ShardingJdbc-水平分库
水平分库
- 表结构相同、记录不同、所属库不同
- 多个库中表记录数和才是总的记录数
- 通常根据主键ID进行分表,这里采用奇偶策略
案例
- 建立库 sharding_demo-1、sharding_demo-2
- 每个库建立表 user_1、user_2 表结构相同
- id 为主键,bigint 类型
- clientId,bigint 类型
- 分库规则
- client_id 为偶数的记录存储到 sharding_demo-1 库
- client_id 为奇数的记录存储到 sharding_demo-2 库
- 分表规则
- id 为偶数的记录存储到 user_1表
- id 为奇数的记录存储到 user_2表
建表语句
库(sharding_demo-1、sharding_demo-2)自行创建
Bash
CREATE TABLE `user_1` (
`id` bigint NOT NULL,
`client_id` bigint NOT NULL,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NULL DEFAULT NULL,
`age` int NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic;
项目代码
自行创建 SpringBoot 项目 ShardingJDBCDemo
- 导入依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.1.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.study</groupId>
<artifactId>ShardingJDBCDemo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ShardingJDBCDemo</name>
<description>ShardingJDBCDemo</description>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<!-- mysql 数据库连接依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!-- 数据库连接池依赖 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<!-- MybatisPlus -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.0.5</version>
</dependency>
<!-- shardingsphere 必须的依赖 sharding-jdbc !!! -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!-- 简化实体get/set依赖 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>- 创建用户实体类
java
package com.study.shardingjdbcdemo.demo.entity;
import lombok.Data;
@Data
public class User {
private Integer id;
private String name;
private Integer age;
private Integer clientId;
}- 编写 mapper
java
package com.study.shardingjdbcdemo.demo.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.study.shardingjdbcdemo.demo.entity.User;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface UserMapper extends BaseMapper<User> {
}- 启动类增加mapper扫描
java
package com.study.shardingjdbcdemo;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("com.study.shardingjdbcdemo.demo.mapper")
public class ShardingJdbcDemoApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingJdbcDemoApplication.class, args);
}
}水平分库分表配置
application.yml 配置详解
yaml
# 水平分库分表 多库多表
server:
port: 8081
spring:
main:
# 一个实体类对应两张表,覆盖
allow-bean-definition-overriding: true
shardingsphere:
datasource:
names: ds1,ds2 # 多数据源
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3307/sharding_demo-1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: r#dcenter9
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3307/sharding_demo-2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC
username: root
password: r#dcenter9
sharding:
# default-database-strategy: # 默认分库策略 所有表的分库策略
# inline:
# # 分库列
# sharding-column: id
# # 分库算法 id 偶数存储到 user_1 奇数存储到 user_2
# # 除2取余数 要么是0要么是1 然后给+1 对应的就是user_1 user_2
# algorithm-expression: ds$->{id % 2 + 1}
tables:
user:
# 分表规则 哪个库(ds1)哪张表(user)以及表名称规则(user_1、user_2)
# ds1 ds2 user_1 user_2
actual-data-nodes: ds$->{1..2}.user_$->{1..2}
# key-generator:
# column: id
# type: SNOWFLAKE
# 分表策略
table-strategy:
inline:
# 分表列
sharding-column: id
# 分表算法 id 偶数存储到 user_1 奇数存储到 user_2
# 除2取余数 要么是0要么是1 然后给+1 对应的就是user_1 user_2
algorithm-expression: user_$->{id % 2 + 1}
database-strategy: # 个性化指定某个表(user)的分库策略
inline:
# 分库列
sharding-column: client_id
# 分库算法 client_id 偶数存储到 ds1 奇数存储到 ds2
# 除2取余数 要么是0要么是1 然后给+1 对应的就是ds1 ds2
algorithm-expression: ds$->{client_id % 2 + 1}
props:
# 打印SQL日志
sql:
show: true 说明:
与水平分表相比, 只是额外配置多配置了一个数据源(ds2)以及 user 表的 分库策略 (database-strategy)测试结果
奇数测试
insert_client2_id1:插入 clientId 为 2、id 为 1 的数据
java
@Test
void insert_client2_id1() {
User user = new User();
user.setId(1);
user.setName("user_" + 1);
user.setClientId(2);
user.setAge(18);
userMapper.insert(user);
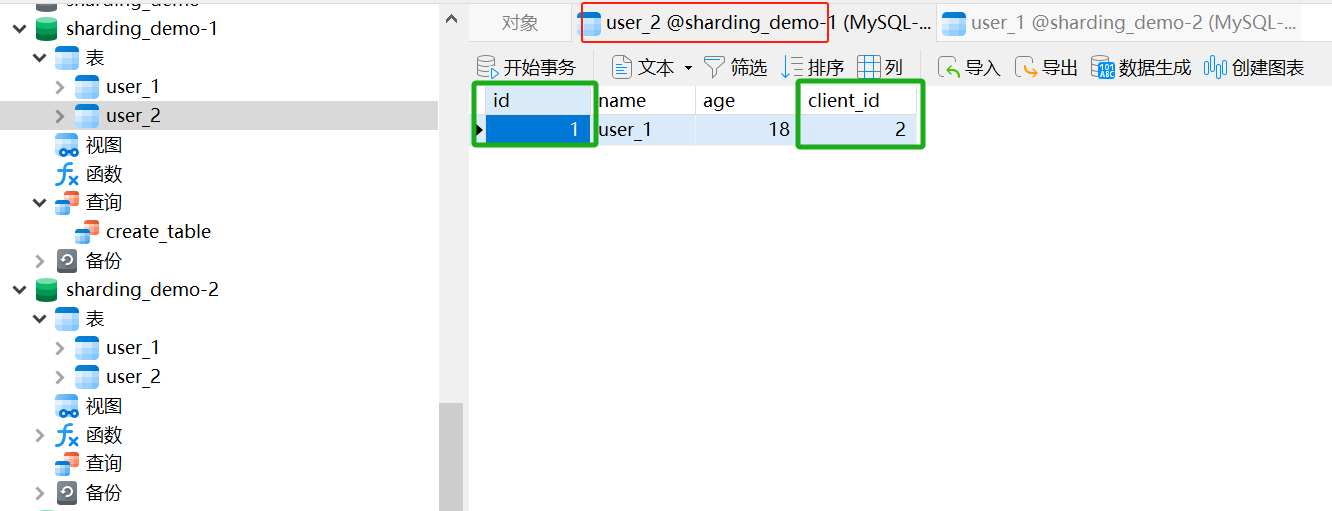
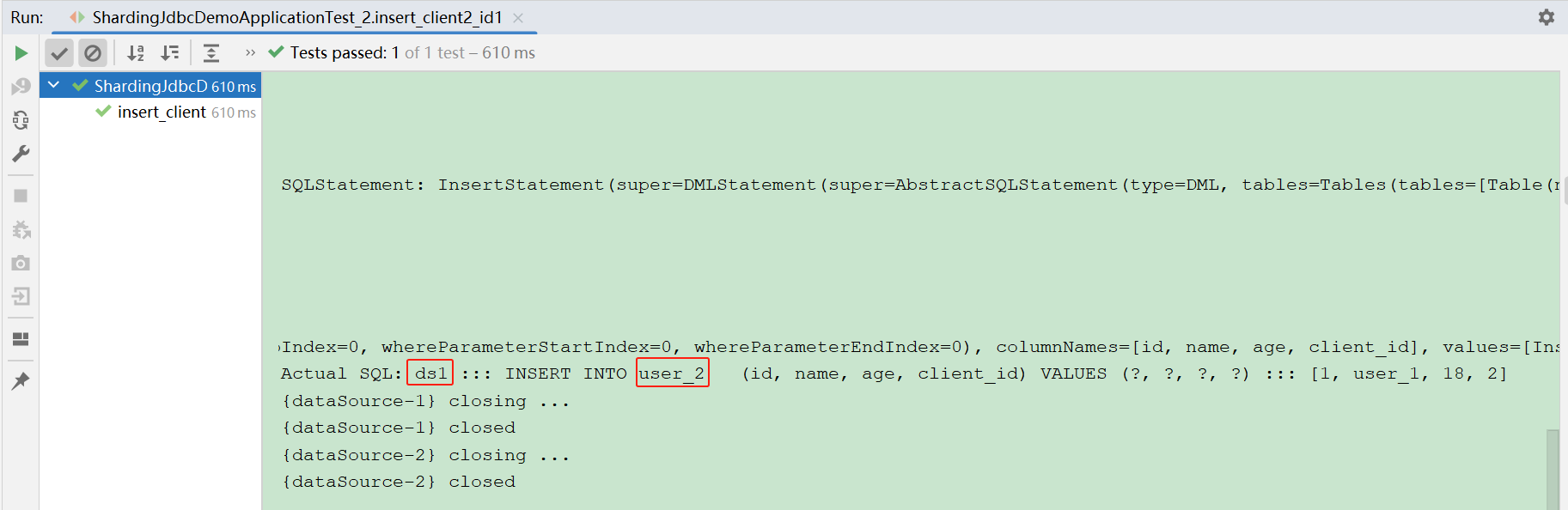
}- 运行结果
- clientId 为 2,根据奇偶策略,偶数应存储到库 ds1(sharding_demo-1)
- id 为 1,根据奇偶策略,奇数应存储到表 user_2
- 最终存储到 sharding_demo-1 库 的 user_2 表
说明:
日志中也可以看出,使用的是ds1(sharding_demo-1)插入的表为 user_2偶数测试
insert_client1_id2:插入 clientId 为 1、id 为 2 的数据
java
@Test
void insert_client1_id2() {
User user = new User();
user.setId(2);
user.setName("user_" + 2);
user.setClientId(1);
user.setAge(20);
userMapper.insert(user);
}- 运行结果
- clientId 为 1,根据奇偶策略,偶数应存储到库 ds2(sharding_demo-2)
- id 为 2,根据奇偶策略,奇数应存储到表 user_1
- 最终存储到 sharding_demo-2 库 的 user_1 表
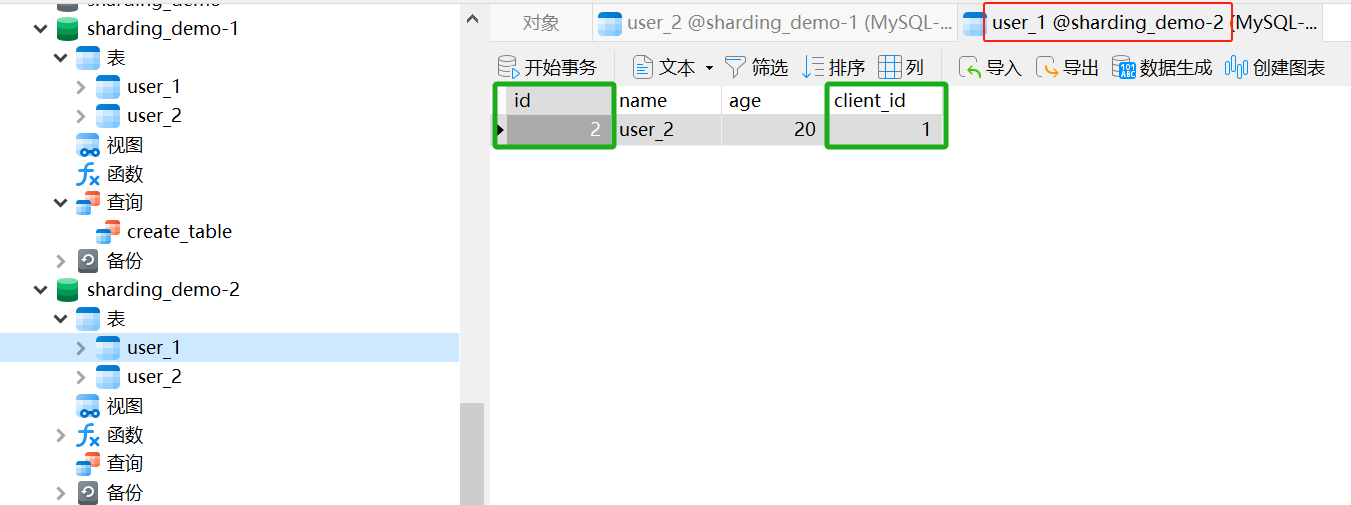
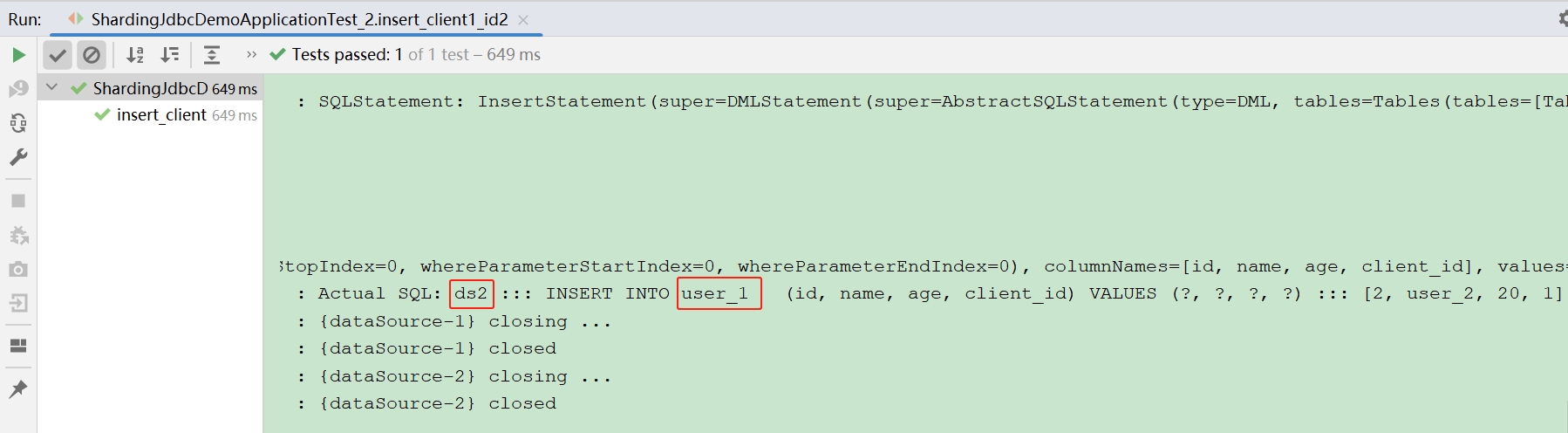
说明:
日志中也可以看出,使用的是ds2(sharding_demo-2)插入的表为 user_1查询测试
selectById
- 查询 id为1 且 clientId为2 的记录
- 查询 id为2 且 clientId为1 的记录
java
@Test
void selectById() {
userMapper.selectOne(new QueryWrapper<User>().eq("id",1).eq("client_id",2));
userMapper.selectOne(new QueryWrapper<User>().eq("id",2).eq("client_id",1));
}-
运行日志
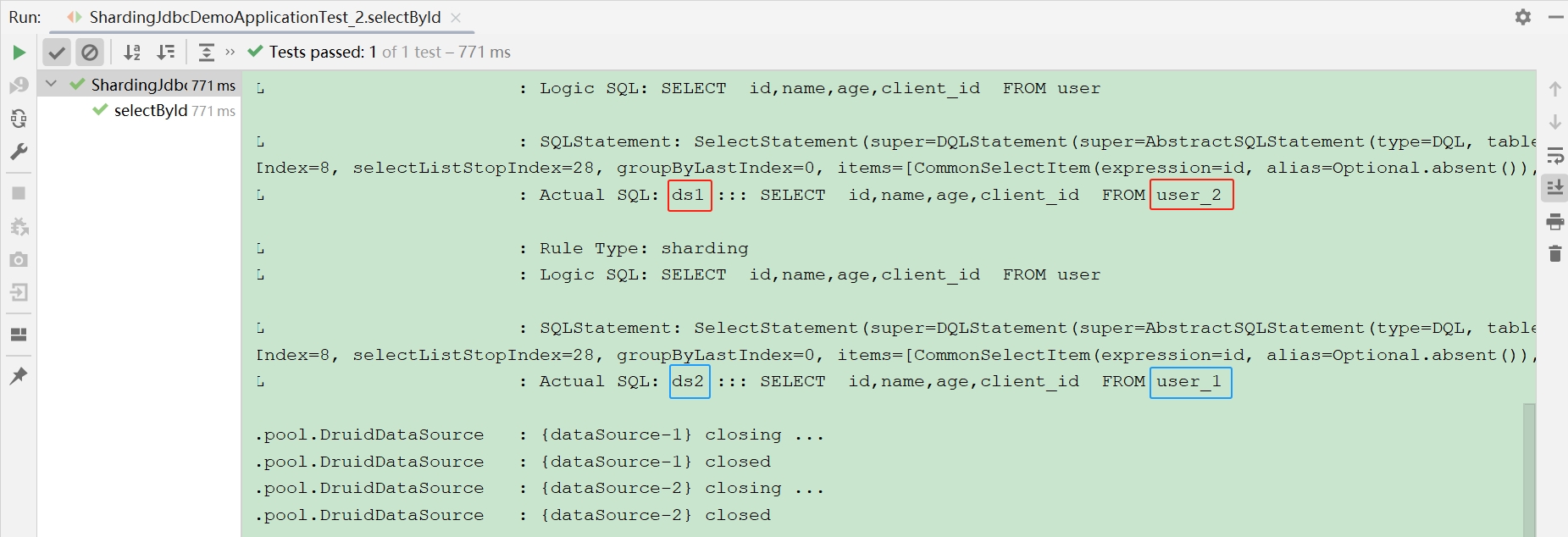
说明:
1. clientId = 2 且 id = 1, 数据库 ds1 (sharding_demo-1) ,查询的表为 user_2
2. clientId = 1 且 id = 2, 数据库 ds2 (sharding_demo-2) ,查询的表为 user_1
3. 查询和插入均遵守分表奇偶策略,完全正确 !!!
综上所述,ShardingSphere-ShardingJdbc-水平分库奇偶策略 Demo 则告一段落,希望对大家有所帮助!