个RGB视频演示中模仿人类操作的人形机器人 Zhou等,2024,即Learning Diverse Bimanual Dexterous Manipulation Skills from Human Demonstrations
最近的研究中 Firoozi等,2023,即Foundation models in robotics: Applications, challenges, and the future
Hu等,2023,即 Toward general-purpose robots via foundation models: A survey and meta-analysis
机器人代理将基础模型(Foundation Models, FMs)与基于学习的机器人技能相结合,利用FMs在通用视觉语言理解中的能力,用于 技能规划 Ahn等,2022,即Do as i can, not as i say: Grounding language in robotic affordances
Chen等,2024,即Commonsense reasoning for legged robot adaptation with vision-language models
成功检测 Huang等,2022,即Inner monologue: Embodied reasoning through planning
with language models 和推理
虽然这些方法在为 机械臂 (Liang等,2023-Code as policies: Language model programs for embodied control) 轮式机器人 (Ahn等,2022-Do as i can, not as i say)
和四足机器人 (Chen等,2024),即Commonsense reasoning for legged robot adaptation with vision-language models
构建代理方面取得了一些成功,但能否将同样的成功复制到人形机器人上?
低层技能库
作者首先为一个基于通用 FM 的智能体框架「Tan 等人2024 年-Cradle: Empowering foundation agents towards general computer control(一个基于GPT-4o构建的代理框架)------下文的 " 1.2.2 高层:基础模型Foundation Model*" 还会再次提到*」
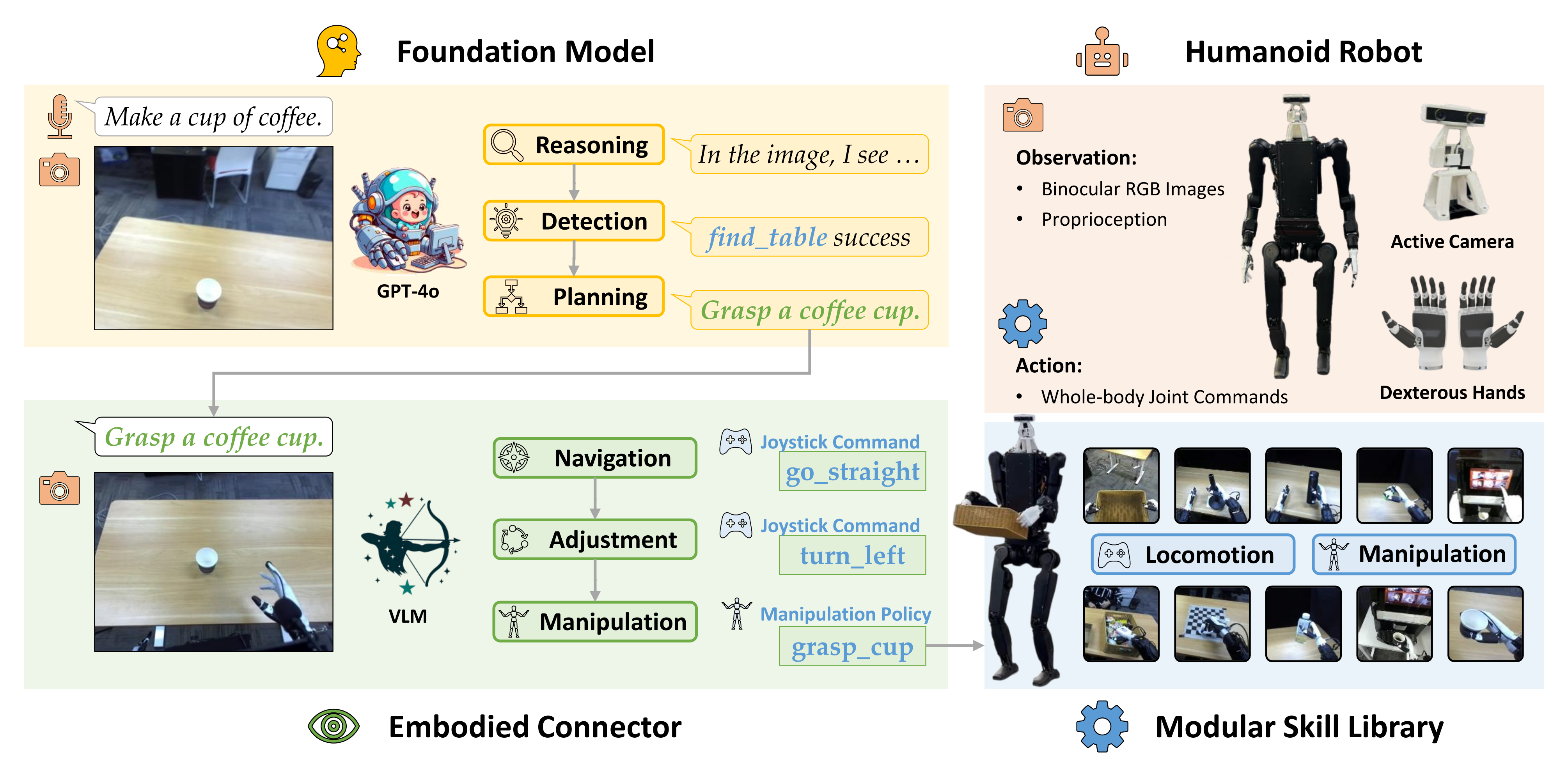
配备了一个模块化的机器人技能库 We begin by equipping a universal FM-based agent frame-work (Tan et al., 2024) with a modular robotic skill library.
该技能库包含一个基于操纵杆指令的稳健移动技能,以及一组通过最先进的遥操作(Cheng 等人,2024 年 b-Opentelevision),和模仿学习(Zhao 等人2023 年-ALOHA ACT)方法获取的语言描述的操作技能 This skill library includes a robust locomotion skill basedon joystick commands and a set of manipulation skills withlanguage descriptions, acquired through state-of-the-art tele-operation (Cheng et al., 2024b) and imitation learning (Zhaoet al., 2023) methods.
这种不稳定性要求频繁调整行走指令以进行误差修正
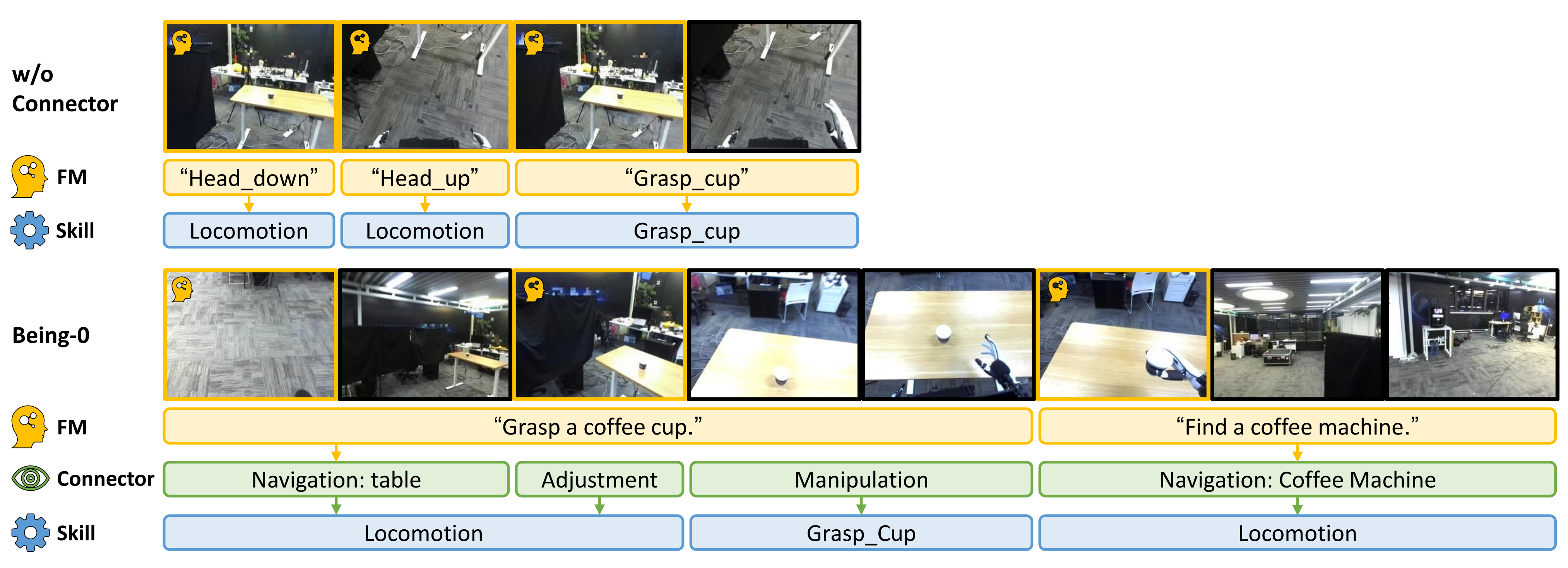
然而,现有的功能模型,例如 GPT-4o,在推理效率和具身场景理解方面存在局限性,这使得人形智能体在长时任务中导航和操作交替进行的阶段反应性较差且不够稳健 However, existing FMs, such as GPT-4o, suf-fer from limitations in inference efficiency and embodiedscene understanding, making humanoid agentsless reactiveand robust during thealternating phasesof navigation and manipulation in long-horizon tasks.
其根据FM的语言计划和视觉观察,为运动和操作技能生成实时命令
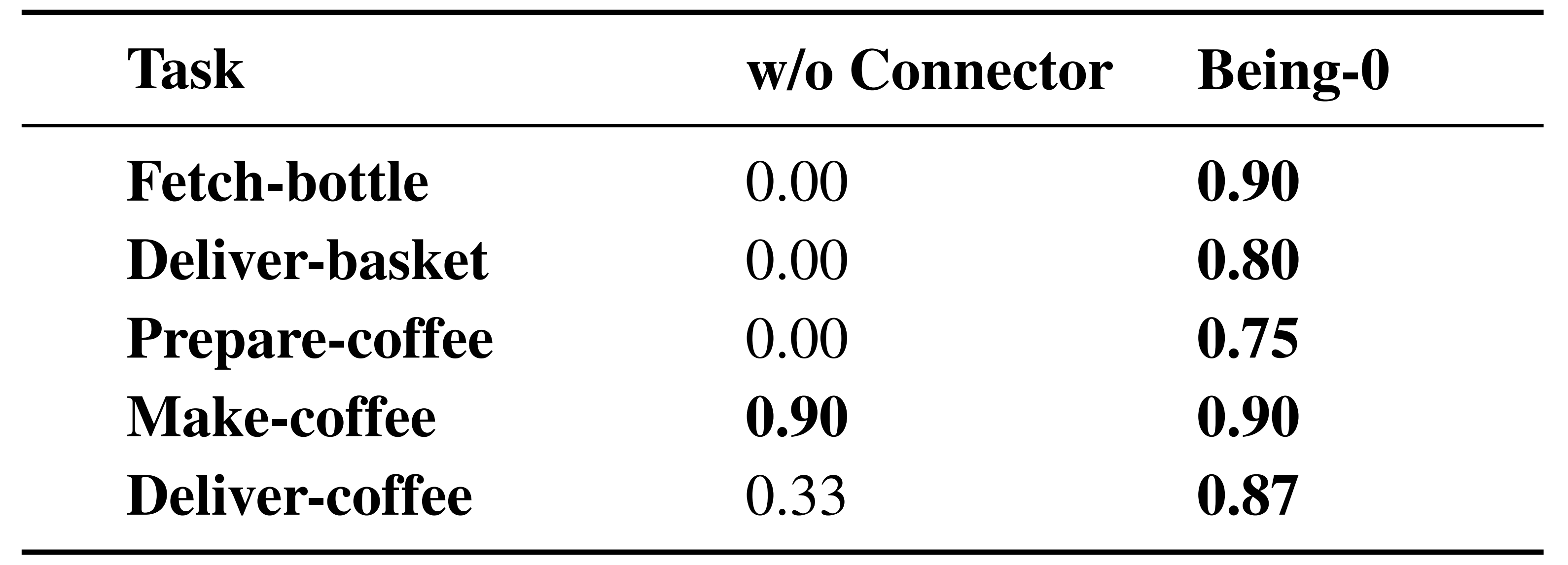
将连接器建模为一种视觉语言模型(VLM),并使用带有语言指令、++对象标签和边界框++ 注释的第一人称室内导航图像对其进行训练 We model the Connector as a vision-language model(VLM) and train it using first-person images of indoor navi-gationannotatedwith language instructions, ++object labels,and bounding boxes++.
这种训练方案将视觉-语言导航数据中的具体知识提取到基于轻量级VLM的连接器中,从而实现准确的技能规划和更高控制频率下的高效导航
此外,为了无缝衔接导航和操作技能,连接器可以发送运动命令以调整人形机器人的姿态,从而改善后续操作任务的初始化状态 结果表明,通过在机载计算设备上部署所有模块(云端仅部署 FM),Being-0在导航方面的效率比完全基于 FM 的代理高出 4.2 倍------详见下文的2.1.3 消融研究:导航调整、主动视觉、效率
想让对应的运动技能控制下肢关节,必须能够实现多方向导航并在操控任务期间保持稳定站立
对此,作者采用强化学习RL方法「Ha et al., 2024-Learning-based legged locomotion: State of the art and future perspectives」来训练
先在仿真中使用条件本体感知策略(Makoviychuk等,2021- Isaac gym: High performance gpu-based physics simulation for robot learning),然后以50 Hz的控制频率进行仿真到现实的部署
++远程操作和模仿学习++ 已成为以低成本获取多样化机器人操控技能的有希望的方法「Teleoperation and imitation learning have emerged as promising approaches for acquiring diverse robotic manipulation skills at low cost」
双目图像观测结果或投影到 Vision-Pro 上,所捕捉到的人类头部、手腕和手指的动作以10 Hz的控制频率重新定位到机器人动作上 Binoc-ular image observations ol, or are projected to the Vision-Pro, and the captured human motions of the head, wrists,and fingers are retargeted to robot actions at a control fre-quency of 10 Hz
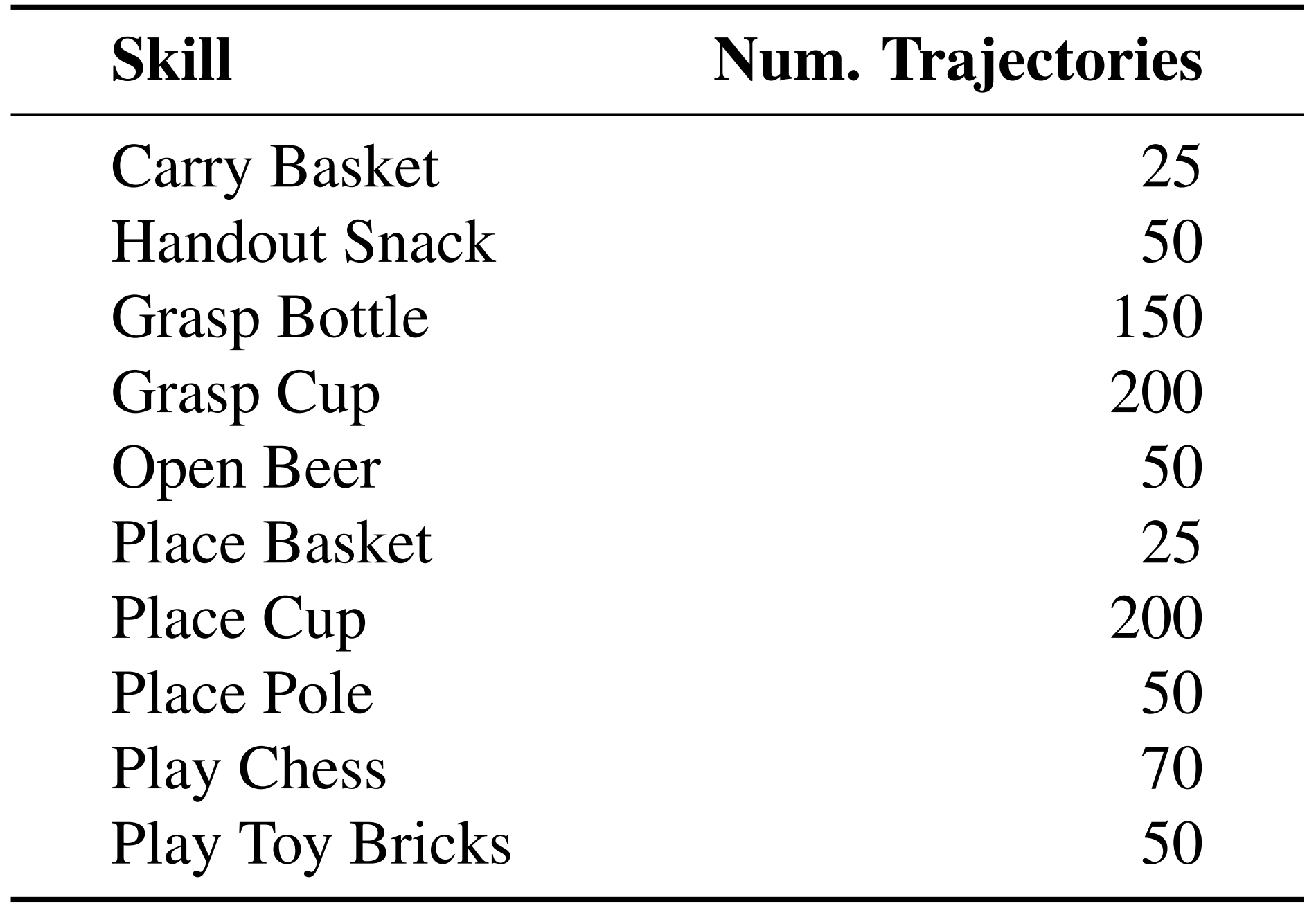
对于每项技能,都记录了遥操作轨迹
其中包括机器人观测值和动作(不包括下身动作)
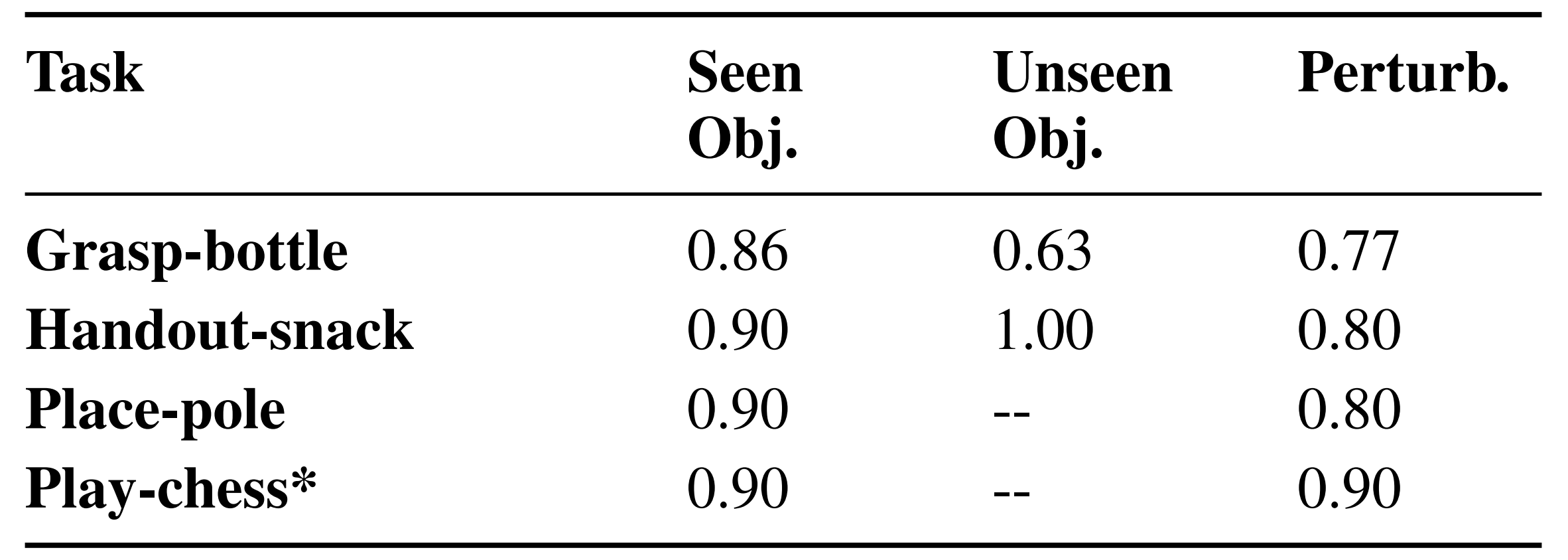
接着,使用 ACT「Zhao等人2023,即ALOHA ACT,详见此文」来训练与诸如"抓取瓶子"之类的语言描述++相关联++ 的每种操作技能的策略 We use ACT (Zhao et al., 2023), a behavior-cloning method with a Transformer architecture, to train the pol-icy πMi �auj , ahj t+Kj=t |olt, ort, qut , qht�for each manipulationskill Mi,++associated++ with a language description such as"grasp bottle".
好在基础模型(FMs)在这些领域表现出色,并且在最近关于人工智能代理的研究中被广泛采用 Wang等人,2024-A survey on large language model based autonomous agents Tan等人,2024-Cradle: Empowering foundation agents towards general computer control
其项目地址为:baai-agents.github.io/Cradle
其GitHub地址:github.com/BAAI-Agents/Cradle
双足运动的固有不稳定性使得人形机器人的位置在短时间行走后变得不可预测,这需要频繁调整操纵杆命令,而不是执行开环指令序列 The inherent instability of bipedal lo-comotion makes the humanoid's position unpredictable aftershort periods of walking, necessitating frequent adjustmentsto joystick commands rather than executing open-loop com-mand sequences
连接器的主要目标是将由任务规划器生成的基于高级语言的任务计划,可靠且高效地转换为可执行的技能指令「The primary goal of the Connector is totranslatehigh-level language-based plansgenerated by the FMinto**executables kill commands reliably and efficiently」
连接器的核心是一个基于注释导航数据训练的轻量级视觉语言模型(VLM),它增强了代理的具身能力 At the core of theConnector is a lightweight vision-language model (VLM)trained on annotated navigation data, which enhances theagent's embodied capabilities.
该 VLM 实现了多项下游功能,包括基于场景的技能规划、闭环导航以及在长时任务执行期间导航与操作之间的平滑过渡 This VLM enables severaldownstream functionalities, including grounded skill plan-ning, closed-loop navigation, and improved transitions be-tween navigation and manipulation during long-horizon taskexecution
且最终采用VideoLLaMA2「Cheng et al., 2024c-Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms」作为主干架构------其使用图像观察和文本指令作为输入
该模型通过多任务学习进行优化,包括图像描述、技能预测和目标检测
为了使机器人能够到达视觉导航目标(例如一张桌子),连接器利用视觉语言模型(VLM)的视觉理解和物体检测能力「To enable the robot to reach visual navigation goals (e.g.,a table), the Connector leverages the VLM's visual under-standing and object detection capabilities」
当目标物体在机器人视野范围内时,连接器使用检测到的边界框和双目图像的合成深度来估计其相对位置 When the goalobject is within the robot's field of view, the Connector esti-mates its relative position using the detected bounding boxand synthetic depth from binocular images
基于此估计,VLM 选择最合适的运动技能向物体方向移动 Based on this es-timation, the VLM selects the most appropriate locomotionskill to move towards the object's direction.
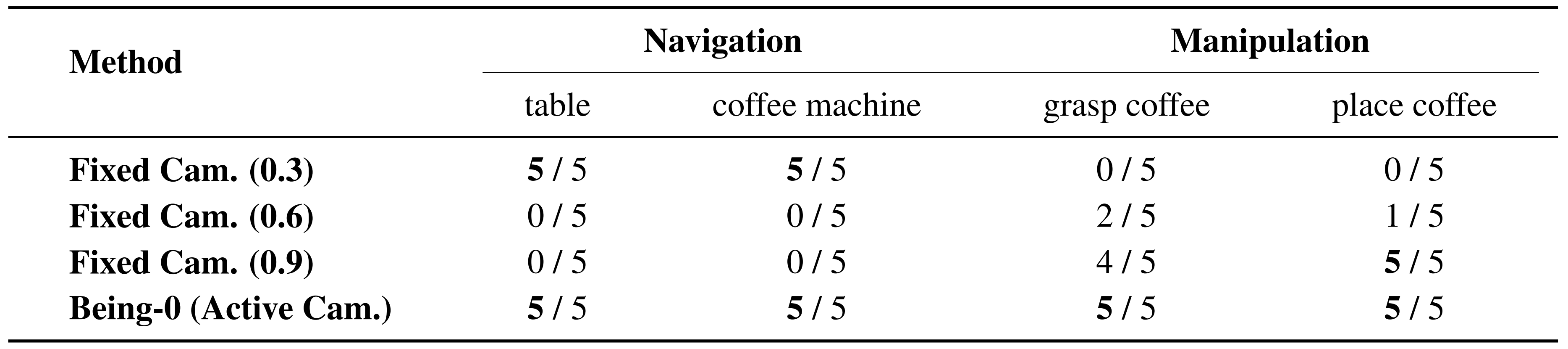
如果物体不可见,VLM 触发探索程序,结合运动技能和主动相机移动来搜索目标。这种方法与固定相机的系统相比,显著提高了机器人定位物体的能力。实现细节见附录 B.2 If the object isnot visible, the VLM triggers an exploration routine, com-bining locomotion skills with active camera movements tosearch for the goal. This approach significantly enhancesthe robot's ability to locate objects compared to systemswith fixed cameras. Implementation details are provided inAppendix B.2.
通过将 VLM 的高效推理能力与模块化运动技能相结合,此方法加快了人形机器人导航速度,同时在动态环境中保持了稳健性 By integrating the VLM's efficient inferencecapabilities with modular locomotion skills, this methodaccelerates humanoid robot navigation while maintainingrobustness in dynamic environments.
为了解决导航过程可能以不利于后续操作技能的次优姿态结束这一挑战------To address the challenge that navigation processes may ter-minate in suboptimal poses for subsequent manipulation skills
人形机器人(Goswami &Vadakkepat,2018;Gu et al.,2025)被认为是适合人类设计环境的理想形态,其中行走和操作是基本技能
对于行走
早期的方法侧重于使用最优控制进行行走 Miura & Shimoyama,1984,Dynamic walk of a biped
Dariush etal.,2008,Whole body humanoid control from human motion descriptors
Wensing et al.,2023, Optimization-based control for dynamic legged robots
而最近的进展通过强化学习RL和sim-to-real技术
Ha et al.,2024,Learning-based legged locomotion: State of the art and future perspectives
且成功地训练了行走策略,实现了在平地上的稳健行走
Xie etal.,2020,Learning locomotion skills for cassie: Iterative design and sim-to-real
包括复杂地形 Siekmann etal.,2021,Blind bipedal stair traversal via sim-to-real reinforcement learning
Radosavovic et al.,2024
Li et al.,2024b, Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
以及高级跑酷技能 Zhuang et al.,2024,Humanoid parkour learning
对于操作,尽管基于RL的方法(Yuan et al.,2024;Huanget al.,2024)面临显著的模拟到现实间隙
基于模仿学习的遥操作数据的方法由于其简单性和有效性成为主流
研究探索了多种遥操作方案,利用
VR
*Cheng et al.,2024b,*Opentelevision
外骨骼 Fu etal.,2024b,Mobile aloha
Yang et al.,2024,Ace: A cross-platform visualexoskeletons system for low-cost dexterous teleoperation
或摄像头 Fu etal.,2024a,Humanplus
改进的模仿学习方法,如
Diffusion Policies Chi et al.,2023,Diffusion policy
Ze et al.,2024b;a
第一种方法是直接将预先在互联网规模数据集上训练的现有基础模型应用于机器人任务,而无需额外的微调。这些模型利用其强大的通用视觉语言理解能力用于执行具身任务的能力,例如规划 Ahn 等,2022, Do as i can, not as i say
Yuan 等,2023,Skill reinforcement learning and planning for open-world long-horizon tasks
Chen 等,2024,Commonsense reasoning for legged robot adaptation with vision-language models
Kannan等,2024,Smartllm: Smart multi-agent robot task planning using large
language models
和推理 Huang 等,2022,Inner monologue: Embodied reasoning through planning with language models
Zhang 等,2023a,Creative agents: Empowering agents with imagination for creative
tasks
Liu 等,2024b,Rl-gpt: Integrating reinforcement learning and code-as-policy
视觉-语言-动作(VLA)模型
*Jiang 等,2022, Vima:General robot manipulation with multimodal prompts
Kim 等,2024,Openvla
Team 等,2024,Octo
Liu 等,2024a,Rdt-1b
Black 等,2024,*π0 Cheang 等,2024,Gr-2
以及视频-语言规划模型 Yang等,2023,Learning interactive real-world simulators
Du 等,2023, Video language planning
Alayrac et al., 2022,Flamingo: a visual language model for few-shot learning
Chen et al.,2023,Minigpt-v2
Li et al., 2023,BLIP-2
Bai et al., 2023,Qwen-vl
Liu etal., 2023,Visual instruction tuning
和文本-视频VLMs
Zhang et al.,2023b,Video-llama: An instructiontuned audio-visual language model for video understanding
Shu et al., 2023,Audiovisual llm for video understanding
Maaz et al., 2024,Videochatgpt: Towards detailed video understanding via large vision and language models
Jin et al., 2024,Video-lavit: Unified video-language pre-training with decoupled visual-motional tokenization
的开发
在本Being-0的工作中,作者利用开源的VideoLLaMA2「Cheng et al., 2024c-Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms」来训练人形代理中的连接器模块,从而提高效率并使决策过程更贴近实际任务
Ze等,2024a,即iDP3,Generalizable humanoid manipulation with improved 3d diffusion policies