分库分表介绍
有关分库分表的介绍说明,参考下面文章:
https://blog.csdn.net/liangmengbk/article/details/155918663?spm=1001.2014.3001.5501
shardingsphere官网:
https://shardingsphere.apache.org/index_zh.html
分库分表实战
下面用一个操作的案例,说明如何用shardingsphere完成分库分表。
案例中用到的Java代码和SQL脚本,从下面的链接可以直接下载:
https://download.csdn.net/download/liangmengbk/92463969
数据库创建
为了能够清楚的看到分库分表的效果,需要准备两台电脑(服务器),分别安装MySQL。
第一台服务器做以下操作:
1.创建数据库,名称为mall_0
2.执行创建表的脚本
脚本执行完成后,会在数据库中创建两张表,如下图:
第二台服务器做以下操作:
1.创建数据库,名称为mall_1
2.执行创建表的脚本
脚本执行完成后,会在数据库中创建两张表,如下图:
以上操作完成后,数据库和表就创建好了。一共创建了两个数据库,每个数据库有两张表,一共四张表,四张表的字段完全一样。
在创建表时,有一点要注释,就是表的主键,不要设置自增,因为多个表都是自增的话,在查询时会出现主键重复的情况。用雪花算法来生成唯一的主键。
运行代码
把代码用idea打开,然后重点关注applicationContext.xml配置文件,这个文件是shardingsphere的核心配置文件
配置文件中的所有配置,都添加了中文注释说明,下面对配置中的重点内容进行说明:
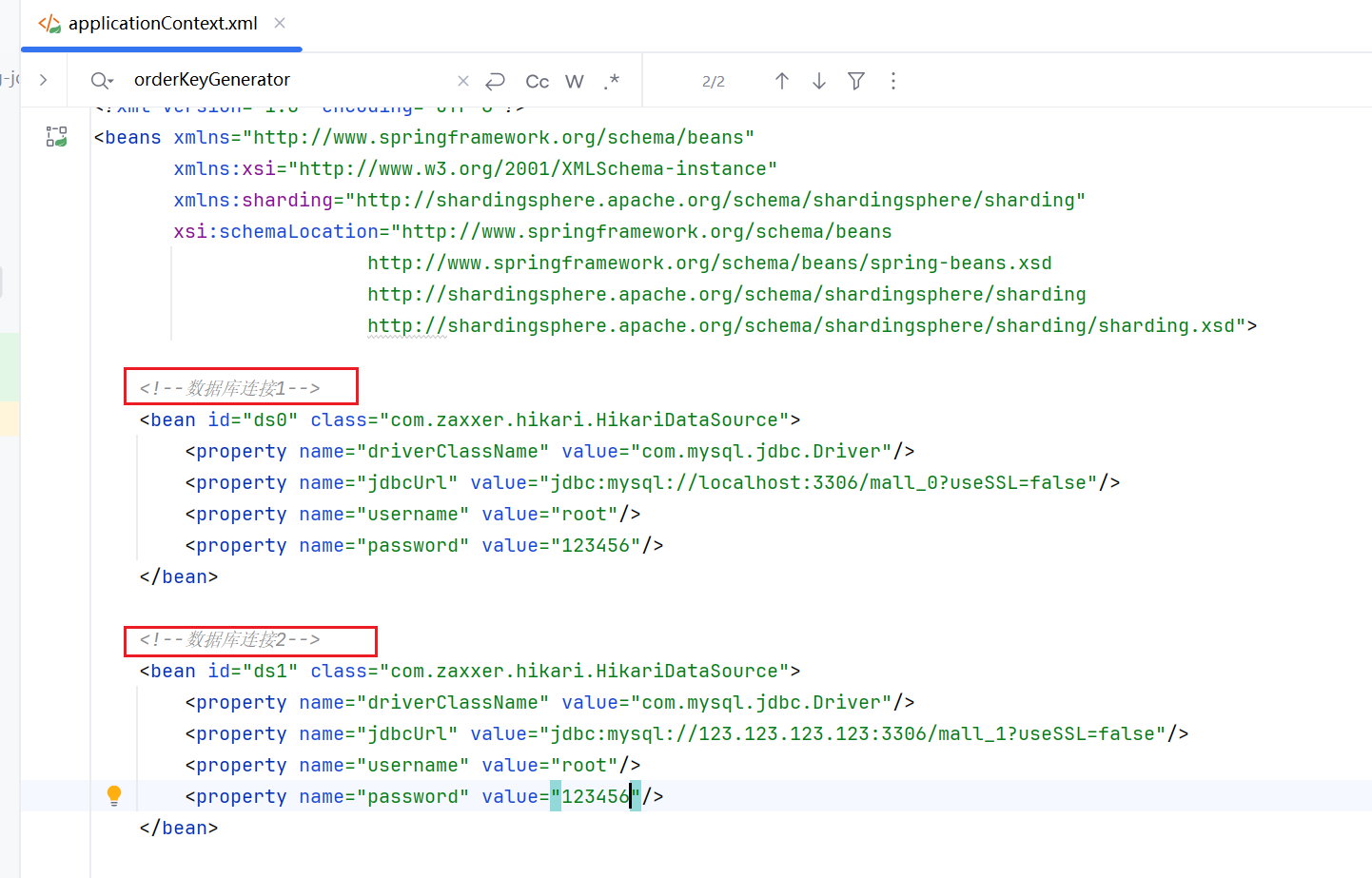
1.定义两个数据源的链接信息
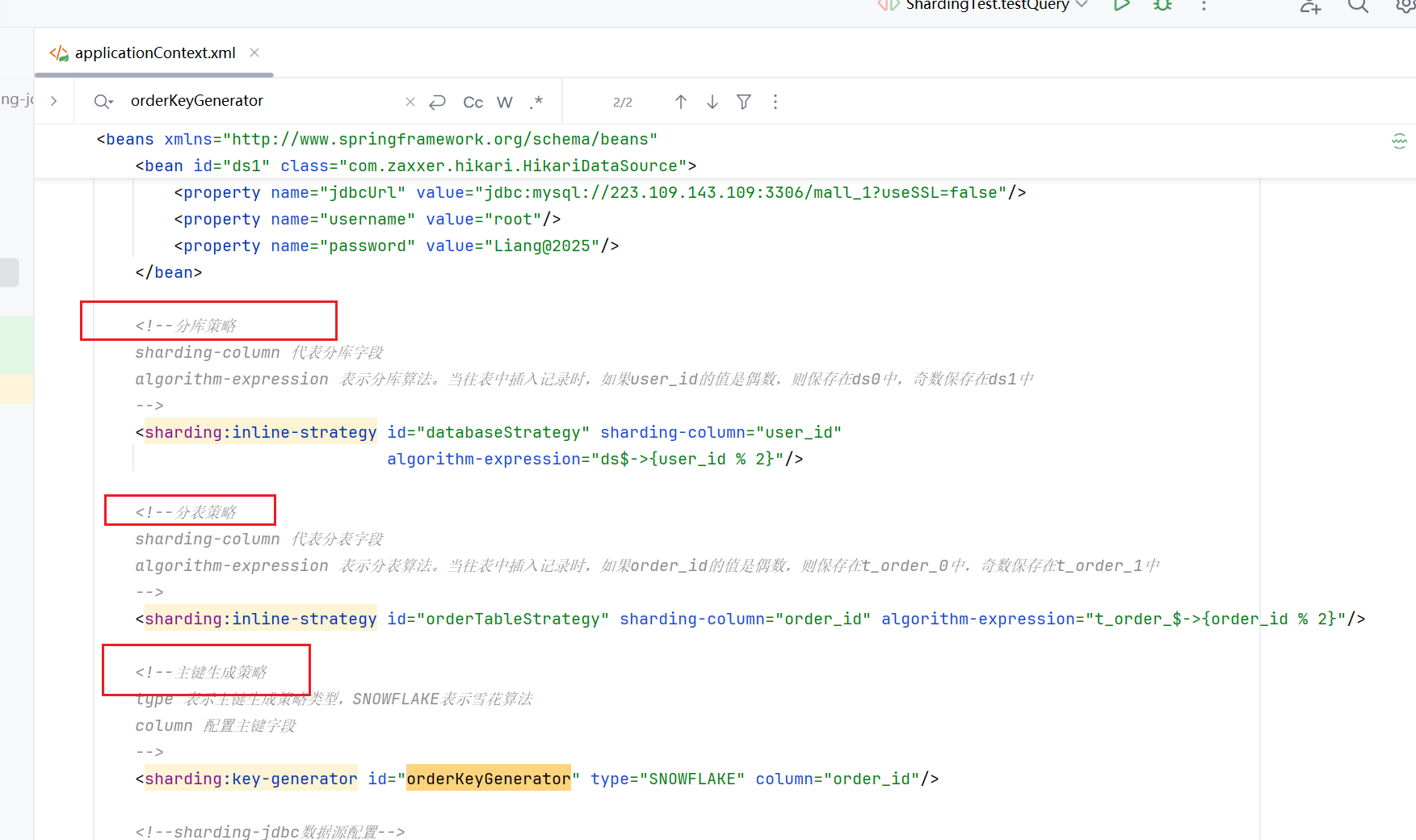
2.定义分库、分表、主键生成策略
3.将定义的数据源和各种策略应用到sharding-jdbc
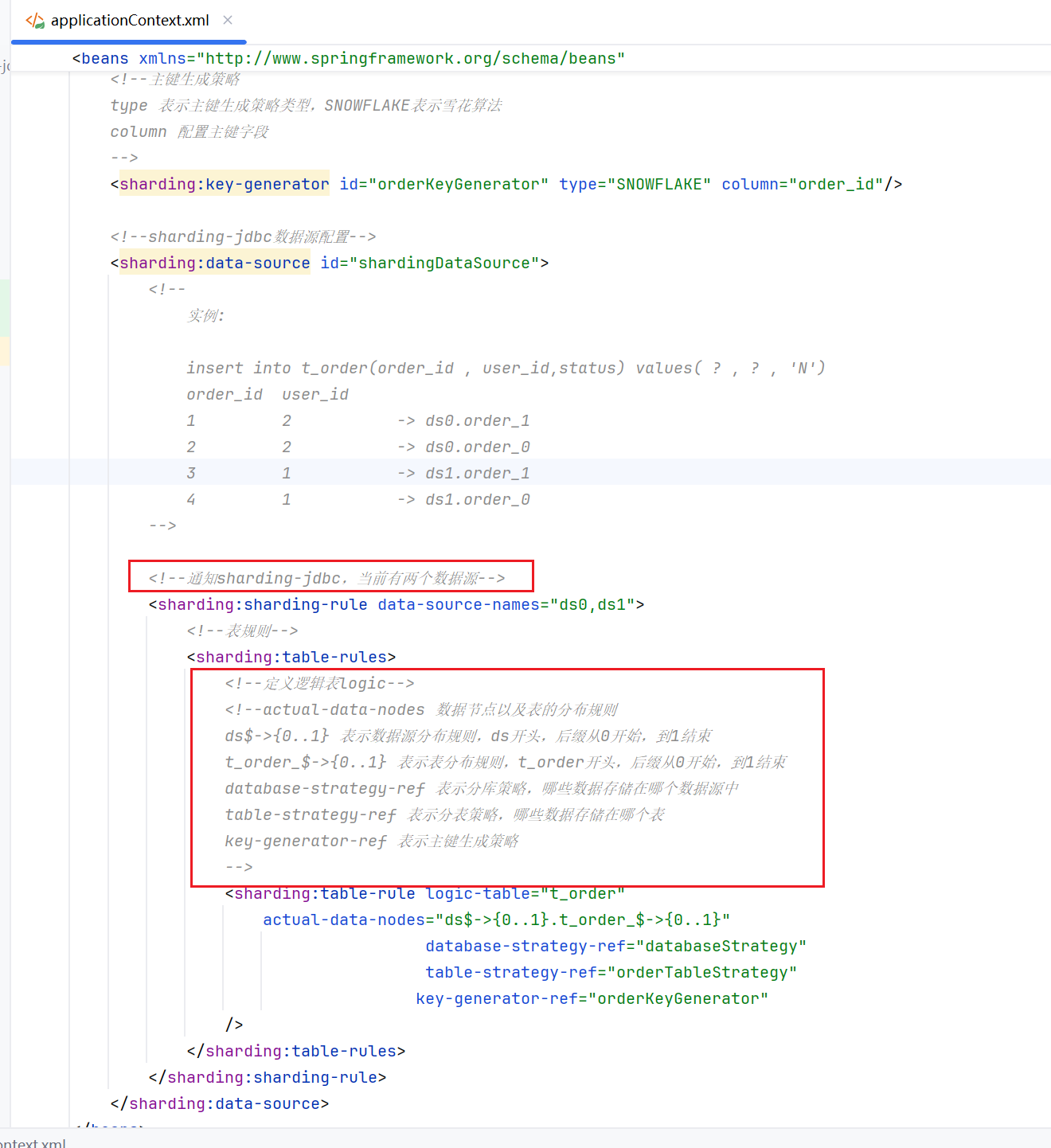
上面的三步就是核心的配置,通过这些配置就告诉了sharding-jdbc,数据源有哪些,分库分表及主键生成策略是什么。
具体的配置内容,通过注释去理解就可以了,不做过多解释。
下面把代码运行起来,看看效果:
打开ShardingTest.java测试类,运行testBatchInsert方法,往表中插入一些测试数据。
把for循环次数改成20,执行。
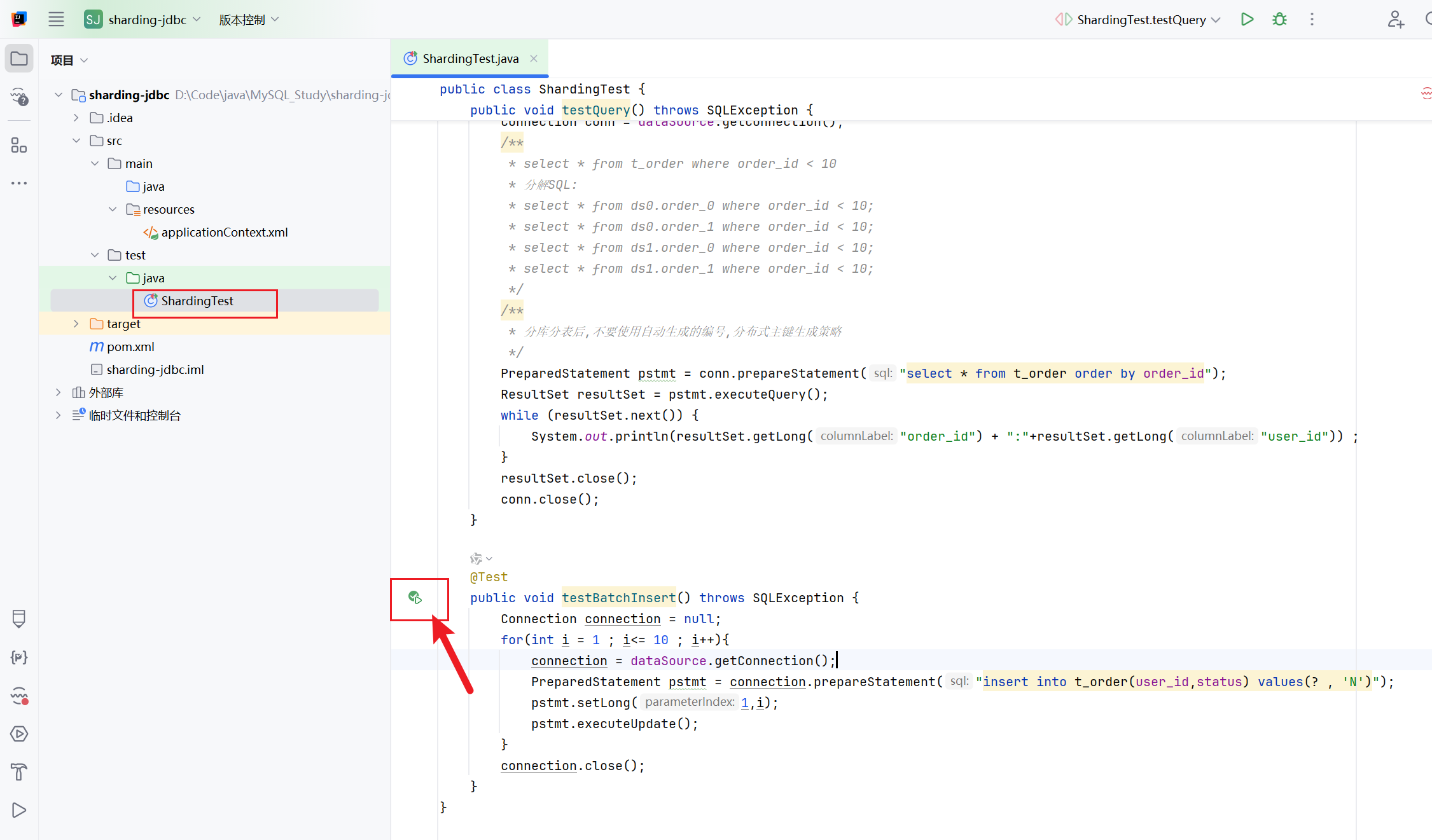
观察控制台,看到测试通过,就说明数据已经插入完成。
查询表数据
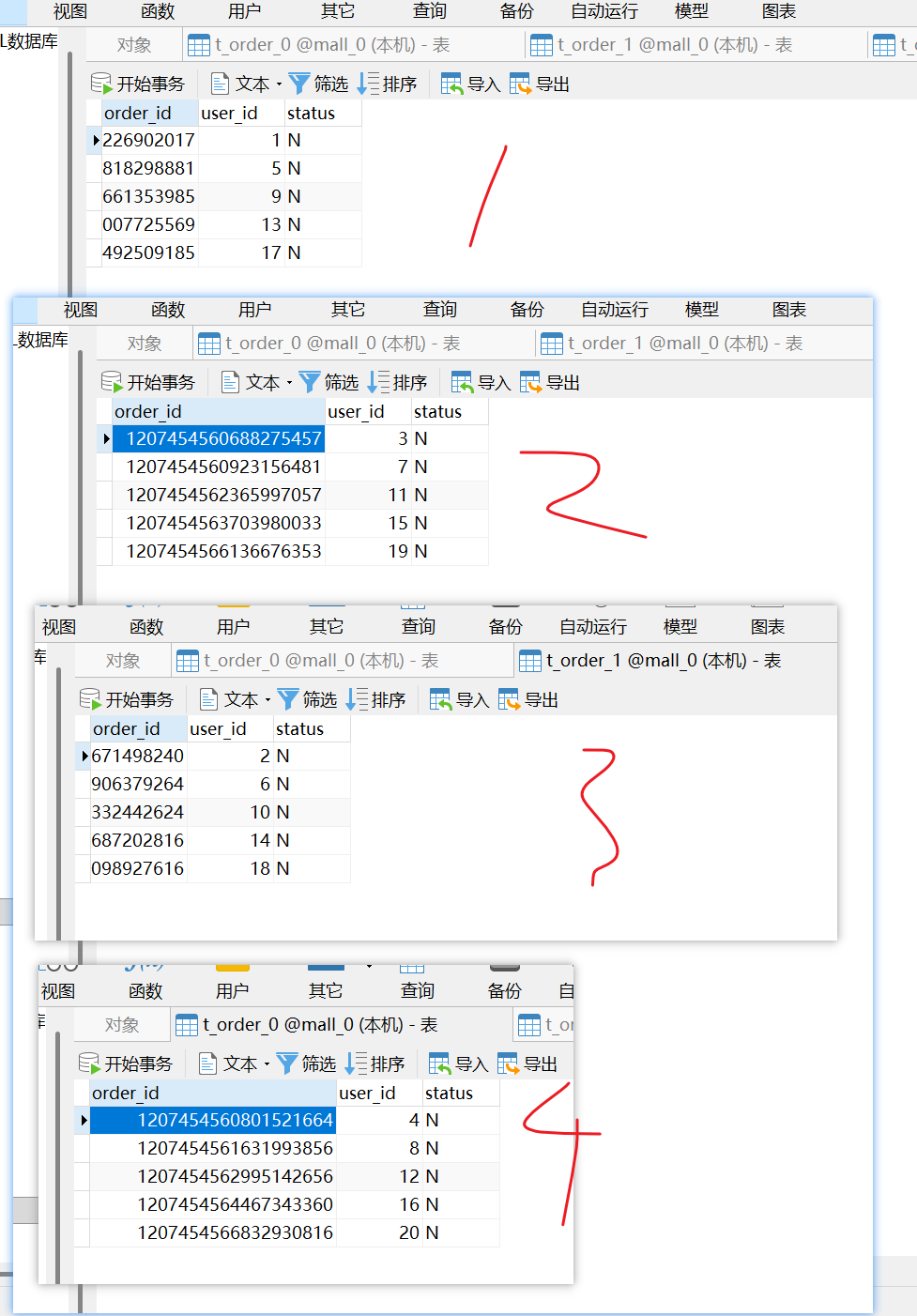
通过查询表记录,可以看到在2个不同的数据库,4张不同的表中,一共插入了20条记录。
为什么20条记录分布在两台服务器的这四个表中呢?
这就是由配置文件中的分库分表策略控制的,当前的策略是:
1.当往表中插入记录时,如果user_id的值是偶数,则保存在ds0数据库中(第一台服务器),奇数保存在ds1数据库中(第二台服务器)。
2.当往表中插入记录时,将 user_id 除以 2 取整,如果结果是偶数则保存在 t_order_0 表中,奇数保存在 t_order_1 表中。
根据这个策略,数据就会被插入到不同数据库的不同表。
策略是可以调整的,根据实际情况进行调整,数据就会插入到不同的库和表中。
数据插入完成,下面看一下数据查询:
运行testQuery方法,观察控制台的输出结果:
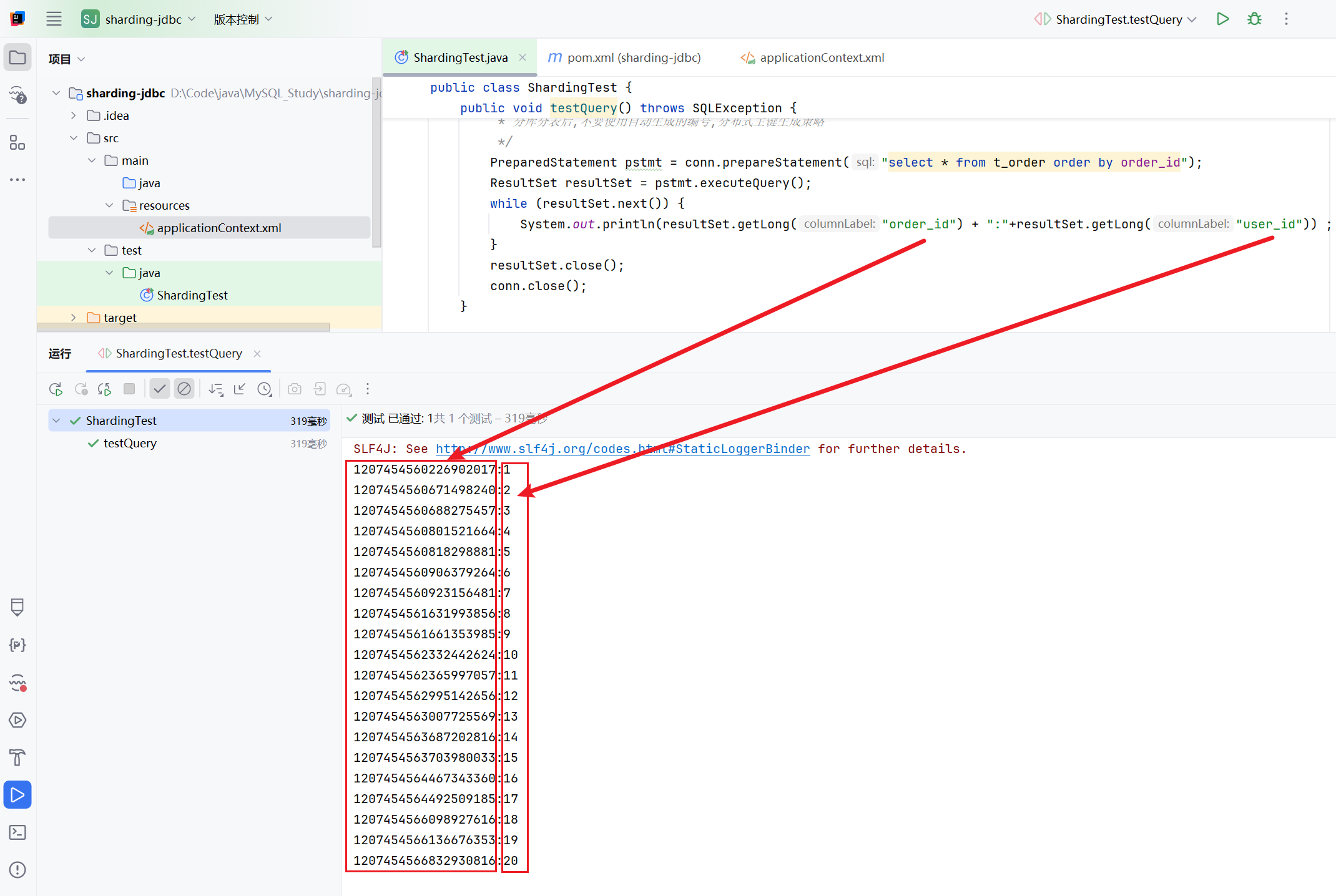
数据库查询的结果打印出来了。
一共20条记录,也就说明是把两个数据库的4张表记录都查询出来了。
总结
通过上面的操作,可以看到shardingsphere这个中间件,可以根据设置的策略把数据插入到不同的数据库和不同的表中。
在查询时,也是把多个数据源的不同表记录一起查询出来了。
更多的关于shardingsphere的用法,看官方文档。
shardingsphere目前支持所有数据库类型。