这里主要是为了记录我学习Python的过程,更多是使我规范书写Pyhton语言!
1. 第一章
Python
定义:一种解释型的语言,区别于其他的高级语言,逐行翻译进行执行。
过程:首先编写编程语言,利用Python解释器将代码翻译为二进制代码并提交给计算机进行执行
注意:通过安装Python解释器来对代码进行执行,一般叫做 python.exe,即为 Python 解释器

2. 第二章
2.1 字面量
概念:代码中的固定的值
2.2 注释
概念:对代码进行解释说明的文字,不影响代码的执行
分类:(1)单行注释 # XXX(2)多行注释 """ XXX"""
2.3 变量
概念:类似于一个容器来去存储结果和值,即变量值
特征:变量存储的值可以发生改变
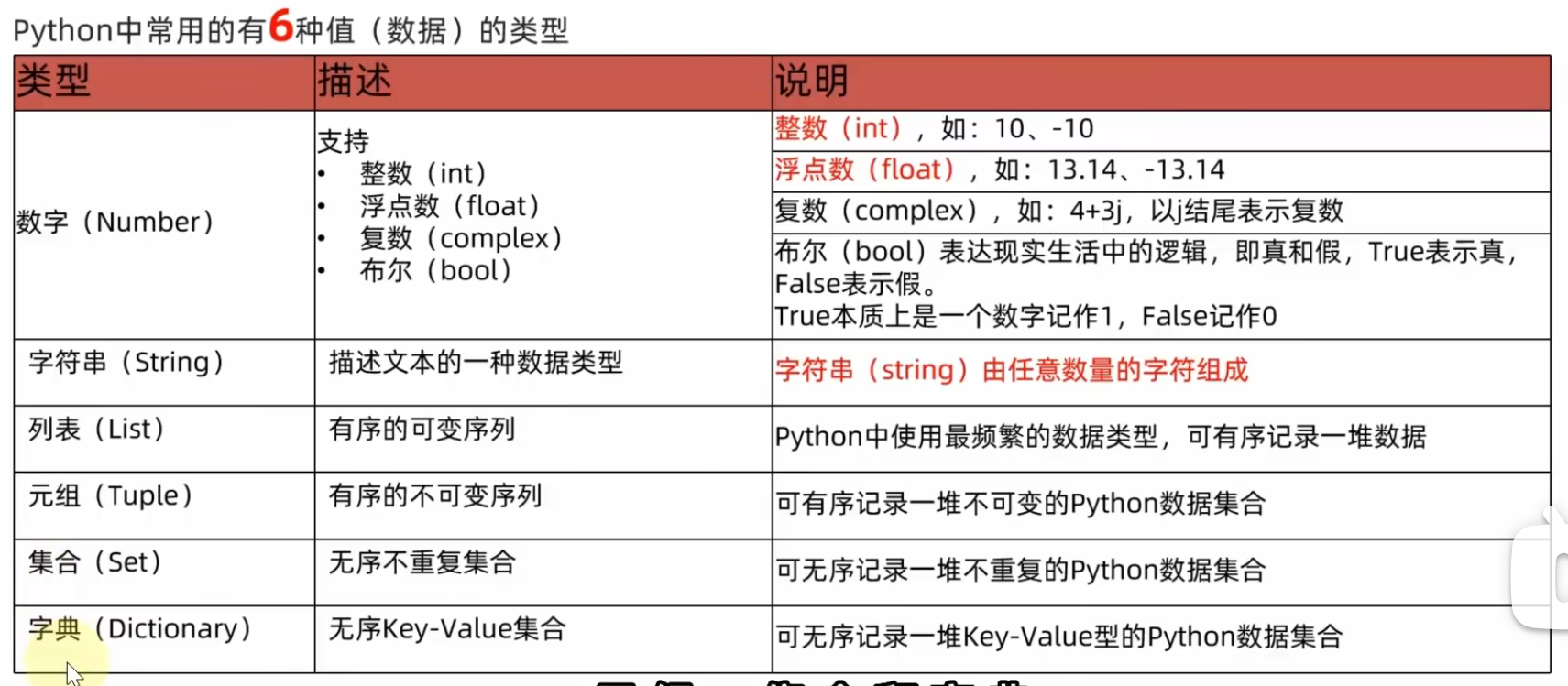
2.4 数据类型
数据类型查看: type()
特征:变量存储的值可以发生改变,数据才有类型,变量没有类型
2.5 数据类型转换
数据类型转换:str();
特征:万物皆可转换为字符串;反之则不是。并且数据转换可能会发生精度问题
2.6 标识符
标识符: 即方法、变量以及类的名字
特征:内容敏感(数字、字母和下划线),大小写区分并且不适用关键字
变量的命名规范:见名知意,下划线命名法以及疑英文字母全小写
2.7 运算符
常见运算符以及对应的复制运算符
2.8 字符串的三种定义
三种:(1)单引号;(2)双引号;(3)三引号 ,支持换行必须有变量接收,否则为注释
注:转义字符可以消除引号的作用或者单引号中可以写双引号,双引号中写单引号
2.9 字符串的拼接
拼接方法:使用 "+" 对字符串进行拼接
注:无法和非字符串类型进行拼接
2.10 字符串的格式化
(1)占位符:一般常常使用到的是三个 %s, %d,%f
python
"%占位符" % 变量精度的控制:辅助符号 m.n ,若m太小的话不会生效,并且 .n 对小鼠部分做精度限制同时对小数部分进行四舍五入
(2)字符串的快速格式化
python
f"{变量1}{变量2}"的方式进行快速格式话注:不理会类型,不做精度控制
2.11 表达式的格式化
定义:(1)代码语句;(2)有执行的结果
python
f"{表达式}"
"%s\%d\%f" % {表达式1,表达式2,表达式3}精度的控制:辅助符号 m.n ,若m太小的话不会生效,并且 .n 对小鼠部分做精度限制同时对小数部分进行四舍五入
(2)字符串的快速格式化
python
f"{变量1}{变量2}"的方式进行快速格式话注:不理会类型,不做精度控制
2.12 数据输入 input()
定义:(1)代码语句;(2)有执行的结果
python
name = input("请输入您的名字")
==
print("请输入您的名字")
name = input()注意:input 接收的数据均是字符串类型
3. 第三章
3.1 布尔类型和比较运算符
通过比较运算也可以得到布尔类型的结构
3.2 if 语句的基本格式
python
if xxx: 执行 else: 执行
if xxx: 执行 elif xxx: 执行 else: 执行 4. 第四章
4.1 while 的基础语法格式
概念:条件和操作,一定要设计好停止条件
python
while xxx:
执行代码注意:为了使得 print() 语句不换行
python
print(f"{表达式}XXX", end = "")注意:为了使得输出内容能够对齐 \t
print("Hello\tWorld")
print("itheima\tbest")4.2 for 的基础语法格式
4.2.1 基础语法
for tmp in tmp_list(序列):
xxx4.2.2 range 语句
一般是左闭右开的区间,range(num1, num2),range(num1),range(num1,num2,step)
4.3 continue 和 break 语句
continue 跳过本此次循环,break 整个循环结束
注:在嵌套循环中,只能作用在所在循环上,无法对上层循环起作用
5. 第五章
5.1 函数初体验
定义:函数专门为某种功能组织好的代码段,可供人重复进行使用
好处:提高代码的复用性,减少重复代码,提高开发效率
def 函数名(传入参数):
函数体
return 返回值5.2 函数的传入参数
定义函数的形参,调用函数的实参。参数可以是0个,也可以是无限个
5.3 函数的返回值
return 之后的所以语句均不会进行执行!
如果没有 return 语句,也有对应的返回值 None,即没有实际意义
注:None 一般用于函数的返回值以及搭配 if 的判断上
5.4 函数的说明文档
通过书写函数的说明文档,能够悬停函数的时候显示对应的内容
def func(x, y):
"""
函数说明
: param x: x的说明
:param y: y 的说明
: return: 返回值的说明
函数体
return
"""5.5 函数的嵌套调用
在一个函数中嵌套调用了另一个函数
5.6 局部变量和全局变量
变量的作用域:即变量的作用范围
局部变量:定义在函数体内的变量,即只在函数体内部生效
全局变量:在函数体内、外都能生效的变量
注:使用 global 关键字,可以在函数内部声明变量为全局变量进行修改
6. 第六章
6.1 Python 数据容器
定义:一种可以容纳多份数据的数据类型,每一份数据叫做1个元素
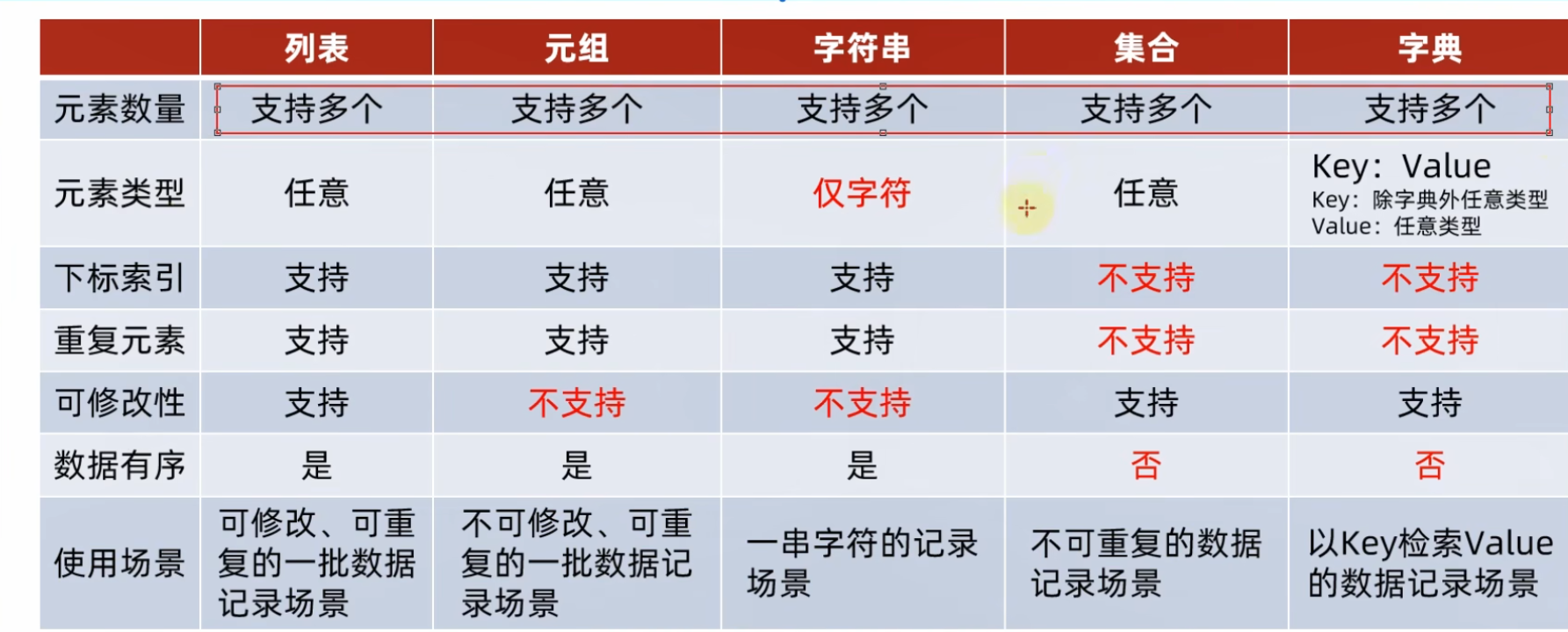
分类:(1)列表;(2)元组;(3)字符串;(4)集合;(5)字典
6.2 列表 list
6.2.1 基本语法
# 字面量
[元素1,元素2,元素3,元素4,...]
# 定义变量
变量名称 = [元素1,元素2,元素3,元素4,...]
# 定义空列表
变量名称 = []
变量名称 = list()元素:数据容器中的每一份数据都称为元素,其数据类型没有任何限制,甚至元素也可以是列表
注:list 中可以存储类型不一致的元素,并且也是支持嵌套的
6.2.2 列表的下标索引:从左往右(0,1,2...),从右往左(-1,-2,-3...)
6.2.3 列表的常用操作:
列表的常用操作主要通过方法来实现,在Python中,如果将函数定义为class的成员,那么函数会称之为方法,即方法和函数的功能是一样的,只不过是使用有区别。比如,函数直接可以使用函数名就可以调用,但是方法我们必须先获取到类的对象实例,然后通过该对象实例来进行调用
my_list= [1,2,5,7,8]
# 获取元素的下标索引值
index = my_list.index(5) // 5元素在列表中的下标索引值
# 修改指定索引的元素值
my_list[0] = "传智教育"
# 插入元素
my_list.insert(1, "hello") // 在指定的下表位置插入指定的元素
# 元素的追加
my_list.append(元素) // 在尾部对元素进行追加
my_list.extend([4,5,6]) // 在尾巴添加一批元素
# 元素的删除
del my_list[2]
element = my_list.pop(下标) // 删除指定下标的元素并返回
my_list.remove(元素) // 删除匹配的第一个元素(从左往右开始匹配删除)
# 列表的清空
my_list.clear()
# 列表的统计元素的功能
count = my_list.count(被统计的元素)
# 列表中的元素个数,len() 函数
len(my_list)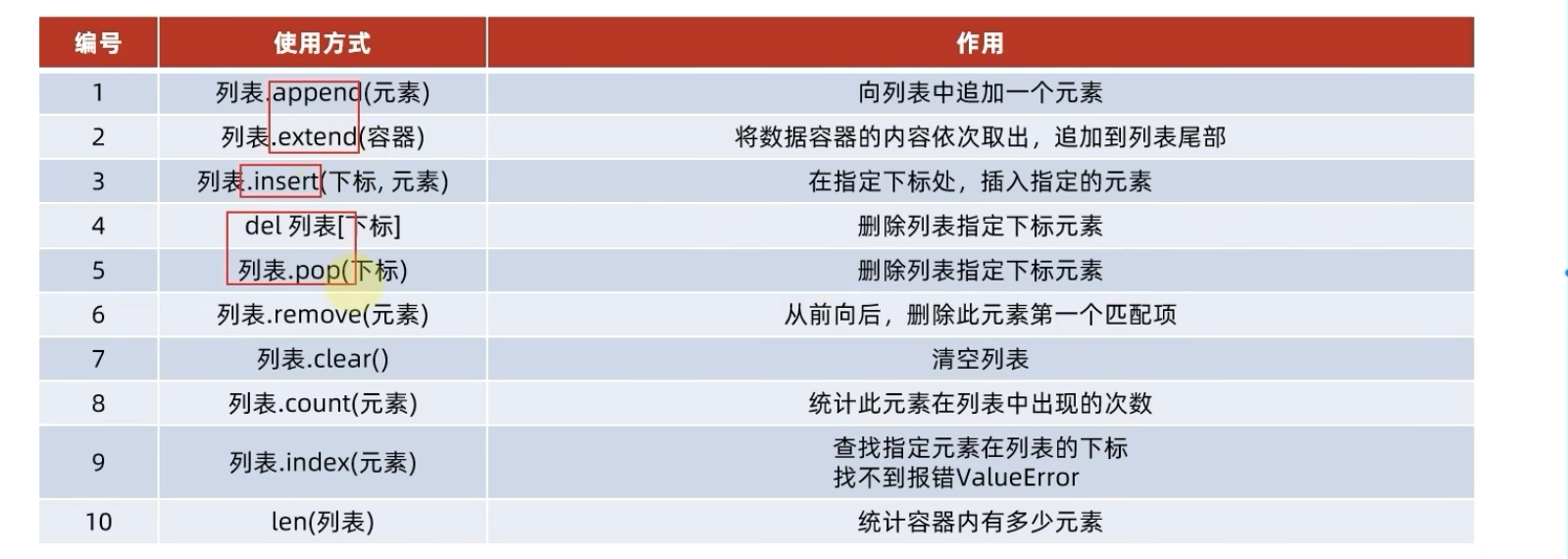
列表的特点:

6.2.4 列表的遍历:
遍历:将元素一次从容器中取出,并处理
6.3 元组 tuple
6.3.1 元组的定义
可以理解为一个不可修改(只读)的 list,想要在容器中封装数据,但是又不希望被篡改
# 元组的字面量
(元素,元素,...)
# 定义元组变量
变量名称 = (元素,元素,。。。,元素)
# 定义空元组
变量名称 = ()
变量名称 = tuple()注: 对于单个元素的元组定义,需要有一个逗号 (元素,);元组中的元素类型不受限
t6 = ("ggg", "gytgy", "hello")
# 查找元素的功能
index = t6.index("ggg")
# 元组的操作: count 统计方法
num = t6.count("hello")
# 元素的个数
len(t6)
注意:对于元组中的可修改元素是可以修改成功的,内部list中的内部元素

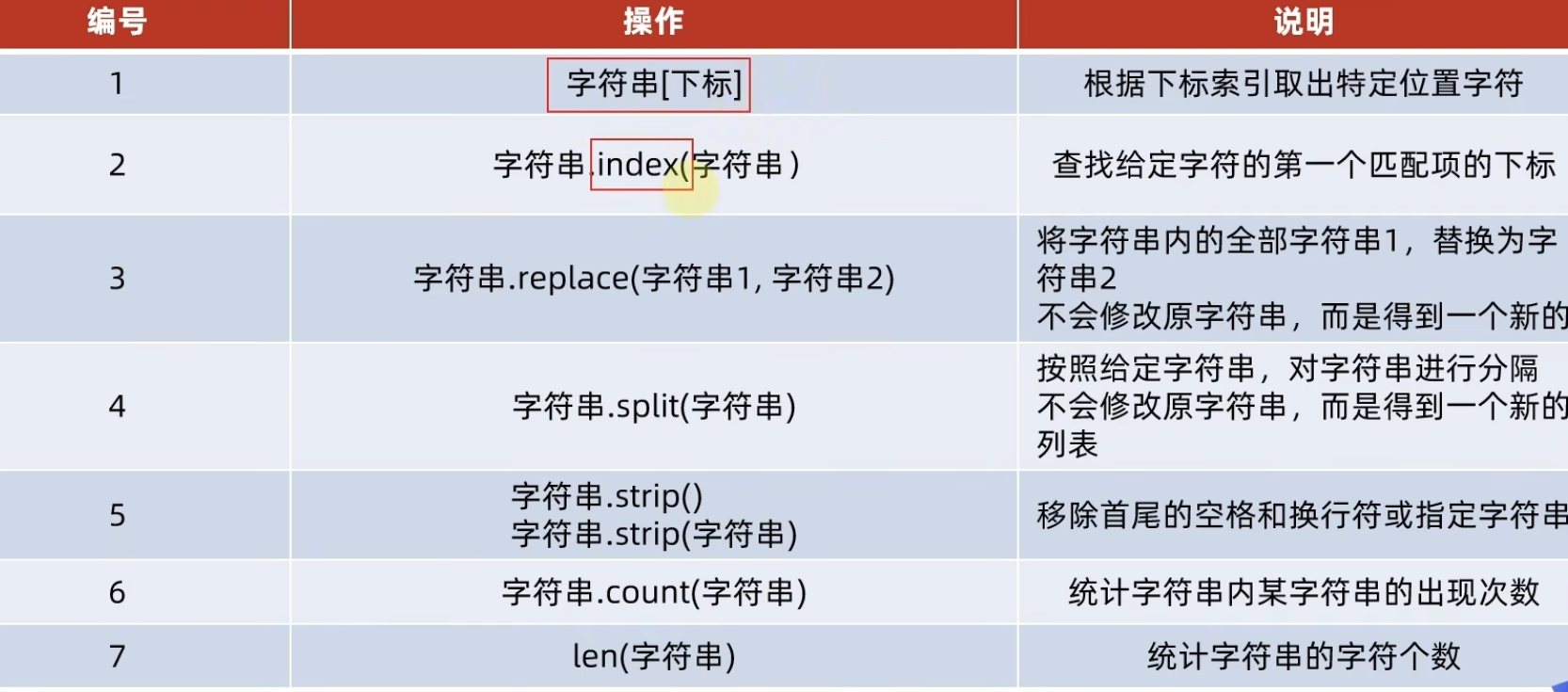
6.4 字符串 string
6.4.1 字符串的定义
字符串字符的容器,一个字符串可以存放任意数量的字符
注意:字符串是不可修改的容器
my_str = "hello world!"
# 查找元素的索引值
my_str.index(h) // 返回对应的索引值
# 字符串的替换
new_my_str = my_str.replace("it", "程序") # 字符串本身就不支持修改,是一个新的字符串
# 字符串的切分,字符串本身不发生改变,但是得到了一个新的列表对象
my_str.split("")
# 字符串的规整操作
my_str.strip() # 去掉前后的空格
my_str.strip("xxx") # 去掉前后的xxx字符串
# 统计某个元素出现的次数
count = my_str.count('x')
# 统计长度 len()注: 对于单个元素的元组定义,需要有一个逗号 (元素,);元组中的元素类型不受限
6.5 数据容器的切片操作
6.5.1 序列
概念:指连续、有序,可以使用下表索引的一类数据容器,列表,元组以及字符串均可以看作序列
6.5.2 切片操作
对于序列而言,切片是其的一个操作,即从一个序列中取出一个子序列
语法: 序列[起始下表:结束下标:步长]注意:一般左闭右开;步长是-1表示的是从后往前取,即序列的反转
6.6 集合
6.6.1 集合
概念:元素无序并且不重复,可以用于去重的操作
6.6.2 基本语法
# 定义集合字面量
{元素,元素,...,元素}
# 定义集合变量
变量名称 = {元素,元素,...,元素}
# 定义空集合
变量名称 = set()
变量名称 = {1,2,23}注意:集合是无序且不重复,并不支持索引访问,但是支持修改
my_set = {1,23,34}
# 添加元素
my_set.add("Python")
# 移除对应的元素
my_set.remove("Python")
# 从集合中随机取出元素
e = my_set.pop()
# 清空集合
my_set.clear()
# 集合的差集
set3 = set1.difference(set2)
# 消除差集
set1.difference_update(set2)
# 集合的合并
set3 = set1.union(set2)
# 统计集合的元素 len() 函数
# 集合的遍历,集合不支持下标索引,不能 while 循环
for e in set:
xxx 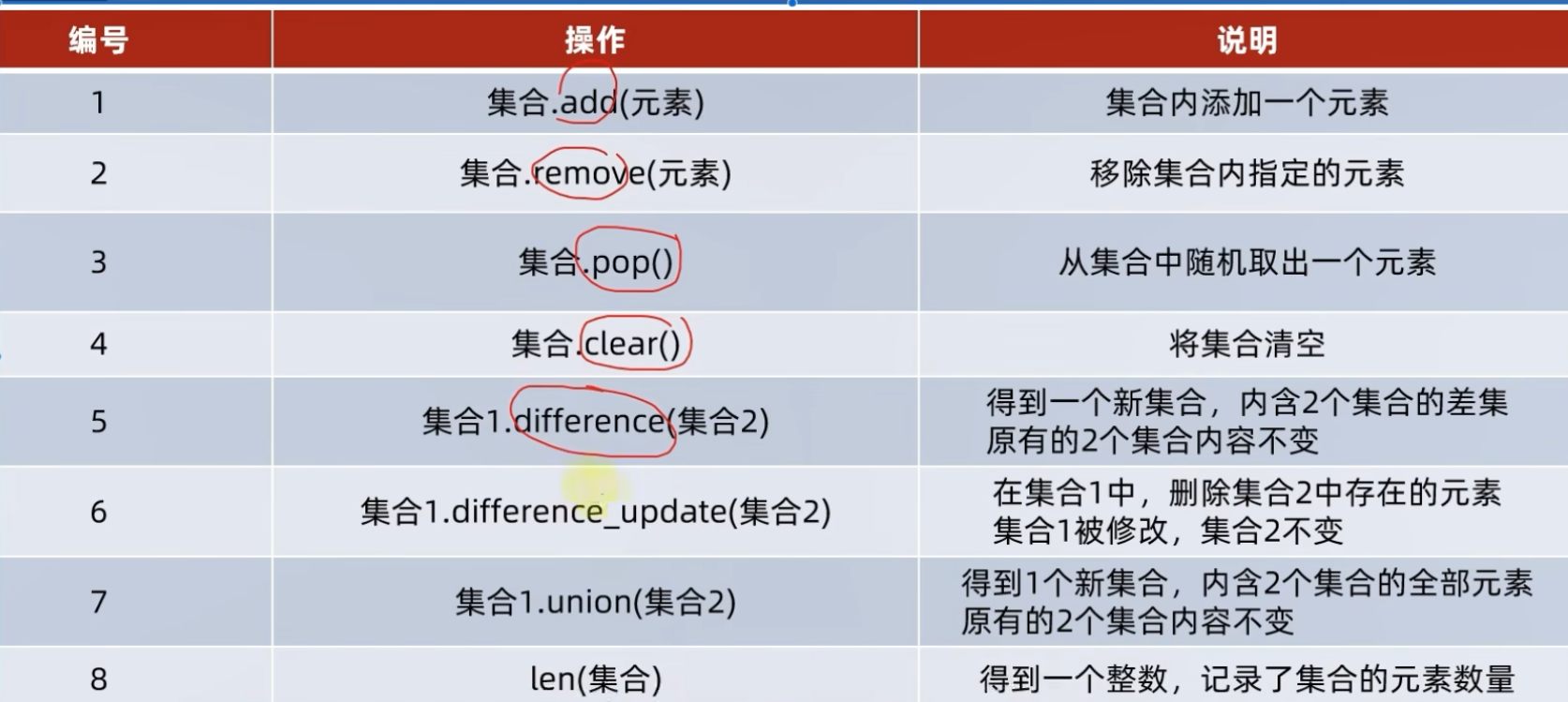
6.7 字典
6.7.1 字典
概念:通过 key 来检索到 value ,存储的是键值对
# 定义字典的字面量
{key: value, key: value, ...}
# 定义字典变量
my_dict = {key: value, key:value,...}
# 定义空字典
my_dict = {}
my_dict = dict()注意:Python 中的键是不可以重复的,如果存在则是更新操作;没有下标索引,仅可以通过key来获取对应的value;
Python 中的 key 和 value 可以是任意数据类型,key 不可以是字典 -> 字典是可以嵌套的
6.7.2 字典的常用操作
my_dict = {"小明":89,"小王":89}
# 新增元素
my_dict["小李"] = 90;
# 更新元素
my_dict["小王"] = 98;
# 删除元素
score = my_dict.pop(key)
# 清空元素
my_dict.clear()
# 获取全部的 keys
my_dict.keys()
# 遍历字典
for key in my_dict.keys():
xxx
for key in my_dict:
xxx
# 统计字典内的元素数量 len()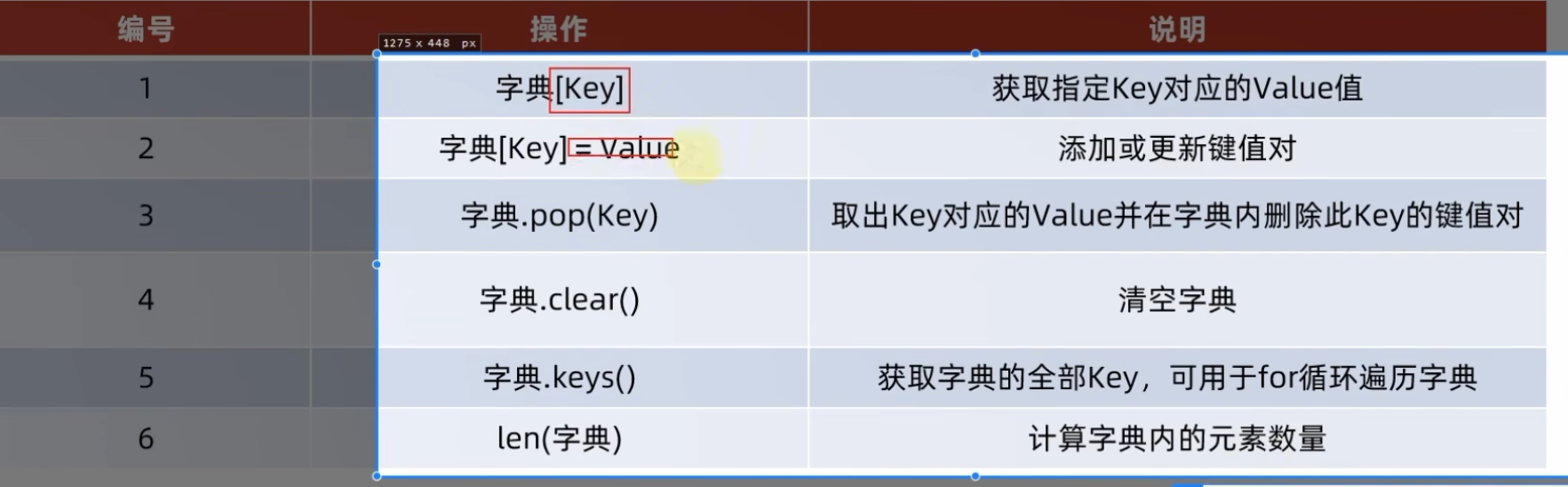
6.8 5类数据容器的整理

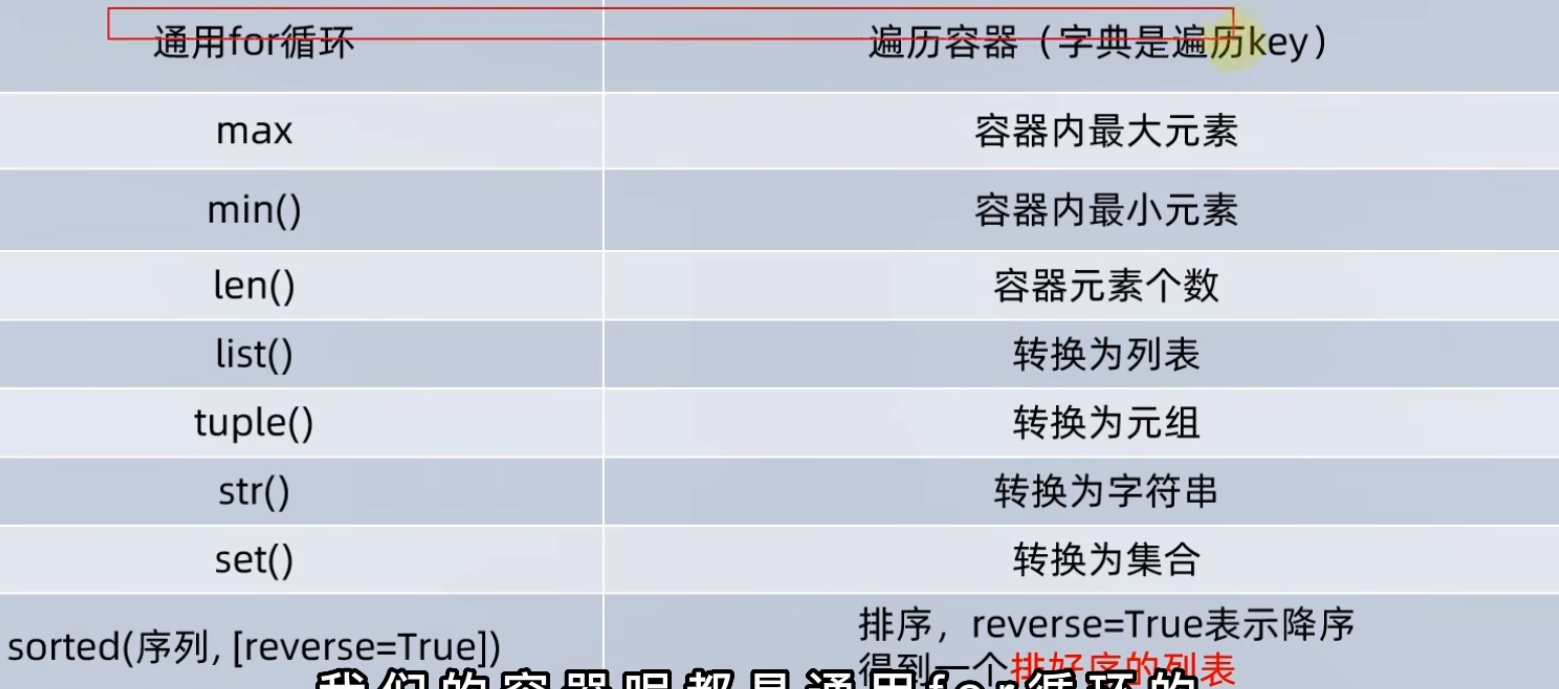
6.9 5类数据容器的通用操作
-
支持 for 的遍历
-
len 可以获取元素的数量
-
max(容器)/min(容器),可以获取容器中的最大元素,如果不是数值,则比较字符串的字典序
-
容器转化列表 list(),字符串转列表为每个字符军事元素;字典转列表,抛弃value
-
容器转元组,同转列表
-
容器转化字符串,会带上引号
-
容器转化集合,数据无序,且会去重
8. 通用排序 sorted(容器,reverse = True),将给定的容器进行排序,排序结果会变成 列表
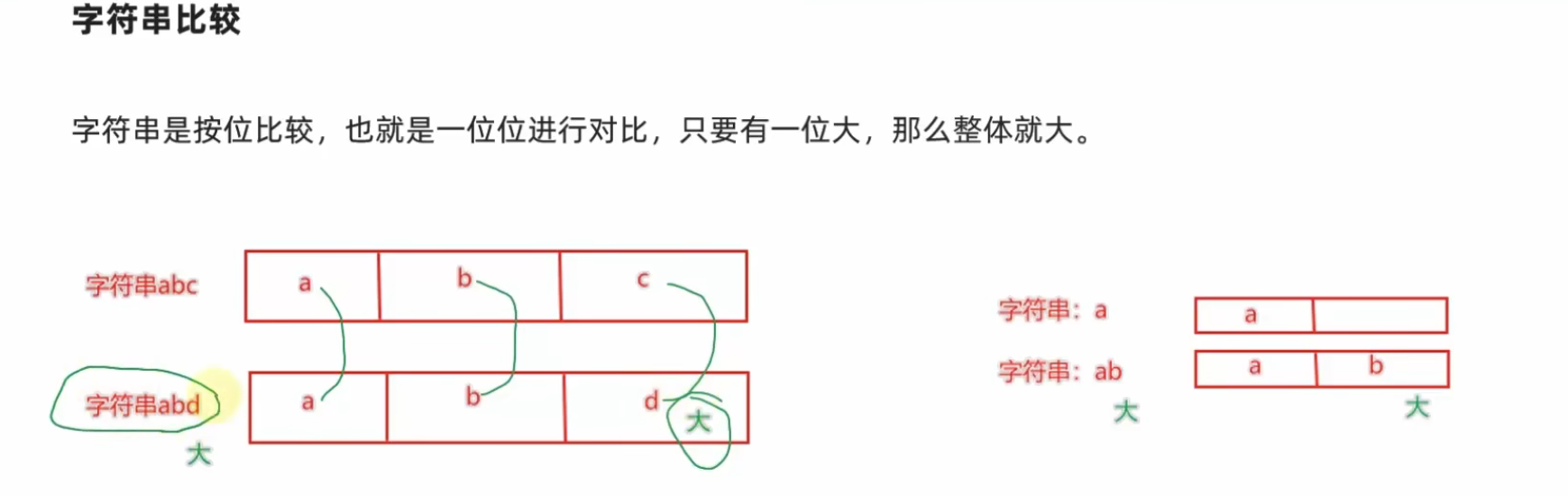
6.10 字符串的比较
- ASCII 码表
字符串比较的基础就是字符对应的码值
7. 第七章 函数进阶
7.1 函数多返回值
定义:通过 return 返回多个值,使用逗号进行分割
7.2 函数多种传参方式
函数的四种传参:
(1)位置参数:根据参数的位置来确定
(2)关键字参数:通过键值来进行传参,也清除了参数的顺序需求
(3)缺省参数/默认参数:为参数提供默认值
(4)不定长参数/可变参数:不确定调用的时候会传递多少参数,主要有两种类型:
<1>位置传递 *args 元组

<2> 关键字传递 **kwargs 字典

注意:位置参数和关键字参数混用的时候,必须在关键字参数的前面;默认参数一般是写在最后的
7.3 函数作为参数进行传递
定义:函数作为参数进行传递
注意:之前是数据的传递,现在是一种计算逻辑的传递,类型是 function
7.4 lambda 匿名函数
函数的定义:
(1)def 关键字,可以定义有名称的函数
(2)lambda关键字,可以定义匿名函数(无名称),只可以临时使用一次
注意:匿名函数只支持一行代码,并且不能被重复使用
def test_fun(compute):
return compute(1,2)
def compute(x, y):
return x+y
test_fun(lambda x, y: x+y)
lambda 传入参数: 函数体(一行代码)8. 第八章
8.1 文件编码概念
编码技术:要使用正确的的编码才能进行正确的读写操作,即内容和二进制之间相互的转化规则
- UTF-8:目前使用最多的
- BGK:之前用的中文
- Big5:繁体字
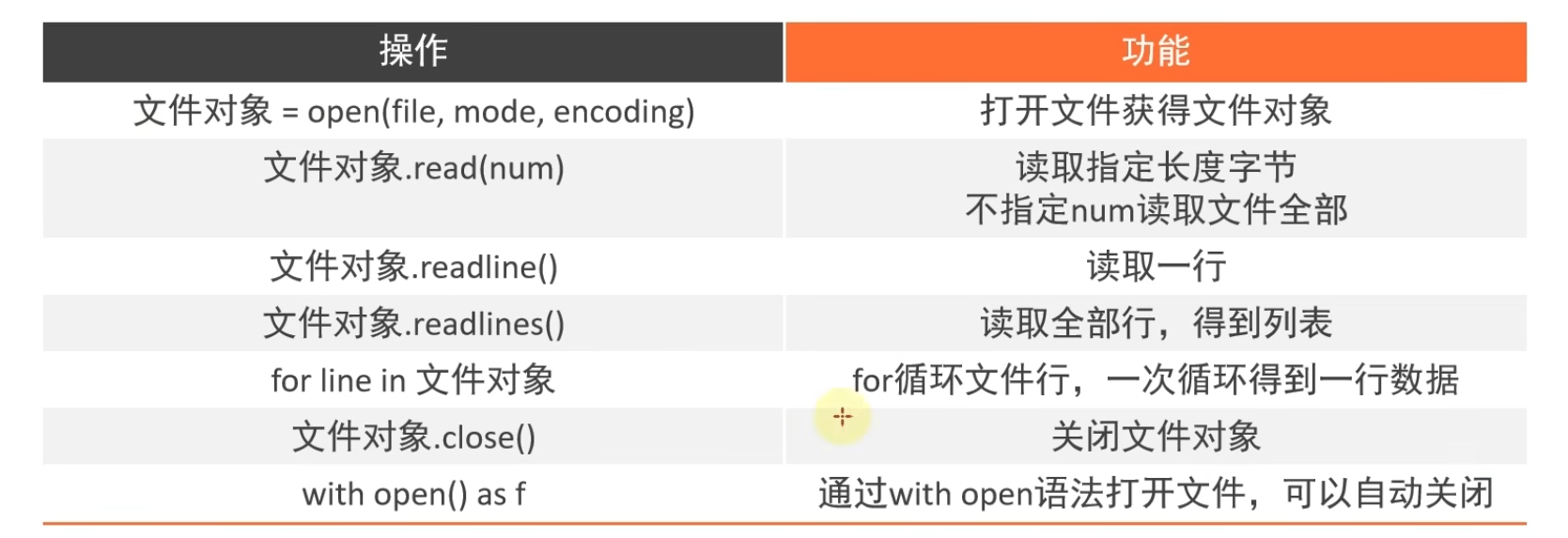
8.2 文件的读取
文件的3种基本操作:(1)文件打开(2)文件读写(3)读写文件
open(name, mode, encoding)
name: 文件路径
mode: w, r, a
encoding: 编码格式 utf-8,不是第三位,一般使用关键字参数来进行指定
read(num)
# num 表示从文件中读取的数据长度,单位是字节。没有参数表示全部内容
# 多次调用 read 会在上次读取的位置进行读取
readlines()
# 表示的是按照行的方式把在整个文件的内容一次性读取,返回一个列表
readline()
# 表示的是一次读取一行的内容
for line in open(name, 'r'):
print(line)注意:需要关注前面读取的指针会不会影响之后的读取;需要使用 f.close() 来停止对文件的占用;
with open ... 执行完成后对实现对文件的关闭
8.3 文件的写出

f.write():写到内存
f.flush():写到磁盘
8.4 文件的追加写入
注意:a 模式,文件不存在则会创建文件;文件存在则会在末尾追加文件
9. 第九章
9.1 了解异常
定义:程序运行过程中出现了异常 bug
9.2 异常的捕获
定义:在力所能及的范围内,对可能出现的 bug 进行提前准备和处理 -> 异常处理(捕获异常)
try:
可能发生错误的代码
except:
如果出现异常执行的代码
try:
可能发生错误的代码
except NameError as e:
如果出现异常执行的代码
# 多个异常
try:
可能发生错误的代码
except (NameError, ZeroDivsionError) as e:
如果出现异常执行的代码
try:
可能发生错误的代码
except Exception as e:
如果出现全部异常执行的代码异常的finally
try:
open...
except Exception as e:
print("出现异常执行")
else:
print("没有异常执行")
finally:
print("有没有异常都执行")
f.close()9.3 异常的传递性
定义:异常是具有传递性的

9.4 模块的概念
定义:是一个 Python 文件,以 .py 结尾,可以人为一个模块就是一个实现特定功能工具包,可以定义函数、类以及变量
[ from 模块名 ] import [类 | 变量 | 方法 | 模块] [ as 别名 ]9.5 自定义模块
注意:若有同名的模块,则后面的会覆盖前面;if main == "main" 表示,只有程序是直接执行的才会进入 if 内部,如果是被导入,则if无法进入 ;通过 all 变量去向外导出
9.6 自定义Python包
概念:Python包是一个文件夹,在该文件夹下包含一个 init.py 的文件,该文件夹可以用于包含多个模块文件,从逻辑上来看,包的本质依然是模块。
作用:主要是可以帮助我们管理多个模块
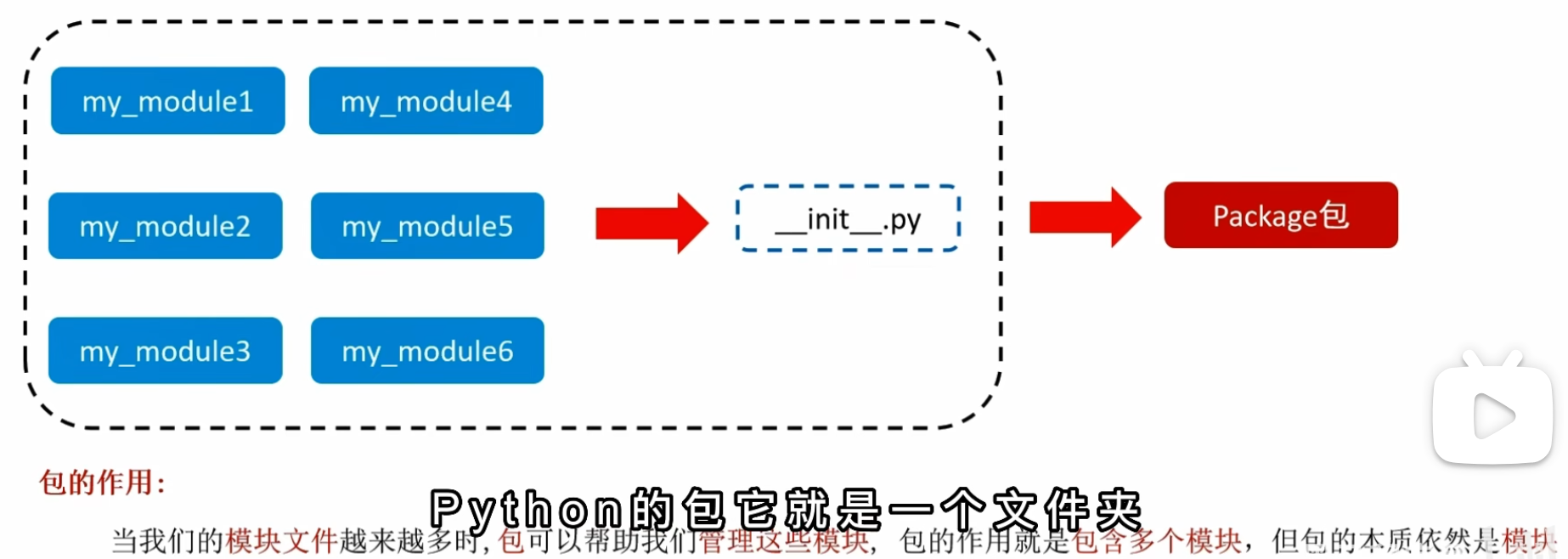
注意: init.py 文件,通过该文件能够表示一个文件夹是Python的包,而非普通的文件夹
all 变量的作用,控制 import * 能够导入的内容
9.7 安装第三方包
概念:非Python广泛内置的包,可以安装它们扩展功能,提高开发效率

9.8 安装第三方包
概念:非Python广泛内置的包,可以安装它们扩展功能,提高开发效率
10. 第十章
10.1 案例介绍 - 数据可视化
百度开源的数据可视化框架 echarts -> js; pyecharts -> pyecharts
10.2 JSON数据格式
概念 :json 以一种特定的格式去组织和封装数据,本质上是一个字符串,流通于各个编程语言
注意: Python使用json有很大的优势,无非是一个单独的字典或一个内部元素都是字典的列表

json.dumps(data, ensure_ascii=False) # 将python -> json str
json.loads(data) # 将json -> python [] or dict10.3 Pyecharts 模块的简介
link: Document
见代码
11. 第十一章
11.1 初识对象
与表格进行对比,在生活或者程序中,通过使用设计表格、生产表格、填写表格的形式来组织数据
- 设计表格 -> 设计类(Class)
- 打印表格 -> 创建对象
- 填写表格 -> 对象属性赋值
11.2 类的成员方法
class 类名称(Student):
类的属性 成员变量
类的行为 成员方法
def hello(self, 参数列表):
xxx
创建类对象的语法:
对象 = 类名称() self 关键字,一般是成员方法定义的时候必须填写的,有以下含义:
(1)表示类对象自身的意思
(2)在方法内部,想要访问类的成员变量,必须使用 self
(3)使用类对象调用方法的时候,self 会自动被 python 传入 传参数的时候可以当它不存在
11.3 类和对象
类就是具有相同特点的一类,对象则是类的具体实例
11.4 类的构造方法
Python 类使用 init() 方法,称之为构造方法
- 在构建类对象的时候,会自动执行,并将传入参数自动传递给 init 方法使用
- 构造方法一定要有 self 关键字,在方法内使用成员变量需要 self 关键字
11.5 魔术方法
Python 类内置的一些方法,即叫做魔术方法
(1)init(self) 构造方法
(2)str(self) 字符串方法,一般的话会给出对象的内存地址,其余会给自定义的
(3)lt(self, other) 小于或大于两种符号的比较
(4)le(self, other) 小于等于或大于等于两种符号的比较
(4)eq(self, other) 两个对象是否相等的比较,若自身不进行定义,则是比较内存地址
11.6 面向对象的三大特性
面向对象:基于模板类去创建实体对象,通过对象完成编程
面向对象的三大主要特性:封装、继承和多态
11.7 封装特性
封装:将模板类对应的属性和方法进行封装
私有成员: __ 两个下划线作为开头,即类中有些属性和方法并不支持对使用者是开放的
<1> 类对象无法访问私有成员
<2> 类中的其它成员可以访问私有成员
11.8 继承特性
继承:属于同一类别并且有明显的层级关系
class 类名(父类名):
类内容体继承的分类:分为单继承和多继承
<1> 单继承:子类只是继承一个父类
<2> 多继承:子类继承多个父类,从左到右依次继承,先继承的优先级高于后继承的
calss Phones(父类1,父类2,)
pass # 能保证语法上不出现错误,表示内容为空复写父类成员和调用方法,直接同名复写父类的成员变量和对应的方法;
注意:一旦复写父类成员,那么类对象调用成员的时候,就会调用复写后的新成员,因此有以下两种方法来调用
(1)
父类名.成员变量
父类名.成员方法(self)
(2)
super().成员变量
super().成员方法()11.9 变量的类型注解
功能:帮助第三方 ide 工具对代码类型进行类型的推断,协助代码提示;对代码的运行不会造成影响
变量: 类型
# 容器的类型注解
mylist: list[int] = [1,2,3,4]

11.10 函数和方法的类型注解
(1)形参的类型注解
(2)返回值的类型注解
def 函数方法名(形参:类型,...) ->返回值类型:
XXX11.11 Union 类型注解
当类型多样不太好进行注解的时候,使用union类型进行联合类型注解
# 使用 Union 类型,必须先进行导包
from typing import Union
my_list: list[Union[str, int]] = [1, 2, "hello"]11.12 多态特性
多态,指的是多种状态,即完成某个行为的时候,使用不同的对象实例会得到不同的状态
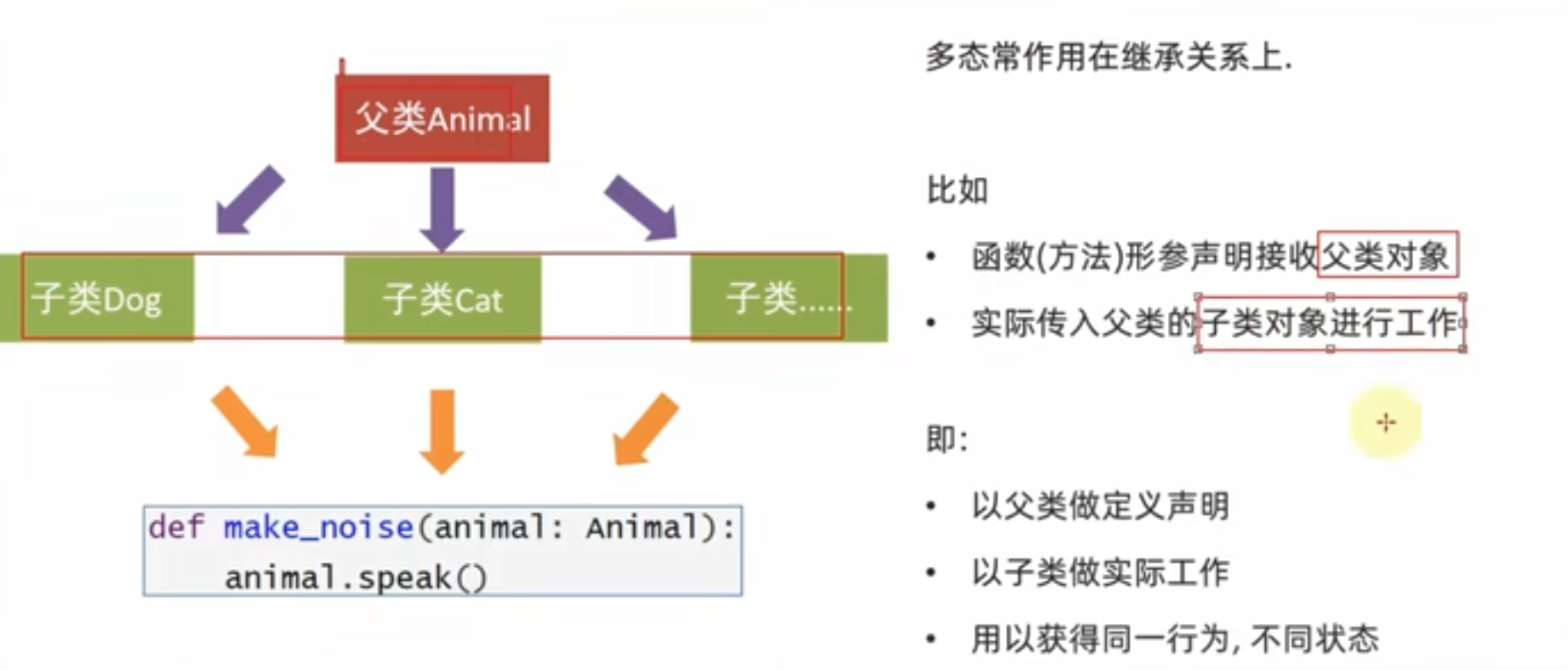

抽象类就好比定义一个标准,包含了一些抽象的方法,要求子类必须对其进行实现 -> 顶层的设计
抽象类的作用:
(1)多用于顶层设计(设计标准),以便子类做具体的实现
(2)要求子类必须对其的一些抽象方法进行复写
12. 第十二章
12.1 数据库的介绍
通过三个层级,即库->表->数据进行数据的存储
通过数据库管理系统来完成数据管理,即数据库软件
联系:通过数据库管理系统(数据库软件)来组织库,表和数据,同时借助SQL语言完成对数据的增删改查

12.2 Mysql 的入门使用
show databases; 展示数据库
use yansha;
show tables;
Mysql 的图形化工具 DBevar 安装、连接和使用
12.3 SQL 基础和DDL
SQL定义:结构化查询语言,用于访问和处理数据库的标准计算机语言
SQL的功能:基于其实现的功能,主要分为四种:
(1)DDL 数据定义
库和表的创建和删除
(2)DML 数据操纵
增删改
insert into stu() values()
delete from stu [where 条件判断]
update stu set 列 = 值 [条件判断](3)DCL 数据控制
用户增删,权限管理
(4)DQL 数据查询
基于需求查询和计算数据
select 字段列表 from 表名;
SQL的特点:
(1)大小写不敏感;
(2)支持单行和多行,最后以分号结尾;
(3)关于注释:支持单行和多行的注释

show databases;
use database; # 具体的数据库名称
show tables;
create database 数据库名称;
drop database 数据库名称;
select database(); # 查看当前使用的数据库
show tables;
drop table 表名称; # 删除特定的表
drop table if exists 表名称;
create table 表名称(
列名称 列类型,
列名称 列类型
);
列类型有
int --- 整数
float ---浮点数
varchar(长度) ---可变长度
date ---日期
timestamp --- 时间戳类型注意:字符串的值,出现在 sql 语句中,必须要使用单引号包围起来;
13. 第十三章
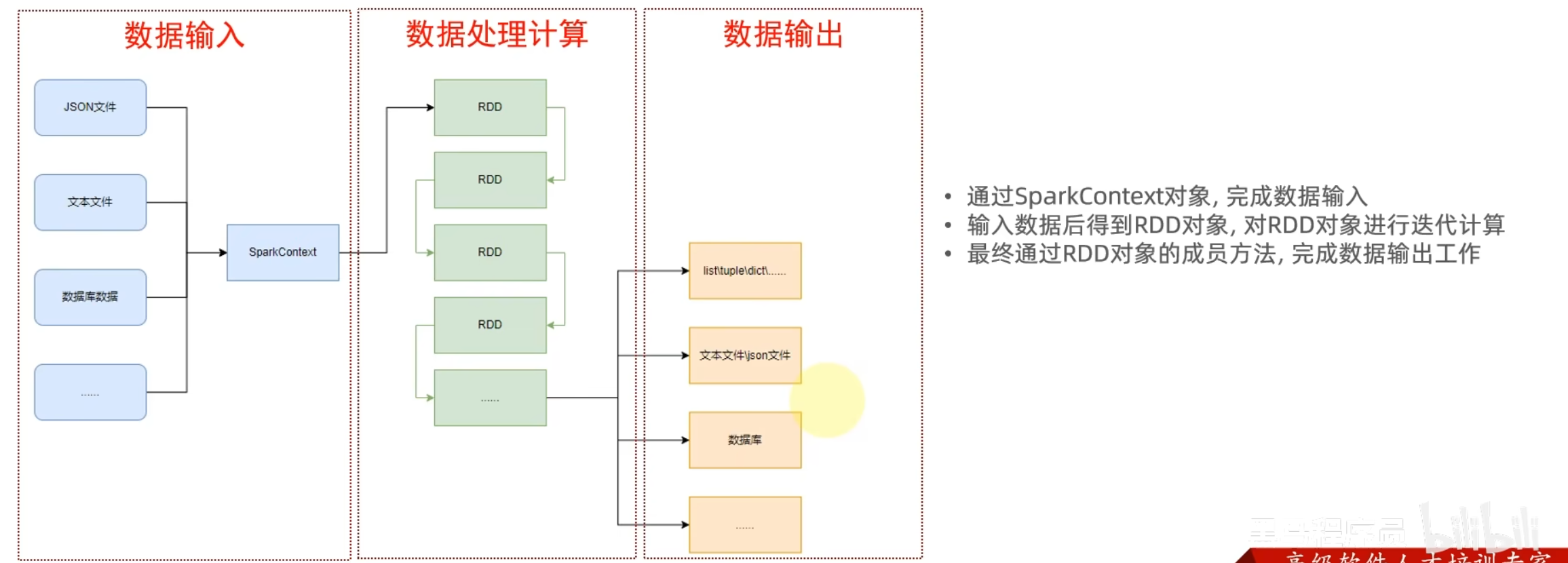
13.1 PySpark 实战
Spark 主要是用于大规模数据处理分析引擎的,是一款分布式计算框架,用于调度成百上千的服务集群
Spark的编程模型:
- 数据输入:通过 sparkContext 完成数据读取
- 数据计算:读取到的数据转化为RDD对象,调用RDD的成员方法完成计算
- 数据输出:调用RDD的数据输入相关成员方法,将结果输出到list,元组、字典等
RDD,即弹性分布式数据集,Spark针对数据的处理,都是以RDD对象作为载体
-
数据存储在RDD中
-
各类数据的计算方法,也都是RDD的成员方法
-
RDD的数据计算方法,返回值依旧是RDD对
14. 第十四章
14.1 闭包
Python 的闭包功能,无需定义全局变量可以通过函数持续访问和修改某个值

在闭包中,内部函数想要修改外部函数的变量值,需要使用 nonlocal 声明这个变量
14.2 装饰器
装饰器:一种能够在不破坏目标函数原有代码和功能的前提下,为目标函数增加新功能
14.3 设计模式
设计模式是一种编程套路,使用特定的套路来得到特定的效果
14.4 单例设计模式
单例模式就是一个类,只获取其唯一的类实例对象,持续复用它
- 节省内存
- 节省创建对象的开销
14.5 工厂模式
当需要大量创建一个类的实例的时候,通常使用工厂模式
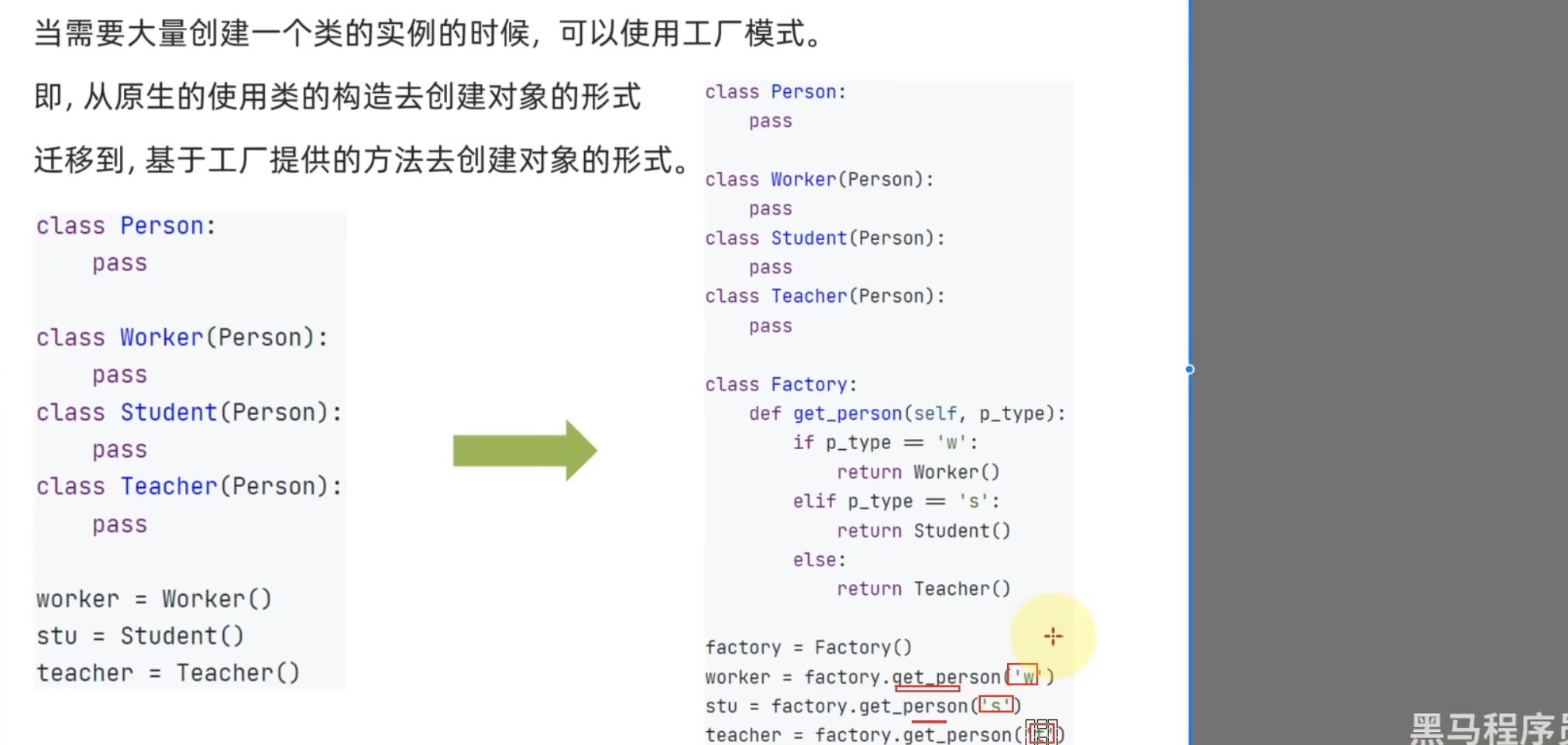
- 大量创建对象的时候有统一的入口,易于代码维护
- 当发生修改,仅修改工厂类的创建方式即可
- 符合现实世界的模式,即是由工厂来制作产品
14.6 多线程并行执行概念
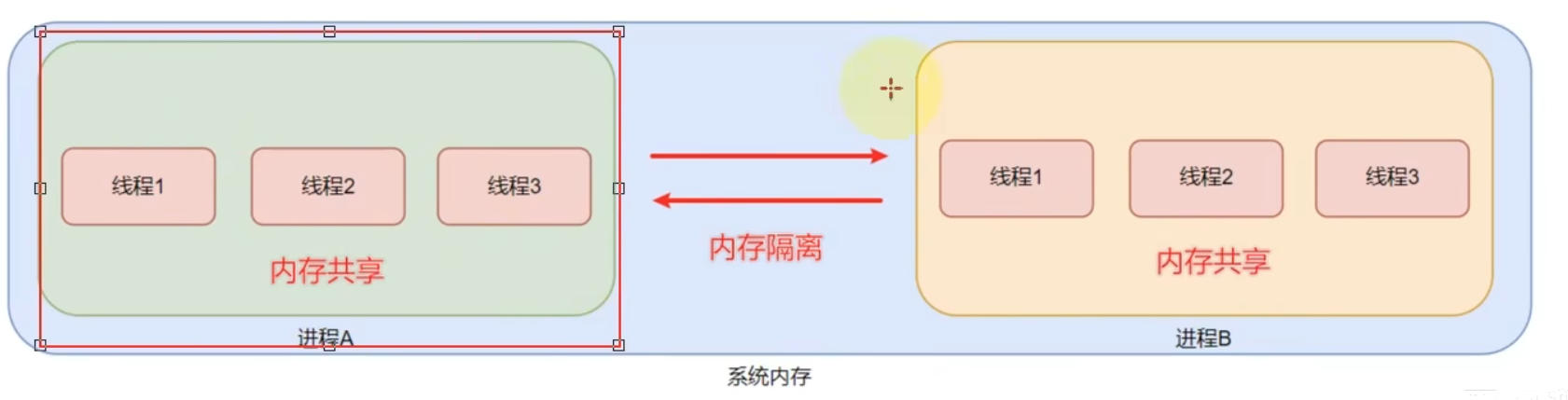
进程:进程就是一个运行在系统之上的进程,是计算机分配资源的最小单位 -》 多任务执行
线程:线程就是os执行的最小单元,是归属于进程的,同享进程下的所有资源 -> 多线程执行
注意点:
(1)进程之间是内存隔离的,即不同的进程拥有各自的内存空间
(2)线程之间是内存共享的,一个进程的多个线程之间是共享这个进程所有的内存空间
14.5 多线程编程
import threading
thread_obj = threading.Thread(target = sing)
thread_obj.start()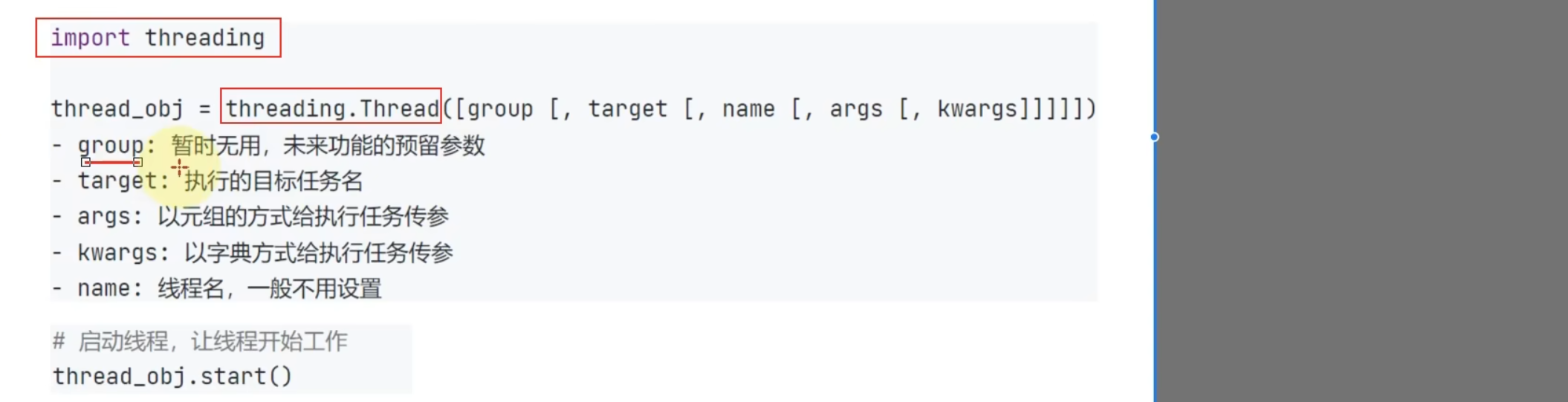
14.6 Socket 编程
视频到 139
Reference: