加法 ADD
减法 SUB
取负 NEG
比较 CMP
乘法 MUL
移位 LSL、LSR、ASL、ASR、ROL、ROR加法和减法
绝大多数微处理器都实现了带进位的加法指令,能够将两个操作数和条件码寄存器中的进位位加到一起。这条指令会使字长大于计算机固有字长的链接运算更加方便。
说明了如何使用带进位的加法指令实现链式运算。如:指令ADD r2,r1,r0将源寄存器r0和r1的内容相加,将结果保存到r2中,该操作产生的进位被保存到进位位中。
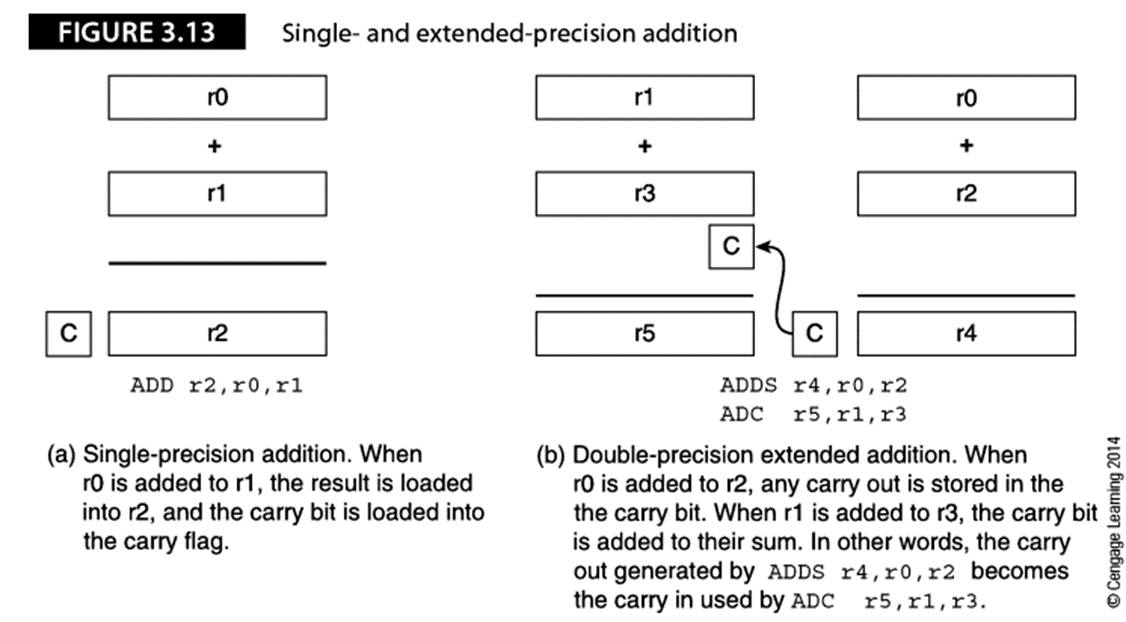
假设使用32位体系结构的ARM处理器,要处理64位整数并要完成64位加法。上图(b)说明了64位算术运算中如何使用32位寄存器来传播进位。两个64位数已经保存到寄存器r1、r0和r3、r2中。
指令ADDS r4,r0,r2,完成r0+r2并将结果保存到r4中,进位输出保存到CCR中进位位中。
指令ADC r5,r1,r3将高位的两个数字相加时,进位位也被加到r1与r3的和中。助记符ADC表示带进位的加法。
ARM还提供了SBC或带借位的减法指令来支持扩展精度的减法运算。
逆减法指令RSB:减法指令SUB r1,r2,r3被定义为r1<-r2 -- r3,逆减法指令RSB r1,r2,r3被定义为r1<-r3-r2
取负
取负就是用零减去一个数字。如r0的负数就是0 - r0。ARM没有这样的取负指令。可以使用逆减法来实现,因为RSB r1,r1,#0等价于NEG r1
比较
通过执行指令CMP Q,P比较P和Q时,将发生显示比较,这条指令会计算Q-P但
不会保存结果。比较操作会修改CCR的内容,后面的指令会测试CCR的值以决定
按顺序继续执行还是进行跳转。
考虑下面的例子:
CMP r1,r2 ; r1=r2?
BEQ DoThis ; 如果相等则跳转到DoThis
ADD r1,r1,#1 ; 否则r1 = r1 + 1
B Next ; 不要忘记跳过THEN部分代码
.
DoThis SUB r1,r1,#1 ; r1 = r1 -1
Next ... ; 两个分叉汇聚于此
乘法
乘法运算将两个m位的操作数相乘,得到一个2m位 的积。结果的位长加倍带
来一个问题。计算机要么自动将结果截断,32位乘以32位得到一个32位结果。
要么设计一个四操作数指令:两个源操作数,两个目的操作数(分别保存结果
的高半部分和低半部分)。而且,二进制补码加减法运算能得到正确结果,但
乘除法却不一定,即对有符号和无符号数不能使用同样的乘法操作。
有些微处理器提供了有符号和无符号乘法操作,以及结果为32位的16位乘法、
结果为64位的32位乘法。
ARM乘法指令MUL Rd,Rm,Rs计算保存在32位寄存器Rm和Rs中的两个32位有符号数的积,将结果保存在32位寄存器Rd中,仅存放64位积的低32位。当然,应保证结果不超出范围。如,计算121乘96:
MOV r0,#121 ; 将121加载到r0中
MOV r1,#96 ; 将96加载到r1中
MUL r2,r0,r1 ; r2 = r0 x r1
目的寄存器Rd和源寄存器Rm不用使用相同的寄存器,因为ARM在乘法计算过程中将Rd当作临时寄存器使用,这是Arm的一个特点。
除了32位乘法指令MUL外,ARM还包括:
UMULL 无符号长整型乘法(Rm x Rd乘积为64位,存放在两个寄存器中)
UMLAL 无符号长整型乘累加
SMULL 有符号长整型乘法
SMLAL 有符号长整型乘累加
MLA
ARM乘累加指令MLA,先进行乘法,再将乘积与另一个数相加。
MLA指令采用四操作数形式:MLA Rd,Rm,Rs,Rn。RTL定义为Rd<-RmxRs+Rn,32位数与32位数的乘积被截断为低32位结果。
内积运算
ARM乘累加操作使用一条指令完成乘法和加法运算,支持内积计算。
假设向量a有n个元素a1,a2,...,an,向量b有n个元素b1,b2,...,bn,则a与b的内积就是标量s=a x b = a1 x b1 + a2 x b2 +...+ an x bn
下面代码段展示MAL指令计算两个n元素向量Vector1和Vector2的内积:
n EQU 4
MOV r4,#n ; r4为循环计数器
MOV r3,#0 ; 将内积清零
ADR r5,Vector1 ; r5指向Vector1
ADR r6,Vector2 ; r6指向Vector2
Loop LDR r0,[r5],#4 ; REPEAT 读向量Vector1的一个元素并更新指针
LDR r1,[r6],#4 ; 读取向量Vector2的相应元素
MLA r3,r0,r1,r3 ; 乘累加操作r3= r3 + r0 x r1
SUBS r4,r4,#1 ; 循环计数器递减(更新CCR)
BNE Loop ; UNTIL所有计算完毕位操作
逻辑操作也叫位操作,这些操作被应用到寄存器的每一位。微处理器一般只支持AND(与)、OR(或)、NOT(非)和EOR或(异或)操作。
下面说明了对r1=110010102和 r0=000011112进行的逻辑操作:

逻辑运算的典型应用就是数据合并,即把多个变量合并到一个寄存器或存储单元中。
假设寄存器r0包含8位数bbbbbbxx,寄存器r1包含8位数bbbyyybb,寄存器r2包、
含8位数zzzbbbbb,x、y、z代表需要的位,b是不需要的位。希望把这些位合并
得到最后结果zzzyyyxx。通过以下代码可以到达目的:
AND r0,r0,#2_00000011 ; 保留2位xx,其他屏蔽
AND r1,r1,#2_00011100 ; 保留3位yyy,其他屏蔽
AND r2,r2,#2_11100000 ; 保留3位zzz,其他屏蔽
OR r0,r0,r1 ; 合并r1和r0得到000yyyxx
OR r0,r0,r2 ; 合并r2和r0得到zzzyyyxx
假设有一个8位二进制串abcdefgh,需要b、d两位清零,a、e、f三位置1,h位
取反。可以通过AND、OR和EOR操作完成:
AND r0,r0,#2_10101111 ; 清除b和d位,得到a0c0efgh
OR r0,r0,#2_10001100 ; a、e、f位置1,得到10c011gh
EOR r0,r0,#2_00000001 ; b位取反,得到10c011gh(h取反)位清楚指令BIC
ARM提供了位清除指令BIC,将第一个操作数与第二个操作数的反码进行与操作。如,IBC r0,r1,r2实现了:
如果BIC第二个操作数中某位为0,则将第一个操作数中对应的位复制到目的操作数中,如果第二个操作数中某位为1,则把目的操作数中对应的位清零。
如果r1=10101010且r2=00001111,则BIC r0,r1,r2的结果为:

可用BIC指令对寄存器的最低位字节清零。指令BIC r0,r1,#0xFF把寄存器r1中的32位复制到寄存器r0中,然后把r0中的第0~7位清零。
移位操作
移位操作就是把字中的位向左或向右移动一个或多个位置。当移位一个位串时,串的一端的位会被丢弃,并在另外一端补充新的位,如:

这里的移位是逻辑移位
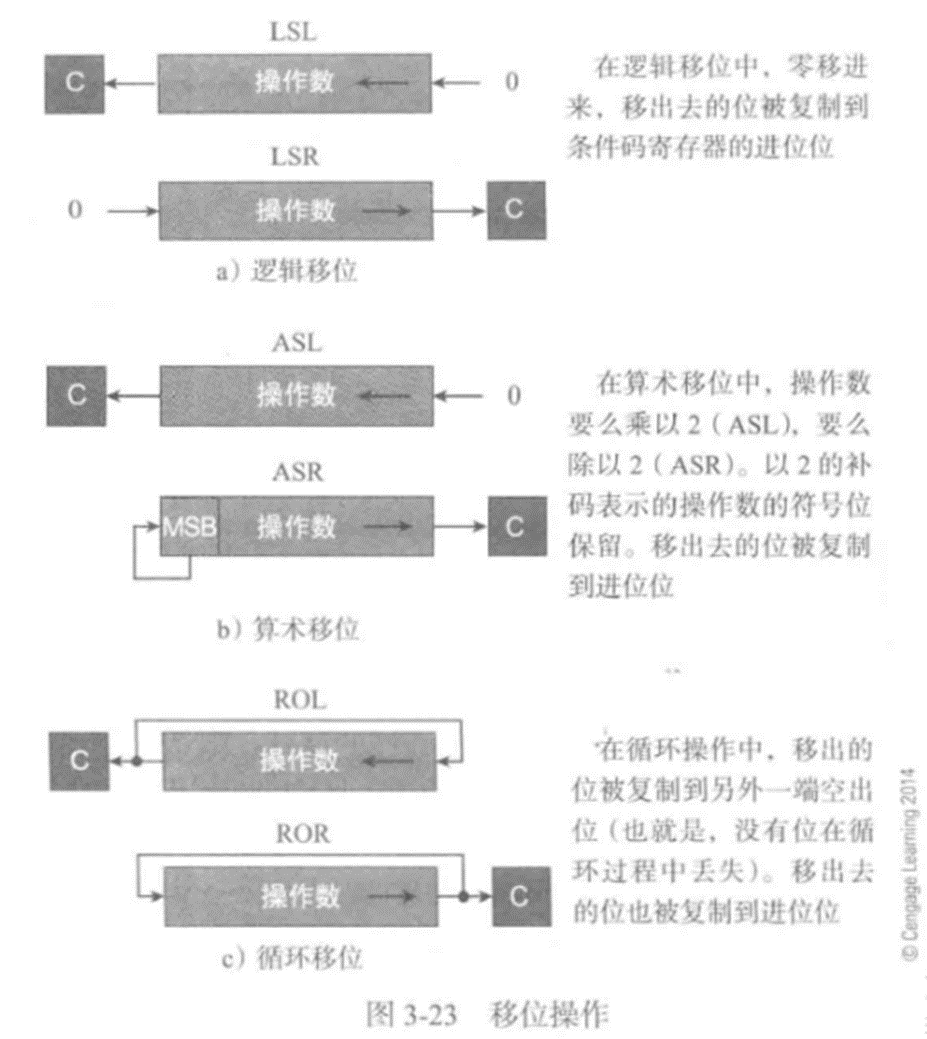
所有微处理器都支持逻辑移位操作。有些支持向左或向右移动一位,其他的支持多位移位。如
果移位的位数在指令中被编码为常量,这种移位叫作静态移位,在运行时不能改变移位位数,
如果移位的位数由寄存器的值指定,则叫作动态移位,可以在程序运行时修改移位的位数。
移位的典型应用是从一个字中提取特定的位。假设有一个8位的串bxxxxbbb,x表示要提取的位,
b表示无需关心的位。下面代码提取所需要的位且将其右对齐:
LSR r0,r0,#3 ; r0右移3位,得到000bxxxx
AND r0,r0,#2_00001111 ; 屏蔽不需要的位,得到0000xxxx
ARM没有独立的移位指令,移位是作为其他指令的一部分来实现的。ARM允许对寄存器-寄存
器型指令的第二个操作数进行移位。如,指令ADD r0,r1,r2,LSL #4,先寄存器r2逻辑左移4位,
然后将移位结果与寄存器r1相加。
算术移位
算术移位将操作数视作一个有符号二进制补码。可以用来完成除以2(右移一
位)或乘以2(左移一位)等运算。算术移位的目的是在进行移
位运算时保留二进制补码数的符号,移位运算代表乘以或除以2的幂。
算术左移与逻辑左移是等价的。算术右移会保留符号位,每次右移后符号位会
自动复制。
例如,如果将8位数11001110算术左移一位,得到10011100(最低位补0),而
算术右移一位得到11100111(符号位被复制)。一个整数算术左移m位相当于
乘以2m,而算术右移m位相当于除以2m。
循环移位
循环移位操作把寄存器的内容看作一个LSB(最低位)和MSB(最高位)相邻的环。如上图
(c),进行移位操作时,从一端移出的位会从另一端进来。与逻辑移位和算术移位相比,循
环移位不会丢失位。
例如,如果将8位数11001110循环左移一位,得到10011101,移出的位也被复制到进位寄存器。
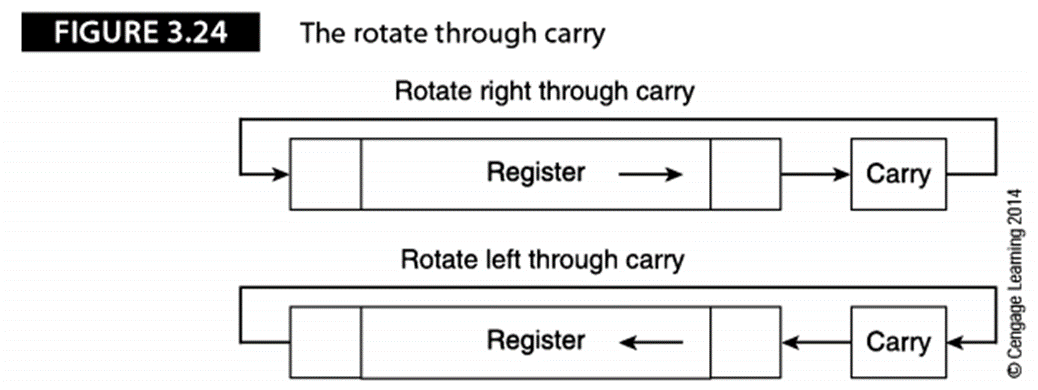
有些处理器实现了另一种循环操作,叫作扩展循环移位或带进位的循环移位。这种操作与循环
移位一样,只不过循环时包含了进位位。
如下图,移出的位被复制到进位位,原来的进位位变成了被移出的位:
ARM移位操作的实现
ARM没有独立的移位操作。实际上,移位操作与其他数据处理操作组合到一起,可以在使用第
二个操作数之前将其移位。
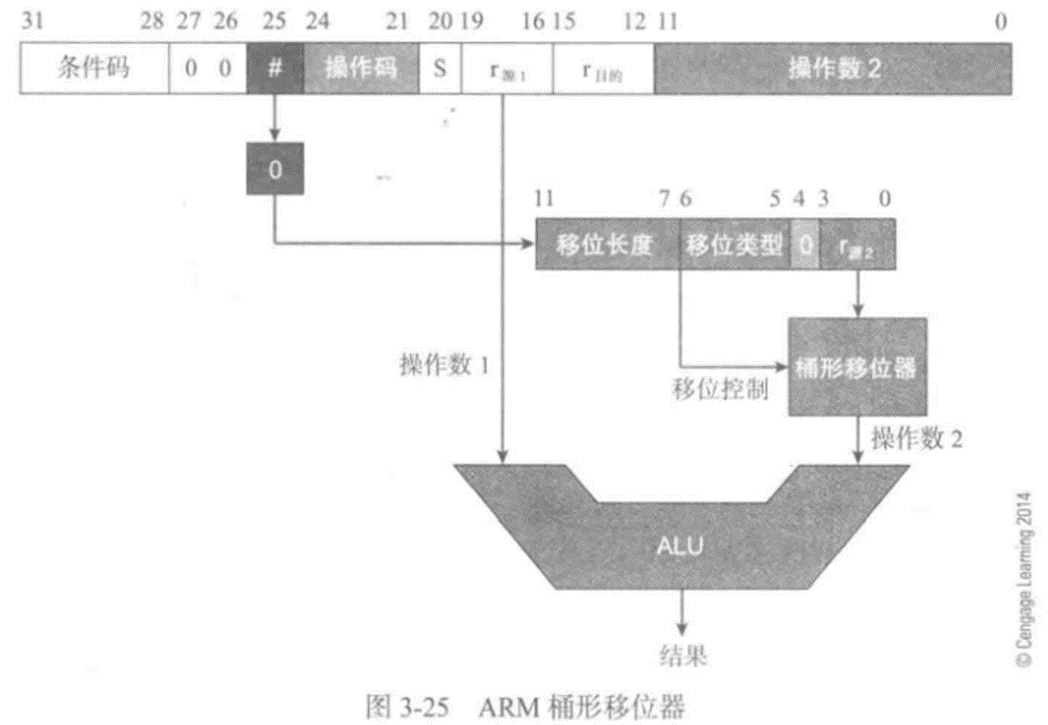
下图描述了ARM的移位机制,在第二个源操作数的数据通路上增加了一个桶形移位器:
考虑第二个源操作数被移位的ADD操作的例子:
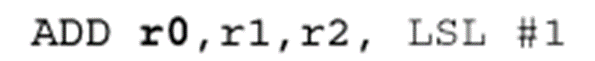
将r2与r1相加之前,先将r2的内容逻辑左移一位,因此该操作等价于
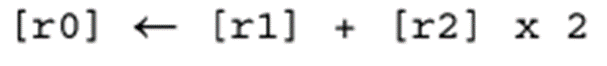
如果仅希望对寄存器进行移位操作,而不需要进行其他数据处理,可以使用下面指令:
MOV r3,r3, LSL #1
由于可以完成动态移位,也可使用指令MOV r4,r3,LSL r1,以r1为移位位数对r3
进行移位,结果送入r4。
假设r0中的数为0.00000010101111....,希望规格化为0.101...,如果用寄存器r1
表示指数,则执行MOV r0,r0,LSL r1可以在一个周期内完成规格化操作。
除了仅允许移动一位RRX指令外,ARM支持静态和动态移位。静态移位在编程
时就已经确定了移位的位数,而动态移位允许在执行代码时改变移位位数。如,
指令MOV r3,r3,LSL r2以r2的值为移位位数对r3进行逻辑左移。r2的值被看作模
32的数,因为移位不能超过32次。
ARM仅实现了以下5种移位操作
LSL 逻辑左移
LSR 逻辑右移
ASR 算术右移
ROR 循环右移
RRX 带进位的循环右移(移位一次)
尽管没有循环左移操作,可以借助循环右移实现。
下面说了4位二进制数的循环左移和循环右移。经过4次循环移位,操作数没有
变化。循环左移和循环右移是对称的。对于32位数,循环左移n位等价于循环
右移32-n位。
循环右移 循环左移
1101 开始 1101 开始
1110 循环右移1次 1011 循环左移1次
0111 循环右移2次 0111 循环左移2次
1011 循环右移3次 1110 循环左移3次
1101 循环右移4次 1101 循环左移4次
ARM没有实现带进位的循环左移操作,通过指令ADCS r0,r0,r0可以实现带进位
的循环左移,因为它把r0与r0以及进位位一起相加,并将结果保存在r0中(即
结果为2 x r0 + C),左移等价于乘以2,把进位位移动到最低位等价于加上进
位位,得到2 x r0 + C,指令后添加S会强制更新CCR,确保进位输出被加载到C
位。因此ADCS r0,r0,r0与RXL r0等价。
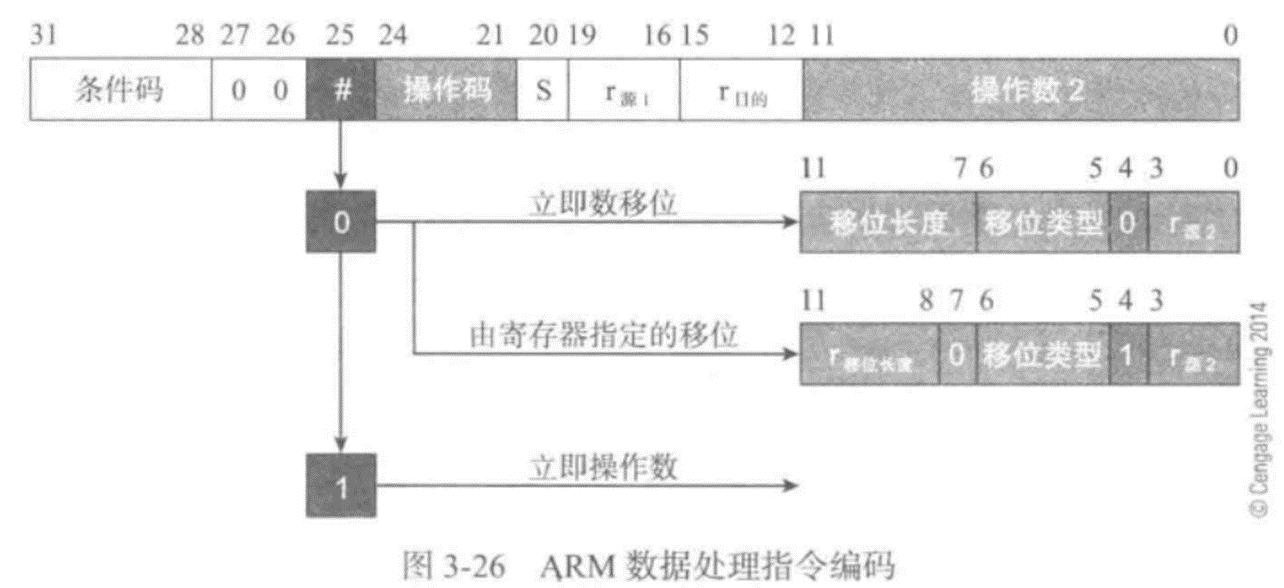
指令编码------洞察ARM体系结构
简单的看一下ARM的移位操作是如何编码的,下图给出了ARM数据处理指令的二进制编码,遵循RISC体系结构 的一般模式:包括一个操作数、两个寄存器操作数以及第三个多目的操作数。寄存器操作数r源和r目的定义了第一个源操作数和目的寄存器。0~11位是第二个源操作数的编码: