文章目录
- List的特点介绍
- lpush,lpushx,rpush,rpushx命令
- lrange命令
- lpop和rpop
- lindex命令
- linsert命令
- llen命令
- [lrem 命令](#lrem 命令)
- ltrim命令
- lset命令
- 阻塞版本的命令
- 命令小结
- list的内部编码
- List的应用场景
List的特点介绍
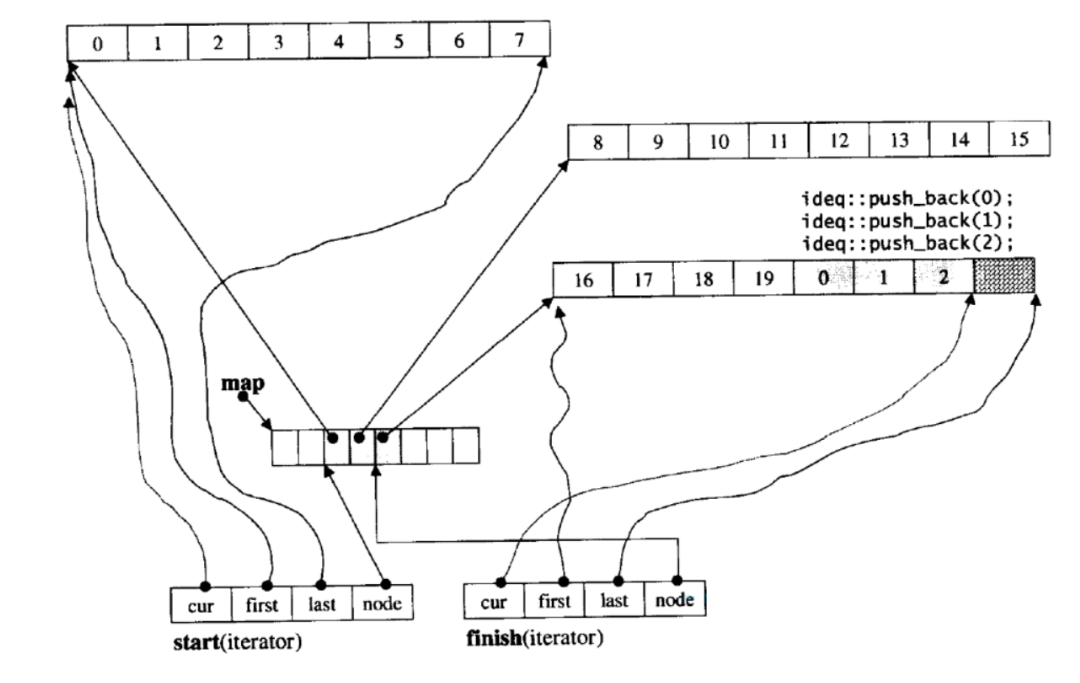
列表相当于一个数组或者顺序表,但是不是一个简单的数组,而是接近双端队列(deque)的结构。
对于双端队列来说,头插头删和尾插尾删的效率都很高,时间复杂度是O(1).
对于普通的数组来说,只有尾插尾删的效率高一点,但是头插和头删会涉及到内存的大量操作,效率不高。
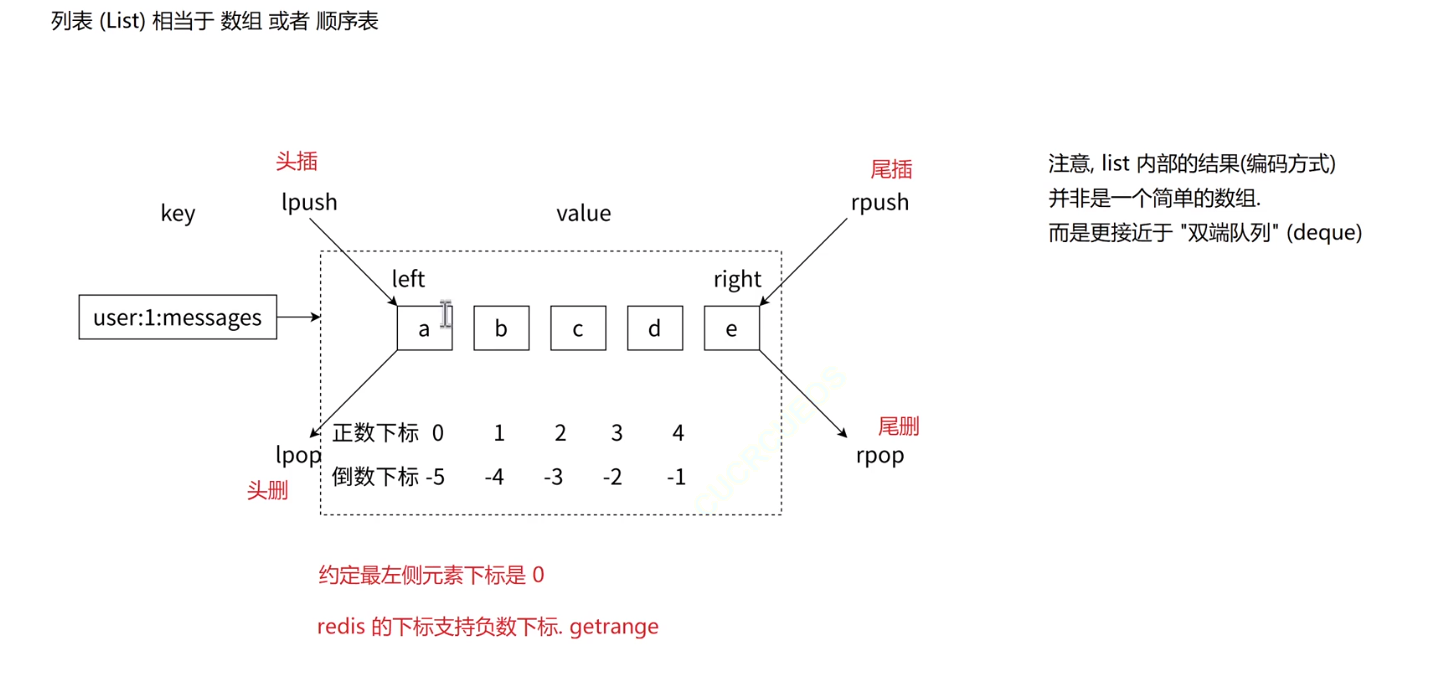
列表类型的特点:
-
- 列表中的元素是有序 的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表,例如要获取上图第 5 个元素,可以执⾏ lindex user:1:messages 4 或者倒数第 1 个元素,lindex
user:1:messages -1 就可以得到元素 e。
- 列表中的元素是有序 的,这意味着可以通过索引下标获取某个元素或者某个范围的元素列表,例如要获取上图第 5 个元素,可以执⾏ lindex user:1:messages 4 或者倒数第 1 个元素,lindex
这里的有序两个字,要根据上下文区分。
很明显,列表的有序指的是元素按照一定的顺序排列的。
但是实际中的有序,可能是升序和降序,也有可能是按照某个条件进行的有序。
举个例子:假如面试官问你堆栈的区别,你这时候就先不要着急回答。
而是先反问面试官,您这里说的堆栈,是数据结构的堆栈呢,还是操作系统的堆栈呢,还是JVM中的堆栈呢?亦或者是进程地址空间的堆栈呢?
还有一个同步,同步是指通过加锁来保证线程安全的同步呢,还是IO中的同步和异步(这里的异步其实就是并发)中的同步呢?
-
- 区分获取和删除的区别,例如 lrem 1 b 是从列表中把从左数遇到的前 1 个 b 元素删除,这个操作会导致列表的⻓度从 5 变成 4;但是执⾏ lindex 4 只会获取元素,但列表⻓度是不会变化的。
-
- 列表中的元素是允许重复的。
deque的底层结构介绍如下:
注意区分lindex和lrem,即获取元素和删除元素的区别。
lindex 能获取到元素的值,lrem也能返回被删除的元素的值。
因为当前的list的头和尾都能高效地插入和删除元素,所以当前的List可以用来作栈和队列使用。
后端开发中,栈用的比较少,但是队列就非常重要。比如使用队列实现生产消费者模型。
还有实现消息队列。
lpush,lpushx,rpush,rpushx命令
将一个或多个元素头插到list中
lpush key element element ...
比如:lpush key 1 2 3 4 ,插入完成后,列表的元素是4 3 2 1
返回值:插入后的list的长度。
如果key已经存在,且key对应的value不是list类型,则lpush命令会报错。
Redis中所有类型的容器都是类似效果。
时间复杂度O(1).
lpushx命令:
在 key 存在时,将⼀个或者多个元素从左侧放⼊(头插)到 list 中。不存在,直接返回
lpushx key element element ...
时间复杂度O(1)
rpush和rpushx,其实就是尾插入,其他的完全相同。
操作的时间复杂度也是O(1)
lrange命令
获取key对应的start stop区间的元素,左闭右闭。
lrange key start stop
时间复杂度O(n)
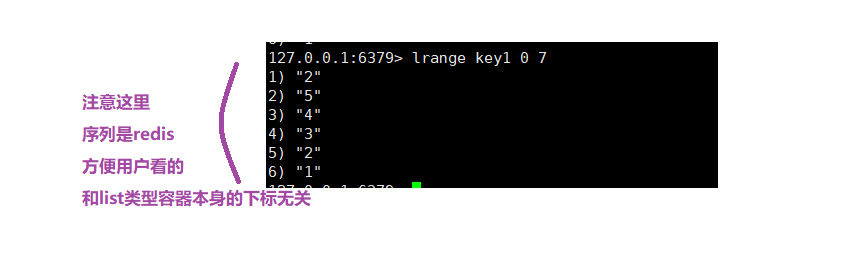
如果给出的下标超出范围了,在Redis中的做法是:
直接尽可能给到区间内的元素,如果下标非法,就尽可能获取对应的内容。
这就是所谓的 "鲁棒性":你对我越粗鲁,我表现的越棒。(其实就是容错性强了)
然而在C++中,下标超出范围,这是一个未定义行为:
1.可能导致程序崩溃
2.可能得到不合法的数据
3.可能得到看起来合法,但是是错误的数据。
4.可能得到一个恰好符合结果的数据
就像是开盲盒一样。
缺点:程序员不能第一时间发现问题,可能会出现连锁反应。
优点:效率是最高的。相比其他编程语言,比如java,对下标超范围行为会多了一个合法性验证,然后抛异常,这就导致多了一些动作。
但是人家java这样做也有优点,就是对程序员来说能更快发现问题,也就能更高效开发代码。
所以就产生了两个问题:
是机器跑得快重要呢,还是程序员开发代码更快重要呢?
肯定是程序员开发代码重要,因为涉及到了利益问题,程序员如果开发的慢了,可能要加班修bug开发代码,甚至如果搞砸了,可能要丢失年终奖。但是对程序员来说,机器跑的快不快跟我有啥关系呢,跑的慢的话,让老板多搞两台机器过来不就行了嘛。
lpop和rpop
lpop相当于头删
lpop key
返回值:返回删除后的元素,如果列表没有元素了,则返回nil
时间复杂度O(1)
rpop相当于尾删
rpop key
返回值:返回删除后的元素,如果列表没有元素了,则返回nil
时间复杂度O(1)
从Redis 6.2版本中,新增了一个count选项(当前我用的是Redis 5,暂不考虑)
lpop key count
表明要头删几次
lindex命令
给定下标,获取到指定下标的元素
lindex key index
支持负数下标,-1表示倒数第一个了。依次类推。
如果下标非法,返回nil
时间复杂度O(n),因为在redis的list列表不是一个简单的数组,所以不能理解成O(1)的复杂度。
linsert命令
在指定位置插入元素
linsert key <before | after> pivot element
在指定的元素pivot之前/之后,插入元素element
如果指定的元素pivot在列表中存在多个,则在从左往右搜索到的第一个pivot之前/之后插入。
llen命令
获取key对应的list的长度
llen key
lrem 命令
rem就是remove命令的缩写,就是删除命令。
lrem key count element
count是要删除的个数,element是删除的值
官方文档给定的解释如下

意思是:
如果count > 0,则是从头到尾开始删除等于element的元素,删count个。
如果count < 0, 则是从尾到头开始删除等于element的元素,删count个。
如果count = 0, 则是删除所有等于element的元素。
lrem返回值是被删除的元素个数。
ltrim命令
该命令是保留key对应的list的start stop区间内的元素(同样是左闭右闭),区间外的元素都删除。
ltrim key start stop
时间复杂度O(1),也可以理解为O(N),这个N是要删除的元素个数。
lset命令
把key对应的list列表中的index下标的元素修改成element
lset key index element
时间复杂度O(N),如果是修改头或者尾,则时间复杂度是O(1)
如果给的下标非法,则直接报错。
相比于lindex命令不同的是,lindex命令对于非法的下标不报错,而是尽可能满足。。。
阻塞版本的命令
blpop和brpop
blpop key key ... timeout
意思是可以同时对多个key的list进行头删
返回值是成功执行blpop命令的key和其删除的元素
brpop key key ... timeout
同理
这个timeout(必选项,单位是秒)是设置阻塞的时间,下面会详细介绍
在list中存在元素的情况下,blpop和brpop命令和lpop,rpop命令作用完全相同。
但是如果list中没有元素,则blpop和brpop会产生阻塞。
这里的阻塞很好理解,就是生产消费者模型中的阻塞。
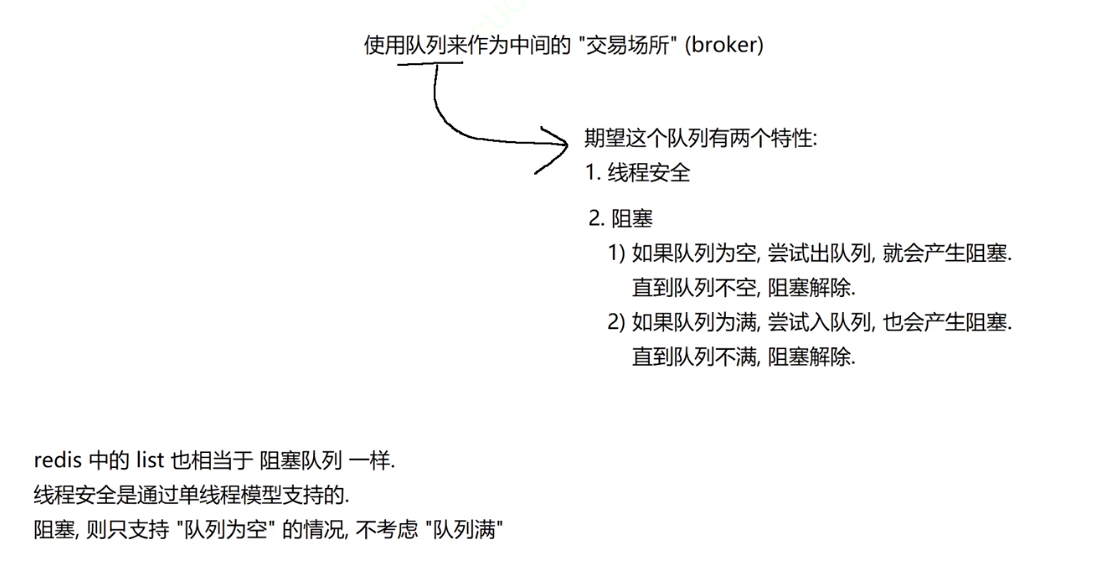
这里并不是无休止地阻塞,阻塞时间由timeout决定,在阻塞期间,Redis可以执行其他命令(这是经过特殊处理的,毕竟怎么可能让两个命令阻塞住Redis处理命令时的单线程模型呢,如果阻塞住了, 其他客户端发来的命令请求就得不到执行了。
注意事项:
- 1.如果命令设置了多个key,那么会从左到右遍历这些key,一旦有其中一个key对应的list的元素就绪了,就会马上头删该key对应的list,然后立即返回。
- 2.如果多个客户端同时对一个key进行blpop/brpop,则最先执行命令的客户端会得到删除后的元素

所以返回值是一个二元组,一方面是告诉我这个数据是来自哪个key,一方面是告诉我这个数据是什么。
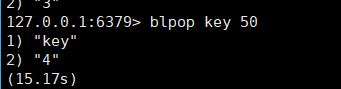
这种情况就是key不存在,所以阻塞住了,一旦key就绪了,就立即删除返回。
这个15.17s就是阻塞的时长。
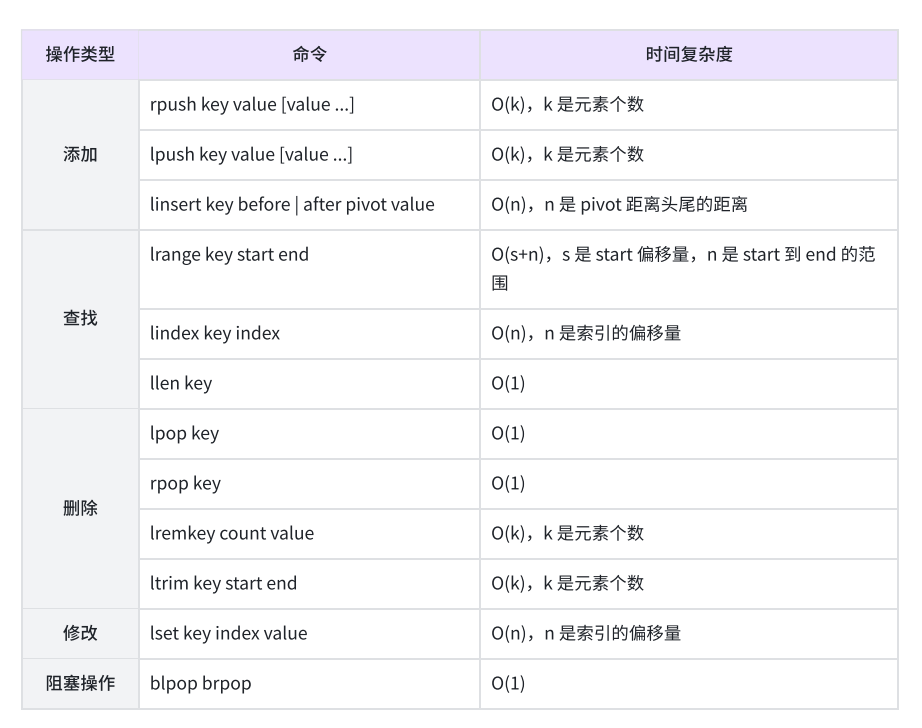
命令小结
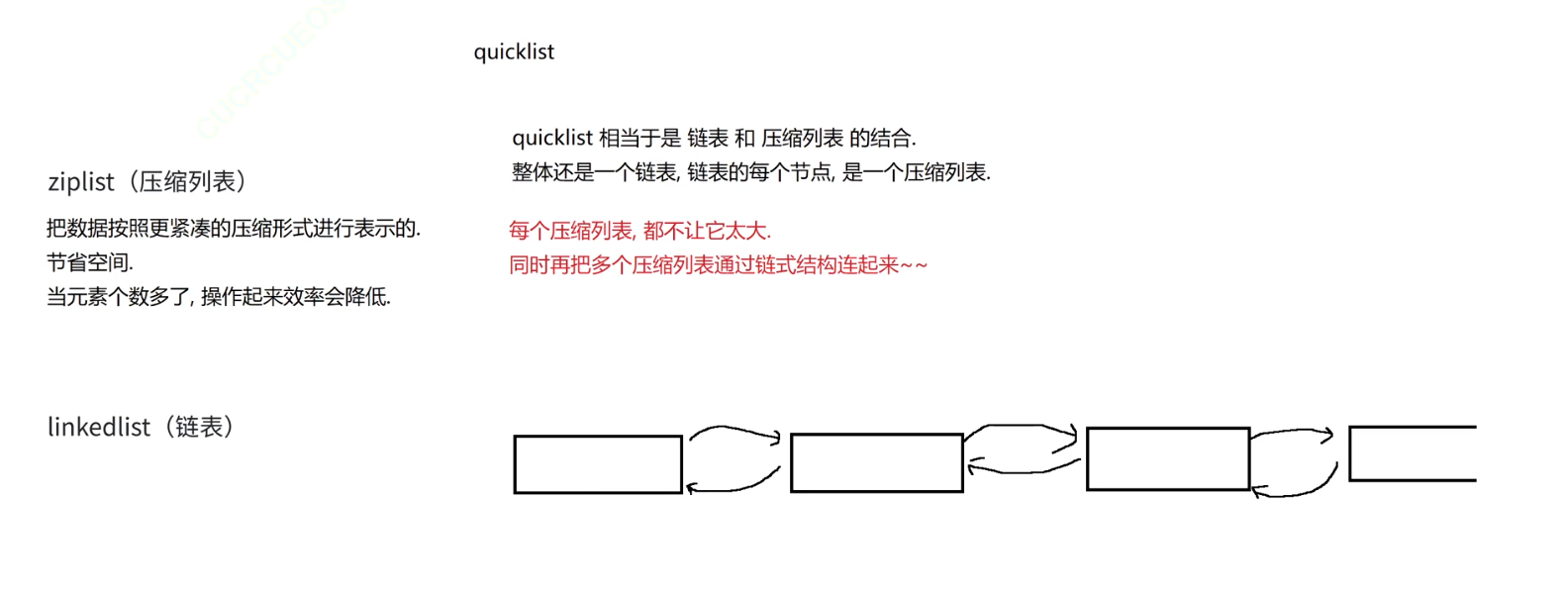
list的内部编码
其实前面的文章讲过了。
List的应用场景
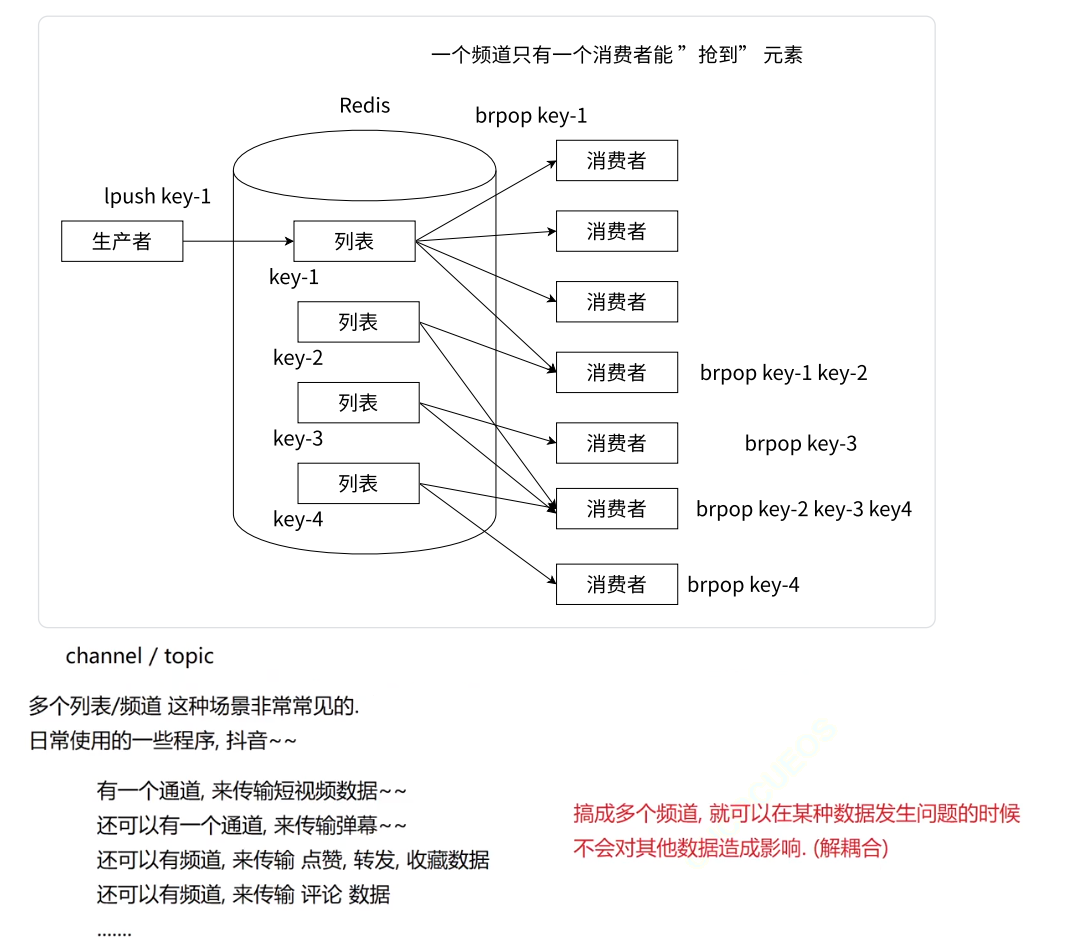
Redis 阻塞消息队列模型

分频道阻塞消息队列模型