前言
在我们的日常工作中,经常会有Excel数据导出的需求。
但可能会遇到性能和内存的问题。
今天这篇文章跟大家一起聊聊Excel高性能导出的方案,希望对你会有所帮助。
1 传统方案的问题
很多小伙伴门在开发数据导出功能时,习惯性使用Apache POI的HSSF/XSSF组件。
这类方案在数据量超过5万行时,会出现明显的性能断崖式下跌。
根本原因在于内存对象模型的设计缺陷:每个Cell对象占用约1KB内存,百万级数据直接导致JVM堆内存爆炸。
示例代码(反面教材):
java
// 典型内存杀手写法
Workbook workbook = new XSSFWorkbook();
Sheet sheet = workbook.createSheet();
for (int i = 0; i < 1000000; i++) {
Row row = sheet.createRow(i); // 每行产生Row对象
row.createCell(0).setCellValue("数据"+i); // 每个Cell独立存储
}这种写法会产生约100万个Row对象和1000万个Cell对象(假设每行10列),直接导致内存占用突破1GB。
更致命的是频繁Full GC会导致系统卡顿甚至OOM崩溃。
2 流式处理架构设计
高性能导出的核心在于内存与磁盘的平衡。
这里给出两种经过生产验证的方案:
方案一:SXSSFWorkbook
使用SXSSFWorkbook类,它是Apache POI的增强版。
具体示例如下:
java
// 内存中只保留1000行窗口
SXSSFWorkbook workbook = new SXSSFWorkbook(1000);
Sheet sheet = workbook.createSheet();
for (int i = 0; i < 1000000; i++) {
Row row = sheet.createRow(i);
// 写入后立即刷新到临时文件
if(i % 1000 == 0) {
((SXSSFSheet)sheet).flushRows(1000);
}
}通过设置滑动窗口机制,将已处理数据写入磁盘临时文件,内存中仅保留当前处理批次。实测百万数据内存占用稳定在200MB以内。
方案二:EasyExcel
EasyExcel是阿里巴巴开源的Excel高性能处理框架,目前在业界使用比较多。
最近EasyExcel的作者又推出了FastExcel,它是EasyExcel的升级版。
java
// 极简流式API示例
String fileName = "data.xlsx";
EasyExcel.write(fileName, DataModel.class)
.registerWriteHandler(new LongestMatchColumnWidthStyleStrategy())
.sheet("Sheet1")
.doWrite(data -> {
// 分页查询数据
int page = 0;
while (true) {
List<DataModel> list = queryByPage(page, 5000);
if (CollectionUtils.isEmpty(list)) break;
data.write(list);
page++;
}
});该方案通过事件驱动模型 和对象复用池技术,百万数据导出内存占用可控制在50MB以下。
其核心优势在于:
- 自动分批加载数据(默认每批次5000条)
- 通过反射缓存消除重复对象创建
- 内置样式优化策略避免内存碎片
3 数据库查询的黄金法则
即便导出工具优化到位,若数据查询环节存在瓶颈,整体性能仍会大打折扣。这里给出三个关键优化点:
3.1 解决深度分页问题
传统分页查询在百万级数据时会出现性能雪崩:
plain
SELECT * FROM table LIMIT 900000, 1000 -- 越往后越慢!正确姿势应使用游标方式:
java
// 基于自增ID的递进查询
Long lastId = 0L;
int pageSize = 5000;
do {
List<Data> list = jdbcTemplate.query(
"SELECT * FROM table WHERE id > ? ORDER BY id LIMIT ?",
new BeanPropertyRowMapper<>(Data.class),
lastId, pageSize);
if(list.isEmpty()) break;
lastId = list.get(list.size()-1).getId();
// 处理数据...
} while (true);该方案利用索引的有序性,将时间复杂度从O(N²)降为O(N)。
3.2 减少字段数量
sql
-- 错误写法:全字段查询
SELECT * FROM big_table
-- 正确姿势:仅取必要字段
SELECT id,name,create_time FROM big_table实测显示,当单行数据从20个字段缩减到5个字段时,查询耗时降低40%,网络传输量减少70%。
3.3 连接池参数调优
yml
# SpringBoot配置示例
spring:
datasource:
hikari:
maximum-pool-size: 20 # 根据CPU核数调整
connection-timeout: 30000
idle-timeout: 600000
max-lifetime: 1800000导出场景建议使用独立连接池,避免影响主业务。
连接数计算公式:线程数 = CPU核心数 * 2 + 磁盘数。
4 生产级进阶技巧
4.1 异步分片导出
想要提升Excel数据导出的性能,我们必须使用多线程异步导出的方案。
具体示例如下:
java
@Async("exportExecutor")
public CompletableFuture<String> asyncExport(ExportParam param) {
// 1. 计算分片数量
int total = dataService.count(param);
int shardSize = total / 100000;
// 2. 并行处理分片
List<CompletableFuture<Void>> futures = new ArrayList<>();
for (int i = 0; i < shardSize; i++) {
int finalI = i;
futures.add(CompletableFuture.runAsync(() -> {
exportShard(param, finalI * 100000, 100000);
}, forkJoinPool.commonPool()));
}
// 3. 合并文件
CompletableFuture.allOf(futures.toArray(new CompletableFuture)
.thenApply(v -> mergeFiles(shardSize));
return CompletableFuture.completedFuture(taskId);
}通过分治策略将任务拆解为多个子任务并行执行,结合线程池管理实现资源可控。
4.2 配置JVM参数
我们需要配置JVM参数,并且需要对这些参数进行调优:
java
// JVM启动参数示例
-Xmx4g -Xms4g
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:ParallelGCThreads=4
-XX:ConcGCThreads=2
-XX:InitiatingHeapOccupancyPercent=35这样可以有效的提升性能。
导出场景需特别注意:
- 年轻代与老年代比例建议2:1
- 避免创建超过50KB的大对象
- 使用对象池复用DTO实例
4.3 整体方案
Excel高性能导出的方案如下图所示:
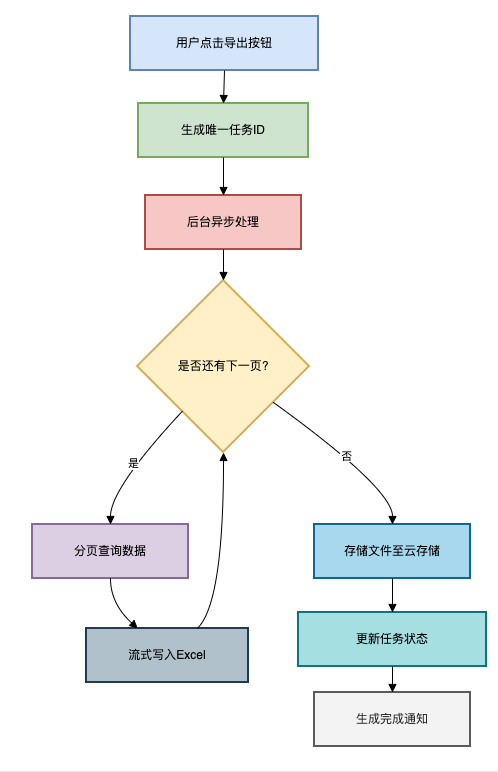
用户点击导出按钮,会写入DB,生成一个唯一的任务ID,任务状态为待执行。
然后后台异步处理,可以分页将数据写入到Excel中(这个过程可以使用多线程实现)。
将Excel文件存储到云存储中。
然后更新任务状态为以完成。
最后通过WebSocket通知用户导出结果。
5 总结
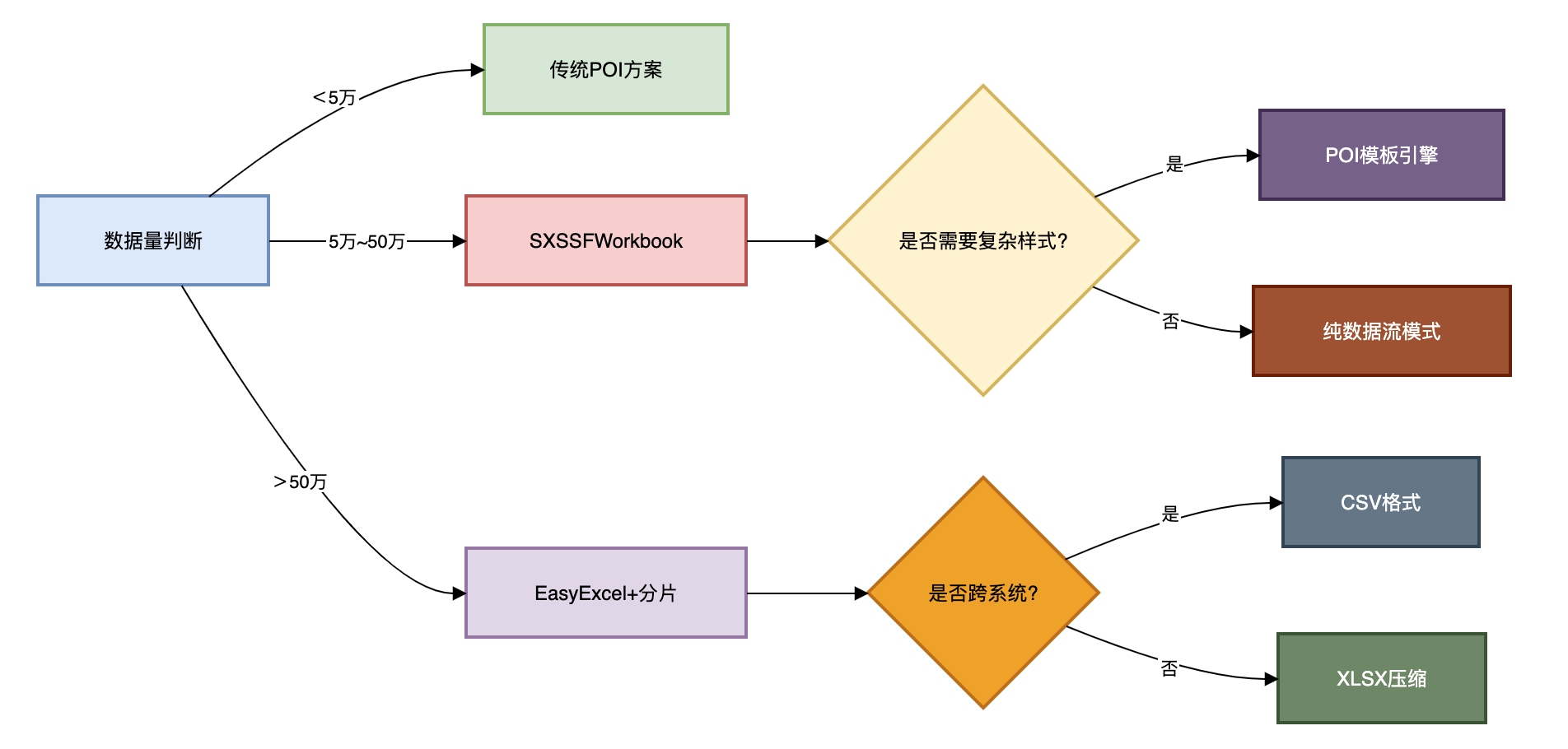
经过多个千万级项目的锤炼,我们总结出Excel高性能导出的黄金公式:
高性能 = 流式处理引擎 + 分页查询优化 + 资源管控
具体实施时可参考以下决策树:
最后给小伙伴们的三个忠告:
- 切忌过早优化:在需求明确前不要盲目选择复杂方案
- 监控先行:务必埋点记录导出耗时、内存波动等关键指标
- 兜底策略:始终提供CSV导出选项作为保底方案
希望本文能帮助大家在数据导出的战场上,真正实现"百万数据,弹指之间"!
最后说一句(求关注,别白嫖我)
如果这篇文章对您有所帮助,或者有所启发的话,帮忙关注一下我的同名公众号:苏三说技术,您的支持是我坚持写作最大的动力。
求一键三连:点赞、转发、在看。
关注公众号:【苏三说技术】,在公众号中回复:进大厂,可以免费获取我最近整理的50万字的面试宝典,好多小伙伴靠这个宝典拿到了多家大厂的offer。